- The paper demonstrates that standard evaluation protocols penalize retrievers by neglecting semantic redundancy in high-similarity corpora.
- It introduces RARE, a modular pipeline that combines atomic fact extraction, redundancy tracking, and CRRF-based multi-criteria ranking for robust analysis.
- Experiments reveal dense retrievers outperform sparse models in low-overlap settings, with performance declining as document similarity increases.
RARE: Redundancy-Aware Retrieval Evaluation Framework for High-Similarity Corpora
Motivation and Context
Traditional QA benchmarks are constructed upon corpora with minimal inter-document overlap, promoting clear answer–passage mappings and tractable evaluation. However, retrieval-augmented generation (RAG) systems in enterprise contexts operate over large, highly redundant corpora—such as financial reports, legal codes, and patents—where semantic information is duplicated across documents. The paper "RARE: Redundancy-Aware Retrieval Evaluation Framework for High-Similarity Corpora" (2604.19047) substantiates that standard evaluation protocols fail to account for redundancy, thereby penalizing retrievers that surface semantically correct but non-canonical evidence. Moreover, retrievers tuned for low-overlap settings generalize poorly under real-world corpus conditions characterized by substantial similarity and redundancy.
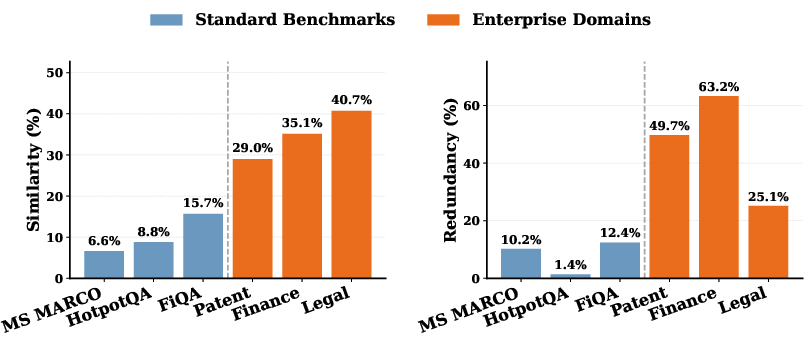
Figure 1: Similarity and redundancy statistics across domains; enterprise corpora exhibit markedly higher values than standard QA benchmarks.
RARE Framework Architecture
RARE offers a modular pipeline comprising three principal stages: Valid Information Selection, Redundancy Tracking, and Question–Answer Generation. Atomic granularity is achieved via LLM-based extraction, splitting passages into minimal factual units. Validity filtering eliminates incomplete, trivial, or meta-information, while multi-criteria ranking (validity, completeness, specificity, clarity, questionability) via CRRF (Criterion-wise Prompting with Reciprocal Rank Fusion) stabilizes the selection of information units.
Redundancy tracking is accomplished in two steps: (i) embedding-based candidate retrieval using cosine similarity, and (ii) LLM-based verification to establish factual equivalence between candidate units. This dual-stage approach yields high recall and precision by dissipating semantic similarity ambiguity and leveraging atomic units for tractable equivalence judgments.
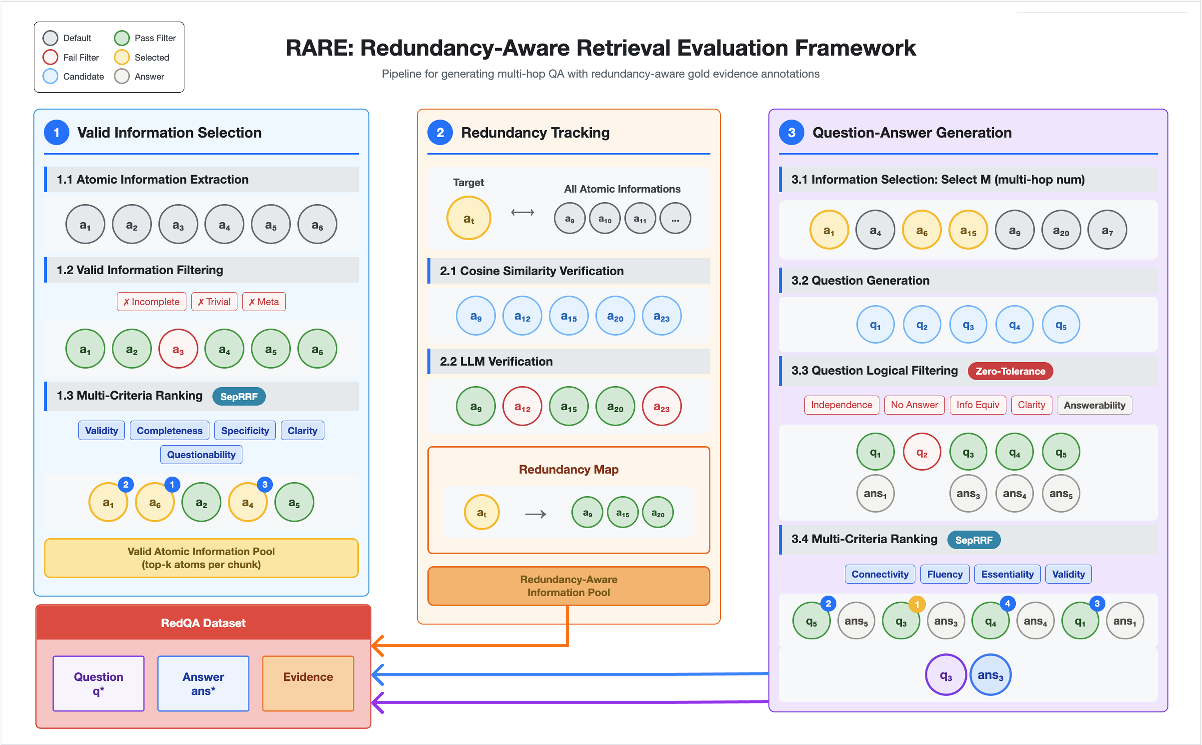
Figure 2: End-to-end RARE workflow—valid information selection, redundancy tracking, and question–answer generation, with CRRF stabilizing judgments and redundancy-aware labeling.
Candidate questions are generated by combining atomic units into reasoning chains. Strict logical filtering applies five zero-tolerance criteria—contextual independence, answer exclusion, information equivalence, question clarity, and answerability—ensuring that only logically valid questions are retained. The ranking of candidate questions again leverages CRRF for robust selection.

Figure 3: Examples of filtering and ranking criteria in RARE; includes atomic information validity, completeness, logical checks for question answerability, and connectivity.
Benchmark Construction and Dataset Composition
RARE's deployment yields RedQA, a benchmark suite spanning Finance (SEC 10-K), Legal (U.S. Code), Patent (USPTO technical areas), and General-Wiki (Wikipedia as a low-overlap baseline). Corpora are chunked into 512-token segments with atomic facts extracted and ranked. Redundancy and similarity metrics are computed per domain, confirming extensive overlap in enterprise data.
Human validation on filtering stages demonstrates high recall (89.6% and 83.6%) and moderate precision (57.5% and 50.8%), favoring exclusion of ambiguous or logically flawed questions to maintain benchmark integrity.
Experimental Analysis on Retrieval and Multi-Hop QA
Nine retrievers are evaluated: BM25 (sparse), embedding-based dense models (E5-Large, BGE-M3, Jina-v4, Qwen3-Embedding variants), and LLM-derived embeddings (E5-Mistral, Qwen3). PerfRecall@10 and Coverage@10 are principal metrics, calculated with redundancy-aware labeling.
Dense retrievers exhibit clear superiority over sparse alternatives in low-overlap domains, but the performance gap contracts in high-overlap corpora. Scaling yields incremental gains, yet even top models (Qwen3-8B) attain only 41.5% PerfRecall@10 on Legal and 8.5% on Finance at 4-hop depth; in contrast, General-Wiki maintains 66.4% at 4-hop.
Analysis reveals that document similarity exacerbates retrieval confusion and performance degradation, while redundancy may furnish alternative evidential pathways. PerfRecall@10 decreases monotonically with similarity, but redundancy produces a weaker, non-monotonic effect.
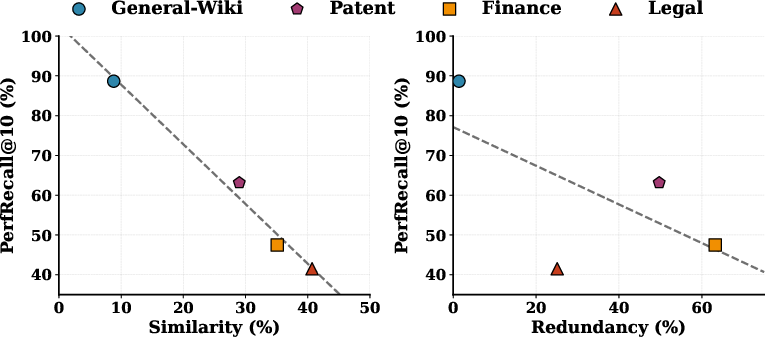
Figure 4: PerfRecall@10 for Qwen3-8B decreases with similarity, while redundancy induces less pronounced association.
Performance degrades sharply with hop depth in high-overlap domains, with General-Wiki exhibiting resilience. Overlap induces evidence bottlenecks wherein retrievers recycle near-duplicate facts instead of assembling complementary chains, intensifying compositional retrieval difficulty.
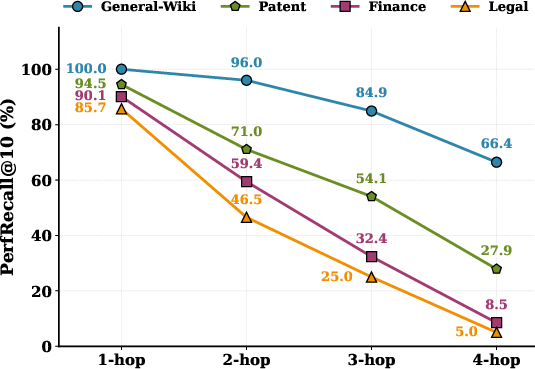
Figure 5: PerfRecall@10 degradation with hop depth is most prominent in high-overlap domains, revealing multi-hop bottlenecks.
CRRF: Robust Multi-Criteria Ranking in LLMs
CRRF decouples criterion evaluation via separate prompts and rank fusion, eschewing poorly calibrated confidence scores in favor of robust ordinal aggregation. Ablation studies demonstrate that Separate+RRF prompting consistently outperforms holistic or score-based aggregation, both in mean NDCG@3 and stability metrics.
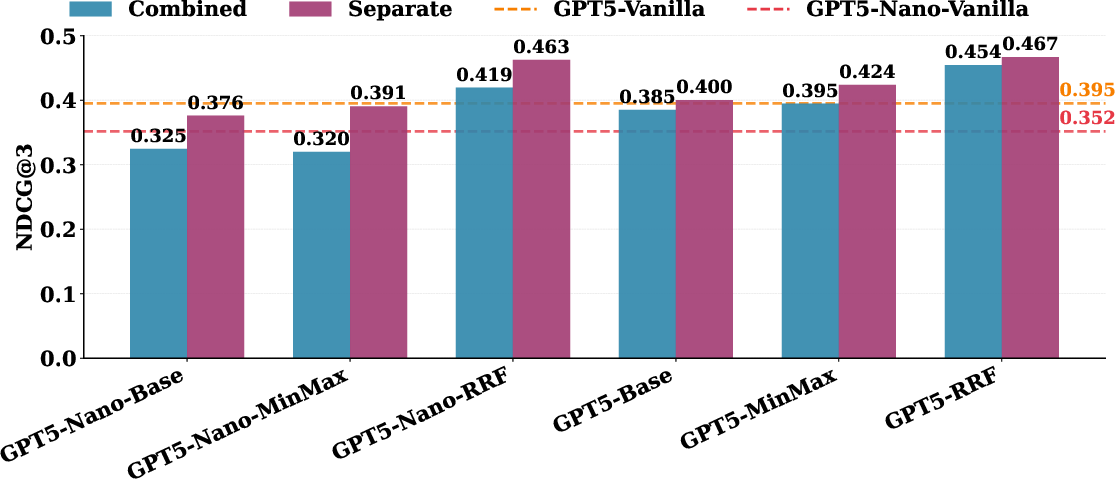
Figure 6: CRRF achieves superior NDCG@3 for multi-criterion ranking under both GPT-5 Nano and GPT-5; rank fusion is more reliable than score-based aggregation.
End-to-End RAG Evaluation: Retrieval, Utility, and Parametric Knowledge
An end-to-end analysis dissects accuracy into coverage types—retrieval-only, parametric-only, complementary, and intersection. RAG gain grows with reduced parametric retention, especially in enterprise domains. Utilization bottlenecks in patents highlight the generator's challenges in exploiting retrieved context. Retrieval quality dominates final correctness; missing evidence overwhelmingly limits answer quality.
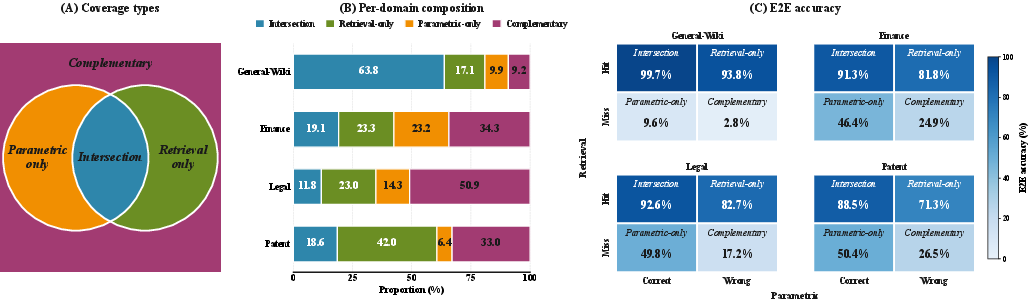
Figure 7: Decomposition of end-to-end accuracy demonstrates retrieval and parametric gains, revealing context utilization bottlenecks and complementary signal fusion.
Implications and Future Directions
RARE elucidates that high-similarity and high-redundancy corpora found in enterprise RAG scenarios pose significantly greater retrieval challenges than standard QA benchmarks capture. Evaluations that neglect redundancy penalize retrievers and fail to reflect true robustness. The modular atomic decomposition enables precise tracking and fair assessment of alternative evidence, while CRRF provides stable multi-criteria quality control for LLM-generated benchmarks.
These findings underscore the necessity of domain-specific retrieval benchmarks with redundancy-aware gold labeling for deployment-grade evaluation. Future directions include optimizing redundancy thresholds per domain, exploring graph-based evidence connectivity modeling for more natural multi-hop chains, and extending CRRF generalization to other tasks and granularities.
Conclusion
RARE delivers a comprehensive framework integrating atomic fact decomposition, systematic redundancy tracking, and stable multi-criteria LLM evaluation for constructing realistic retrieval benchmarks in high-similarity corpora. Application to Finance, Legal, and Patent domains via RedQA reveals substantial robustness gaps missed by current QA benchmarks, with similarity correlating strongly to performance decay. The theoretical and practical ramifications point to the urgent need for redundancy-aware protocols in retrieval evaluation, especially for enterprise deployment scenarios.