Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Abstract: LLMs are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present \textbf{Agent-World}, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI assistants (like smart chatbots) to act more like helpful “doers,” not just talkers. The authors build a big, realistic “practice world” called Agent‑World where an AI can use tools (like search, calendars, or databases), solve multi‑step tasks, get checked by automatic graders, spot what it’s bad at, and then practice more on exactly those weak spots. Over time, the AI keeps improving in a loop—like a student who gets new lessons based on past mistakes.
What questions did the researchers ask?
- How can we give AI agents a huge, realistic place to practice using tools and handling real data, not just made‑up text?
- How can we make the practice smart—so the AI is tested, its weaknesses are found, and new training tasks are created to fix those weaknesses?
- Does this kind of “self‑evolving” practice actually make the AI better across many different challenges?
How did they do it?
The project has two main parts that work together: building the worlds and training the agent in a self‑improving loop.
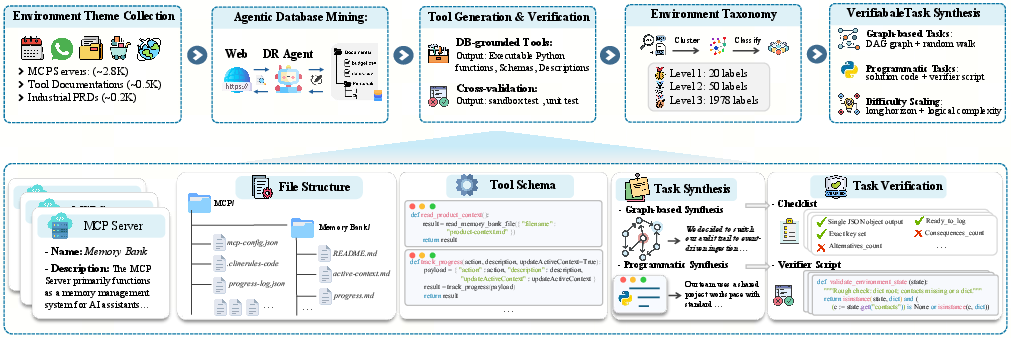
Building realistic practice worlds (Environment–Task Discovery)
Think of this as making thousands of mini “workplaces” for an AI:
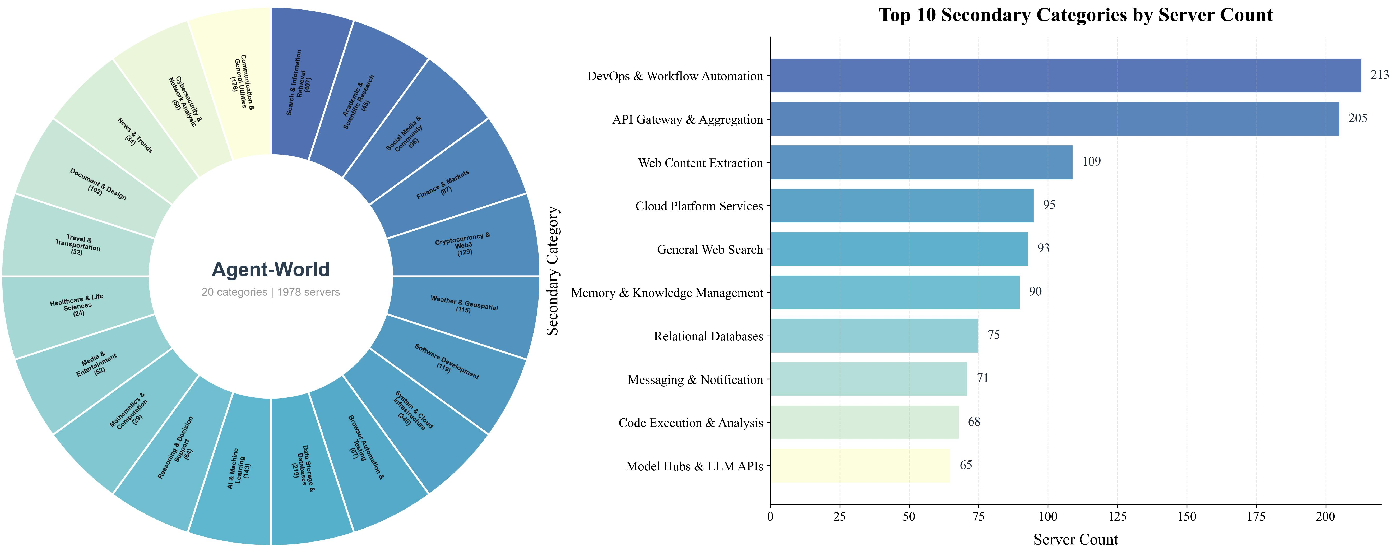
- Real topics and data: They start with thousands of real topics (like travel, shopping, or science tools). A “research agent” gathers structured, trustworthy data from the web to build databases for each topic.
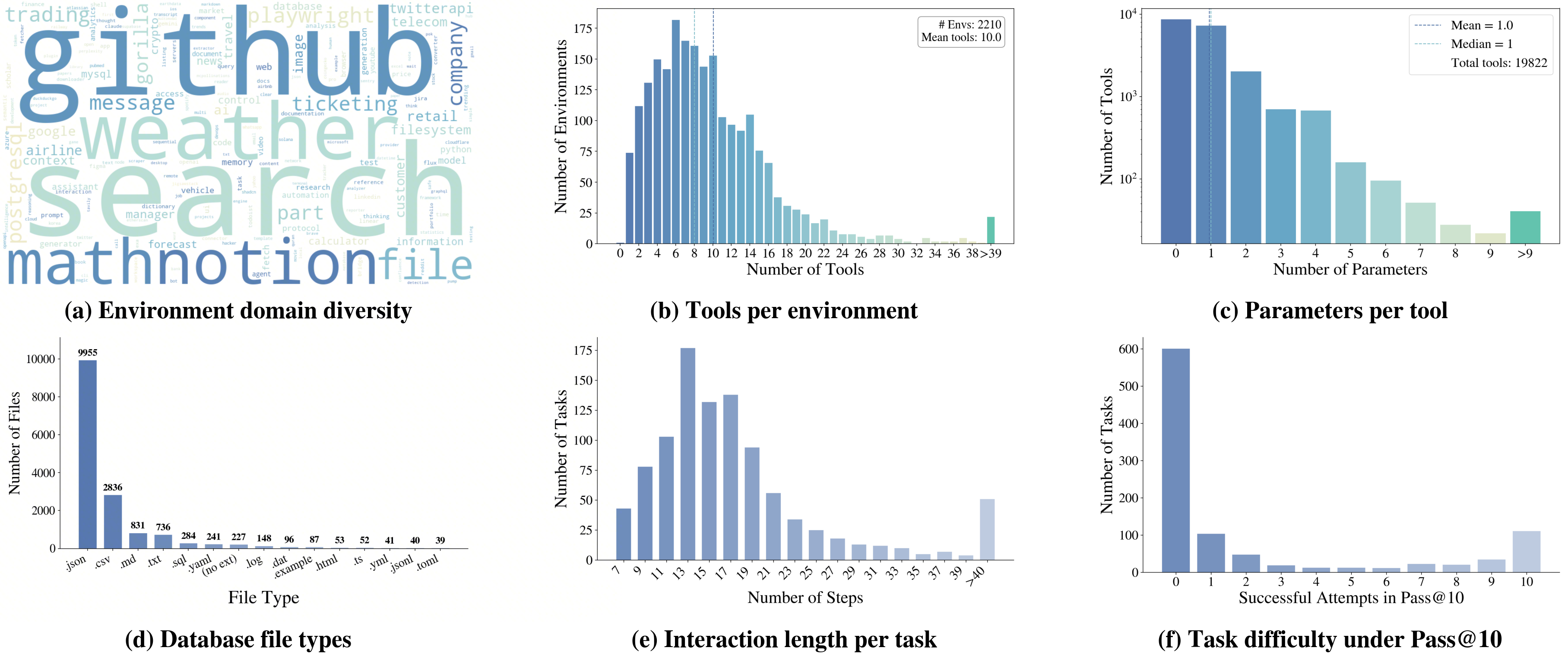
- Tools with tests: They auto‑create tool functions (like “search_flights” or “add_to_calendar”) and attach unit tests to make sure those tools actually work. Only tools that compile and pass tests are kept.
- Flowchart puzzles: To create tasks, they connect tools into flowcharts (a graph), then turn these flows into puzzles the AI must solve—without telling it which tools to use. This makes the tasks feel like real multi‑step problems.
- Adjustable difficulty: They can make tasks harder by adding more steps, mixing tools in trickier ways, and hiding obvious hints—so the AI must figure out the right sequence itself.
- Automatic grading: Each task comes with a clear, machine‑checkable checklist or validator. The agent’s actions can change the database (like booking something), and the grader checks that the final state and answer are correct.
Training an agent that improves itself (Self‑Evolving Training)
Think of this as a “coach + gym + video‑game levels” loop:
- Many environments, real feedback: The AI practices across lots of different worlds. It chooses actions (use a tool or respond), tools run in a safe sandbox, and the database updates. Rewards come from automatic checks, not just the final answer.
- Diagnosis arena: After a training round, the agent is tested on fresh tasks. A “diagnosis agent” analyzes failures (like wrong tool order or bad data handling) and pinpoints where the AI is weak.
- Targeted new tasks: The system then generates new tasks focused on those weaknesses, and can “complexify” the databases to add more variety.
- Iterate: The AI trains again on these targeted tasks. Repeating this builds a co‑evolution loop: as the AI improves, the worlds and tasks evolve too.
In everyday terms: it’s like a personalized video game that keeps generating new levels based on what you struggled with last time.
What did they find?
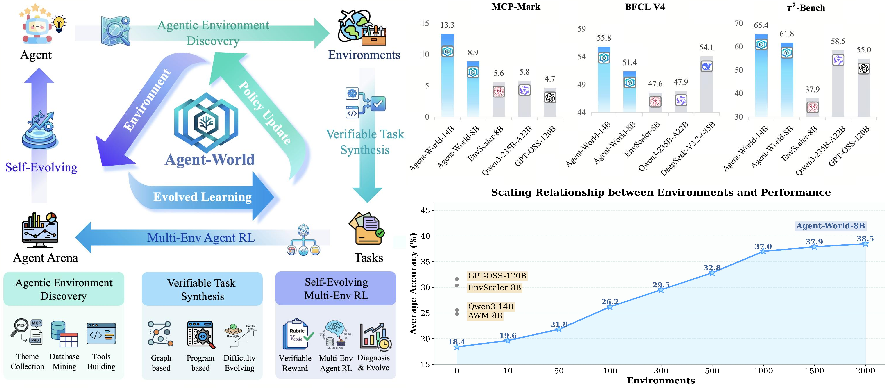
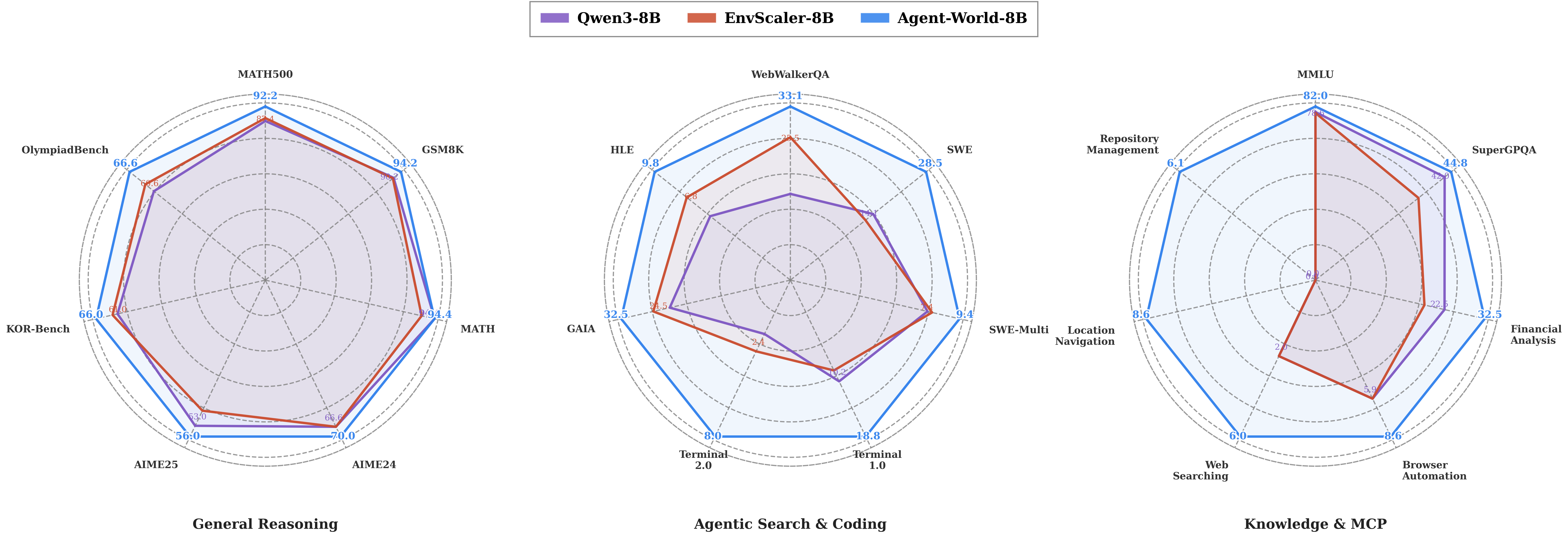
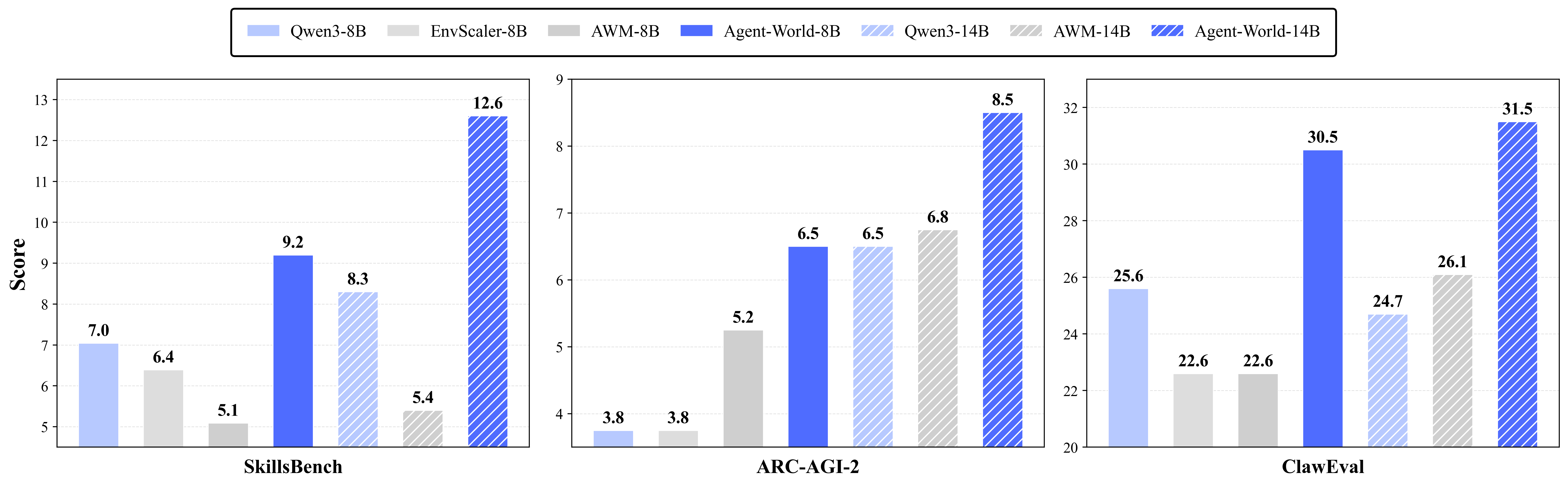
- Better overall performance: Their trained models (Agent‑World‑8B and Agent‑World‑14B) beat strong proprietary models and other scaling baselines on 23 tough benchmarks. These tests included tool use, software tasks, deep research, and general reasoning.
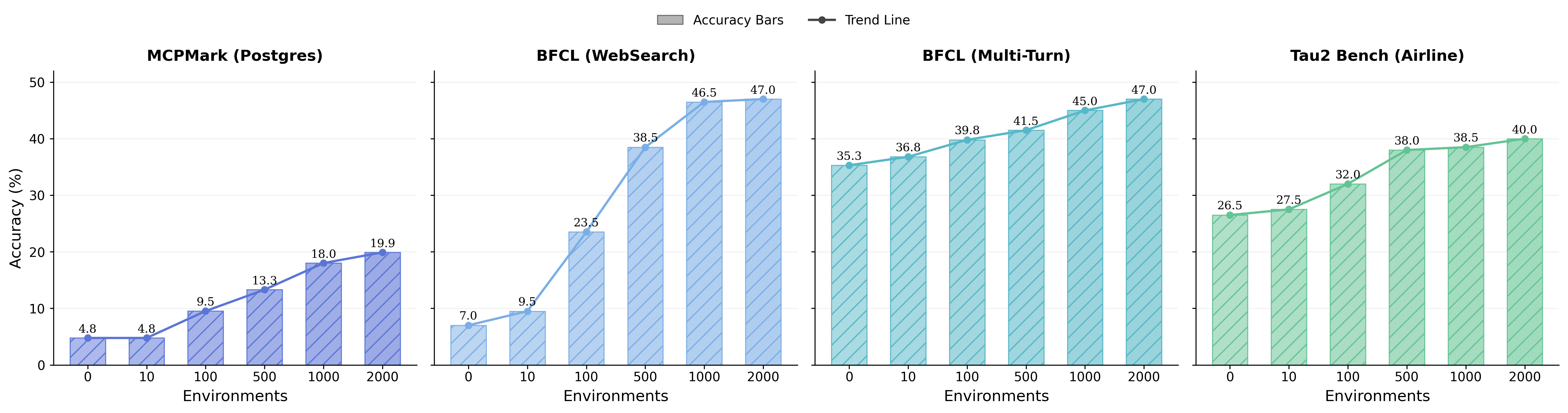
- Scaling helps: More diverse environments and more rounds of the self‑evolving loop led to better results. In short, breadth (variety of worlds) and persistence (keep iterating) both matter.
- Stronger real‑world skills: The gains were especially clear on tasks that need multiple steps, correct tool order, and tracking changes to the environment (like “check → do → update” workflows).
Why does this matter?
- Toward reliable “general” agents: Realistic practice plus targeted self‑improvement helps AI move from chat to action—using tools correctly, following steps, and handling changing information like a capable assistant.
- Less manual work: Instead of people hand‑crafting every training task, the system mines real data, builds tools with tests, and automatically creates and verifies tasks at scale.
- Practical impact: This approach can power better AI helpers for research, operations, software engineering, and everyday tasks that require careful multi‑step work.
- A roadmap for growth: The paper shows that if you keep expanding environment variety and keep the self‑evolving loop running, agents keep getting better—offering a clear path to building more general, dependable AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up research:
- Environment realism and dynamics
- Lack of evidence that the mined “real” databases are live or time-evolving; it is unclear how the approach handles real-time APIs, streaming data, rate limits, and external state drift beyond static snapshots.
- No assessment of how well synthesized environments mirror real-world workflows (schema coverage, inter-tool dependencies, failure modes); a systematic realism audit is missing.
- Absence of metrics characterizing environment complexity (e.g., tool-graph depth, branching factor, mutability) and coverage across domains; difficulty is controlled heuristically without ground-truth calibration.
- Task generation and reward fidelity
- Rewards for “graph-based tasks” rely on a rubric-conditioned LLM judge; the robustness, inter-annotator agreement, and bias of this judge are not quantified. Deterministic, state-based validators are not consistently enforced.
- The paper presents a verifiable reward only for graph-based tasks; it is unclear how rewards are defined for programmatic tasks or how to unify reward definitions across task types.
- Risk of reward hacking is unaddressed (e.g., exploiting rubric phrasing vs achieving correct state transitions). No adversarial stress testing of reward robustness is reported.
- Tool generation and verification
- Tool acceptance threshold (>0.5 unit-test pass rate) is low; the impact of noisy or partially correct tools on policy learning remains unexplored.
- No study of tool robustness under out-of-distribution inputs, error propagation, or adversarial inputs (e.g., malformed parameters, injected payloads).
- Tool provenance, licensing, and maintenance (versioning, updates) are not described, raising reproducibility and legal questions for released environments.
- Diagnostic arena and curriculum design
- The diagnosis agent’s reliability is unverified—how accurate are its failure attributions and how stable are its recommendations across runs and seeds?
- Curriculum stability is not studied: does the self-evolving loop avoid mode collapse, oscillatory curricula, or overfitting to generated weaknesses?
- Criteria for “database complexification” (what to add, how much, when to stop) are underspecified; no ablation on complexification intensity vs learning gains.
- Continual learning and forgetting
- The pipeline claims lifelong learning but provides no analysis of catastrophic forgetting across evolution rounds or mechanisms to preserve prior skills (e.g., replay buffers, regularization).
- No diagnostics on skill retention across domains when new environments/tasks are introduced.
- Generalization and contamination
- Potential data leakage is unaddressed: overlap between mined web data/tools and the 23 evaluation benchmarks is not ruled out (topic, content, or template similarity).
- Cross-model dependence is possible: the same (or similar) LLMs are used for environment/task generation, judging, and training, risking generator–evaluator coupling. No cross-judge or cross-generator validation is presented.
- Zero-shot generalization to unseen tool schemas and domains is asserted but not stress-tested with explicit hold-out strategies (e.g., tool families, API patterns, or taxonomy tiers withheld from training).
- Methodological and reporting clarity
- Model details for “Agent-World-8B/14B” (base architectures, initialization, pretraining data, RL compute budgets, training durations) are missing; this prevents reproducibility and fair comparison.
- GRPO application specifics (group size, advantage computation for long-horizon tool calls, token- vs action-level credit assignment) are not fully specified; off-policy effects and variance control are unreported.
- No formal scaling law is provided despite claims of “scaling relationships”; quantitative fits, exponents, and confidence intervals are absent.
- Benchmarking and ablations
- The list and composition of the 23 benchmarks are not enumerated; task distributions, overlap with training domains, and evaluation protocols (seeds, retries) are unspecified.
- Critical ablations are missing: single-round vs self-evolving training, with/without diagnosis agent, with/without database complexification, and LLM-judge vs code validator rewards.
- Cost–performance trade-offs (compute, wall-clock, energy, tool execution overhead) are not benchmarked, hindering practical adoption.
- Safety, security, and governance
- No discussion of sandboxing guarantees, OS/tool isolation, prevention of prompt/command injection, or data exfiltration risks during agent–tool–OS interactions.
- Absence of red-teaming for unsafe tool behaviors (e.g., destructive file ops) or policies for dangerous requests; no alignment measures for tool use are described.
- Legal/ethical considerations for web data mining (copyright, PII handling, licenses) are not addressed.
- Multimodality, multi-agent, and interaction richness
- The approach appears text- and code-centric; extensions to multimodal tools (e.g., vision, audio) and stateful GUIs are not evaluated.
- Multi-agent coordination, role specialization, or competitive/cooperative settings are not explored, despite relevance to complex real-world workflows.
- Robustness to environment/tool failure
- The agent’s behavior under partial tool outages, latency spikes, stale caches, or inconsistent DB states is untested. Recovery strategies (fallbacks, retries, rollbacks) are not designed or evaluated.
- Reproducibility and release
- The project page/release status is unclear, and the dynamic task synthesis makes exact replication difficult; there is no documented protocol for snapshotting environments, tools, and tasks with fixed seeds.
- Taxonomy construction (LLM-driven clustering/merging) lacks validation against human-curated ontologies; reproducibility of taxonomy labels is unproven.
- Theoretical foundations and guarantees
- No theoretical analysis of convergence or stability for the self-evolving loop (coupled data generation and policy updates) is provided.
- The credit assignment problem for long-horizon, stateful tool use is left open; principled methods to align token-level GRPO with environment-level goals are not developed.
Practical Applications
Immediate Applications
The paper introduces Agent-World’s environment-task discovery and self-evolving training loop, enabling concrete uses that can be deployed with current tools and standards (e.g., MCP, Python sandboxes, unit-test–backed tool verification).
- Agent QA and benchmarking via a self-evolving arena
- Sectors: software, AI platforms, academia
- What it delivers: A dynamic, stateful evaluation harness that synthesizes fresh, verifiable tasks across diverse environments to measure agent performance and robustness over time.
- Potential tools/products/workflows: “Arena-as-a-Service” for internal QA; procurement/vendor comparisons; continuous benchmarking dashboards; integration with MCP-Universe, τ²-Bench-like suites.
- Assumptions/dependencies: Availability of MCP-compatible tools/databases; stable execution sandboxes; LLM-judge accuracy for rubric scoring; compute budget for periodic evaluations.
- Capability-gap diagnosis and targeted curriculum generation
- Sectors: software (agent teams), AI operations (MLOps), academia
- What it delivers: Automatic aggregation of failure traces and environment metadata to identify weak skills (e.g., tool orchestration, state updates), then synthesize targeted training tasks to close gaps.
- Potential tools/products/workflows: Diagnostic dashboards; auto-curriculum builders; prioritized task packs by skill; closed-loop training pipelines (GRPO) wired into CI for agents.
- Assumptions/dependencies: Logging/telemetry from agent runs; reliable task synthesis and validators; careful control of overfitting to synthesized patterns.
- MCP toolchain CI/CD (tool generation, unit testing, schema validation)
- Sectors: software (platforms, API providers)
- What it delivers: Automated design of tool interfaces and tests, retention of tools that compile and pass minimum accuracy, providing a quality gate for MCP servers and API harnesses.
- Potential tools/products/workflows: Toolsmith bots; unit-test generation; “MCP readiness” checks; regression tests on API updates.
- Assumptions/dependencies: Access to tool docs/specs; legal use of API endpoints; unit tests reflecting real behavior; versioning and sandboxing for safe execution.
- Data and environment pack creation for internal workflows
- Sectors: finance, e-commerce, travel, customer support, enterprise IT
- What it delivers: Topic-aligned database mining and complexification to create realistic, up-to-date environment “packs” (data + tools) mirroring internal workflows for training/QA.
- Potential tools/products/workflows: Internal MCP environment registries; workflow replay sandboxes (e.g., booking, case management); golden paths and failure-mode packs.
- Assumptions/dependencies: Data licensing/compliance; redaction and PII handling; mapping internal APIs to MCP; security review of tool execution.
- Instructor-led teaching labs and competitions for agentic tool use
- Sectors: education, academia
- What it delivers: Verifiable, difficulty-scaled tasks and stateful environments for hands-on courses (POMDPs, tool RL), with executable rubrics and validators.
- Potential tools/products/workflows: Courseware; hackathon challenge suites; student progress analytics by skill taxonomies.
- Assumptions/dependencies: Classroom compute/sandboxing; calibrated judges; curated content for pedagogy; minimized reliance on proprietary APIs.
- Rapid onboarding of new APIs/skills into agents
- Sectors: software, SaaS ecosystems
- What it delivers: Graph-based task synthesis to quickly generate multi-tool workflows and validators for new APIs, shortening time-to-robust agent behavior.
- Potential tools/products/workflows: API onboarding playbooks; auto-generated skill demos; post-integration robustness tests.
- Assumptions/dependencies: Clear tool schemas; reliable dependency graphs; stable API availability during synthesis/testing.
- Pre-deployment safety checks for stateful interactions
- Sectors: finance, healthcare (non-critical workflows), operations
- What it delivers: Executable rewards/rubrics to confirm correct state transitions and sequencing (e.g., “check inventory → book → update calendar”), reducing deployment regressions.
- Potential tools/products/workflows: Safety gates in release pipelines; state-diff validators; rollback simulations in sandboxed envs.
- Assumptions/dependencies: High-fidelity environment states; coverage of critical paths; human-in-the-loop review for high-stakes use.
- Knowledge management and research assistants in sandboxes
- Sectors: R&D, enterprise knowledge management
- What it delivers: Autonomous database mining for topic corpora (with iterative complexification) to keep testbeds current and evaluate research agents’ retrieval/citing behaviors.
- Potential tools/products/workflows: Research sandboxes; citation verification tasks; change-detection and re-evaluation schedules.
- Assumptions/dependencies: Crawler legality; deduplication, provenance tracking; recurrent updates to avoid staleness.
Long-Term Applications
These rely on broader ecosystem adoption (e.g., MCP standardization), domain validators, governance, and additional research to meet safety and performance requirements.
- Continuous-learning “digital workers” across enterprise systems
- Sectors: enterprise software, back-office automation, customer ops
- What it delivers: Agents that co-evolve with their task environments, continually diagnosing gaps and learning new workflows/tools.
- Potential tools/products/workflows: Always-on self-evolving loops connected to production mirrors; SLA-aware upgrade cycles; automated change-impact analyses.
- Assumptions/dependencies: Robust sandbox mirroring; change control; privacy and access governance; guardrails for uncontrolled behavior.
- Domain-safe generalist agents in high-stakes settings
- Sectors: healthcare, finance, legal
- What it delivers: Verifiable, rubric-checked task frameworks aligned to domain policies (e.g., HIPAA, SOX), enabling trustworthy multi-tool orchestration.
- Potential tools/products/workflows: Domain-specific validators; compliance-aware task packs; auditable traces with policy-aware judges.
- Assumptions/dependencies: Expert-crafted rubrics/validators; certified data sources; human oversight; liability frameworks.
- Standardized agent safety/compliance certification
- Sectors: policy/regulation, standards bodies
- What it delivers: Dynamic, stateful test suites as a certification protocol for agent deployments (analogous to safety “driving tests” for agents).
- Potential tools/products/workflows: Public registry of certified environment packs; third-party audits; industry benchmarks tied to release gates.
- Assumptions/dependencies: Cross-vendor agreement on schemas and metrics; transparent, reproducible validators; governance for test updates.
- Cross-organization agent marketplaces and environment registries
- Sectors: software platforms, ecosystems (SaaS, marketplaces)
- What it delivers: Shareable “environment packs” (database + tools + tasks) for onboarding partners, facilitating faster integration and evaluation.
- Potential tools/products/workflows: Environment-pack stores; partner certification flows; shared taxonomy for discoverability.
- Assumptions/dependencies: IP/licensing for datasets; secure distribution; consistency across MCP versions.
- Robotics and embodied tool use via stateful API bridges
- Sectors: robotics, logistics, manufacturing
- What it delivers: Extending stateful tool APIs to device APIs (control, telemetry), allowing agents to learn orchestrations that affect physical states with executable verification.
- Potential tools/products/workflows: Digital twins with API parity; environment-task graphs mapped to robot skills; closed-loop training with safety envelopes.
- Assumptions/dependencies: High-fidelity simulators/digital twins; real-time constraints; rigorous safety certification before physical deployment.
- Grid and facility operations assistants
- Sectors: energy, facilities management
- What it delivers: Workflow-verified assistants for scheduling, maintenance, and anomaly triage across multiple tools/databases.
- Potential tools/products/workflows: Multi-tool orchestration policies; state auditors; ops dashboards with agent-driven remediation proposals.
- Assumptions/dependencies: Integrations with legacy systems; event-driven validators; robust rollback plans.
- Federated and privacy-preserving environment synthesis
- Sectors: healthcare, finance, public sector
- What it delivers: On-prem or federated environment-task discovery where data never leaves organizational boundaries, enabling self-evolving training without centralizing sensitive data.
- Potential tools/products/workflows: Federated “arena nodes”; privacy-preserving judges; differentially private telemetry.
- Assumptions/dependencies: Federated MLOps; secure enclave support; compliance sign-off.
- Knowledge-update agents with continual environment refresh
- Sectors: academia, media, research organizations
- What it delivers: Agents that mine and re-structure evolving web content into databases, learn new tool workflows, and keep reasoning aligned with current information.
- Potential tools/products/workflows: Scheduled refresh pipelines; drift detection; re-certification of skills after large web changes.
- Assumptions/dependencies: Content provenance and licensing; robust change-verification; mitigation of misinformation.
- Unified agent MLOps standards for self-evolving loops
- Sectors: ML infrastructure, platforms
- What it delivers: Standard interfaces for evaluation, diagnosis, targeted task generation, and RL updates across diverse environment packs.
- Potential tools/products/workflows: GRPO-based training services; plug-in validators; orchestration templates integrated with CI/CD.
- Assumptions/dependencies: Wide MCP adoption; interoperable metadata/taxonomies; cost controls for frequent retraining.
- Public-good simulators for policy and service delivery
- Sectors: government, NGOs
- What it delivers: Stateful, verifiable simulations of citizen-facing workflows (applications, bookings, benefits) to test agents for accessibility, correctness, and fairness.
- Potential tools/products/workflows: Open environment packs for civic workflows; fairness-aware rubrics; public scorecards.
- Assumptions/dependencies: Open data availability; equity-aware validation metrics; stakeholder oversight and transparency.
Glossary
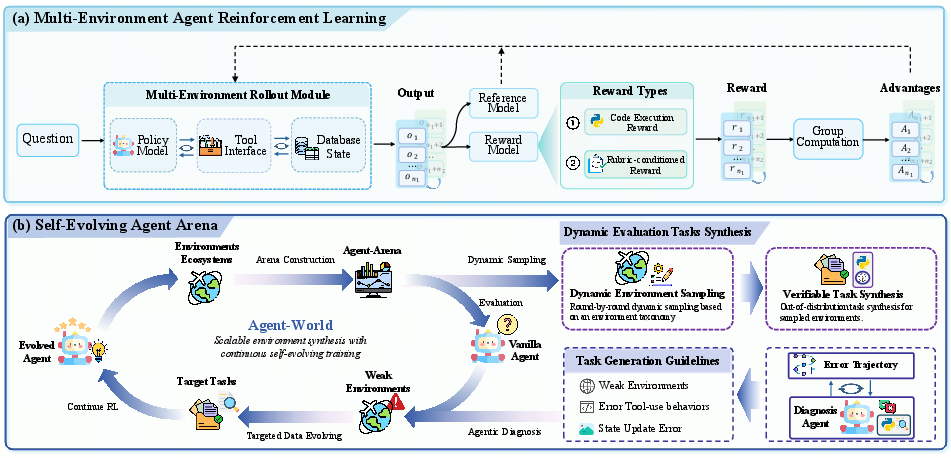
- Agent–tool–database interaction: A closed-loop pattern where an agent decides on tool calls that read/write a database and uses the resulting feedback to guide subsequent actions. "our training implements a closed-loop ``agent--tool--database'' interaction"
- Agentic diagnosis: An approach where an agent analyzes failures and environment metadata to identify capability gaps and guide targeted training. "Agentic Diagnosis."
- Agentic Environment-Task Discovery: A pipeline that mines real-world databases and executable tools from themes and synthesizes verifiable tasks. "We propose Agentic Environment-Task Discovery, which mines realistic executable environments from real-world environment themes and synthesizes diverse verifiable tasks with controllable difficulty."
- Agentic reinforcement learning (Agent RL): Reinforcement learning focused on tool-using agents operating in interactive environments. "With the rise of agentic reinforcement learning (Agent RL), several agent systems built on static tool environments have demonstrated strong practical value"
- Closed-loop training: A training paradigm where evaluation, diagnosis, and data generation feed back into subsequent training rounds. "Agent-World follows a two-stage design that forms a closed-loop training process."
- Co-evolution: Joint evolution of agent policies and environments through iterative training and environment/task updates. "enabling the co-evolution of agent policies and environments."
- Cross-environment rollouts: Executing trajectories across independently paired environments to improve generalization. "with tasks in each global batch paired with independent environments to realize cross-environment rollouts."
- Database complexification: Iteratively enriching a mined database to increase state diversity and realism. "A database complexification process then iteratively enriches each database"
- Deep-research agent: An autonomous agent equipped with search, browsing, and coding tools to mine and structure web data. "we use a deep-research agent autonomously mines topic-aligned real-world databases and executable tool interfaces from real-world MCP themes."
- Executable rewards: Rewards computed via verifiable checks of environment state and outputs rather than only final answers. "using executable rewards for state-aware supervision."
- Executable trajectory: A full sequence of observations and actions that can be executed and verified against the environment. "This yields an executable trajectory ."
- Graph-Based Task Synthesis: A method that builds a tool-dependency graph and samples tool-call chains to generate tasks with verification. "we introduce Graph-Based Task Synthesis as follow."
- Group Relative Policy Optimization (GRPO): A policy-gradient method that optimizes relative advantages within groups of sampled trajectories. "We adopt Group Relative Policy Optimization (GRPO) to maximize the verifiable returns."
- Hierarchical clustering: A clustering technique (e.g., Ward’s method) used to build a taxonomy over environment themes. "We apply hierarchical clustering~\citep{ward1963hierarchical} over 2K+ themes"
- Hierarchical environment taxonomy: A multi-level categorization of environments used for stratified sampling and coverage. "Based on the hierarchical environment taxonomy (Sec.~\ref{section:method-env-discovery}), we construct an evaluation arena"
- MCP (Model Context Protocol): A standard interface for connecting agents with scalable tools and services. "such as the Model Context Protocol (MCP)~\citep{mcp_spec_2025}"
- Multi-environment agent reinforcement learning: RL over multiple distinct environments to train generalizable tool-using policies. "we perform multi-environment agent reinforcement learning with ``agent--tool--database'' interaction rollouts"
- Partially Observable Markov Decision Process (POMDP): A framework modeling decision-making under partial observability over states and observations. "We model multi-turn agentic interaction with external environments as a Partially Observable Markov Decision Process (POMDP)"
- Programmatic tasks: Tasks generated via executable code or programmatic procedures, often paired with validators. "consisting of both graph-based tasks and programmatic tasks"
- Python sandbox: An isolated execution environment for safely running tool chains and validators. "we execute it step-by-step in a Python sandbox"
- ReAct agent: An agent that interleaves reasoning and action steps to solve tasks. "a ReAct agent solves each task 5 times"
- Rubric-conditioned LLM judge: An LLM evaluator guided by structured rubrics to verify task success. "evaluated by a rubric-conditioned LLM judge."
- Self-evolving arena: A dynamic environment set that continuously diagnoses weaknesses and generates targeted tasks for training. "our environment ecosystem naturally serves as a self-evolving arena"
- Stratified sampling: Sampling that preserves coverage across taxonomy categories when building the evaluation arena. "we construct an evaluation arena by stratified sampling."
- Tool graph: A directed, weighted graph whose nodes are tools and edges encode call dependencies. "Tool Graph Construction."
- Tool runtime: The execution layer that runs tools against databases and manages environment-side state. "the tool runtime executes environment-specific tools in a sandbox"
- Validators: Executable checks or code used to verify that task outcomes and state changes meet specifications. "with executable rubrics or validators"
- Verifiable tasks: Tasks paired with executable rubrics or validators that allow objective success checking. "synthesizes verifiable tasks with controllable difficulty"
- Weight-biased random walk: A sampling procedure over the tool graph that favors edges by weight to generate tool-call sequences. "by performing a weight-biased random walk on "
Collections
Sign up for free to add this paper to one or more collections.