- The paper presents a comprehensive evaluation of ten retrieval methods, showing that hybrid fusion with reranking achieves a Recall@5 of 0.816.
- It highlights that BM25 outperforms dense retrieval due to financial documents’ precise lexical cues and structured numerical data.
- The analysis provides actionable recommendations for using hybrid RAG and contextual summaries in financial QA to improve precision.
Benchmarking Retrieval for Text-and-Table RAG: An Expert Analysis of "From BM25 to Corrective RAG"
Overview
"From BM25 to Corrective RAG: Benchmarking Retrieval Strategies for Text-and-Table Documents" (2604.01733) provides the most comprehensive evaluation to date of retrieval-augmented generation (RAG) strategies in financial QA over heterogeneous text-and-table documents. The study implements and systematically benchmarks ten prominent retrieval methods—including sparse, dense, hybrid fusion, reranking, query-side and index-side augmentations, and adaptive correction—on T²-RAGBench, a synthetic but highly realistic corpus spanning 23,088 queries over 7,318 financial filings with mixed content.
The core contributions are (1) multi-metric retrieval and generation evaluation, (2) ablations on fusion and reranker architecture, (3) actionable engineering guidance grounded in extensive error analysis, and (4) highlighting fundamental limitations in current RAG recipes when numerical reasoning and structure-sensitive grounding are required.
Experimental Design
The authors leverage T²-RAGBench, which unifies and reformulates three canonical financial QA datasets (FinQA, ConvFinQA, TAT-DQA) into a retrieval-evaluation framework. Every query is precisely formulated (via Llama 3.3-70B and human validation) to ensure document-unique answers, eliminating ambiguity and ensuring that retrieval quality, not question ill-posedness, is the dominant variable.
The main evaluation metrics are Recall@k, MRR@k, nDCG@k, MAP for retrieval, and Number Match (NM) with strict relative tolerance for downstream answer quality. All significance testing adopts paired bootstrap with Bonferroni correction. The studied retrieval methods include rigorous default baselines (BM25, state-of-the-art dense retrieval via OpenAI text-embedding-3-large), hybrid pipelines (Reciprocal Rank Fusion, Convex Combination), cross-encoder reranking (Cohere Rerank v4.0), LLM-driven query expansion (HyDE, multi-query RRF fusion), document-side augmentations (contextual summaries), and adaptive correction (CRAG).
Main Results
Hybrid retrieval fused with neural cross-encoder reranking represents the clear Pareto-optimal solution for this domain, achieving Recall@5 of 0.816 and MRR@3 of 0.605—a substantial margin over all single-stage methods.
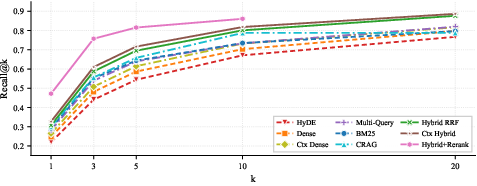
Figure 1: Recall@k curves for BM25, dense, and hybrid RRF retrieval; hybrid fusion exhibits the dominant recall curve, especially at low k.
BM25 consistently outperforms dense retrieval for financial document search on all primary metrics except Recall@20, opposing frequent claims of universal semantic search dominance. This is attributed to the high lexical signal of financial documents, where company names, fiscal periods, and metric labels are highly formulaic and precisely matched.
Query-side augmentation methods (HyDE, multi-query) were found to provide negligible or negative returns for numerical financial QA. HyDE, in particular, underperforms vanilla dense baselines. The authors attribute this to the inability of LLMs to reliably generate accurate pseudo-numeric passages, contaminating embeddings with spurious numbers. Contextual retrieval—adding a document-level summary at indexing—yields consistent, albeit moderate, gains for both dense and hybrid pipelines.
Adaptive corrective retrieval (CRAG) helps recover some failures (Recall@5 0.658, +1.4pp over BM25), but not to the level of straightforward hybrid fusion. As most CRAG triggers are invoked, this indicates the presence of numerous challenging queries where first-pass retrieval is ambiguous or irrelevant, but existing correction mechanisms are unable to fully compensate for the complexity.
Grouped metric comparisons empirically anchor these conclusions.
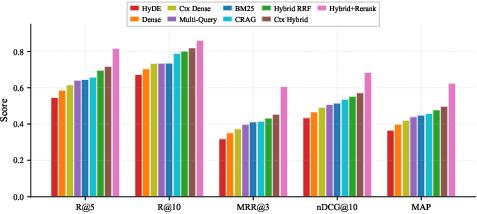
Figure 2: Hybrid RRF dominates grouped metrics; BM25 outperforms dense retrieval in every measured category on this financial benchmark.
Subset analyses demonstrate that TAT-DQA is the most challenging segment, especially for structured table-centric queries, with hybrid fusion producing the largest absolute and relative improvements, underscoring the complimentary nature of lexical and semantic signals in this context.
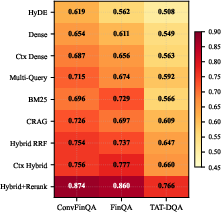
Figure 3: Recall@5 heatmap; TAT-DQA is the hardest subset, and hybrid fusion closes the gap most strongly.
End-to-end evaluation with both GPT-4.1-mini and GPT-5.4 reinforces the finding that retrieval quality and model capability are independent axes of performance, with strong positive correlation (r>0.99) between Recall@5 and downstream number match.
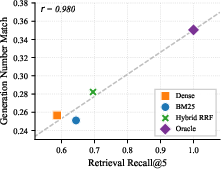
Figure 4: Retrieval quality (Recall@5) correlates almost perfectly with generation quality (Number Match) for both LLMs.
Ablation studies reveal that score fusion requires careful calibration: Convex Combination with equal BM25/dense weights slightly outperforms RRF for some settings, and reranker candidate depth is crucial—too few candidates starves the reranker, capping attainable precision.
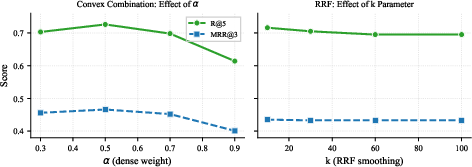
Figure 5: Fusion ablation demonstrates optimal results with equal dense-BM25 weighting; lower RRF k values benefit ranking at practical depths.
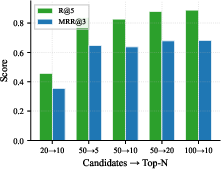
Figure 6: Reranker depth ablation shows candidate pool increases Recall@5, with sharp gain when increasing to 50+; diminishing returns after top-10 reranked output.
Error Analysis
A detailed manual audit attributes 73% of retrieval failures in hybrid RRF to table structure mismatch—i.e., the inability of embedding models to bridge markup structure and textual queries—rather than vocabulary mismatch or document length. Numerical reasoning (20%) remains a profound challenge, especially when aggregation or multi-step computation is needed.
Per-subset failure rates highlight the persistent challenge of the TAT-DQA segment, directly mapped to its emphasis on multi-table, multi-operation questions.
Implications and Theoretical Insights
These results unsettle several widely adopted heuristics for RAG system design:
- Sparse lexical matching (BM25) remains highly competitive for domains with structured, terminology-rich documents, even when advanced dual-encoder or LLM-driven approaches are available.
- Hybrid fusion consistently outperforms both BM25 and dense methods individually, confirming the orthogonal information captured by lexical and semantic signals.
- Downstream answer quality is strictly bottlenecked by retrieval quality in numerically grounded tasks; advances in LLM architecture do not compensate for retrieval failures when context is missing.
- Neural reranking is critical for maximizing recall and precision in the top ranks, especially when addressing ambiguous or structurally complex queries.
- LLM-driven query expansion or hypothetical augmentation (HyDE) can degrade performance in precision-critical (e.g., financial) domains, due to high hallucination risk in numeric content.
These empirical findings raise open theoretical questions about the representation power of current embedding models on structured, multi-format content, and the fundamental limitations of retrieval-first architectures for complex evidence aggregation.
Practical Recommendations
The paper offers concrete recommendations for practitioners:
- Adopt hybrid retrieval (BM25 + dense via RRF or convex fusion) as the baseline for any heterogeneous or terminology-rich domain.
- Add cross-encoder reranking as the most effective upgrade for improved top-k recall and ranking quality; invest in sufficient reranker candidate pools.
- Employ document-level contextual summaries where possible, but do not expect query-variant or hypothetical expansion to yield high returns in numerically precise tasks.
- Avoid LLM pseudo-document approaches like HyDE when precision is paramount.
- Tailor evaluation to domain-specific metrics—standard benchmarks like MTEB/BEIR are not predictive of real-world performance in financial or structured QA.
Limitations and Future Directions
While comprehensive, the study is bounded by domain (financial filings), answer format (numerical), and retrieval granularity (document-level). The extension of these findings to chunked, passage-level, or non-financial domains is a critical area for future work. Comparative studies across embedding architectures (beyond text-embedding-3-large), more sophisticated late-interaction models (ColBERT, BGE-M3), and tree/graph-augmented retrievers (RAPTOR, GraphRAG) will further refine practical deployments.
Conclusion
The systematic benchmarking conducted in "From BM25 to Corrective RAG" delivers nuanced, empirically grounded insights for the RAG and QA communities. The evidence demonstrates the enduring value of lexical matching, the additive power of hybrid pipelines, the necessity of reranking, and the conditional utility—sometimes incapacity—of LLM-driven expansion in domains dominated by structural and numerical constraints. The released code and analysis establish a new baseline and reference point for the community developing RAG architectures for complex, heterogeneous corpora.