- The paper demonstrates a modular Gym environment that mitigates infinite loops and reward sparsity in Pokemon Red.
- It employs a convolutional actor-critic network using an 8-channel input with visited masks to enhance spatial and temporal awareness.
- Empirical results indicate improved exploration (coverage from 12% to 41%) and reduced looping (41.2% to 4.7%) through engineered anti-spam measures.
PokeRL: Reinforcement Learning for Pokemon Red
Introduction
"PokeRL: Reinforcement Learning for Pokemon Red" (2604.10812) investigates reinforcement learning (RL) in the context of the long-horizon, partially observable, reward-sparse JRPG Pokemon Red. The paper addresses critical failure modes observed in prior RL approaches—including infinite action loops, reward sparsity, button spam, incorrect movement semantics, and memoryless exploration—by engineering a modular Gym environment that introduces loop detection, anti-spam penalties, spatial memory via visited masks, and hierarchical rewards. The study focuses on three early-game tasks: exiting the player's house, exploring Pallet Town to reach tall grass, and winning the first rival battle, serving both as practical curriculum steps and diagnostic benchmarks for RL robustness in complex games.
System Architecture
The environment is constructed using PyBoy and Gymnasium, augmented with direct memory reading to extract game-specific variables necessary for event-triggered rewards and episode termination. The agent employs a convolutional actor-critic model (Stable-Baselines3 CnnPolicy) that processes an 8-channel input composed of four stacked grayscale frames and their corresponding visited-mask frames, generating a 1,920-dimensional latent embedding used by both the policy and value networks.
Figure 1: The actor-critic network architecture used for RL in PokeRL, utilizing frame stacks and visited masks to encode spatial and temporal context.
The action space is explicitly pruned: only up, down, left, right, A, B, and no-op are permitted, with Start and Select removed to prevent agents from exploiting menus. Double-press semantics are encoded in the environment abstraction to accurately capture the grid navigation mechanics of Pokemon Red. Direct RAM access is employed solely for reward computation and episode termination; these signals are not exposed to the policy, maintaining a separation between environmental engineering and agent learning.
Observation and Reward Engineering
Spatial memory is implemented via a per-map visited mask, which marks tiles the agent has traversed and remains aligned with global map coordinates despite camera scrolling.
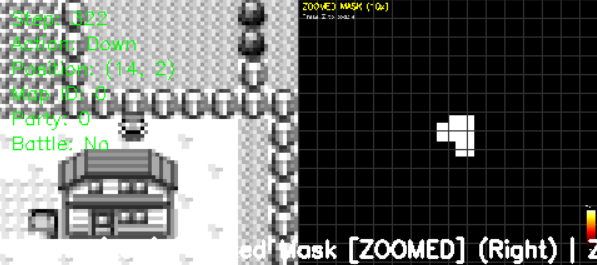
Figure 2: Downsampled grayscale frame paired with its per-map visited mask, providing the agent with explicit spatial memory.
Hierarchical reward design spans micro (per-step navigation, unique tile visits), meso (map transitions, first entry bonuses), and macro (key events such as entering tall grass, starting battles, and winning). Penalties for loops and spam are carefully calibrated; harsh negatives were empirically shown to destabilize training, whereas mild penalties suppress pathological behaviors without drowning out positive shaping rewards.
The curriculum consists of three task-oriented sequences:
- House Exit: navigation and door interaction; episode termination via map ID change.
- Exploration: reaching tall grass; metrics focus on exploration coverage.
- Battle: turn-based combat; rewards incentivize effective offensive moves and victory.
Loop and Spam Mitigation
A three-layer anti-loop strategy is implemented:
- Position visit penalties based on repeated tile occupancy within an episode.
- Action pattern detection leveraging a sliding window, penalizing repetitive button sequences.
- Position loop detection via radius-based revisit tracking.
Empirical analysis demonstrates a dramatic reduction in pathological looping episodes upon activation of the anti-loop modules.
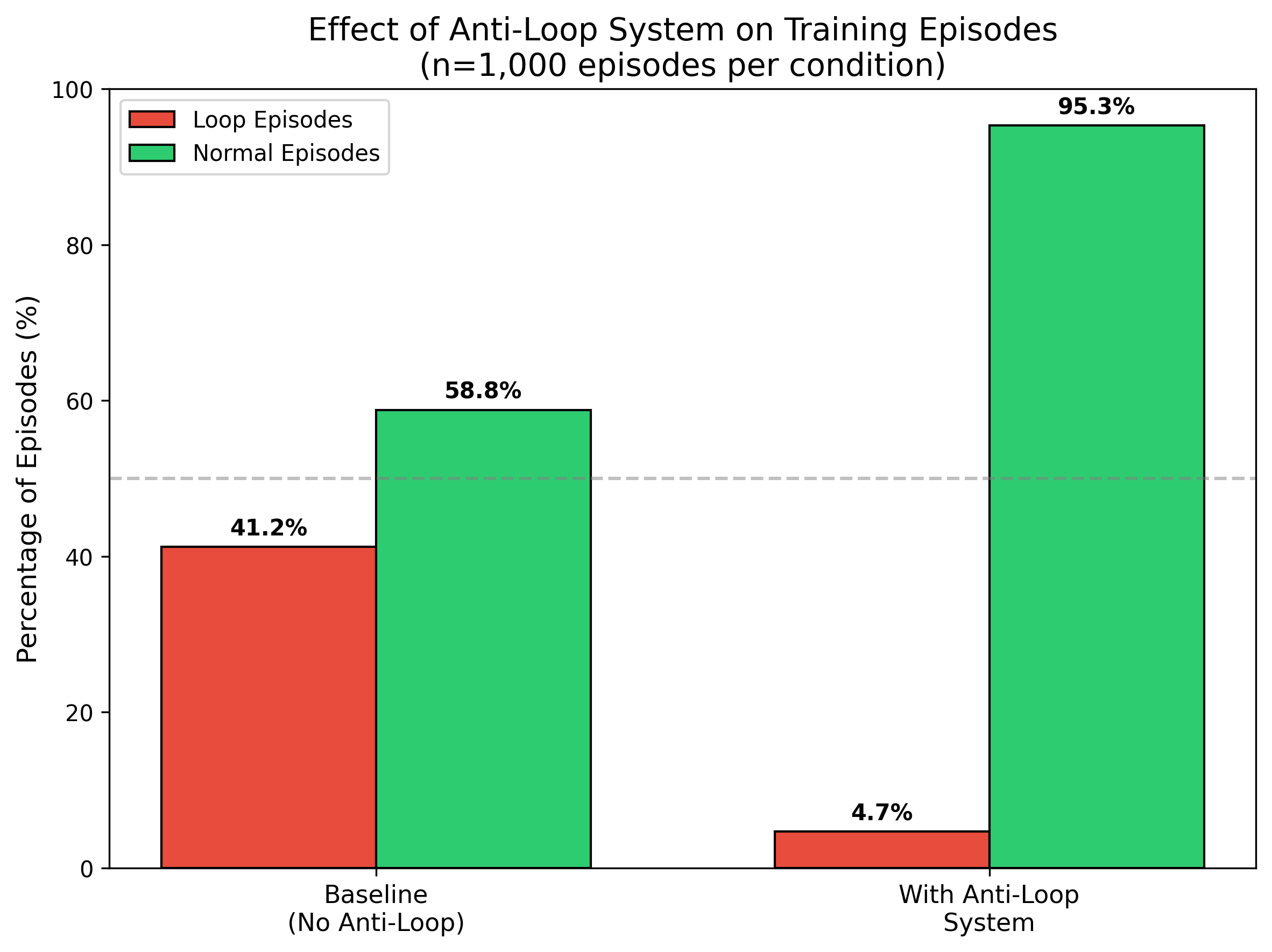
Figure 3: The anti-loop system substantially reduces loop episodes during training, shifting agent behavior towards more effective exploration.
Anti-spam is managed through graduated penalty schemes targeting button streaks, specifically for A, B, and static position actions. Removal of Start/Select closes key loopholes. Action distribution is monitored and quantified using Shannon entropy, with entropy rising from 1.21 to 1.82 bits post anti-spam, indicating more uniform action exploration and preventing mode collapse.
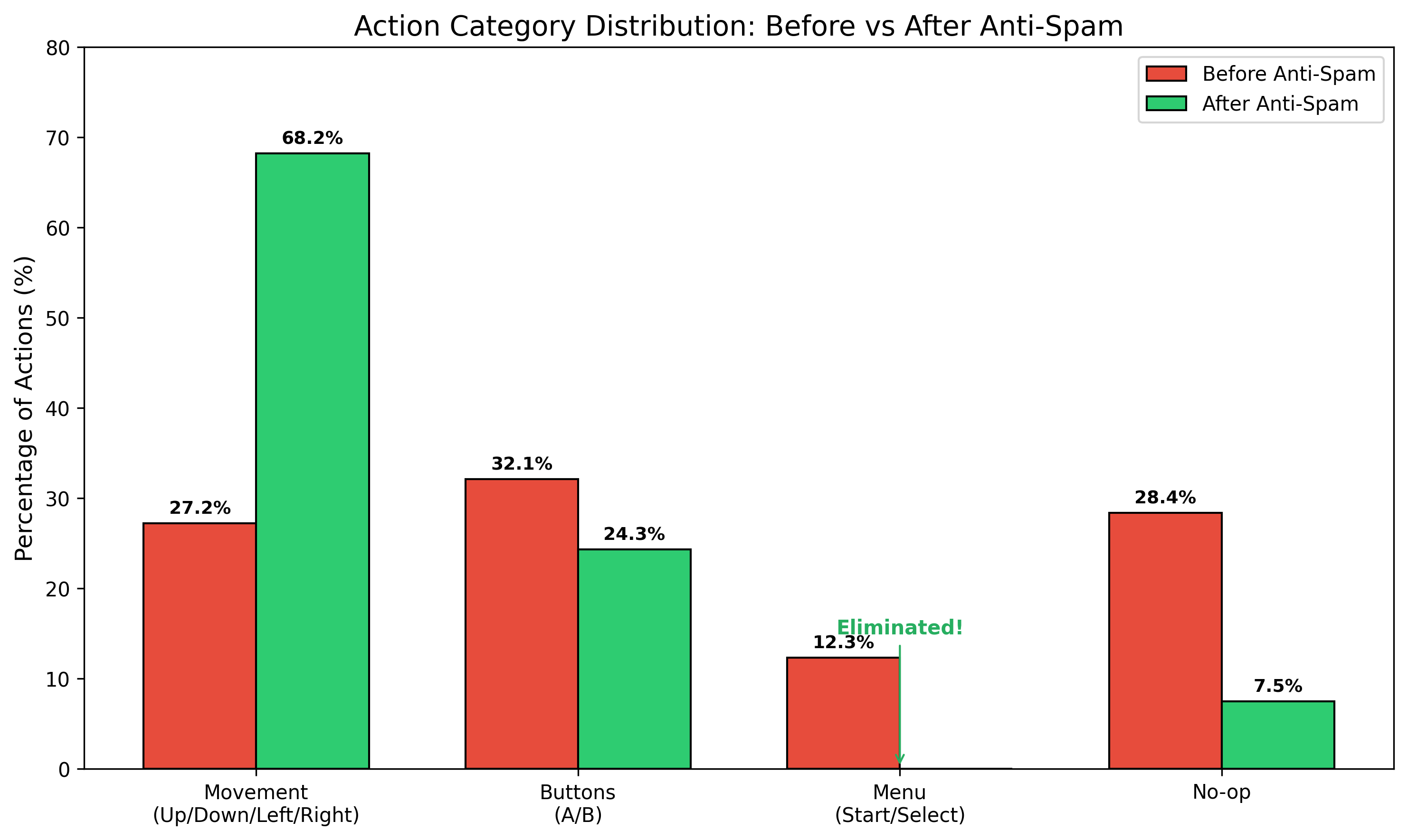
Figure 4: Action distribution improves markedly after anti-spam implementation, increasing movement frequency and reducing menu/button spam.
Empirical Results
Ablation studies reveal significant benefits when spatial memory is introduced. Comparing environments with and without the visited mask, exploration coverage, unique positions per episode, and revisit ratio improve considerably; coverage rises from 12% to 41%, unique positions increase by over 40%, revisit ratio drops from 4.8 to 3.1.
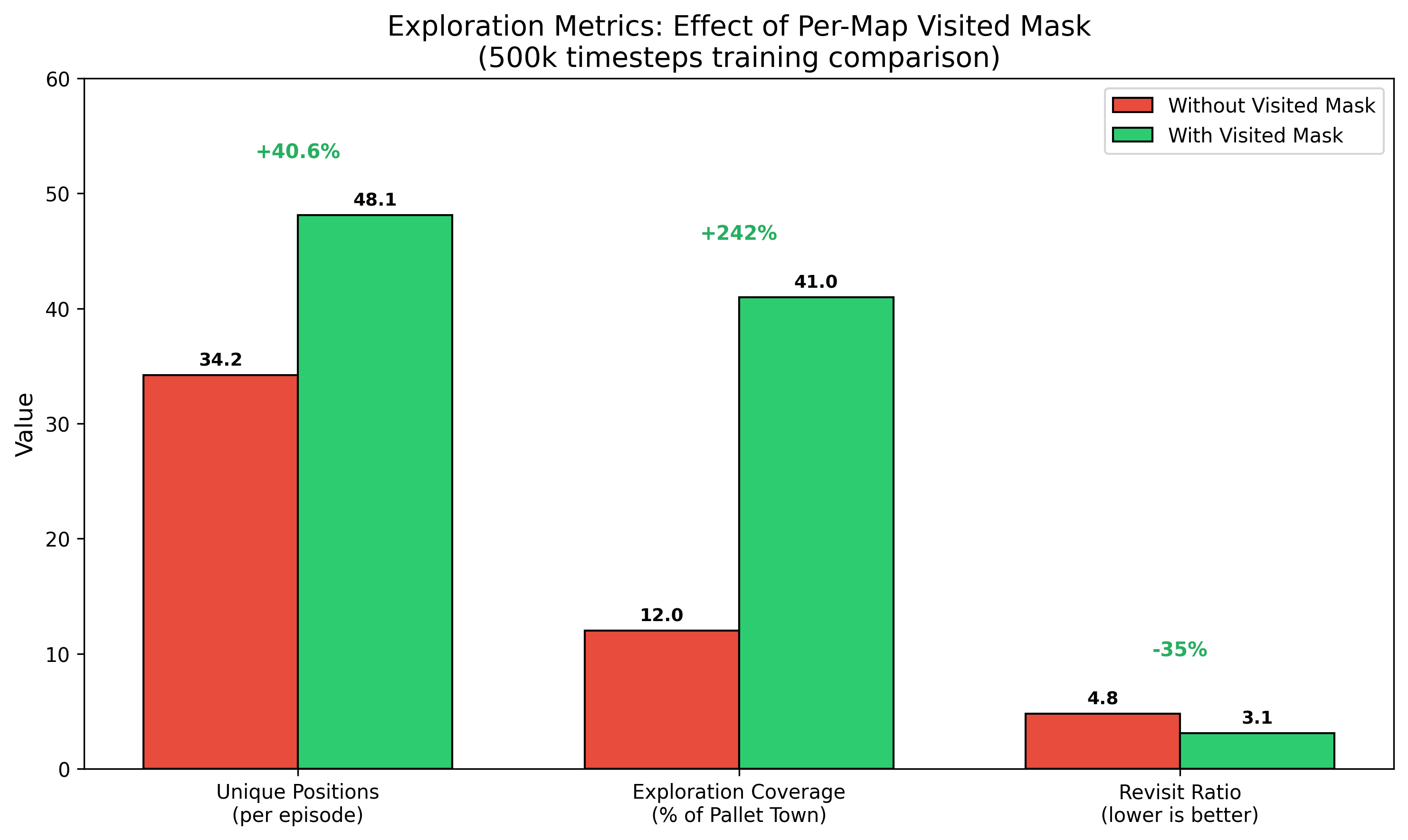
Figure 5: Exploration performance is enhanced by incorporating per-map visited masks, enabling agents to avoid redundant exploration.
Similarly, loop episodes (where pathological repetitive behaviors dominate) are reduced from 41.2% to 4.7% following anti-loop integration. Sequence-level performance metrics indicate reliable acquisition of target behaviors, e.g., house exits achieved in 65% of episodes, tall grass exploration in 60%, and rival battle wins around 50% after sustained training. However, RL agents still fall short of human-level consistency, and manual intervention is occasionally needed for dialogue progression, highlighting ongoing limitations.
Discussion and Implications
The explicit modeling of game-specific quirks, curriculum decomposition, and mild negative shaping collectively yield a more stable, interpretable RL training process for complex, partially observable, reward-sparse games. By instrumenting the environment with loop/spam detectors and spatial memory, the authors circumvent key pitfalls observed in vanilla PPO deployments, while maintaining agent autonomy over reward acquisition strategies. The theoretical implication is that environment-side engineering, rather than solely algorithmic innovation, is necessary to advance RL beyond toy benchmarks towards full-game competence in JRPG settings.
From a practical standpoint, PokeRL offers a viable template for modular RL research in video games. The open-source system can be adapted for rapid iteration, metric extraction, and benchmarking, facilitating community-driven progress. The approach aligns with insights from battle-focused RL studies ("PokeLLMon: A Human-Parity Agent for Pokemon Battles with LLMs" (Hu et al., 2024)) and prior exploration-centric works (Go-Explore (Ecoffet et al., 2019)), positioning PokeRL as a critical intermediate platform for sequential decision making.
Future Directions
Potential advancements include merging the curriculum into unified, end-to-end agents that coordinate navigation, exploration, and combat over full game trajectories. Incorporating intrinsic motivation (curiosity, Go-Explore-style archives), inverse RL, and preference-based reward models may reduce reliance on handcrafted shaping and improve reward alignment. Integration of LLMs for decision making in battle modules could close the gap with human-parity performance. Open benchmarking against standardized tasks would drive reproducibility and accelerate progress in long-horizon RL for JRPGs.
Conclusion
PokeRL demonstrates that rigorous environment-side intervention—loop/spam mitigation, spatial memory design, and hierarchical rewards—is essential for training RL agents in complex games such as Pokemon Red. The system reliably acquires non-trivial early-game behaviors and avoids critical failure modes observed in prior attempts, underscoring that successful RL in real games depends as much on clever environment engineering as on algorithmic sophistication. The methods and empirical findings of PokeRL provide a concrete foundation for future integrated RL research in games with challenging structure and sparse rewards.

