- The paper introduces a novel framework that integrates future visual supervision into a recurrent latent state for proactive navigation.
- It leverages a lightweight Pilot Token to embed action-conditioned visual reasoning directly into the decision backbone without external rollouts.
- Experimental results demonstrate significant improvements in navigation accuracy, efficiency, and real-world transferability across various VLN benchmarks.
LatentPilot: Internalized Latent Visual Foresight for Vision-and-Language Navigation
Introduction
LatentPilot introduces a novel approach for Vision-and-Language Navigation (VLN) by internalizing action-conditioned latent visual dynamics directly into the agent’s decision backbone. Existing VLN methods predominantly focus on reasoning over historic and current observations while disregarding future visual consequences of actions, resulting in myopic or reactive policies. Contrastingly, LatentPilot leverages future observations as privileged supervision strictly during training, converting trajectory hindsight into foresight representations but retaining causality at inference. This is operationalized via a light-weight step-propagated latent ("Pilot Token") that recurrently grounds anticipatory reasoning and is updated in the backbone itself—eschewing any need for explicit world-model rollouts or external predictive computation at test time. The paradigm systematically bridges the gap between offline trajectory knowledge and real-time navigation, demonstrating substantial improvements on continuous VLN benchmarks (R2R-CE, RxR-CE, R2R-PE) and in real-world, cross-embodiment robot settings.
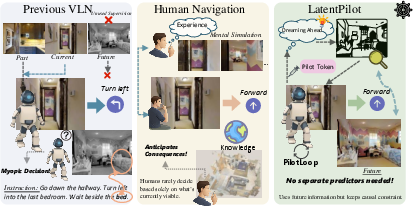
Figure 1: Prior approaches ignore supervision from future observations, while LatentPilot uses them during training only, maintaining causal inference.
Methodology: Propagated Latent Visual Dynamics
LatentPilot’s architecture is based on a vision encoder, a large vision-LLM backbone, and a lightweight Pilot module. At every timestep, the current observation is encoded into visual tokens. The backbone consumes language tokens, visual tokens, and the prior step’s Pilot Token, concatenated into a multimodal context. The Pilot Token is a persistent, continuous latent state, carried forward at each navigation action and serving as a vehicle for compact scene anticipation without explicit chain-of-thought or external rollouts.
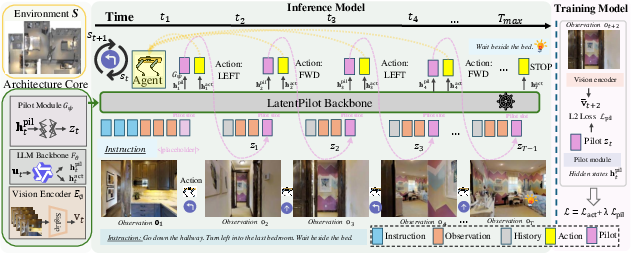
Figure 2: Overview of LatentPilot inference. Visual tokens and prior Pilot Token are integrated for recurrent action selection and latent update.
During training, LatentPilot employs a two-step privileged supervision mechanism: the one-step future visual embedding is fed as the input Pilot slot, and the two-step future view serves as the regression target for the predicted Pilot Token. This design aligns the latent with action-conditioned consequences, enabling single-model amortization of anticipation and control. Crucially, at test time, only the causal (current and prior) observations and the prior latent are used; no future views or external prediction is permitted.
To further improve robustness and close the train-test gap, a flywheel-style closed-loop (PilotLoop) training regimen is adopted. On-policy rollouts under the evolving policy are corrected by expert takeover upon excessive deviation, and these new trajectories are used to iteratively update the model.
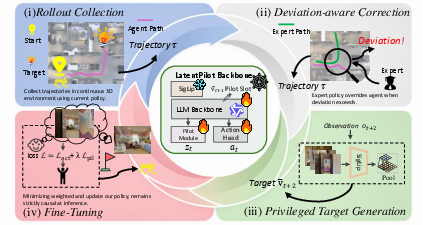
Figure 3: PilotLoop flywheel training alternates trajectory collection, expert correction, future-privileged target extraction, and joint fine-tuning.
Experimental Results
LatentPilot is evaluated under both simulation (VLN-CE) and physically realistic (VLN-PE) settings. Strong numerical results are reported: On R2R-CE Val-Unseen, LatentPilot achieves Navigation Error of 4.41m, Success Rate of 62%, and SPL of 58.0—outperforming all prior RGB-only approaches and even methods reliant on panoramic or geometric modalities. On the RxR-CE Val-Unseen split, similar dominant gains are observed. Notably, in the physically realistic VLN-PE scenario, LatentPilot retains higher SR and lower NE than all prior art, including methods with explicit world models or additional sensors.
Ablations establish the critical importance of visual future supervision; naive propagation, textual, or geometric proxies significantly underperform. Comparisons with plug-in video world models reveal LatentPilot is not only superior in navigation scores but also 10–40× faster with markedly lower memory footprint.
Latent space diagnostics confirm the avoidance of collapse: PCA projections of the propagated Pilot Token demonstrate well-structured action-related variation rather than degeneration to trivial or uninformative vectors.
LatentPilot is also deployed on real robots (wheeled and quadruped), maintaining multi-step instruction following and successful zero-shot transfer from simulation to hardware, evidencing strong generalization and practicality.

Figure 4: LatentPilot controlling wheeled and quadruped robots for long-horizon, multi-step navigation under natural-language instructions.
Practical and Theoretical Implications
By internalizing action-conditioned visual dynamics into a compact, step-propagated latent, LatentPilot provides a mechanism for "dreaming ahead" within the inference path of a vision-language backbone, as opposed to explicit planning, external world-model rollouts, or chain-of-thought sample explosion. This reduces policy-model mismatch, compounding prediction errors, and heavy computation costs endemic to prior approaches. The architecture integrates latent visual reasoning with the flexibility to reuse learned dynamics across robot morphologies and sensor suites. The privileged training regime (LUPI) is strictly enforced so that inference remains deployable and causal.
Theoretically, LatentPilot's success validates the efficacy of distilling trajectory consequences as latent causal state within the policy network, aligning embodied anticipation with amortized latent state propagation. This methodological shift can be extended to other embodied control and sequential LM tasks where foresight is crucial yet full rollouts are intractable or leak future information.
Conclusion and Future Outlook
LatentPilot establishes a robust, unified framework for vision-and-language navigation by amortizing scene-level anticipation through a stepwise internal latent state, enabled by privileged future supervision in training. Empirical evidence from simulation, physically realistic, and hardware environments confirms significant advances in navigation accuracy, efficiency, and robustness. This approach paves the way for scalable, deployable scene-understanding agents and suggests promising avenues for integrating latent imagination into broader domains such as agentic planning, temporal reasoning, and real-world robotic control, where strictly causal inference constraints must be preserved.
Reference: "LatentPilot: Scene-Aware Vision-and-Language Navigation by Dreaming Ahead with Latent Visual Reasoning" (2603.29165)