Scientific Algorithm Discovery by Augmenting AlphaEvolve with Deep Research
Abstract: LLMs hold promise as scientific assistants, yet existing agents either rely solely on algorithm evolution or on deep research in isolation, both of which face critical limitations. Pure algorithm evolution, as in AlphaEvolve, depends only on the internal knowledge of LLMs and quickly plateaus in complex domains, while pure deep research proposes ideas without validation, resulting in unrealistic or unimplementable solutions. We present DeepEvolve, an agent that integrates deep research with algorithm evolution, uniting external knowledge retrieval, cross-file code editing, and systematic debugging under a feedback-driven iterative loop. Each iteration not only proposes new hypotheses but also refines, implements, and tests them, avoiding both shallow improvements and unproductive over-refinements. Across nine benchmarks in chemistry, mathematics, biology, materials, and patents, DeepEvolve consistently improves the initial algorithm, producing executable new algorithms with sustained gains. By bridging the gap between unguided evolution and research without grounding, DeepEvolve provides a reliable framework for advancing scientific algorithm discovery. Our code is available at https://github.com/liugangcode/deepevolve.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeepEvolve, an AI “assistant” that helps discover better scientific algorithms. Think of it as a smart teammate that doesn’t just come up with ideas, but also looks things up, writes code across a whole project, fixes errors, tests what it built, and then improves it over and over. It’s designed to avoid two common problems:
- Only “evolving” code from what the AI already knows (which quickly gets stuck).
- Only doing “deep research” online (which can suggest cool ideas that don’t actually work in code).
DeepEvolve combines both, so ideas are grounded in real knowledge and also turned into working programs that are tested and improved.
What questions does the paper try to answer?
The authors wanted to know three things:
- Can this combined approach (deep research + code evolution) actually create better algorithms across different fields?
- How do the research and coding parts help each other during the process?
- Which parts of the system matter most (like debugging, multi-file coding, or the research steps)?
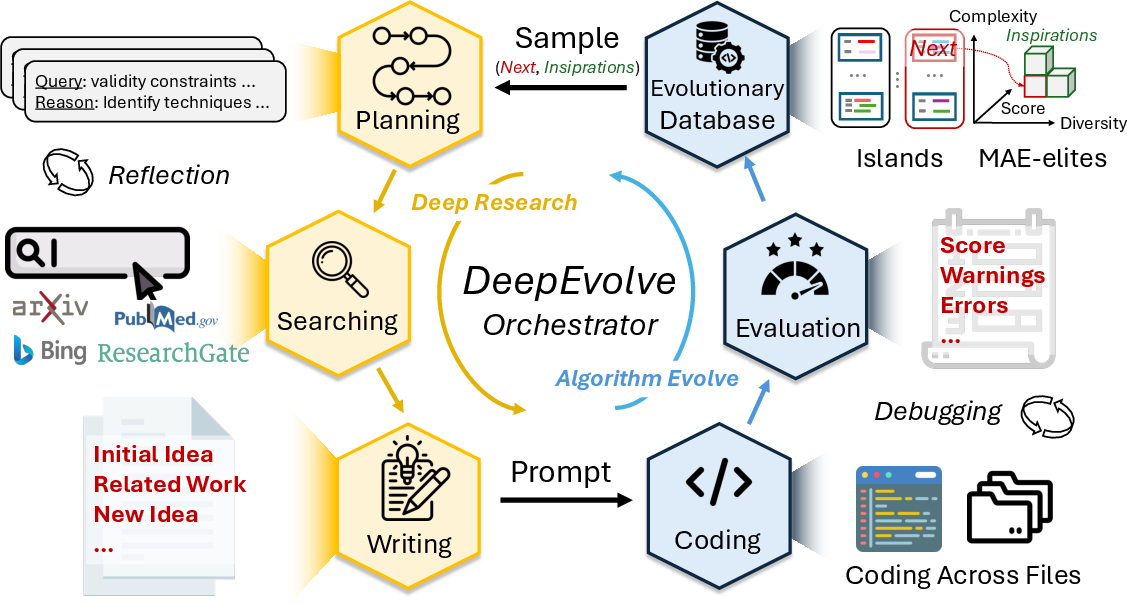
How does DeepEvolve work?
Imagine a science fair team that repeats this cycle: ask questions → research → propose a plan → build → test → keep the best parts. DeepEvolve follows a similar loop, but for algorithms and code.
Here’s the loop in everyday terms:
- Plan: Decide the next research questions to explore (e.g., “What methods work best for this kind of data?”).
- Search: Look up trustworthy sources online (like scientific papers and reputable sites) and summarize what’s useful.
- Write: Propose a new idea for improving the algorithm and include simple pseudo-code (a step-by-step plan).
- Code: Edit the actual project, even if it has many files (like changing a model file, a data file, and a training script).
- Debug: If the code fails, use error messages to fix it automatically within a few tries.
- Evaluate and Select: Run the algorithm, score it, save it, and choose what to try next in a smart way that balances “best so far” and “let’s explore something different.”
Why this works:
- “Pure evolution” (only tweaking code based on internal knowledge) often hits a plateau.
- “Pure deep research” (only reading and brainstorming) can produce ideas that are too hard or vague to implement.
- The combo makes sure ideas are both informed and executable, and the testing provides feedback to get better each round.
A simple analogy:
- DeepEvolve is like having a researcher (finds ideas), an engineer (writes and edits multi-file code), a tester (runs and scores it), and a coach (chooses what to try next) all working together in a loop.
What did they test, and what did they find?
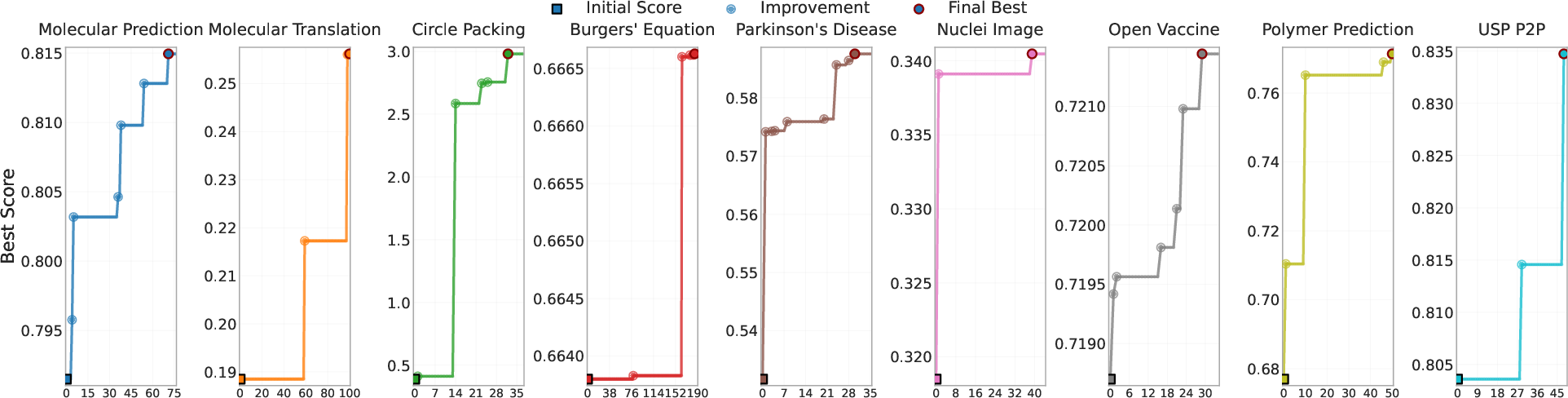
They tried DeepEvolve on nine different problems in chemistry, math, biology, materials science, and patents. Examples include:
- Predicting molecule properties (chemistry)
- Translating molecule images into text descriptions
- Packing circles inside a square (math puzzle)
- Solving a physics equation (Burgers’ equation)
- Predicting Parkinson’s disease progression (biology)
- Segmenting cell nuclei in images
- Predicting mRNA stability
- Predicting polymer properties (materials)
- Matching phrases in patents (text)
Main results:
- DeepEvolve usually beat the starting (baseline) algorithms and kept making progress with more iterations.
- In some tasks, improvements were modest (because the baseline was already very strong, or time limits were tight).
- In others, the gains were big. For example, in the circle packing problem, it jumped from a poor, inflexible approach to a method that worked across many cases, leading to a huge score increase.
- The debugging step mattered a lot: it turned many “this idea fails to run” cases into successfully tested algorithms, raising the success rate dramatically in multiple tasks.
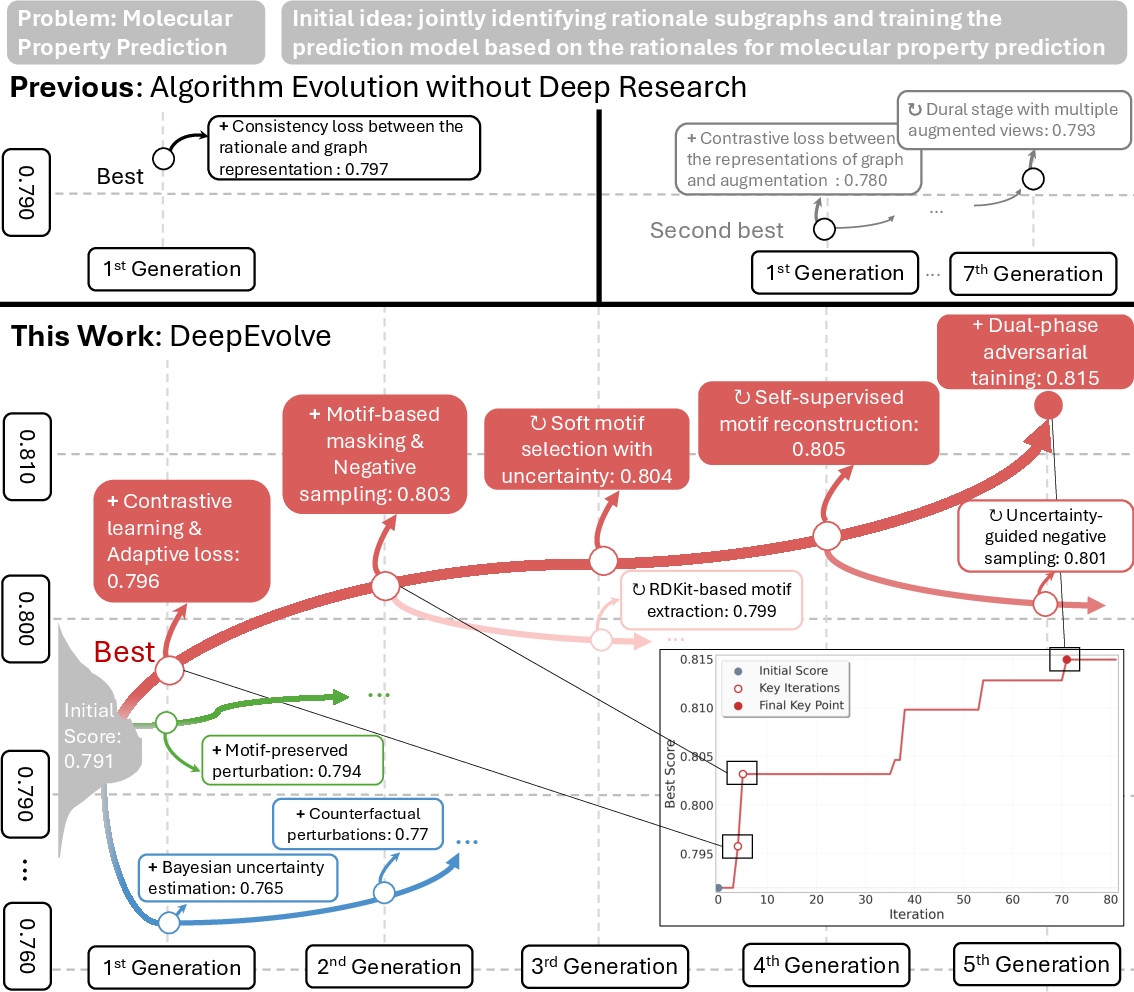
- The research part steered the system toward smarter, domain-aware ideas (like using chemical “motifs” in molecules or special time-series models for disease data), not just quick fixes.
- Over time, the system moved from simple tweaks to more principled methods (for example, adding physics-aware rules or optimization strategies).
Why this is important:
- The system didn’t just chase random improvements. It made noticeable, meaningful jumps at key steps, often by adopting better-informed ideas and implementing them correctly.
Why does this matter?
- It speeds up scientific algorithm discovery: Instead of only brainstorming or only tinkering, DeepEvolve does both in a grounded, test-and-learn loop.
- It handles real-world code: Many projects have multiple files and hidden bugs. DeepEvolve edits across files and debugs automatically.
- It generalizes: The same framework worked across very different areas—math puzzles, chemistry data, medical predictions, and more.
- It’s a step toward reliable AI “co-scientists”: systems that can read, reason, build, test, and improve without drifting into unrealistic ideas.
Bottom line
DeepEvolve shows that combining deep research (to find smart, evidence-based ideas) with careful code evolution (to build, test, and fix those ideas) can steadily discover better scientific algorithms. This approach makes AI assistants more trustworthy and useful for real scientific work, helping humans push forward in fields like chemistry, biology, and math.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain after this work and that future researchers could act on:
- External validity across stronger baselines: No head-to-head comparisons against state-of-the-art agent systems (e.g., AlphaEvolve with official code, FunSearch variants, Paper2Code/AutoP2C pipelines augmented with evaluators), or human experts under matched compute/time budgets.
- Statistical rigor and robustness: Improvements are reported mostly once per task without repeated trials, confidence intervals, or statistical tests; sensitivity to random seeds, dataset splits, and evaluation noise remains unknown.
- Generalization vs. overfitting to the evaluator: Iterative selection on the same evaluation datasets risks overfitting to scoring scripts; there is no unseen holdout, cross-task generalization test, or adversarial evaluation to ensure robustness.
- Metric design and potential gaming: The “new score” transformations (e.g., combined AUC mean/std, inverted error metrics) are not justified or stress-tested; potential for metric gaming or unintended optimization behaviors is unaddressed.
- Multi-objective optimization is ad hoc: Efficiency is “included in the prompt” but not optimized with principled multi-objective methods (e.g., Pareto-front selection); trade-offs between accuracy, runtime, and memory are not systematically explored.
- Compute and scalability limits: The 30-minute, single-GPU constraint may bias the search toward short-horizon gains; scalability to longer training loops, multi-GPU/HPC settings, or larger-scale scientific problems is untested.
- Cost and carbon accounting: Token/compute costs of planning, search, coding, and debugging loops are not measured; no analysis of cost-performance trade-offs or environmental footprint.
- Retrieval reliability and reproducibility: Web retrieval lacks snapshotting, versioning, or provenance guarantees; results may be irreproducible as web content changes, and there is no mechanism to cache, cite, or verify sources.
- Contamination and trustworthiness: No safeguards against data leakage (e.g., Kaggle forum/code leaks) or untrusted sources; defenses against prompt injection, malicious pages, or hallucinated citations are not discussed.
- Contribution attribution: The relative impact of deep research vs. evolutionary selection vs. debugging is not disentangled beyond a single ablation; no causal or variance decomposition to identify which module drives which gains.
- Evolution strategy design space: Island models and MAP-Elites are used without ablations against alternatives (e.g., novelty search, quality diversity variants, different behavior descriptors, selection pressures, or population sizes).
- Memory and knowledge retention: The evolutionary database stores algorithms but not retrieved sources or rationales; there is no study of long-term memory management, forgetting, or cross-task knowledge transfer.
- Debugging scope and limits: While debugging improves success rate, error taxonomies, failure modes, and the trade-off between retry budget and quality are not analyzed; safety limits for automatic code modifications are unspecified.
- Code quality and correctness: Beyond “runs without error,” there is no assessment of code maintainability, unit-test coverage, numerical stability, or correctness beyond the benchmark’s scoring script.
- Cross-file editing reliability: The cross-file code editing mechanism is described conceptually but lacks quantitative evaluation (precision/recall of edits, dependency tracking accuracy, refactoring safety).
- Safety and sandboxing: Security measures for executing LLM-written code (filesystem/network isolation, dependency pinning, supply-chain risk mitigation) are not specified; ethical considerations for autonomous code execution are missing.
- Intellectual property (IP) risks: The system may synthesize code from web-retrieved materials; licensing compliance and plagiarism detection are not addressed.
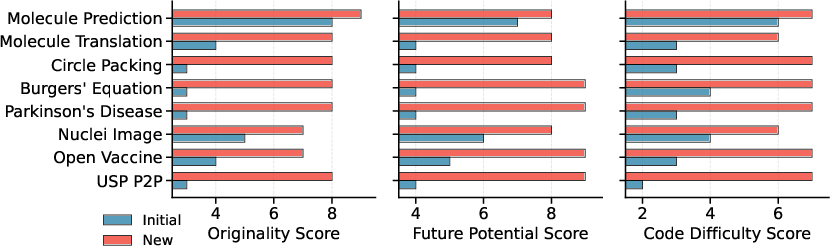
- Bias and subjectivity in idea evaluation: LLM-as-a-judge for originality and potential is subjective, model-dependent, and possibly biased; there is no human expert assessment, inter-rater reliability, or cross-model agreement study.
- Domain depth vs. breadth: Despite nine tasks, domain coverage is shallow per domain; no evaluation on deep, production-scale scientific workloads (e.g., large PDE systems, reaction planning pipelines, or clinical datasets).
- Long-horizon research chains: The agent executes short cycles; it remains unclear how it performs on multi-week pipelines with experiment scheduling, checkpoints, hyperparameter sweeps, and literature tracking over time.
- Theoretical underpinnings: No analysis of convergence properties, sample-efficiency bounds, or conditions under which deep research plus evolution is expected to outperform evolution alone.
- Failure case analysis: Little qualitative analysis of when deep research proposes unimplementable or low-yield ideas, when debugging fails, or when evolution stagnates; no diagnostics to predict/avoid such cases.
- Fairness of baselines: Some initial algorithms are strong (e.g., CodePDE), others are simple competition baselines; normalization of starting points and fairness of comparisons are not ensured.
- Transferability of discovered patterns: The claim that reusable patterns (e.g., uncertainty estimation, adaptive loss) emerge is not validated via cross-task transfer experiments or prospective tests on new benchmarks.
- Parameter sensitivity: Key hyperparameters (search breadth, reflection limits, retry budgets, evolutionary population sizes, MAP-Elites grid choices) are not tuned or analyzed for sensitivity.
- Resource allocation across modules: Time/token budgets across planning, retrieval, coding, and debugging are not optimized or profiled; no adaptive budget allocation strategy is explored.
- Data and environment reproducibility: Precise environment specs, dependency versions, dataset preprocessing, seeds, and exact prompts/checkpoints are not fully documented for end-to-end reproducibility.
- Ethical and societal considerations: No discussion of misuse risks (e.g., generating deceptive “novel” algorithms), transparency of provenance, or guidelines for responsible deployment in scientific workflows.
Practical Applications
Immediate Applications
The following list outlines concrete, deployable use cases that leverage DeepEvolve’s integrated deep research, cross-file code editing, iterative debugging, and evaluation-driven evolution. Each item includes sectors, potential tools/workflows, and key assumptions or dependencies.
- Algorithm Discovery Copilot for R&D — sectors: software, ML engineering, academia
- Use case: Embed DeepEvolve in research groups and ML engineering teams to systematically propose, implement, and test algorithmic improvements on existing codebases and benchmarks (e.g., AUC, RMSE, mAP).
- Tools/workflows: IDE plugin or CLI that runs the plan–search–write–code–debug–evaluate–select loop; maintains an evolutionary database using island-based sampling and MAP-Elites to balance performance, code diversity, and complexity.
- Assumptions/dependencies: Clear, executable evaluation functions; bounded runtimes; access to internet retrieval; sufficient compute (GPU/CPU); secure access to code repositories.
- Scientific Code Refactoring and Multi-file Editor — sectors: software, DevTools
- Use case: Automate cross-file modifications for complex repositories (data preprocessing, model architecture, training loop) while preserving functionality via iterative debugging and self-reflection.
- Tools/workflows: “Cross-file Edit + Debug” assistant integrated into CI; automatic patch proposals grounded by pseudo-code from deep research; failure-driven debugging with capped attempts.
- Assumptions/dependencies: Reliable tests/logging, dependency management (conda/pip), permissioned write access; developer oversight for security and compliance.
- Benchmark Acceleration Services — sectors: academia, software
- Use case: Improve baseline solutions on public benchmarks (e.g., OGB molecules, PDE solvers, image segmentation, patent matching) by running bounded discovery cycles.
- Tools/workflows: One-click “Improve Baseline” pipelines; portfolio of candidate algorithms scored and archived; LLM-as-a-judge for idea quality (originality, potential, difficulty) with human-in-the-loop triage.
- Assumptions/dependencies: Valid datasets/metrics, time budget (e.g., ≤30 minutes per run), transparent reporting of changes and reproducibility artifacts.
- Materials and Polymer Informatics Model Tuning — sectors: materials, energy, manufacturing
- Use case: Evolve models predicting polymer or material properties to boost accuracy or robustness (e.g., motif-aware features, periodicity priors).
- Tools/workflows: Domain-informed deep research (motifs, periodic structures); adaptive loss reweighting; uncertainty estimation modules; archived evolution history for audit.
- Assumptions/dependencies: Quality labeled datasets, domain priors available from literature, compute budget alignment with lab cadence.
- Drug and Molecular Modeling Enhancement — sectors: healthcare, pharma, biotech
- Use case: Integrate motif-aware masking, contrastive learning, and grammar-constrained tokenization to advance molecular property prediction and molecular translation pipelines.
- Tools/workflows: Literature-informed proposals (PubMed/arXiv retrieval); modular graph ML code edits; uncertainty-guided rationale selection; validation against held-out assays or tasks.
- Assumptions/dependencies: Licensed chemical datasets; computational resources; adherence to regulatory data-handling policies.
- Biomedical Imaging Segmentation Assistant — sectors: healthcare, medical imaging
- Use case: Improve nuclei or pathology segmentation pipelines via reusable design patterns (boundary refinement, uncertainty-guided post-processing, loss balancing).
- Tools/workflows: Drop-in modules for existing imaging codebases; cross-file edits to augment training/inference; automated mAP evaluation and score tracking.
- Assumptions/dependencies: DICOM or standardized imaging formats; clinical validation workflows; data privacy and compliance.
- Clinical Time-series Modeling Support — sectors: healthcare analytics
- Use case: Evolve disease progression models (e.g., Parkinson’s) with Neural CDEs, physics-informed regularization, and adaptive reweighting to handle heterogeneous signals.
- Tools/workflows: Pipeline improvements aligned to SMAPE or similar metrics; documented pseudo-code and code patches; reproducible iterations under runtime limits.
- Assumptions/dependencies: Valid patient data access with strict governance; careful model validation; oversight on clinical use.
- Patent Analytics and Prior Art Matching — sectors: IP, legal tech, finance
- Use case: Enhance phrase-to-phrase matching with CPC embeddings and low-rank adaptation (LoRA) for portfolio mining, licensing, and risk assessment.
- Tools/workflows: Retrieval-informed proposals; automated fine-tuning and evaluation; result archiving to support IP audits.
- Assumptions/dependencies: Licensed patent corpora; reproducible correlation metrics; monitoring for IP/privacy constraints.
- Automated Reproducibility and Paper-to-Repo Upgrades — sectors: academia, publishing, software
- Use case: Reproduce and then evolve published algorithms, generating improved repositories with documented differences, scores, and provenance.
- Tools/workflows: “Reproduce→Improve” workflow layered atop SciReplicate/CORE-like checks; deep research proposals grounded in prior art; reproducibility reports with code diffs.
- Assumptions/dependencies: Access to paper artifacts; standardized environments; alignment with journal/conference reproducibility policies.
- Productivity Aid for Data Science Competitions — sectors: education, daily life
- Use case: Assist students and practitioners in Kaggle-style settings to move beyond heuristic tuning by proposing grounded algorithmic changes and implementing them safely.
- Tools/workflows: Competition-ready runner with capped compute; evolutionary memory of candidate ideas; human review of changes.
- Assumptions/dependencies: Clear rules and data licenses; explicit runtime limits; ethical use aligned with competition guidelines.
Long-Term Applications
These applications require additional research, scaling, formalization, or integration with hardware and governance.
- AI Co-Scientist for Closed-loop Scientific Discovery — sectors: healthcare, chemistry, materials, energy, academia
- Use case: Couple DeepEvolve’s algorithm discovery with robotic labs (e.g., AI Chemist) to propose models, run experiments, ingest results, and iteratively refine theory-guided algorithms.
- Tools/workflows: End-to-end lab orchestration; physics/chemistry-informed priors; experiment planners; formal hypothesis tracking; robust failure-aware debugging.
- Assumptions/dependencies: Reliable experiment-to-model feedback loops; safety and governance; multi-modal data integration; high-availability compute.
- Certified Optimization and Formal Verification of Evolved Algorithms — sectors: software, safety-critical systems, robotics
- Use case: Extend the framework with formal methods to certify optimization steps (e.g., global optimization guarantees for packing/logistics) and verify changes across codebases.
- Tools/workflows: SMT/Coq/Lean integration; proof-aware coders; audit trails linking proposals to certified properties.
- Assumptions/dependencies: Mature formal tooling; domain-specific specification languages; expert oversight for correctness.
- Autonomously Generated IP Portfolios and Patent Scouting — sectors: finance, legal tech, industry R&D
- Use case: Systematically generate and evaluate novel algorithmic ideas, prioritize patentable innovations, and manage filings based on performance and originality.
- Tools/workflows: Novelty scoring (LLM-as-a-judge + prior art retrieval); IP risk analysis; portfolio dashboards; traceable evolution histories.
- Assumptions/dependencies: Legal frameworks for AI-generated inventions; reliable novelty detection; ethical governance.
- National-scale Reproducibility and Credibility Audits — sectors: policy, academia, public research funding
- Use case: Deploy agents to audit computational results in funded projects, reproduce baselines, evolve improvements, and report credibility scores at scale.
- Tools/workflows: Federated audit infrastructure; standardized evaluation APIs; transparency dashboards for funders and journals.
- Assumptions/dependencies: Policy mandates; secure data access; standardized reporting formats; neutrality safeguards.
- Industry-wide Algorithm Discovery Hubs — sectors: cross-industry software and ML
- Use case: Create centralized “Evolution Hubs” where organizations contribute problems and baselines; agents continuously evolve algorithms and share vetted improvements.
- Tools/workflows: Multi-tenant evolutionary databases; MAP-Elites diversity tracking; governance policies for sharing and attribution.
- Assumptions/dependencies: Inter-org data sharing agreements; incentives for contribution; IP and compliance frameworks.
- Education: Studio Courseware for Algorithmic Innovation — sectors: education
- Use case: Curriculum-integrated agent that teaches students to plan research questions, search literature, write proposals with pseudo-code, implement multi-file changes, and evaluate systematically.
- Tools/workflows: Classroom sandboxes; graded evolution histories; scaffolded reflection checkpoints; peer review of agent-generated proposals.
- Assumptions/dependencies: Faculty adoption; guardrails against academic integrity violations; accessible compute resources.
- Decision Support for Public Policy Modeling — sectors: policy, economics, energy, environment
- Use case: Evolve simulation and forecasting models (e.g., epidemiology, energy demand, environmental risk) under bounded, auditable evaluation functions.
- Tools/workflows: Scenario builders; documentation of assumptions; uncertainty-aware modules; reproducibility archives for legislative review.
- Assumptions/dependencies: High-quality public datasets; transparent, domain-appropriate metrics; governance to avoid model misuse.
- Cross-domain Knowledge Graphs for Algorithmic Priors — sectors: software, research infrastructure
- Use case: Build structured priors from literature across chemistry, biology, mathematics to inform searches and constrain proposals (e.g., motifs, grammars, physical laws).
- Tools/workflows: Retrieval + curation pipelines; ontology alignment; priors-as-modules for proposal writers.
- Assumptions/dependencies: Ongoing curation; licensing of sources; quality control on knowledge ingestion.
- Safety, Compliance, and Secure Code Evolution — sectors: software, cybersecurity
- Use case: Extend the debugging/reflection stack with threat modeling, dependency vulnerability scanning, and compliance checks for regulated environments.
- Tools/workflows: Secure coding agents; policy-as-code; supply-chain security integrations; audit logs for every edit.
- Assumptions/dependencies: Up-to-date vulnerability databases; continuous monitoring; organizational buy-in for agent governance.
- HPC-Scale Evolution for Frontier Scientific Problems — sectors: HPC, national labs, academia
- Use case: Scale evolutionary search (islands + MAP-Elites) across large clusters to explore vast algorithm spaces in PDEs, combinatorial optimization, and mathematical discovery.
- Tools/workflows: Distributed orchestration; prioritized sampling strategies; meta-learning across tasks; checkpointing and lineage tracking.
- Assumptions/dependencies: Substantial compute budgets; robust schedulers; failover and reproducibility guarantees.
Notes on Feasibility Assumptions (cross-cutting)
- Evaluation functions must be computable in bounded time with trustworthy metrics; success hinges on “easy to evaluate” problems.
- Access to high-quality external knowledge (web retrieval) and reliable LLM capabilities for planning, synthesis, and code generation.
- Compute, data licensing, and security constraints must be respected; multi-file editing requires robust CI and testing.
- Human oversight remains important for safety, correctness, and domain validity, especially in healthcare and policy contexts.
- Organizational governance (IP, compliance, reproducibility) and standardization will impact deployment speed and adoption.
Glossary
- AlphaEvolve: An LLM-driven evolutionary coding system that proposes and optimizes programmatic hypotheses via iterative selection. "Pure algorithm evolution, as in AlphaEvolve, depends only on the internal knowledge of LLMs and quickly plateaus in complex domains,"
- AUC: Area under the ROC curve; a scalar measure of binary classifier performance averaged over thresholds. "AUC over multiple model initializations"
- Burgers' equation: A fundamental nonlinear PDE used to model viscous fluid flow and shock formation. "Solving Burgers' equation"
- Circle packing: The optimization problem of arranging circles without overlap in a region (e.g., unit square) to maximize a target such as total radii. "A problem instance in mathematics and geometry is the circle packing."
- Contrastive learning: A self-supervised learning paradigm that pulls similar representations together while pushing dissimilar ones apart. "DeepEvolve proposes contrastive learning in Line 29-34"
- Cooperative Patent Classification (CPC): A hierarchical patent taxonomy used to categorize inventions and enable feature embeddings in NLP models. "Cooperative Patent Classification (CPC) embeddings"
- Cross-file code editing: Automated program modification spanning multiple source files, requiring global codebase understanding. "uniting external knowledge retrieval, cross-file code editing, and systematic debugging"
- Deep research: An agentic process that performs structured planning, web retrieval, and synthesis to generate evidence-backed hypotheses. "integrates deep research with algorithm evolution"
- GREA: Graph Rationalization with Environment-based Augmentations; a method to extract subgraph rationales supporting predictions. "we improve the graph rationalization method GREA"
- Grammar-constrained tokenization: Sequence tokenization restricted by a formal grammar (e.g., chemical rules) to ensure syntactic validity. "grammar-constrained tokenization"
- Island-based populations: A distributed evolutionary scheme where multiple subpopulations (islands) evolve semi-independently with occasional exchange. "We use island-based populations~\citep{tanese1989distributed}"
- Krylov subspace solvers: Iterative linear algebra methods that approximate solutions to large systems by projecting onto Krylov subspaces. "Krylov subspace solvers for partial differential equations"
- Levenshtein distance: An edit-distance metric measuring the minimum number of single-character edits to transform one string into another. "Levenshtein distance"
- LLM-as-a-judge: An evaluation setup where a LLM provides rubric-based assessments of ideas or outputs. "an LLM-as-a-judge approach"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that inserts low-rank adapters into pretrained model layers. "low-rank adaptation (LoRA)"
- MAP-Elites: A quality-diversity evolutionary algorithm that illuminates a space by storing elites across feature-map cells. "MAP-Elites~\citep{mouret2015illuminating} samples nearby algorithms of based on three features:"
- mAP: Mean Average Precision; averages precision over recall levels for object detection/segmentation tasks. "Mean average precision (mAP)"
- MCRMSE: Mean Column-wise Root Mean Squared Error; averages RMSE across multiple target columns. "Mean column-wise RMSE (MCRMSE)"
- Motif-aware masking: A masking strategy that leverages chemically meaningful substructures (motifs) to guide learning objectives. "motif-aware masking in Line 8"
- Neural Controlled Differential Equations (CDEs): Neural models that learn dynamics driven by continuous-time control signals via controlled differential equations. "Neural Controlled Differential Equations (CDEs)"
- Normalized RMSE (nRMSE): RMSE scaled (e.g., by data range or mean) to enable comparable error magnitudes across datasets. "Normalized RMSE (nRMSE)"
- OpenEvolve: An open-source reproduction of AlphaEvolve for evolutionary code generation. "OpenEvolve~\citep{openevolve}, an open-source implementation of AlphaEvolve."
- Physics-informed regularization: Constraints or losses that encode physical laws (e.g., PDEs) to steer model learning. "physics-informed regularization for disease dynamics"
- Pseudo-code: High-level algorithmic description using language-agnostic constructs to guide implementation. "including pseudo-code to guide the implementation."
- R2: Coefficient of determination; proportion of variance explained by a model in regression. "Weighted MAE (wMAE) and "
- Sequential Least Squares Programming (SLSQP): A constrained nonlinear optimization algorithm using sequential quadratic approximations. "Sequential Least Squares Programming (SLSQP) solver"
- SMAPE: Symmetric Mean Absolute Percentage Error; a scale-independent forecasting error metric. "Symmetric Mean Absolute Percentage Error (SMAPE)"
- Textualization function: A mapping that serializes structured objects (e.g., problems, algorithms) into text strings. "We define a textualization function that converts structured objects into text."
- Uncertainty-guided refinement: A scheme that allocates modeling or post-processing effort based on estimated predictive uncertainty. "uncertainty-guided refinement is used in Molecular Prediction"
- wMAE: Weighted Mean Absolute Error; averages absolute errors with specified weights across targets. "Weighted MAE (wMAE)"
Collections
Sign up for free to add this paper to one or more collections.