Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
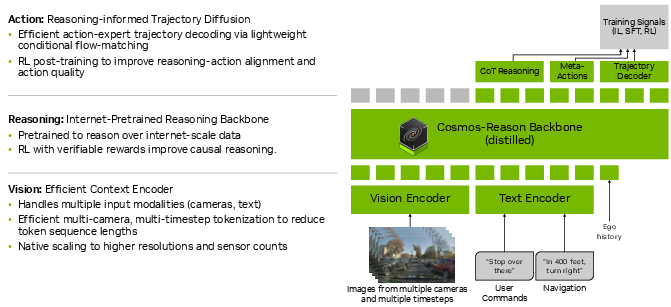
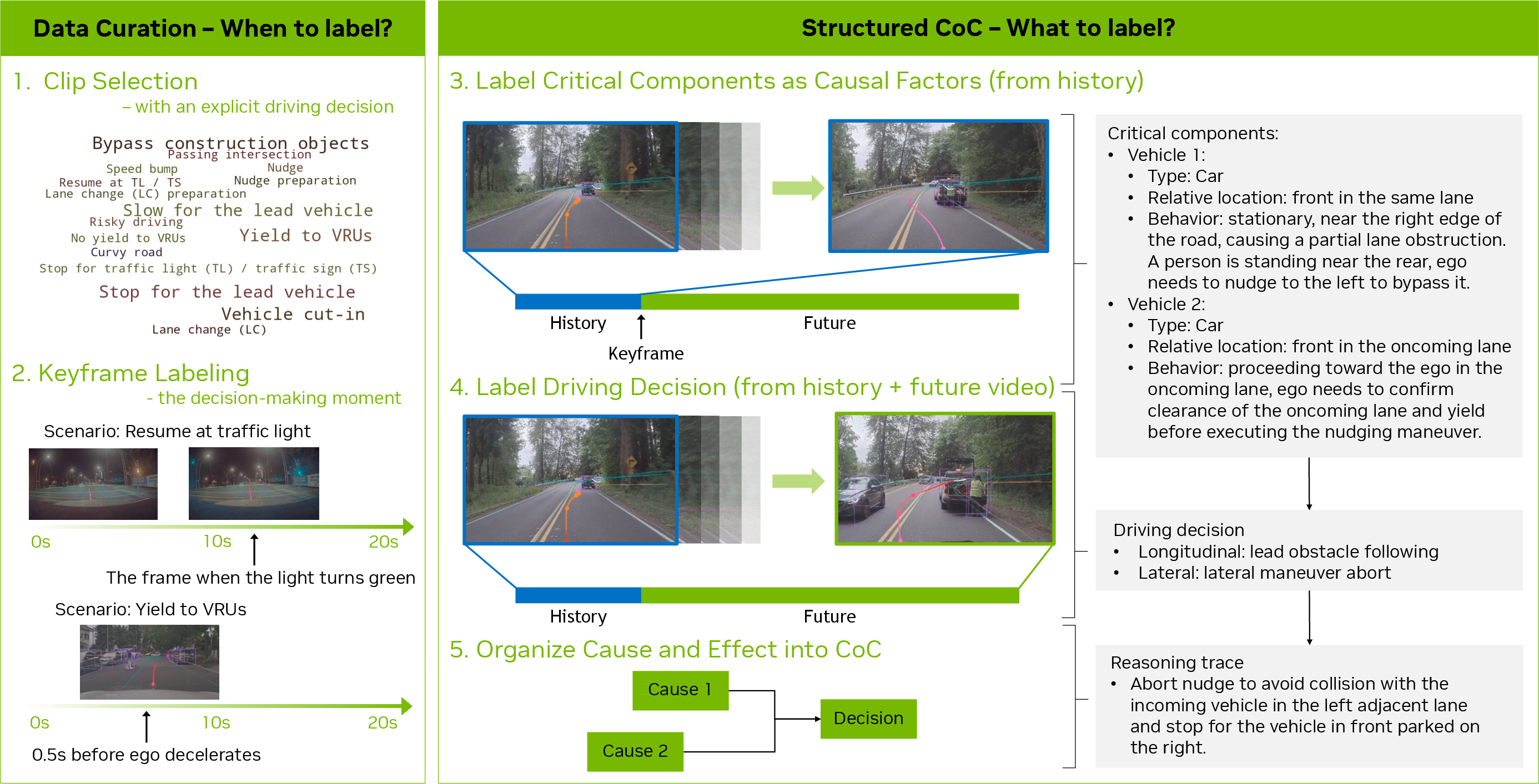
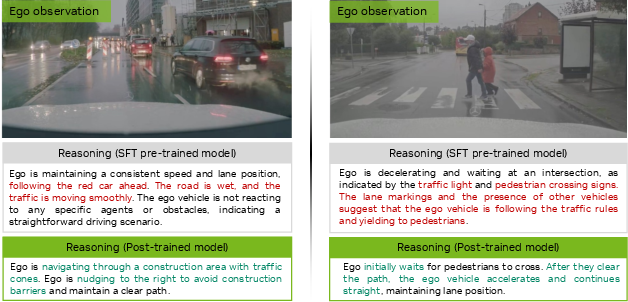
Abstract: End-to-end architectures trained via imitation learning have advanced autonomous driving by scaling model size and data, yet performance remains brittle in safety-critical long-tail scenarios where supervision is sparse and causal understanding is limited. To address this, we introduce Alpamayo-R1 (AR1), a vision-language-action model (VLA) that integrates Chain of Causation reasoning with trajectory planning to enhance decision-making in complex driving scenarios. Our approach features three key innovations: (1) the Chain of Causation (CoC) dataset, built through a hybrid auto-labeling and human-in-the-loop pipeline producing decision-grounded, causally linked reasoning traces aligned with driving behaviors; (2) a modular VLA architecture combining Cosmos-Reason, a Vision-LLM pre-trained for Physical AI applications, with a diffusion-based trajectory decoder that generates dynamically feasible plans in real time; (3) a multi-stage training strategy using supervised fine-tuning to elicit reasoning and reinforcement learning (RL) to optimize reasoning quality via large reasoning model feedback and enforce reasoning-action consistency. Evaluation shows AR1 achieves up to a 12% improvement in planning accuracy on challenging cases compared to a trajectory-only baseline, with a 35% reduction in off-road rate and 25% reduction in close encounter rate in closed-loop simulation. RL post-training improves reasoning quality by 45% as measured by a large reasoning model critic and reasoning-action consistency by 37%. Model scaling from 0.5B to 7B parameters shows consistent improvements. On-vehicle road tests confirm real-time performance (99 ms latency) and successful urban deployment. By bridging interpretable reasoning with precise control, AR1 demonstrates a practical path towards Level 4 autonomous driving. We plan to release AR1 models and a subset of the CoC in a future update.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.