QuCo-RAG: Quantifying Uncertainty from the Pre-training Corpus for Dynamic Retrieval-Augmented Generation
Abstract: Dynamic Retrieval-Augmented Generation adaptively determines when to retrieve during generation to mitigate hallucinations in LLMs. However, existing methods rely on model-internal signals (e.g., logits, entropy), which are fundamentally unreliable because LLMs are typically ill-calibrated and often exhibit high confidence in erroneous outputs. We propose QuCo-RAG, which shifts from subjective confidence to objective statistics computed from pre-training data. Our method quantifies uncertainty through two stages: (1) before generation, we identify low-frequency entities indicating long-tail knowledge gaps; (2) during generation, we verify entity co-occurrence in the pre-training corpus, where zero co-occurrence often signals hallucination risk. Both stages leverage Infini-gram for millisecond-latency queries over 4 trillion tokens, triggering retrieval when uncertainty is high. Experiments on multi-hop QA benchmarks show QuCo-RAG achieves EM gains of 5--12 points over state-of-the-art baselines with OLMo-2 models, and transfers effectively to models with undisclosed pre-training data (Llama, Qwen, GPT), improving EM by up to 14 points. Domain generalization on biomedical QA further validates the robustness of our paradigm. These results establish corpus-grounded verification as a principled, practically model-agnostic paradigm for dynamic RAG. Our code is publicly available at https://github.com/ZhishanQ/QuCo-RAG.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Understanding “QuCo-RAG: Quantifying Uncertainty from the Pre-training Corpus for Dynamic Retrieval-Augmented Generation”
What is this paper about?
This paper introduces a new way to help LLMs avoid “hallucinations”—times when they confidently say something that isn’t true. The method is called QuCo-RAG. Instead of trusting the model’s own confidence, it checks the model’s training data (the huge collection of text it learned from) for signs that the model might be unsure or making something up. When it detects risk, it decides to look up information and use it to fix or support the answer.
What questions did the researchers ask?
The researchers focused on two simple questions:
- When should the model stop and look things up to avoid making mistakes?
- Can we make that decision using facts from the model’s training data, rather than the model’s own “confidence” signals?
In everyday terms: Can we tell when the model needs help by checking whether the facts it mentions actually exist in its “textbook” (the big training corpus), and then bring in the right sources at the right time?
How did they do it?
Think of an LLM like a student writing an answer. Sometimes the student should check a reliable source mid-way. QuCo-RAG decides when to check based on two simple ideas drawn from the model’s training data:
- Before the model starts answering: Check if the question mentions rare entities
- Entities are names of people, places, organizations, etc.
- If the names in the question show up rarely in the model’s training data, that’s a warning sign: the model probably didn’t see those enough times to remember them well.
- If things look rare, QuCo-RAG triggers an early retrieval (like opening a trusted encyclopedia) and adds helpful information before the model starts writing.
- While the model is answering: Check if the entities it connects ever appear together
- If the model writes a claim like “Person A worked at Company B,” QuCo-RAG checks whether “Person A” and “Company B” ever occur together in the training data.
- If they never co-occur (appear together even once), that’s a strong hint the model might be hallucinating.
- In that case, QuCo-RAG triggers retrieval again and regenerates the sentence using the found evidence.
To do these checks quickly, QuCo-RAG uses a tool called Infini-gram. You can think of Infini-gram as a very fast “word counter” for massive text collections. It can instantly tell you things like “how often does this name appear?” or “do these two names ever show up together?” across trillions of tokens.
A few words explained in everyday terms:
- Pre-training corpus: The huge library of text an LLM learned from, like a student’s full set of textbooks and notes.
- Co-occurrence: Two names appearing together in the same passage. If two things never appear together, the model’s claim connecting them is suspicious.
- Entropy/logits: Internal math signals about the model’s confidence. The paper argues these are unreliable for deciding when to retrieve.
- Retrieval-Augmented Generation (RAG): Having the model look up supporting documents while answering, so it can use evidence instead of guessing.
What did they find?
In tests on tough, multi-step question-answering tasks, QuCo-RAG beat other methods that rely on the model’s internal confidence. Key results include:
- Consistent accuracy gains: QuCo-RAG improved Exact Match (EM) scores by about 5 to 12 points compared to strong baselines when used with OLMo-2 models (sizes 7B, 13B, and 32B).
- Works across different model families: Even for models whose training data isn’t public (Llama, Qwen, GPT), using OLMo-2’s corpus as a proxy still boosted EM by up to 14 points.
- Robust in special domains: On biomedical questions (PubMedQA), QuCo-RAG achieved the best accuracy, while methods based on internal signals either retrieved too much (wasting time) or too little (missing evidence).
- Efficient use of retrieval: QuCo-RAG triggered retrieval fewer times than most dynamic methods, yet got better accuracy. In other words, it retrieved at the right moments, not constantly.
Why this matters: The model’s own “confidence” isn’t a reliable guide—LLMs often sound sure even when they’re wrong. QuCo-RAG uses objective evidence from the training corpus to catch risky claims and fix them with retrieval.
Why does it matter?
- More trustworthy answers: By checking whether the model’s claims are supported by its training data, QuCo-RAG reduces hallucinations. This is crucial for tasks like research, medical help, or education.
- Model-agnostic and practical: It works well even when a model’s exact training data is unknown, because many modern LLMs learn from overlapping web-scale sources. That makes it broadly usable.
- Better decisions about when to look things up: Instead of guessing when to retrieve based on shaky internal signals, QuCo-RAG uses clear, corpus-based rules—rare entities and zero co-occurrence—so retrieval happens only when it’s likely needed.
- Data-centric insights: These checks can highlight the model’s knowledge gaps. Developers could use that signal to add more examples about rare topics during training, or to filter and improve synthetic data.
A quick note on limitations:
- Name variations: If two related entities appear under different names (like “NYC” vs. “New York City”), a simple co-occurrence check might miss them. The authors say it’s safer to “retrieve when in doubt,” and future work can add better name-linking.
- Time lag: If the corpus is from last year, it won’t help with brand-new facts. Regular updates can help here.
In short, QuCo-RAG shows that grounding decisions in what’s actually present in the training data is a reliable, efficient way to trigger retrieval, improving accuracy and making LLMs more trustworthy without needing to trust the model’s own confidence.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased as concrete, actionable gaps for future research:
- Quantify positive evidence: Measure P(correct | cooc > 0) and establish when non-zero co-occurrence is actually predictive of correctness (vs spurious co-occurrence in unrelated contexts).
- Windowing sensitivity: Systematically ablate co-occurrence window size (sentence/paragraph/document), and constrain windows to document boundaries to reduce accidental co-occurrence inflation.
- Normalization of co-occurrence: Explore PMI/PPMI, significance testing, and normalization by entity base frequencies to distinguish genuine associations from popularity effects.
- Relation-aware verification: Move beyond head–tail co-occurrence to verify relations (e.g., via pattern mining, Open IE, or weakly supervised relation extractors) to catch wrong relations between frequent entity pairs.
- Triplet extraction reliability: Report precision/recall of the 0.5B triplet extractor, characterize error propagation into retrieval triggers, and test extractor confidence-aware triggering.
- Entity canonicalization and aliasing: Integrate entity linking/canonicalization (synonyms, abbreviations, spelling variants) and approximate matching to reduce false “zero co-occurrence” detections.
- Entity disambiguation: Add typing and disambiguation (e.g., “Apple” the company vs fruit; “Cook” as surname vs verb) to avoid spurious co-occurrence or missed matches.
- Tokenization and segmentation effects: Evaluate sensitivity to multiword entity segmentation, subword tokenization, casing, punctuation, and language-specific tokenization.
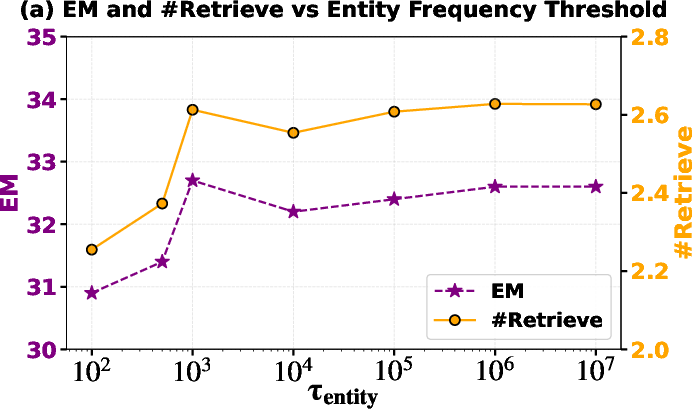
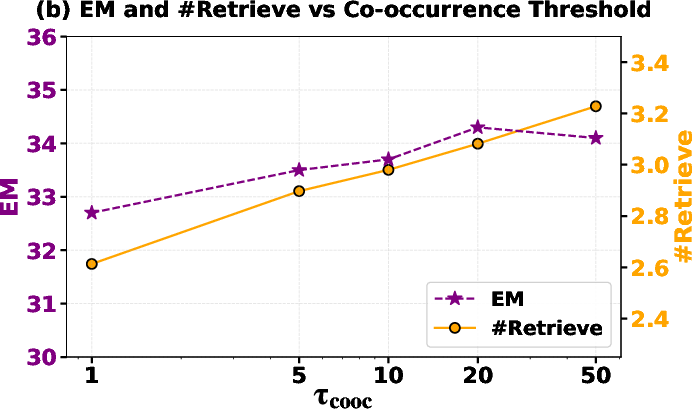
- Threshold design and adaptation: Go beyond fixed τ_cooc = 1 and τ_entity; conduct sensitivity analyses across tasks and domains, and develop adaptive/learned thresholds tied to retrieval budgets or risk targets.
- Aggregation for pre-check: Compare average vs min/percentile-based entity-frequency aggregators to avoid masking a single rare but critical entity in the question.
- Query formulation: Evaluate and learn query construction strategies beyond q = h ⊕ r (e.g., incorporate broader context/history, multi-hop decomposition, iterative reformulation, and retrieval-augmented re-ranking).
- Regeneration policy: Specify and study rollback scope (token/sentence/paragraph), loop termination, and coherence preservation when repeated retrieval/regeneration is triggered.
- Hallucination detection metrics: Report trigger precision/recall/AUROC against ground-truth hallucination labels, not just downstream EM/F1, to calibrate the detector itself.
- Robustness to adversarial inputs: Test resistance to misspellings, rare aliases, obfuscation, and adversarial paraphrases designed to evade lexical matching and entity extraction.
- Domain and task scope: Evaluate beyond short-form QA (e.g., long-form generation, summarization, coding, tool use) where claims span multiple sentences, coreference, and dispersed evidence.
- Discourse-level verification: Extend detection to cross-sentence/coreferent claims and multi-sentence propositions that sentence-level triplets may miss.
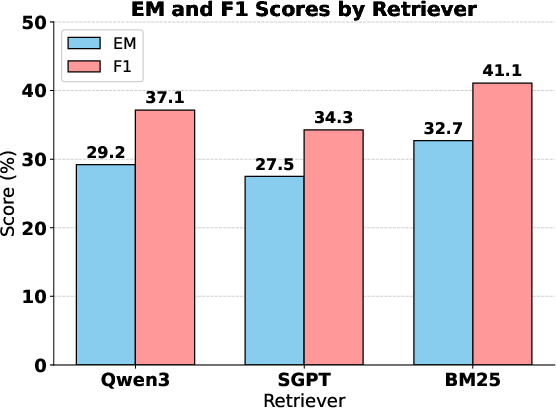
- Retriever and corpus choice: Systematically assess dense/hybrid retrieval, larger or domain-specific corpora, top-k settings, and re-ranking effects on QuCo-RAG’s gains.
- Proxy-corpus validity: Quantify overlap between proxy and target model pre-training corpora, derive criteria to assess when a proxy is reliable, and determine minimal proxy scale for transfer to hold.
- Misinformation and bias: Develop mechanisms to downweight low-credibility sources, time-stamp and reconcile conflicting claims, and mitigate the risk of “validating” repeated falsehoods in pre-training data.
- Temporal dynamics: Implement and evaluate time-aware statistics (e.g., recency-weighted co-occurrence, rolling indexes) to handle evolving knowledge and stale facts.
- Fairness impacts: Analyze whether frequency-based pre-checks disproportionately burden long-tail/minority entities and propose mitigations (e.g., adaptive thresholds, cost-aware triggering).
- Privacy and safety: Assess risks of exposing or reinforcing sensitive/PII content via corpus-grounded verification and retrieval; explore redaction and differential privacy safeguards.
- Efficiency and deployability: Report the memory/disk/compute footprint of trillion-token indices (local vs API), latency under load, failure modes (API outages), and caching strategies for production viability.
- Signal fusion: Explore complementary fusion of corpus-grounded signals with calibrated internal signals or external fact-checkers to improve recall without excessive retrieval.
- Theoretical grounding: Formalize connections between corpus statistics and hallucination probability; derive bounds for detection error rates and conditions under which proxy-corpus transfer is guaranteed.
Practical Applications
Immediate Applications
Based on the paper’s methods and results, the following applications can be deployed now using corpus-grounded uncertainty quantification (entity frequency and co-occurrence) with tools like Infini-gram and standard retrievers (BM25/dense).
- Corpus-grounded RAG controller for existing LLM stacks
- Sector: software, enterprise AI
- Description: Plug QuCo-RAG’s two-stage uncertainty detection into LangChain/LlamaIndex or custom pipelines to trigger retrieval only when entities are rare or when generated claims lack corpus evidence. Demonstrated EM gains and reduced token/LLM-call budgets.
- Potential tools/workflows: “Uncertainty-to-retrieval” middleware; Infini-gram index as a microservice; lightweight triplet extractor model; BM25 or dense retriever; observability dashboards of retrieval triggers.
- Assumptions/Dependencies: Access to a large pre-training or proxy corpus (e.g., OLMo/Dolma/CC/Wikipedia) indexed by Infini-gram; basic entity extraction; threshold tuning; network or local storage for index.
- Black-box model guardrails (GPT/Qwen/Llama) via proxy corpus
- Sector: software, platform operations
- Description: Wrap proprietary LLM calls with QuCo-RAG’s detection using statistics from a transparent, overlapping proxy corpus (as validated in the paper), improving correctness without model fine-tuning.
- Potential tools/workflows: Proxy-corpus verification API; SDK for GPT/Llama/Qwen endpoints; audit logs of zero-co-occurrence triggers.
- Assumptions/Dependencies: Significant overlap between proxy and model training corpora; API integration; careful rate limiting and latency management.
- Enterprise knowledge assistants with selective retrieval
- Sector: enterprise productivity, knowledge management
- Description: Internal document assistants that only retrieve when question entities are infrequent (long-tail) or claim entities never co-occur, reducing hallucinations and cost for multi-hop tasks (e.g., HR policy queries, cross-department references).
- Potential tools/workflows: Internal corpus indexing; policy-aware retrieval orchestrator; human-in-the-loop escalation for zero-evidence cases.
- Assumptions/Dependencies: Indexing internal corpora; alias/canonicalization for entity names; governance on data security.
- Biomedical literature QA and claim verification
- Sector: healthcare, life sciences R&D
- Description: PubMed/clinical guideline assistants that verify claims (drug–disease, author–trial, gene–condition) via co-occurrence and trigger retrieval for citations; validated by gains on PubMedQA with lower token cost than internal-signal methods.
- Potential tools/workflows: PubMed and textbook indices; entity linking for biomedical aliases; citation-aware query formulation using head entity + relation.
- Assumptions/Dependencies: Coverage of biomedical corpora; time-stamped indexes to mitigate recency gaps; clinician oversight for safety-critical use.
- Compliance and research assistants for regulated domains
- Sector: finance, legal, public sector
- Description: Assistants that flag and retrieve evidence when making relationship claims (e.g., issuer–subsidiary, director–company, statute–case) with zero co-occurrence triggers for high-risk statements.
- Potential tools/workflows: SEC filings, case law, regulatory bulletins indexed; retrieval summaries annotated with source provenance; escalation workflow.
- Assumptions/Dependencies: High-quality regulated corpora; strict privacy controls; alias resolution (e.g., legal citations, corporate renamings).
- Content generation guardrails (marketing, editorial, education)
- Sector: media, education
- Description: Writers’ assistants that detect unsupported entity pairs during drafting and fetch sources before publishing; tutors that verify facts against textbooks/course materials, reducing hallucinations in study help.
- Potential tools/workflows: CMS plugin that runs co-occurrence checks; textbook indexes for class materials; “selective answering” mode that declines when there is no corpus evidence.
- Assumptions/Dependencies: Reliable content corpora; canonicalization for aliases (author pen names, institution acronyms); editorial review.
- Synthetic data filtering and training-data curation
- Sector: ML engineering, academia
- Description: Use corpus statistics to filter synthetic training examples (exclude unsupported claims) and prioritize data collection for low-frequency entities, improving downstream model reliability.
- Potential tools/workflows: Batch Infini-gram jobs; “long-tail coverage” dashboard; pipeline hooks that reject zero-evidence samples.
- Assumptions/Dependencies: Scalable indexing and batch querying; agreed thresholds for “low frequency”; domain-relevant corpora.
- LLM observability for uncertainty and retrieval cost control
- Sector: MLOps
- Description: Monitoring panels that track trigger rates by entity frequency bins, co-occurrence failures, and per-question retrieval counts/tokens, enabling budget-aware configuration of dynamic RAG.
- Potential tools/workflows: Metrics collection and visualization; A/B testing of thresholds; alerting on unusual over/under-retrieval patterns.
- Assumptions/Dependencies: Logging integration; stable thresholds; reproducible query windows (e.g., passage-level).
Long-Term Applications
These applications require further research, scaling, standardization, or infrastructure development (e.g., better canonicalization, multilingual/temporal corpora, policy adoption).
- Multilingual corpus-grounded verification
- Sector: global software, education, public sector
- Description: Extend QuCo-RAG to cross-lingual entity resolution and co-occurrence across languages, enabling evidence-aware assistants worldwide.
- Potential tools/workflows: Multilingual Infini-gram indexes; cross-lingual entity linking; language-aware relation normalization.
- Assumptions/Dependencies: High-quality multilingual corpora; robust alias/canonicalization across scripts; latency budgets.
- Time-aware (temporal) verification and updates
- Sector: news, finance, healthcare
- Description: Incorporate time-stamped corpora to reflect evolving facts (new CEOs, mergers, clinical updates), adjusting co-occurrence checks with temporal windows.
- Potential tools/workflows: Periodic index refresh; time-filtered co-occurrence queries; “recency risk” flags that enforce retrieval.
- Assumptions/Dependencies: Ongoing corpus maintenance; versioned provenance; policies for stale knowledge.
- Event, relation, and numerical claim verification beyond entity pairs
- Sector: software, research, media
- Description: Move from entity co-occurrence to structured relation/event/numeric verification (e.g., “revenue grew 12%,” “trial enrolled 400 patients”) via canonical relation extraction and grounding.
- Potential tools/workflows: Relation canonicalization; numerical fact bases; schema-aware retrieval; hybrid symbolic–neural verification.
- Assumptions/Dependencies: Robust relation extraction (beyond lexical variability); domain schemas; curated numerical datasets.
- Safety-critical agentic systems with pre-act self-verification
- Sector: robotics, aviation, energy, clinical decision support
- Description: Agents check corpus evidence before executing actions or recommendations; decline or escalate when zero evidence is detected for key action preconditions.
- Potential tools/workflows: “Verification-before-action” policy engine; action gating with evidence requirements; simulation fallback workflows.
- Assumptions/Dependencies: Real-time indexing performance; safety certifications; human oversight; comprehensive domain corpora.
- Standards and audits for trustworthy generative AI
- Sector: policy, compliance, procurement
- Description: Regulatory and industry standards that mandate corpus-grounded uncertainty signals (e.g., zero co-occurrence checks) for high-risk use cases; auditing protocols and reporting.
- Potential tools/workflows: Evidence traceability APIs (OLMoTrace-style); standardized uncertainty reports; third-party audit services.
- Assumptions/Dependencies: Consensus on verification requirements; access to vetted corpora; legal/privacy frameworks.
- Data-centric model improvement loops (model editing, targeted pretraining)
- Sector: ML engineering, academia
- Description: Use frequency/co-occurrence gaps to guide continued pretraining, model editing, or targeted data acquisition for long-tail entities and relations.
- Potential tools/workflows: “Gap-to-data” recommendation system; automatic curriculum generation; post-training injection pipelines.
- Assumptions/Dependencies: Editable training workflows; data licensing; measurement of downstream reliability gains.
- Publisher-grade fact-checking pipelines and provenance tracking
- Sector: media, scientific publishing
- Description: Build end-to-end editorial workflows combining corpus-grounded verification, retrieval, and provenance linking, reducing risk of published hallucinations.
- Potential tools/workflows: Submission-time verification; source attestation; reviewer dashboards; archiving of evidence trails.
- Assumptions/Dependencies: Interoperable provenance standards; domain corpora completeness; organizational adoption.
- Enterprise data governance and privacy-preserving indexing
- Sector: enterprise IT, cybersecurity
- Description: Secure, privacy-aware indexing of internal corpora to enable QuCo-RAG while complying with data policies; federated verification across data silos.
- Potential tools/workflows: On-prem Infini-gram mini/FM-index; differential privacy; federated query orchestration.
- Assumptions/Dependencies: IT investment; privacy controls; legal approvals; performance tuning for large-scale corpora.
Glossary
- Agentic web search: A capability where an LLM autonomously invokes web search tools during inference to gather information. "Conversely, GPT models with agentic web search perform substantially worse than even the no-retrieval baseline, likely due to noisy web results not optimized for complex retrieval demands."
- BM25: A classic probabilistic ranking function used in information retrieval to score and retrieve relevant documents. "For retrieval, we employ BM25~\cite{robertson2009probabilistic} over the Wikipedia dump from~\citet{karpukhin-etal-2020-dense} as our external corpus , retrieving top-3 documents per query."
- Co-occurrence: The frequency with which two entities appear together within a defined corpus window, used as evidential support for claims. "we verify entity co-occurrence in the pre-training corpus, where zero co-occurrence often signals hallucination risk."
- Corpus-grounded verification: Validating generated content by checking statistics or evidence directly from the pre-training corpus instead of relying on model confidence. "These results establish corpus-grounded verification as a principled, practically model-agnostic paradigm for dynamic RAG\footnote{Our code is publicly available at \url{https://github.com/ZhishanQ/QuCo-RAG}.}."
- Dense retrievers: Neural retrieval models that use dense vector embeddings to find relevant documents rather than sparse term-based matching. "We also verify robustness with dense retrievers in Appendix~\ref{app:retriever_robustness}."
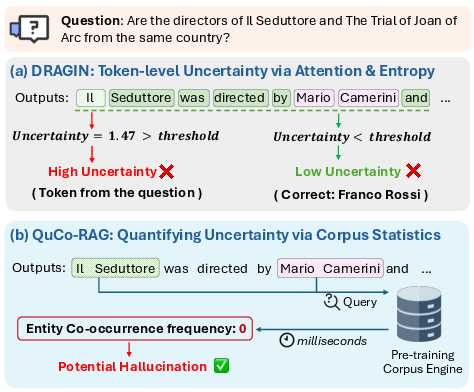
- Entropy: A measure of uncertainty in model predictions; higher entropy indicates less confident outputs. "Current dynamic RAG methods predominantly rely on quantifying uncertainty through model-internal signals such as token probability~\cite{jiang-etal-2023-active} or entropy~\cite{su-etal-2024-dragin,li2025modeling}."
- Exact lexical matching: Matching text based exactly on surface forms without normalization (e.g., aliases), used here for entity verification. "Our co-occurrence verification relies on exact lexical matching of entity surface forms."
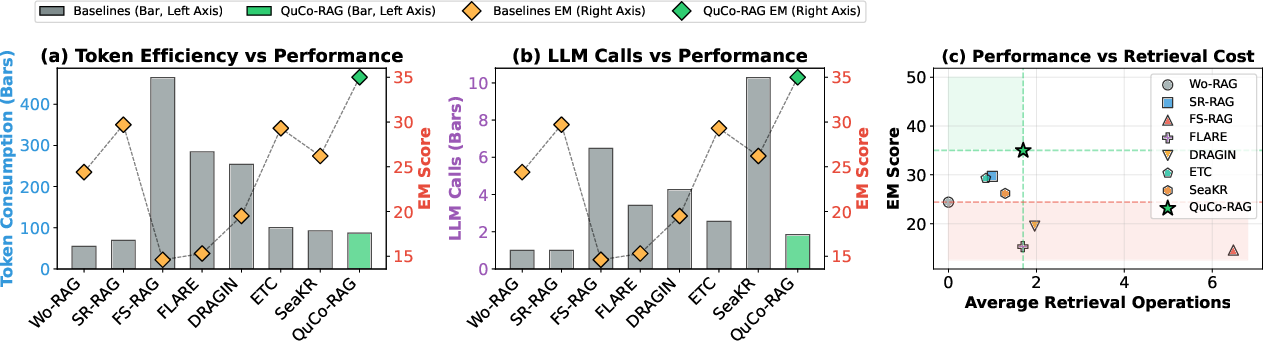
- Exact Match (EM): An evaluation metric for QA that checks whether the predicted answer string matches the ground-truth exactly. "Results show QuCo-RAG achieves 5--12 point improvements on Exact Match (EM) over state-of-the-art baselines across all model scales, while maintaining competitive efficiency."
- Feed-Forward Network (FFN) states: Internal activations of the feed-forward layers in a transformer, used as signals for uncertainty estimation. "SeaKR~\cite{yao2025seakr} extracts self-aware uncertainty from LLMs' internal FFN states."
- FM-index: A compressed full-text index enabling efficient substring queries, built upon the Burrows–Wheeler transform. "Infini-gram mini~\cite{xu-etal-2025-infini} reduces index size to 44\% of the corpus via FM-index~\cite{ferragina2000opportunistic}."
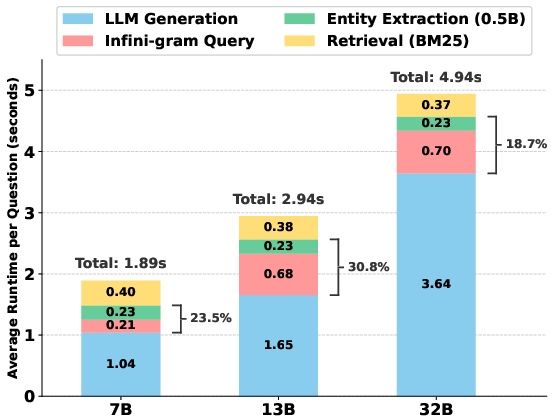
- HBM3e: A generation of high-bandwidth memory used in GPUs, offering large capacity and bandwidth for AI workloads. "All experiments are conducted on NVIDIA H200 GPUs (141GB HBM3e)."
- Ill-calibrated: Describes models whose confidence scores do not align with actual accuracy, leading to unreliable uncertainty signals. "LLMs are typically ill-calibrated and often exhibit high confidence in erroneous outputs."
- Infini-gram: A large-scale n-gram indexing and querying system enabling millisecond-latency corpus statistics over trillions of tokens. "Both stages leverage Infini-gram for millisecond-latency queries over 4 trillion tokens, triggering retrieval when uncertainty is high."
- Knowledge triplets: Structured facts represented as (head entity, relation, tail entity) extracted from text for verification. "we extract knowledge triplets from each generated sentence and verify entity co-occurrence; zero co-occurrence triggers retrieval and regeneration."
- LLM-as-judge: An evaluation paradigm where an LLM assesses the correctness or quality of model outputs. "Prior work~\cite{li2025modeling} has shown that EM/F1 conclusions align with LLM-as-judge~\cite{li2025generation} evaluations on these datasets."
- Long-tail knowledge: Rare or infrequently seen facts/entities in the training data that models are less likely to memorize reliably. "we identify low-frequency entities indicating long-tail knowledge gaps;"
- Miscalibration: The misalignment between a model’s predicted confidence and actual accuracy. "This miscalibration leads to ``confident hallucinations,'' where models produce incorrect content with high confidence~\cite{tian-etal-2023-just}."
- Multi-hop QA: Question answering tasks requiring reasoning over multiple pieces of evidence across documents or passages. "Experiments on multi-hop QA benchmarks show QuCo-RAG achieves EM gains of 5--12 points over state-of-the-art baselines with OLMo-2 models, and transfers effectively to models with undisclosed pre-training data (Llama, Qwen, GPT), improving EM by up to 14 points."
- OLMoTrace: A tracing tool that maps LLM outputs back to their occurrences in the training corpus for provenance. "OLMoTrace~\cite{liu2025olmotrace} enables real-time tracing of LLM output back to verbatim matches in training documents."
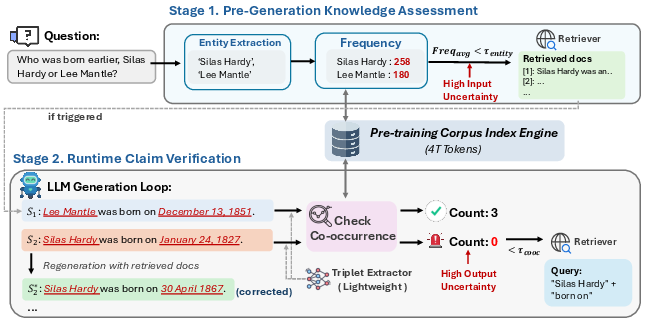
- Pre-Generation Knowledge Assessment: A stage that checks entity frequencies before generation to decide whether early retrieval is needed. "Pre-Generation Knowledge Assessment: We query entity frequencies in the pre-training corpus, triggering retrieval when entities are low-frequency (long-tail knowledge risks)."
- Pre-training corpus: The large text dataset used to train an LLM, whose statistics shape the model’s knowledge. "Our key insight is that an LLM's factual knowledge is fundamentally shaped by its pre-training corpus~\cite{balepur2025reverse}:"
- Retrieval-Augmented Generation (RAG): A paradigm where generation is grounded by retrieving external evidence to reduce hallucinations. "Retrieval-Augmented Generation (RAG)~\cite{lewis2020retrieval,gao2023retrieval} mitigates LLM hallucinations by grounding generation in external evidence."
- Semantic-Oriented Query: A retrieval query constructed from the semantic components (e.g., head entity and relation) of a claim. "When retrieval is triggered (), we construct a Semantic-Oriented Query using the head entity and relation () to retrieve supporting documents and regenerate the sentence."
- SFT (Supervised Fine-Tuning): Post-training where models are tuned on labeled data to improve task performance, which can affect calibration. "Furthermore, post-training techniques such as SFT~\cite{dong2024abilities} and Reinforcement Learning~\cite{ouyang2022training,guo2025deepseek} often exacerbate this by encouraging decisive answers."
- Suffix arrays: Data structures for efficient substring and n-gram queries over large text corpora. "Infini-gram~\cite{liu2024infinigram} provides millisecond-latency -gram counting via suffix arrays, while Infini-gram mini~\cite{xu-etal-2025-infini} reduces index size to 44\% of the corpus via FM-index~\cite{ferragina2000opportunistic}."
- Token probability: The model-assigned likelihood of the next token, often used as an internal uncertainty signal. "Current dynamic RAG methods predominantly rely on quantifying uncertainty through model-internal signals such as token probability~\cite{jiang-etal-2023-active} or entropy~\cite{su-etal-2024-dragin,li2025modeling}."
- Token-level F1: An evaluation metric comparing overlap between predicted and gold tokens, used for short-form QA answers. "and report Exact Match (EM) and token-level F1 score as evaluation metrics, which are well-suited for these benchmarks as answers are short-form entities that can be reliably extracted and matched."
- Zero co-occurrence: A condition where two entities never appear together in the pre-training corpus, signaling high hallucination risk. "we verify entity co-occurrence in the pre-training corpus, where zero co-occurrence often signals hallucination risk."
Collections
Sign up for free to add this paper to one or more collections.