- The paper introduces DRA, an autonomous system that iterates through hypothesis generation, code execution, and reflective analysis in deep learning experiments.
- It implements a zero-cost monitoring strategy using OS-level process checks and a two-tier constant-size memory to manage long-running experiment cycles.
- Empirical results show a 52% metric improvement with minimal human intervention and significant cost savings in LLM usage.
Deep Researcher Agent: Autonomous, Cost-Efficient Deep Learning Experimentation
Introduction
Deep Researcher Agent (DRA) establishes a new framework for autonomous research workflows in deep learning, targeting the automation of end-to-end experiment execution, iteration, and monitoring. Unlike prior LLM agents with competencies in static coding or document authoring, DRA incorporates an integrated autonomous cycle that encompasses hypothesis generation, code modification, execution, zero-cost process monitoring, log-based analysis, and iterative refinement. The design addresses core bottlenecks in persistent deep learning experimentation: scaling agent-driven cycles indefinitely without accumulating context or incurring prohibitive LLM costs, and ensuring operational safety and intervention capabilities during long runtimes.
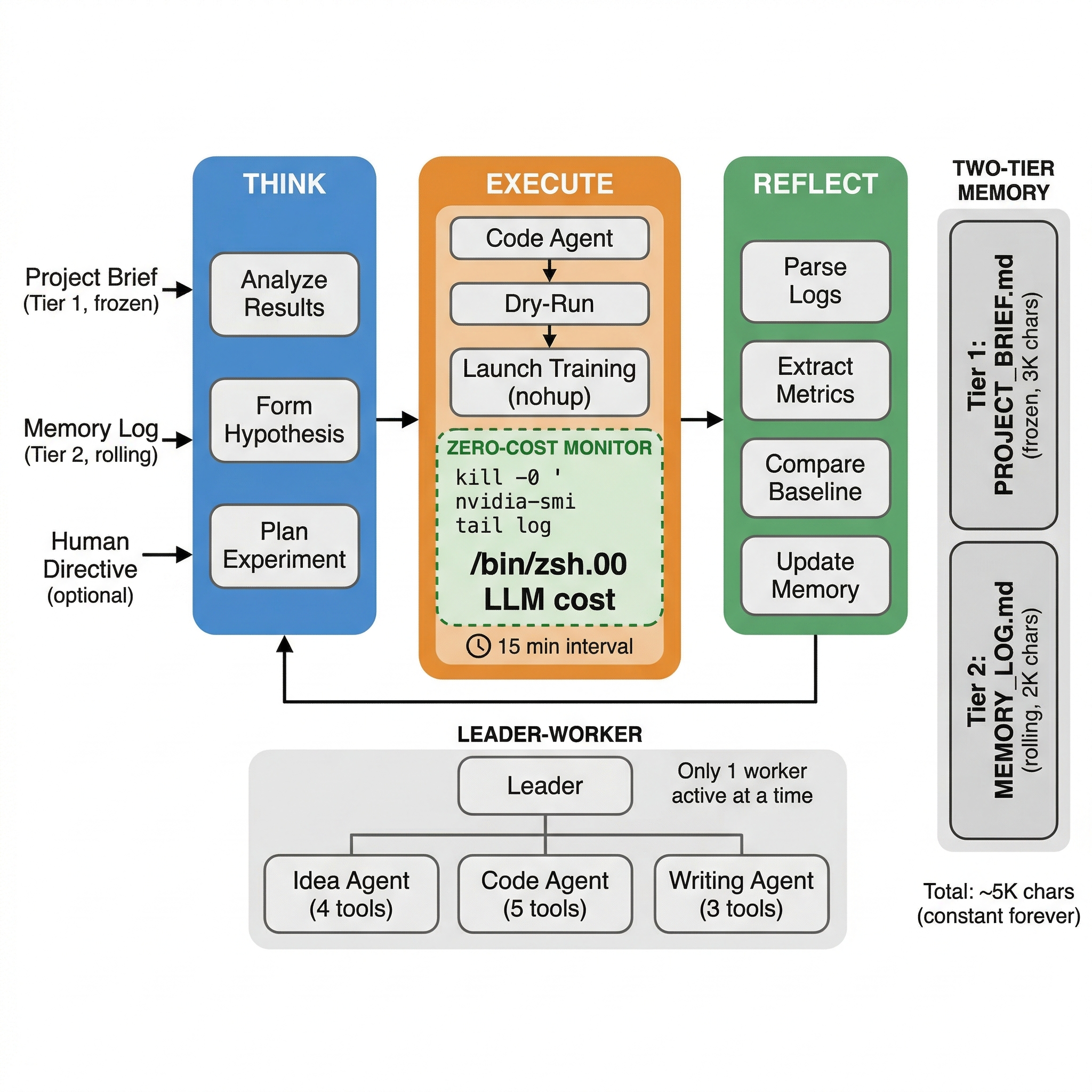
Figure 1: Overview of the DRA system’s continuous Think→Execute→Reflect loop with zero-cost process monitoring and constant-sized two-tier memory.
System Architecture
Autonomous Experiment Lifecycle
DRA's main loop operates as a Think→Execute→Reflect cycle. The agent consumes project briefs and memory logs, autonomously designs and executes experiments, monitors progress via process-level checks, and performs reflective analysis on results for the next cycle's planning. Human override is possible at any cycle start through prioritized directives.
Zero-Cost Monitoring Paradigm
A key innovation is eliminating LLM queries during protracted training phases. Training jobs, typically dominating experiment wall-times, are monitored strictly via OS-level process checks and log file tails—eschewing LLM polling. This strategy achieves genuine zero API cost during training while preserving accurate status tracking and resource utilization validation. The LLM is only activated upon experiment termination for post mortem log parsing and adaptive planning.
Two-Tier Constant-Size Memory
Agent context management is architected as a two-tier system:
- Tier 1 (Project Brief): Static, human-rich documentation detailing goals and constraints, capped at 3,000 characters.
- Tier 2 (Memory Log): A rolling, auto-compacting log of milestone results and recent decision rationales, capped at 2,000 characters. Milestones are pruned when exceeding bounds, emulating human prioritization of salient events.
This constant-size context (total ∼5,000 chars) precludes context overflow—regardless of operation duration—ensuring performance stability and cost containment.
DRA leverages a modular multi-agent paradigm optimized for communication cost efficiency:
- Leader Agent: Governs high-level decision logic, task assignment, and has access to only three core tools, keeping prompts minimal.
- Worker Agents: Dedicated functional units (Idea, Code, Writing agents) equipped with minimal, task-specific tool subsets (3-5 each). Only one worker is active at any time—eliminating parallel LLM invocation overhead.
This arrangement reduces per-call token bloat by up to 73% compared to conventional frameworks with fully packed toolsets.
Safety and Human-in-the-Loop Mechanisms
- Mandatory Dry-Run: All code modifications undergo enforced dry runs to preempt training-time errors, capturing common ML code faults before GPU resource allocation.
- File Protections: Core state/config files are immutable by workers.
- Human Directive/Override: Researchers can asynchronously inject directives file-based or via command-line flags.
- Anti-Burn Cooldown: Cool-downs are escalated following repeated unproductive cycles, preventing runaway costs during deadlocks or logic flaws.
Empirical Evaluation
Deployment Protocol
DRA was deployed on four GPU servers (NVIDIA L20X 144GB), managing four concurrent research tracks (generative models, multimodal learning, etc.) using Claude Sonnet as the LLM backend with prompt caching.
Experimental Results
Over sustained 30-day operation:
- 500+ autonomous experiment cycles were conducted.
- Autonomous optimization yielded a 52% improvement on the target metric in the most successful project, achieved via over 200 experimental iterations.
- The system maintained an average LLM cost of \$0.08 per 24-hour cycle.
- The mandatory dry-run intercepted 18% of code faults pre-training, maintaining a post-dry-run training crash rate below 3%.
- Human directives were rarely necessary (every 3–5 days), reflecting high system autonomy for routine scientific search and hyperparameter optimization.
Cost Control and Memory Stability
DRA incorporates eight layered cost-reduction mechanisms, spanning zero-LLM monitoring, bounded memory, minimal toolset allocation, and prompt slimming. Compared to polling agents, which incur up to \$1.6 per day, DRA realized a 10--20×reduction, dropping operational costs under \$5 per month.
Memory log analysis verified strict upper-bounding, with the tier-2 log stabilizing near its 2k-character cap through lossless and lossy compaction, regardless of deployment duration.
Comparison With Existing Agents
Compared to Claude Scholar [claude-scholar], AI Scientist [ai-scientist], SWE-Agent [swe-agent], and OpenHands [openhands], DRA is the only platform supporting autonomous, cost-efficient, 24/7 deep learning experimentation and GPU management. Other frameworks focus on paper writing, idea generation, or single-shot coding without persistent autonomous refinement or experiment execution.
Limitations and Future Directions
Current limitations include:
- Single-GPU Focus: Multi-GPU distributed training and multi-server orchestration are not yet supported.
- Heuristic Log Parsing: Regex-based metric extraction may fail on unorthodox logging schemes; structured logging is an upgrade path.
- Exploration Suboptimality: Experiment proposal is LLM-driven without structured global optimization or search; integration with Bayesian/Al-based strategies promises better sample-efficiency.
- Evaluation Methodology: Standardized metrics for autonomous agents operating on open-ended research tasks remain to be established and adopted.
Conclusion
DRA demonstrates that, through carefully engineered context management and monitoring, fully autonomous deep learning experimentation is practical at minimal LLM cost, maintaining operational safety and scalability. The release as open-source software enables further research into distributed, agent-driven, long-term scientific automation. Future directions include extending DRA to multi-GPU and distributed settings, enhancing experiment proposal logic, and contributing to standardized evaluation benchmarks for autonomous research agents.