Merlin: Deterministic Byte-Exact Deduplication for Lossless Context Optimization in Large Language Model Inference
Abstract: Data-intensive applications, ranging from large-scale retrieval systems to advanced data pipelines, are increasingly bottlenecked by the processing of highly redundant text corpora. We present Merlin, a local-first, agnostic, high-throughput deduplication and context optimization engine designed to mitigate these inefficiencies. Utilizing a highly optimized, SIMD-friendly open-addressing flat hash set combined with xxHash3-64, Merlin performs rapid, byte-exact deduplication of text passages and data chunks. While broadly applicable to any text-processing workflow, its impact is particularly pronounced in LLM ecosystems, such as Retrieval-Augmented Generation (RAG). Our empirical evaluations demonstrate an input reduction ranging from 13.9% in low-redundancy datasets to over 71% in high-redundancy pipelines, maintaining absolute data fidelity. Furthermore, we detail the system's integration architecture via the Model Context Protocol (MCP), enabling secure, zero-network-interception deployment across major IDEs and autonomous agents. This paper outlines the core algorithmic design, performance benchmarks, and the architectural principles required to process data at sustained speeds of up to 8.7 GB/s.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a tiny, very fast tool called Merlin that removes exact duplicates from the text you send to a LLM before it answers a question. Think of it like cleaning up a study guide: if the same paragraph appears more than once, Merlin keeps only the first copy. The big claim is that this cleanup is “lossless” for quality: answers don’t get worse, but responses can be faster and cheaper to produce.
What were the researchers trying to find out?
They wanted to check three simple things:
- Can we delete exact duplicate chunks of text from a prompt without hurting the model’s answer quality?
- Can this be done deterministically (always the same result) and “byte-exact” (copies must be identical down to the last character)?
- Is it so fast and small that it barely adds any delay or resource cost in real use?
How did they do it?
They placed Merlin between the part of a system that collects text (like retrieved passages or chat history) and the part that builds the final prompt. Merlin:
- Looks at each piece of text as raw bytes (every character counts).
- Removes exact duplicates while keeping the original order and the first appearance of each piece.
- Produces the cleaned set very quickly, the same way every time.
Key ideas in everyday language:
- “Byte-exact” means two pieces must be literally identical to count as duplicates—no fuzzy matching and no guessing.
- “Deterministic” means the same input always produces the exact same output—no randomness.
- “Inference” is the step where the AI reads your prompt and generates an answer.
- “Latency” is the time delay; Merlin’s own work takes microseconds (millionths of a second).
How they tested it:
- They tried Merlin across four real LLM APIs: Google Gemini 2.5 Flash, OpenAI GPT-5.1, Anthropic Claude Sonnet 4.6, and Meta Llama 3.3 70B.
- They used well-known tests (benchmarks): RULER (long-context retrieval), LongBench tasks that are safe for paragraph-level cleanup, and HumanEval-Snowball (coding with real multi-turn dialogue history).
- They compared answers with and without Merlin to check if quality changed.
- They also measured speed in different ways: as a function call inside a program, as a separate process, and by checking internal timers.
- For correctness, they compared Merlin’s “unique count” (how many unique chunks are left) with a simple reference everyone can use: Python’s built-in set() (which removes exact duplicates). On a huge real dataset (22.2 million passages), Merlin and Python agreed every time.
What did they find?
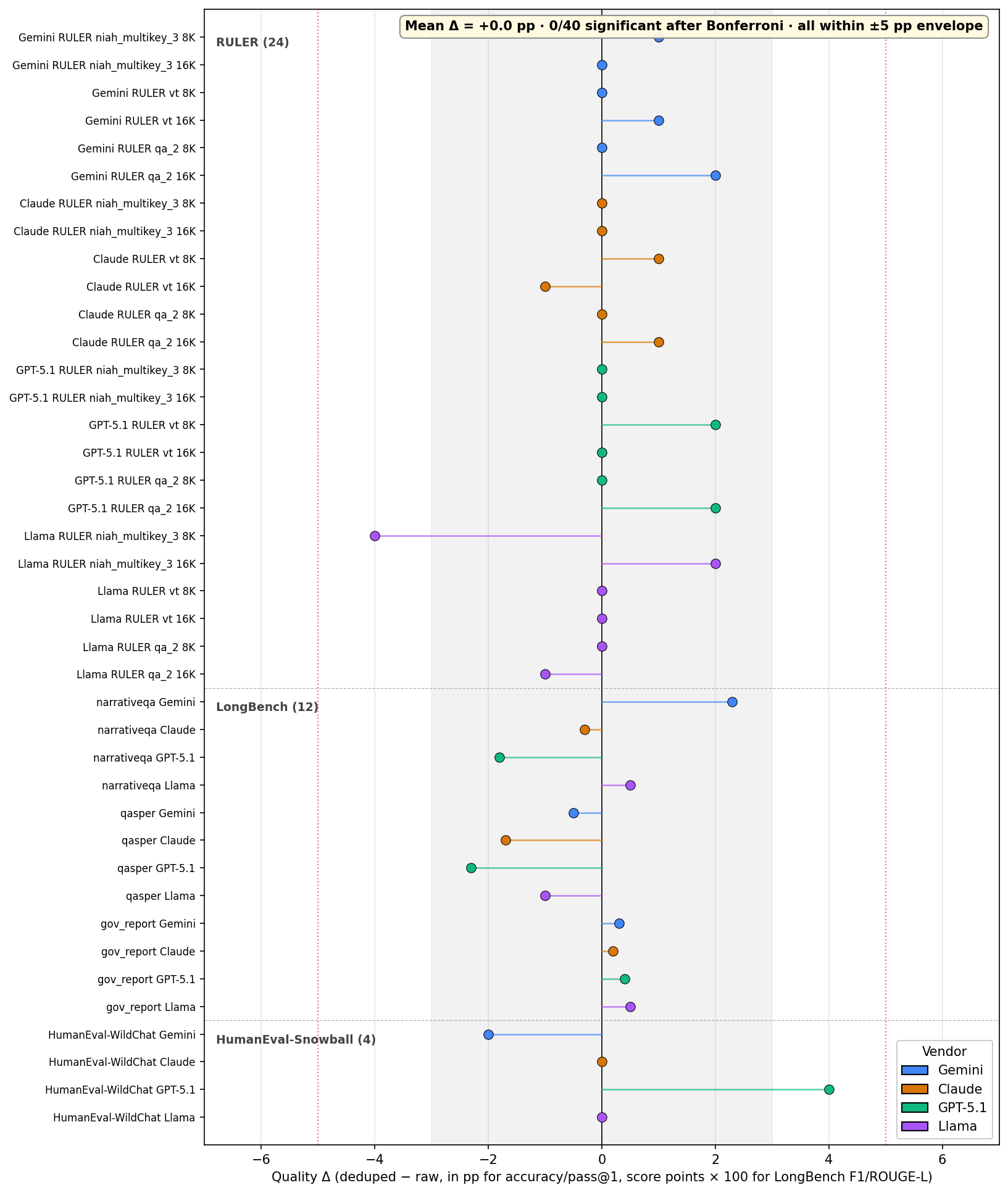
- Quality stayed the same:
- Across 40 main test settings and an extra 200 follow-up checks, the average change in score was +0.0 percentage points (main) and -0.5 points (follow-up), with no statistically significant drops after strict testing. In simple terms: removing exact duplicates didn’t make answers worse.
- It’s extremely fast and tiny:
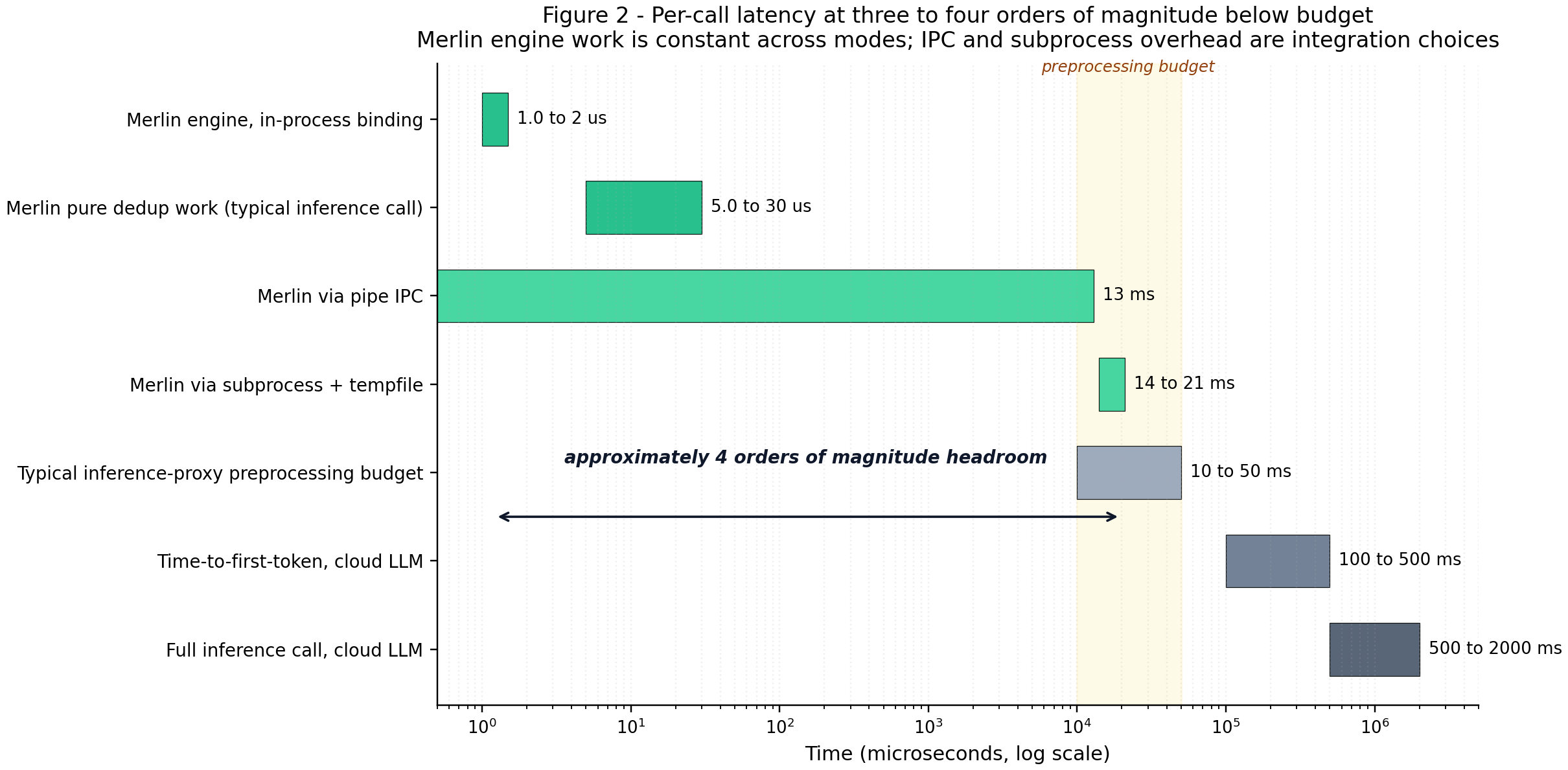
- In-process (best way): about 1.10 microseconds of work per call.
- As a separate process (less ideal): the operating system adds about 13–21 milliseconds, which is overhead from starting/stopping programs, not from Merlin itself.
- Typical LLM calls take tens of milliseconds to several seconds, so Merlin’s cost is effectively “free” when integrated properly.
- The binary (the program file) is small: about 3.8 MB on Windows and 3.5 MB on Linux.
- It’s reliable:
- Output is byte-for-byte consistent on the same computer type (deterministic).
- On Windows, Merlin matched an independent reference wrapper’s outputs on 100% of non-code prompts and 99.2% overall.
- On 22.2 million real passages (BeIR), Merlin’s unique counts exactly matched Python set() for all tested queries.
- Where duplicates matter (and shouldn’t be removed), they excluded those tasks:
- Some tasks intentionally repeat text as part of the instruction (e.g., a label repeated on purpose). Those were not used to make the “lossless” claim.
Why does it matter?
- Faster, cheaper AI: If the model doesn’t waste time re-reading identical text, the “prefill” stage (where it loads your prompt) gets quicker, potentially saving time and money at scale.
- Safe first step: Because the cleanup is exact and preserves answer quality, it’s a low-risk optimization to apply before any other tricks.
- Plays nicely with others: It works across different model vendors and can be combined with other methods (like caching or retrieval improvements) for even bigger gains.
- Practical and portable: It’s tiny, has no extra dependencies, and works the same way across platforms—useful for real production systems.
- Honest testing: The team locked in their methods ahead of time and made it possible to verify the main claims using public data and simple tools (like Python’s set()).
In short, Merlin is like a super-fast “duplicate remover” that cleans prompts without changing what they mean, making LLMs more efficient without hurting the quality of their answers.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Items are grouped to aid follow‑up research and engineering validation.
Methodology and reproducibility
- Closed-source constraint: Lack of public code, binary, and architectural details prevents independent replication of throughput, memory profile, and tail-latency claims; the clean‑room track is restrictive and not verifiable at scale by third parties.
- Power analysis and sensitivity: No formal power analysis to quantify the minimal detectable degradation; risk of Type II errors given small deltas and provider noise floors.
- Temporal robustness: Model APIs evolve; reproducibility of “no quality loss” as vendors silently update models (e.g., GPT‑5.1, Gemini 2.5) is untested over time.
- Router effect: Measurements rely on OpenRouter; the impact of routing-layer policies (queueing, caching, retries) on stability and noise floors is not isolated.
- Statistical corrections: Bonferroni correction is used, but family definitions and per-task sample sizes may mask small but systematic effects; alternative FDR controls or hierarchical models are not explored.
Scope of evaluation (tasks, models, data)
- Limited task coverage: Excludes known repetition-sensitive tasks (e.g., LongBench trec); broader classes where repetition is a supervision signal (few-shot ICL with repeated labels, chain-of-thought scaffolds, tool-API schema repetition) remain untested.
- Code-task anomalies: 99.2% byte-identical rate overall indicates edge cases for code prompts; root causes, conditions, and mitigations are unspecified.
- Language and domain breadth: Predominantly English, text-only, and RAG-style; multilingual prompts, non-Latin scripts, mixed encodings, and domain-specific prompts (legal, biomedical) are not evaluated.
- Model diversity: Focus on four large API models; generalization to smaller/edge models, open-source local LLMs, and multi-modal models is unassessed.
- High-redundancy safety: Safety under substantial byte removal is deferred to the companion paper; this paper does not present panel-validated quality for high‑redundancy conversational settings (∼80% reduction).
Systems performance and deployment
- Tail latency and scalability: p99/p99.9 latency, throughput under high QPS, and head-of-line blocking are not reported for server-grade CPUs (e.g., AMD EPYC) or ARM (AWS Graviton) in production-like loads.
- Memory footprint at scale: Runtime memory usage, cache behavior, and allocation patterns for large contexts (e.g., thousands of chunks or multi‑MB prompts) are not disclosed.
- Concurrency behavior: Interaction with thread scheduling, NUMA, and contention under multi-tenant deployments is not quantified.
- Containerization/Orchestration: Impact of container runtime, cgroup limits, CPU throttling, and cold starts on latency is unmeasured.
- Integration overhead: Current production mode uses subprocess+tempfile (~21 ms); the paper does not quantify end‑to‑end impact under realistic pipelines or provide a migration path and API for in‑process integration.
- Energy/efficiency: No measurements of power, CPU cycles per byte, or cost/throughput trade-offs across hardware generations.
Correctness, determinism, and security
- Cross‑ISA determinism: Determinism is guaranteed “within ISA”; cross‑ISA byte-identical behavior (e.g., x86‑64 vs ARM64) for real RAG inputs is not fully established (ARM64 performance noted as pending).
- Hash collision and adversarial robustness: Fingerprint primitive is undisclosed; no formal collision bounds, empirical collision rates, or adversarial threat model (crafted collisions or degenerate inputs) are provided.
- Worst‑case behavior: No analysis of performance under worst‑case distributions (e.g., extremely high duplicate rates, all-unique inputs with many near-collisions triggering byte-verify fallbacks).
- Input validation and failures: Behavior on malformed inputs, extremely large individual records, embedded NULs, non-UTF‑8 bytes, or corrupted boundaries is unspecified; error handling and backpressure policies are not described.
- Stability across compilers/OS versions: Determinism under different compiler flags, standard library implementations, and OS upgrades is not characterized.
Algorithmic design choices and extensions
- Only record‑level exact dedup: Near-duplicate, paraphrase, or overlapping substring redundancy is untouched; effectiveness when chunkers use sliding windows or unaligned boundaries remains limited.
- Granularity trade-offs: Line-level dedup led to model‑specific outcomes (harmful/helpful depending on vendor) but no principled guidance, detection heuristics, or adaptive strategies are proposed.
- Hybrid pipelines: Integration of exact dedup with safe approximate dedup (e.g., MinHash+verification) to capture formatting/whitespace differences is unexplored.
- Canonicalization: No investigation of safe, deterministic canonicalization (e.g., newline normalization, whitespace folding) that could widen exact-match coverage without semantic loss.
Interaction with upstream and downstream components
- Retriever interactions: Effects on retriever rank distributions, dedup across multi-source retrievers, and interplay with re‑ranking are unmeasured; only first‑occurrence order is preserved without reweighting analysis.
- Prompt-caching synergy: Empirical measurements of combined gains and cache-key behavior with vendor prompt caching are absent.
- Tokenization effects: Removal of duplicate records may alter tokenization‑level statistics and positional biases (e.g., positional encodings, attention patterns); these dynamics are not analyzed.
- Tool and schema prompts: Structured prompts (JSON schemas, tool signatures) often rely on repetition; automatic detection to bypass dedup for such cases is not provided.
- Cross‑call/session dedup: Only per‑call dedup is described; dedup across sessions or batched requests (where redundancy is cross‑request) is not addressed.
Safety boundaries and failure modes
- When dedup should be disabled: No automated safeguards to detect prompts where repetition is required (e.g., ICL templates, CoT scaffolding, safety disclaimers).
- Partial removal artifacts: Potential for dangling references (e.g., “as stated above”) after duplicate removal is not discussed; although order is preserved, cross‑record referential coherence is untested.
- Provider non-determinism: While baseline noise is acknowledged, a principled decision framework for deploying dedup under varying vendor stability is not given.
Data handling and encoding
- Encoding normalization: Byte‑exact criterion ignores Unicode normalization (NFC/NFD), line endings (CRLF vs LF), BOMs, and trailing whitespace—leaving semantically identical items as distinct; safe normalization options are not evaluated.
- Privacy and compliance: Telemetry (e.g., stderr metrics) and temporary-file integration imply handling of raw prompt bytes; data retention, PII handling, and compliance considerations are not discussed.
Generalization and maintenance
- Cross‑domain validation details: Claims of validation on logs, web crawl, and scientific data (Section 4.13) lack dataset specifics, metrics, and results in this paper.
- Model/version drift monitoring: No maintenance plan or CI protocol to re‑validate safety as models and retrievers evolve.
- API/library surface: Lack of documented in‑process API for adopters hampers integration and reproducibility of “1 μs” path; versioning and semantic‑version guarantees are unspecified.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage byte‑exact, deterministic deduplication with microsecond‑scale overhead and no measurable quality loss across evaluated LLMs and benchmarks. Each item notes sectors, possible tools/workflows, and key dependencies/assumptions.
- Deduplicate retrieved chunks in RAG pipelines before prompt assembly
- Sectors: software, customer support, legal, healthcare, finance, education
- Tools/workflows: in‑process plugin for vLLM/TGI/Triton; LangChain/LlamaIndex/Haystack “post‑retrieval dedup” component; K8s sidecar in inference pods; proxy middleware in FastAPI/Node services
- Why now: Proven lossless at evaluation resolution; median in‑process latency ~1–5 μs (vs 10–100 ms preprocessing budgets); tiny static binary (<4 MB) or equivalent compiled library
- Assumptions/dependencies: Best integrated in‑process (subprocess adds 13–21 ms OS overhead); preserves first‑occurrence order; benefits scale with redundancy multiplicity ρ (overlapping windowed chunkers and repeated KB hits)
- Prune duplicate turns in multi‑turn chat/session histories
- Sectors: SaaS productivity suites, CX chatbots, IDE code assistants
- Tools/workflows: stateful proxy that deduplicates at “turn” granularity before context packing; telemetry to report unique_count for audit
- Why now: Empirically high redundancy in conversational logs; microsecond overhead; complements vendor prompt caching
- Assumptions/dependencies: Ensure repetition isn’t a supervision signal; retain first occurrence for chronology; privacy policies if deduplicating across users
- Post‑retrieval dedup for BM25/vector hybrid search results
- Sectors: enterprise search, e‑commerce, knowledge portals
- Tools/workflows: drop-in filter between retriever and ranker/prompt assembler; content‑addressable IDs for traceability
- Why now: Sliding windows create structural overlap; safe, model‑agnostic preprocessing step
- Assumptions/dependencies: Byte‑exact matching only (near‑dupes remain unless normalized upstream); keep ranking order by preserving first instance
- Log/observability summarization cost reduction
- Sectors: DevOps, SRE, cybersecurity
- Tools/workflows: Fluent Bit/Vector/Logstash filter to dedup exact repeats before LLM summarizers; CI dashboards surface unique_count
- Why now: Operational logs often contain repeated lines; cost/time savings with zero model changes
- Assumptions/dependencies: Some tools require preserving counts; emit (unique + counts) if frequency matters downstream
- Web crawl and ETL curation before LLM processing
- Sectors: search, content moderation, data labeling
- Tools/workflows: pipeline stage to remove exact duplicate pages/snippets before classification/summarization; fingerprints recorded for audit
- Why now: Demonstrated correctness at 22.2M‑passage scale on public BeIR data; reduces token load immediately
- Assumptions/dependencies: Byte‑exact identity only; identical content with different encodings will not match unless normalized prior to dedup
- Legal/e‑discovery document dedup prior to LLM review
- Sectors: legal, compliance
- Tools/workflows: exact duplicate elimination with provenance logs; chain‑of‑custody friendly (no lossy transformations)
- Why now: Lossless and deterministic; auditable via SHA‑256 and unique_count equivalence to Python set()
- Assumptions/dependencies: Retain metadata to show which duplicates were removed; some workflows may require “duplicate families” reporting
- On‑device and edge LLM assistants
- Sectors: mobile, embedded, robotics
- Tools/workflows: static CPU‑only library in iOS/Android/embedded apps that dedup context before local/remote model calls
- Why now: <4 MB static binary, no third‑party deps, microsecond latency; helps tight TTFT budgets on device
- Assumptions/dependencies: ISA‑scoped determinism (validate per architecture); ensure byte‑stable serialization of attachments
- Multimodal prompt cleanup (exact duplicate images/files)
- Sectors: healthcare imaging reports, enterprise document workflows, design tools
- Tools/workflows: remove repeated identical attachments/base64 payloads from prompts; keep first reference
- Why now: Byte‑exact applies to any bytes, not just text; immediate token/time savings for repeated assets
- Assumptions/dependencies: Only exact‑byte matches; visually identical but re‑encoded assets will not match
- Academic baselines and reproducible evaluation
- Sectors: academia, evaluation platforms
- Tools/workflows: mandate byte‑exact dedup (Python set() suffices for reproducibility) in RAG experiments to remove duplication confounds; publish unique_count and reduction fraction 1−1/ρ
- Why now: paper shows quality neutrality; easy to adopt; prevents overestimating retriever/model gains due to redundancy
- Assumptions/dependencies: Keep tasks where repetition is supervision (e.g., some ICL setups) out of this step
- Governance and cost reporting in production LLM ops
- Sectors: enterprise IT, platform teams
- Tools/workflows: include dedup telemetry (unique_count, duplicate_count, ρ) in OpenTelemetry; use as a “no‑regrets” optimization before any lossy compression
- Why now: Determinism + auditability supports SRE/FinOps; complements vendor prompt caching and RAGBoost‑style indexing
- Assumptions/dependencies: Apply first in the preprocessing cascade; monitor provider non‑determinism floors separately
Long‑Term Applications
Below are opportunities that benefit from further productization, standardization, or research (e.g., cross‑ISA guarantees, scaling across tenants, or domain‑specific policies).
- Built‑in, standard preprocessor in model servers and SDKs
- Sectors: software infrastructure
- Tools/workflows: native “dedup first” stage in vLLM/TGI/Triton/OpenAI‑style proxies; SDK hooks in LangChain/LlamaIndex
- Dependencies/assumptions: Vendor/community adoption; standard output contracts (order‑preserving, first‑occurrence)
- Content‑addressable prompt assembly with cross‑vendor caches
- Sectors: platform infrastructure, cloud
- Tools/workflows: canonical fingerprints for context items enabling deterministic cache keys across providers; unify with retrieval indices
- Dependencies/assumptions: Shared fingerprint standards; privacy/tenancy boundaries; cache‑key versioning across ISA/builds
- Cross‑session/global dedup in multi‑tenant environments
- Sectors: SaaS, productivity, support platforms
- Tools/workflows: cross‑user dedup of common KB snippets to reduce cost at scale while preserving per‑user context
- Dependencies/assumptions: Strict privacy and consent controls; robust accounting to attribute savings; strong audit trails
- Multimodal and streaming dedup beyond text
- Sectors: media, robotics, healthcare imaging, IoT
- Tools/workflows: exact dedup for repeated frames/files in video/audio/document streams prior to LLM/VLM processing
- Dependencies/assumptions: Byte‑stable ingest (identical encoders/containers); otherwise use upstream normalization to enable exact matches
- Retrieval/store‑level dedup and storage savings
- Sectors: data platforms, vector DBs, search engines
- Tools/workflows: enforce content‑addressable chunk storage to avoid duplicates; propagate IDs through retrieval to prompt
- Dependencies/assumptions: Migration path for existing indexes; de‑duplication must not degrade recall/diversity metrics
- Adaptive cascades: lossless dedup → lossy compression under budget
- Sectors: all high‑throughput LLM applications
- Tools/workflows: “Dedup‑first” gate that decides if further compression (e.g., LLMLingua) is needed to meet token/latency budgets
- Dependencies/assumptions: Budget‑aware controllers; per‑task safe lists (avoid compression on sensitive tasks)
- Energy/carbon reduction policies and procurement standards
- Sectors: public sector, energy/ESG reporting, large enterprises
- Tools/workflows: mandate byte‑exact dedup in AI procurement as a lossless energy‑saving measure; include in carbon accounting
- Dependencies/assumptions: Verified telemetry on token reduction; standardized reporting schemas
- Healthcare and regulated‑data pipelines with auditability
- Sectors: healthcare, finance, gov
- Tools/workflows: dedup as “data minimization” step before LLMs; signed logs of removed duplicates for compliance audits
- Dependencies/assumptions: Validate that removing repeats does not erase clinically or legally relevant multiplicity signals; retain counts/links to originals
- IDE and repository‑scale assistants with deterministic context packing
- Sectors: software engineering
- Tools/workflows: large‑repo assistants that fingerprint and dedup repeated boilerplate or vendored code before inference
- Dependencies/assumptions: Line‑ vs paragraph‑level granularity can affect model behavior differently by vendor; vendor‑specific evaluation needed (paper flags mixed results for line‑level in code tasks)
- Standardized benchmarks and leaderboards that control for redundancy
- Sectors: academia, benchmarking orgs
- Tools/workflows: require publishing metrics both with and without exact‑dedup to avoid inflating gains from structural overlap
- Dependencies/assumptions: Community consensus; task‑specific exceptions (e.g., where repetition is the signal)
- Edge robotics and real‑time agents
- Sectors: robotics, industrial automation
- Tools/workflows: integrate dedup into on‑robot NL interfaces to cut context size and TTFT without GPU reliance
- Dependencies/assumptions: Real‑time schedulability analyses; byte‑stable sensor‑to‑text bridges
- Open‑source, audited equivalents and language bindings
- Sectors: developer tools
- Tools/workflows: minimal C/C++/Rust libraries with Python/JS bindings implementing the paper’s formalism (hash + byte‑verify; order‑preserving)
- Dependencies/assumptions: Community maintenance and cross‑ISA test matrices; clear determinism guarantees per platform
- Security/tooling: tamper‑evident context assembly
- Sectors: security, regulated IT
- Tools/workflows: log fingerprints of included/excluded context items; detect replayed or injected duplicate payloads
- Dependencies/assumptions: Governance around acceptable transformations; distinguish benign duplicates from adversarial repetition
Cross‑cutting assumptions and dependencies
- Benefit scales with redundancy multiplicity ρ; low‑redundancy corpora (clean academic) see little gain, whereas constructed enterprise and conversational settings can see large reductions (reported up to ~80% in companion work).
- Determinism is guaranteed within an instruction‑set architecture; verify cross‑ISA behavior and byte‑stable serialization for multimodal payloads.
- Integration mode matters: in‑process linking yields microsecond overhead; per‑call subprocess invocation adds 13–21 ms OS overhead that can erase benefits.
- Preserve first‑occurrence order to maintain context semantics; do not apply on tasks where repetition is the supervision signal (e.g., specific ICL prompts).
- Closed‑source engine availability may limit adoption; functionally equivalent compiled implementations (hash + byte‑verify, order‑preserving) satisfy the paper’s formal definition and can be used where open solutions are required.
- Provider‑side non‑determinism (even at temperature 0) sets a noise floor; monitor and separate this from preprocessing effects.
Glossary
- AVX2: An x86 SIMD instruction set extension that accelerates vectorized operations. "AVX2 active, L2 28 MB, L3 24 MB, high-resolution timer 1ns granularity."
- BeIR: A public benchmark suite for information retrieval used to evaluate retrieval and RAG systems. "Empirical validation at scale: 22.2M passage cross-corpus run on real public BeIR data."
- BM25: A probabilistic ranking function widely used in information retrieval to score document relevance. "Per-query math-equivalence verification across 327 BM25 retrieval queries"
- Bonferroni correction: A multiple-comparison adjustment that controls family-wise error by dividing alpha across tests. "with zero statistically significant degradations after Bonferroni correction within either family."
- byte-exact deduplication: Removing exact duplicate byte sequences with no semantic interpretation or transformation. "The primary contribution is the safety property: byte-exact deduplication preserves model quality at evaluation-grade resolution"
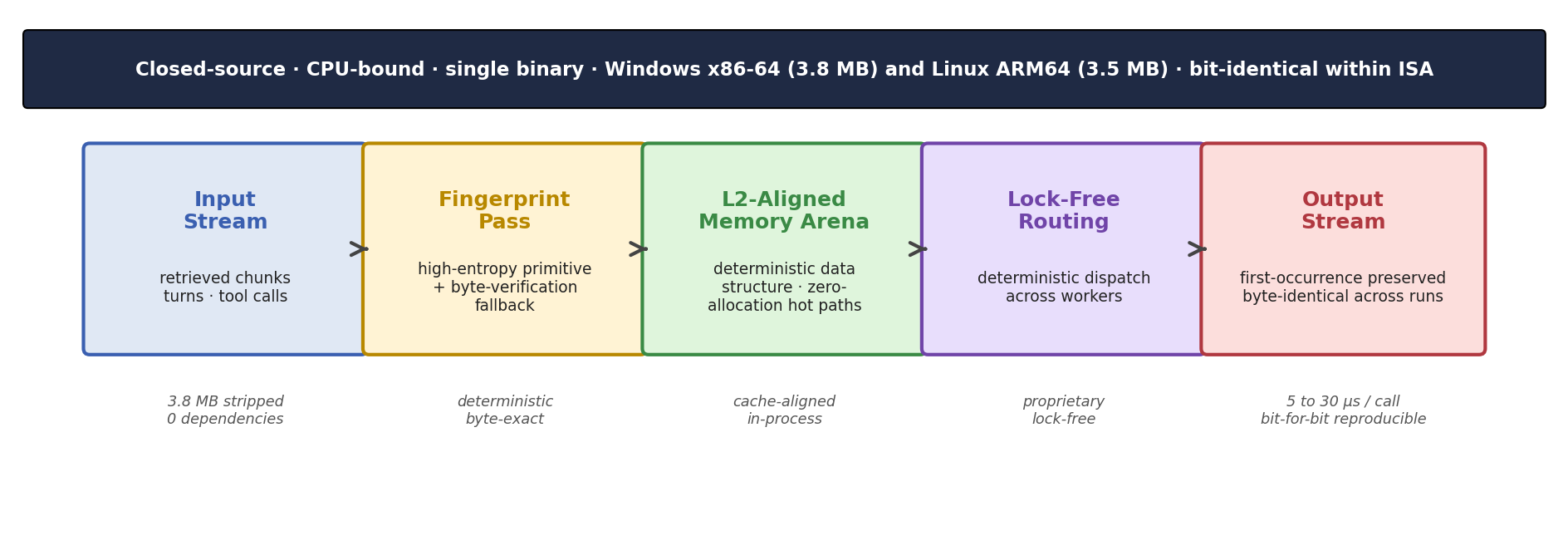
- cache-aware memory layout: Organizing data structures to align with CPU cache hierarchies for performance. "the systems literature, the engine is described as a CPU-bound architecture with cache-aware memory layout."
- canonical representative: A chosen member of an equivalence class used to represent that class consistently. "The deduplicated context is the canonical representative ordered subset"
- clean-room evaluation track: A controlled, isolated evaluation process allowing external parties to test proprietary systems without code disclosure. "throughput and binary-size claims is offered through a clean-room evaluation track for qualified parties."
- collision-probability assumption: The assumption that cryptographic hash collisions are negligibly probable for high-entropy families. "under the standard collision-probability assumption for high-entropy hash families."
- content-addressable workloads: Systems where data is retrieved or managed by content hashes rather than locations. "GogetaFS and Tidehunter redesign the storage engine for content-addressable workloads."
- content-defined chunking: A chunking method that splits data based on content patterns rather than fixed sizes. "VectorCDC accelerates content-defined chunking using vector instructions."
- Data Streaming Accelerator: A hardware engine (e.g., Intel DSA) that accelerates data movement and comparison tasks. "Para-ksm offloads byte-exact memory-page comparison to a Data Streaming Accelerator."
- deterministic byte-verification fallback: A guaranteed exact byte-by-byte check performed when a hash collision is suspected. "paired with a deterministic byte-verification fallback on collision"
- equivalence relation: A relation that is reflexive, symmetric, and transitive; here, equality of byte sequences. "Define the byte-exact equivalence relation"
- family-wise error rate: The probability of making one or more false discoveries across a family of tests. "Bonferroni correction is applied for family-wise error rate at alpha / N_cells."
- fingerprint primitive: A hashing function used to generate a compact, high-entropy identifier of data. "a high-entropy, low-collision fingerprint primitive"
- first-occurrence order: The preservation of the original input order by keeping the first instance of each duplicate set. "emission preserving first-occurrence order."
- FreeTSA RFC 3161: A standard for trusted timestamping used to pre-register and verify documents and decisions. "Pre-registration (FreeTSA RFC 3161): Methodology decisions for both companion papers are anchored via FreeTSA RFC 3161."
- GIL (Global Interpreter Lock): A Python interpreter mutex that limits true parallel execution of threads. "A long-running Python daemon faces GIL contention under high QPS"
- Graviton: Amazon’s ARM-based server CPU used for cloud workloads and benchmarking. "which is left for follow-up with access to a Graviton instance."
- high-entropy hash families: Hash function families designed to distribute outputs uniformly, minimizing collision probability. "high-entropy hash families."
- HumanEval-Snowball: A multi-turn coding benchmark variant that accumulates dialogue history. "HumanEval-Snowball with real WildChat dialogue history"
- instruction-cache footprint: The code size and layout characteristics that affect CPU instruction cache usage. "without consuming meaningful memory or instruction-cache footprint."
- instruction-set architecture: The abstract model and set of machine instructions (e.g., x86-64, ARM64) a CPU implements. "operating systems of the same instruction-set architecture"
- inverted index: A data structure that maps terms to the documents containing them, used in information retrieval. "IDEA integrates deduplication metadata into an inverted index."
- L2-aligned memory arena: A memory region aligned to L2 cache boundaries to improve cache performance. "indexing into an L2-aligned memory arena"
- locality-sensitive hashing: A hashing technique that increases the likelihood of similar items colliding to enable near-duplicate detection. "Locality-sensitive hashing over MinHash sketches"
- lock-free deterministic dispatch: A concurrency approach that avoids locks while ensuring predictable task assignment and order. "lock-free deterministic dispatch across workers"
- LongBench: A benchmark suite for long-context tasks evaluating LLM performance on extended inputs. "LongBench paragraph-safe long-document tasks"
- math-equivalence: The property that two implementations produce numerically identical results for the same inputs. "Math-equivalence verified: merlin unique_count equals Python set() unique_count"
- MinHash: A sketching algorithm that estimates set similarity via hashed subset minima. "Locality-sensitive hashing over MinHash sketches"
- OpenRouter: A routing layer that proxies requests to multiple LLM providers for consistent evaluation. "All inference-side measurements are conducted via the OpenRouter routing layer"
- openssl ts -verify: An OpenSSL command that verifies RFC 3161 timestamp tokens. "verifiable offline via openssl\ ts\ -verify."
- paired one-sample t-test: A parametric test comparing mean differences of paired observations against zero. "the paired one-sample t-test on the per-example score difference"
- paired sign-test: A nonparametric test that evaluates the direction of paired differences without assuming normality. "the paired sign-test, which treats each delta as a categorical outcome"
- perplexity: A language modeling metric measuring how well a probability model predicts a sample. "accelerating TTFT by approximately thirty times at preserved perplexity."
- prefill: The initial phase of LLM inference where the model processes the entire prompt before decoding. "prefill compute dominates cost and latency on long-context workloads."
- pre-registration: The practice of timestamping methodology decisions to prevent post hoc changes. "Pre-registration (FreeTSA RFC 3161): Methodology decisions for both companion papers are anchored via FreeTSA RFC 3161."
- prompt assembler: The component that constructs the final prompt from retrieved or historical context. "between the retriever (or, in multi-turn settings, the prior-history accumulator) and the prompt assembler"
- prompt caching: A mechanism where identical prompts are cached to avoid recomputation. "Vendor prompt caching"
- quotient map: A mapping from elements to their equivalence classes in a quotient space. "if pi: C â C / equiv_B is the quotient map"
- RAG (Retrieval-Augmented Generation): An approach that augments generation with retrieved external context. "The companion paper extends the panel-validated safety claim to substantial byte removal on the RAG retrieval mechanism"
- redundancy multiplicity (ρ): The ratio of total items to unique items after deduplication, indicating duplication level. "The redundancy multiplicity is"
- REFRAG: A method replacing tokens with compressed embeddings to speed up inference while maintaining quality. "REFRAG replaces tokens with pre-computed compressed chunk embeddings"
- RULER: A benchmark for evaluating long-context retrieval performance. "RULER long-context retrieval"
- semantic-similarity criteria: Methods that deduplicate or cluster based on meaning rather than exact byte equality. "SemDeDup and D4 applied semantic-similarity criteria."
- SHA-256: A cryptographic hash function producing 256-bit digests used for integrity verification. "SHA-256 5575836967fe1a149b63a7fa63a1b3d11d598fb71343e2e19a546e680f4a3294"
- shingle granularity: The size of subsequences (shingles) used in approximate deduplication or similarity detection. "This relation admits no parameter tuning, no shingle granularity"
- statically linked: A binary that includes all necessary libraries at compile time, avoiding runtime dependencies. "both statically linked."
- subprocess invocation overhead: The additional time cost incurred when launching a separate process to perform work. "Subprocess invocation overhead."
- Time to First Token (TTFT): The latency from request start to the first generated token in LLM inference. "accelerating TTFT by approximately thirty times"
- upper confidence limit (UCL): The upper bound of a confidence interval, here for Wilson intervals on proportions. "post-audit UCLs 1.90\%-4.34\%"
- UUID: Universally Unique Identifier, often used as random identifiers in datasets. "approximately zero percent on RULER's UUID-based haystacks"
- warm binary: A process that has been initialized and cached for repeated use, reducing startup overhead. "a separate two-hundred-cell pipeline confirmation pass using a warm binary"
- Wilson 95% confidence intervals: Proportion confidence intervals using Wilson’s method, offering better coverage than normal approximations. "We use Wilson 95\% confidence intervals for proportion-based scores"
- zero-allocation hot paths: Performance-critical code paths designed to avoid dynamic memory allocations. "indexing into an L2-aligned memory arena with zero-allocation hot paths"
Collections
Sign up for free to add this paper to one or more collections.