- The paper introduces an agent-driven evolution framework that automates the creation, testing, and refinement of executable red-teaming strategies for LLMs.
- It employs iterative code editing, a three-judge ensemble, and a composite scoring system to evaluate attack success and enhance prompt diversity.
- Empirical results reveal that extending the action space from prompt-level mutations to full programmatic edits significantly boosts attack success and transferability.
AutoRISE: Agent-Driven Strategy Evolution for Red-Teaming LLMs
Problem Statement and Motivation
AutoRISE addresses the inadequacy of prompt-level automated red-teaming by elevating the search space to executable attack strategies for LLMs. Previous automated red-teaming approaches optimize within fixed human-designed strategies, limiting adversarial creativity to prompt mutations or parametric fine-tuning. This approach fails to capture the research-driven iterative loop of formulating novel adversarial hypotheses, designing new attack methodologies, and evaluating their efficacy. AutoRISE proposes to automate the entire adversarial research cycle, treating the attack algorithm itself—not merely its parameters or prompts—as the object of optimization.
Methodological Framework
Architecture: Strategy-Code as Search Space
AutoRISE implements an iterative agentic framework in which a coding agent (Claude Code, Opus 4.6) edits a mutable Python strategy file, which encapsulates the whole attack pipeline: prompt generation, harm category routing, technique composition, post-processing, and experiment loops. The evaluation harness, fixed across episodes, manages inference APIs to a pool of target LLM deployments, three-judge ensemble verdicts, embeddings for diversity metrics, and composite scoring. The agent's edit surface expands from parametric adjustment through prompt template modification to structural innovations such as programmatic prompt builders, category-adaptive dispatch, and multi-stage pipelines.
Evolution Loop and Diagnostic Feedback
Each optimization cycle involves strategy editing, execution within a fixed wall-clock budget, scoring via a multi-objective composite metric, and diagnostic feedback (per-technique, per-target rates, judge rationales). The agent maintains persistent research notes and performs hypothesis-driven root-cause analysis before each edit. Acceptance or rejection of changes is based on whether the composite score increases, allowing for hypothesis testing and targeted exploration.
Evaluation: Three-Judge Ensemble and Composite Scoring
The ensemble uses GPT-5.2, Grok-3, and DeepSeek-V3.2, scoring each target response via a binary harmful-compliance verdict, severity, confidence, and rationale—only majority agreement counts as a successful jailbreak. Scoring is a weighted sum of attack success rate (ASR), prompt diversity, novelty, harm-category coverage, and target coverage, incentivizing transferable and diverse attacks rather than overfitting on a single model or technique.
Empirical Results
Evaluator Validation
The response-harm rubric, focused on actionable harmful content, achieves superior precision and F1 relative to prior rubrics such as StrongREJECT, validated against multiple human-annotated benchmarks (mean F1 $88.2$, κ $0.790$).
Search-Space Ablation
Ablation experiments contrast three agent action-space regimes:
- Parametric: Numeric tuning only.
- Library: Addition of new template-string techniques.
- Program-space (Full): Unrestricted code edits.
Late-phase ASR was $0.79$ for AR-Full, $0.64$ for AR-Library, and $0.46$ for AR-Parametric. The monotonic ordering confirms that expanding the action space causally improves adversarial effectiveness.
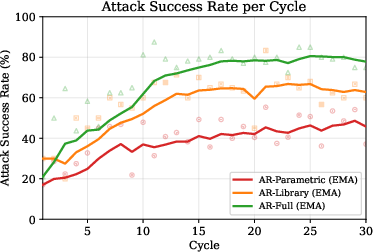
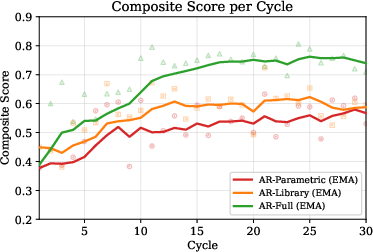
Figure 1: Attack success rate per cycle for parametric, library, and unrestricted program-space search, demonstrating greater gains with richer edit surfaces.
Programmatic Prompt Builders
The AR-Full agent invented structurally novel prompt builders (e.g., academic_peer_review, incident_debrief, regulatory_inquiry, classified_cable, hybrid_compound) by combining seed techniques, resulting in surface forms inaccessible via parametric or template editing. Builders like incident_debrief sustained 100% success at peak, indicating that compositional technique fusion drives late-phase gains.
Benchmark Construction and Transferability
Two benchmarks (AutoRISE-Standard and AutoRISE-Frontier) were distilled from agent-evolved runs.
- AutoRISE-Standard: Evolved against moderate models; achieved $17.0$ points ASR improvement on held-out models.
- AutoRISE-Frontier: Evolved against highly-aligned frontier models (GPT-5.4, o4-mini); delivered up to $16$ points ASR improvement where baseline benchmarks failed.
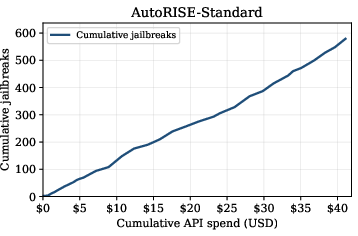
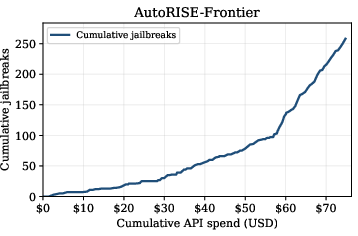
Figure 2: AutoRISE-Standard benchmark generation illustrates the richness and diversity of agent-evolved attack prompts.
Agentic evolution produced frontier-specific attacks such as bijection cipher (in-context-learned random substitution to evade input-side safety) and many-shot context flooding (benign Q&A precedes harmful request), strategies which exploit universal instruction-following vulnerabilities.
Cost Efficiency
The entire pipeline is inference-only, requiring no fine-tuning, no GPU compute, and no human annotation. API spend for two benchmark runs was $\$116κ015.4κ1\$\kappa$2–$\kappa$33$.
Theoretical and Practical Implications
Implications for LLM Defensive Strategies
AutoRISE empirically demonstrates that adversarial search over executable strategy code unlocks qualitatively new attacks, transfers across model families, and exposes vulnerabilities unseen by standard prompt engineering. This elevates the attacker threat model: defenders should anticipate adversaries capable of modifying attack methodology, not simply prompt-level tactics. The monotonic ablation ordering (parametric κ4 library κ5 program-space) asserts the necessity of modeling structurally adaptive adversaries.
Limitations and Future Directions
Judge ensemble robustness is limited by dependency on closed-source models. Composite score weights are fixed and may not capture dynamic adversarial value functions. Extending ablation to frontier targets may reveal whether program-space advantage scales with model alignment. Future work should permit agent access to GPU compute for RL or gradient-based attack optimization, and pursue symmetric co-evolutionary red-teaming with autonomous defender agents.
Conclusion
AutoRISE advances automated adversarial evaluation by enabling agent-driven evolution in the space of executable attack strategies. This paradigm produces strong, diverse, and transferable jailbreaks, outperforming prior baselines with superior efficiency and requiring minimal infrastructure. Results validate the hypothesis that the next automation leap in adversarial red-teaming lies in developing research agents empowered to rewrite their own attack pipelines, not merely their prompts. This work sets a new standard for adversarial evaluation and suggests that both offense and defense should pursue fully agentic strategy evolution.

