Agent World Model: Infinity Synthetic Environments for Agentic Reinforcement Learning
Abstract: Recent advances in LLM have empowered autonomous agents to perform complex tasks that require multi-turn interactions with tools and environments. However, scaling such agent training is limited by the lack of diverse and reliable environments. In this paper, we propose Agent World Model (AWM), a fully synthetic environment generation pipeline. Using this pipeline, we scale to 1,000 environments covering everyday scenarios, in which agents can interact with rich toolsets (35 tools per environment on average) and obtain high-quality observations. Notably, these environments are code-driven and backed by databases, providing more reliable and consistent state transitions than environments simulated by LLMs. Moreover, they enable more efficient agent interaction compared with collecting trajectories from realistic environments. To demonstrate the effectiveness of this resource, we perform large-scale reinforcement learning for multi-turn tool-use agents. Thanks to the fully executable environments and accessible database states, we can also design reliable reward functions. Experiments on three benchmarks show that training exclusively in synthetic environments, rather than benchmark-specific ones, yields strong out-of-distribution generalization. The code is available at https://github.com/Snowflake-Labs/agent-world-model.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about giving AI “agents” (smart computer programs that can use tools) a huge, safe playground to practice in. Instead of making agents learn in the real world—which is slow, expensive, and sometimes unreliable—the authors build 1,000 fully fake but realistic “practice worlds” (like apps for shopping, travel, finance, social media, and more). In these worlds, agents can click buttons, call tools, and change data, then see what happens—just like playing in a video game with rules that always make sense.
What questions are the authors trying to answer?
The paper focuses on simple but important questions:
- Can we automatically build lots of reliable practice worlds where agents can learn to use tools?
- Will training agents in these synthetic (fake but realistic) worlds help them do better on new, unseen tasks?
- How can we make the practice fair and accurate, so the agent gets correct feedback when it succeeds or fails?
How did they do it? (In everyday language)
Think of each practice world like a tiny app with its own “brain” and “hands”:
- The “brain” is a database (like a super-organized spreadsheet) that stores the world’s state—customers, orders, flights, posts, etc.
- The “hands” are tools (buttons or functions) the agent can call to do things—add an item to cart, change a booking, post a comment, and so on.
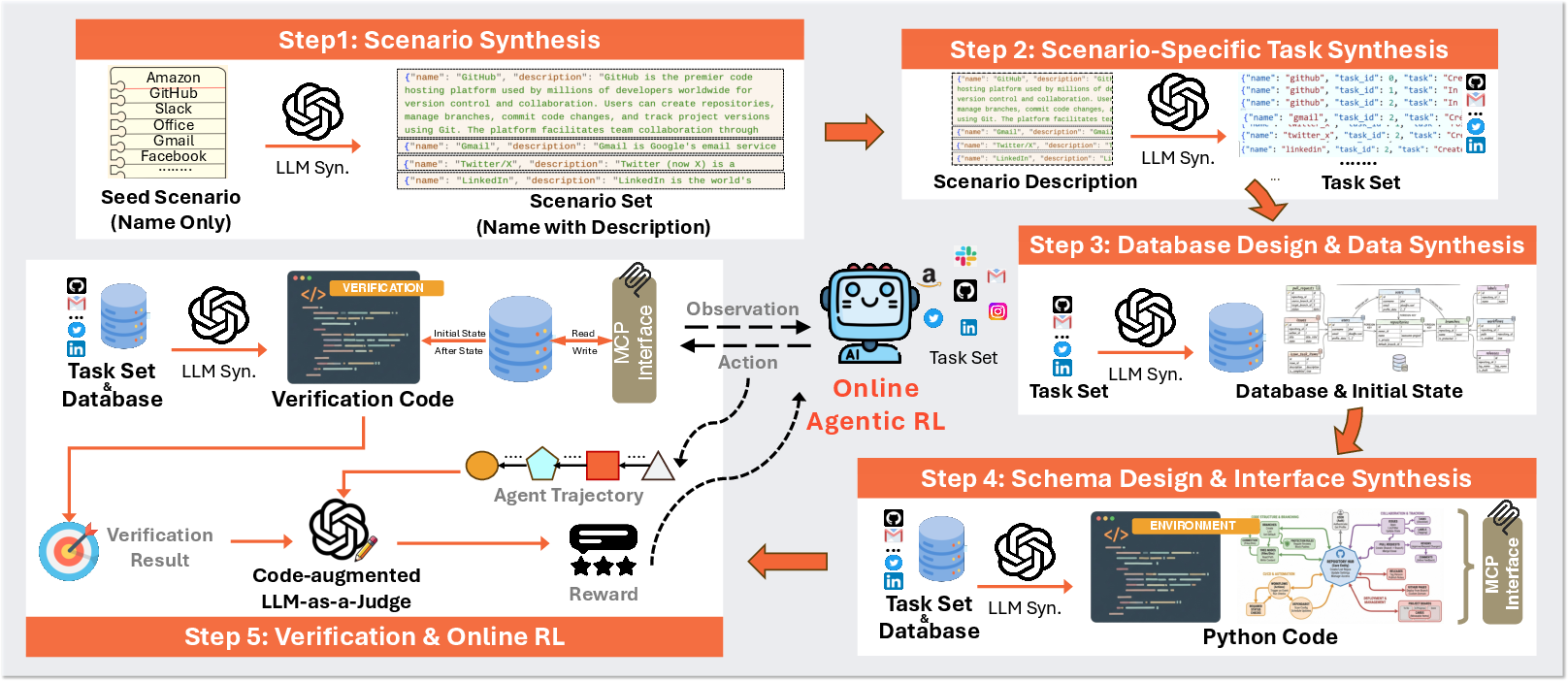
To make 1,000 different worlds, the authors followed a step-by-step pipeline. Here’s the process, using simple analogies:
- They start with an idea for a world (like “online shopping”).
- They write down typical things a user might want to do (tasks), such as “return an item” or “track an order.” These are the goals the agent must complete.
- They build a database that matches those tasks (tables and records, like sheets with rows and columns) and fill it with sample data so the tasks actually work.
- They create tools (via MCP, a standard way for agents to call functions) that read and update the database—like “place_order” or “update_address.”
- They add “referees” (verification code) that check the database before and after the agent acts to decide if the task was completed.
- If the code doesn’t run at first, they automatically fix it by rerunning it, showing the error to a LLM, and trying again. This repeat-until-it-works approach is called self-correction.
Then they train agents in these worlds using reinforcement learning (learning by trial and error), where the agent:
- Tries a sequence of tool calls,
- Gets feedback (rewards) if it completes the task, partly completes it, or makes mistakes,
- Improves over many practice runs.
Two extra details that help:
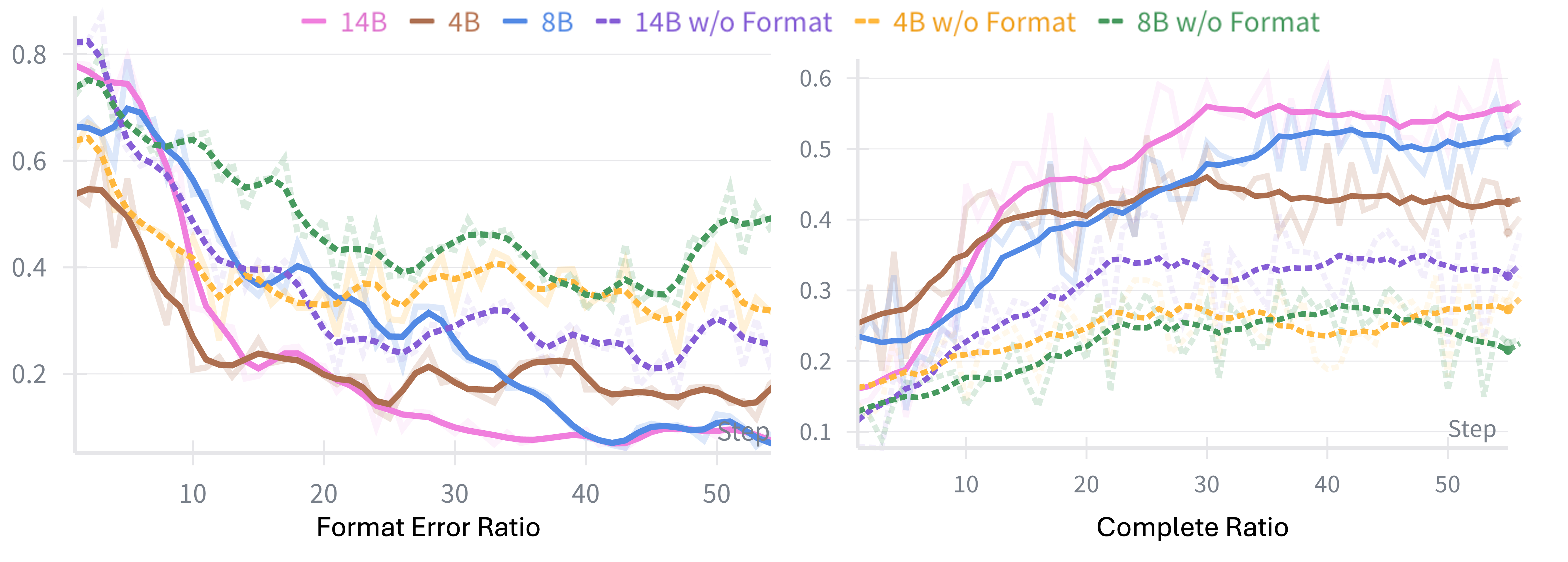
- Hybrid rewards: The agent gets small penalties if it formats tool calls incorrectly (so it learns to “press buttons” properly) and bigger rewards based on whether the final task is completed. To judge success fairly, they combine code checks with an “LLM judge” (a LLM that reviews what happened), which helps when the world’s code is imperfect.
- History-aware training: During real use, agents don’t always see the full long history (for speed, old messages are trimmed). So they train the agent with the same shortened history it will see later, keeping training and testing consistent.
What did they find, and why does it matter?
The authors built:
- 1,000 unique practice worlds,
- Around 35 tools per world on average,
- 10,000 tasks total.
They trained agents in these worlds and tested them on three public benchmarks (independent tests). The main takeaways are:
- Agents trained only in these synthetic worlds performed well on new, different tasks—this is called “out-of-distribution” generalization. In plain terms, they didn’t just memorize; they learned skills that transferred.
- Training in code-driven worlds (with real databases and tool code) beat training in purely language-model-simulated worlds. Why? Because the code worlds are consistent and don’t “hallucinate” (make things up), so feedback is more reliable and faster.
- A mix of code checks plus an LLM judge gave better reward signals than using only code checks or only an LLM judge. This hybrid judging is more robust when a world has small bugs.
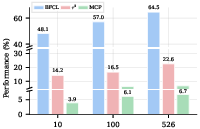
- As they added more training worlds (from 10 to 100 to 500+), agents got noticeably better. More variety leads to stronger, more flexible skills.
- Aligning training with how the agent will actually be used (shortened history) improved results compared to training with full histories.
Why is this important?
- It makes agent training cheaper, faster, and safer: Instead of relying on real websites or services (which can be slow, restricted, or costly), researchers can use these high-quality synthetic worlds.
- It’s open-source: The pipeline and many worlds are shared, so other teams can build on this work.
- It helps agents learn useful, general tool-using skills: From booking flights to managing orders, the practice worlds mirror real app logic, so the skills transfer better than if the agent only read instructions.
- It points to a path for scaling up: Thousands of reliable worlds can be created automatically, which is key for training very capable agents.
In short, the paper shows a practical way to mass-produce realistic practice environments for AI agents, prove that training in these worlds works, and provide tools the community can use to push agent learning further.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- External validity and realism
- How well do the synthesized environments capture real-world API idiosyncrasies (e.g., authentication/authorization, token refresh, rate limits, pagination, versioning, partial failures, retries, race conditions, eventual consistency)?
- The pipeline explicitly avoids UI/browser/IR tasks and post-authentication flows; how to extend to GUI/browser automation, web search, multi-modal inputs, and realistic auth flows without sacrificing executability and efficiency?
- Current transitions appear largely deterministic and synchronous; how to introduce controlled stochasticity, asynchronous events (e.g., background jobs), and time-dependent behaviors that are common in production systems?
- State and system modeling
- Environments are backed by single-node SQLite; how to model distributed state, multi-service workflows, transactional isolation anomalies, and concurrency (e.g., multi-user contention, locks, deadlocks)?
- No explicit modeling of temporal evolution or exogenous data changes; how to incorporate time-series dynamics, scheduled tasks, delayed effects, and data drift within an episode and across episodes?
- Tasks are designed to be solvable from the initial state; how to include precondition-building tasks that require multi-stage setup, inventory constraints, or long-horizon dependencies?
- Verification and reward robustness
- Heavy reliance on a closed-model LLM-as-a-Judge (GPT-5) raises reproducibility, bias, and stability questions; what is the effect of judge model choice, prompt framing, and temperature on reward noise and training outcomes?
- How vulnerable is the code-augmented judge to reward hacking (e.g., exploiting edge cases, misleading trajectories, or manipulating verification queries)? Can adversarial evaluation and adversarial training harden the verifier?
- What are principled de-noising strategies when code checks and judge decisions disagree? Can we calibrate, ensemble, or learn confidence-weighted verifiers with gold-labeled subsets?
- Environment quality and reliability
- Bug prevalence is high (74–83% environments with bugs; up to 57% blocked tasks in baselines): there is no automated regression testing suite, fuzzing, or property-based testing; can we add invariant checks, spec-based generation, and CI to reduce defects?
- How do bugs, partial implementations, and blocked tasks bias learned policies (e.g., suboptimal exploration, failure priors)? Can we quantify and mitigate such effects with counterfactual training or filtering?
- Self-correction retries (up to 5) are basic; can iterative program synthesis, unit-test generation, and repair-by-diff improve success rates and reduce manual oversight?
- Scaling and data efficiency
- Training used 526 of 1,000 environments and 96 optimization steps; scaling laws (performance vs. number of environments/tasks/steps) remain unquantified beyond this range. What are returns to scale and optimal mixes of diversity vs. depth?
- What is the cost–quality frontier for environment generation (LLM size, number of retries, prompt strategies) and for verification (judge calls per step), and how does it impact final performance?
- Generalization and evaluation breadth
- Evaluation spans three suites but excludes GUI-heavy, information-retrieval-heavy, and authenticated enterprise workflows; can we validate transfer to (i) browser automation benchmarks, (ii) live enterprise APIs, and (iii) multi-modal tool environments?
- Leakage checks are not reported; can we audit overlap between synthesized tasks/tools and test benchmarks to ensure strict out-of-distribution evaluation?
- Metrics focus on success rates; how do agents trade off efficiency (tool-call count, latency, cost), safety (refusal when appropriate), and calibration (when not to act)?
- Reward design choices
- Step-level “format correctness” shaping improves tool discipline but degrades hallucination/refusal behavior; how to design shaping that encourages appropriate abstention, uncertainty-aware behavior, and safe refusal?
- Outcome reward granularity is coarse (Completed/Partial/Other); can denser, progress-aware rewards (e.g., state-diff coverage, subgoal completion) accelerate learning without encouraging reward hacking?
- History and memory
- History-aware training uses simple sliding-window truncation (w=3); can learned memory mechanisms (e.g., retrieval, compressive memory, summarization) or selective replay improve long-horizon reasoning without training–inference mismatch?
- How do different history strategies affect credit assignment and stability with very long tasks (>20 turns) and multi-episode dependencies?
- Algorithmic choices
- Only GRPO is explored; comparisons to PPO-style token-level RL, Q-learning with tool calls as actions, advantage estimation variants, off-policy or offline RL, and imitation + RL hybrids are missing.
- How do different exploration strategies (e.g., intrinsic rewards from state novelty, tool coverage bonuses) interact with large, sparse, code-driven action spaces?
- Protocol and tooling ecosystem
- The pipeline centers on MCP; how well do learned policies transfer to other tool-calling protocols (e.g., OpenAI functions, JSON schemas), and what adaptations are required?
- Tool documentation is auto-generated; what is the impact of doc–behavior misalignment on learning and inference? Can we co-generate formal contracts/tests to ensure fidelity?
- Model and reproducibility constraints
- Synthesis and judging depend on closed models (GPT-5); what is performance with open-source generators and judges, and how sensitive is the pipeline to model capability?
- Results reported for Qwen3 (4B/8B/14B); do findings replicate across backbones (Llama, Mistral, Claude, GPT), and how does backbone pretraining (reasoning vs. general) influence gains?
- Safety and security
- No explicit permissioning, role-based access control, or audit logging is modeled; how to incorporate granular permissions and security policies to train agents in safe tool-use?
- Are environments robust to malicious inputs (e.g., injection into tool parameters), and can the training pipeline detect and discourage unsafe or privacy-violating behaviors?
- Multi-agent and multi-user dynamics
- All experiments assume a single agent and single-user state; how to extend to multi-agent coordination, negotiation, shared resources, and conflict resolution with realistic contention patterns?
- Diversity measurement and coverage
- Diversity metrics rely on embeddings and category counts; can we introduce structural metrics (tool-graph topology, API schema entropy, state-machine complexity) and coverage targets to avoid hidden mode collapse?
- How to actively steer synthesis toward underrepresented domains (e.g., healthcare, logistics) and task types (e.g., scheduling with resource constraints, streaming analytics)?
- Hybrid and real-world integration
- Pathways to hybrid training (mixing synthetic environments and live APIs) are not explored; how to design curricula that gradually introduce real-world noise, latency, and failure modes while retaining training efficiency?
- Lifecycle and self-evolution (partially acknowledged)
- The pipeline is a fixed generation process; how to implement self-evolving loops where trained agents find environment bugs, missing tools, or new tasks, and feed them back into synthesis with automatic validation and deduplication?
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, directly leveraging the paper’s open-source pipeline, released environments, and training/evaluation practices.
Industry and Software
- Agent CI/CD and regression testing for tool-use agents
- Description: Stand up a “synthetic app farm” of MCP-backed environments to run nightly regression suites on internal or vendor agent releases; catch tool-call format errors, broken reasoning chains, and changes in tool schemas before production.
- Sectors: Software, platform engineering, developer tools
- Potential products/workflows: “Agent CI” service integrating the paper’s step-level format rewards as linting/early-termination checks; GRPO-based smoke tests across 100–1,000 synthetic apps; dashboards of pass/fail by tool and scenario.
- Assumptions/dependencies: MCP adoption or adapters; containerized orchestration to launch hundreds–thousands of isolated env instances; budget for LLM-as-a-Judge or code-only checks when cost-sensitive.
- Synthetic integration testing for internal APIs and microservices
- Description: Use the database-backed environments to mimic business backends (CRUD-heavy workflows) and validate API contracts, schema migrations, and failure handling with grounded state transitions instead of flaky LLM simulators.
- Sectors: Software, enterprise IT
- Potential products/workflows: “Contract Guard” that auto-generates MCP tool schemas from OpenAPI/DB schemas, runs differential tests before/after releases, and flags breaking changes.
- Assumptions/dependencies: Mappings from real schemas to synthetic analogs; stable DB seeds; test data governance.
- Internal agent benchmarking and vendor evaluation
- Description: Compare multiple agent stacks across a fixed, diverse, SQL-grounded environment set for tool-use performance, long-horizon reliability, and hallucination resistance.
- Sectors: Software procurement, platform teams
- Potential products/workflows: Continuous benchmark harness combining BFCL-like tests, τ2-style multi-turn tasks, and custom KPIs (latency, cost per successful task).
- Assumptions/dependencies: Common telemetry format; cost guardrails for judge calls.
- Rapid prototyping of enterprise automations (CRM, e-commerce, ticketing)
- Description: Prototype agents for order management, returns, lead updates, inventory checks against realistic synthetic backends; swap synthetic MCP servers for real APIs once flows stabilize.
- Sectors: Retail, CRM/SaaS, operations
- Potential products/workflows: “Sandbox-to-Prod” playbook: scenario and task generation → RL fine-tuning with history-aware training → staged rollout on real endpoints.
- Assumptions/dependencies: Availability of corresponding real tools/APIs; drift handling between synthetic and production schemas.
- Tool interface design and documentation assistant
- Description: Use the toolset schema generation to draft consistent, minimal MCP/FC endpoints with typed parameters and response schemas aligned to tasks; iterate with execution-based self-correction.
- Sectors: Developer tools, API design
- Potential products/workflows: “ToolBench Studio” that converts user stories into DB schemas and MCP tools, emits tests and verification modules automatically.
- Assumptions/dependencies: Human-in-the-loop review for security, PII handling, and access control (intentionally excluded by the paper).
- Reward and verification service for RL training
- Description: Reuse the code-augmented LLM-as-a-Judge to produce robust outcome rewards for long-horizon agent training, with state diffs plus trajectory context.
- Sectors: ML platforms, MLOps
- Potential products/workflows: “RewardJudge API” that ingests traces + DB diffs and returns Completed/Partial/Agent Error/Env Error with scores; cheap code-only mode for pre-filtering.
- Assumptions/dependencies: Judge cost and policy; ensuring low environment error rates (≈4% in the paper) or routing those to retriable queues.
Academia and Education
- Reproducible agentic RL research at scale
- Description: Train and evaluate algorithms (GRPO variants, curriculum learning, exploration bonuses) across 1,000 consistent, code-driven environments without dependence on brittle LLM simulations.
- Sectors: Academia (ML/RL), open-source research
- Potential products/workflows: Public leaderboards for generalization across unseen environments; ablations on history-aware training, reward shaping, and verification methods.
- Assumptions/dependencies: Compute for 1,024 parallel instances and long-horizon rollouts; standardized logging.
- Auto-graded teaching labs for databases, APIs, and agents
- Description: Use the environments as hands-on assignments for CRUD design, transactional integrity, and agent tool-use; students iterate until code- or judge-based verification passes.
- Sectors: Higher education, bootcamps
- Potential products/workflows: Course packs with seeds (scenario → tasks → DB → MCP tools) and grading rubrics; local SQLite for reproducibility.
- Assumptions/dependencies: Classroom compute and sandboxing; curated subsets of environments for pedagogy.
Policy, Governance, and Safety
- Sandboxed compliance testing for AI agents
- Description: Validate that agents respect scoped permissions, least-privilege access, and data minimization in realistic but synthetic backends before touching production data.
- Sectors: Finance, public sector, regulated industries
- Potential products/workflows: “Policy-in-the-Loop” test batteries that assert allowed tool calls and lawful data flows; audit trails from DB state diffs and action logs.
- Assumptions/dependencies: Compliance mappings (synthetic → real control objectives); sign-off processes.
- Standardized evaluation protocols for tool interfaces (MCP)
- Description: Use the open environments to define conformance tests and reference scenarios for MCP or function-calling standards bodies/consortia.
- Sectors: Standards, industry alliances
- Potential products/workflows: MCP conformance suite, versioned test packs, badge/certification programs.
- Assumptions/dependencies: Community buy-in; versioning and backward-compatibility strategies.
Daily Life and Small Teams
- Local sandboxes to practice personal automation
- Description: Individuals or small teams rehearse workflows (budget planners, trip organizers, habit trackers) against safe synthetic apps before connecting to real accounts.
- Sectors: Productivity, prosumer
- Potential products/workflows: Prebuilt “life admin” scenarios (finance, travel, scheduling) with switchable connectors; no-auth mode for practice, live mode for deployment.
- Assumptions/dependencies: Connector shims; user safeguards for switching to live endpoints.
- Hobbyist and startup agent-building kits
- Description: Starter kits combining MCP servers, sample data, and verification to accelerate MVPs for vertical agents.
- Sectors: Startups, indie developers
- Potential products/workflows: “Agent Starter” templates by vertical (retail ops, bookings, content ops), with CI harness and generalization tests.
- Assumptions/dependencies: LLM access; cost constraints.
Long-Term Applications
These require further domain specialization, scaling, integration with live systems, or additional research.
Sector-Specific Digital Twins and Operational Agents
- Privacy-preserving clinical workflow training on synthetic EHR-like environments
- Description: Generate domain-specific schemas and tasks (order labs, reconcile meds, schedule follow-ups) to train agents without touching PHI; later bridge to vetted FHIR/EHR APIs.
- Sectors: Healthcare
- Potential tools/workflows: FHIR-aware MCP servers; clinically validated reward functions; safety rails for escalation.
- Assumptions/dependencies: Domain ontology alignment, clinical validation, strong governance and risk management.
- Bank/back-office digital twins for risk/compliance agents
- Description: Synthetic ledgers, KYC/AML case management, dispute workflows to train agents that assist with reconciliation, exception handling, and audit prep.
- Sectors: Finance
- Potential tools/workflows: MCP wrappers for core banking APIs; auditor-grade verification; evidence packs from state diffs.
- Assumptions/dependencies: Mapping to real control frameworks, model risk management (MRM), secure deployment.
- Grid/asset operations simulators for scheduling and anomaly response
- Description: CRUD-centric digital twins (work orders, asset registries, outage tickets) to train agents that coordinate maintenance/scheduling, later linking to SCADA/EMS via read-only first.
- Sectors: Energy, utilities
- Potential tools/workflows: Incident playbooks as tasks; reward shaping for safety and reliability.
- Assumptions/dependencies: Safety certification, integration with real-time systems, human-in-the-loop.
- Public services case-management assistants
- Description: Synthetic social services/permit systems to train agents for intake triage, eligibility checks, and status updates; deploy with strict audit trails.
- Sectors: Government
- Potential tools/workflows: Policy-aware verification modules; red-teaming suites for fairness and bias.
- Assumptions/dependencies: Legal constraints, procurement standards, transparency requirements.
Platform and Ecosystem Evolution
- Organization-specific environment generators (enterprise “digital twin factory”)
- Description: Feed internal user stories, real schemas, and policy constraints to synthesize bespoke MCP environments for pre-production agent training and testing.
- Sectors: Enterprise platforms
- Potential tools/workflows: “EnvGen” pipelines tied to data catalogs; automated seed-data synthesis aligned with real distributions.
- Assumptions/dependencies: Secure schema access, data synthesis that preserves utility while protecting privacy.
- AgentOps platforms with end-to-end flywheels
- Description: Continuous loop of environment synthesis → RL training with history-aware objectives → deployment → telemetry → automatic curriculum generation.
- Sectors: ML platforms, MLOps
- Potential tools/workflows: Auto-curriculum based on failure clusters; environment difficulty scaling; self-correction loops.
- Assumptions/dependencies: Robust failure categorization; reliable verification at scale; governance over self-evolving assets.
- Cross-vendor, sector-wide certification of agent reliability
- Description: Neutral foundations maintain large, rotating pools of synthetic environments to evaluate generalization, safety, and tool-use quality across agents.
- Sectors: Standards, consortia
- Potential tools/workflows: Rotating test sets to prevent overfitting; public scorecards with domain tags and difficulty bands.
- Assumptions/dependencies: Community stewardship; firewalling training from evaluation pools.
Advanced Research Directions
- Stronger verification and reward engineering
- Description: Develop hybrid verifiers that fuse code checks with cheaper small LLMs or constraint solvers; explore uncertainty-aware rewards and partial credit on long horizons.
- Sectors: Academia, safety research
- Potential tools/workflows: Learned judges fine-tuned on state diffs; formal methods for certain task classes.
- Assumptions/dependencies: High-quality adjudication datasets; careful bias and error analysis.
- Multi-agent and market simulations over MCP environments
- Description: Compose multiple synthetic services to study cooperation/competition, tool-sharing, and emergent behaviors in realistic business ecosystems.
- Sectors: Economics research, enterprise simulation
- Potential tools/workflows: Orchestrators for multi-server workflows; negotiation protocols layered over tool-use.
- Assumptions/dependencies: Scalable orchestration and tracing; richer cross-environment state models.
- Bridging to robotics and cyber-physical systems
- Description: Extend the MCP abstraction to control gateways for devices; pair CRUD backends with simulators (digital twins) for safe, closed-loop training.
- Sectors: Robotics, manufacturing, logistics
- Potential tools/workflows: Tool wrappers for ROS/PLC; safety-constrained rewards; sim-to-real curricula.
- Assumptions/dependencies: High-fidelity physical simulators; safety certification paths; latency constraints.
- Privacy-preserving benchmarking and data-sharing via synthetic surrogates
- Description: Share “functionally equivalent” synthetic environments that capture workflow and constraint structure without exposing sensitive data.
- Sectors: Finance, healthcare, public sector
- Potential tools/workflows: Utility/privacy audits comparing synthetic vs. real task solvability; governance registries of approved environments.
- Assumptions/dependencies: Proofs or empirical guarantees of non-disclosure; regulator acceptance.
Key cross-cutting assumptions and dependencies
- Reliability and cost of LLM generation and judging: While the pipeline reports strong self-correction (≈1.13 retries) and low env error rates (~4%), judge calls add cost; code-only checks can offset this with some brittleness.
- MCP adoption and tooling: Broad uptake of MCP or robust adapters to existing FC frameworks will ease integration.
- Domain alignment: Synthetic schemas/tasks must reflect real workflows; bridging layers are needed to map synthetic to live APIs safely.
- Compute and orchestration: Scaling RL with 1,024+ parallel instances and long-horizon episodes requires container orchestration, tracing, and cost controls.
- Security and governance: Authentication is intentionally out-of-scope in synthesis; production use must add access control, secrets management, auditability, and compliance checks.
Glossary
- API-solvability: A design criterion ensuring tasks can be completed via programmatic interfaces rather than UI interactions. "API-solvability, avoiding purely UI-dependent actions"
- Attention sink: A phenomenon where long contexts dilute attention on salient information, reducing model effectiveness. "avoid attention sink and improve efficiency"
- BFCLv3: A benchmark suite evaluating function-calling across scenarios including live tools, multi-turn contexts, and hallucination resistance. "BFCLv3~\citep{bfcl}, a comprehensive benchmark for function-calling ability evaluation"
- Code-augmented LLM-as-a-Judge: An evaluation approach that feeds code-derived signals to an LLM judge to make more robust decisions. "code-augmented LLM-as-a-Judge is more robust."
- CRUD operations: Fundamental database actions—Create, Read, Update, Delete—used to define stateful functionality. "core CRUD operations (create, read, update, delete)"
- Distribution mismatch: A training–inference discrepancy where the model faces different input distributions than it was optimized for. "creating a distribution mismatch issue between training and inference."
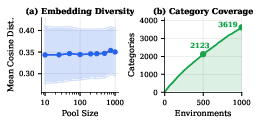
- Embedding-based deduplication: Using vector embeddings to identify and remove near-duplicate items to preserve diversity. "embedding-based deduplication ensures diversity."
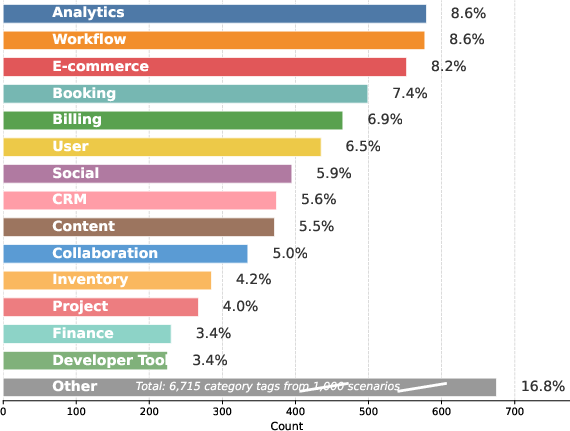
- Embedding diversity: A measure of semantic variety computed from embeddings of textual artifacts. "Embedding diversity is calculated by encoding the scenario description, database schema and toolset schema."
- Environment synthesis: The automatic construction of executable environments for agents to train and be evaluated in. "scalable environment synthesis."
- Format correctness: A constraint that actions (e.g., tool calls) must adhere to specified formats during training. "step-level format correctness"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that normalizes rewards within groups of trajectories to stabilize training. "Group Relative Policy Optimization (GRPO)~\citep{shao2024deepseekmath}"
- Group-relative advantage: The normalized advantage signal computed across a group of rollouts to guide policy updates. "is the group-relative advantage computed from the rollout rewards"
- Hallucination: An LLM error mode where it produces confident but incorrect content; often stress-tested in evaluations. "hallucination tests"
- History-Aware Training: Training that mirrors inference-time history truncation to align optimization with deployment conditions. "History-Aware Training"
- LLM-as-a-Judge: Using a LLM to assess task success or quality based on trajectories and evidence. "the ultimate decision is made by an LLM-as-a-Judge"
- LLM-based simulation: Emulating environment dynamics using an LLM to generate state transitions and observations. "LLM-based simulation often simulates the environment by prompting reasoning model to generate state transition and observation."
- Model Context Protocol (MCP): A protocol for exposing tools in a standardized way for agent interaction. "Model Context Protocol (MCP)~\citep{anthropic_mcp_2024}"
- NoSQL: Non-relational databases that store data in formats like key-value or document stores. "simplified NoSQL or key-value stores"
- Out-of-distribution generalization: The ability to perform well on tasks or domains not seen during training. "yields strong out-of-distribution generalization."
- Partially observable Markov decision processes (POMDPs): Sequential decision models where the agent has limited observability of the true state. "partially observable Markov decision processes (POMDPs) suitable for agentic RL training."
- Pass@k: A metric that counts success if any of k attempts solve the task. "Pass@k denotes task success rate allowing attempts"
- Procedural generation: Automatically creating content or environments through algorithmic rules. "Procedural generation has also been explored"
- Programming-based synthesis: Building environments via executable code and databases to ensure consistent state transitions. "Programming-based synthesis builds environments through programming and database"
- SQL-backed state consistency: Ensuring environment states and transitions are reliably enforced by an SQL database. "SQL-backed state consistency."
- SQLite: A lightweight SQL database used as an embedded state backend. "We use SQLite~\citep{sqlite} as the state backend"
- State diffs: Structured summaries of changes between pre- and post-execution environment states. "from state diffs and rule-based checks"
- Supervised fine-tuning (SFT): Training a model on labeled examples to specialize behavior via supervised learning. "supervised fine-tuning (SFT)"
- Tool graphs: Structured representations of tools and their dependencies or call sequences. "extract tool graphs from documentation"
- Truncated history: Using only a recent window of the interaction history as model context at training or inference time. "the agent may condition on a truncated history"
- Verification module: Code that inspects state changes and outcomes to determine task success and generate rewards. "a task-associated verification module"
Collections
Sign up for free to add this paper to one or more collections.