The PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Abstract: We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “The PokeAgent Challenge: Competitive and Long-Context Learning at Scale”
1) What is this paper about?
This paper introduces the PokeAgent Challenge, a big, fair test (a “benchmark”) for AI systems using Pokémon games. It has two parts:
- Competitive Battling: two-player Pokémon battles (like on Pokémon Showdown).
- Speedrunning: finishing a Pokémon Emerald storyline segment as fast as possible.
The goal is to measure and improve how AI makes decisions when:
- it can’t see everything (hidden information),
- it faces smart opponents,
- and it must plan far ahead over thousands of steps.
2) What did the researchers want to learn?
In friendly, everyday terms, they wanted to answer:
- Can AI think strategically when it doesn’t know everything, like in a card game where the opponent’s hand is hidden?
- Can AI plan well over a long time, like planning a whole road trip with many stops, detours, and changing conditions?
- Do general-purpose AIs (LLMs, or LLMs) actually play well, or do specialist methods (like reinforcement learning, RL) work better?
- Can we build a standard, fair way to compare different AI systems on the same tasks so results are meaningful?
3) How did they study it?
They built two standardized tracks with tools, datasets, and leaderboards so anyone can test their AI fairly.
- Competitive Battling (Pokémon Showdown):
- What it’s like: A turn-based, two-player game where you choose moves without seeing everything about the opponent’s team at first. That’s called “partial observability.” Think of it like chess where some pieces are hidden until revealed.
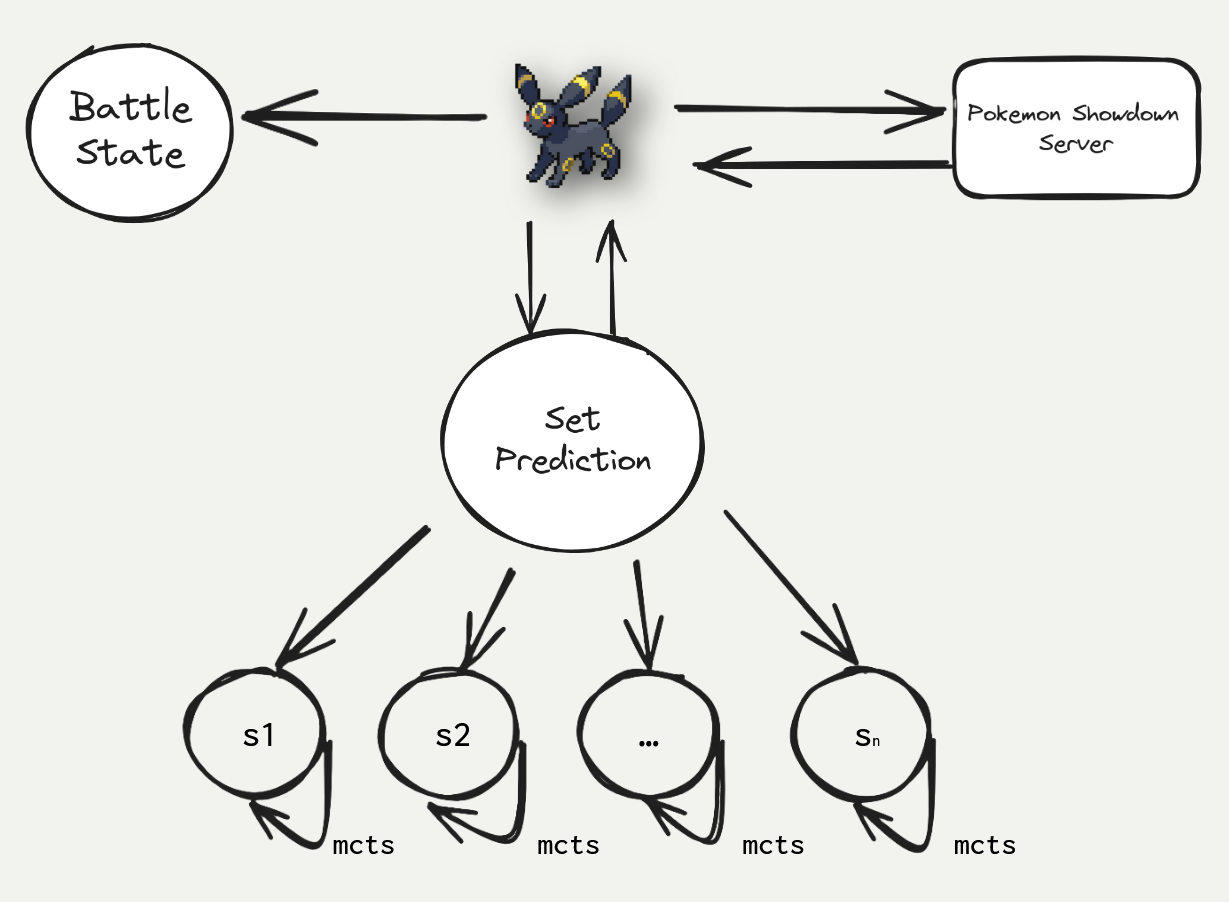
- What they provided: Over 20 million recorded battle examples (so AIs can learn), 200,000+ realistic team setups, and strong example AIs (baselines) using different methods:
- RL (reinforcement learning): AIs learn by trying actions and getting feedback—like practicing a sport and improving with coaching.
- LLM-based agents: A LLM “reasons” about the game using a support system (a “harness”) that turns the game state into text and lets the model analyze options.
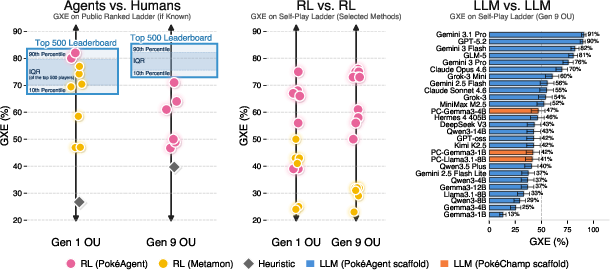
- How they scored AI: They ran AI-vs-AI matches on a dedicated server and used stable rating systems to rank skill (similar to Elo, but tuned for AI-only play).
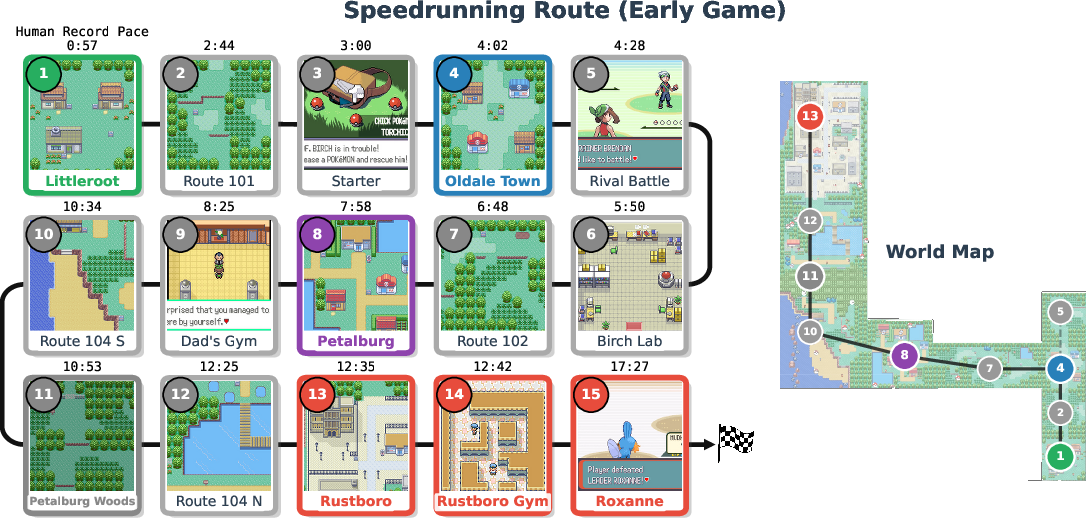
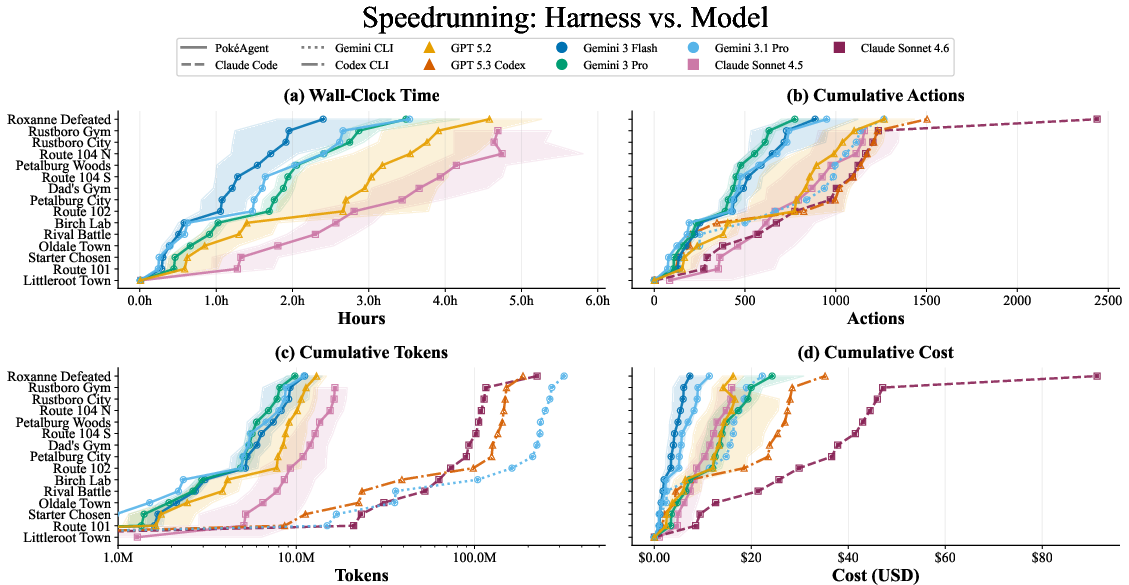
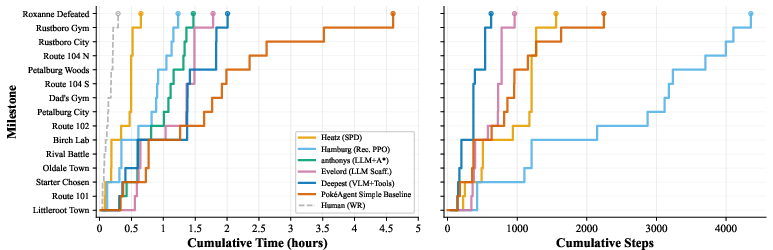
- Speedrunning (Pokémon Emerald, early-game route):
- What it’s like: The AI only sees the game screen (plus a tiny bit of status info) and must navigate, battle, and manage items to reach key “milestones” as quickly as possible. This needs good vision, memory, and planning over hours.
- What they provided: A fixed-speed emulator, a list of milestones (like checkpoints), and a timing/step-count system. They also released the first open-source “multi-agent orchestration” harness for long tasks. Think of it as a smart control room that:
- keeps the long-term plan,
- calls specialized helper bots for battles, pathfinding, and puzzles,
- and compresses history so the AI doesn’t forget what happened hours ago.
- Why a “harness” matters: A harness is like giving the AI a map, a to-do list, and tools (e.g., a pathfinder) so it doesn’t get lost. Without this support, even very advanced models wander or get stuck.
They validated everything by running a NeurIPS 2025 competition with 100+ teams across both tracks, then set up permanent leaderboards at https://pokeagentchallenge.com.
4) What did they find, and why is it important?
Here are the main takeaways, in simple terms:
- Specialist methods beat generalist models right now.
- In battles, RL and search-based agents (like advanced planning bots) performed better than LLMs that “think in words.”
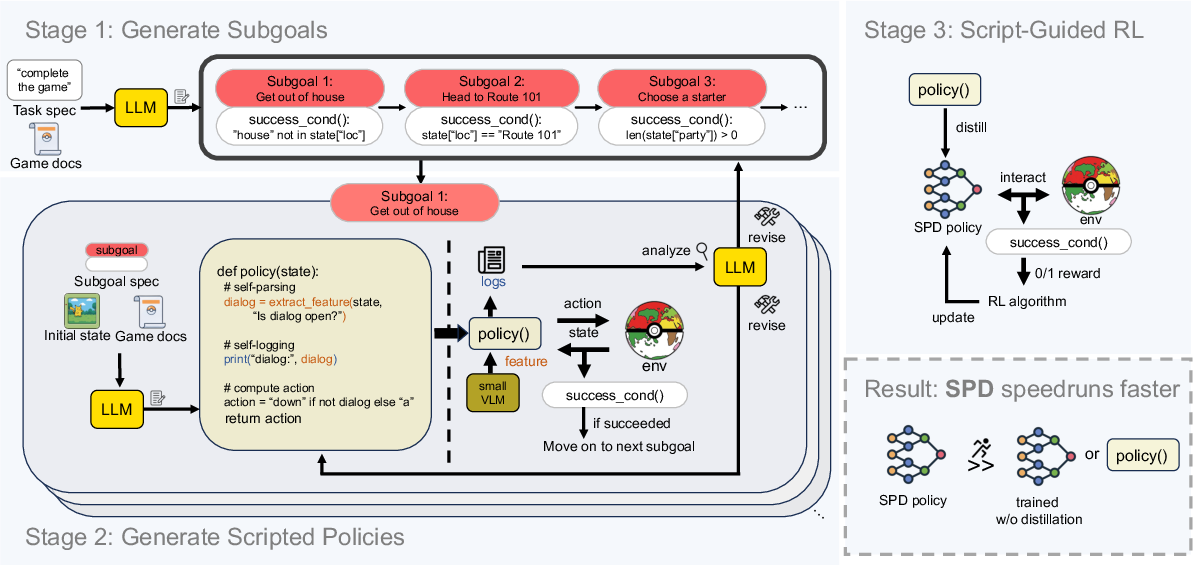
- In speedrunning, the winner combined LLMs and RL: an LLM first wrote simple “scripts” for sub-tasks, then RL distilled these into fast, reliable policies. This hybrid was far faster than pure LLM setups.
- A harness is essential for long tasks.
- Raw LLMs (even very powerful ones) made almost no progress in speedrunning without a good harness. They forgot plans, repeated mistakes, or got stuck in menus.
- With the right harness, the same models improved a lot—but still lagged humans and RL-heavy approaches.
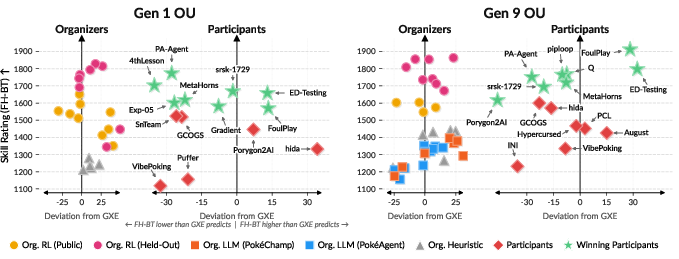
- Pokémon tests skills other benchmarks miss.
- The paper shows that being good on typical LLM tests (like trivia or coding problems) does not predict being good at Pokémon battling.
- That means Pokémon battles measure different abilities—like recovering after mistakes, planning under pressure, and reasoning when parts of the world are hidden.
- Big, high-quality resources are now public.
- 20M+ battle examples, 200k+ team sets, strong baseline agents, servers, and evaluation tools are all released. This helps the community make fair, reproducible progress.
Why this matters: Real-world decision-making often involves hidden information, changing opponents, and long-term plans (think cybersecurity, logistics, or robotics). A benchmark that brings all three together can push AI toward skills that transfer beyond games.
5) What’s the impact, and what’s next?
This challenge turns Pokémon into a “living benchmark”—a shared, evolving place to test AI systems fairly and repeatedly. It already drew strong interest and produced new ideas (like script-to-RL distillation). The authors highlight four open problems that point to future progress:
- Better in-game “sense of place” for vision models.
- Today’s agents often struggle to know exactly where they are and how far actions move them. This is like trying to navigate a city with a blurry map.
- Closing the LLM–RL gap in battles.
- Can we combine LLMs’ knowledge with RL’s precision so generalist models play as strategically as specialist ones?
- Full-game runs with open-source models.
- Frontier (proprietary) models have finished full games with heavy support; doing this with open models would make research more accessible.
- Approaching human speedrunning times.
- The best AI is still much slower than skilled humans. Getting faster requires better navigation, route planning, and fewer wasted steps—useful skills for any time-critical task.
In short: The PokeAgent Challenge gives AI researchers a clear, fair way to test and improve decision-making under pressure and over long stretches of time. It’s fun (it’s Pokémon!), but it also pushes AI toward abilities that matter in the real world.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The following concrete gaps and open problems emerge from the paper and can guide targeted follow‑up research:
- Benchmark scope in RPG speedrunning is limited to early-game (first gym in Emerald); it remains unclear how methods scale to mid/late‑game puzzles (HMs, dungeons, long multi-battle segments), full-game completion, and cross‑title generalization (e.g., Red/Blue/Crystal/Emerald, remakes, ROM hacks).
- Perception settings are not standardized across difficulty tiers: the speedrunning track provides visual frames plus privileged state (party/HP), while the battling track uses structured symbolic state. A pure vision-only setting (for both tracks) and a strictly “no privileged state” variant are not provided or evaluated, leaving perception and representation learning effects underexplored.
- Compute and latency fairness are not fully controlled: Extended Timer enables arbitrarily long deliberation; API costs, token budgets, and inference latencies vary widely. There is no budgeted track (e.g., fixed think-time, token count, or FLOP limits) or compute-tier leaderboards to disentangle algorithmic merit from compute.
- Harness-versus-model attribution remains only partially disentangled despite the S×T×M×F×Φ (state, tools, memory, feedback, fine-tuning) framework; a factorial evaluation with fixed harnesses across multiple models and fixed models across multiple harnesses, under identical compute budgets, is not reported.
- Data quality for reconstructed private-information trajectories (4M “from each player’s perspective”) is not validated with error bounds; the accuracy of hidden-state inference from spectator logs, bias in reconstruction, and its downstream impact on training/offline RL are unquantified.
- Synthetic self-play (18M trajectories) and curated team datasets may encode organizer-baseline biases; generalization to adversaries and teams outside these distributions is not rigorously measured with held-out, adversarially generated, or human-curated OOD test sets.
- Team-building is central to competitive Pokémon but is not benchmarked as a standalone task; there is no standardized evaluation for team construction, opponent team inference, or joint team+policy optimization.
- Robustness to metagame shifts and ruleset changes is not systematically tested (e.g., time-split evals, “patch/week” generalization); adaptation to evolving opponent distributions and tier rebalancing remains unmeasured.
- The new Full-History Bradley–Terry (FH‑BT) rating is motivated but not deeply analyzed: sensitivity to opponent-pool composition, match sampling, and non-stationarity (live leaderboard drift) is not characterized; required match counts for stable rankings and confidence calibration are unspecified.
- Rare-event stochasticity (crits, secondary effects) and variance under different RNG seeds are not benchmarked; no protocols quantify agent stability, risk sensitivity, or robustness to tail events across repeated seeded evaluations.
- Opponent modeling and belief-state tracking under partial observability are not directly evaluated; there is no auxiliary benchmark for belief calibration (e.g., ability/sets/posterior inference), nor metrics like Brier scores for outcome/win-prob prediction.
- Failure mode taxonomies (panic behavior, goal oscillation, memory corruption) are qualitative; there is no standardized stress-test suite to elicit and quantify these failure patterns across models and harnesses.
- Search‑time scaling laws in battling (benefit of additional lookahead or rollouts) are not measured across formats/timers; the trade-off between compute and rating gains is unquantified.
- Memory and localization in long-context RPG play are identified as bottlenecks (VLM‑SLAM), but no dedicated sub-benchmarks exist to isolate map-building, place recognition, action-distance estimation, or objective verification under perceptual noise.
- The speedrunning environment lacks standardized ablations that isolate subskills (e.g., pure navigation tasks, dialogue/menu parsing micro-tasks, deterministic vs stochastic battle modules) to diagnose where agents fail.
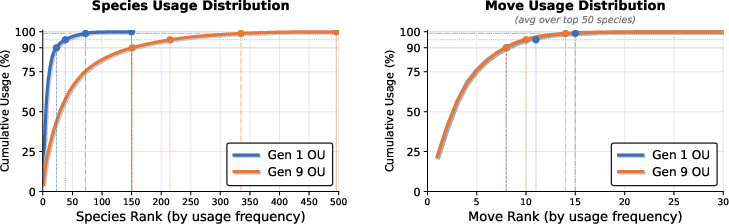
- Generalization across game versions and formats (e.g., transfer from Gen 1 OU to Gen 9 OU, or Emerald to other games) is not evaluated; cross-domain transfer benchmarks and protocols are missing.
- Leaderboard overfitting risks are unaddressed: there are no secret test pools, periodic test-set refreshes, or anti-adversarial measures to deter tailoring agents to organizer baselines and fixed opponent pools.
- Frontier API reproducibility is fragile (version drift, rate limits, context window differences); standardized “frozen” model snapshots and/or reproducible open-source surrogates are not provided for long-term comparability.
- Human comparators are limited: beyond ladder ratings and a small set of speedrun references, there’s no controlled human-vs-agent experimental design quantifying human learning/adaptation against agents or human supervision effects (e.g., coaching, preference feedback).
- Accessibility and resource equity are not enforced; training on tens of millions of trajectories and the advantage of low-latency distillations create barriers for low-compute labs; a low‑resource track or fixed‑data regime is not offered.
- Privacy/licensing implications of replay-derived datasets are not discussed; consent, TOS compliance, and any redaction policies for sensitive metadata are unclear.
- Battle evaluation uses symbolic Showdown mechanics; perception-to-action agents in a visual battle UI (to align with RPG perception demands) are not benchmarked, obscuring the cost of perception in competitive settings.
- Calibration of value estimates and action-confidence in battling is not scored; probabilistic accuracy metrics (e.g., calibration curves for win-rate predictions) are missing, hindering apples-to-apples comparison of RL vs LLM vs search.
- Training sample efficiency and compute-to-performance curves (in both tracks) are not systematically reported; standardized protocols for measuring improvement per environment step, token, or GPU-hour are absent.
- Full-game completion with open-source models remains an explicit open challenge, but the benchmark does not yet provide a scaffolding, milestones, or resource estimates for end-to-end open-source attempts.
- Safety and robustness to adversarial harness inputs (e.g., malformed observations, emulator glitches, tool failures) are not tested; failure-handling and recovery benchmarks are missing.
Practical Applications
Immediate Applications
The paper’s resources and methods can be deployed today to improve how organizations build, test, and compare decision-making agents and long-horizon systems.
- Agent performance benchmarking and QA (software, AI platforms)
- Use the live Battling leaderboard, FH-BT skill ratings, and standardized Showdown server to run A/B tests, regression checks, and release gates for agent updates.
- Apply the real-time Speedrunning evaluation to measure latency–performance tradeoffs for long-horizon agents where the world does not pause while the agent reasons.
- Potential tools/products: “FH-BT-as-a-Service” for competitive agent ranking; CI plugins that run nightly matches or route segments; dashboards tracking GXE/FH-BT vs inference cost.
- Dependencies/assumptions: Access to compute for match volumes; integration of agents with the Showdown or Emerald harness APIs.
- Harness × model evaluation for agent design (software, MLOps, academia)
- Adopt the S×T×M×F×Φ framework to disentangle model capability from scaffolding in complex agents (state, tools, memory, feedback, finetuning).
- Potential workflows: “Harness profiler” that audits agent stacks, comparable across teams/models; standardized ablation templates for research reports.
- Dependencies/assumptions: Ability to expose harness components modularly; logging standards for reproducibility.
- Offline RL experimentation with large-scale demonstrations (academia, industry R&D)
- Leverage 4M reconstructed human trajectories and 18M self-play battles to study offline RL, partial observability, and dataset curation (e.g., dynamic data weighting).
- Potential products: Starter kits with preprocessed trajectories; curriculum-learning splits; reproducible training pipelines and checkpoints.
- Dependencies/assumptions: GPU time for training; acceptance of game domain as a proxy for real-world sequential decision-making.
- Multi-agent orchestration for long-horizon tasks (software automation, enterprise RPA, education)
- Reuse the open-source orchestration system (sub-agents, A* planning, objective verification, context compaction) to build tool-using agents for UI navigation, multi-step workflows, and game-based education labs.
- Potential products: “Long-horizon agent SDK” with planners, memory, and verifiers; plug-ins for A* over GUI graphs or web DOMs; curriculum routes with milestones.
- Dependencies/assumptions: Domain-specific adapters (e.g., GUI graph extraction); careful tool permissions and sandboxing.
- Scripted Policy Distillation (SPD) to accelerate agents (software automation, operations)
- Apply the winning approach—LLM decomposes tasks into scripts, then distill into fast neural policies—to compile slow prompt-chains into fast runtime controllers for repetitive workflows (e.g., form processing, multi-step ETL, UI macros).
- Potential products: “LLM→Policy compiler” that emits executable policies plus a verification harness; distillation pipelines integrated with RL fine-tuning.
- Dependencies/assumptions: Tasks decomposable into stable sub-policies; availability of simulators or safe sandboxes for imitation/RL.
- Competitive evaluation for market-facing agents (adtech/auctions, games, security)
- Use FH-BT and tournament play to evaluate bidding or game bots against fixed pools of baselines; schedule round-robin stress tests under partial observability.
- Potential products: “Competitive agent ladder” for internal agents; anomaly detection for sudden rating drops; tournament organizers for vendor bake-offs.
- Dependencies/assumptions: Domain simulators with comparable rules; careful mapping of reward structure to business KPIs.
- Agent failure-mode diagnostics beyond standard LLM benchmarks (safety, reliability engineering)
- Employ the battling and speedrunning tracks to surface “panic,” goal oscillation, and memory-corruption failure modes that do not appear in static QA tests.
- Potential workflows: Pre-deployment stress-tests; postmortem templates tied to observed failure classes; guardrail policies (e.g., reset, mode switch) when panic patterns hit.
- Dependencies/assumptions: Engineering time to wire telemetry; acceptance of game-derived failure taxonomies as predictors of real-world brittleness.
- Game and esports operations (gaming industry)
- Use datasets and bots to test balance changes, detect degenerate strategies, and run fairness checks on metagame shifts.
- Potential products: “Metagame simulator” for balance teams; automated scrimmage systems; anti-exploit regression suites.
- Dependencies/assumptions: Legal/IP coordination; internal simulator integrations.
- Teaching and skills development (education)
- Integrate the benchmark into coursework on RL, game theory, and agent systems with plug-and-play baselines, leaderboards, and reproducible labs.
- Potential products: Course modules; capstone competitions; grading rubrics aligned to FH-BT/GXE/milestones.
- Dependencies/assumptions: Instructor familiarity with RL/LLM agents; classroom compute or cloud credits.
- Procurement and model selection due diligence (policy, enterprise IT)
- Add PokéAgent tasks to vendor evaluation to test long-horizon, adversarial, partially observed reasoning that is orthogonal to standard LLM benchmarks.
- Potential workflows: “Orthogonal capability panel” alongside MMLU/code/math; scorecards separating model vs harness; inference-latency budget checks.
- Dependencies/assumptions: Willingness to include game-based evals in RFPs; governance for handling model logs and costs.
Long-Term Applications
These opportunities require additional research, domain adaptation, or integration to meet safety, regulatory, and performance thresholds.
- Clinical decision support under uncertainty (healthcare)
- Map partial observability and adversarial reasoning to differential diagnosis, triage, and multi-visit care planning; use SPD to compile guideline-aware, fast policies for routine pathways.
- Potential products: “Care-path compilers” that distill clinician-authored protocols into verifiable policies; longitudinal memory modules for patient histories.
- Dependencies/assumptions: Regulatory approvals, robust clinical datasets, bias/safety audits, human-in-the-loop oversight.
- Hierarchical autonomy with VLM-SLAM (robotics, logistics, home/warehouse)
- Translate the VLM-SLAM challenge into embodied localization, action-distance estimation, and objective verification; reuse orchestrator + sub-agents for navigation, manipulation, and recovery behaviors.
- Potential products: Long-horizon task planners with grounded maps; perception–memory bridges; failure-aware controllers that avoid panic cascades.
- Dependencies/assumptions: Reliable perception stacks, real-world simulators/digital twins, safety validation, sim2real transfer.
- Multi-agent planning in dynamic markets (finance, energy)
- Use RL + search + self-play to train bidding/hedging/scheduling agents under partial information and adversarial counterparts; evaluate strategies with FH-BT-like ranking over fixed agent pools.
- Potential products: “Market ladder” simulators for strategy testing; policy distillation for low-latency execution; risk-constrained training with adversarial scenarios.
- Dependencies/assumptions: High-fidelity market sims, risk/compliance guardrails, robust backtesting to avoid overfitting.
- Cybersecurity red–blue tournaments (security)
- Adapt competitive evaluation to attacker–defender simulations with hidden information and evolving tactics; track capability growth with FH-BT ratings and orthogonal benchmarks.
- Potential products: Continuous attack lab with agent ladders; SPD to compile playbooks into fast detection/response policies.
- Dependencies/assumptions: Secure sandboxes, curated threat models, oversight to prevent unsafe generalization.
- Autonomous driving and traffic coordination (mobility)
- Model multi-agent, partially observed interactions (merging, negotiation) with RL + search; deploy hierarchies that separate high-level route planners from fast, distilled low-level policies.
- Potential products: Scenario ladders for behavior validation; latency-aware controllers for edge compute; failure-mode monitors to prevent panic-like error cascades.
- Dependencies/assumptions: Certified simulators, regulatory testing, explainability and safety cases.
- Grid and plant operations optimization (energy/manufacturing)
- Apply long-horizon planning and milestone frameworks to scheduling, maintenance, and contingency management with real-time latency budgets.
- Potential products: Orchestration layers coordinating sub-policies for different subsystems; verifiers for objective completion and safety constraints.
- Dependencies/assumptions: High-quality telemetry, digital twins, operator oversight, fail-safes.
- Standardized agent evaluation governance (policy, standards bodies)
- Establish benchmarks that separate harness and model effects, track inference cost, and include adversarial/partially observed tasks to complement existing suites.
- Potential products: Open standards for long-horizon agent eval; certification programs; public leaderboards for safety-relevant capabilities.
- Dependencies/assumptions: Multi-stakeholder consensus; sustained funding for “living benchmarks.”
- Edge deployment via policy distillation (IoT, on-device AI)
- Use SPD to convert heavy LLM workflows into compact, robust controllers for constrained hardware (e.g., AR assistants, inspection drones).
- Potential products: Toolchains that auto-generate, verify, and continuously improve on-device policies from scripted behavior.
- Dependencies/assumptions: Reliable verification/oracles, continual learning without drift, safe update mechanisms.
- Cross-domain benchmark kits (transport, operations, education)
- Port the living-benchmark template—datasets, leaderboards, FH-BT ranking, orchestration stack—to other simulators (e.g., rail networks, warehouses) to catalyze reproducible progress.
- Potential products: “Benchmark-in-a-box” for new domains; reusable rating servers; standardized baselines (LLM/RL/hybrids).
- Dependencies/assumptions: Domain owners providing simulators/data; IP considerations; community maintenance.
- Robustness stress-tests for generalist models (enterprise AI safety)
- Institutionalize Poké-like adversarial, long-context exams as part of pre-deployment checks to detect brittleness not seen in static QA (panic behavior, goal oscillation).
- Potential products: Safety scorecards with orthogonal benchmarks; failure-mode libraries and mitigations; red-team playbooks.
- Dependencies/assumptions: Alignment with internal risk frameworks; resources to respond to discovered weaknesses.
Glossary
- A* pathfinding: A best-first graph search algorithm that finds shortest paths using cost-to-come plus heuristic estimates. "MCP tools (A* pathfinding, button inputs, knowledge retrieval)"
- Action space: The set of all actions available to an agent at a decision point. "alternative observation spaces, action spaces, and reward functions"
- BenchPress evaluation matrix: A large curated matrix of models and benchmarks used to analyze and predict LLM performance across tasks. "Analysis against the BenchPress evaluation matrix shows"
- Bradley--Terry model: A statistical model for pairwise comparisons that estimates latent skill from match outcomes. "based on a Bradley--Terry model"
- Bootstrapped uncertainty: An uncertainty estimate obtained by resampling data (bootstrapping) and aggregating variability in the estimated metric. "with bootstrapped uncertainty"
- CLI-agent: An LLM agent architecture that operates via command-line interfaces to plan and execute actions. "common CLI-agent harnesses (Claude Code, Codex CLI, Gemini CLI)"
- Context compaction: The process of compressing or pruning accumulated reasoning/context to fit within model context limits over long tasks. "requires context compaction to manage the thousands of reasoning steps involved"
- Dynamic data weighting: Adjusting the relative importance of training samples over time to improve learning. "iterative offline RL with dynamic data weighting"
- Elo rating: A rating system for estimating relative skill from game outcomes via incremental updates. "an Elo variant incorporating uncertainty"
- Episodic MDP: A Markov Decision Process with episodes that start and terminate, often with undiscounted returns. "We formalize RPG gameplay as an episodic MDP "
- Extended Timer: An evaluation setting that relaxes per-turn time limits to allow longer test-time reasoning. "an ``Extended Timer'' variant provides nearly unlimited deliberation time"
- FH-BT rating (Full-History Bradley--Terry): A Bradley–Terry skill rating fit to an agent’s full match history, used as the primary leaderboard metric. "We refer to this metric as the Full-History Bradley--Terry (FH-BT) rating"
- Gen 1 OU: The Generation 1 “OverUsed” competitive format in Pokémon Showdown with specific rules and metagame. "Gen 1 OU and Gen 9 OU"
- Gen 9 OU: The Generation 9 “OverUsed” competitive format in Pokémon Showdown with contemporary rules and metagame. "Gen 1 OU and Gen 9 OU"
- Glicko-1: A rating system extending Elo by modeling rating uncertainty that updates with matches. "We report the standard Showdown implementations of Glicko-1"
- GXE: “Glicko X-Act Estimate,” an expected win probability metric derived from rating. "and GXE (expected win probability against a randomly sampled opponent)"
- Harness (LLM harness): The surrounding software scaffold that handles perception, tools, memory, and control around an LLM. "harness-based LLM approaches"
- Imitation learning: Learning policies by mimicking expert demonstrations rather than via environmental rewards. "distilled into neural networks via imitation learning"
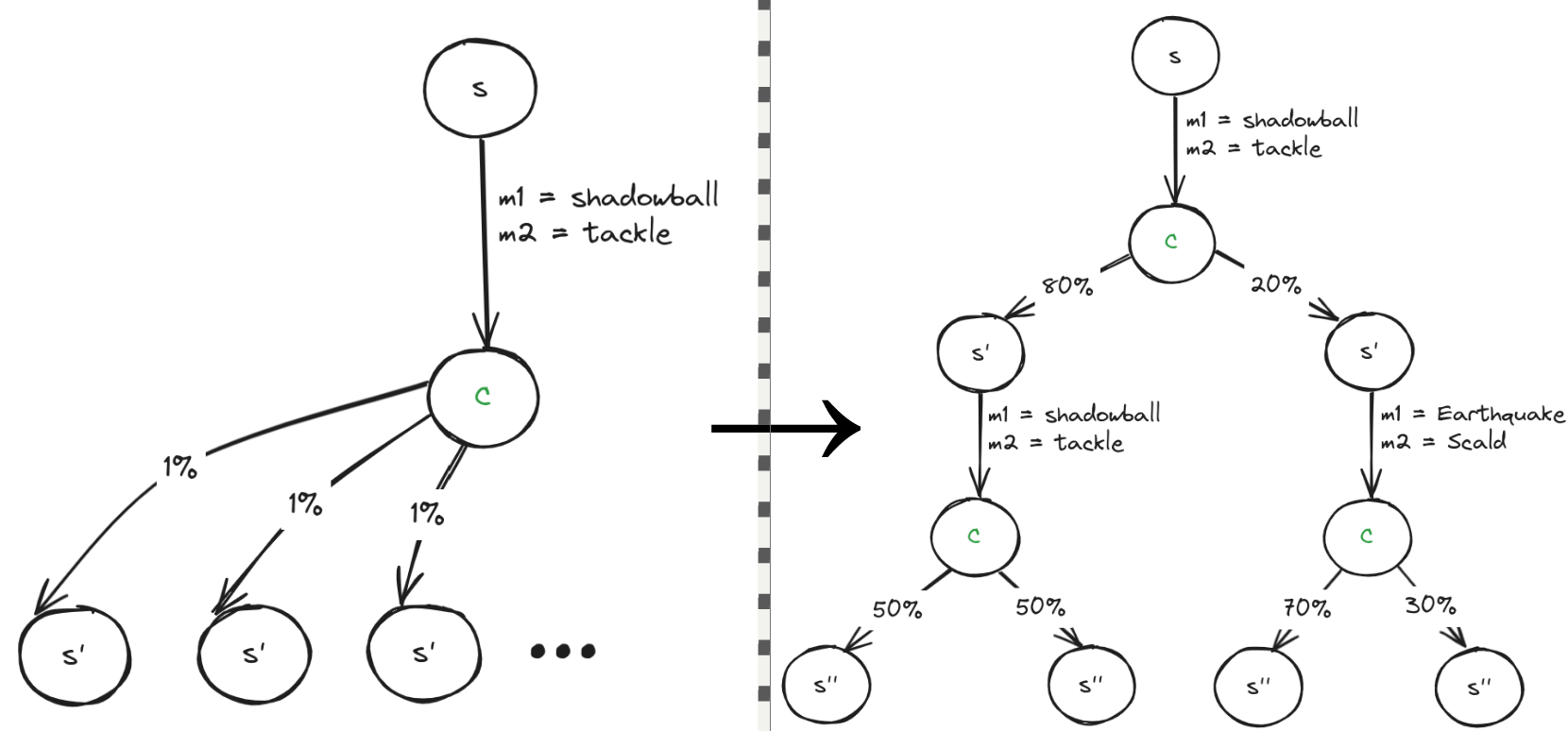
- Imperfect information: Settings where agents lack full knowledge of the game state or opponent’s hidden variables. "stochastic games with imperfect information and simultaneous action selection"
- Long-horizon planning: Planning that spans many steps with delayed credit assignment and extended context. "Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems"
- MCP tools: Tooling integrated via a Model Context Protocol interface to extend agent capabilities (e.g., planning, I/O). "MCP tools (A* pathfinding, button inputs, knowledge retrieval)"
- Metagame: The evolving ecosystem of dominant strategies and counter-strategies shaped by players and rules. "a competitive metagame that evolves continuously"
- Minimax search: An adversarial search algorithm that optimizes against a worst-case opponent. "combining minimax search with LLMs"
- Multi-agent orchestration system: Infrastructure that coordinates multiple specialized agents or modules toward a shared objective. "an open-source multi-agent orchestration system that enables modular, reproducible comparisons"
- Observation space: The set or structure of information available to the agent at decision time. "alternative observation spaces, action spaces, and reward functions"
- Offline reinforcement learning (offline RL): Learning policies from fixed logged data without further environment interaction. "iterative offline RL with dynamic data weighting"
- Orthogonality analysis: Studying (lack of) correlation between evaluations to identify independent capability axes. "and orthogonality analysis showing that Pokémon battling captures capabilities not predicted"
- Out-of-distribution evaluation: Testing a model on tasks or distributions that differ from its training data to assess generalization. "offers a distinctive form of out-of-distribution evaluation"
- Panic behavior: A failure mode where an agent compounds errors after a setback rather than recovering. "exhibit ``panic behavior'' (also observed by \citep{gemini2p5report})"
- Partial observability: Conditions where the agent cannot directly see the full state and must infer hidden information. "Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems"
- Rank-2 SVD: A two-dimensional singular value decomposition capturing most variance in a data matrix. "the rank-2 SVD that explains 91% of standard benchmark variance"
- Recurrent PPO: Proximal Policy Optimization augmented with recurrent networks to handle partial observability. "recurrent PPO with milestone-conditioned rewards"
- Reward function: A mapping that assigns scalar feedback to states/actions to guide learning. "alternative observation spaces, action spaces, and reward functions"
- Root-parallelized MCTS: Monte Carlo Tree Search where simulations from the root are parallelized to improve search throughput. "root-parallelized MCTS in imperfect-information battling"
- Scripted Policy Distillation (SPD): Generating scripted sub-policies with an LLM and distilling them into neural policies via imitation/RL. "Scripted Policy Distillation (SPD)"
- Self-play: Training by having an agent play against itself or its past versions to generate data. "competitive performance often requires the scale of self-play"
- Showdown ladder: The public ranked matchmaking ladder on Pokémon Showdown used to benchmark against humans. "Official ratings on the Showdown ladder"
- Simultaneous action selection: Both players choose actions at the same time, increasing strategic uncertainty. "simultaneous action selection"
- SLAM: Simultaneous Localization and Mapping; building a map while tracking position within it. "analogous to classical SLAM but through language-vision interfaces"
- Spearman ρ: A nonparametric rank correlation coefficient measuring monotonic association. "max Spearman ; mean "
- Stochastic game: A game with probabilistic state transitions and/or outcomes. "two-player, zero-sum, stochastic games"
- Trajectories: Sequences of states, actions, and outcomes collected from play for training or evaluation. "a dataset of 20M+ battle trajectories"
- VLM-SLAM: Applying SLAM-like grounding to vision-LLM outputs to stabilize spatial understanding. "VLM-SLAM: Speedrunning agents struggle with basic localization"
- Vision-LLM (VLM): A model that processes and reasons over visual inputs and language jointly. "raw frontier VLMs achieve effectively 0\% task completion"
- Zero-sum game: A game where one player’s gain is exactly the other’s loss. "two-player, zero-sum, stochastic games"
Collections
Sign up for free to add this paper to one or more collections.

