Fast-ThinkAct: Efficient Vision-Language-Action Reasoning via Verbalizable Latent Planning
Abstract: Vision-Language-Action (VLA) tasks require reasoning over complex visual scenes and executing adaptive actions in dynamic environments. While recent studies on reasoning VLAs show that explicit chain-of-thought (CoT) can improve generalization, they suffer from high inference latency due to lengthy reasoning traces. We propose Fast-ThinkAct, an efficient reasoning framework that achieves compact yet performant planning through verbalizable latent reasoning. Fast-ThinkAct learns to reason efficiently with latent CoTs by distilling from a teacher, driven by a preference-guided objective to align manipulation trajectories that transfers both linguistic and visual planning capabilities for embodied control. This enables reasoning-enhanced policy learning that effectively connects compact reasoning to action execution. Extensive experiments across diverse embodied manipulation and reasoning benchmarks demonstrate that Fast-ThinkAct achieves strong performance with up to 89.3\% reduced inference latency over state-of-the-art reasoning VLAs, while maintaining effective long-horizon planning, few-shot adaptation, and failure recovery.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to think and act quickly. It introduces Fast-ThinkAct, a method that helps a robot look at a scene (vision), understand a written instruction (language), and decide what to do next (action) without wasting time on long explanations. Instead of writing out long step-by-step thoughts, the robot makes short, “hidden” plans that still capture the important ideas. This makes the robot much faster while staying smart and reliable.
What questions does the paper try to answer?
- Can a robot keep the benefits of “thinking out loud” (better planning and generalization) without the slowdowns caused by long explanations?
- Is there a way to pack a robot’s reasoning into short, efficient “internal notes” that still guide good actions?
- Can this fast reasoning help with tough tasks like long, multi-step plans, adapting to new situations with few examples, and recovering from mistakes?
How does Fast-ThinkAct work? (Simple explanation)
Think of two students:
- The Teacher writes long essays explaining every step of a problem.
- The Student learns to write short, powerful notes that contain the same key ideas.
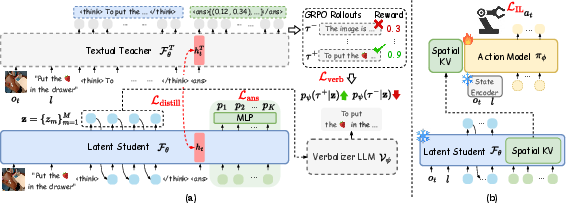
Fast-ThinkAct trains the Student to use short “internal notes” (called latent thoughts) instead of long text. Here’s how the pieces fit together, using everyday analogies:
- Short internal notes (latent thoughts): Instead of writing a long plan in words, the robot creates a few tiny codes—like shorthand—inside its brain. These codes capture the essential plan.
- A translator that checks understanding (verbalizer): During training, there’s a “translator” that can turn those short internal notes back into simple sentences. This ensures the notes actually represent good reasoning, not nonsense.
- Choosing better thoughts with preferences (reward guidance): The Teacher tries several plans and gets a score for each (like trying different solutions and seeing which ones work best). The Student learns to create notes that translate into the Teacher’s best (highest-scoring) plans and avoid the weak ones.
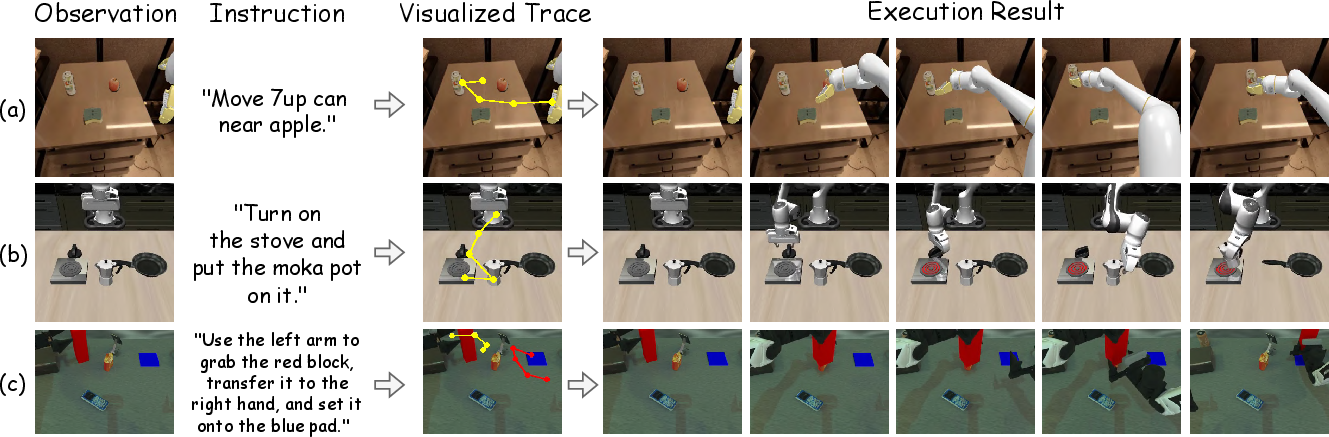
- Visual waypoints for planning movement (spatial tokens): To plan how to move in the scene, the model predicts a few important points (like dots on a map) that the robot’s hand should pass through. This gives a clear, quick-to-compute sketch of the path.
- Turning plans into actions (action model): A separate movement model reads the short plan (the internal notes plus waypoints) and produces smooth, continuous robot actions—like moving arms or hands to the right places. You can think of it as turning a sketch into a dance the robot performs.
- Training phases (big picture): 1) The Teacher practices making long, detailed plans and gets rewards for good results. 2) The Student learns to compress those good plans into short notes that can be translated back into clear reasoning. 3) The movement model learns to follow these short plans to produce precise actions.
At test time (when actually running the robot), only the Student and the movement model are used—no long essays and no translator needed—so it’s fast.
What did they find, and why is it important?
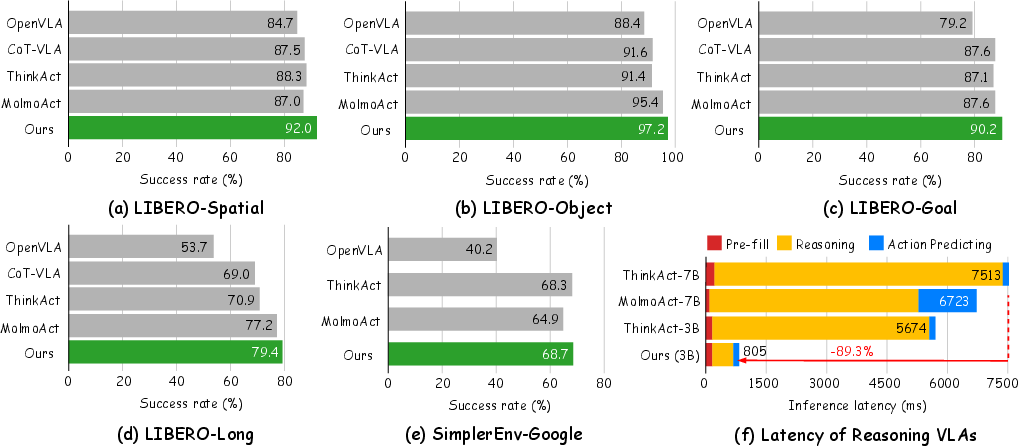
The authors tested Fast-ThinkAct on several robot and reasoning benchmarks. In plain terms, it:
- Became much faster:
- Up to about 89% lower delay (latency) compared to other “thinking” robot models. In many cases, it was around 9× faster than a strong baseline.
- Stayed smart (or got smarter):
- Did better on robot tasks that require planning and manipulation (like stacking, handing over items, or pressing buttons) on benchmarks such as LIBERO, SimplerEnv, and RoboTwin2.0 (including hard, long, two-arm tasks).
- Outperformed other systems on planning and question-answering about what’s happening in videos (EgoPlan-Bench2, RoboVQA, OpenEQA). These measure whether the model can understand and plan in complex, real-life scenes.
- Handled long, multi-step tasks well, showing strong “long-horizon” planning.
- Recovered from failures: it could recognize when things went wrong and suggest fixes—like repositioning the arm before trying to grasp again.
- Adapted from just a few examples (few-shot learning), improving quickly with very little new data.
Why this matters: Robots often need to make decisions many times per second. Long, text-based reasoning slows them down and can be unsafe in time-critical tasks. Fast-ThinkAct keeps the benefits of reasoning while meeting real-time needs.
What does this mean for the future?
- Faster, safer robots: Compact reasoning helps robots react quickly, which is important for real-world jobs like helping at home, assembling parts, or navigating busy spaces.
- Efficient learning and generalization: Because the model keeps the “thinking” benefits in a compressed form, it can handle longer tasks, adapt with fewer examples, and bounce back from errors.
- Still interpretable when needed: Even though it thinks with short, hidden notes, a translator can turn those notes back into readable explanations during training or debugging. That helps humans understand what the robot is planning.
- Limitations and next steps: The translator that turns notes into sentences may sometimes make mistakes (“hallucinate”), but it’s not used during real-time control—only for training and understanding. Future work can make the explanations even more reliable.
In short, Fast-ThinkAct shows that robots don’t have to choose between being thoughtful and being fast—they can do both by learning to think with compact, meaningful internal notes.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions the paper leaves unresolved. These items are intended to be actionable directions for future research.
- End-to-end real-world deployment: No measurement of closed-loop control-cycle frequency (Hz), absolute inference latency, and success rates on physical robots under time-critical constraints and hardware I/O (camera capture, actuation delays).
- Latency breakdown: Reported speedups are token-level; missing an explicit breakdown of end-to-end latency contributions from the student VLM, verbalizer (during training), and diffusion policy, plus CPU/GPU utilization.
- Safety and risk assessment: No evaluation in safety-critical settings (collision avoidance, near-miss rates, emergency stop efficacy) or formal safety certification considerations.
- Reward sensitivity and stability: Lacking ablations on teacher GRPO reward components, their relative weighting, and training stability across diverse task families; unclear robustness to reward misspecification.
- Verbalizer-induced bias: Although hallucination is acknowledged, there is no quantification of how verbalizer inaccuracies affect latent learning during training or methods to audit and mitigate this impact.
- Faithfulness of latent-to-text decoding: Missing metrics to validate that decoded text reliably reflects latent plans (e.g., alignment scores, consistency checks, counterfactual tests).
- Distillation granularity: Trajectory alignment uses an L2 match on a single <answer> token hidden state; the effect of multi-token, multi-layer, or sequence-level/contrastive alignment is unexplored.
- Spatial representation limits: Latent plans produce 2D waypoints; depth/3D pose, camera calibration, and world-coordinate planning are not addressed, limiting generalization to varied viewpoints and 6D action spaces.
- Latent and waypoint budget: No systematic analysis of how the number of latent tokens (M) and waypoints (K) affect accuracy, robustness, and latency; adaptive token budgeting remains open.
- KV cache layer selection: The layer(s) used to extract c_t are not justified; ablations to determine optimal layers/adapters and their impact on policy performance are missing.
- Embodiment generalization: Transfer to other platforms (mobile bases, multi-finger hands), non-prehensile/manipulative skills, and multi-contact tasks is untested.
- Domain shift robustness: Stress-testing under severe variations (lighting, occlusion, clutter, distractors, camera pose) beyond SimplerEnv is missing; worst-case performance analysis is needed.
- Online replanning and closed-loop recovery: Failure detection is evaluated via QA datasets; integration that updates c_t during execution for real-time recovery is not demonstrated or quantified.
- Multimodal sensing: Reasoning is vision-centric; incorporating proprioception, force/torque, tactile, and audio signals into latent planning remains open.
- Data/compute efficiency: The approach still leverages large 2D trajectory annotations; no quantitative comparison of annotation costs and training compute versus supervised CoT or other efficient baselines.
- Evaluation metrics: Heavy reliance on LLM-based scoring (OpenEQA, RoboFAC) without human-grounded or task-grounded metrics; reproducibility and metric robustness need verification.
- Baseline comparability: Training data, model sizes, and action backbones differ across baselines; controlled comparisons and harmonized settings are needed to establish fair performance claims.
- Policy latency trade-offs: Diffusion policies can be slow; a direct comparison of policy architectures (diffusion vs deterministic Transformer/MPC) under identical latent conditioning is missing.
- Scaling laws: Results are on a 3B backbone; whether latent reasoning gains persist or improve at larger model scales (7B/8B/72B) is an open question.
- Edge-device viability: Memory footprint, throughput, and thermal constraints on robot edge hardware (e.g., Jetson) are not reported; on-device optimization strategies are unexplored.
- Long-horizon memory: Persistence of plans across timesteps and memory mechanisms (e.g., latent state carryover, external memory) are not studied; handling delayed rewards and plan drift is open.
- Object grounding: How latents encode object selection, affordances, and constraints in multi-object scenes is unclear; integration with detection/segmentation for precise grounding is needed.
- Label noise analysis: Dual-arm trajectory labels extracted via CoTracker may be noisy; there is no error analysis or study of label noise impact on student training and downstream policy.
- Preference pair construction: Using only top/bottom samples may limit learning signal; exploring richer pairwise rankings, margin tuning, and sensitivity to the β parameter is needed.
- Interpretability and editability: Tooling to inspect, edit, and constrain latent thoughts (e.g., mapping to subgoals, constraints, uncertainty) is not provided; interactive plan correction is open.
- Risk-aware planning: No methods to incorporate uncertainty estimates or risk constraints into latent planning for safer execution.
- Dynamic agents/humans: Handling moving objects/humans, social compliance, and forecasting in shared spaces is not evaluated.
- Temporal input modeling: Clarity on whether o_t is a single frame or short video is missing; systematic evaluation of temporal encoders and their benefit to latent reasoning is needed.
- Lifelong learning: Few-shot adaptation is shown, but catastrophic forgetting under continual fine-tuning and strategies for lifelong/multi-environment learning remain unaddressed.
- Negative transfer and data mixing: The effects of mixing heterogeneous datasets on reasoning quality and action performance (curriculum, sampling strategies) are not analyzed.
- Viewpoint invariance: Camera/viewpoint invariance of 2D tokens is assumed; cross-view consistency and multi-view training to ensure robust generalization are open.
Glossary
- Action-aligned visual plan distillation: A distillation method that transfers a teacher model’s spatial reasoning to a student by aligning plan-related hidden states. "we introduce action-aligned visual plan distillation to transfer the teacher 's spatial reasoning ability to the student ."
- Advantage function: In reinforcement learning, a measure of how much better a trajectory is compared to others in its group. "The advantage function for group rewards is represented as:"
- Autoregressively: A generation mode where outputs (tokens or latents) are produced sequentially, each conditioned on previously generated elements. "the student model performs latent reasoning by autoregressively generating continuous latent vectors"
- BLEU score: An n-gram-based metric for evaluating the quality of generated text against references. "RoboVQA~\cite{sermanet2024robovqa} (BLEU score~\cite{papineni2002bleu})"
- Bimanual manipulation: Robotic manipulation requiring coordinated control of two arms/grippers. "a challenging bimanual manipulation benchmark requiring long-horizon planning."
- Chain-of-thought (CoT): Explicit step-by-step intermediate reasoning used to improve generalization and planning. "explicit chain-of-thought (CoT) can improve generalization"
- CoT-SFT: Supervised fine-tuning on chain-of-thought data to teach models explicit reasoning patterns. "followed by CoT-SFT for 15K iterations with the same hyperparameters."
- Denoising objective: The loss used in diffusion models/policies that trains the model to reconstruct clean signals from noise. "where denotes the denoising objective for diffusion policy"
- Diffusion policy: An action-generation policy modeled as a diffusion process to sample control sequences. "denoising objective for diffusion policy"
- Diffusion Transformer: A Transformer architecture used to implement diffusion-based policies for action generation. "a diffusion Transformer-based action model (e.g., RDT~\cite{liu2024rdt})"
- DiT-Policy: A diffusion Transformer-based policy model for robotic control. "we initialize from DiT-Policy~\cite{chi2023diffusion} pre-trained on OXE~\cite{o2024open}"
- Direct Preference Optimization (DPO): A training method that learns from preference pairs by directly optimizing likelihood ratios without explicit reward modeling. "Inspired by DPO~\cite{rafailov2023direct}, we formulate this as an optimization guided by the reward preferences:"
- Domain randomization: Varying environment parameters (e.g., visuals, dynamics) during training/evaluation to improve robustness and generalization. "E and H denote easy and hard settings (without/with domain randomization)."
- DOF: Degrees of Freedom; the number of independent control variables in a robot. "represented as a sequence of continuous robot control vectors (e.g., 7- or 14-DOF for single- or bimanual robots, respectively)."
- ECoT-Lite: An approach that accelerates embodied reasoning by dropping or skipping explicit reasoning traces at inference. "ECoT-Lite~\cite{chen2025training} proposes reasoning dropout to accelerate inference"
- EgoPlan-Bench2: A benchmark evaluating multi-step planning in egocentric everyday scenarios. "we use EgoPlan-Bench2~\cite{qiu2024egoplan2} (accuracy on multiple-choice questions)"
- Embodied AI: AI systems that perceive and act in physical or simulated environments via sensors and effectors. "In embodied AI applications such as robotic manipulation and autonomous driving"
- Failure recovery: Detecting execution errors and generating corrective plans to recover and complete the task. "while maintaining effective long-horizon planning, few-shot adaptation, and failure recovery."
- GRPO: Group Relative Policy Optimization; an RL training algorithm using group-wise relative advantages to guide policy updates. "The teacher is trained with GRPO~\cite{shao2024deepseekmath} using action-aligned rewards~\cite{huang2025thinkact}"
- Imitation learning: Learning a policy by mimicking actions from expert demonstrations. "updating only with the imitation learning objective"
- Key-value cache (KV cache): Cached attention keys and values used for conditioning or speeding up inference across modules. "We extract visual latent planning from the KV cache of spatial tokens"
- Key-value pairs (KV pairs): The key and value tensors used in attention mechanisms to compute context-weighted outputs. "concatenate with KV pairs from the action model's state encoder."
- Latent chain-of-thought (CoT): Reasoning represented in continuous hidden states instead of explicit text tokens. "latent chain-of-thought (CoT) reasoning to produce a compact visual plan latent "
- Long-horizon planning: Planning over extended sequences with multiple steps and dependencies, often beyond training distributions. "demanding robust long-horizon planning and contextual adaptation."
- Preference-based learning: Training guided by comparisons (preferences) between outputs, favoring higher-quality solutions. "we adopt a preference-based learning framework"
- Preference-guided distillation: Distilling a teacher’s reasoning into a student using preference signals to emphasize high-quality reasoning. "We introduce preference-guided distillation with manipulation trajectory alignment"
- RDT: A diffusion Transformer policy model for robotic control and trajectory generation. "a diffusion Transformer-based action model (e.g., RDT~\cite{liu2024rdt})"
- Reinforcement fine-tuning: Post-training via reinforcement learning on task-specific rewards to improve performance. "recent works~\cite{yuan2025embodied,huang2025thinkact} alternatively leverage reinforcement fine-tuning to generate reasoning chains"
- SFT: Supervised fine-tuning on labeled datasets to adapt a pre-trained model. "The SFT stage runs for 1 epoch with batch size 64 and learning rate "
- Spatial tokens: Learnable tokens that represent waypoints or spatial elements, enabling parallel trajectory prediction. "the student uses learnable spatial tokens "
- Teacher-student framework: A setup where a student model learns by distilling knowledge/signals from a stronger teacher. "we employ a teacher-student framework where a textual teacher model first learns explicit reasoning"
- Trajectory-level rewards: Rewards assessed over entire action sequences to encourage coherent plans and successful outcomes. "which is trained with trajectory-level rewards (e.g., goal completion and trajectory alignment~\cite{huang2025thinkact})"
- Verbalizer LLM: A LLM that decodes latent representations into natural language to make latent reasoning interpretable and trainable. "We then train the verbalizer LLM to decode these latents into natural language."
- Visual latent planning: A compact latent representation of intended visual trajectories or plans. "We extract visual latent planning from the KV cache of spatial tokens"
- Visual trajectory alignment: Aligning trajectories or plan representations in visual space to transfer planning capabilities. "reward-guided preference distillation with visual trajectory alignment to compress linguistic and visual planning"
- Visual traces: 2D path annotations that depict intended motion for manipulation in images/videos. "generate structured visual reasoning representations such as sub-goal images, image depth, and 2D visual traces"
- Vision-Language-Action (VLA): Models integrating perception (vision), language understanding, and action generation for embodied tasks. "Vision-Language-Action (VLA) tasks require reasoning over complex visual scenes and executing adaptive actions in dynamic environments."
- Vision-LLMs (VLMs): Models that process and understand both visual inputs and language. "Recent large vision-LLMs (VLMs)~\cite{liu2023visual,comanici2025gemini,liu2024nvila,bai2025qwen2,shi2024eagle,li2025eagle,chen2025eagle,wang2025internvl3,xie2024show}"
- Waypoints: Intermediate target positions used to specify and plan a trajectory through space. "with each output hidden state simultaneously projected to a waypoint via an MLP."
Practical Applications
Overview
Below are practical, real-world applications that stem from the paper’s findings and innovations in efficient Vision-Language-Action (VLA) reasoning via verbalizable latent planning. Each item notes the sector, concrete use case, potential tools/products/workflows that could emerge, and assumptions/dependencies affecting feasibility.
Immediate Applications
- Robotics and Manufacturing (assembly, pick-and-place, quality checks)
- Use case: Replace verbose reasoning VLAs in robotic cells with Fast-ThinkAct to reduce cycle time for single- and bimanual tasks (e.g., fastening, cable routing, tool handover).
- Tools/Workflows: “Fast-ThinkAct Policy Module” (student VLM + RDT/DiT policy), spatial-token trajectory head to emit parallel waypoints, ROS2/MoveIt/Isaac Sim integration, on-robot edge inference (3B VLM).
- Assumptions/Dependencies: Calibrated cameras and stable viewpoints; sufficient task demonstrations (few-shot OK); safety guardrails and PLC integration; access to OXE/ALOHA-like data for pretraining; GPU/accelerator availability.
- Logistics and Warehousing (bin picking, packing, kitting)
- Use case: Few-shot adaptation to new SKUs with rapid training from ~10 demonstrations; failure recovery to reduce mis-picks using video-based reasoning signals.
- Tools/Workflows: SKU onboarding pipeline with “Reasoning-Enhanced Policy Learning” and a failure-analysis dashboard powered by RoboFAC-style prompts; trajectory latent cache sharing with pick controller.
- Assumptions/Dependencies: Reliable object perception under varied lighting; minimal occlusion or additional depth sensing; on-premise compute for latency targets (1–15 Hz).
- Retail Operations (stocking, returns handling, backroom tasks)
- Use case: Compact latent planning for deformable item handling (bags, clothing), reducing inference delays that cause stoppages on crowded shelves.
- Tools/Workflows: Store-level “Latent Planning Service” that schedules micro-updates from short demos; audit-friendly verbalizer for explanations to staff.
- Assumptions/Dependencies: Domain-specific visual traces; human-in-the-loop oversight; safe motion primitives for tight spaces.
- Healthcare and Assistive Robotics (bedside support, rehab aids)
- Use case: Assistive manipulation (fetching items, opening doors) with faster decision rates and failure recovery prompts for human caregivers.
- Tools/Workflows: Low-latency assist module with optional verbalized guidance for operators; teleoperation with latent planning overlays.
- Assumptions/Dependencies: Regulatory compliance (medical-grade hardware); rigorous safety policies; supervision where needed; diverse environment coverage for generalization.
- Agriculture (harvesting, sorting, packing)
- Use case: Few-shot adaption to new crops/varieties and quick reconfiguration of manipulation routines across seasons.
- Tools/Workflows: Field-deployable “Latent Planning + Policy” bundle with domain-randomized simulation pretraining; mobile GPU inference.
- Assumptions/Dependencies: Outdoor robustness (lighting, weather); possible need for depth/tactile sensing; stable camera calibration on mobile platforms.
- Software Engineering and ML Ops (VLA systems optimization)
- Use case: Drop-in replacement of textual CoT with verbalizable latent reasoning to cut inference latency and cost in embodied pipelines.
- Tools/Workflows: SDK components: “Preference-Guided Distillation Trainer,” “Spatial Token Trajectory Head,” “Verbalizer for audit-only,” “KV-cache projector” into diffusion policies; monitoring for runtime failures.
- Assumptions/Dependencies: Access to teacher GRPO training with action-aligned rewards; compatibility with existing controllers; quantization-friendly model variants.
- Policy and Safety Operations (industrial safety governance)
- Use case: Maintain audit trails via optional verbalized latents and deploy failure recovery checklists to reduce incident rates in time-critical tasks.
- Tools/Workflows: SOPs that codify failure detection and corrective steps; compliance logs using verbalizer outputs; risk dashboards correlating latency and incident metrics.
- Assumptions/Dependencies: Clear governance on what constitutes acceptable “interpretability”; acknowledgment that verbalizer can hallucinate (audit use only); human review protocols.
- Education and Academic Labs (embodied AI courses, research)
- Use case: Teach efficient embodied reasoning and planning with compact latents; run reproducible labs on EgoPlan/RoboVQA/RoboFAC.
- Tools/Workflows: Open training recipes for teacher-student distillation; benchmark harnesses; curriculum modules illustrating spatial tokens and KV-cache conditioning.
- Assumptions/Dependencies: Moderate GPU resources; data licensing and access; reproducible seeds and logging for pedagogy.
- Daily Life and Home Robotics (tidying, kitchen assistance)
- Use case: Household robots perform long-horizon tasks (load dishwasher, clear tables) with few-shot teaching-by-demonstration and reduced wait times.
- Tools/Workflows: “Home Teach-and-Repeat” workflow: user records a handful of demos; robot fine-tunes policy; failure-guidance overlays for the user in a companion app.
- Assumptions/Dependencies: Affordable hardware with camera calibration; variability in home layouts; strong safety constraints; optional human supervision.
Long-Term Applications
- Autonomous Driving and Mobile Robotics
- Use case: Latent reasoning for fast spatiotemporal decision-making in navigation and complex maneuvers; reduce planning delays relative to textual CoT.
- Tools/Workflows: Multi-sensor latent planning heads (lidar/camera fusion), preference-guided distillation with traffic-rule rewards, real-time trajectory tokens for MPC.
- Assumptions/Dependencies: Extensive validation in diverse conditions; robust reward design; stringent regulatory approval.
- Multi-Robot Coordination and Swarm Manipulation
- Use case: Share compact visual-plan latents across robots to coordinate handovers or assembly lines without verbose messaging.
- Tools/Workflows: “Latent Plan Exchange Protocol” for KV-cache snippets; multi-agent cross-attention; fleet-level failure recovery strategies.
- Assumptions/Dependencies: Communication reliability and bandwidth guarantees; standardized latent formats; joint safety certification.
- Generalist Household Robot Platform
- Use case: End-to-end home assistant with efficient reasoning, few-shot personalization, and recovery guidance for complex chores.
- Tools/Workflows: Productized “Fast-ThinkAct SDK” with on-device optimized models; user-friendly demonstration tools; optional audit verbalizer for transparency.
- Assumptions/Dependencies: Broad, high-quality multimodal datasets; robust hardware; strong safety and privacy features; consumer-grade reliability.
- Healthcare Robotics (surgical assistance, sterile handling)
- Use case: Latent planning for precise, long-horizon procedures under supervision; fallback reasoning for anomaly recovery.
- Tools/Workflows: Multi-modal integration (vision + force/tactile), clinical SOP-aligned reward design, real-time verification mechanisms.
- Assumptions/Dependencies: Extensive trials; regulatory approvals; multi-modal sensing; fault-tolerant controllers.
- Standardization and Policy Frameworks for Embodied AI
- Use case: Industry standards around “verbalizable latent” audit logs, failure recovery benchmarks, and latency thresholds for safe operation.
- Tools/Workflows: Certification suites (RoboFAC-like for failure analysis); conformance tests (EgoPlan/RoboVQA expansions); traceability requirements for latent plans.
- Assumptions/Dependencies: Multi-stakeholder alignment; harmonization across vendors; legal clarity on interpretability claims.
- Edge Deployment and Model Compression
- Use case: Quantization and pruning of VLM + policy stacks for low-power robots and drones with limited compute.
- Tools/Workflows: Compression pipelines tailored to latent reasoning (KV-cache-aware pruning), hardware-aware distillation to micro-accelerators.
- Assumptions/Dependencies: Hardware support (NPUs/accelerators); research on preserving spatial-token fidelity under compression; field tests.
- Robotics Toolchain Interchange Standards
- Use case: Define a “Spatial Token Trajectory” interchange across perception, VLMs, and controllers within ROS2/industrial tooling.
- Tools/Workflows: Open schema for trajectory latents; adapters for MoveIt/Isaac; interop testbeds.
- Assumptions/Dependencies: Consensus on schema; backward compatibility; vendor buy-in.
- Energy and Hazardous-Environment Operations
- Use case: Remote manipulation for inspection/maintenance in plants and refineries; leverage failure recovery to minimize downtime.
- Tools/Workflows: Ruggedized robots with latent planning for high-risk tasks; offline analysis of recorded operations with verbalized reasoning.
- Assumptions/Dependencies: Harsh environment resilience (dust, temperature); communication constraints; strong safety interlocks.
- Research Advances in Reasoning Efficiency and Robustness
- Use case: Explore broader latent reasoning paradigms that integrate temporal memory, multimodal grounding, and formal guarantees on safety/performance.
- Tools/Workflows: New training protocols (reward shaping, curriculum), hybrid symbolic-latent planners, standardized long-horizon evaluation suites.
- Assumptions/Dependencies: Availability of richer datasets; community benchmarks; reproducible training with RL-style instabilities managed.
Notes on feasibility across applications:
- The verbalizer is used for training and interpretability; action execution relies on grounded latent representations. Interpretability audits must consider possible verbalizer hallucinations.
- The method assumes access to teacher models trained via GRPO with well-designed action-aligned rewards and data with visual trajectory labels or waypoints.
- Real-time performance depends on hardware; while 3B backbones and spatial tokens reduce latency, achieving consistent 10+ Hz may require edge accelerators.
- Few-shot adaptation (e.g., 10 demos) is shown feasible in controlled benchmarks; robustness in unstructured environments may require additional sensing and domain randomization.
Collections
Sign up for free to add this paper to one or more collections.