- The paper presents a teacher–student distillation framework that uses generative world models to synthesize structured supervision for trajectory prediction.
- It integrates semantic-spatial memory, geometric planning, and explicit obstacle grounding to generate traversable navigation paths from single observations.
- Experimental results show WorldMAP outperforms baseline VLMs with lower ADE and FDE, marking significant improvements in accuracy for vision-language navigation.
WorldMAP: Bootstrapping Vision-Language Navigation Trajectory Prediction with Generative World Models
Introduction and Motivation
The study presents WorldMAP, a teacher–student distillation framework for vision-language navigation (VLN), addressing persistent deficits in navigation trajectory prediction from limited egocentric observations. While Vision-LLMs (VLMs) are effective at high-level semantic understanding and generative world models provide look-ahead reasoning via imagined futures, neither alone nor in naive combination yields reliable, traversable navigation trajectories from a single observation. Prior evidence demonstrates that VLMs' direct trajectory outputs are unstable, and world-model generations, though visually plausible, often lack actionable or geometrically grounded structure for navigation learning.
WorldMAP (World-Memory-Action-Perception) proposes a structured, two-stage approach: a world-model-driven teacher synthesizes structured supervision—converting generated future observations into persistent semantic-spatial memory, target/obstacle grounding, and explicit planning; a lightweight student is distilled on these pseudo-labels for direct, efficient vision-language-to-trajectory prediction at inference (Figure 1). This conceptual separation between complex scene-level reasoning (expensive, slow, and explicit at training) and amortized scene-to-action mapping (fast and compact at test time) has significant implications for the embodied AI community.
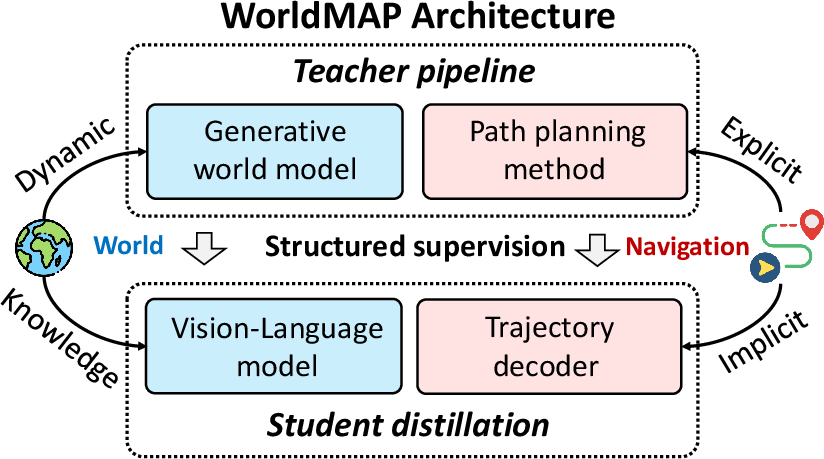
Figure 1: Teacher-student distillation in WorldMAP: a world-model-driven teacher produces grounded supervision for a vision-language student trajectory predictor.
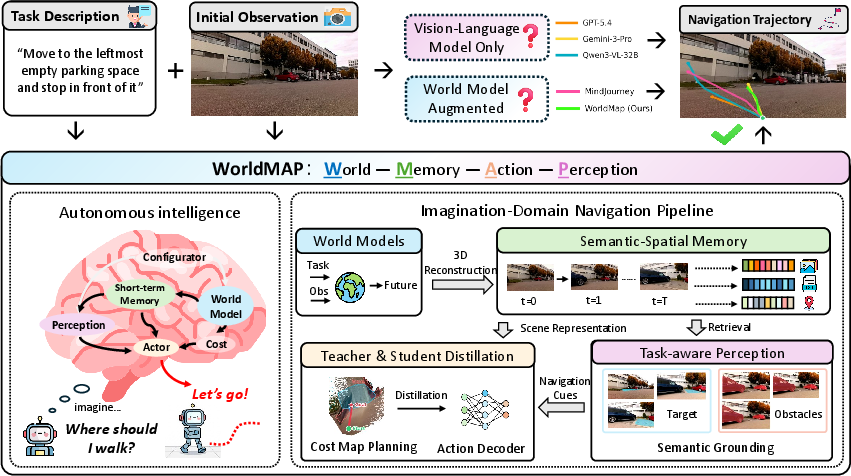
Figure 2: Shortcomings of VLM-only and naive world-model augmentation; WorldMAP's factorized architecture for robust trajectory learning.
Structured spatial representations remain crucial in navigation, both in classical SLAM-based pipelines and in recent learned embodied agents that leverage differentiable scene graphs, top-down semantic maps, or volumetric representations. World models have been previously deployed for mental simulation, imagined planning, and derived multi-view context, as exemplified by PathDreamer, Dreamwalker, NavMorph, and related frameworks. However, studies such as Target-Bench and NaviTrace have highlighted instabilities when these models are used naively at test time for downstream decisions.
VLMs, notably in approaches like LM-Nav, VLMnav, and PIVOT, have demonstrated improved language grounding but substantial geometric and navigational errors when required to output spatially consistent traces. Concurrent research on test-time augmentation with generated views (e.g., MindJourney, ImagineNav) further reveals that unfiltered imagination may introduce noise rather than guidance, especially when cross-view consistency is absent.
WorldMAP distinguishes itself by employing world models not as real-time evidence providers, but as engines for synthesizing persistent supervision—thus inverting the "imagination at test time" paradigm.
Methodology
Overall Architecture
WorldMAP is decomposed into a teacher–student framework (Figure 3). The teacher, given an egocentric RGB image and language instruction, generates multimodal future observations via world models. These are transformed into a persistent semantic-spatial memory, supporting both 3D geometric planning and task-aware semantic grounding.
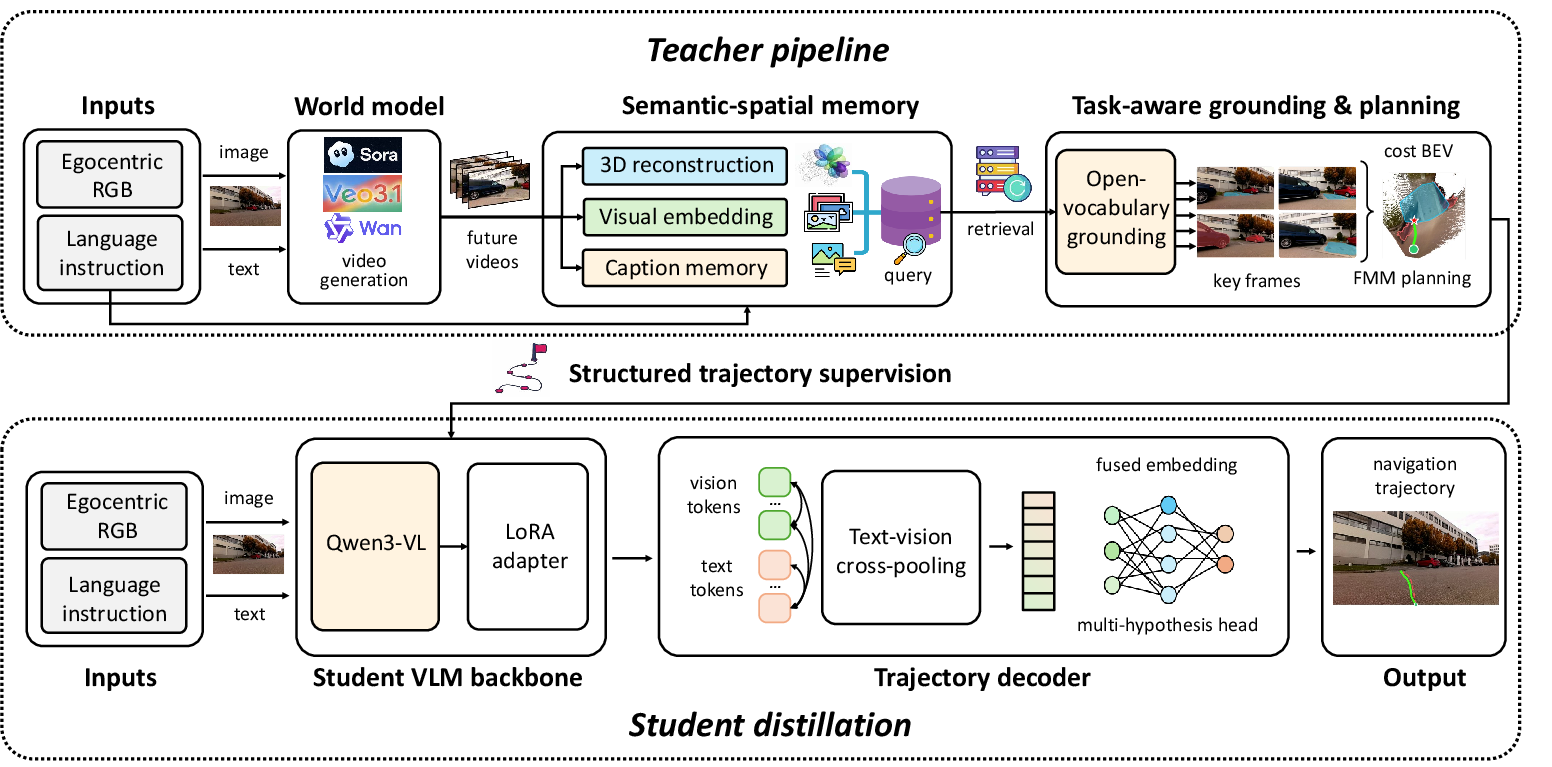
Figure 3: WorldMAP architecture: pipeline for teacher-driven trajectory supervision and streamlined student inference.
The teacher pipeline consists of:
- World Construction: Monocular depth is inferred for generated frames (using Depth Anything 3), backprojected into a scene-level grid, forming the scene's ground plane and corresponding BEV representation.
- Task-Aware Grounding: Semantic retrieval leverages CLIP similarities to locate instruction-relevant views. Open-vocabulary segmentation (UniPixel) provides target and obstacle masks, which are fused across viewpoints and projected into BEV coordinates.
- BEV Planning: Cost maps are constructed with blocked cells for obstacles, safety margins, and conservative treatment of unobserved regions. FMM is used for trajectory generation, with smoothing and waypoint resampling.
Pseudo-trajectories derived from this process represent robust, geometrically feasible navigation paths aligned with grounded semantic entities, forming high-value supervision (Figure 4).
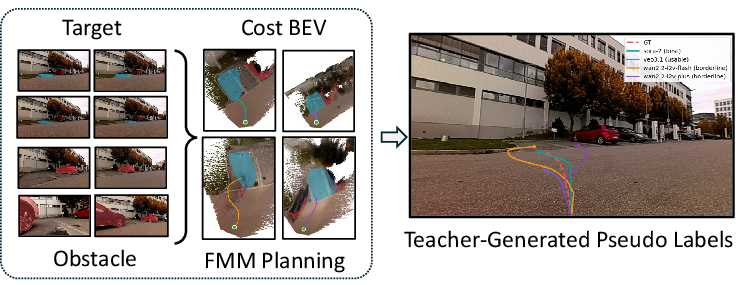
Figure 4: Generation of pseudo-labels—multi-view target and obstacle grounding fused into BEV cost maps and planned trajectories.
The student model is a compact vision-language predictor emitting K trajectory hypotheses, distilled using the best-of-K regression and direction consistency objectives on pseudo-labels plus any available ground-truth. Thus, complex scene reasoning occurs only at train time; inference is a single forward pass.
Experimental Evaluation
The principal benchmark is Target-Bench, a real-world navigation dataset capturing challenging indoor/outdoor scenarios with minimal prior observation. Evaluation employs ADE (Average Displacement Error), FDE (Final Displacement Error), and normalized DTW on 2D projected trajectories.
WorldMAP is compared against direct trajectory prediction by strong proprietary VLMs (GPT-5.4, o3, Gemini-3-Pro), open-source VLMs (Qwen3-VL-4B/8B/32B, InternVL3-14B), and the MindJourney world-model-augmented baseline (which applies generated views as test-time evidence). The key findings are:
- WorldMAP yields the lowest ADE and FDE across all methods, outperforming Gemini-3-Pro (ADE: 42.06 vs. 51.27, FDE: 38.87 vs. 67.19), and achieves competitive normalized DTW (31.95 vs. 31.63).
- MindJourney underperforms even its direct VLM baseline, indicating that unfiltered test-time imagination can degrade performance, particularly in cases where imagined views are geometrically inconsistent with real scene structure.
- The magnitude of improvement from supervision distillation dominates gains from simply increasing student backbone scale.
Qualitative results (Figure 5) confirm that WorldMAP consistently produces traversable, grounded, and instruction-compliant paths, whereas baselines show drift, overshoot, and violations of scene geometry.

Figure 5: Qualitative comparison—WorldMAP produces navigation traces that are not only semantically consistent but also geometrically plausible and safe.
Ablation studies on supervision quality (curated using a VLM-based protocol, Figure 6) demonstrate that high-quality pseudo-labels are indispensable—mixed or low-quality generations significantly harm downstream trajectory accuracy.
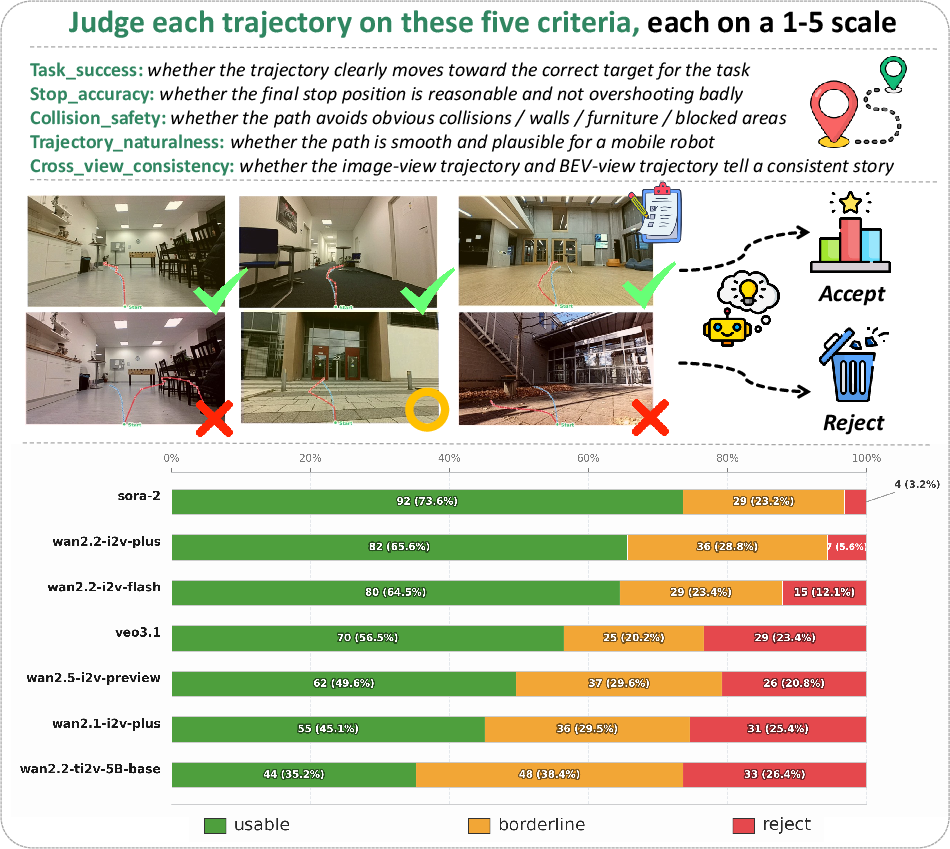
Figure 6: VLM-based multi-criteria quality assessment for pseudo-label selection into training supervision.
Analysis and Implications
The central empirical finding is stark: direct VLM prediction remains unreliable, even for strong proprietary models, while indirect supervision via planning-driven pseudo-labels raises even small open-source VLMs to competitive performance on challenging navigation metrics.
WorldMAP demonstrates that world models' value is maximized not when their generated views are consumed at test time, but when they enable the synthesis of structured, persistent semantic and geometric reference frames from which more robust policies can be distilled. This conclusion is supported both by quantitative metrics and by the observed brittleness of real-time imagination in MindJourney and related approaches.
This reinforces a "fast–slow" system perspective: the teacher (slow, expensive, deliberate) amortizes complex long-horizon reasoning into training supervision; the student (fast, efficient) inherits navigation competence without the need for explicit scene reasoning at inference.
Limitations remain, including reliance on the fidelity of world-model generations, incomplete handling of highly dynamic scenes or multi-level structures, and potential error propagation in target/obstacle segmentation when future imagination is itself uncertain or misaligned.
Conclusion
WorldMAP advances the state of VLN by structurally leveraging the strengths of generative world models and VLMs within a principled teacher–student pipeline. The approach reframes the role of world models: not as direct action policymakers but as supervision generators—fusing semantic memory, geometric grounding, and explicit planning into robust navigational pseudo-labels. This enables lightweight, efficient vision-language navigation agents that are robust to the spatial and semantic ambiguities present in real-world settings.
The theoretical and practical implications are clear: for long-horizon, grounded trajectory prediction, distillation via explicit, structured supervision is superior to direct generative inference or naive test-time imagination. Future directions may explore tighter coupling between world model generation quality, richer semantic map synthesis, and more nuanced uncertainty modeling in both the teacher and student, as well as broader generalization to dynamic or open-world scenes.

Figure 7: Representative examples of 3D SLAM trajectory projection onto 2D first-person frames underlying ground-truth references.

Figure 8: Scene-specific homography protocol for precise alignment of imagined and true navigation traces.
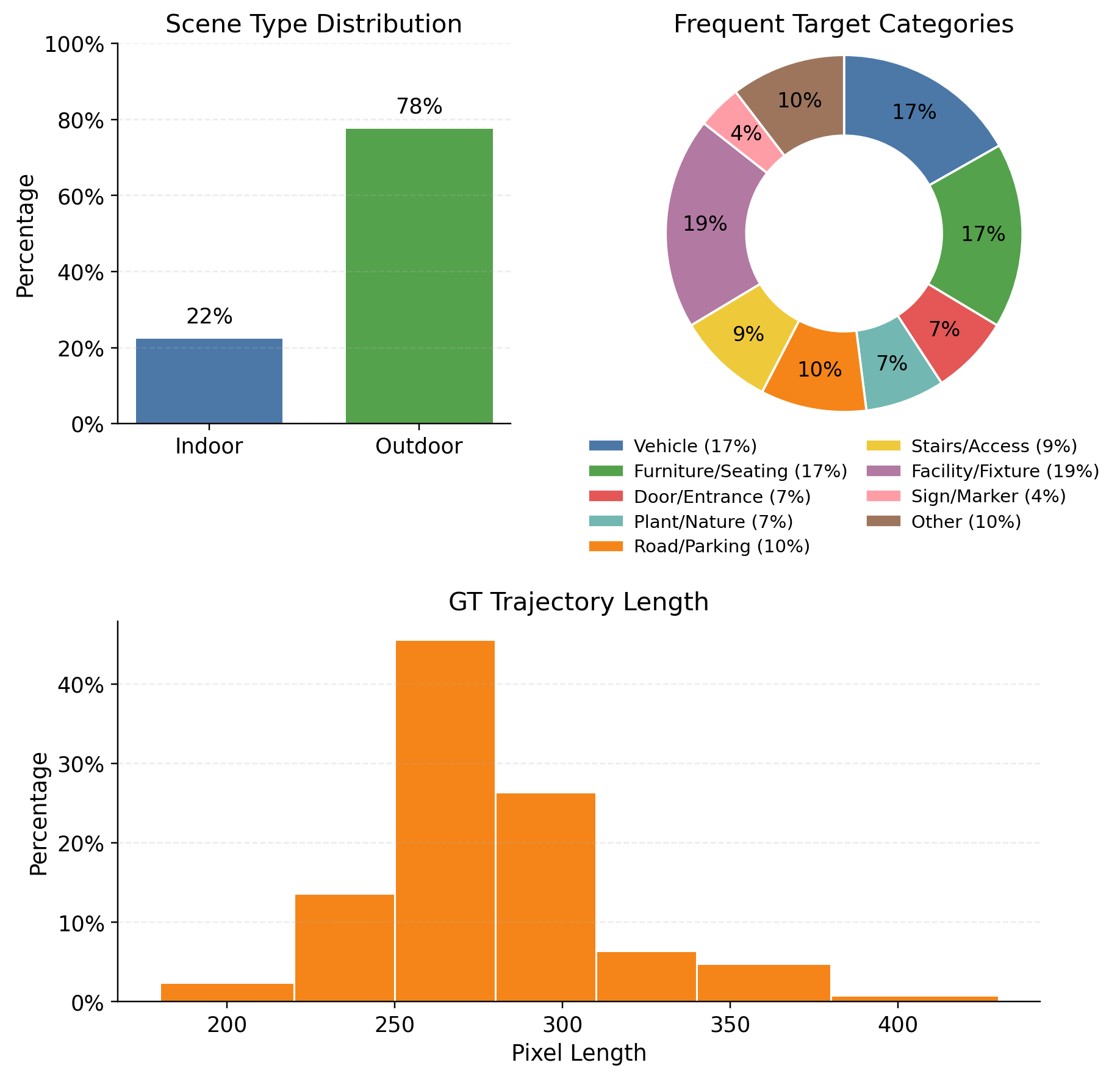
Figure 9: Statistics of the processed Data—indoor/outdoor split, target categories, and path lengths.
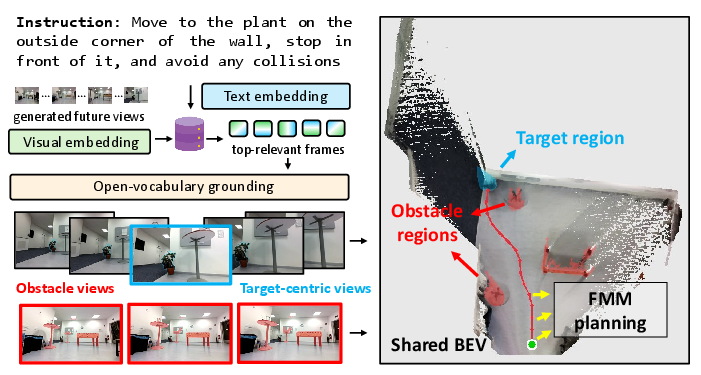
Figure 10: Intermediate teacher pipeline stages—memory retrieval, multi-view semantic segmentation, BEV fusion, and FMM planning.

Figure 11: Additional qualitative results—WorldMAP produces navigation outputs closely matching ground-truth in diverse environments.
Reference: "WorldMAP: Bootstrapping Vision-Language Navigation Trajectory Prediction with Generative World Models" (2604.07957)