- The paper demonstrates that per-instance RAG gain prediction is feasible using holistic, ModernBERT-based modeling, achieving high correlations (up to 0.89).
- It evaluates predictors across pre-retrieval, post-retrieval, and post-generation stages, showing the superiority of supervised approaches over unsupervised baselines.
- The study implies selective RAG can optimize quality and cost by dynamically invoking retrieval only when predicted to improve answer performance.
Introduction and Problem Statement
Retrieval-Augmented Generation (RAG) integrates external retrieval mechanisms with LLM generation, grounding answers in external textual resources and mitigating hallucinations. While RAG demonstrates average gains in question answering (QA), indiscriminate retrieval augmentation often introduces latency, computational overhead, and may even degrade generation quality if retrieved passages are irrelevant or distracting. The central question addressed is whether it is possible—at the instance level—to predict the gain attributable to RAG, relative to pure parametric (no-retrieval) LLM answering. Instance-level gain prediction could enable selective RAG, optimizing quality/cost trade-offs in production QA systems.
RAG Gain Definition and Evaluation Metrics
The study adopts and extends the notion of RAG gain from prior work, operationalized as the (log) ratio of answer quality with vs. without augmentation, evaluated using three categories of metrics:
- Traditional metrics: Exact Match (EM), token-level F1.
- Semantic metrics: Embedding-based (E5 cosine), cross-encoder association (RoBERTa-large cross-encoder), and NLI entailment (DeBERTa-v3-large-NLI). These favor semantic overlap and entailment over surface string matching.
- LLM-as-judge: LLMs evaluate response-reference similarity per "LLM-as-a-judge" protocols, providing high alignment with human annotation but at significant computational cost.
Substantial correlations are observed among the semantic metrics (e.g., r=0.61 to $0.84$), but non-redundancy implies each captures complementary aspects of answer quality. Gains computed with these metrics are also strongly correlated across datasets.
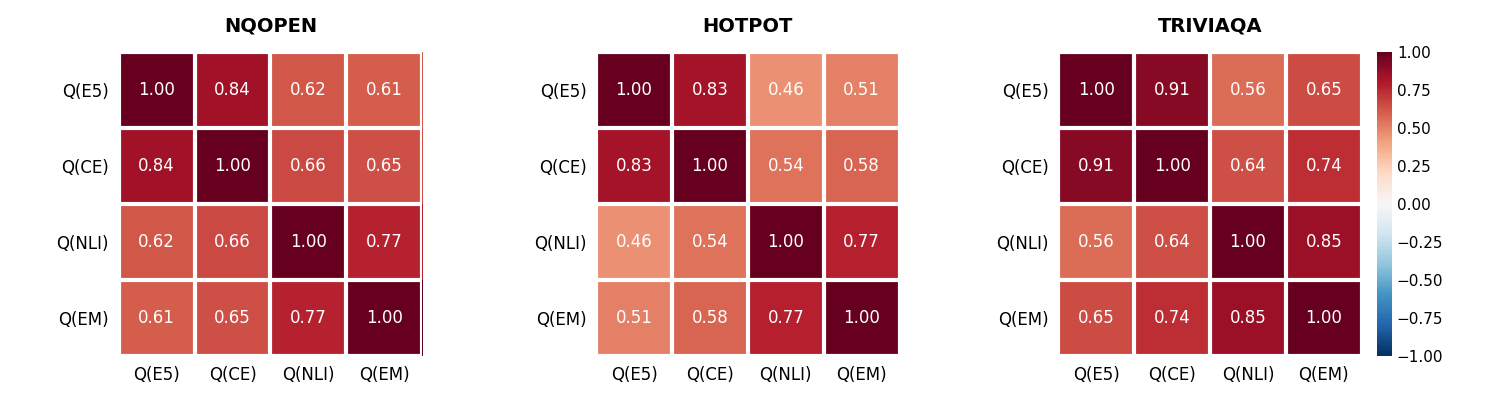
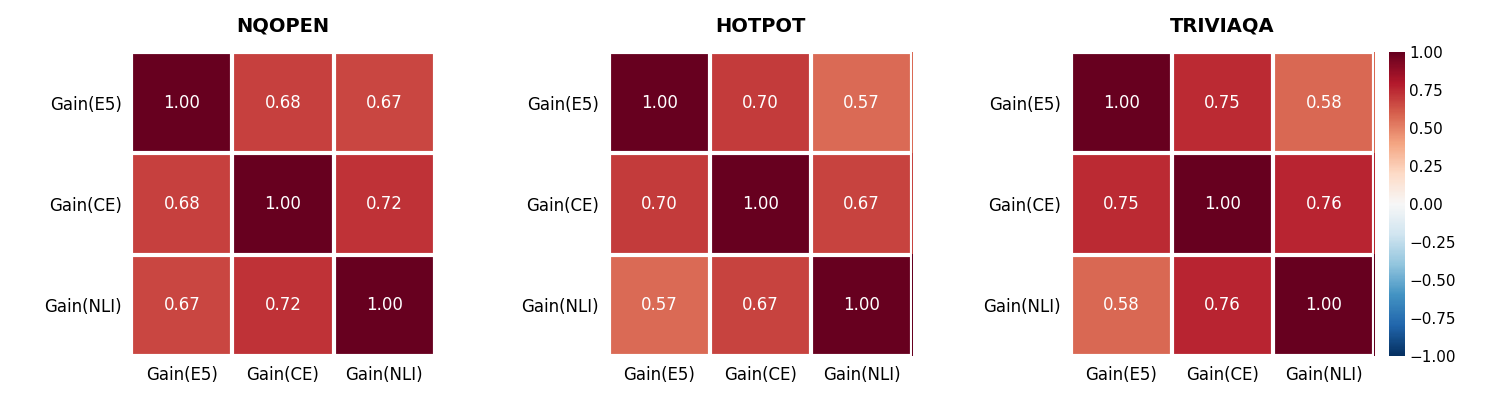
Figure 1: Pairwise correlations among quality metrics and among gain values computed with these metrics, showing metric complementarity and high gain correlation.
RAG Gain Distribution and Motivation for Prediction
The empirical distribution of RAG gain, tested across Falcon3-10B-instruct with BM25 retrieval over Wikipedia (across NQ, TriviaQA, and HotpotQA), reveals:
- The average RAG gain is positive across all datasets and evaluation metrics, confirming that on aggregate, RAG enhances QA performance.
- However, the gain distribution is sharply concentrated near zero with heavy positive tails, and a non-trivial fraction of questions exhibit negative RAG gain—i.e., RAG degrades answer quality.
This heterogeneity highlights the practical risk of indiscriminate retrieval augmentation and the need for precise RAG gain prediction.
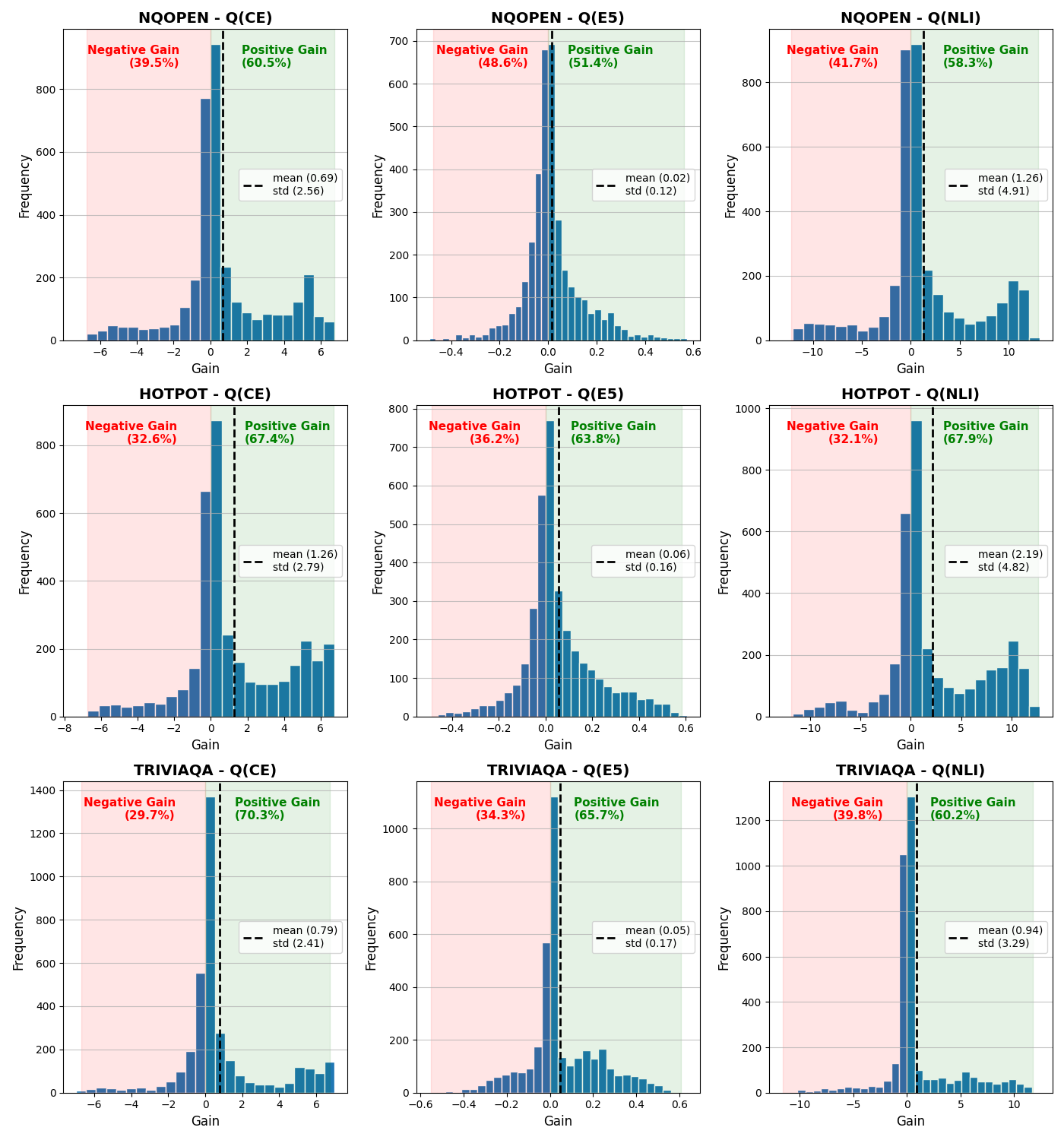
Figure 2: The empirical distribution of RAG gain across QA datasets, revealing many questions with little or negative gain and motivating selective RAG.
Predictive Modeling Approaches
Three classes of predictors are investigated:
Pre-Retrieval Predictors
These rely on question and corpus-level statistics alone (e.g., SCQ, mean/max/min IDF, variance of tf-idf across documents), adapted from query performance prediction (QPP) in IR. Across all conditions, these features are found to be ineffective for forecasting RAG gain in QA, with correlations negligible to slightly positive.
Post-Retrieval Predictors
Analyzing both the input question and retrieved passages, post-retrieval predictors include:
- Unsupervised statistics such as score differential and variance-based features computed over retrieval rankings.
- Supervised regression using a ModernBERT-large cross-encoder trained on question + retrieved passage pairs, with regression targets set to actual RAG gain (as per Equation 1).
Unsupervised post-retrieval features yield moderate improvements (Pearson r≈0.1−0.2), but the ModernBERT-based approach provides significantly stronger predictive performance (up to r=0.45−0.49 on select datasets and retrieval settings).
Post-Generation Predictors
These leverage the generated answers under both RAG and no-RAG conditions. The approaches include:
- Unsupervised: Token-level entropy gap between the generation distributions (measuring uncertainty reduction), and NLI entailment between the RAG-generated answer and the context passages.
- Supervised holistic modeling: A ModernBERT-based regressor over the question, retrieved passages, and both generated answers (with RAG and no-RAG), trained to predict true RAG gain.
This last approach yields the highest overall correlation with true gain (r up to $0.87-0.89$ on TQA, $0.71-0.79$ on NQ), significantly outperforming all other unsupervised and supervised baselines.
Experimental Protocol
Comprehensive evaluation is performed across:
- Two LLMs (Falcon3-10B-Instruct, Llama-3.1-8B-Instruct)
- Two retrieval paradigms (BM25, E5 dense retrieval)
- Three QA benchmark datasets (NQ, HotpotQA, TriviaQA)
- Multiple semantic evaluation metrics
Training data comprises 24,000 questions per dataset, with validation and test splits strictly enforced. The ModernBERT-based models are trained per LLM/retriever/dataset/metric combination.
Empirical Results
Key numerical findings:
- Pre-retrieval predictors: Ineffective for practical gain prediction (∣r∣<0.1 in most cases).
- Unsupervised post-retrieval predictors: Slight gain over pre-retrieval but remain suboptimal (r≈0.2).
- Supervised post-retrieval modeling: Highest pre-generation performance (r=0.45−0.49).
- Unsupervised post-generation (entropy gap): Moderate to strong signal ($0.84$0).
- Supervised holistic model (ModernBERT with both answers): Statistically significant improvement over all alternatives, with $0.84$1 (TQA) and $0.84$2 (NQ), establishing a new upper bound in RAG gain prediction accuracy on these benchmarks.
All gains are robust across LLM, retrieval method, and evaluation metric.
Theoretical and Practical Implications
The empirical results underscore that reliable per-instance RAG gain prediction is feasible, but only if semantic interactions among the question, context, and generated answers are modeled holistically. Simple IR-derived predictors, even when supervised, lack sufficient discriminative power in the more challenging QA-RAG setting (where answer quality is not fully determined by passage relevance alone).
The practical implication is the possibility of selective RAG—dynamic, instance-aware invocation of retrieval only when gain is predicted to be positive and/or above a context-sensitive threshold. This approach can substantially reduce unnecessary computation and mitigate the risk of generation quality degradation due to extraneous or misleading retrieved content. Adaptive RAG also has economic ramifications for production systems, balancing answer quality and inference/retrieval costs in a principled manner.
Future Directions
The research opens avenues for:
- Exploring richer and more computationally efficient predictive signals (including modalities or external knowledge sources).
- Scaling holistic, post-generation predictors to even larger models, broader sets of questions, or non-factoid QA tasks.
- Integrating gain prediction into online RAG policies for robust, cost-sensitive QA delivery.
Selective RAG based on gain prediction has immediate applicability in systems where latency, accuracy, or retrieval costs are critical.
Conclusion
This study establishes that instance-level prediction of RAG gain is feasible, particularly through supervised modeling that explicitly encodes semantic interactions among the question, retrieved context, and potential answers. The combination of semantic metrics, comprehensive empirical analysis, and statistically robust supervised models delivers state-of-the-art RAG gain prediction. These insights support the design and deployment of adaptive, efficient, and reliable RAG-based question answering systems.
References:
Dado, O., Carmel, D., & Kurland, O. "Rag Performance Prediction for Question Answering" (2604.07985)