- The paper presents the Pioneer Agent system, which implements autonomous, closed-loop fine-tuning of small language models from cold-start to production adaptation.
- It leverages agentic orchestration, Monte Carlo Graph Search, and strict regression gates to ensure monotonic improvement and safe deployment in real-world scenarios.
- Empirical results demonstrate significant performance gains on tasks like ARC-Challenge, TriviaQA, and CLINC150 through targeted curriculum synthesis and rollback mechanisms.
Pioneer Agent: Autonomous, Continual Improvement for Small LLMs in Production
Motivation and Problem Setting
There is strong practical motivation to deploy small LLMs (SLMs, 1B–8B parameters) in production due to their low serving cost, inference latency, and targeted specialization. However, adapting SLMs to high-value tasks remains non-trivial. The principal challenges lie not in the optimization loop, but in upstream and surrounding engineering: dataset curation, failure diagnosis, non-monotonic improvement detection, regression avoidance, and iterative control. Standard AutoML, prompt optimization, and data-centric methods provide partial automation but fall short of fully autonomous SLM fine-tuning, especially in scenarios demanding continual improvement and safety-focused production adaptation. The Pioneer Agent system addresses this full model improvement loop, supporting both cold-start settings and production adaptation from observed failures.
System Architecture
Pioneer Agent is implemented as an LLM-orchestrated agent (Claude Sonnet 4.6) that autonomously coordinates data acquisition, curation, training, and evaluation within a LangGraph-driven state machine. Tool calls, contextual knowledge management, and sub-agent delegation are all mediated through an extended context window (106 tokens) and durable logs, supporting hundreds of turns and complex multi-stage workflows.
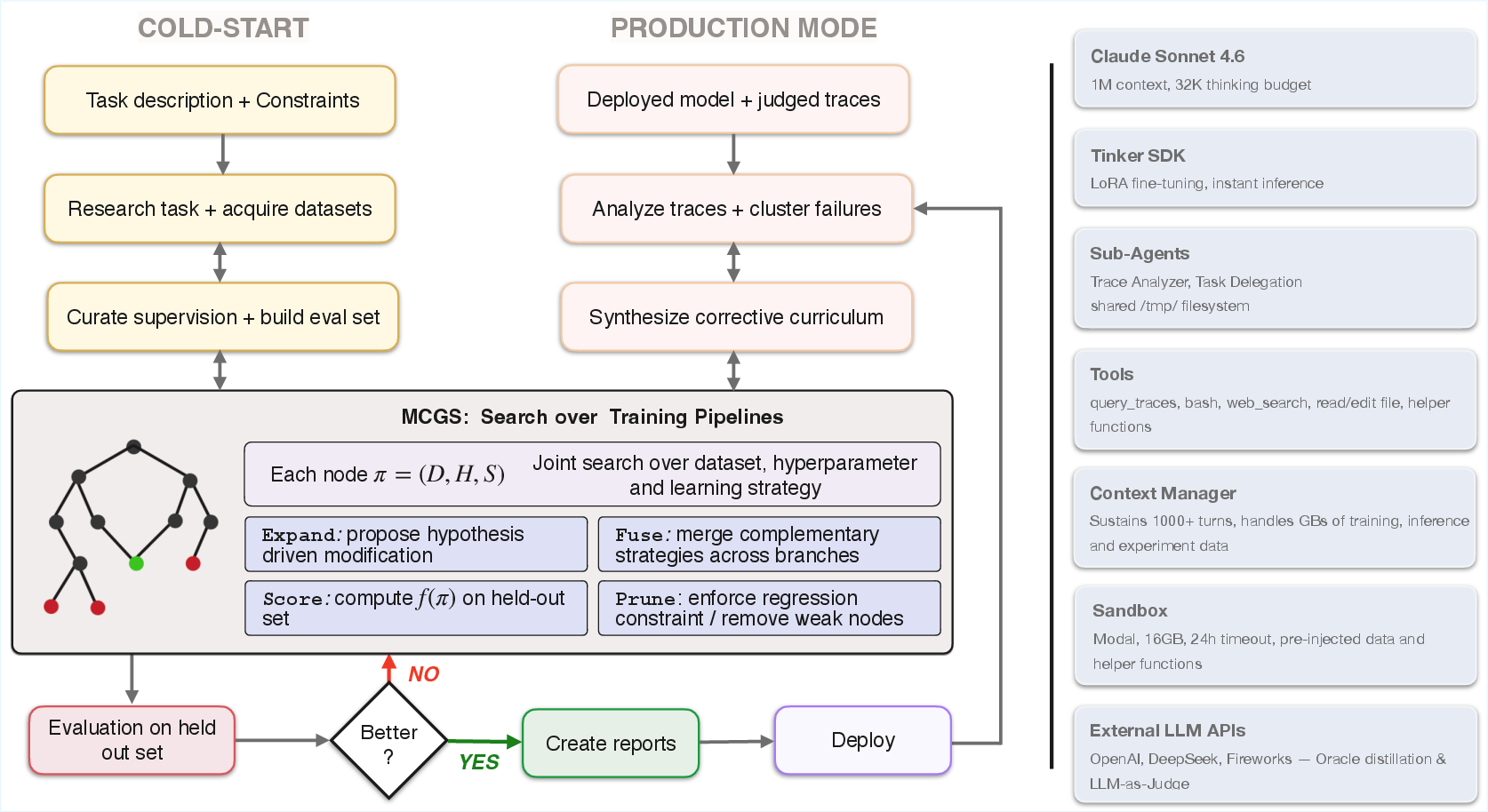
Figure 1: System architecture—an orchestrator LLM drives a LangGraph state machine; cold-start mode is left, production mode is right. Both share agent-guided iterative search over training pipelines π=(D,H,S). MCGS is invoked on select runs.
Training pipelines are structured as π=(D,H,S), spanning dataset composition, hyperparameters, and supervision format. Search is conducted agentically using an MCGS formalism when explicit graph structure is maintained (notably for ARC-Challenge), enabling the agent to reason causally about intervention effectiveness and perform branch fusion across independent trajectories.
Autonomous Cold-Start and Production Adaptation
Cold-Start
In cold-start, the only input is a natural-language task description. The agent autonomously discovers relevant datasets, constructs held-out evaluation splits, synthesizes curricula (with enforced quality control and balanced positives/hard negatives), and iterates until task-specific performance converges or the objective is deemed unattainable for a given base model. All configurations, from optimization strategy (e.g., LoRA vs. full FT) to learning schedules and prompt construction, are selected via agentic reasoning guided by observed downstream signal—no explicit strategy instructions are given.
Production Mode
Production adaptation is initiated by deployment drift and user/LLM-judged failures derived from real inference logs. Pioneer Agent analyzes these logs to construct failure taxonomies, explicitly clustering failure types, surfacing structural/semantic confusions, and distinguishing “fixable” from externally unfixable classes (upstream errors, ambiguous inputs, adversarials). The agent then synthesizes a targeted correction set—gold fixes, contrastive hard negatives, and replay buffer for catastrophic forgetting prevention—and retrains only when regression gates are satisfied.
A central contribution is the structural use of cross-checkpoint regression gates to enforce monotonic improvement on previously-passing data, with absolute regression thresholds (usually, at most 2 regression errors tolerated) to provide strong safety guarantees. The agent rolls back immediately upon regression, ensuring safe adaptive deployment.
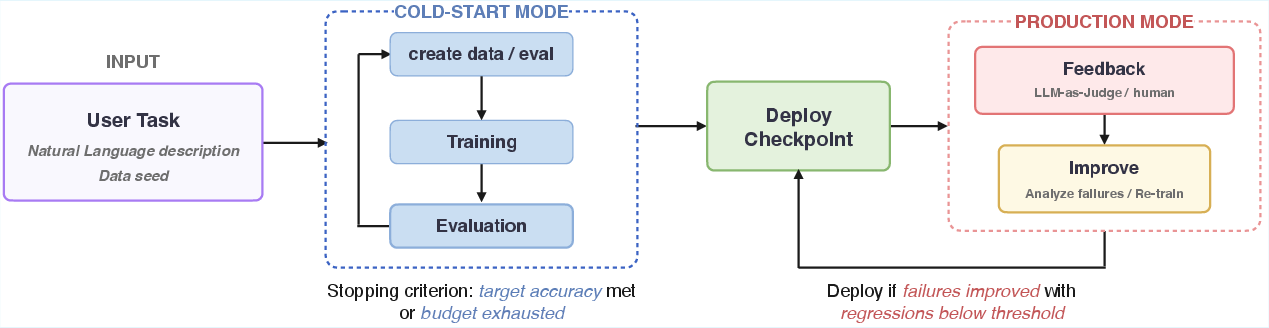
Figure 2: End-to-end closed-loop: Cold-start and production improvement share core data curation, curriculum synthesis, and iterative evaluation principles.
Data Curation and Quality Control
Data curation policies are uniform across modes, with required label balancing, entity diversification, context-length matching, and systematic inclusion of hard negatives (the 2-for-1 rule: for each challenging positive, synthesize a counterexample). Dataset sizes are compact, with strong preference for high-quality over scale (classification/NER: ~100–200 examples; generation: 500–3,000). Example construction uses teacher LLMs (GPT-4.1, DeepSeek-R1) for chain-of-thought and diverse supervision in reasoning tasks.
Monte Carlo Graph Search and Search Dynamics
The agent’s search over Π is MCGS-based where relevant, treating each pipeline as a node and scoring edge expansions by causal linkage (e.g., data change, LR sweep, supervision format switch). Child configurations are driven by explicit failure analyses, not stochastic perturbations, yielding interpretable and efficient exploration. Fusion and trajectory-aware evolution mechanisms escape local optima and allow strategy recombination—for ARC-Challenge, for example, branch fusion combined chain-of-thought supervision with validation set expansion, yielding all validated post-fusion attempts regressing and being pruned.
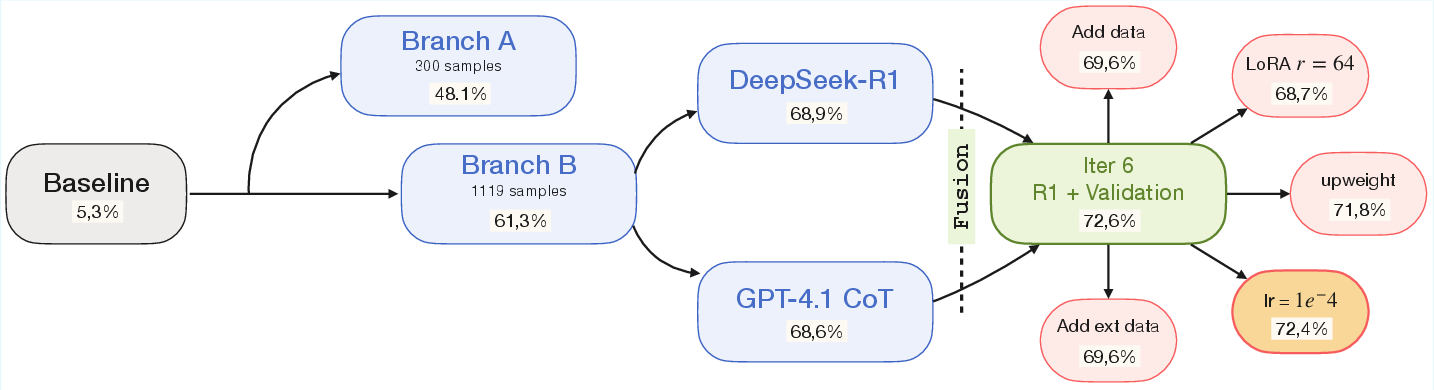
Figure 3: MCGS trajectory for ARC-Challenge (Llama 3.2-3B): Three phases culminate in branch fusion (72.6%) followed by regressive expansions confirming convergence.
Empirical Results
Cold-Start Benchmarks
In cold-start evaluation (eight diverse tasks), Pioneer Agent outperforms base models by +1.6 to +83.8 points (metric-dependent), notably:
- SMS Spam: F1 0.159 → 0.997 (+83.8)
- ARC-Challenge: 5.3% → 72.6% (+67.3)
- TriviaQA: near 0 → 48.6%
- XSum: ROUGE-2 6.9 → 17.9 (+159%)
- HumanEval: pass@1 71.3% → 92.7% (+21.4)
- On strong instructions-tuned baselines, gains are measurable but modest.
The system discovers high-leverage fine-tuning strategies emergently: e.g., chain-of-thought supervision yields +21pp gain on ARC-Challenge, precise system prompts drive summarization improvements, data augmentation is immediately rolled back if it triggers regression.
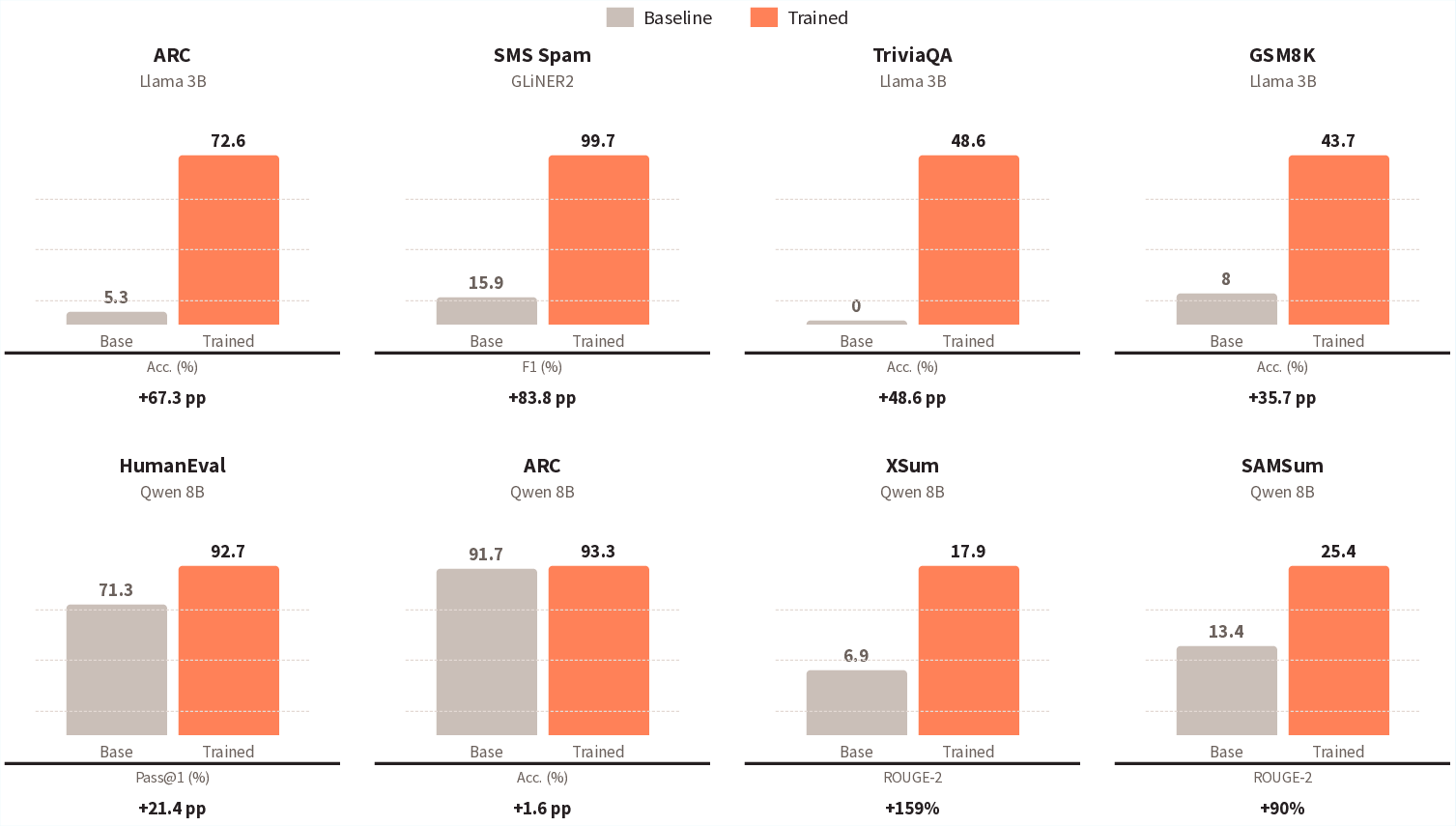
Figure 4: Cold-start performance improvement across model families and task types. Gains substantial when base model is format- or reasoning-deficient.
Production/Continual Adaptation: AdaptFT-Bench
AdaptFT-Bench, a new benchmark suite of seven noise-injected synthetic log scenarios with rising poison rates, probes the agent’s ability to adapt deployed models under realistic failure signals. Across all scenarios, agent-guided adaptation is strictly non-decreasing, while naive retraining monotonically degrades as poisoning accumulates. On challenging tasks (e.g., TriviaQA, ARC-Challenge, GSM8K), performance gaps between agent and naive retrain after three noisy stages range +17 to +43 points.
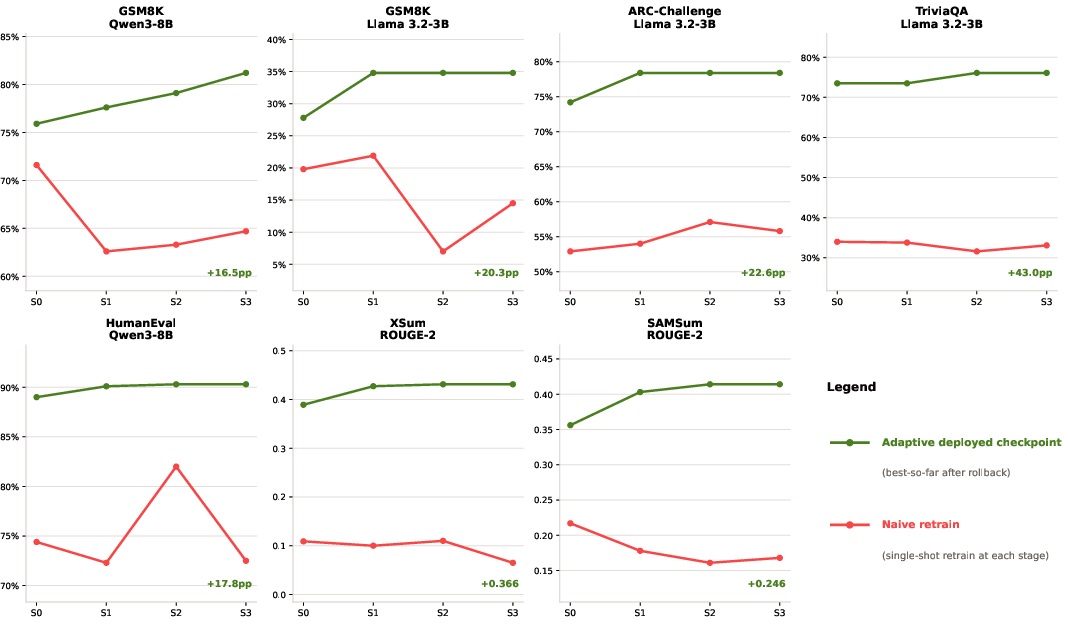
Figure 5: Stage trajectories across AdaptFT-Bench: the green line (Pioneer Agent) is non-decreasing, while naive retraining (red) degrades sharply on accumulating poison.
Crucially, the controlled experimental setting with perfect labels demonstrates that Pioneer Agent even surpasses “clean-only” training baselines due to selective, meaning-preserving exposure to fixable noise, yielding robustness not available from static datasets.
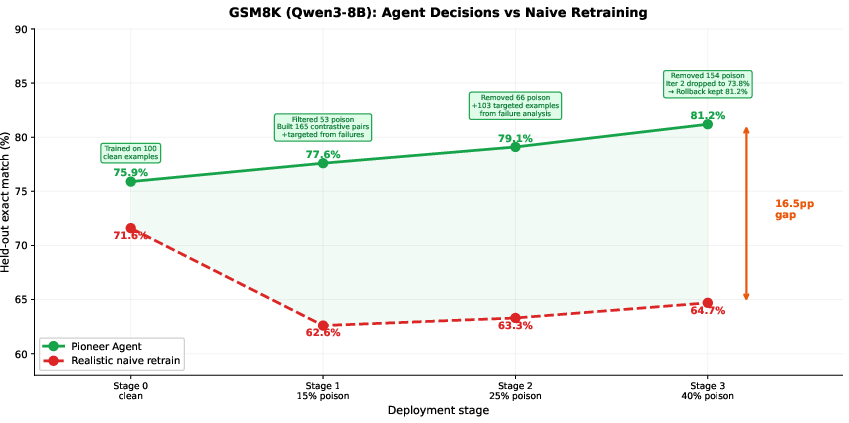
Figure 6: GSM8K stage-based deployment simulation: Pioneer Agent applies poison filtering and rollback, achieving monotonic improvement, unlike naive retraining which rapidly degrades.
Production Case Studies
- CLINC150 (Intent Classification): Starting with 84.9% accuracy and 453 residual failures, the agent constructs fine-grained confusion-pair taxonomies and applies targeted curriculum, reaching 99.3% fix rate with only 3 non-fixable residuals; further augmentation is automatically rolled back due to incipient regression.
- CoNLL-2003 (NER): The agent recovers from an FP-dominated failure regime, transitions from LoRA to full FT post-infrastructure error, and tunes the deployment threshold to t=0.99, improving Entity F1 from 0.345 to 0.810 and reducing errors from 2,740 to 821.

Figure 7: CLINC150 production taxonomy—dominant confusions and root causes are diagnosed, directly informing targeted curriculum and curriculum synthesis.
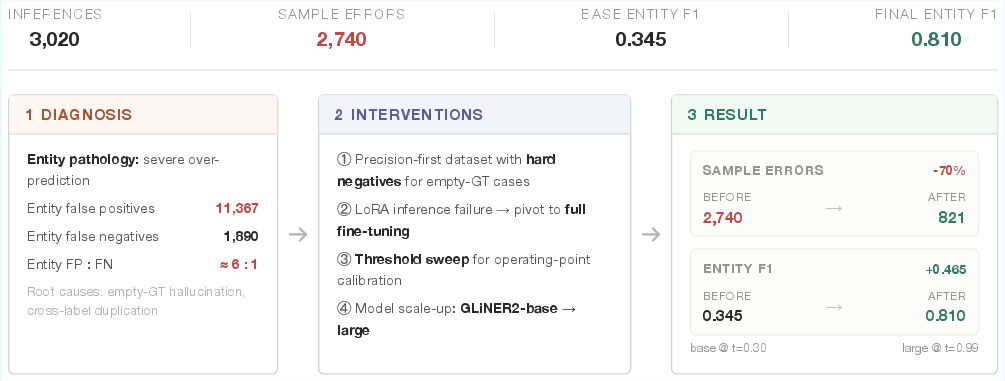
Figure 8: CoNLL-2003 adaptive recovery—precision-oriented curriculum and threshold tuning drastically reduce errors and raise F1.
Emergent Training Strategies, Iterative Policy, and Failure Analysis
The iteration policy, rollback principle, and MCGS enable the agent to discover effective strategies typically reserved for expert practitioners:
- Supervision Format: Chain-of-thought is correctly selected for reasoning tasks.
- Hyperparam Schedule: Epoch, batch size, and LR are auto-tuned based on overfit/convergence analysis.
- Data Selection: The agent prefers small, high-quality datasets, only minimally supplementing as accuracy improves, and rolls back on regression.
- Format Sensitivity: For regex-enforced tasks, the agent switches to dedicated format learning.
- Error-Mode-Specific Strategies: On NER with hallucinated FPs, the system pivots to aggressive hard negative construction and threshold calibration.

Figure 9: Representative closed-loop agent trajectories—across families, observe the motif: diagnose, construct targeted supervision, test interventions, roll back on regression.
Theoretical and Practical Implications
The Pioneer Agent system demonstrates that closed-loop autonomous improvement in SLMs for concrete tasks is achievable via outcome-driven agentic control. The explicit regression gate and crossover evaluation set ratchet are essential for safe continual deployment in non-stationary settings; naive fine-tuning is demonstrably brittle and prone to catastrophic regression. The work highlights the importance of task-contextual, feedback-driven search over data, hyperparameter, and supervision axes, going beyond the limitations of static recipe-based fine-tuning.
The main limitations are inherited from dependency on LLM-as-judge or human annotations for regression/fixable classification, model family restriction (SLM-centric), and cost overhead from orchestrator LLM usage, which is justified in high-value, failure-prone, or complex regimes but not for clean, static tasks.
Theoretically, the trajectory motifs elucidate the limits of blind stochastic search in high-dimensional, non-monotonic, and causally entangled pipeline spaces, and the need for interpretable, hypothesis-driven agentic expansion.
Conclusion
Pioneer Agent (2604.09791) defines a framework for closed-loop, production-grade, continual improvement of SLMs, integrating agentic search, interpretable curriculum construction, and rigorous regression control across the entire life cycle from cold-start to continual post-deployment adaptation. The strong empirical results, especially the monotonic non-decreasing adaptive trajectories under accumulating noise, contradict the naive intuition that model improvement is monotonic with additional data without explicit error-driven curation and rollback.
The practical implications for robust, safe, and efficient SLM deployment are substantial. Future developments should extend into richer modality support, broader alignment/formal safety constraints, and integration with human/team-in-the-loop protocols for scalable, verifiable improvement in complex production systems.