- The paper introduces a novel chunk filtering methodology that leverages semantic, topic, and entity signals to effectively reduce redundancy in RAG pipelines.
- The paper demonstrates that NER-based filtering can shrink index sizes by 25–36% while maintaining accurate token coverage in varied datasets.
- The paper’s findings indicate that targeted filtering optimizes storage and retrieval efficiency, potentially enhancing downstream answer generation quality.
Redundancy Reduction in Retrieval-Augmented Generation via Chunk Filtering
Introduction
The paper "Reducing Redundancy in Retrieval-Augmented Generation through Chunk Filtering" (2604.24334) addresses redundancy in chunked document corpora for Retrieval-Augmented Generation (RAG) pipelines. RAG architectures couple LLMs with retrieval systems, leveraging external knowledge bases to enhance reliability, traceability, and factual grounding (Figure 1).
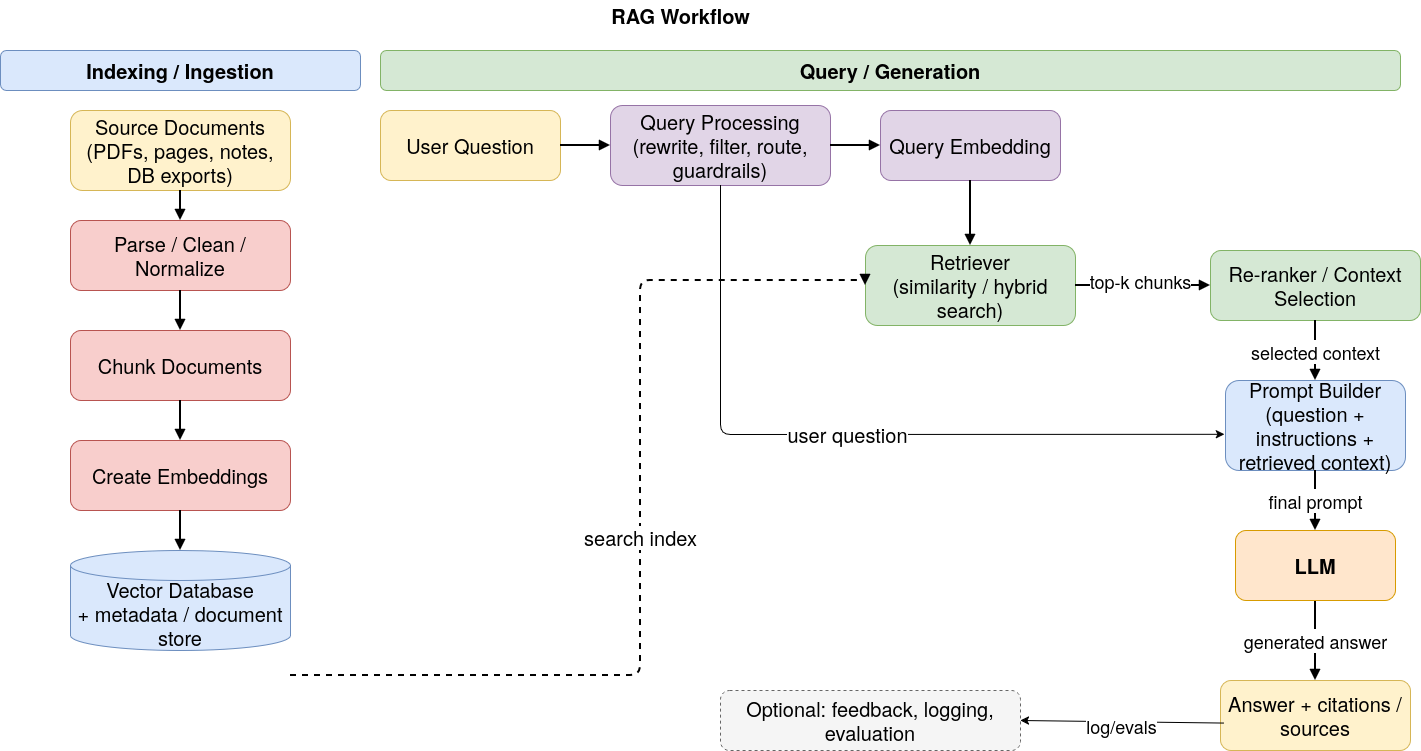
Figure 1: RAG workflow illustrating document chunking, embedding, retrieval, and context augmentation.
Chunking—a preprocessing step that segments documents before embedding and indexing—commonly uses overlapping strategies to preserve contextual continuity. However, these methods introduce substantial redundancy, inflating vector index sizes and degrading retrieval efficiency. The authors hypothesize that systematic chunk filtering can eliminate redundant segments, reducing storage and computation burdens while preserving retrieval quality.
Theoretical Foundation and Prior Work
RAG systems are critically dependent on the chunking strategy applied during indexation. Overlapping chunk methods ensure context preservation but routinely generate near-duplicate content across index entries. Prior literature on passage retrieval, semantic chunking, and dataset deduplication indicates the detrimental effects of excessive redundancy: decreased retrieval diversity and wasted context window space in LLM prompts.
Redundancy in vector databases manifests at several levels:
- Exact and near-exact duplication: from repeated boilerplate or aggressive overlap.
- Semantic and structural redundancy: chunks with high lexical or topical similarity, or identical named entity structure.
Recent alternatives to conventional chunking—such as late chunking and contextual embedding—focus on enriching chunk representations rather than compacting the index. The present study distinguishes itself by targeting outright removal of redundant chunks using filtering signals.
Chunk Filtering Methodology
The study rigorously evaluates multiple filtering signals for redundancy detection:
- Lexical deduplication (ExactNorm, MinHash-LSH): Baselines targeting exact or near-duplicate text.
- Semantic similarity: Chunk embeddings compared via cosine similarity, with thresholding to remove highly similar pairs.
- Topic modeling (LDA, BERTopic): Filtering within topic clusters to avoid eliminating semantically close but topically diverse chunks.
- Named Entity Recognition (NER): Chunks sharing identical or overlapping named entity sets are flagged as structurally redundant.
Combined signals further refine filtering: semantic similarity gated within topical clusters or entity-matched segments. Filtering strategies are applied post-chunking, before embedding and indexing.
The evaluation protocol employs token-based precision, recall, and intersection-over-union (IoU) metrics, comparing coverage of reference passages in retrieved top-k chunks. An oracle chunk selection process establishes upper bounds for retrieval given the filtered index (Figure 2).
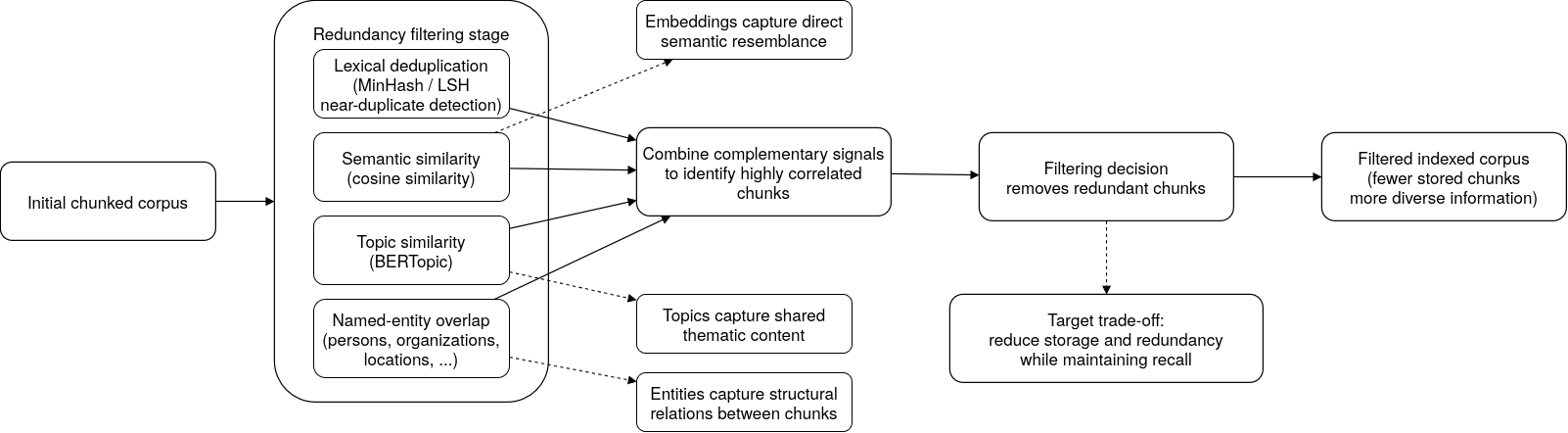
Figure 3: Filtering pipeline combining semantic, topic, and entity signals to maximize diversity and minimize redundancy.

Figure 2: Greedy oracle chunk selection, maximizing token coverage for reference answers.
Empirical Results
Experiments span diverse corpora: structured speeches, Wikipedia articles, chat logs, financial QA, biomedical texts, and multilingual web documents. Multiple chunking strategies—fixed token splits, recursive splits, semantic clustering—are tested with Sentence Transformers and BGE embedding models.
Similarity-Based Filtering
Semantic similarity thresholds moderately reduce index size but often present a trade-off: aggressive filtering degrades recall and IoU. Adding topic or entity constraints yields marginal improvements, except in highly clustered or entity-rich datasets.
NER-Based Filtering
Entity-based filters—especially Exact NER matching—achieve substantial index reduction (25–36%), with minimal loss in token coverage metrics. This is particularly pronounced in recursively chunked corpora and domains with dense entity distribution (e.g., finance, biomedical). Partial entity overlap filtering (NER Half) offers less predictable trade-offs and can remove complementary content.
Lexical deduplication baselines reduce index size insignificantly compared to semantic and entity-driven methods. Random chunk removal produces much sharper performance degradation, underscoring the selectivity and efficacy of signal-based filtering.
Dataset-Specific Findings
- Structured/Entity-rich corpora: NER Exact consistently preserves recall and precision close to baseline while dramatically shrinking the index.
- Homogeneous datasets (SQuAD): Semantic similarity suffices; entity filtering becomes more aggressive, risking loss of contextual information.
- Multilingual and heterogeneous corpora (WebFAQ): Entity-based filtering leverages cross-lingual entity anchors, sustaining retrieval quality amid greater lexical and structural variability.
Implications for RAG Pipeline Design
Practical implications include:
- Index compactness: Filtering strategies provide a principled mechanism for reducing storage and compute costs.
- Retrieval efficiency: Removing redundant chunks minimizes wasted retrieval slots and improves context utilization.
- Downstream generation potential: The observed gains at the retrieval level suggest that filtering has potential utility for downstream answer quality, though empirical validation is needed.
Theoretically, the results affirm the multi-modal nature of redundancy: structural signals (entities, topics) combined with semantic embeddings provide robust filtering criteria. This enables more compact yet diverse information representations, critical for scalable RAG deployments.
Future Directions
Key avenues for further research:
- End-to-end generation assessment: Validate that retrieval-level improvements translate to better LLM outputs.
- Integration with reranking and graph-based chunk organization: Explore synergy between upstream filtering and sophisticated context selection/ranking downstream.
- Adaptive filtering in dynamic corpora: Investigate real-time redundancy reduction as corpora evolve, especially in domains with frequent updates.
Conclusion
Chunk filtering is demonstrated as an effective mechanism for reducing redundancy and improving efficiency in RAG pipelines. Entity-based filters (especially NER Exact) yield optimal precision–recall–IoU trade-offs, substantially shrinking the index while maintaining access to relevant information. Filtering based on semantic, topic, and entity signals outperforms basic lexical deduplication, establishing structural redundancy detection as foundational for scalable retrieval systems. Future work should bridge retrieval-level gains with end-to-end answer generation and deeper integration with ranking and context modeling.