- The paper presents a deterministic, lossless deduplication primitive that reduces prompt bytes in retrieval-augmented generation (RAG) pipelines.
- It empirically evaluates three regimes—academic, enterprise, and multi-turn conversational—showing significant byte reduction (up to over 80%) with consistent output fidelity.
- The study validates the method across major LLM APIs using rigorous human-in-the-loop audits and cost/latency analyses to ensure practical applicability.
Byte-Exact Deduplication in Retrieval-Augmented Generation: Technical and Empirical Analysis
Introduction
This paper presents an empirical study on the role of byte-exact, chunk-level deduplication in contemporary retrieval-augmented generation (RAG) pipelines. The study examines three distinct regimes—clean academic (BeIR benchmark), constructed enterprise, and multi-turn conversational retrieval—quantifying not only reduction in prompt length, but also the impact on model output fidelity using a rigorous, multi-judge quality protocol. The findings establish that substantial prompt-size reduction can be achieved through a deterministic, lossless deduplication primitive without measurable output degradation, across top production APIs and retriever scenarios.
Methodological Framework
The core operation under investigation is deterministic, byte-exact deduplication at the chunk granularity. The deduplication operation is mathematically equivalent to constructing a set from the multiset of retrieved chunk byte-strings, and is agnostic to implementation. Empirical benchmarks span four major vendor APIs (Gemini 2.5 Flash, Claude Sonnet 4.6, Llama 3.3 70B via Groq, GPT-5.1), with output preservation evaluated by a five-judge, cross-vendor panel leveraging explicit categorical anchors. The panel discriminates between "equivalent," "minor differences," and "materially different" outputs, deploys a human-in-the-loop audit for panel-majority material-difference cases, and computes Wilson 95% confidence intervals for material difference rates.
The three redundancy regimes are:
- Clean Academic: 22.2M BeIR passages, essentially unique-by-design.
- Constructed Enterprise: Wikipedia revisions, arXiv versions, StackExchange Q&A, reflecting common enterprise RAG duplication patterns.
- Multi-Turn Conversational: 5,000 WildChat conversations under the HumanEval-Snowball protocol, capturing redundancy from dialogue turn-history accumulation.
Cost, latency, and output quality were evaluated for each regime, and all data and protocols are public-reproducible.
Redundancy Regimes and Quantitative Results
The central empirical findings reveal a wide spectrum of reduction achievable via lossless deduplication.
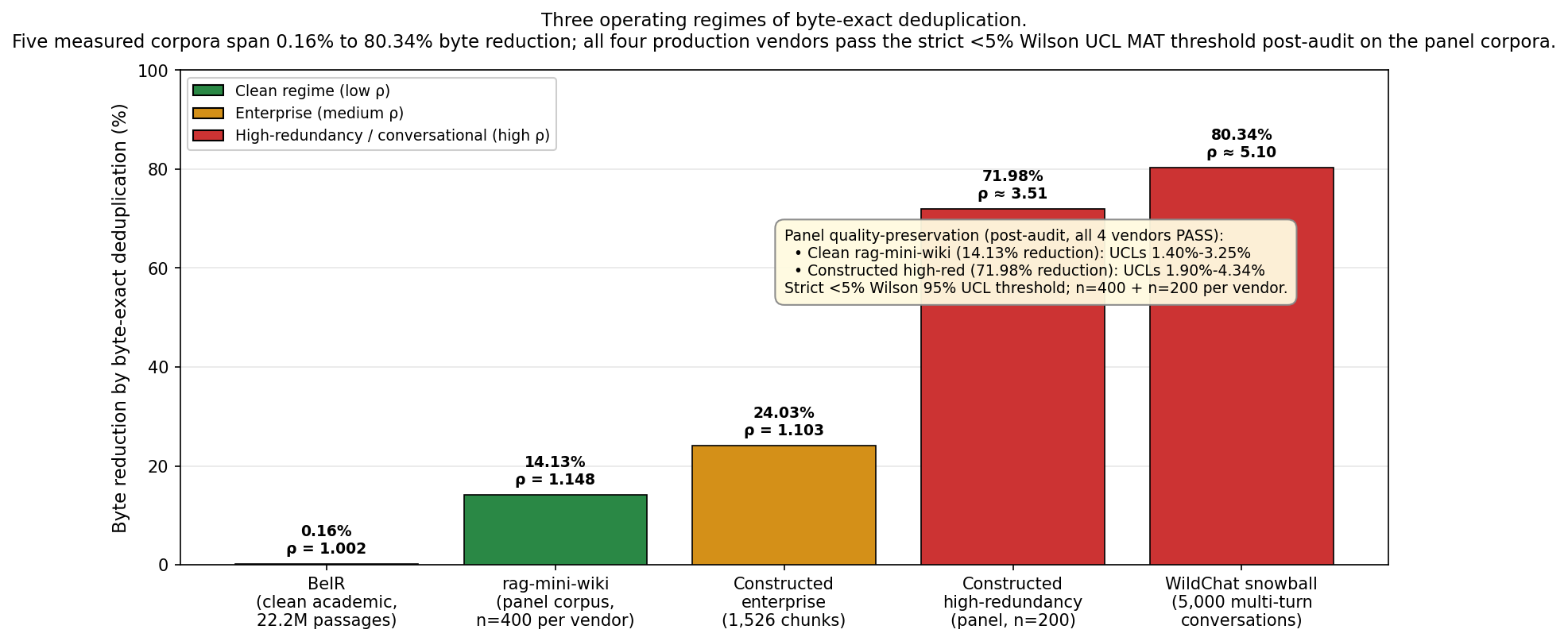
Figure 1: Byte reduction across five measured corpora, illustrating minimal redundancy in clean academic benchmarks and >80% reduction in multi-turn conversational contexts.
Clean Academic (BeIR)
In clean academic retrieval (BeIR corpus), byte-exact deduplication yields negligible byte reduction—0.16% across the full corpus and only 0.07% per query. No byte-exact duplicates were detected in the per-query sample, and all deduplication operations were math-equivalent across implementations. Thus, unique-by-design academic benchmarks are not meaningfully impacted by pre-prompt deduplication.
Constructed Enterprise
Enterprise corpora, representing realistic deployment patterns (multi-versioning, boilerplate, duplicated Q&A content), exhibited moderate but operationally significant redundancy: 24.03% aggregate byte reduction at the string level. The observed redundancy aligns with pretraining-corpus deduplication rates reported in the literature (e.g., Lee et al., ROOTS at 21.67%, RealNews at 18.6%). This regime bridges the clean academic and chat extremes.
Multi-Turn Conversational
Conversational regimes demonstrated high redundancy, with aggregate reduction at 80.34% over 5,000 WildChat conversations. This arises primarily from the naive protocol of resending cumulative conversation history, leading to O(N2) communication overhead versus O(N) under stateful, proxy-caching deployments. The magnitude of reduction was highly correlated with conversation length: reduction reached >91% for dialogues of 20–49 turns.
Output Quality and Losslessness
A central claim is that byte-exact deduplication at the chunk level is lossless with respect to output quality, under regimes relevant to production RAG.
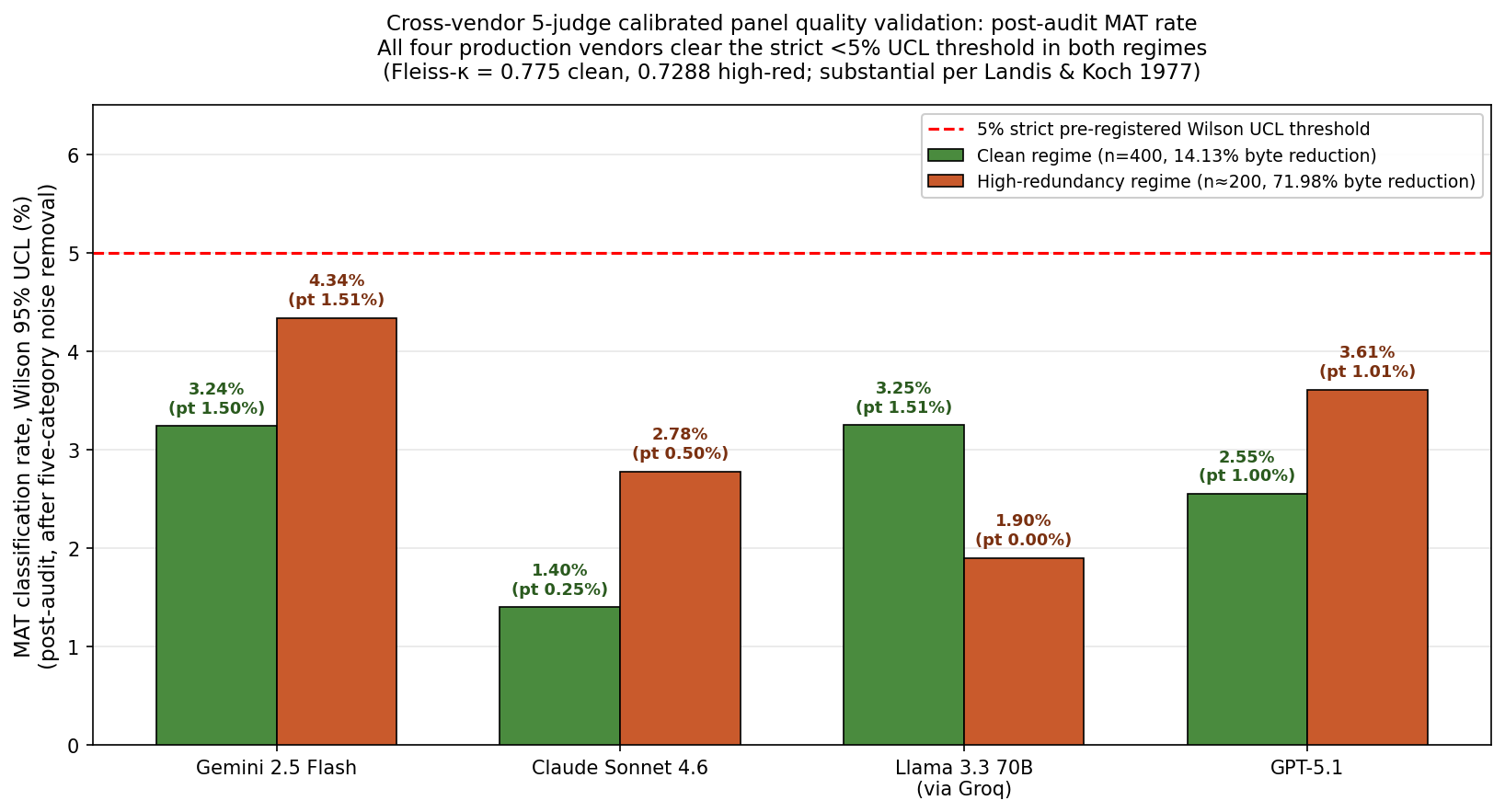
Figure 2: Cross-vendor, five-judge panel validation of output quality pre- and post-deduplication for both clean and high-redundancy regimes. All vendors clear the strict 5% Wilson UCL threshold post-audit.
In both the clean and the high-redundancy regimes, every vendor passed the 5% upper confidence limit (Wilson 95% UCL) threshold for "materially different" outputs after audit-based noise removal. For the clean regime, aggregate byte reduction was 14.13% (multiplicity ρ=1.148), with post-audit MAT rates ranging from 1.40–3.25%. Under high redundancy (multiplicity ρ=3.513, 71.98% reduction), post-audit rates were 1.90–4.34%. Inter-rater reliability (Fleiss-kappa) was substantial in both (0.775 for clean, 0.7288 for high redundancy). Critically, the lossless claim remains valid when removing over 70% of prompt bytes.
The integrity of this result was strengthened by a human-in-the-loop audit of all panel-majority material-difference pairs, applying a five-category verdict that isolates true regressions from over-flagging and defective queries. Confirmed regressions were rare, frequently attributable to model output truncation rather than deduplication error, and aggregate panel false-positive rates for "materially different" outputs were high in the noise-audit.
Implementation Independence and Computational Cost
The deduplication step is trivial computationally—it is strictly a set operation on byte-strings, and Python's built-in set() achieves reference performance of 1–4 μs for typical RAG prompt lengths. No statistical or cryptographic subtleties are required; any correct byte-exact filter yields identical outputs. While Python suffices for offline verification, production deployments may prefer compiled engines for operational reasons (interpreter startup cost, cross-platform determinism).
In large-scale streaming deployment (over 14.87M records and 53GB), deduplication throughput consistently exceeded network ingest limits (6.25 GB/s), confirming that filtering does not bottleneck even at peta-scale data rates.
Theoretical and Practical Implications
The findings have several implications for the design and optimization of large-scale RAG deployments:
- Lossless Context Reduction: Substantial token and byte reduction is achievable prior to prompt assembly, especially in enterprise and conversational deployments. This translates directly to prefill compute and per-call cost reductions in settings where prefill dominates.
- Audit-Grade Provenance: By operating as a lossless, invertible mapping, byte-exact deduplication preserves audit-trail reconstructibility, a critical property in regulated domains (e.g., finance, healthcare, legal) that lossy compression methods like LLMLingua cannot offer.
- Complementarity: The deduplication technique is orthogonal to caching and learned prompt compression. Optimization stacks can combine prompt-side deduplication with inference-side caching for even greater aggregate reduction.
- Data Quality and Reliability: The prevalence of redundancy in practical RAG deployments underscores the need for both explicit deduplication and more stringent data hygiene at vector store construction and ingestion.
Empirically, the results are robust to retrieval depth (tested at top-k=15 and 50) and task domain (Q&A and code-generation benchmarks). Directory-exact deduplication passes through paraphrased context unchanged, as expected.
Limitations
The noise-removal audits relied on author annotation. Further external validation would strengthen confidence. While the corpora spanned a range of regimes, they did not include all possible domains (e.g., medical, legal, multimodal), and the highest redundancy regime (conversational) was not subject to panel output validation (as no semantic transformation occurs on unique turn content).
Future Perspectives
This work motivates several directions:
- Adapting the deduplication primitive for multi-modal or paraphrastic-near-duplicate detection, potentially integrating fuzzy-deduplication measures post chunk-deduplication.
- Automated, inline deduplication within open-source and vendor RAG frameworks as a default pipeline component.
- Detailed measurement of cost/benefit curves when deduplication is combined with advanced caching and token-pruning compression strategies.
- Systematic evaluation on specialized, regulated-domain corpora and benchmarking frameworks (e.g., MedGemma, FinanceBench, LegalBench).
Conclusion
The study demonstrates that byte-exact deduplication is a safe, cost-effective, and implementation-agnostic primitive for reducing prompt redundancy in RAG pipelines. Substantial cost savings (up to >80% reduction) are achievable without measurable quality loss, validated across multiple industry-leading LLM APIs. The method is compatible with both operational and regulatory deployment requirements and is empirically robust to a range of data regimes and retrieval/deployment settings. Context deduplication is, therefore, a justifiable default operation for production-scale RAG, and future work should explore its role alongside emerging learned and semantic reduction mechanisms.