- The paper introduces a novel live training environment that unifies agentic evidence search, outcome-based reward assignment, and continuous RL updates.
- The paper details a robust pipeline leveraging LLMs, domain balancing, and clustering to generate high-quality prediction prompts from diverse real-world sources.
- The paper demonstrates significant improvements in prediction accuracy, Brier score, and calibration over daily cycles, evidencing robust transfer across domains.
FutureWorld: A Live Training Environment for Predictive Agents with Real-World Outcome Rewards
Motivation and Background
The live future prediction task entails making forecasts about events before their resolution, leveraging LLM-based agentic systems capable of reasoning, information retrieval, and continual learning from outcome feedback. Existing benchmarks and training protocols either rely on static datasets or process-based rewards, failing to close the training loop with outcome-grounded supervision. Notably, previous works such as "FutureX" (Zeng et al., 16 Aug 2025), "ForecastBench" (Karger et al., 2024), and "Echo" have advanced live evaluation or agentic rollouts, but none simultaneously integrate agentic evidence search, outcome-based rewards, and continuous live prediction streams.
FutureWorld addresses these gaps by unifying prediction, outcome realization, and agent parameter update in a daily, autonomous RL environment. The system implements large-scale question generation, domain balancing, enforced agentic interaction, and delayed reward assignment based on realized outcomes, thereby supporting robust, scalable, and generalizable continual learning.
Environment Architecture
FutureWorld's environment pipeline initiates each day by harvesting candidate events from 72+ publicly accessible sources covering diverse domains (Figure 1). High-quality binary prediction questions, paired with supplementary descriptions, are generated using template rules and, in some cases, LLM-based description synthesis via GPT-5.4. The pipeline integrates LLM-assisted filtering to ensure objective resolvability, exclusion of low-value or sensitive content, and then applies K-means clustering and center-biased sampling for domain balancing and reduction of semantic redundancy.
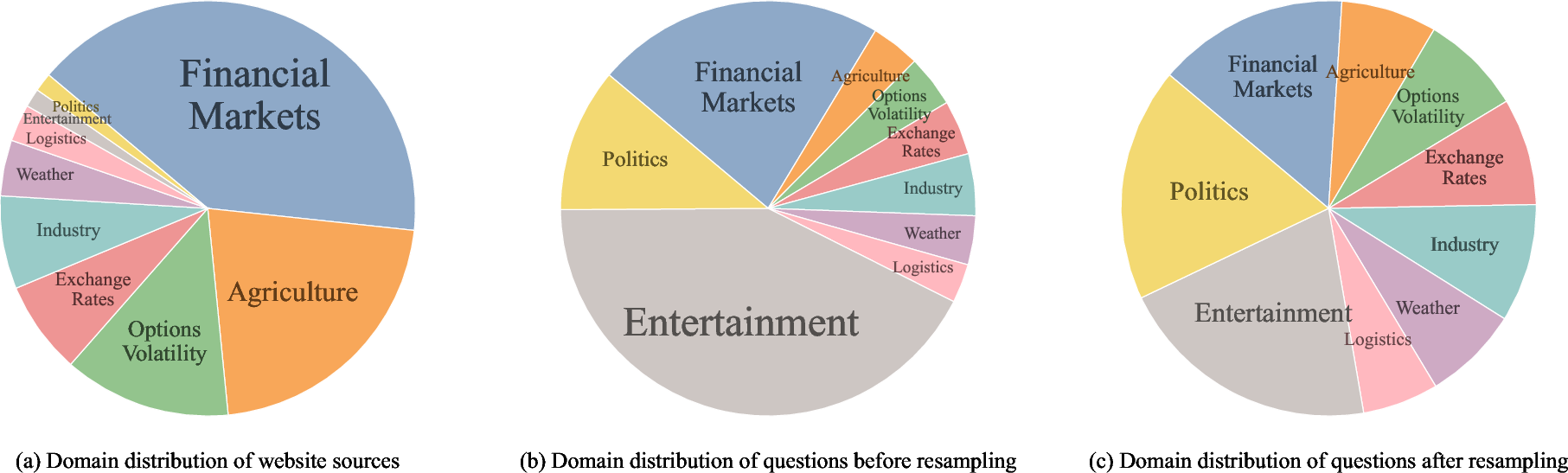
Figure 1: Domain distributions of website sources (a), questions before resampling (b), and questions after resampling (c).
These retained questions are transformed into probability estimation prompts, explicitly omitting descriptions, to preserve task difficulty and maximize learning signal granularity (Figure 2).
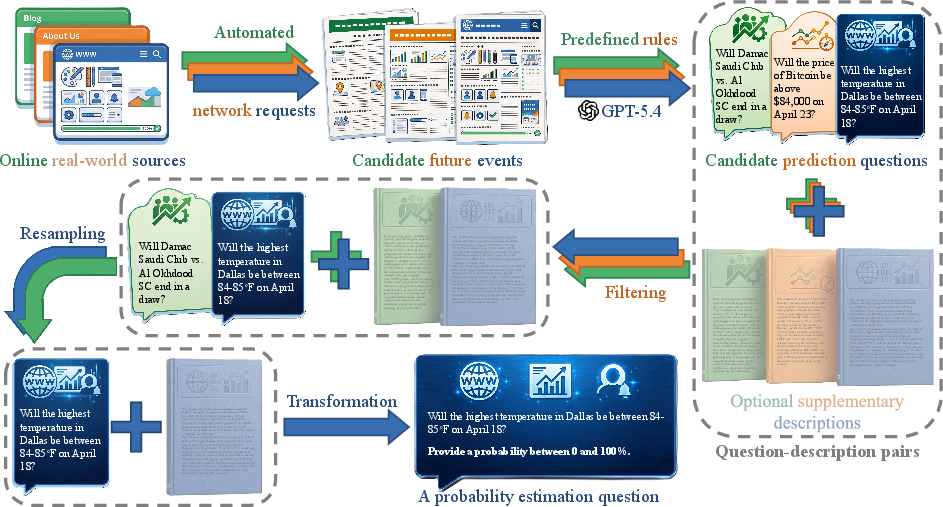
Figure 2: Overview of the FutureWorld pipeline for constructing prediction questions.
Once deployed, agents interact with the prompt by conducting web search (minimum one query enforced), document analysis, evidence-based reasoning, and probabilistic prediction. Full trajectory logging of agent episodes is implemented for delayed outcome matching and reward assignment (Figure 3).
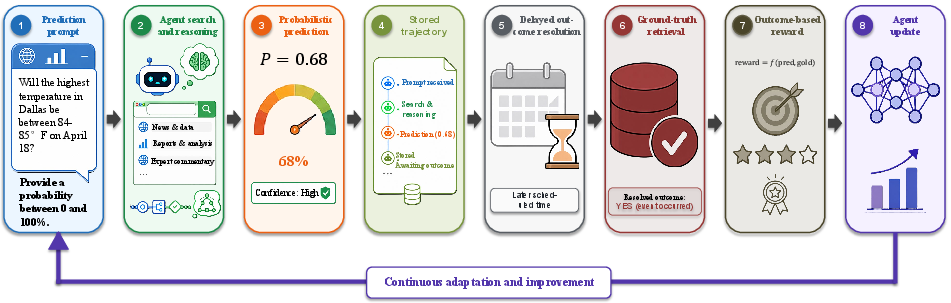
Figure 3: Overview of the FutureWorld training loop.
Resolution and reward assignment occur after events conclude, with negative Brier loss utilized as trajectory-level reward. RL updates are performed via Group Relative Policy Optimization (GRPO) (Shao et al., 2024), normalizing rewards across sampled rollouts per question group, with tool observations masked in policy loss.
Agent Training Protocol
Three open-source models—Qwen3-4B-Instruct-2507 (Yang et al., 14 May 2025), Qwen2.5-3B-Instruct [qwen2.5], DeepSeek-R1-0528-Qwen3-8B (DeepSeek-AI et al., 22 Jan 2025)—are trained in daily cycles, each processing 500 prediction prompts. The environment operates with high-frequency update and outcome retrieval, accommodating delays in event reporting by discarding unresolved questions. Four stochastic rollouts per prompt are sampled, with minimum one web search per episode enforced via the Serper API, ensuring agentic information acquisition.
The RL optimization uses AdamW (Loshchilov et al., 2017) with low learning rate, FSDP (Zhao et al., 2023) for distributed training, vLLM for rollout generation, and FlashAttention-2 (Dao, 2023) for accelerated computation.
Empirical Results
The training efficacy is evidenced by consistently improving accuracy, Brier score, and ECE over eight daily training rounds (Figure 4). Aggregate and domain-wise gains are observed, with day8 checkpoints outperforming day0 across most domains (Figure 5). These improvements are robust to domain shifts and the scaling of daily prediction question counts, with performance positively correlated to the number of questions processed (Figure 6).
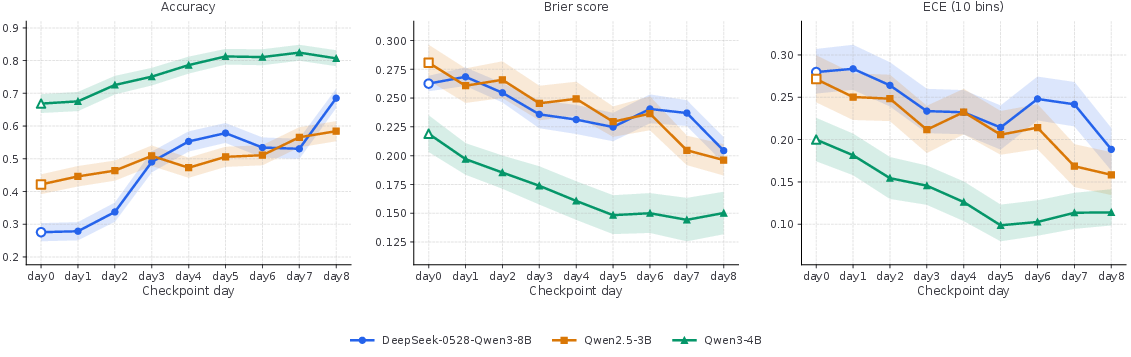
Figure 4: Prediction performance across model checkpoints saved on different days. Shaded regions indicate 95% bootstrap confidence intervals.
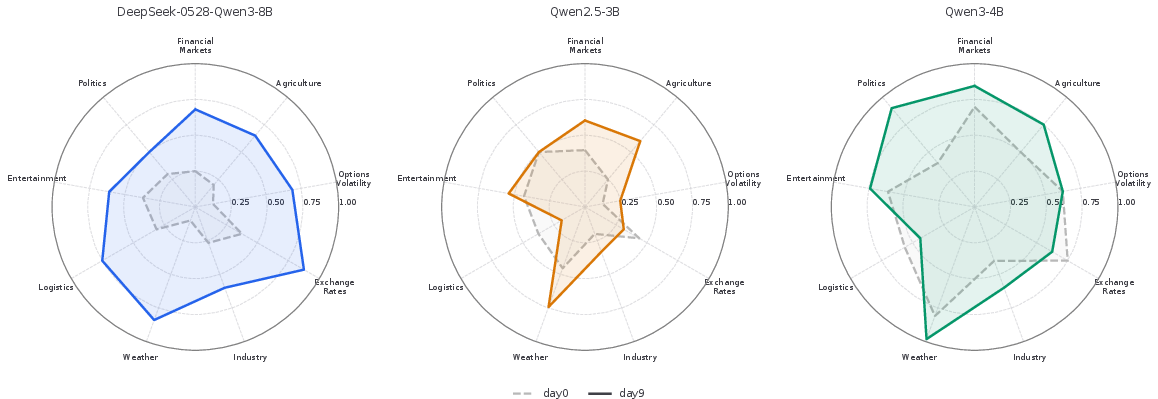
Figure 5: Prediction performance across model checkpoints saved on different days. Shaded regions indicate 95% bootstrap confidence intervals.
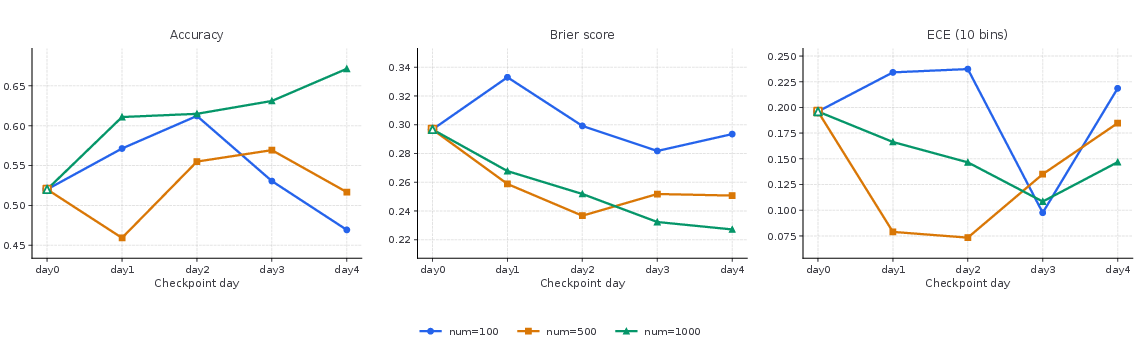
Figure 6: Effect of scaling the number of daily prediction questions on Qwen2.5-3B-Instruct training. Each curve corresponds to a different daily question budget.
Daily Benchmark and Agent Evaluation
FutureWorld supports a live benchmark with four question types: binary choice, simple multiple choice, difficult multiple choice, and numeric predictions. Type-specific scoring—option-level F1 for categorical responses, normalized squared error for numeric forecasts—enables robust evaluation under distributional shifts.
Frontier agents (x-ai/grok-4.20, z-ai/glm-5.1, openai/gpt-5.4, anthropic/claude-opus-4.6, google/gemini-3.1-pro-preview, qwen/qwen3-max-thinking) are benchmarked across four days, with qwen/qwen3-max-thinking achieving highest overall score. There is marked performance heterogeneity across question types; binary and simple multiple choice tasks are substantially easier than difficult multiple choice and numeric forecasts. Periodic abrupt distribution shifts are empirically observable, with agent scores fluctuating notably (Figure 7).
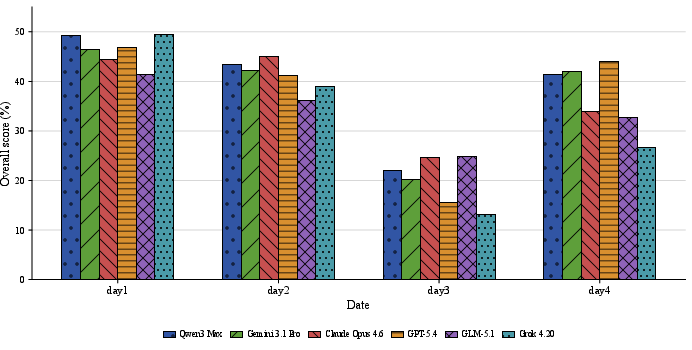
Figure 7: Daily overall scores of frontier agents on the FutureWorld daily benchmark over four consecutive days.
Agents trained in FutureWorld exhibit substantial gains over their untrained baselines; notably, Qwen2.5-3B-Instruct fails to comply with prompt/output requirements when untrained, but achieves nonzero scores post-training—even though the four benchmark question formats are unseen during RL training.
Practical and Theoretical Implications
FutureWorld's methodology enables scalable RL grounded in real-world outcome feedback, obviating the need for human annotation and mitigating data leakage. The continual, live nature of the environment establishes agents capable of dynamic adaptation to evolving world states, improving not only aggregate prediction metrics but also maintaining performance robustness across domains and under abrupt distribution shifts.
From a practical standpoint, FutureWorld presents a realistic framework for predictive agent deployment in dynamic, high-value applications—finance, weather, geopolitics—where outcome-based reward alignment is critical. Theoretically, FutureWorld positions outcome-based RL as an effective paradigm for continual learning in agentic systems, facilitating generalized skill acquisition beyond prompt templates.
Future Directions
Several research avenues emerge from FutureWorld: optimized handling of longer-delayed feedback, expansion of source pools and domain diversity, exploration of advanced reward shaping (beyond negative Brier loss), integration with multimodal agent environments, and comprehensive comparison with state-of-the-art continual learning protocols.
Live outcome-based RL environments may serve as foundation for training AGI-level prediction agents, capable of persistent adaptation and robust evidence acquisition.
Conclusion
FutureWorld establishes a unified agentic RL environment for live future prediction, tightly integrating autonomous question generation, agentic evidence search, delayed outcome feedback, and outcome-based policy improvement. This environment demonstrates effective continual learning from real-world rewards, robust performance across domains and task formats, and provides a tractable testbed for benchmarking frontier agent capabilities. The framework offers significant practical and theoretical value for developing predictive agents aligned with the evolving dynamics of the real world.