OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Abstract: Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces OneVL, a new way for self-driving car AIs to “think” quickly and safely. Today, many models use Chain-of-Thought (CoT) reasoning: they write out their step-by-step thoughts before deciding what to do. That helps accuracy, but it’s too slow for real-time driving. OneVL compresses those thoughts into a few tiny “latent” notes the model can read all at once, making it fast. It also teaches those notes to understand both language and the actual future look of the road, so the AI doesn’t just talk about the scene—it truly predicts how the scene will change.
Key questions the paper asks
- Can we keep the accuracy and safety benefits of step-by-step reasoning without waiting for a long explanation every time?
- If we compress “thinking” into a small space, how do we make sure it still understands real-world cause-and-effect (like where cars, lanes, and people will move)?
- Can a single model explain its decisions in both words and pictures while staying fast enough for real driving?
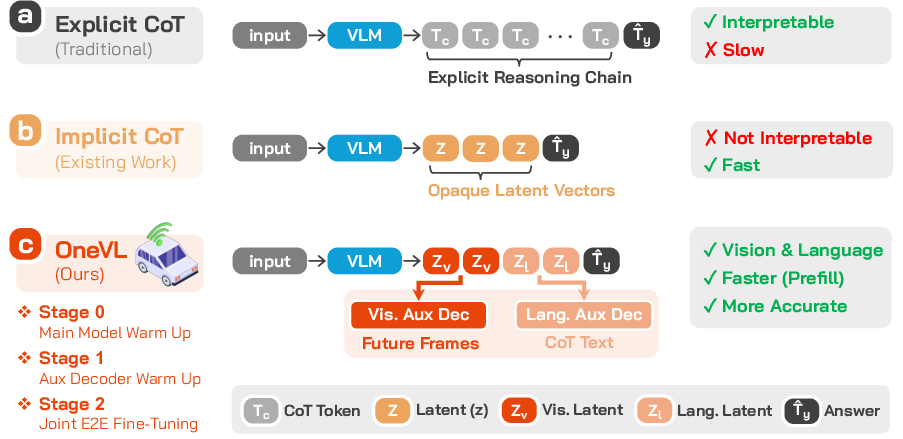
How OneVL works (in everyday language)
To make this easy to picture, imagine a student planning a bike ride through busy streets:
- Traditional CoT: The student writes a long essay about every detail (“There’s a bus ahead, the light is yellow, the bike lane merges…”), then finally decides what to do. Accurate, but slow.
- OneVL: The student instead keeps a few smart sticky notes (latent tokens) that summarize the important stuff. Two kinds of notes:
- Language notes: key reasoning in words (short and compact).
- Visual notes: a quick mental sketch of how the street will look in a moment (future frames).
Because the student has practiced turning those notes back into both clear explanations and future scene previews, the notes must capture the real causes and effects of driving scenes—not just labels or surface descriptions.
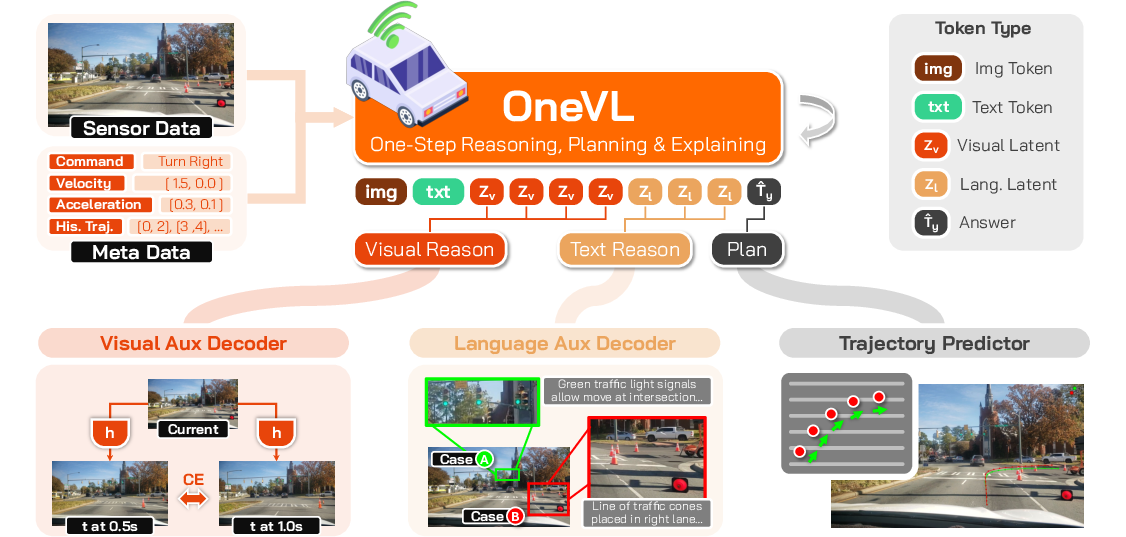
What are the building blocks?
- Vision-LLM (VLM): A model that reads images and text together.
- Latent tokens: Tiny, compact placeholders where the model packs its “thinking.”
- Two helper decoders (used only during training):
- Language decoder: turns the compact notes back into a human-readable explanation (like reconstructing the essay).
- Visual decoder (a simple “world model”): predicts what the camera might see 0.5s and 1.0s into the future (like flipping ahead in a comic to preview the next panels).
By forcing the notes to be good enough to recreate both a clear explanation and believable future images, the model learns the true dynamics of driving—who moves where, how roads guide motion, and what hazards might appear.
Why is this faster?
In older CoT systems, the model has to “speak” its reasoning one token at a time before making a decision, which adds delay. OneVL’s compact notes are “prefilled” all at once. The model reads them in a single pass and goes straight to the final driving plan, matching the speed of answer-only systems that don’t explain themselves.
How is it trained? (Three simple stages)
Think of it like training a team:
- Warm up the main model: Teach it to make decent driving plans and to use the note slots meaningfully.
- Train the helpers (with main model frozen):
- The language helper learns to turn notes into clear reasoning text.
- The visual helper learns to turn notes into likely future frames.
- Fine-tune everything together: Now feedback flows both ways, making the notes even better for planning and explanations.
During real driving, the helpers are turned off to keep things fast. The main model uses prefilled notes and outputs the trajectory. If needed (for auditing or debugging), you can still use the helpers afterward to generate language and visual explanations.
Main findings and why they matter
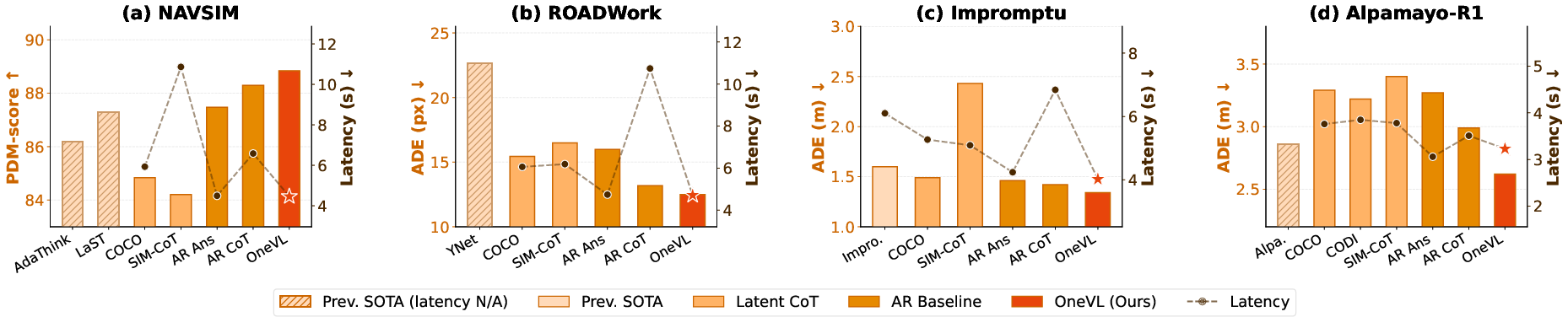
- OneVL is the first “latent CoT” method to beat explicit (token-by-token) CoT on accuracy while running at answer-only speed.
- It works across four benchmarks (including NAVSIM and ROADWork), showing:
- Higher accuracy than models that write full reasoning text first.
- Latency as fast as models that give only the final answer (and much faster than explicit CoT).
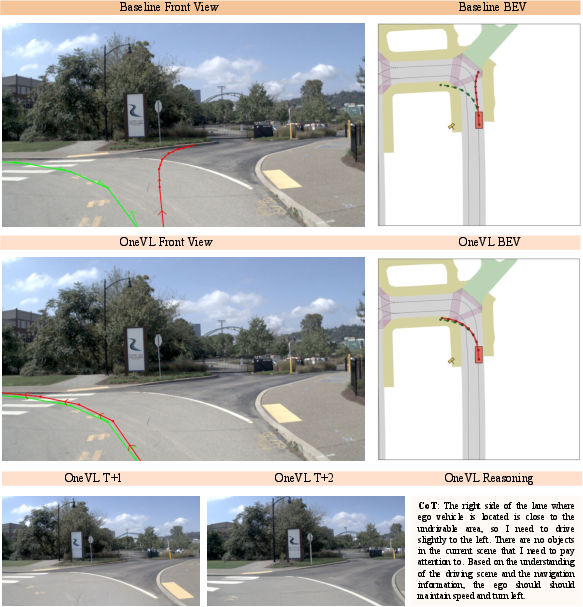
- It provides two kinds of explanations:
- Language: the model can reconstruct a readable step-by-step rationale.
- Visual: it can preview what the road ahead is expected to look like (short-horizon future frames).
Why this is important:
- Real-time systems like self-driving need low latency (fast decisions) and high reliability (safe decisions).
- Compressing reasoning into well-supervised notes that understand both “what things mean” (language) and “how things change” (visual future) leads to better generalization and safer planning.
What this could change (implications)
- Faster, safer autonomous driving: Cars can make high-quality decisions without waiting to generate long explanations.
- Better troubleshooting and trust: Even though the model runs fast, it can still show its reasoning in words and predicted future visuals for auditing or human review.
- A broader lesson for AI: Teaching compact “thinking notes” with both language and world prediction encourages the model to learn true cause-and-effect, not just memorize patterns. This idea could help other robots, assistants, and planning AIs that need to be both smart and quick.
In short, OneVL shows that you don’t have to choose between speed and strong reasoning. With the right training, compact thinking beats long explanations—especially when those thoughts are grounded in how the world will actually change next.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. These items are intended to guide actionable follow-up research.
- Closed-loop evaluation is missing: All results are open-loop (e.g., PDM, ADE/FDE). There is no closed-loop simulator (CARLA/nuPlan non-reactive→reactive) or hardware-in-the-loop validation to assess safety (collisions/infractions), comfort, and progress under feedback control.
- Real-time deployment unclear: Reported “latency (s)” is ~4–7 s/tokenized episode in tables, which is not consistent with real-time control. The only real-time figure (0.24 s ≈ 4.16 Hz via an MLP head) is not evaluated across benchmarks or compared to baselines; no profiling across batch sizes, sequence lengths, or hardware. It remains unclear whether OneVL meets 10–20 Hz control requirements in realistic pipelines.
- Prefill latent tokens mechanism is under-specified: At inference, latent tokens are “prefilled as fixed token sequences.” It is unclear how sample-specific information is encoded if these tokens are fixed strings. A rigorous analysis of how context-dependent hidden states at these positions capture instance-specific reasoning is missing.
- Faithfulness of explanations not evaluated: Language and visual explanations are claimed to be interpretable, but there is no quantitative assessment of faithfulness (e.g., causal mediation tests, counterfactual consistency, or alignment between predicted trajectory and decoded explanations).
- No quantitative evaluation of visual world-model predictions: The visual auxiliary decoder’s future-frame predictions are neither measured (e.g., token reconstruction accuracy, perceptual metrics, Fréchet distances, CLIP/DINO similarity) nor subjected to human evaluation; thus, the claimed visual interpretability remains unvalidated.
- Limited prediction horizons for the world-model auxiliary: Visual supervision is only at s and s. It is unknown how horizon length affects planning performance, generalization, or stability; whether longer horizons (e.g., 2–4 s) or curriculum over horizons would help is unexplored.
- Lack of multi-frame temporal inputs for the visual decoder pretraining: The visual auxiliary is pretrained on a single current frame (no temporal stack), which may be insufficient for motion modeling. The benefit of conditioning on short video histories is untested.
- Missing consistency checks between predicted trajectory and predicted future frames: There is no explicit constraint tying trajectory outputs to world-model predictions; potential inconsistencies are not analyzed. Joint consistency losses or cross-check metrics could be explored.
- Sensitivity to latent token budget and placement: The paper fixes and but actually “realizes” them as 35 and 20 tokens using the base vocabulary. The rationale, compression ratio, and sensitivity/ablation over number and placement of latent tokens are not provided.
- Ambiguity in latent token realization: Using base-vocabulary tokens instead of special tokens reportedly helps, but why 35 “visual latent tokens” and 20 “language latent tokens” map to and is unclear. Implementation details, learned embeddings, and their effect on stability are not specified.
- Lack of adaptive latent capacity: There is no mechanism to allocate more/fewer latent tokens based on scenario complexity. Whether dynamic latent budgets improve performance/efficiency is unstudied.
- No robustness/OOD evaluation: The method is not tested under domain shifts (weather/night, sensor noise, heavy occlusion, rare maneuvers), nor on unseen cities/datasets. Generalization across sensors (e.g., multi-camera rigs, LiDAR, radar) is unproven.
- Limited sensing and representation: Experiments appear to use a single front-view image and structured text. The benefits/limits of multi-camera, BEV features, or 3D geometric inputs are not assessed. Visual supervision relies on pixel-space tokenizers rather than BEV occupancy/flow or vectorized map forecasts.
- Map and topology reasoning not integrated: The framework does not incorporate explicit map priors (HD maps/lane graphs) or BEV planning; it remains unknown whether pairing latent CoT with structured map reasoning would yield larger gains.
- Dataset and annotation reproducibility: CoT labels are partly generated in-house and APR1 labels are derived using another model; there is no commitment to release these annotations or code, making replication challenging.
- Baseline adaptation details and fairness: The paper adapts COCONUT/CODI/SIM-CoT to driving but omits full implementation details (e.g., latent lengths, teacher-forcing, training schedule). It is unclear if baselines got comparable engineering attention (e.g., prefill or non-AR latent inference variants).
- Statistical significance and variability: Gains over explicit CoT are sometimes modest (e.g., NAVSIM PDM 88.84 vs. 88.29) with no confidence intervals, seed sweeps, or significance tests. Stability across runs and datasets remains unknown.
- Compute and memory footprint unreported: Extending the vocabulary by 131,072 visual tokens and training dual decoders likely increases memory/compute. Training cost, convergence time, and resource requirements are not quantified.
- Hyperparameter sensitivity not explored: Only one set of weights is reported (e.g., , ). The impact of these weights, latent token counts, and auxiliary decoder capacities on performance and stability is not studied.
- Visual tokenizer choice and codebook size: The paper adopts IBQ/Emu3.5 with a large codebook but does not evaluate alternatives (smaller codebooks, continuous VQ-VAEs, masked image modeling) or their effect on compression, fidelity, and training stability.
- Long-horizon planning quality not measured: While ADE/FDE are reported, there is no analysis of long-horizon (>4 s) behavior, multi-modal trajectory diversity, or rare-event avoidance over extended horizons.
- No uncertainty quantification: The model outputs point trajectories without calibrated uncertainty or risk-aware planning; handling multi-modality and confidence calibration remains open.
- Explanations at inference-time: Decoders are “discarded” for deployment but later said to be usable for post-hoc explanations. The mechanism, latency overhead, and workflow for on-demand explanations are not specified.
- Causal claims are not rigorously validated: The core hypothesis—that joint language/visual supervision makes latents more “causal”—is not tested with causal diagnostics (counterfactuals, interventions, or invariance tests).
- Failure analysis is absent: No qualitative or quantitative breakdown of common failure modes (e.g., merges, occluded pedestrians, construction detours), and no analysis linking failures to latent/explanation behavior.
- Safety and human factors: No study on how explanations help human oversight, debugging, or driver cooperation; no human-in-the-loop evaluation or safety-case integration is provided.
- Scalability and transfer: The approach is only tested on a 4B backbone; whether benefits persist or grow on larger VLMs/VLAs, or transfer to reinforcement learning and on-policy data, is untested.
Practical Applications
Immediate Applications
Below are applications that can be deployed or prototyped now using the paper’s methods and findings, given standard development effort and access to data/models.
- Stronger, faster trajectory proposal in ADAS and autonomy stacks
- Sectors: automotive, robotics (mobile robots, delivery bots)
- What it is: Drop-in trajectory proposal/planning module that matches answer-only latency while surpassing explicit CoT quality. The language and visual auxiliaries provide optional human-readable and visual previews of the plan for debugging/HMI.
- Tools/products/workflows:
- A ROS2/Autoware-compatible “OneVL Planner” node producing waypoints at 4–5 Hz (as reported with an MLP head ~0.24 s latency).
- HMI hook to display optional language rationales and short-horizon future-frame previews for driver monitoring or safety driver review.
- Integration with existing perception stacks (camera-first; can be extended to multi-sensor).
- Assumptions/dependencies:
- Camera quality and synchronization; access to ego-state and basic scene priors.
- Closed-loop validation and safety case beyond offline benchmarks (NAVSIM, ROADWork, Impromptu, APR1).
- Compute budget compatible with Qwen3-VL-4B-class models or equivalent.
- Post-hoc safety auditing and incident analysis with dual explanations
- Sectors: automotive, insurance, regulators
- What it is: Use recovered CoT text and visual future-frame previews to analyze decisions after disengagements/incidents, offering auditor-friendly narratives and visualized “what the model foresaw.”
- Tools/products/workflows:
- “Explanation logger” that stores latent tokens per event; offline auxiliary decoders reconstruct rationales and visual previews.
- Integration with event data recorders (EDR) and fleet telemetry dashboards.
- Assumptions/dependencies:
- Policy-compliant data retention; privacy-preserving storage of sensor data.
- Clear procedures that explanations are post-hoc aids, not definitive causal proofs.
- Corner-case mining and dataset curation
- Sectors: automotive, data ops, academia
- What it is: Use language latents and visual-preview failures to identify challenging patterns (e.g., construction zones, occluded pedestrians) and auto-tag scenarios for targeted data collection.
- Tools/products/workflows:
- “Scenario triage” service: thresholding on ADE/FDE deltas and inconsistency between visual previews and ground truth to flag hard cases.
- Semi-automatic CoT annotation generation using the language auxiliary decoder to bootstrap reasoning labels.
- Assumptions/dependencies:
- Access to raw logs and ground-truth references; pipeline for IBQ tokenization to compare visual predictions.
- Simulation-in-the-loop evaluation at answer-only latency
- Sectors: automotive, simulation vendors
- What it is: Faster throughput for large-scale non-reactive sims (e.g., NAVSIM-like) with interpretability preserved.
- Tools/products/workflows:
- Batch simulation runners that prefill latent tokens and decode only trajectory, logging latent states for later explanation.
- Assumptions/dependencies:
- Sim-to-real gap acknowledgment; additional closed-loop stress testing needed before deployment.
- Explainable planning SDK for OEM and Tier-1 engineering teams
- Sectors: software, automotive suppliers
- What it is: A developer kit exposing (a) trajectory head, (b) optional CoT text decoder, and (c) optional visual future-frame decoder for internal QA and customer demos.
- Tools/products/workflows:
- ONNX/TensorRT packaged inference for the planner; toggleable interpretable outputs in dev builds.
- Assumptions/dependencies:
- License alignment for base VLM and IBQ codebooks; internal GPU availability for training/fine-tuning.
- Warehouse and facility navigation with compact latent reasoning
- Sectors: robotics (AMRs, cleaning robots), logistics
- What it is: Latent CoT with world-model supervision improves plan quality without sequential reasoning latency; usable for aisle following, obstacle negotiation, and human-robot interaction corridors.
- Tools/products/workflows:
- ROS2 navigation plugin replacing classical local planner; optional on-robot visual previews to confirm intent around humans.
- Assumptions/dependencies:
- Domain adaptation to indoor visuals and dynamics; limited retraining on facility-specific data.
- Driver coaching and training aids with visual previews
- Sectors: education, consumer apps
- What it is: Dashcam/desktop tool that provides short-horizon previews and language explanations for “why a human should do X,” useful in instruction and post-drive feedback.
- Tools/products/workflows:
- Desktop app that ingests video, reconstructs decisions, and shows predicted future frames plus rationale.
- Assumptions/dependencies:
- Clear messaging that this is advisory, not an automated driving function; liability considerations for consumer-facing use.
- Research baseline for latent CoT with world-model supervision
- Sectors: academia, open-source communities
- What it is: Reusable architecture and three-stage training recipe to study compression-generalization trade-offs in embodied tasks.
- Tools/products/workflows:
- Reproducible training scripts; ablation-ready code; standard metrics (PDM, ADE/FDE, L2 error).
- Assumptions/dependencies:
- Access to CoT annotations and future-frame data; GPU resources for staged training.
Long-Term Applications
These require further research, scaling, domain adaptation, closed-loop validation, or policy development before broad deployment.
- Transparent L4 autonomy with real-time dual explanations
- Sectors: automotive
- What it is: Production L4 stacks that provide regulator- and rider-facing explanations (text+visual previews) and maintain answer-only latency for planning.
- Tools/products/workflows:
- On-vehicle explanation interface for safety operators/regulators; “explanation confidence” telemetry.
- Assumptions/dependencies:
- Robust closed-loop performance across long-tail conditions; standardization of explanation reporting; comprehensive safety cases.
- Standardized “Explanation EDR” for regulatory compliance
- Sectors: policy, regulators, insurance
- What it is: A black-box recording schema that stores latent tokens and reconstructable explanations for post-incident analysis aligned with AI Act/ISO standards.
- Tools/products/workflows:
- Standards for logging latent states, reconstruction procedures, and cryptographic integrity checks.
- Assumptions/dependencies:
- Agreement on admissibility/value of explanations; privacy-preserving protocols; certification pathways.
- Cross-agent reasoning via V2X latent sharing
- Sectors: smart cities, automotive, infrastructure
- What it is: Vehicles and infrastructure share compact latent tokens encoding causal scene dynamics to improve cooperative planning without streaming raw video.
- Tools/products/workflows:
- Lightweight over-the-air latent broadcast; fusion modules to combine local and external latents.
- Assumptions/dependencies:
- Communication standards, latency and security constraints; robustness to distribution shift between agents.
- Unified embodied VLA for drones and inspection robots
- Sectors: energy (powerline/wind inspection), construction, public safety
- What it is: Apply one-step latent reasoning with world-model supervision to flight planning: anticipate near-future frames around structures to avoid collisions while keeping inference on-device.
- Tools/products/workflows:
- Edge-deployable models with visual tokenizer adapted to aerial imagery; mission planning with explainable previews for operators.
- Assumptions/dependencies:
- Domain-specific retraining; severe compute/power constraints on UAVs; safety/regulatory approvals for BVLOS.
- Human-robot collaboration with intent previews
- Sectors: manufacturing, healthcare logistics, hospitality
- What it is: Robots communicate intent using future-frame previews and brief rationales, improving predictability and trust around humans.
- Tools/products/workflows:
- HRI toolkits to display next-1s visual previews on robot screens/AR devices; safety interlocks reacting to human acknowledgement.
- Assumptions/dependencies:
- Verified alignment between previews and actual motion; user studies; ergonomic and accessibility considerations.
- Curriculum RL with action-conditioned world-model auxiliaries
- Sectors: research, autonomy, simulation vendors
- What it is: Use the visual auxiliary as an action-conditioned world model for policy learning, with latent tokens steering rollouts to reduce sample complexity.
- Tools/products/workflows:
- Hybrid SFT+RL training loops; simulators that query auxiliary decoders for imagined futures; policy gradients constrained by explanation consistency.
- Assumptions/dependencies:
- Stability of joint training; sim2real transfer; compute availability for large-scale RL.
- Pedestrian/cyclist AR navigation with hazard anticipation
- Sectors: consumer, urban mobility, education
- What it is: AR devices preview near-future scene changes (e.g., fast-approaching vehicles) with concise explanations to teach safer crossing/route choices.
- Tools/products/workflows:
- On-device lightweight OneVL variants; privacy-preserving processing; edge visual tokenizers.
- Assumptions/dependencies:
- Robust performance in unconstrained handheld/AR camera settings; battery/thermal limits; liability frameworks.
- Multi-sensor, multi-view generalization and standardization
- Sectors: automotive, robotics, standards bodies
- What it is: Extend latent-world-model supervision to LiDAR/RaDAR and surround-view camera rigs, with standardized training and evaluation protocols.
- Tools/products/workflows:
- Tokenizers for non-image modalities; benchmarks that evaluate explanation fidelity alongside planning metrics.
- Assumptions/dependencies:
- Research on multi-modal tokenization; consensus metrics for explanation fidelity.
- Safety certification workflows using explanation consistency tests
- Sectors: policy, certification, QA
- What it is: Incorporate “explanation consistency under perturbations” (language/visual) as a test dimension in audits to detect brittle shortcuts.
- Tools/products/workflows:
- Automated counterfactual scenario generation; scoring of divergence between predicted trajectories and decoded explanations.
- Assumptions/dependencies:
- Evidence that such tests correlate with real-world safety; acceptance by certification bodies.
- Domain transfer beyond driving (e.g., medical imaging guidance, industrial inspection)
- Sectors: healthcare, industrial QA
- What it is: Use compact latent reasoning plus future-visual-token prediction to support tool guidance (e.g., anticipating next-view in endoscopy or pipeline inspection) with textual rationale.
- Tools/products/workflows:
- Fine-tuned visual tokenizers for the target imagery; decision-support UI that separates plan suggestions from physician/inspector authority.
- Assumptions/dependencies:
- Strong domain adaptation; clinical/industrial validation; strict safety, privacy, and compliance requirements.
Notes on Feasibility and Dependencies Across Applications
- Model/data: Requires access to a capable VLM backbone (e.g., Qwen3-VL-4B or equivalent), CoT annotations, and short-horizon future frames for auxiliary training; visual tokenizer (e.g., IBQ/Emu3.5 with ~131k-code vocabulary).
- Engineering: Three-stage training pipeline (visual auxiliary pretraining → main model warmup → joint finetuning) is important to stability and final quality.
- Performance scope: Reported gains are on offline/non-reactive or controlled benchmarks; closed-loop on-road validation, long-tail coverage, and failure-mode analysis are prerequisites for safety-critical deployment.
- Compute/edge constraints: While prefill yields answer-only latency, edge deployment still requires optimization (quantization, compilation) and careful thermal/power budgeting.
- Governance: Explanations help transparency but are not formal correctness proofs; policies should treat them as complementary evidence, with protections for privacy and misuse.
Glossary
- Ablation studies: Systematic experiments that remove or alter components to assess their contribution to performance. Example: "Ablation studies confirm each component's contribution."
- Action-conditioned rollouts: World-model predictions that are guided by the agent’s planned actions or latent plans. Example: "the decoder effectively transitions from unconditioned next-frame generation to action-conditioned rollouts of the world model."
- Autoregressive (AR): A sequential generation process where each token is produced conditioned on previously generated tokens. Example: "Standard autoregressive~(AR) CoT generation must emit every reasoning token before the trajectory can be produced."
- Auxiliary decoder: A training-only decoder that supervises or reconstructs signals (e.g., language or vision) from latent representations. Example: "dual auxiliary decoders decode these into future-frame visual tokens and CoT text, respectively"
- Bird's-eye-view (BEV): A top-down spatial representation of a scene often used for driving perception and planning. Example: "augmented VLMs with bird's-eye-view feature injection, enabling holistic scene understanding that fuses camera and top-down spatial context"
- Chain of Causation (CoC) annotations: Structured reasoning traces aligning decisions with their causal factors in driving scenarios. Example: "introduces the Chain of Causation (CoC) annotations, featuring decision-grounded reasoning traces aligned with complex driving behaviors"
- Chain-of-Thought (CoT) reasoning: Generating explicit intermediate reasoning steps before producing the final answer or action. Example: "Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving"
- Closed-loop evaluation: Assessment where a model’s actions affect future inputs in a simulated or real environment. Example: "For closed-loop evaluation, DICC leverages generative world models to produce realistic driving images and performs adversarial evaluation on end-to-end driving systems"
- Codebook: A discrete set of tokens used to quantize images or features for generative modeling. Example: "with a codebook of 131,072 discrete visual codes."
- Cross-entropy loss: A standard loss for next-token prediction in sequence models. Example: "applying a cross-entropy loss () to both the trajectory answers and the latent reasoning tokens"
- Curriculum learning: A training strategy that gradually increases task difficulty or replaces components over stages. Example: "COCONUT introduced curriculum learning over latent thought tokens, progressively replacing discrete reasoning steps with continuous vectors."
- Emu3.5 tokenizer: A specific visual tokenizer used to discretize images into token sequences. Example: "We use the Emu3.5 tokenizer~\cite{emu35,ibq} with a codebook of 131,072 discrete visual codes."
- Final Displacement Error (FDE): The distance between predicted and ground-truth endpoint positions in trajectory forecasting. Example: "On ROADWork, we report ADE (Average Displacement Error) and FDE (Final Displacement Error) to measure waypoint accuracy."
- Hidden states: Internal vector representations produced by a model at each token position. Example: "The hidden states extracted at these token positions after LLM processing encode the model's implicit language-grounded reasoning."
- IBQ (Index Backpropagation Quantization): A visual tokenization method that quantizes images into discrete tokens while supporting end-to-end training. Example: "we adopt the IBQ (Index Backpropagation Quantization) visual tokenizer~\cite{ibq}."
- Joint Embedding Predictive Architecture (JEPA): A representation learning framework that predicts latent future embeddings rather than raw pixels. Example: "the introduction of the Joint Embedding Predictive Architecture by \citet{assran2023self}"
- Latent bottleneck: A compact intermediate representation enforcing information compression for generalization. Example: "A principled three-stage training pipeline progressively aligns the latent bottleneck with trajectory prediction"
- Latent CoT: Compressing chain-of-thought reasoning into continuous latent representations instead of explicit tokens. Example: "Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states"
- Latent tokens: Special tokens whose hidden states carry compressed reasoning information for downstream decoders or planning. Example: "latent tokens are prefilled into the prompt, enabling single-pass latent CoT reasoning with no iterative overhead."
- Model-based reinforcement learning: RL approaches that learn a predictive model of the environment’s dynamics. Example: "The concept of the world model originates from model-based reinforcement learning"
- Next-token prediction objective: Training a model to predict the next token given prior context. Example: "The backbone is primarily optimized via a standard next-token prediction objective"
- Non-reactive simulation-based planning: Evaluation using recorded scenarios where other agents do not react to the ego agent’s actions. Example: "providing real-world data for non-reactive simulation-based planning evaluation."
- Predictive Driver Model (PDM) score: A composite metric assessing safety, comfort, and progress for trajectory planning. Example: "using the Predictive Driver Model (PDM) score, a composite metric that jointly assesses trajectory safety, comfort, and progress."
- Prefill inference: Supplying tokens upfront in a parallelizable phase so only final outputs are decoded autoregressively. Example: "we design a prefill inference mechanism."
- Sequence-level self-distillation: Training a student model to match a teacher’s full-sequence behavior in latent space. Example: "CODI~\cite{codi} adopts sequence-level self-distillation, training a student model to align its anchor latent hidden state"
- Spatiotemporal causal dynamics: The time-varying physical interactions and geometry that determine future outcomes. Example: "spatiotemporal causal dynamics that actually determine future outcomes."
- Vision-Language-Action (VLA): Models that integrate perception, language reasoning, and action output (e.g., trajectories). Example: "these models are known as Vision-Language-Action models (VLAs)"
- Vision-LLM (VLM): Models that jointly process visual and textual inputs for multimodal understanding. Example: "Vision-LLMs (VLMs) have rapidly become a foundational building block for autonomous driving"
- Vision Transformer (ViT): A transformer-based architecture for processing images as sequences of patches. Example: "The backbone of OneVL is Qwen3-VL-4B-Instruct, a VLM ... Vision Encoder (ViT)"
- Visual tokenizer: A module that converts images into discrete token sequences for generative modeling. Example: "To represent images as discrete token sequences, we adopt the IBQ (Index Backpropagation Quantization) visual tokenizer"
- Visual world model decoder: A decoder that predicts future-frame visual tokens to capture causal scene dynamics. Example: "we introduce a visual world model decoder that predicts future-frame tokens"
- Vocabulary extension: Adding new token IDs (e.g., visual codes) to a model’s tokenizer vocabulary. Example: "the Qwen3-VL-4B base vocabulary is extended by 131,072 additional visual token IDs."
- Waypoints: Discrete future positions used to represent a planned trajectory. Example: "such as trajectory waypoints or control signals"
- World model auxiliary: A training objective that guides latent representations using future-frame prediction as a proxy for dynamics. Example: "This visual prediction objective serves as a world model auxiliary"
Collections
Sign up for free to add this paper to one or more collections.