Latent Implicit Visual Reasoning
Abstract: While Large Multimodal Models (LMMs) have made significant progress, they remain largely text-centric, relying on language as their core reasoning modality. As a result, they are limited in their ability to handle reasoning tasks that are predominantly visual. Recent approaches have sought to address this by supervising intermediate visual steps with helper images, depth maps, or image crops. However, these strategies impose restrictive priors on what "useful" visual abstractions look like, add heavy annotation costs, and struggle to generalize across tasks. To address this critical limitation, we propose a task-agnostic mechanism that trains LMMs to discover and use visual reasoning tokens without explicit supervision. These tokens attend globally and re-encode the image in a task-adaptive way, enabling the model to extract relevant visual information without hand-crafted supervision. Our approach outperforms direct fine-tuning and achieves state-of-the-art results on a diverse range of vision-centric tasks -- including those where intermediate abstractions are hard to specify -- while also generalizing to multi-task instruction tuning.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
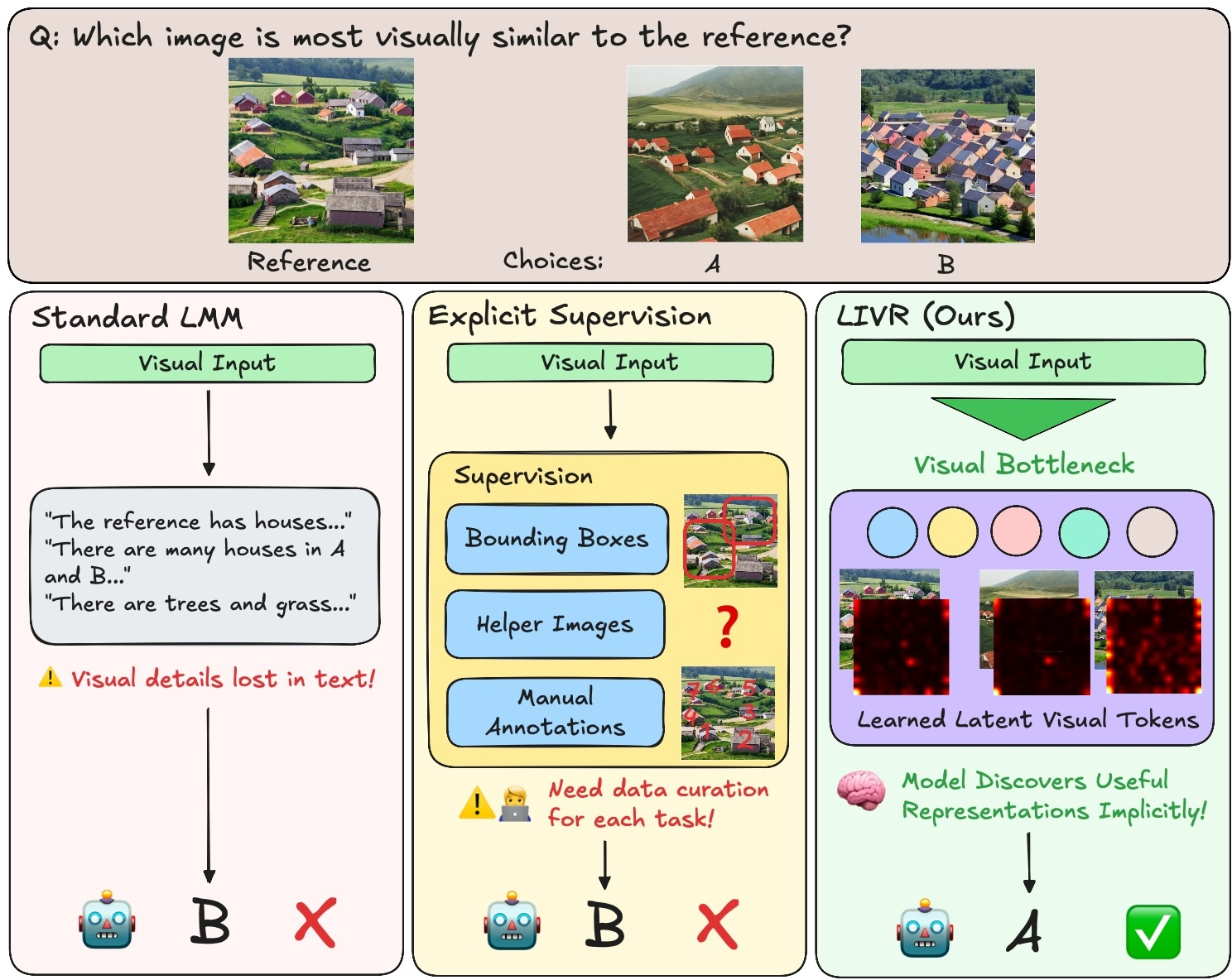
This paper introduces a way to help AI models “think with pictures,” not just with words. Many modern AI systems that handle images and text are very good at reading and talking, but they struggle with tasks that require deep visual understanding—like matching patterns, solving picture puzzles, or finding exact parts of an image. The authors propose a method called Latent Implicit Visual Reasoning (LIVR) that lets the model create its own hidden visual “notes” inside itself, without needing extra human-made labels or step-by-step instructions.
Key Questions the paper asks
The authors set out to explore a few simple but important questions:
- Can we help a model build useful visual ideas internally, without forcing it to explain everything in text?
- Can the model learn these visual “notes” on its own, without extra supervision like bounding boxes, crops, or helper images?
- Does this method make the model better at vision-heavy tasks compared to standard fine-tuning?
- Will these improvements still work when training on several different tasks at once?
How the method works (in plain language)
To make this easy to understand, think of the model as a student taking a test about pictures.
- Latent tokens: These are like invisible sticky notes the student can write on in their head. They’re not words the model says out loud, but private notes it uses to organize visual information.
- Visual bottlenecking: Imagine the student must answer questions but isn’t allowed to look directly at the picture while answering. The only way to “see” the picture is to first capture important details onto those invisible sticky notes. This forces the student to make good visual notes.
Here’s the two-stage training approach, explained with a simple analogy:
- Stage 1 (blinders on): The model is trained so that the answer can’t look directly at the image. The answer can only “read” the hidden sticky notes. This forces the model to put useful visual information into those notes.
- Stage 2 (blinders off): Now the model is allowed to see both the original image and its sticky notes. It learns to use both together for the best results.
A few practical details:
- The team fine-tunes the language part of the model lightly (using a method called LoRA, which is like adjusting small knobs rather than rebuilding the whole machine).
- They do not change the vision part that reads images.
- They do not add extra labels like boxes or helper images; they only use normal question–answer pairs.
What did they find, and why it matters?
The authors tested LIVR on nine vision-heavy tasks, covering things like:
- Counting objects
- Jigsaw puzzles (rearranged image pieces)
- Object localization (choosing the right bounding box)
- Visual and semantic correspondence (matching parts between images)
- Art style classification
- Functional correspondence (finding parts that work the same way across images)
- Relative reflectance (which surface is shinier)
- Visual similarity (which image looks closest to a reference)
Across multiple different AI models, LIVR consistently beat standard fine-tuning, often by several percentage points and sometimes by more than 10 points—especially on tasks that demand strong visual reasoning (like jigsaw or functional matching). It also worked well when training on multiple tasks at once, showing the method is general and not tied to a single problem type.
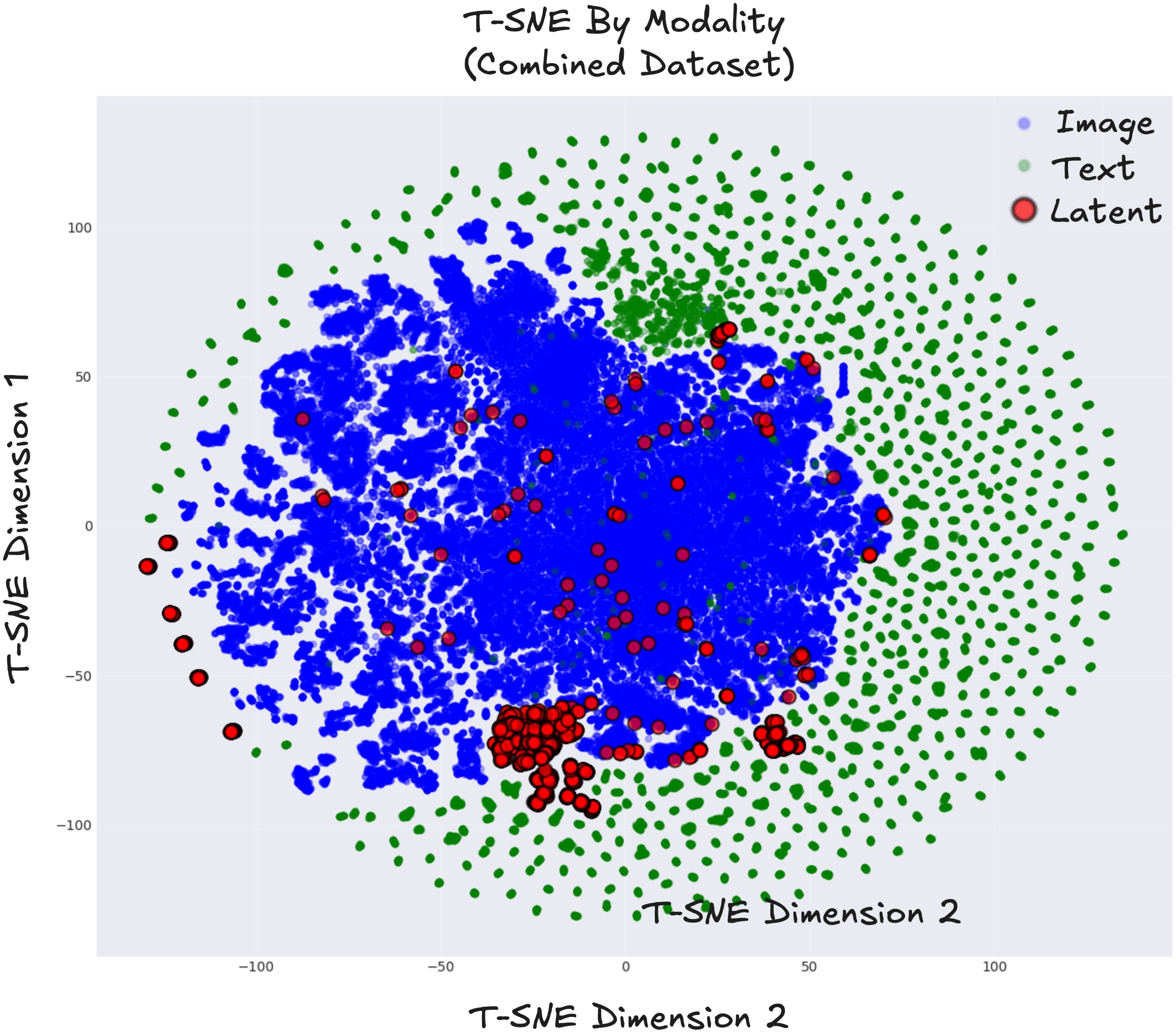
The authors also compared LIVR to a method that uses extra “helper images” (Mirage). LIVR did better without any such extra supervision. Attention maps (which show what the model focuses on) revealed that the hidden “sticky notes” tend to attend to the right parts of the image—like the motorcycle’s handle or the dogs that need counting—suggesting the model really learned meaningful visual structures internally.
Finally, the team ran careful checks (ablations) to understand what matters:
- You need both parts: the hidden notes (latent tokens) and the bottleneck (forcing visual info to pass through those notes). Using just one of these gives smaller gains.
- The training schedule matters: a balanced two-stage setup worked best.
- Around 16 latent tokens was a sweet spot—too few didn’t give enough capacity, too many made attention too spread out.
What’s the impact?
This research shows a practical, task-agnostic way to make AI models better at vision-heavy reasoning without costly, task-specific labels. Instead of asking models to explain everything in words or to follow human-designed visual steps, LIVR lets them build their own internal visual representations that are tailored to the task.
Why this is useful:
- It reduces the need for expensive annotation (like drawing boxes or crafting helper images).
- It scales across different types of visual tasks.
- It helps models handle problems where the “right” intermediate visual steps are hard to define—even for humans.
Limitations and what’s next
- The hidden visual notes are powerful but not always easy to interpret. They don’t give a human-readable explanation like a paragraph of text would.
- The authors suggest future work on bigger models, more latent capacity, and larger training sets.
In short, LIVR is a simple yet effective way to help AI “think visually” inside its own head, leading to better performance on challenging image-based tasks and paving the way for more capable multimodal systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of unresolved issues and open questions that future work could address.
- Scope of evaluation
- Lack of evaluation on standard VQA and vision-language benchmarks (e.g., VQAv2, GQA, TextCaps) to test transferability beyond the curated perception-heavy tasks.
- No assessment on text-centric or mixed reasoning tasks (math, document QA, commonsense), leaving unclear whether latent visual tokens help, hurt, or are neutral outside vision-centric settings.
- Limited comparison to strong multimodal CoT and interleaved-reasoning baselines (e.g., Visual CoT, Argus/VGR, RL-based R1-VL/Visual-RFT) on shared datasets; current head-to-head is mainly against direct SFT and Mirage on two tasks.
- Generalization, robustness, and distribution shift
- No OOD robustness tests (e.g., domain shift, heavy occlusion, noise, adversarial perturbations), so resilience of latent bottlenecks is unknown.
- Unclear cross-dataset generalization (trained on custom splits from COCO/HPatches/etc., tested on BLINK variants); no leave-one-dataset-out or cross-benchmark transfer studies.
- No analysis of robustness to prompt variations, distractor options, or long-tailed categories in multi-choice settings.
- Scalability and compute efficiency
- Inference-time/throughput costs of adding K latent tokens are not measured (latents increase sequence length); memory/latency trade-offs are unknown.
- No scaling laws for K (number of latents) vs. image token count/resolution; unclear how K should grow with input size or model depth.
- Training-time costs and convergence behavior under larger K (beyond K=32) or deeper backbones are not characterized.
- Model scale and backbone diversity
- Only small backbones (3–4B) evaluated; open whether gains persist, shrink, or grow on mid/large LMMs (e.g., 7B–72B+).
- Vision encoder and projector are frozen; unclear whether partial/full unfreezing or joint tuning changes the role and utility of latents.
- Method design choices left unexplored
- Static, input-agnostic K: no mechanism to adaptively allocate the number of latent tokens per input/task difficulty or stop early when sufficient.
- Latents exist only at the input layer; unexplored variants include per-layer latent slots, cross-layer recurrence, or layer-wise bottlenecks.
- Latent embeddings are global parameters; no exploration of dynamic or instance-conditioned latent initializations (e.g., generated latents, key-value caches, memory-augmented latents).
- Only decoder-side attention masking studied; alternatives (e.g., gated cross-attention, mixture-of-experts latents, routing across heads) remain untested.
- Causal grounding analysis is limited: attention visualizations are qualitative; no causal interventions/tracing (e.g., patch/gradient-based ablations) to prove what visual evidence latents actually encode.
- Training protocol and stability
- Two-stage schedule (Stage 1 bottleneck → Stage 2 normal) is fixed and hand-tuned; no automated curriculum, early-stopping, or scheduler that adapts bottleneck duration to task/model feedback.
- Sensitivity to hyperparameters (learning rates, LoRA ranks, masking variants, K) across tasks is not systematically profiled; reproducibility across seeds not reported.
- Potential training instability or representation collapse at larger K hinted by performance drop at K=32, but failure modes and mitigations are not analyzed.
- Interactions with language abilities
- No measurement of post-finetune language performance; potential catastrophic forgetting or interaction effects with instruction-following are unknown.
- No study of whether latent training alters reliance on textual CoT, or whether combining LIVR with textual CoT/RL post-training yields additive gains.
- Data construction and potential biases
- Training datasets are synthesized from task-specific sources; data quality, annotation artifacts, and bias analyses are not provided.
- No learning curves to test data efficiency (1k-per-task is fixed); unclear whether LIVR’s relative gains are larger/smaller in low-data or high-data regimes.
- Task coverage and modalities
- Limited to images; no experiments on video, 3D/geometry tasks, or temporal reasoning where latent compute could be more impactful.
- Only one open-ended task (counting) is evaluated; generality to fully generative settings (dense captioning, segmentation text generation, and step-by-step visual plans) remains untested.
- Multi-image reasoning protocols are not deeply analyzed (e.g., how latents fuse information across multiple images; scalability to many candidates).
- Masking and information flow
- The masking scheme assumes visual information can be reliably funneled through latents; no quantitative bound on residual leaks or unintended shortcuts (e.g., via positional priors or learned biases).
- No analysis of how much image information is preserved/compressed by latents (information-theoretic perspective), nor how bottleneck strength relates to performance.
- Interpretability and controllability
- Latents are acknowledged as less interpretable than text; no tools proposed for inspecting, editing, or constraining what they encode.
- No mechanism to steer latents toward specific skills (e.g., geometry, texture, part-based reasoning) or to enforce disentanglement/sparsity.
- Safety, fairness, and ethics
- No fairness audits (e.g., subgroup analyses on art styles, demographics, object categories) or safety tests (spurious correlations, harmful content).
- No calibration metrics or uncertainty estimates; how bottlenecking affects confidence and error modes is unknown.
- Integration with other training paradigms
- Not combined with RLHF/DPO, reward models for visual reasoning, or planning/pause tokens; unclear if LIVR synergizes with test-time compute methods or self-reflection.
- No exploration of hybrid approaches that mix implicit latents with explicit visual intermediates (e.g., depth/box tokens) to test complementarity.
- Reusability and transfer of latents
- Open whether the same latent token set learned on one task set is reusable for new tasks (frozen-latent transfer) or can serve as a general “visual reasoning adapter.”
- No study of task-conditional latents (e.g., task-specific subsets or routing) for multi-task scaling without interference.
- Evaluation rigor
- No confidence intervals or statistical significance reported; performance variance across seeds and runs is unknown.
- Limited ablations on projector design, vision tokenization granularity, or image resolution, which may interact strongly with the bottleneck.
These gaps suggest concrete next steps: broaden benchmarks and baselines; profile efficiency, robustness, and scaling; explore adaptive/dynamic latents and per-layer bottlenecks; study language interactions and data efficiency; add interpretability, safety, and fairness analyses; and test synergy with RL, textual CoT, and explicit visual intermediates.
Practical Applications
Immediate Applications
The following applications can be built with today’s LMMs by adopting the LIVR training recipe (latent tokens + two-stage bottleneck training with LoRA), using only task Q&A data and no explicit visual intermediate supervision.
- Visual catalog integrity and product matching (Retail/e-commerce)
- What: Improve visual similarity, duplicate detection, and cross-view matching of SKUs; localize product features in listing photos; count items per image (bundles, multipacks).
- Tools/workflow: Fine-tune a 3–4B LMM (e.g., Qwen-VL/LLaVA-OV) with LIVR on internal product photos using simple VQA prompts (e.g., “Which image is most similar to the reference?”; “How many items are in the image?”). Deploy as a microservice for listing validation, search deduplication, and QC checks.
- Assumptions/dependencies: Access to base LMM weights and serving stack that supports attention-mask customization and appending latent tokens at inference; domain shift mitigation via light in-domain tuning.
- Automated visual inspection and counting on production lines (Manufacturing)
- What: Count items on trays, detect subtle material differences (relative reflectance), and match parts to functional roles (functional/semantic correspondence) for assembly verification and inventory reconciliation.
- Tools/workflow: Camera stream → image snapshots → LIVR-fine-tuned model for “count/verify/match” Q&A; integrate with MES/QC dashboards; trigger operator alerts on mismatches.
- Assumptions/dependencies: Sufficient task-specific Q&A pairs from historical images; controlled lighting if reflectance cues are needed; human-in-the-loop thresholds for uncertain cases.
- Visual similarity and mood-board tools for creatives (Design/marketing)
- What: Better “find visually similar assets” and “style-matching” search; recommend assets matching a target style (art style classification + visual similarity).
- Tools/workflow: LIVR-fine-tune on in-house asset library; expose as a plug-in in DAM systems for art directors and designers; batch-tag assets by style.
- Assumptions/dependencies: Tagged exemplars for a few-shot warm start; consistent preprocessing; acceptable latency with 16 latent tokens.
- Cross-view visual correspondence for pick-place and bin-picking (Robotics)
- What: Match a target part across new viewpoints and scenes; localize parts to grasp; count target objects to plan next actions.
- Tools/workflow: LIVR-fine-tune with multi-view captures and point/crop-level prompts (“Which option corresponds to REF?”); feed model outputs to grasp planner.
- Assumptions/dependencies: Calibrated camera rigs and representative training captures; tight loop integration with planner; safety guardrails for failures.
- Asset inventory and change monitoring from imagery (Public sector, Geospatial)
- What: Count vehicles, trees, or infrastructure items; detect correspondences across time (pre/post-event); match features between scenes to aid GIS updates.
- Tools/workflow: Build Q&A datasets from aerial/street-level imagery; LIVR-fine-tune multi-task model for counting + correspondence; export to GIS layers.
- Assumptions/dependencies: Image resolution adequate for the target objects; domain adaptation to aerial/satellite modalities; careful validation for policy uses.
- Art curation and digital restoration (Cultural heritage)
- What: Style classification at scale; visual jigsaw for digital reconstruction; find similar artworks or fragments.
- Tools/workflow: LIVR-fine-tune using curated museum datasets; integrate with archive search and restoration workflows.
- Assumptions/dependencies: High-fidelity scans; provenance-aware deployment; curator review for final decisions.
- Visual tutoring and practice for spatial reasoning (Education/consumer apps)
- What: Interactive puzzles (jigsaw-like), visual pattern recognition, and object counting exercises; explain “where” and “why” via attention overlays.
- Tools/workflow: Use LIVR models behind educational apps; expose optional latent-to-image attention maps as visual aids.
- Assumptions/dependencies: Age-appropriate content controls; clear UI to communicate uncertainty; responsibility for mistaken guidance.
- Low-annotation, multi-task perception stacks (Software/ML tooling)
- What: Quickly stand up small, domain-specific visual assistants (counting, localization, correspondence, similarity) without designing visual intermediates.
- Tools/workflow: Provide a “LIVR fine-tuning” library that wraps LoRA and bottleneck masking; recipe: Stage 1 (visual bottleneck) + Stage 2 (standard mask), K≈16 latents, checkpoint selection by validation accuracy; include latent attention visualization for debugging.
- Assumptions/dependencies: Engineering access to model graph for custom attention masks; GPU for short SFT runs; monitoring for data drift.
- Document-free, visual-first intake in workflows (CX, insurance claims, field ops)
- What: Assess claims photos (count damage points; find best-matching reference damage category); localize areas for adjuster review.
- Tools/workflow: Intake images → LIVR model for structured outputs → route to claim workflow; use multiple-choice prompts to increase reliability.
- Assumptions/dependencies: Clear visual taxonomies; privacy controls; human oversight for payouts.
- Near-duplicate moderation and brand safety (Trust & Safety)
- What: Detect visually similar or manipulated variants of flagged content at scale, beyond simple hash matching.
- Tools/workflow: LIVR similarity verification as a second-pass check; pair with hashing for recall/precision balance; triage uncertain cases.
- Assumptions/dependencies: Robustness to adversarial edits; auditable logs for enforcement; careful bias auditing.
Long-Term Applications
These require further research, scaling, or productization beyond the current paper’s scope (e.g., larger models, interpretability, RL, or domain validations).
- Visual chain-of-thought and latent-space planning (Software, Robotics, Education)
- What: Evolve latent “visual thoughts” over multiple steps for multi-hop reasoning and manipulation planning (e.g., assembling kits, solving visual proofs).
- Path to product: Combine LIVR latents with pause/planning tokens and iterative inference; integrate with RL feedback for closed-loop improvement.
- Dependencies: Compute budgets for multi-pass inference; new decoding strategies; safety guarantees for real-world actions.
- Medical imaging assistance with minimal supervision (Healthcare)
- What: Lesion counting and correspondence across timepoints, cross-modality alignment, subtle material/reflectance cues for dermoscopy/pathology.
- Path to product: Domain-adapt LIVR with curated radiology/digital pathology Q&A sets; validate under clinical QA; regulatory study protocols.
- Dependencies: Rigorous clinical validation, bias checks across demographics/devices, FDA/CE approvals; strong data governance.
- Edge-deployable visuospatial assistants (Mobile/AR/IoT)
- What: On-device counting/localization/similarity for retail audits, warehouse picking, home inventory, and AR guides.
- Path to product: Compress LIVR-tuned 3–4B models; latency-aware masking and dynamic K; hardware-aware kernels.
- Dependencies: Efficient attention-masking support at inference; memory/latency trade-offs; battery constraints.
- Autonomous inspection in energy and infrastructure (Energy, Utilities)
- What: Drone/robot inspection for panel defects (reflectance), cable/component correspondence, part counting in substations.
- Path to product: LIVR multi-task models trained on annotated inspection photos and failure libraries; integrate with maintenance CMMS.
- Dependencies: Robustness to outdoor lighting/weather; safety/regulatory compliance; explainability for audit trails.
- Data flywheels for low-supervision visual tasks (Academia/ML Ops)
- What: Use LIVR to bootstrap task performance with simple Q&A, then auto-label or propose hard negatives/choices to expand datasets.
- Path to product: Semi-automated dataset builder that proposes multi-choice sets and verifies with human raters; continual learning pipelines.
- Dependencies: Reliable uncertainty estimation; human QA interfaces; drift detection.
- Standards and policy for annotation-light AI deployments (Policy)
- What: Procurement and governance frameworks for models trained without heavy intermediate labels; benchmarking guidance for vision-centric tasks.
- Path to product: Public-sector playbooks referencing LIVR-like methods for asset counts and audits, with standardized validation protocols.
- Dependencies: Cross-agency consensus on metrics, bias evaluations, and transparency (e.g., latent-attention reports).
- Forensics and provenance analysis (Security/Media integrity)
- What: Use correspondences and reflectance cues to spot composites/manipulations; match fragments to sources.
- Path to product: LIVR-enhanced forensic toolkits with latent visualizations; court-admissible reporting with confidence estimates.
- Dependencies: Method interpretability, robustness to counter-forensics, legal validation.
- Foundation for multi-modal agents with implicit visual memory (General AI)
- What: Treat latent tokens as a compact, task-adaptive visual memory that can be cached/reused across steps or tasks.
- Path to product: Memory-augmented agents that cache latents for repeated objects/scenes; retrieval-augmented visual reasoning.
- Dependencies: Memory management, eviction policies, privacy safeguards; empirical gains at scale.
- Scientific imaging and microscopy analysis (Academia, Biotech)
- What: Cell/colony counting, correspondence across time-lapse imaging, subtle material/reflectance differences in materials science.
- Path to product: Domain-specific LIVR models validated against lab ground-truth; plug-ins for ImageJ/Fiji.
- Dependencies: High-quality calibration data; reproducibility under varying instruments; open benchmarks.
- Human-understandable latent explanations and safety (XAI)
- What: Translate latent-space visual reasoning into user-facing rationales (e.g., attention maps + minimal evidence crops) without constraining model learning.
- Path to product: Post-hoc explanation layers atop LIVR; UI for inspecting latent-to-image attention during decisions.
- Dependencies: Research on faithful explanations; UI standards; user studies to ensure clarity without over-trust.
Notes on feasibility and deployment
- Compute and integration: The method fine-tunes only LoRA adapters and K latent embeddings while freezing the vision encoder/projector, making short SFT runs practical. Serving must support custom attention masks during training; at inference, you append latent tokens but use standard masks.
- Data requirements: Only Q&A pairs are needed; no helper images, boxes, or depth maps. Multi-task instruction tuning is supported with a single recipe.
- Model scope: Demonstrated on small open-source LMMs (3–4B). Larger models are likely to amplify gains but need careful cost/benefit evaluation.
- Interpretability: Latent tokens improve performance but are less interpretable than text CoT; attention overlays help but are not complete explanations.
- Risk and governance: Apply bias testing, privacy controls, and human-in-the-loop review for sensitive sectors (healthcare, public policy, forensics).
Glossary
- Ablations: Systematic removal or variation of components to assess their impact on performance. "Ablations and Additional Experiments"
- Attention maps: Visualizations of where a model focuses in an input, often derived from attention weights. "Visualizing the attention maps of the latent tokens shows that the model has learned to recognize underlying visual structures"
- Attention mask: A constraint on which tokens can attend to which others during self-attention. "modifying the attention mask so that the answer tokens can only attend to the prompt tokens Q and the latent tokens L, but cannot attend to the visual inputs I"
- Attention sinks: Tokens or regions that attract attention regardless of relevance, potentially diluting useful signal. "Although some attention sinks persist, the dominant patterns align with task-relevant regions"
- Autoregressively: Token-by-token generation where each token is predicted conditioned on previous tokens. "Current LMMs are trained to autoregressively generate text tokens for visual tasks."
- BLINK benchmark: A suite of perception-heavy visual reasoning tasks used for evaluation. "We evaluate our method on nine perception-heavy tasks adapted from the BLINK benchmark"
- Bounding boxes: Rectangular regions used to localize objects in images. "predict bounding boxes and reintegrate the selected visual regions into the reasoning chain"
- Bottleneck attention masking: An attention constraint that forces information flow through specific tokens acting as a bottleneck. "An illustration of our method and bottleneck attention masking."
- Bottlenecking: Forcing information to pass through a limited pathway to encourage specific representations. "we introduce a bottlenecking approach where we force visual information to pass through the latent tokens."
- Chain-of-thought (CoT): Explicit intermediate reasoning steps generated to improve task performance. "Chain-of-thought (CoT) prompting has shown that explicitly generating intermediate text steps can substantially improve LLM performance"
- Decoder (LLM decoder): The generative component of a model that produces outputs from embeddings. "a visual encoder, a LLM decoder, and a projector"
- Direct SFT: A baseline involving standard supervised fine-tuning on task-specific data. "Direct SFT, standard supervised fine-tuning on our task training set"
- Embedding space: The continuous vector space where tokens (text or image) are represented. "projected into the LLM's embedding space"
- Embedding table: The parameter matrix mapping token IDs to embedding vectors. "their corresponding rows in the embedding table remain unfrozen during training"
- End-to-end: Training a model directly from inputs to outputs using task objectives without intermediate supervision. "trained end-to-end from task objectives"
- Epoch: One full pass over the training dataset during optimization. "Direct supervised fine-tuning runs for 10 epochs."
- Fine-tuning: Adapting a pretrained model to a specific task by continuing training on task data. "Direct supervised fine-tuning runs for 10 epochs."
- Functional correspondence: Matching image regions based on functional similarity rather than appearance. "functional correspondence"
- Generative models: Models that produce outputs (e.g., text) conditioned on inputs via a learned distribution. "LMMs are generative models that process both visual and textual inputs"
- Helper images: Additional images provided as explicit supervision to guide intermediate visual reasoning. "by supervising intermediate visual steps with helper images"
- Hidden states: Internal token representations within the layers of a neural network. "We then extract the final-layer hidden states for all token positions"
- Image tokens: Tokenized representations of visual inputs used by multimodal models. "allows the answer tokens to attend to both the original image tokens and the latent tokens"
- Instruction tuning (multi-task instruction tuning): Fine-tuning with instruction-style datasets, often across multiple tasks. "while also generalizing to multi-task instruction tuning."
- Jigsaw: A vision task requiring reassembly or recognition of scrambled image parts. "jigsaw"
- Language backbone: The core LLM component of an LMM used for reasoning and generation. "We fine-tune the language backbone using LoRA"
- Language bias: A tendency of models to rely on textual patterns over visual cues. "This introduces significant language bias, forcing the LMM to reason about visual information through text alone."
- Large Multimodal Models (LMMs): Models that process and generate across multiple modalities, typically images and text. "Large Multimodal Models (LMMs) have demonstrated great progress in visual understanding."
- Latent Implicit Visual Reasoning (LIVR): The proposed method that learns visual reasoning tokens without explicit supervision. "Our proposed approach, Latent Implicit Visual Reasoning (LIVR), enables models to autonomously discover useful intermediate visual representations"
- Latent reasoning: Performing additional computation in hidden (latent) space rather than emitting explicit tokens. "Recent approaches have begun to explore latent-space reasoning in LMMs"
- Latent tokens: Special learnable tokens inserted to carry internal visual reasoning information. "we equip it with latent tokens."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into layers. "We fine-tune the language backbone using LoRA (applied to attention and MLP blocks)"
- Mirage: A latent reasoning approach that depends on explicit visual supervision. "We also compare against Mirage, a recent latent reasoning approach that relies on explicit visual supervision via task-specific helper images."
- Negative log likelihood (NLL): A common training objective that maximizes the likelihood of correct tokens. "train the model using the standard negative log likelihood (NLL) objective:"
- Pause tokens: Special tokens that trigger extra internal computation without producing visible outputs. "Think Before You Speak uses pause tokens to trigger extra forward passes without emitting visible tokens"
- Projector: The module that maps visual encoder outputs into the LLM’s embedding space. "projected into the LLM's embedding space via a projector p."
- Prompt tuning: Adapting a model by learning prompts rather than full model parameters. "Prompt tuning, a lightweight adaptation baseline."
- Relative reflectance: Estimating comparative light reflectance properties across image regions. "relative reflectance"
- Reinforcement learning-based post-training: Using RL to shape model outputs (e.g., longer explanations) after initial training. "use RL-based post-training to encourage long, step-by-step textual explanations"
- Semantic correspondence: Aligning semantically similar regions across different images. "semantic correspondence"
- Supervised fine-tuning (SFT): Continuing training with labeled task data to improve performance. "Direct SFT, standard supervised fine-tuning on our task training set"
- t-SNE: A dimensionality reduction technique for visualizing high-dimensional embeddings. "We then extract the final-layer hidden states ... and embed them with t-SNE"
- Top-1 accuracy: The percentage of predictions where the top choice matches the ground truth. "Typically, the model is evaluated through top-1 accuracy."
- Visual bottlenecking: Constraining visual information flow through latent tokens to enrich their representations. "train our model using the standard negative log likelihood (NLL) objective ... our objective directly optimizes the latent tokens to capture the most useful visual information"
- Visual encoder: The component that extracts features from images. "The image I is encoded using a visual encoder v"
- Visual intermediates: Explicit visual representations (e.g., depth maps) of reasoning steps used during training. "Visual Intermediates. Another approach generates visual representations of intermediate reasoning steps."
- Visual Question Answering (VQA): Tasks where models answer questions about images, often evaluated by accuracy. "In Visual Question Answering (VQA), the LMM is provided with a set of images and tasked with answer questions about the images."
- Visual Spatial Planning (VSP): A visual reasoning task involving spatial decision-making and planning. "For VSP, we use the dataset and helper images released by Mirage."
- Visual token recycling: Reusing selected visual regions (e.g., crops) as part of the reasoning chain. "Visual Token Recycling. Visual CoT ... predict bounding boxes and reintegrate the selected visual regions into the reasoning chain"
- Vocabulary: The set of tokens a model can process and generate, including added special tokens. "The new vocabulary becomes V ∪ L, with a total size of |V| + K."
- Vision-centric tasks: Tasks that require extensive visual processing and reasoning rather than text-only reasoning. "vision-centric tasks that require heavy visual processing."
- Visual correspondence: Matching visually similar points or regions across images. "visual correspondence"
Collections
Sign up for free to add this paper to one or more collections.

