- The paper introduces the CHOP framework that uses LLM-driven context-preserving chunking to reduce semantic drift in multi-document retrieval.
- It employs a CNM-Extractor and a continuity decision module to generate structured metadata, improving precision and ranking in evidence retrieval.
- Empirical results demonstrate significant performance gains over traditional chunking methods, with higher hit rates and enhanced generation metrics.
Chunkwise Context-Preserving Retrieval: The CHOP Framework for Multi-Document RAG
Introduction
Retrieval-Augmented Generation (RAG) architectures are central for knowledge-intensive NLP tasks, particularly in domains with frequent information overlap, high redundancy, and nuanced local references. Classical RAG systems commonly rely on uniform or cosine-based chunking strategies that disregard document-level discourse, exacerbating semantic drift and retrieval ambiguity, especially under multi-document settings. The CHOP framework—Chunkwise Context-Preserving Framework for RAG—targets this gap by introducing a context-aware segmentation and representation scheme. CHOP leverages LLMs for both signature extraction and topical continuity assessment, enabling robust evidence retrieval across ambiguous or highly repetitive technical corpora (2604.15802).
Theoretical Motivation and System Architecture
Conventional RAG chunking protocols, such as naive fixed-length splits or cosine similarity-based boundaries, systematically disrupt local reference chains, context dependencies, and coreference, leading to high false positives in retrieval and degraded factuality in downstream generation. CHOP postulates that injecting structured, contextually stable metadata into chunk representations can regularize the embedding space and enhance retriever discrimination—even when semantic overlap is high.
The CHOP pipeline centers on two principal modules: the Category–Noun–Model Extractor (CNM-Extractor) and the Continuity Decision module. The CNM-Extractor generates per-chunk triplet signatures (Category, Nouns, Model), succinctly encoding semantic anchors amenable to downstream retrieval. The Continuity Decision module, based on LLM classification, determines if consecutive chunks should share semantic context (i.e., share CNMs) or trigger extraction of a new contextual anchor. Chunks are then prefixed with their corresponding CNMs before embedding and database indexing.
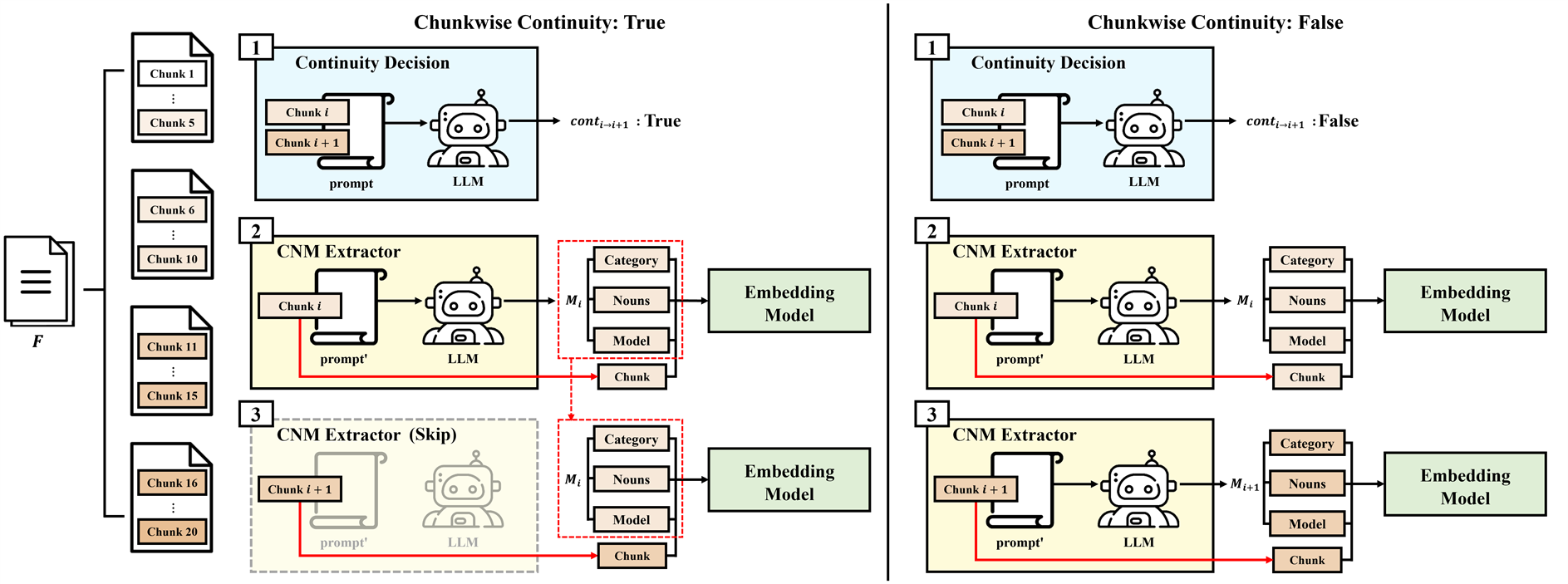
Figure 1: Overview of the CHOP architecture, depicting the flow for context-preserving chunking and prefix injection based on continuity signals and per-chunk CNM extraction.
Detailed Methodology
For an input file divided into sequence {C1,...,Cn}, each chunk is processed by an LLM-driven CNM-Extractor. This module outputs a structured signature {Categoryi,Nounsi,Modeli} per chunk. Notably, the signature mandates concise (max 1–2) noun selection reflecting the most relevant domain and specificity, with fallback to null for ambiguous contexts. The output is strictly formatted as JSON, ensuring stable data anchors.
Continuity Decision Module
Semantic continuity is assessed via another LLM prompt that takes chunk pairs (Ci,Ci+1) and returns a Boolean: TRUE denotes context preservation (inherit CNM), FALSE triggers a new CNM extraction. The classifier employs tightly constrained decision rules to minimize spurious topic splits—continuity is preserved except where explicit evidence supports a product, model, or document boundary transition. This mechanism supports robust propagation of local discourse, suppressing semantic drift from superficial section changes.
For each chunk Ci, the final retrieval representation xi is the concatenation of the prefix PFX(Mi) with the chunk text, which is subsequently encoded (OpenAI’s text-embedding-3-large, 3,072-D) for vector DB storage.
Experimental Evaluation
Experiments employ the MRAMG-Bench dataset, a complex multi-manual corpus constructed to stress-test RAG pipelines in reference-dense, high-overlap settings. The evaluation explicitly reconstructs natural manual topologies, weakening boundary cues and increasing the ambiguity inherent in retrieval.
CHOP achieves a Top-1 Hit Rate of 0.9077, outperforming Naive-500T (0.8128) and Cosine-Chunking (0.7077), with gains persisting across all values of K for Hit Rate, MRR, and NDCG. Importantly, CHOP not only increases the inclusion of relevant evidence among top results; it also improves result ranking, with notable improvements such as NDCG@10 = 0.9291 (+0.0753 over Naive-500T). These findings substantiate the hypothesis that context-aware prefix normalization and continuity preservation reduce cross-document confusion and enhance evidence granularity.
In downstream QA generation, CHOP contributes steady gains across F1, ROUGE-L, and BERTScore, particularly at higher K. For example, F1 reaches 0.3814 at Top-5 (vs. 0.3792 for Naive-500T), with parallel improvements in semantic metrics. Although absolute generation metric increases are modest, they are consistent, indicating a reduction in irrelevant retrievals and error propagation—critical for evidence-grounded LLM applications.
Implications and Future Directions
CHOP’s design addresses several key deficiencies in extant RAG methods: lack of context regularization, omission of discourse-level cues, and retrieval conflation across near-duplicate or highly overlapping segments. By leveraging LLMs for both chunk annotation and context-flow classification, CHOP strengthens semantic alignment and optimizes evidence granularity for both retrieval and generation.
Practically, CHOP’s prefix-injection and continuity assessment are applicable to technical domains plagued by redundancy and local coreference (e.g., manuals, regulatory codes, medical records). The method’s modularity also facilitates its integration with state-of-the-art retrieval stacks and vector databases without retriever retraining.
Theoretically, the work foregrounds the necessity of context-preserved unit representation in document-oriented retrieval tasks and exposes the limitations of local chunk independence paradigms.
Future advances may involve adaptive prefixing sensitive to evolving domain ontologies, dynamic continuity modeling over streaming or non-stationary corpora, and efficient lightweight inference schemes to reduce LLM inference costs in high-throughput indexing.
Conclusion
The CHOP framework introduces a principled approach to context-preserving chunking and retrieval in multi-document RAG pipelines. Through structured metadata prefixing and LLM-driven continuity analysis, CHOP systematically reduces retrieval confusion, improves ranking quality, and enhances generation fidelity. Its empirical results demonstrate dominant retrieval performance and consistent generation metric gains, offering a practical and theoretically motivated solution for robust evidence retrieval in overlapping and reference-heavy corpora (2604.15802).