- The paper demonstrates that supplementing sparse action supervision with dense future image prediction amplifies the data scaling law, reducing ADE by 28.8% and collision rate by 15.9%.
- The methodology leverages both autoregressive and diffusion-based world models integrated with a VLA backbone and a lightweight Mixture-of-Experts for efficient inference.
- Experimental results on NAVSIM benchmarks reveal state-of-the-art performance, robust generalization, and improved trajectory planning in autonomous driving.
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Introduction and Motivation
DriveVLA-W0 addresses a fundamental bottleneck in scaling Vision-Language-Action (VLA) models for autonomous driving: the "supervision deficit" arising from sparse action-only supervision. While VLA models inherit large-scale pretraining from Vision-LLMs (VLMs), their representational capacity is underutilized when fine-tuned solely on low-dimensional control signals. This work proposes a paradigm shift by introducing world modeling—predicting future images—as a dense, self-supervised objective to supplement action supervision. The hypothesis is that world modeling not only improves generalization and data efficiency but also fundamentally reshapes the scaling law, enabling VLA models to realize their full potential as data volume increases.
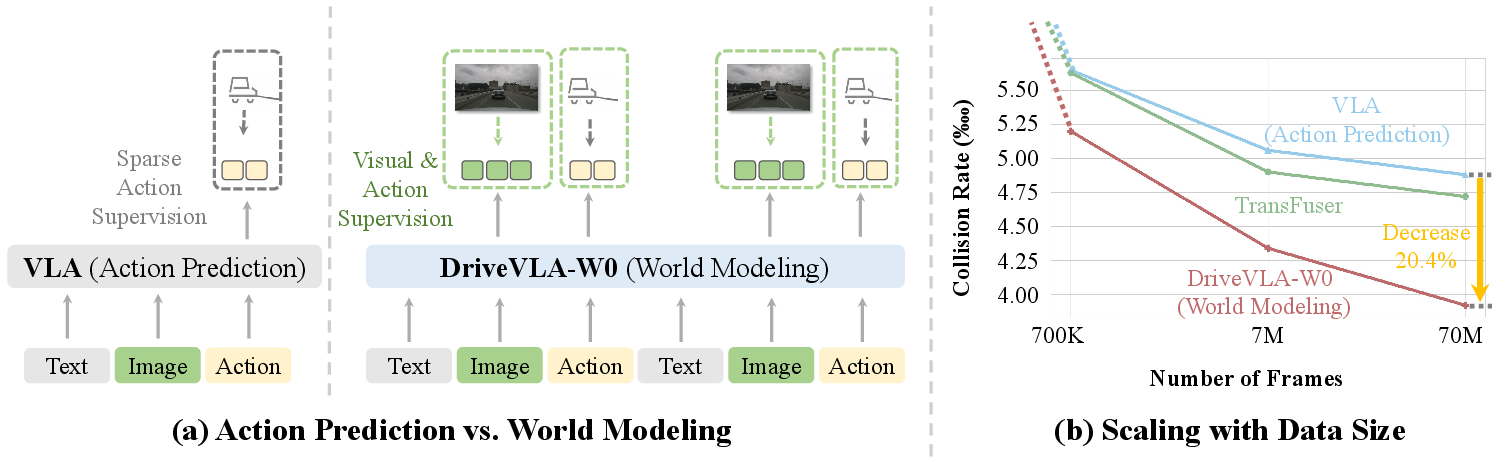
Figure 1: World modeling as a catalyst for VLA data scalability. DriveVLA-W0 is trained to predict both future actions and visual scenes, providing dense supervision for large-scale data.
Architecture and Methodology
DriveVLA-W0 is instantiated for two dominant VLA architectural families: those operating on discrete visual tokens (VQ) and those using continuous visual features (ViT). The pipeline consists of three stages:
- VLA Baseline: Inputs are sequences of language instructions, images, and past actions, tokenized and processed by a large VLM backbone (Emu3 for VQ, Qwen2.5-VL for ViT). Action prediction is performed autoregressively via cross-entropy loss over action tokens.
- World Modeling:
- AR World Model (VQ): Predicts future images as sequences of discrete visual tokens, optimized via next-token prediction loss. Joint training combines action and world model losses.
- Diffusion World Model (ViT): Predicts future images in a continuous latent space using a latent diffusion model, conditioned on current vision and action features. Training minimizes MSE between predicted and true noise in the latent space.
- Action Expert (MoE): To address inference latency, a lightweight Action Expert (500M parameters) is paired with the VLA backbone in a Mixture-of-Experts (MoE) architecture. Joint attention fuses representations, and three decoding strategies are explored: query-based, autoregressive, and flow matching.
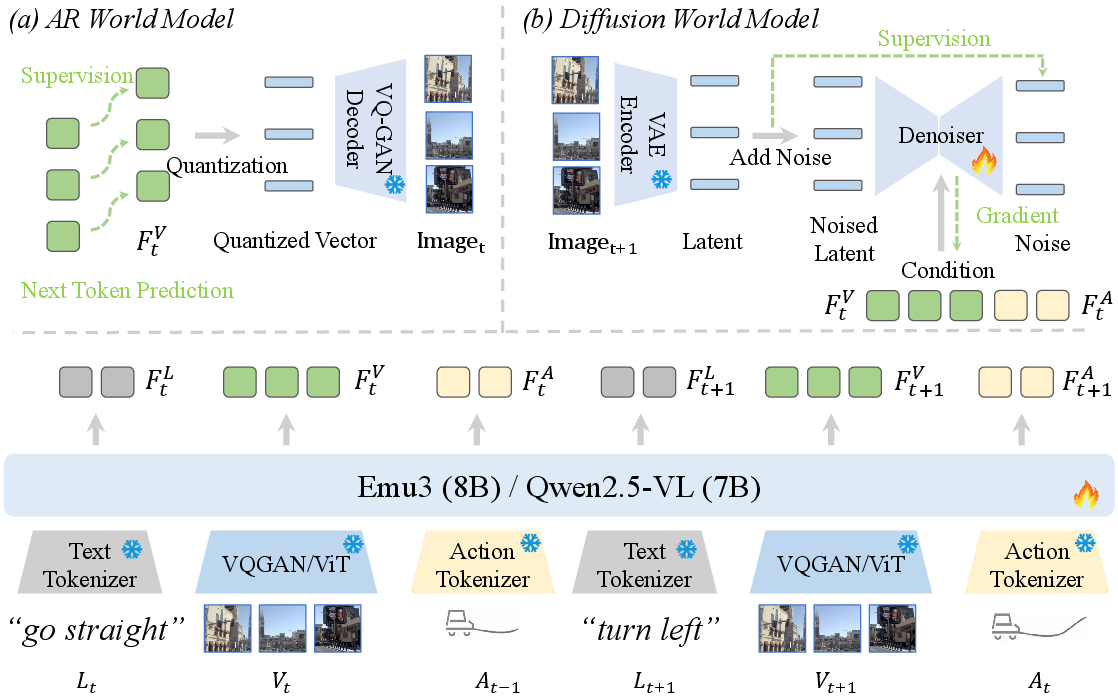
Figure 2: The architecture of DriveVLA-W0, featuring both AR and Diffusion World Models for future image prediction.
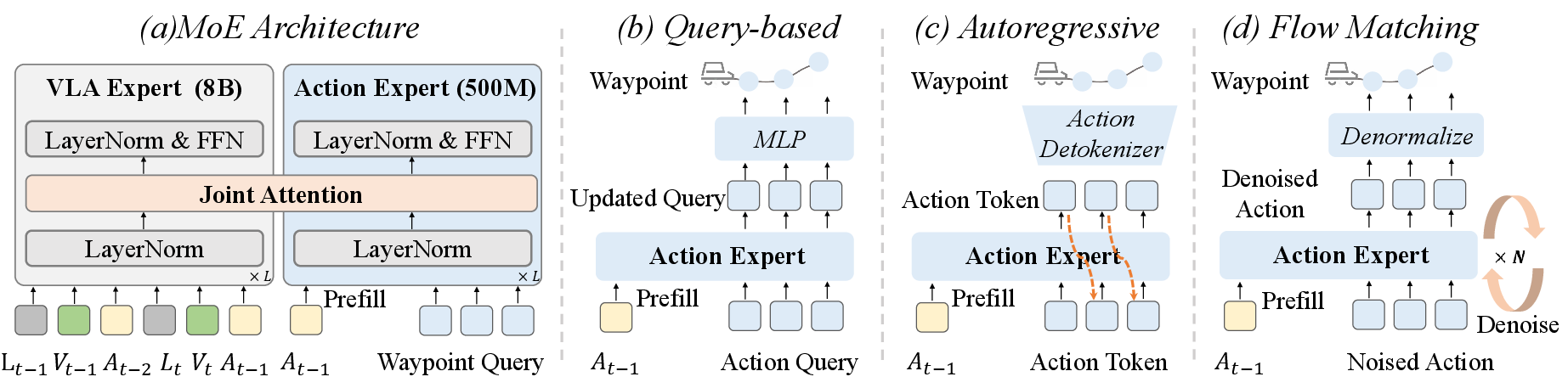
Figure 3: MoE architecture pairing a large VLA Expert with a lightweight Action Expert, enabling efficient inference and comparative study of action decoding schemes.
Experimental Results and Scaling Law Analysis
DriveVLA-W0 achieves new state-of-the-art results on NAVSIM v1/v2 benchmarks, outperforming both BEV-based and VLA-based baselines across all safety and planning metrics, despite using only a single front-view camera. The dense supervision from world modeling is identified as the key factor enabling this performance.
Data Scaling Law Amplification
Extensive experiments on a 70M-frame in-house dataset reveal that world modeling fundamentally amplifies the data scaling law. Baseline models relying on sparse action supervision quickly saturate, while DriveVLA-W0 continues to improve as data volume increases. At the largest scale, world modeling yields a 28.8% reduction in ADE and a 15.9% reduction in collision rate compared to action-only baselines.
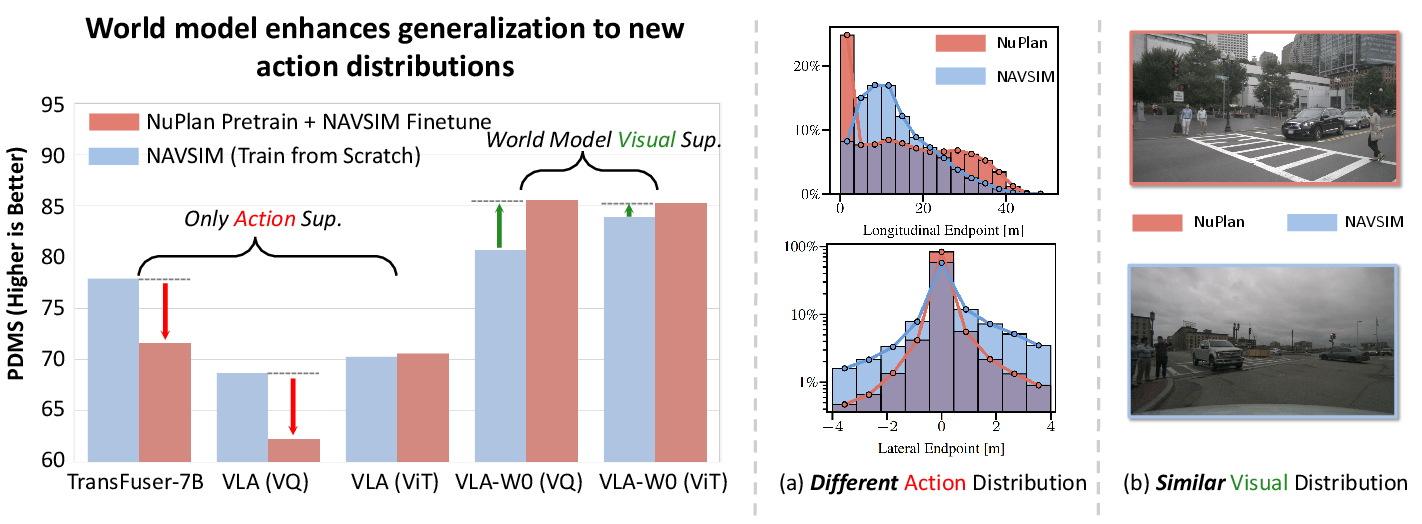
Figure 4: World modeling unlocks generalization with data scaling, enabling positive knowledge transfer across datasets with similar visuals but different action distributions.
Generalization and Transfer
Pretraining on large-scale datasets (NuPlan) and fine-tuning on NAVSIM demonstrates that world modeling enables robust generalization across domains with differing action distributions. Baseline models suffer from overfitting to the source domain, while DriveVLA-W0 benefits from transferable visual representations learned via future image prediction.
Action Decoder Scaling Reversal
A critical finding is the reversal of action decoder performance trends with data scaling. On small datasets, continuous decoders (query-based, flow matching) outperform discrete autoregressive decoders due to lower quantization error. However, at massive scale, the autoregressive decoder's superior modeling capacity and sample efficiency allow it to surpass the others, highlighting a trade-off between precision and capacity.
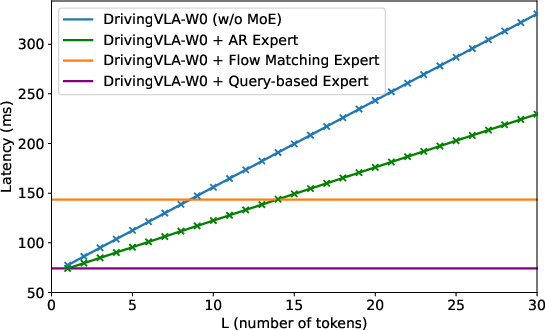
Figure 5: Latency analysis. AR expert and VLA baseline scale linearly with token count, while flow matching and query-based experts maintain constant inference time.
Ablation Studies
- Vision-Only vs. Vision-Action Conditioning: Conditioning future image prediction on both vision and action yields substantial gains, confirming the necessity of grounding visual predictions in ego actions for learning causal dynamics.
- Temporal Context Length: Longer input sequences (6VA) improve both generative fidelity and planning performance, indicating the importance of temporal context for modeling long-horizon dynamics.
- World Model Time Horizon: Optimal performance is achieved with a 1-second interval between input frames; longer intervals introduce excessive scene variation, degrading prediction quality.
Qualitative Analysis
DriveVLA-W0 demonstrates superior trajectory planning in complex scenarios, avoiding collisions where baselines fail due to weak scene dynamics prediction.
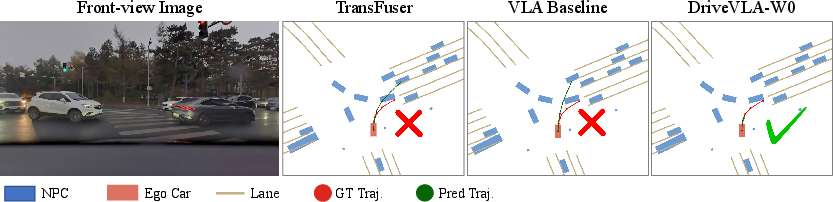
Figure 6: World modeling improves trajectory planning in complex scenarios, enabling avoidance of collisions in challenging interaction scenarios.
Comparisons of action experts show that the AR expert generates more stable and consistent trajectories than flow matching, especially in terms of inter-frame continuity and adherence to drivable areas.
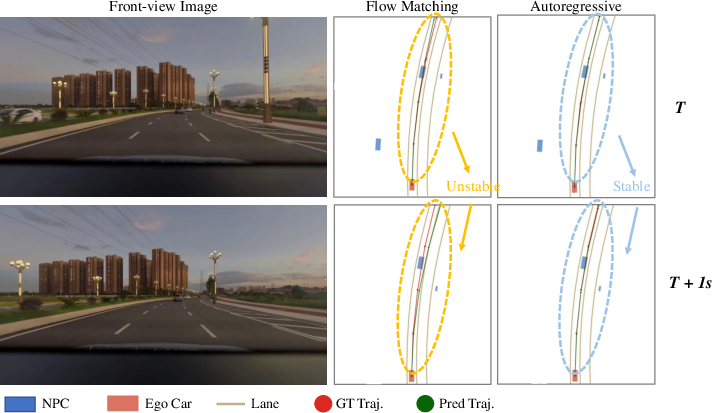
Figure 7: AR action expert generates stable trajectories, while flow matching exhibits instability and jumps between frames.
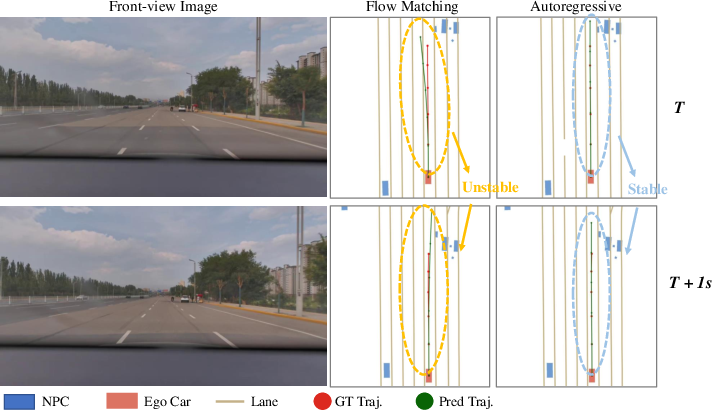
Figure 8: AR action expert maintains stability; flow matching can produce trajectories outside the drivable area.
The world model produces visually realistic and contextually plausible future images across diverse scenarios, with tight alignment between predicted images and planned actions.



Figure 9: World model generates visually realistic and contextually plausible future images in diverse scenarios.


Figure 10: Predicted images and actions are tightly coupled, reflecting coherent internal world representations.
Implementation Considerations
- Training: Two-stage paradigm—joint pretraining of VLA backbone with world modeling, followed by integration with Action Expert for latency reduction.
- Resource Requirements: Large-scale training (up to 64 GPUs, batch size 256) is necessary to realize scaling law benefits.
- Deployment: MoE architecture is critical for real-time inference, with query-based expert achieving lowest latency.
- Limitations: World modeling is bypassed during inference for efficiency; its primary role is in representation learning during training.
Implications and Future Directions
DriveVLA-W0 demonstrates that dense, predictive world modeling is essential for unlocking the full scalability of VLA models in autonomous driving. The paradigm enables superior generalization, data efficiency, and planning performance, and fundamentally reshapes the scaling law. The observed reversal in action decoder performance at scale suggests that model selection should be data-regime-aware. Future work may explore integrating world modeling objectives into closed-loop planning, extending to multi-agent scenarios, and leveraging generative models for simulation and safety-critical data augmentation.
Conclusion
DriveVLA-W0 establishes world modeling as a critical ingredient for scalable, generalized autonomous driving intelligence. By supplementing sparse action supervision with dense future image prediction, it amplifies the data scaling law, enables robust generalization, and achieves state-of-the-art performance with efficient real-time deployment. The findings advocate for a shift toward dense, predictive objectives in large-scale VLA model training, with significant implications for both research and industrial deployment in autonomous driving.