- The paper demonstrates that autonomous specialist agents improve training pipelines through empirical methods, yielding non-trivial recipe enhancements.
- Key improvements include significant performance increases in Parameter Golf, NanoChat-D12, and CIFAR-10 Airbench96, verified under strict budget and metrics.
- The specialist agent system allows for continuous, automated empirical research, transforming failure feedback into subsequent code-level enhancements.
Auto Research via Specialist Agents: Empirical Exploration of Training Recipe Optimization
Introduction
The paper "Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes" (2605.05724) investigates automated empirical ML research by instantiating a closed-loop system of specialist language agents. These agents autonomously propose code-level changes to training pipelines, leveraging measured feedback from external evaluators to iteratively refine their hypotheses and edits. The output of the system is a complete, auditable trajectory of experimentation—proposals, code modifications, external measurements, and lineage of feedback—rather than a static report or a singular model artifact.
The methodology is evaluated across three distinct environments—Parameter Golf, NanoChat-D12, and CIFAR-10 Airbench96—each characterized by different practical compute and evaluation constraints. The primary contribution is a demonstration that, under real-world measurement and audit constraints, specialist agent-based closed loops can not only compose and transfer known techniques effectively but also generate non-trivial code-level recipe improvements in a fully autonomous manner. The performance gains are externally validated with rigorous budget, size, and metric constraints.
Closed Empirical Loop with Specialist Agents
The central mechanism of the approach is a proposal-measure-revise loop tightly interwoven with lineage tracking and role specialization.
- Submitted Trial Loop: Each trial comprises a concrete hypothesis, an executable code edit, submission to an external evaluation harness, and a feedback signal (measurement or failure diagnostic). Agents do not receive human guidance post-launch.
- Lineage Feedback: Cross-trial state (hypotheses, diffs, scores, failures) is persistently tracked, allowing agents to incorporate not only direct successes but also boundary feedback—such as size, crash, or constraint failures—into subsequent proposals.
- Specialist Partitioning: The editable recipe surface is divided by specialist roles (e.g., architecture, optimizer, regularization), with each agent domain-constrained but operating over a shared lineage. This is crucial for proposal diversity and effective exploration of complex, constraint-dominated search spaces.
This process is depicted in (Figure 1).
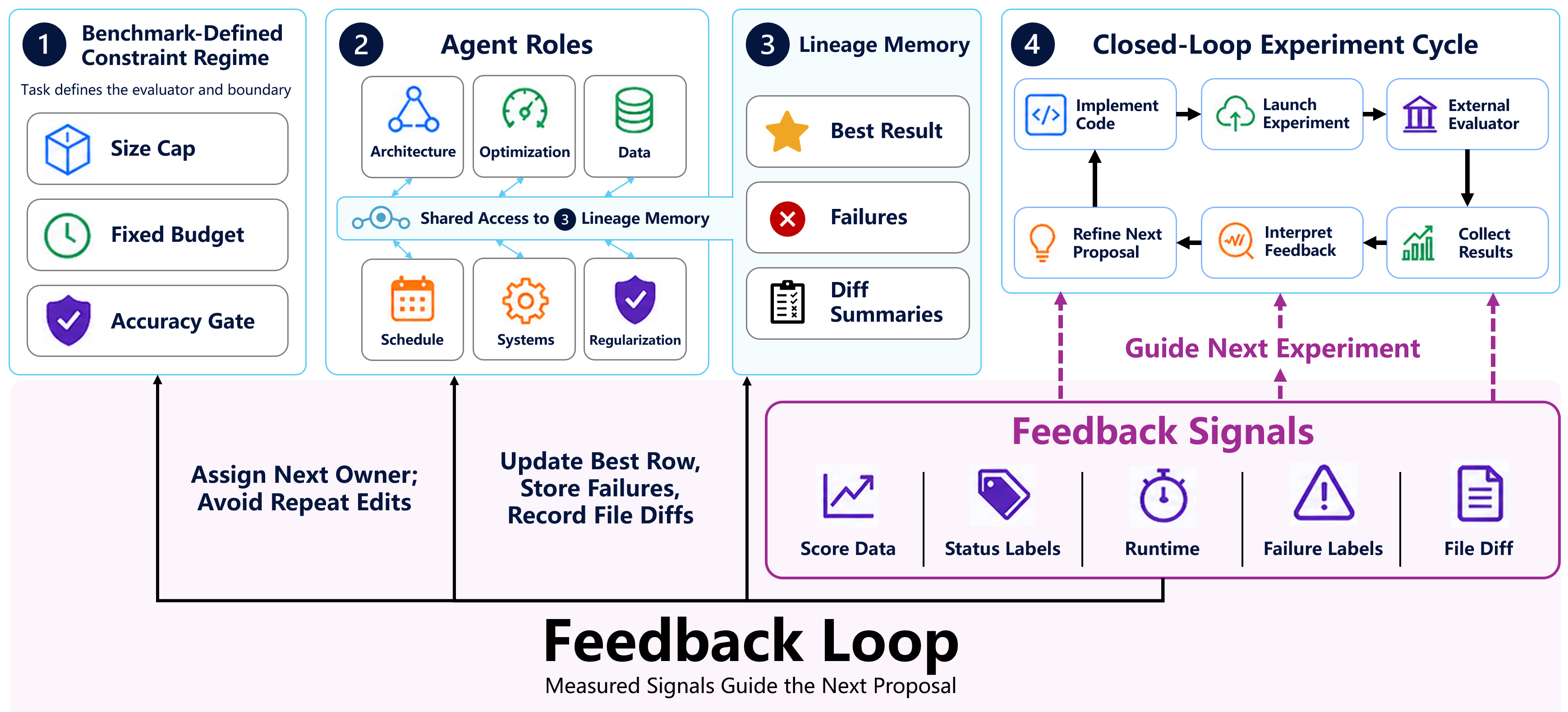
Figure 1: The closed-loop auto research trajectory links proposals, code edits, external evaluator feedback, and iterative lineage, facilitating continual programmatic recipe refinement.
Experimental Environments and Evaluation Protocol
Three environments were selected for their complementary constraint structure and measurement boundaries:
- Parameter Golf: Focuses on minimizing validation bits-per-byte (bpb) under hard artifact size (≤16MB) and compute constraints on FineWeb data.
- NanoChat-D12: Targets maximization of the CORE metric in strict-budget nanochat pretraining, with wallclock/runtime bottlenecks forming dominant constraints.
- CIFAR-10 Airbench96: Optimizes wallclock training time with an accuracy gate (>0.96), where near-misses provide actionable speed-accuracy feedback.
All environments employ external, harness-owned evaluation (no agent-editable metric reporting), strict budget enforcement, and trace logging. Baselines and denominators are calibrated via append-only protocol runs to ensure comparability and reproducibility.
Empirical Results
Recipe-Level Improvements
The auto-research system executed 1,197 headline-run trials (900 Parameter Golf, 200 NanoChat-D12, 97 CIFAR-10), plus control runs. Across environments, the agent loop achieved externally validated improvements:
- Parameter Golf: 0.81% bpb reduction over public SOTA (from 1.0810 to 1.0722)
- NanoChat-D12: 38.7% CORE increase (from 0.1618 to 0.2244)
- CIFAR-10 Airbench96: 4.59% wallclock reduction (from 26.3560s to 25.1464s), while satisfying accuracy gate
Score progressions are shown in (Figure 2).
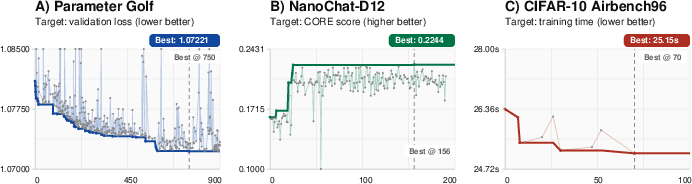
Figure 2: Best-so-far score trajectory for valid measured trials; ineligible trials are omitted, with the bold line tracking the running best.
Autonomously, agents composed program-level changes beyond classical HPO, exemplified by structural edits such as attention-path rewrites, quantization protocol changes, and schedule reconfiguration. Approximately 13.1% of submitted trials represent architecture-surface modifications, serving as a lower bound on non-scalar, program-level contributions.
Specialist Partitioning and Search Dynamics
Specialist roles ensure coverage and effective partitioning of the edit space. Each environment sets its own specialist taxonomy (10 roles in Parameter Golf; 5 in NanoChat-D12 and CIFAR-10), with evidence for diverse search and outcome distributions:
- Specialist role allocation remains balanced (Coefficient of Variation < 0.10 across tasks), with all roles contributing valid improvements.
- The role-partitioned, lineage-sharing organization yields greater effective proposal diversity and runtime throughput versus generalist or generic multi-agent controls. This is visualized by the agent partitioning and search patterns (Figure 3) and the normalized outcome profiles per role (Figure 4).
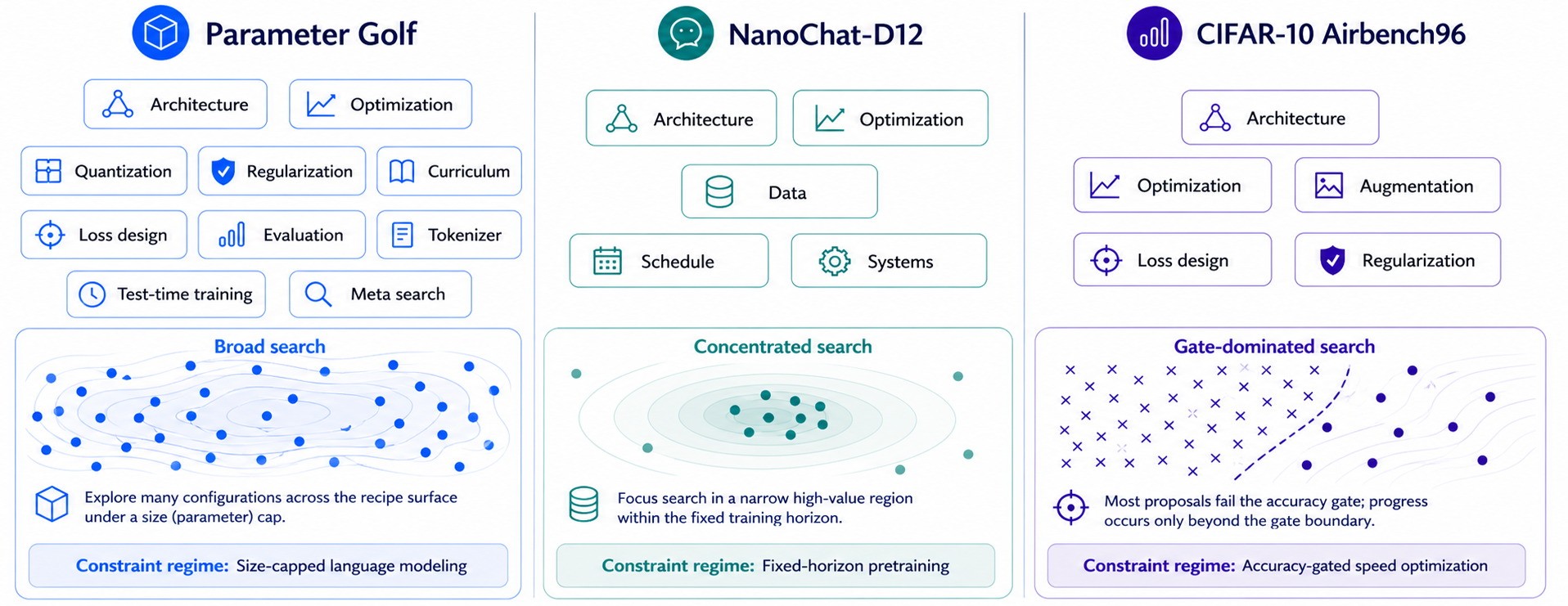
Figure 3: Partitioning and search trajectories for specialist roles across environments, with each regime highlighting different proposal and search patterns.
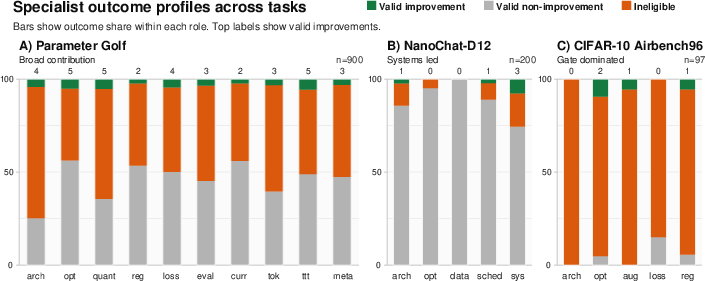
Figure 4: Specialist outcome profiles: green for valid improvements, orange for constraint-violating/ineligible, gray for non-improvements, normalized within each role.
Mechanism Dissection: Lineage, Diversity, and Feedback
Ablation studies and proposal-entropy audits substantiate several key claims:
- Lineage Feedback Essentiality: Removing cross-trial lineage collapses valid improvement count (Parameter Golf: from 16 to 3 by trial 200), increases the frequency of constraint collisions (e.g., size cap), and reduces search breadth. Lineage feedback is necessary for transforming measured boundaries and failures into subsequent program-level edits.
- Proposal Diversity and Boundary Discipline: Role-partitioning ensures specialists do not exhaustively retread local optima, resulting in higher evaluator-facing proposal entropy and lower near-duplicate rates compared to non-partitioned controls.
- Failure as Evidence: The system leverages explicit constraint violation and crash feedback. For instance, size-blocked z-loss trials prompt subsequent edits to recover artifact headroom; near-miss accuracy gate failures guide targeted repair proposals.
Developed Recipes: Component Analysis
The system-generated final recipes are complex, involving non-trivial code and protocol-level changes synthesized across trials, as depicted in Figures 11–13.
- Parameter Golf: Integrates test-time training (TTT)-only z-loss applied during evaluation adaptation, per-head attention output gating, recurrent residual scaling, quantization protocol rewrite (GPTQ/Hessian), and schedule separation. See (Figure 5).
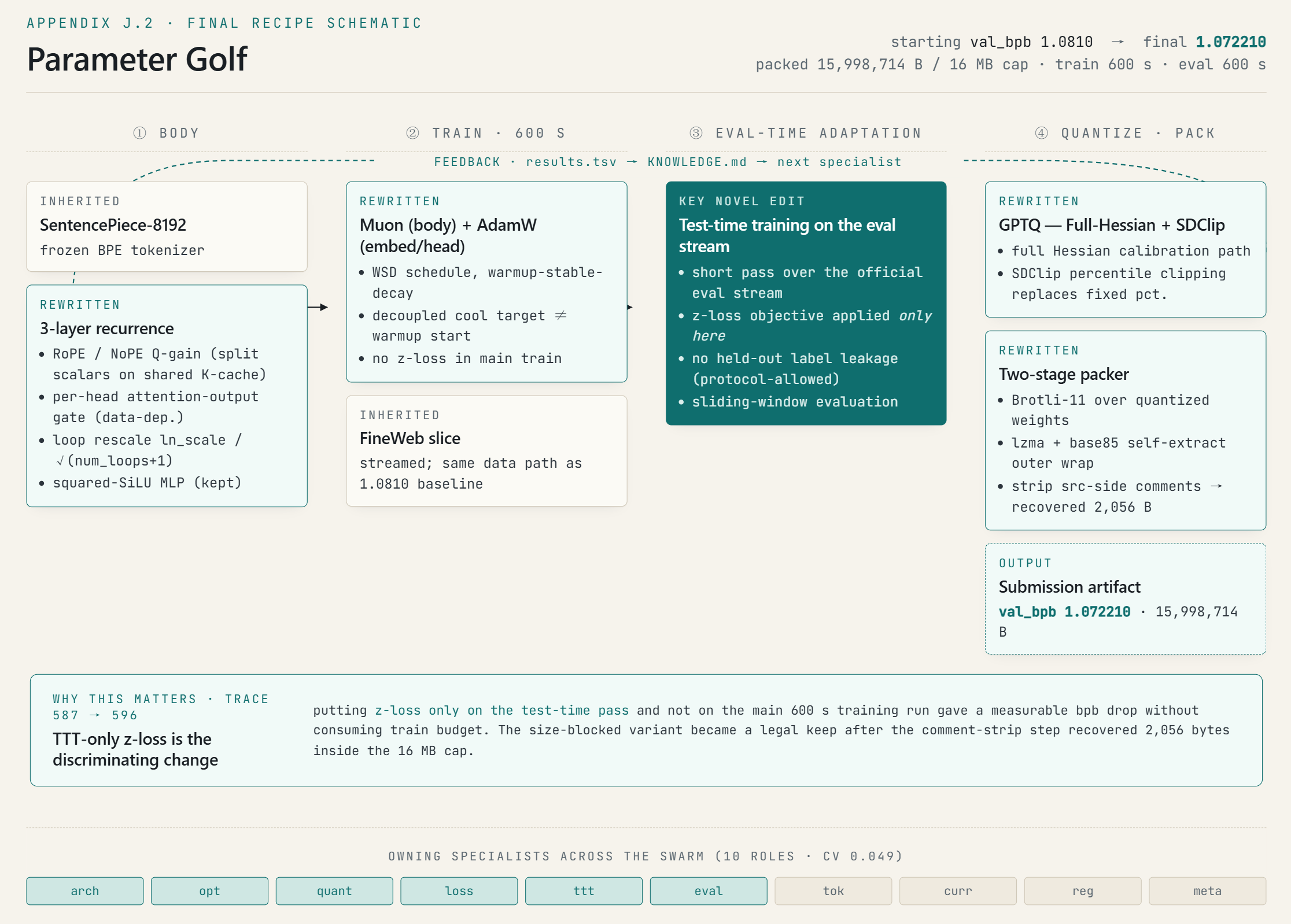
Figure 5: Schematic of the Parameter Golf final recipe, highlighting inherited and agent-rewritten components, lineage integration, and artifact boundaries.
- NanoChat-D12: Completely overhauls the attention path from SSSL to all-layer Flash SDPA, expands training data ratio under strict wallclock, and introduces a learnable logit-bias vector. Feedback cycles from runtime optimization to longer token schedules to final metric improvement. See (Figure 6).

Figure 6: Schematic of the NanoChat-D12 final recipe showing attention path rewrite, extended data ratios, and feedback-driven schedule improvements.
- CIFAR-10 Airbench96: Implements a minimal-logging speed recipe, shortened horizon, increased learning-rate intensity, and warmup repair for recovery of the accuracy margin, transforming gate-failure evidence into valid speedup mechanisms. See (Figure 7).
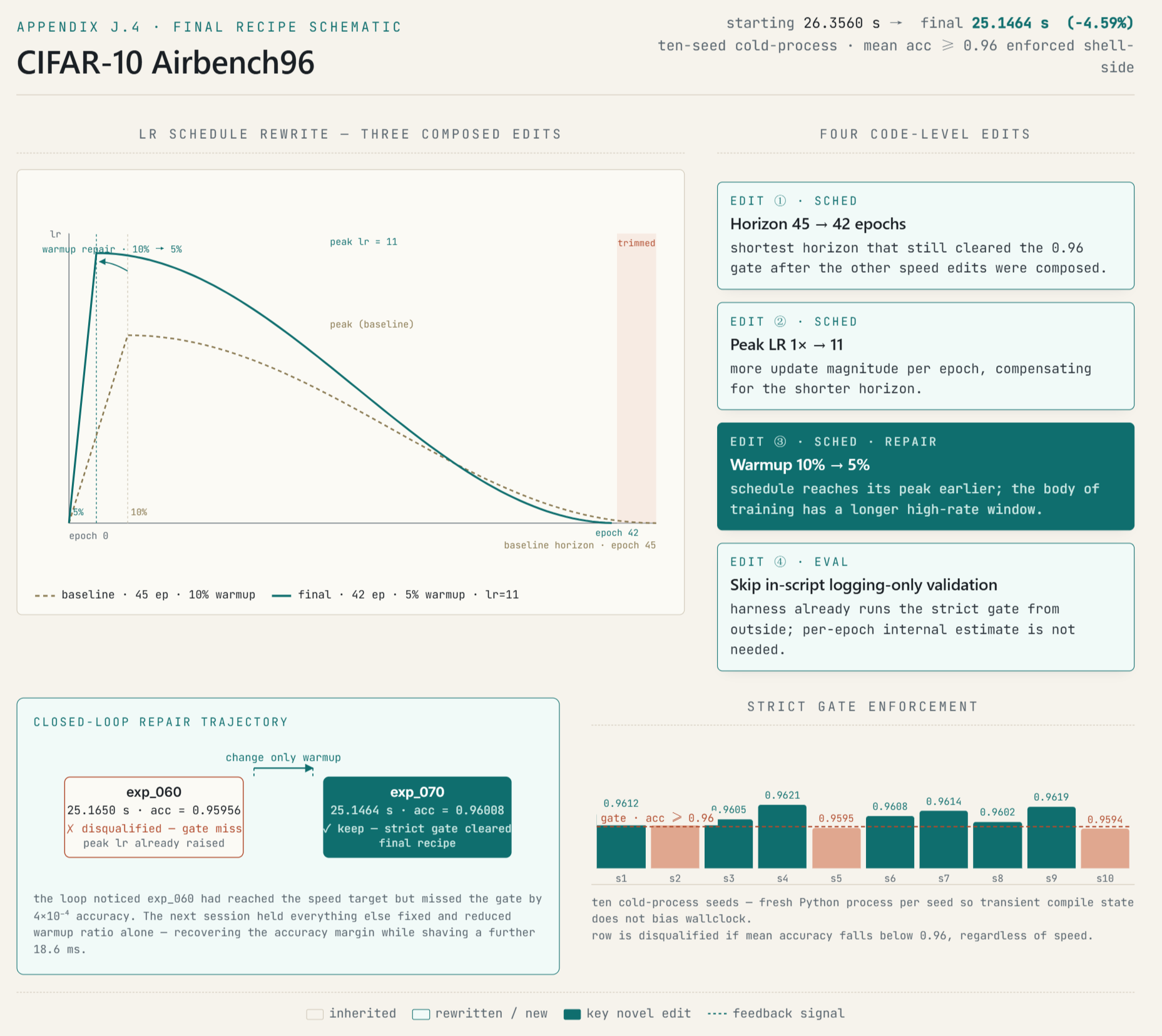
Figure 7: Schematic of the CIFAR-10 final recipe, mapping schedule and optimization changes directly onto the constraint-dominated feedback loop.
Theoretical and Practical Implications
The research formalizes auto research not as static narrative generation but as an empirical system design: a sustained, auditable loop wherein agents produce, test, and refine code-level hypotheses using only the evidence admitted by externally fixed evaluators. The following theoretical insights emerge:
- Evaluator Ownership: Decoupling metric computation from the editable code path enforces genuine empirical rigor and precludes reward gaming.
- Closed-Loop Memory and Auditability: Complete lineage logs support post hoc analysis and reproduction, enabling replicable empirical science and clear traceability of research decisions and outcomes.
- Scalable Closed-Loop Research: Parallel role-partitioned submission scales with near-linear efficiency until resource contention, facilitating feasible exploration over large empirical surfaces.
Practically, this shows that frontier LLMs, when equipped with domain specialization and lineage feedback, can contribute substantial, multifaceted improvements to training recipes fully autonomously—without human intervention during search. The methods and code artifacts are designed for public release and replication in other empirical contexts.
Limitations and Future Directions
Within the investigated horizon, agent-driven improvements are compositional rather than paradigm-level (i.e., no evidence of radical architectural invention). The loop is most effective in settings where failures provide compact, actionable feedback, and total iteration cost is within manageable budgets. Extension to longer-horizon or higher-cost domains (e.g., larger vision/LLMs, reinforcement learning pipelines) will require both enhanced agent reasoning and optimized resource management, potentially benefiting from more explicit cross-role composition and ablation mechanisms.
As future LLMs become more capable, the same closed empirical loop provides both a scalable research accelerator and a robust audit trail for paradigm-shifting modifications or new algorithmic directions.
Conclusion
This paper robustly demonstrates that auto research instantiated as a closed feedback loop with specialist language agents and lineage propagation is a practical, measurable, and interpretable paradigm for training recipe optimization. It enables externally validated, auditable, and non-trivial code- and protocol-level improvements—scaling empirical research beyond static reporting toward continuous, automated, and inspectable empirical science. The framework and insights generalize to other measurement-owning empirical domains as long as results and constraints are externally verifiable and per-trial cost permits tractable iteration.
Reference:
"Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes" (2605.05724)

