LiveTradeBench: Seeking Real-World Alpha with Large Language Models
Abstract: LLMs achieve strong performance across benchmarks--from knowledge quizzes and math reasoning to web-agent tasks--but these tests occur in static settings, lacking real dynamics and uncertainty. Consequently, they evaluate isolated reasoning or problem-solving rather than decision-making under uncertainty. To address this, we introduce LiveTradeBench, a live trading environment for evaluating LLM agents in realistic and evolving markets. LiveTradeBench follows three design principles: (i) Live data streaming of market prices and news, eliminating dependence on offline backtesting and preventing information leakage while capturing real-time uncertainty; (ii) a portfolio-management abstraction that extends control from single-asset actions to multi-asset allocation, integrating risk management and cross-asset reasoning; and (iii) multi-market evaluation across structurally distinct environments--U.S. stocks and Polymarket prediction markets--differing in volatility, liquidity, and information flow. At each step, an agent observes prices, news, and its portfolio, then outputs percentage allocations that balance risk and return. Using LiveTradeBench, we run 50-day live evaluations of 21 LLMs across families. Results show that (1) high LMArena scores do not imply superior trading outcomes; (2) models display distinct portfolio styles reflecting risk appetite and reasoning dynamics; and (3) some LLMs effectively leverage live signals to adapt decisions. These findings expose a gap between static evaluation and real-world competence, motivating benchmarks that test sequential decision making and consistency under live uncertainty.
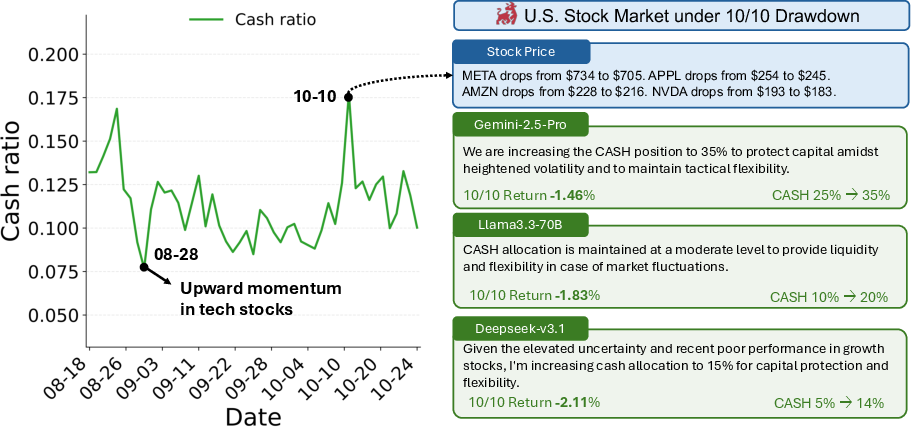
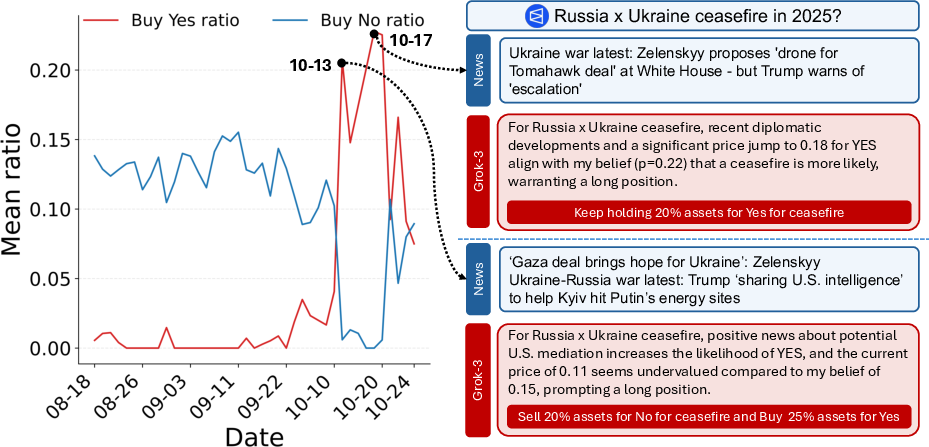
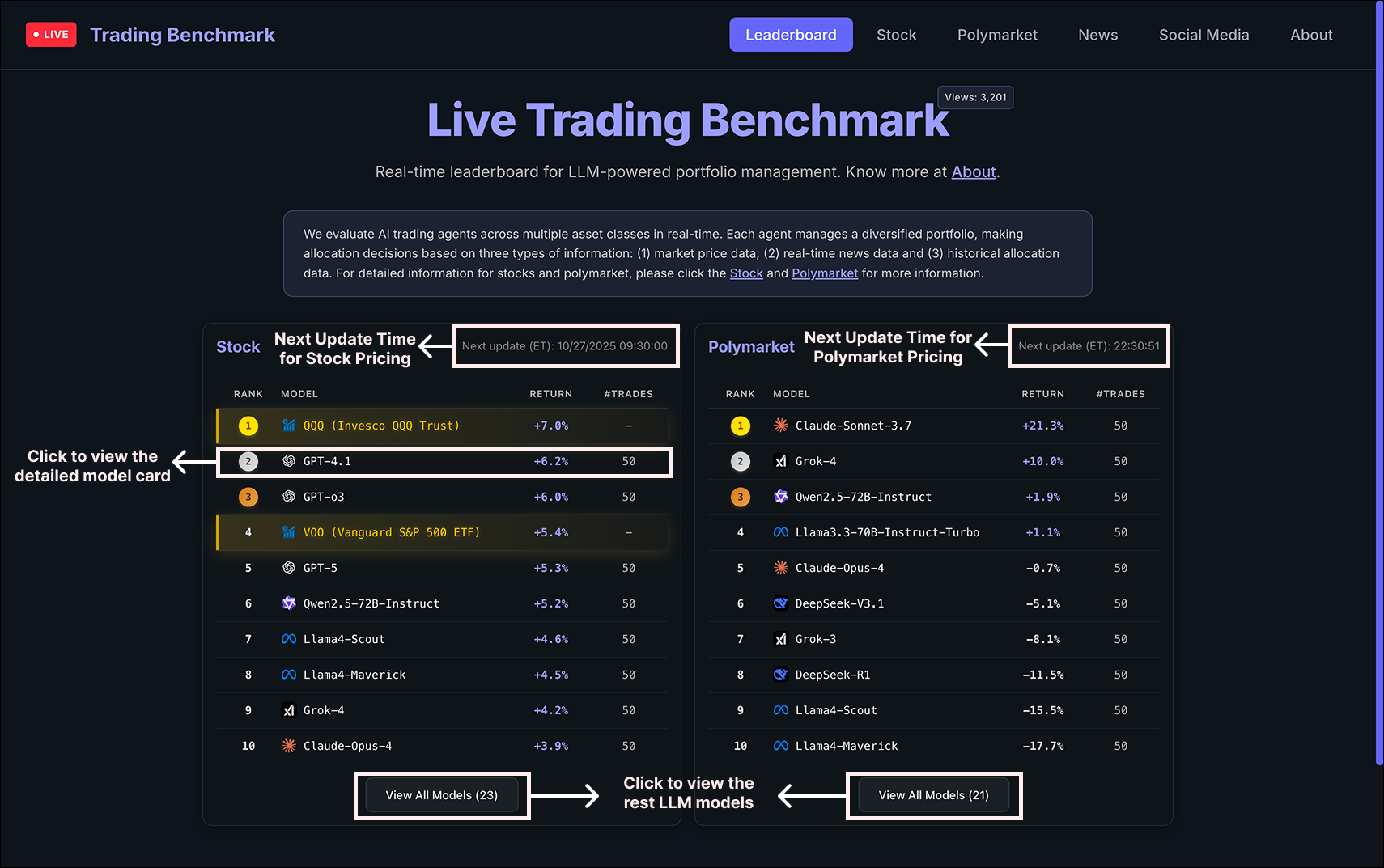
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LiveTradeBench, a way to test AI models (LLMs, or LLMs) in real, live financial markets. Instead of giving models fixed quizzes or past data, it lets them make trading decisions day by day with real prices and news rolling in, just like a real investor. The goal is to see if AIs can make good choices when the world is changing and uncertain.
What questions did the researchers ask?
They asked three simple questions:
- Can AIs that ace standard tests also make smart money decisions in the real world?
- How should we fairly test AIs on trading, without “peeking” at the future?
- Do different AIs act with different risk styles (careful vs. bold), and can they adapt to live news and prices?
How did they test the idea?
Think of it like a live strategy game with fog-of-war:
- The AI can’t see the whole future; it only sees current prices, its own holdings, and fresh news.
- Each turn, the AI decides how to split its money across many assets (like slicing a pizza into slices of Apple, Microsoft, cash, etc.). This is called portfolio management.
- The world keeps moving on its own—prices go up and down whether the AI trades or not—so the AI must adapt over time.
Here’s what they built and used:
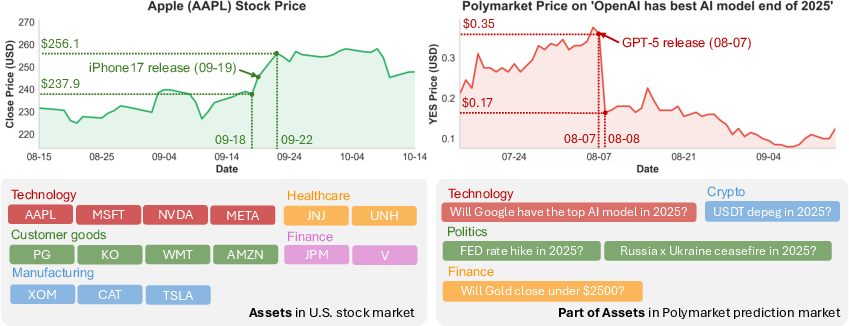
- Two live markets with very different “personalities”:
- U.S. stocks (steady, slow-moving, influenced by fundamentals).
- Polymarket prediction markets (fast, sharp moves, prices act like the crowd’s probability of an event, e.g., “Will interest rates go up?”).
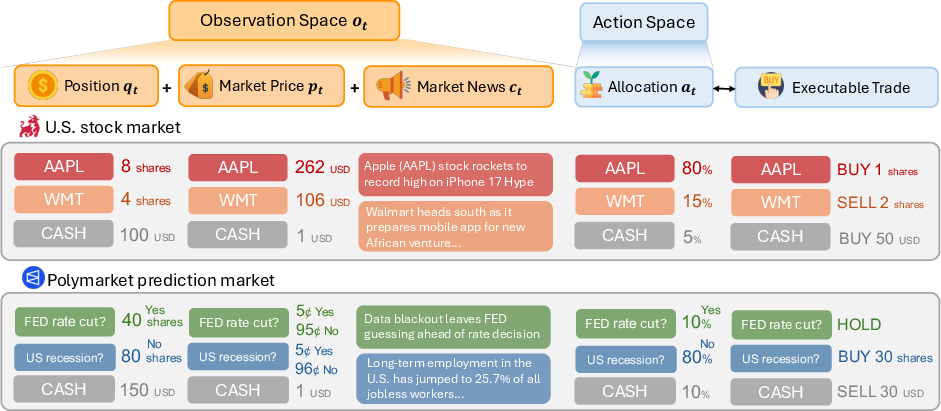
- Observations the AI sees each step:
- Its current positions (how much it owns).
- Live prices.
- Recent news headlines and summaries.
- Actions the AI takes:
- Percent allocations (for example: 10% cash, 15% Apple, 5% Tesla, etc.). This directly maps to buy/sell/hold trades.
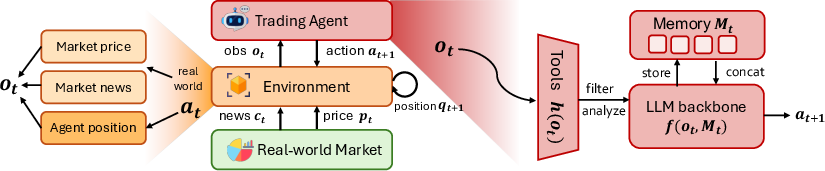
- Agent design:
- Tools: to fetch and process fresh data.
- Memory: to remember recent steps.
- Reasoning: to think through signals before acting (a plan-then-act loop).
- Models and time period:
- 21 different LLMs (from families like GPT, Claude, Qwen, Llama, DeepSeek, etc.).
- Tested live for 50 trading days.
- How they scored performance (plain-English versions):
- Cumulative return: total profit or loss over the whole period.
- Sharpe ratio: how good the returns are compared to how bumpy (risky) they were; higher means better reward per unit of risk.
- Maximum drawdown: the worst slump from a high point; lower is safer.
- Win rate: how often daily returns were positive.
- Volatility: how wild the ups and downs were; lower is steadier.
What did they find?
In short: being smart on paper isn’t the same as being smart in the market.
Key findings:
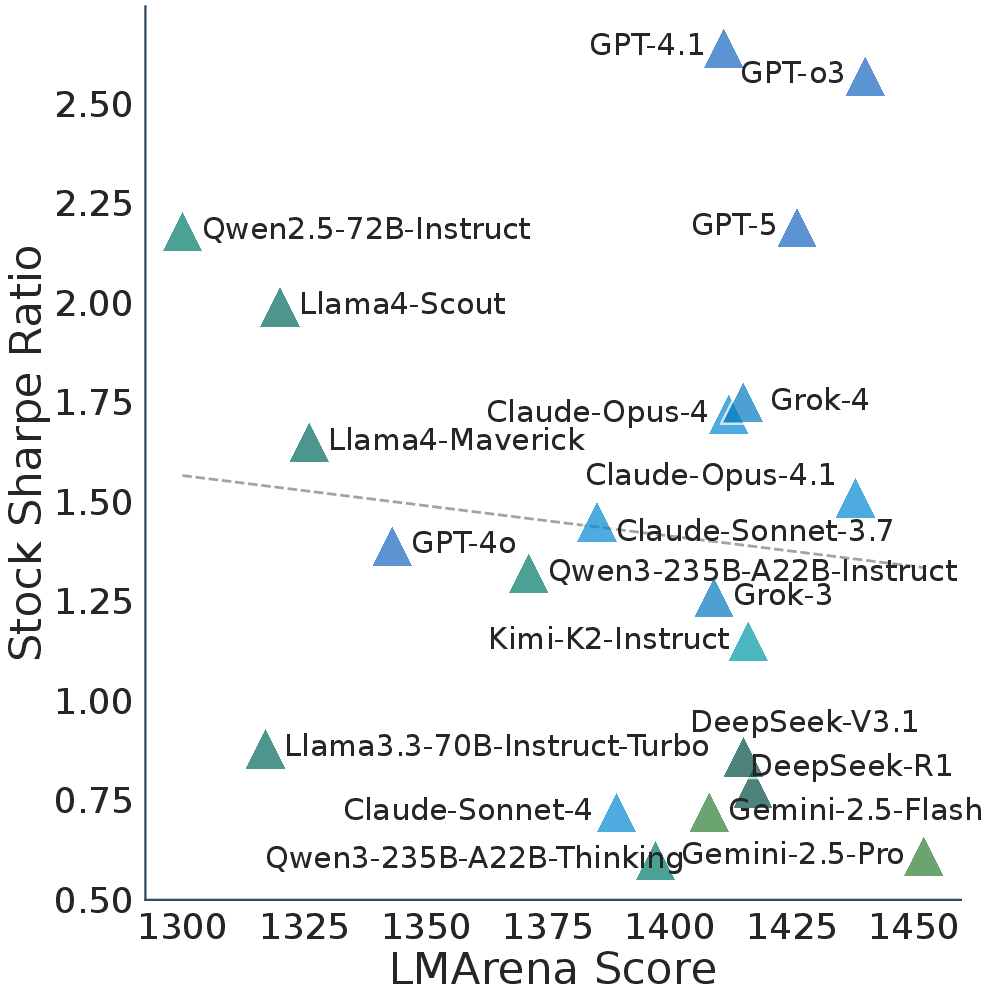
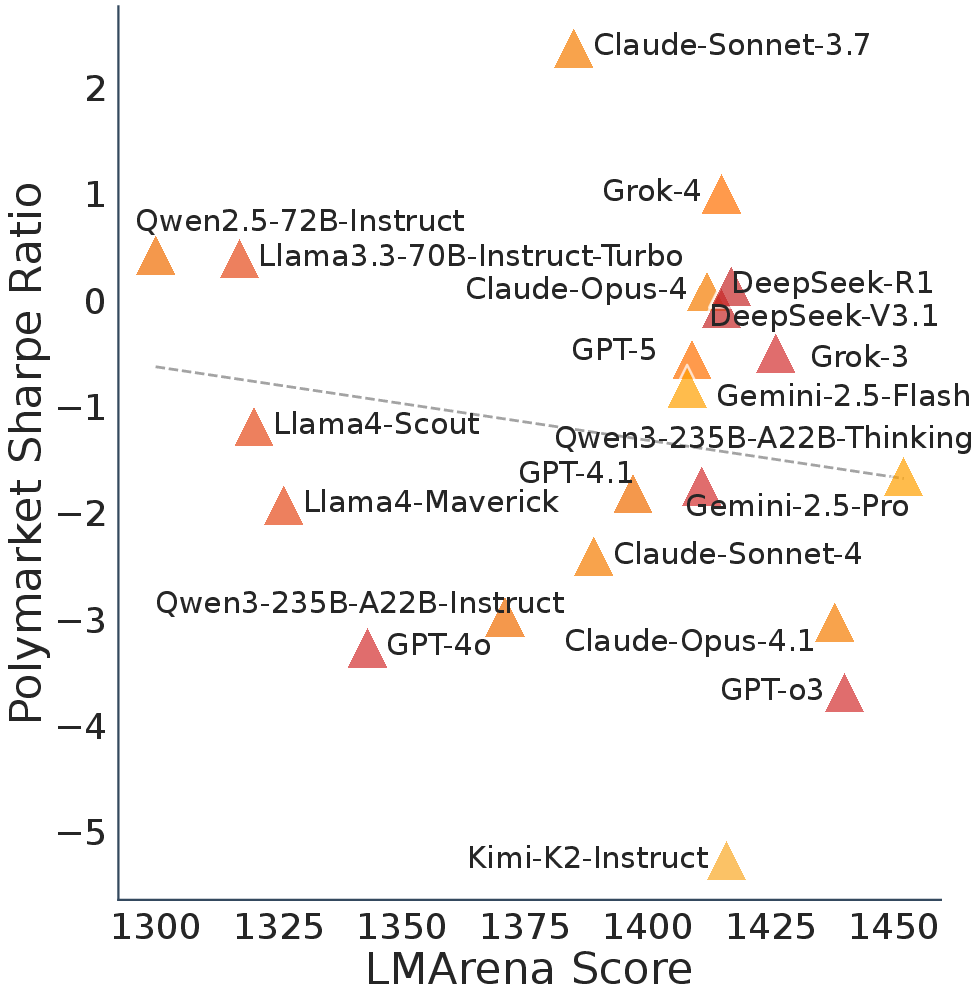
- High test scores didn’t mean better trading. Models that did great on popular AI leaderboards (like LMArena) didn’t necessarily make the best live trading choices. In some cases, the correlation was even slightly negative.
- Success didn’t transfer across markets. Doing well in U.S. stocks didn’t predict doing well in Polymarket. The two markets require different instincts: stocks reward patient, balanced strategies; Polymarket demands quick reactions to events.
- Different models showed different “styles.” Some were cautious (lower swings and smaller losses), others were aggressive (chasing higher returns with bigger risks). Cash handling and which assets they favored varied a lot.
- “Big reasoning” models weren’t automatically better traders. Models designed to think longer didn’t outperform; in fact, some took on more risk and bounced around more, which hurt consistency.
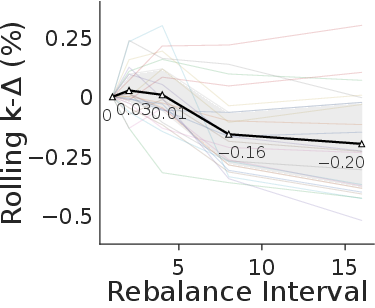
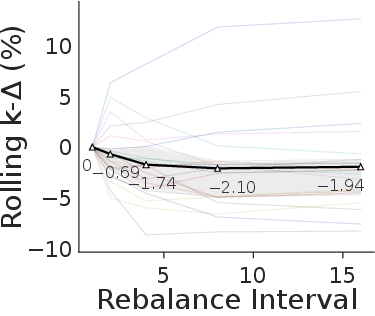
- The AIs used live signals, not random guessing. When the researchers delayed the models’ decisions by a few days (as if reacting late), performance got worse—especially in the fast-moving Polymarket. That means models were actually adapting to fresh information.
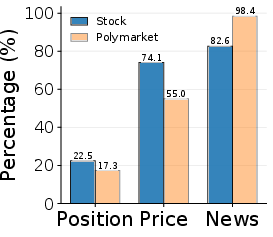
- What guided their reasoning? In stocks, models leaned more on price trends; in Polymarket, they leaned more on news. Many decisions combined multiple cues.
Why this matters: It shows a gap between old-style, static tests and real-world decision-making. Live, sequential choices under uncertainty are a different skill.
Why does this matter?
- Better, fairer testing: LiveTradeBench avoids “information leakage” (no using future data by accident) and measures what really counts—timely, consistent decisions in the face of uncertainty.
- Smarter AI for real tasks: If we want AIs that help with investing (or any live, changing domain like logistics, health monitoring, or online safety), we need benchmarks that test adapting over time—not just solving one-off puzzles.
- New research directions: Results suggest we need market-aware training, improved risk management, and reasoning tuned for noisy, fast-changing signals—not just bigger models.
- Practical insight: Different markets need different strategies. A one-size-fits-all AI won’t cut it; models must adapt their “style” to the context.
In one sentence: LiveTradeBench shows that real-world “smarts” mean making steady, sensible choices as the world changes—and that’s not what most current AI tests measure.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps and open questions that remain unresolved and can guide future research:
- Transaction costs, fees, slippage, bid–ask spreads, and liquidity constraints are not modeled; quantify their impact on performance and incorporate realistic execution (including turnover-adjusted results).
- The action cadence is unclear and inconsistent (“live” streaming vs. daily stock closes); specify and study intraday vs. daily decision frequencies in both markets, and assess sensitivity to timing/latency.
- Limited asset universe (15 U.S. equities/ETFs, 10 Polymarket contracts); evaluate generalization across broader universes (small/mid caps, international equities, fixed income, FX, crypto, futures/options).
- Long-only constraint with no shorting, leverage, derivatives, or hedging; extend to market-neutral, leveraged, and derivative-enabled portfolios, and assess risk-adjusted benefits.
- Cash asset is modeled with zero return; incorporate realistic risk-free yields (e.g., T‑bills for stocks, stablecoin yields for prediction markets) and re-evaluate Sharpe and allocation behavior.
- No comparison to strong non-LLM baselines (e.g., buy-and-hold SPY/QQQ, equal-weight, risk-parity, momentum/trend, mean–variance); add baselines to contextualize LLM performance.
- Statistical rigor is limited: no confidence intervals, no hypothesis tests, and no repeated runs; perform multi-window live evaluations, bootstrapping, and significance testing across seeds/runs.
- Single 50-day window may reflect one regime; test across multiple non-overlapping live periods, regime shifts, macro events, and stress scenarios for robustness.
- Tool-use and memory components are not ablated; quantify each component’s contribution (including memory horizon Δ), and evaluate effects of removing/altering them.
- Prompting/hyperparameters are not standardized across models; control for temperature, decoding strategy, context length, and tool permissions to ensure fair comparisons.
- News ingestion via Google News is unvalidated; evaluate coverage/latency/relevance, deduplication, sentiment quality, and conduct controlled ablations to isolate the incremental value of news.
- Prompt-injection and adversarial content risks from live news are not addressed; design defenses and measure robustness to malicious or misleading external inputs.
- Polymarket modeling abstracts away contract mechanics (fees, order book depth, liquidity, resolution timing); implement mark-to-market consistent with platform rules and evaluate unresolved vs. resolved markets separately.
- No turnover and cost metrics are reported; measure turnover, cost-adjusted returns, and identify model-specific optimal rebalancing cadence under transaction costs.
- Risk metrics are limited (Sharpe, volatility, MDD); include Sortino, CVaR, tail risk, risk-of-ruin, tracking error, and formal drawdown constraints to better capture downside risk.
- Live–live market causality is hypothesized but not tested; quantify lead–lag and information flow between prediction markets and equities (e.g., Granger causality, transfer entropy).
- Reasoning-trace analysis relies on another LLM with no validation; benchmark annotation accuracy with human experts and link rationales to measurable action features/outcomes (causal attribution).
- Reproducibility is challenging in live settings; provide complete data snapshots, time stamps, prompts, parsed actions, and deterministic replays to enable faithful post hoc replication.
- Real-world constraints (lot sizes, margin requirements, borrow availability, trading halts, market hours) are ignored; incorporate these to align with executable trading.
- No exploration of training/adaptation; compare zero-shot agents to RL/fine-tuned or online-adaptive policies, and study sample efficiency and stability under live feedback.
- Calibration in prediction markets is not assessed; evaluate belief calibration (e.g., Brier score, log loss) and align allocation exposures with probabilistic forecasts.
- Model-family analysis lacks scaling laws and resource normalization; study performance vs. model size and ensure equal tool access, token budgets, and compute constraints across families.
- Time synchronization and latency are unspecified; document streaming/data pipeline delays, market-hour alignment, and their effects on decision quality and slippage.
Practical Applications
Immediate Applications
Industry: Finance
- Algorithmic Trading Enhancement: The LiveTradeBench provides a real-time testing environment for developing and refining trading algorithms that leverage LLMs. This can be immediately integrated into existing platforms for improved decision-making under market uncertainty.
Academia
- Educational Tool for Financial Courses: The environment can be used as a practical tool in academic settings for teaching students about portfolio management, financial risk assessment, and the integration of AI in finance.
Policy
- Market Analysis and Regulation: Regulators can use the findings and methods as a benchmarking tool to assess the impact of automated trading decisions in live markets, ensuring fair trading practices.
Daily Life
- Personal Investment Advisory: The insights from the environment can be adapted into personal finance applications that assist individual investors in making real-time, informed investment decisions.
Long-Term Applications
Industry: Software Development
- Development of Advanced AI Trading Tools: Further research can be done to integrate LLMs in broader financial software systems, creating powerful tools that can handle complex multi-asset portfolios with market adaptability.
Energy and Environment
- Renewable Energy Trading Platforms: The portfolio management framework could be extended to live trading markets in renewable energy certificates or carbon credits, requiring additional development to tailor for these specific markets.
Academia
- Cross-domain AI Benchmarking: Development of new benchmarks for evaluating AI capabilities across different domains, such as finance, healthcare, and education, using environments similar to LiveTradeBench.
Assumptions and Dependencies
- Deployment of these applications assumes continuous access to real-time market data.
- Scalability of the LiveTradeBench for different assets may depend on further advancements in computational efficiency of LLMs.
- Effective implementation of personal finance applications would require robust user data privacy frameworks.
The above points synthesize the paper's focus on evaluating LLMs in trading scenarios and translating these insights into diverse, practical applications.
Glossary
- Alpha prediction: Forecasting expected excess returns (“alpha”) for assets to inform trading decisions. "Other approaches focus on alpha prediction, producing continuous vectors of alpha signals that represent expected excess returns or relative performance across assets"
- Backtesting: Evaluating a trading strategy using historical market data rather than live data. "most evaluation frameworks rely on offline backtesting, which is prone to information leakage and fails to capture the uncertainty, volatility, and feedback of real-world environments"
- Binary prediction markets: Markets whose contracts resolve to one of two outcomes (e.g., Yes/No), with prices reflecting outcome probabilities. "We continuously track ten active binary prediction markets from Polymarket"
- Chain-of-thought prompting: A prompting technique that elicits step-by-step reasoning from LLMs. "Similar to chain-of-thought prompting~\citep{wei2022chain}"
- Complementary assets: Paired assets representing opposing sides of a binary contract. "each binary contract corresponds to two complementary assetsâYES and NO"
- Endogenous portfolio adjustment: Changes to an agent’s holdings caused by its own actions. "and an endogenous portfolio adjustment induced by the agentâs allocation decision under the new market state"
- Exogenous market-state evolution: Market changes driven by external dynamics independent of the agent’s actions. "an exogenous market-state evolution, governed by real-world dynamics and observable as "
- Information leakage: Unintended use of future or unavailable information that biases evaluation results. "most evaluation frameworks rely on offline backtesting, which is prone to information leakage"
- Latent market state space: The unobserved true state of the market underlying observed data. "where is the latent market state space"
- Liquidity: The ease of trading an asset without significantly affecting its price. "including asset fundamentals, volatility, liquidity, and other unobserved factors"
- LMArena: A benchmark of general LLM capabilities used as a reference for model performance. "high LMArena scores do not imply superior trading outcomes"
- Long-only setting: A portfolio constraint that allows only nonnegative positions (no short selling). "By default, we assume a long-only setting where for all "
- Maximum drawdown (MDD): The largest peak-to-trough decline in portfolio value during an evaluation period. "maximum drawdown (MDD)"
- Memory horizon: The length of historical observations the agent retains for decision-making. "where denotes the memory horizon"
- Observation emission function: The function mapping latent states to observable data. "and the observation emission function"
- Partially observable Markov decision process (POMDP): A decision-making framework where an agent acts with incomplete information about the true state. "We formulate the portfolio management task as a partially observable Markov decision process (POMDP)"
- Probability simplex: The set of allocation vectors whose nonnegative components sum to one. "the probability simplex action space"
- Portfolio rebalancing: Adjusting holdings to match target allocation proportions. "through proportional rebalancing"
- Prediction market: A market where contract prices reflect the crowd’s beliefs about future events. "Polymarket prediction market"
- ReAct framework: An agent paradigm that interleaves explicit reasoning with actions. "follows the ReAct~\citep{yao2022react} framework"
- Rolling-k delta: A diagnostic that measures performance degradation when actions are delayed by k days. "rolling- delta () analysis"
- Risk-free rate: The theoretical return of an investment with zero risk, used in risk-adjusted metrics. "r_f is the risk-free rate representing the baseline return from a no-risk investment"
- Sharpe ratio: A risk-adjusted performance metric equal to excess mean return divided by return volatility. "Sharpe ratio ()"
- Spearman correlation: A rank-based measure of association between two variables. "the Spearman correlation between LMArena scores and cumulative returns is only 0.054"
- Temporal de-biasing: Procedures to reduce time-related contamination or bias in backtests. "temporal de-biasing protocols"
- Transition dynamics: The rules governing how states evolve over time in an MDP/POMDP. "and the transition dynamics"
- Tree-based searching: Planning method that explores possible action sequences via a search tree. "support tree-based searching~\citep{Koh2024TreeSFA,Putta2024AgentQAA,Aksitov2023ReSTMRA}"
- Volatility: The variability of returns, commonly used as a measure of risk. "Strategies with lower volatility exhibit more stable performance over time"
- Win rate: The proportion of time steps with positive returns. "Win rate ()"
Collections
Sign up for free to add this paper to one or more collections.