- The paper establishes a unified framework to evaluate LLMs as implicit text-based world models using fidelity, consistency, scalability, and agent utility metrics.
- It demonstrates that supervised fine-tuning on agent interaction trajectories significantly enhances next-state prediction and long-horizon consistency in structured environments.
- The study reveals that data diversity and scaling are crucial, with mixed-environment training improving decision safety, sample efficiency, and reinforcement learning performance.
LLMs as Implicit Text-based World Models
Introduction and Motivation
The paper "From Word to World: Can LLMs be Implicit Text-based World Models?" (2512.18832) systematically examines whether LLMs, when properly aligned and scaled, can serve as high-fidelity, robust world models that support agentic learning in text-based decision environments. Central to the investigation is the abstraction of text-based world modeling as next-state prediction in multi-turn agent-environment interactions, providing a unified formalism to quantify the capabilities and limits of LLMs as simulators of interactive worlds.
LLMs inherently encode vast factual and procedural knowledge, but the extent to which this scaffolds actionable predictions about latent world state evolution—beyond mere text generation—remains opaque, especially in high-entropy or open-ended environments. This work rigorously operationalizes world modeling along three axes: fidelity and consistency, scalability and robustness, and agent utility, applying its analysis across a diverse set of environments comprising ALFWorld, SciWorld, TextWorld, WebShop, and StableToolBench.
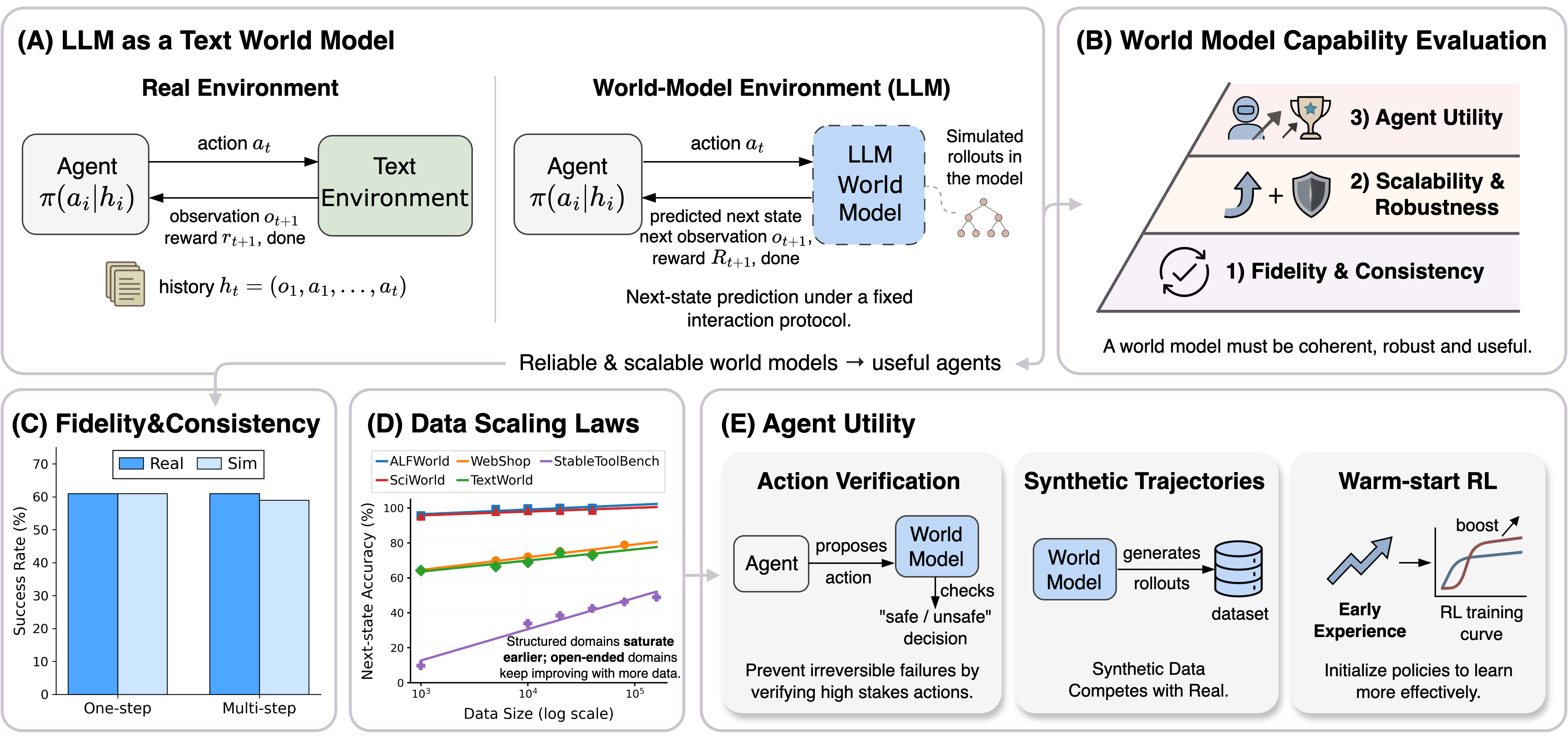
Figure 1: LLMs as text-based world models for agent learning; the evaluation framework quantifies fidelity/consistency, scalability/robustness, and agent utility; higher-fidelity models support agent learning pipelines including verification, synthetic data generation, and RL initialization.
World modeling is cast as learning a mapping from agent histories (states, actions, reasoning traces) to next-state transitions, where both actions and observations are represented in text, and the environment is modeled as a transition function W. The predictive task is fundamentally distinct from static language modeling, as it demands latent state tracking, counterfactual reasoning, and the capacity for long-horizon consistency in generated trajectories.
A rigorous multidimensional evaluation protocol is established:
- Fidelity (One-step prediction): Exact match of generated next states and binary rewards.
- Consistency (Rollout transferability): The success rate of model-generated action sequences executed in both model and real environments; quantified by the Consistency Ratio.
- Scalability: Data and model scaling laws, effects of joint multi-environment training, and analysis on out-of-distribution splits.
- Agent Utility: Downstream improvements in decision safety, sample efficiency, and reinforcement learning effectiveness enabled by world model integration.
Empirical Results: Fidelity, Consistency, and Robustness
Latent Dynamics and Short-term Fidelity:
Pretrained LLMs achieve nontrivial in-context next-state prediction accuracy, with few-shot prompting delivering moderate gains in structured domains. However, high-fidelity world simulation, especially in open-ended contexts, is only attainable with supervised fine-tuning on interaction trajectories, which enables models such as Qwen2.5-7B and Llama3.1-8B to exceed 99% accuracy in ALFWorld and SciWorld, and 49% F1 in the highly open-ended StableToolBench. This demonstrates that dynamics-aligned supervision—not just world knowledge—is essential for convergence to accurate world models in interactive domains.
Long-horizon Consistency:
Rollout stability is sustained across long horizons in structured environments, with consistency ratios (W2R/Real) above 90%, indicating that model-generated action traces remain executable in the real environment with minimal drift. In contrast, in open-ended WebShop settings, consistency deteriorates due to compounding distributional errors, which can be mitigated by anchoring model rollouts with partial real-environment observations.

Figure 2: One-step prediction accuracy as a function of training data size. Structured environments saturate with moderate dataset sizes; open-ended settings benefit from large scale data.

Figure 3: Model scaling yields diminishing returns for structured domains but substantial accuracy improvements in open-ended environments, highlighting the necessity of capacity for compositional, high-entropy tasks.
Scalability and Generalization:
Empirical scaling laws reveal that structured environments saturate quickly with respect to both data and model size; O(20k) trajectories and smaller (1.5B) models suffice. Open-ended environments, conversely, require upwards of O(70k) samples and 7B+ parameter-scale models for non-saturating gains. Mixed-environment training induces positive transfer, especially for environments with common narrative or procedural structures, and broadens agent policy support.
Out-of-Distribution Robustness:
World models exhibit strong transfer across unseen environment configurations, maintaining success in both same-room/different-layout and entirely novel-room OOD splits, supporting the claim that these models genuinely internalize structural transition dynamics rather than resorting to memorization.
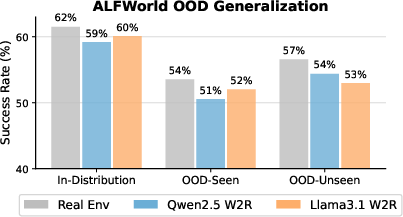
Figure 4: Task success rates in ALFWorld under OOD generalization. High transfer even in unseen layouts validates nontrivial abstraction of the environment’s latent dynamics.
Behavioral Coverage:
Including diverse agent-generated trajectories during training substantially mitigates performance degradation under distribution shift, especially for lower-capacity policies. A single expert is insufficient for robust agent utility in high-variance agent populations.
Agent Utility: Safe Decision-Making and Sample Efficiency
Safety via Counterfactual Verification:
Simulated rollouts in the world model provide a rewindable safety “checker" for irreversible agent actions. Pre-execution verification—gating real-environment effects on predicted positive outcomes—significantly reduces catastrophic failures, boosting task success rates especially for medium-capacity agents in high-risk environments.
Synthetic Data and RL Warm Start:
Model-generated synthetic experience matches or supersedes real-environment data in supervised policy training for both SciWorld and WebShop, and synergistic mixing yields further improvements.
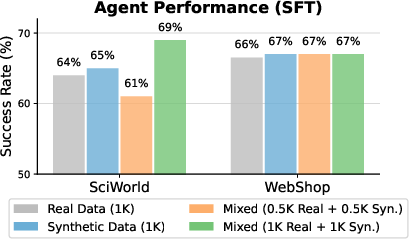
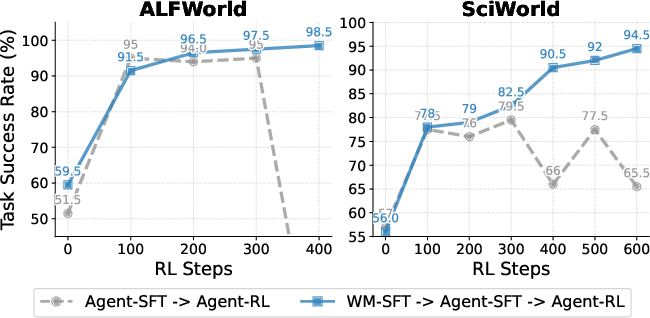
Figure 5: Left: Task success rate in SFT agents with real, synthetic, or mixed trajectory data sources. Right: RL agents with and without early world model-based "dynamics warmup."
Early exposure to world model-generated dynamics before RL training consistently improves sample efficiency and final performance, supporting the hypothesis that world-model pretraining serves as an effective inductive bias for stable RL in text-based domains.
Theoretical and Practical Implications
The results provide robust empirical evidence that LLMs, when fine-tuned with sufficient behavioral coverage and data diversity, can function as general text-based world models supporting model-based RL, counterfactual planning, and synthetic experience generation. However, the benefits are contingent on the match between agent behaviors, environment complexity, and training coverage. The study identifies precise regimes—typically low-entropy or highly structured environments—where world modeling is data- and parameter-efficient, and open-ended, high-entropy domains where modeling capacity and coverage demands increase substantially.
The findings delimit both the promise and the current limits of LLM-based simulators: they are not universal substitutes for real-world interaction, but constitute a powerful ingredient in scalable, safe, and efficient agent learning pipelines in natural language settings. With ongoing advances in data-efficient finetuning, retrieval-augmented rollouts, and multimodal grounding, these implicit world modeling capabilities will increasingly underpin robust agentic behavior in more complex, multimodal and embodied environments.
Conclusion
The study rigorously demonstrates that LLMs, properly supervised and scaled, transcend sequence modeling and effectively serve as text-based world models powering safer, more efficient RL and general agent learning. Fidelity in structured worlds is near-deterministic with modest resources; open-ended simulation scales well but reveals new frontiers in data, model capacity, and behavioral coverage. These results motivate the translation of the text-based world model paradigm to richer modalities and highlight the centrality of world models in future LLM-driven agent architectures.

