LaST$_{0}$: Latent Spatio-Temporal Chain-of-Thought for Robotic Vision-Language-Action Model
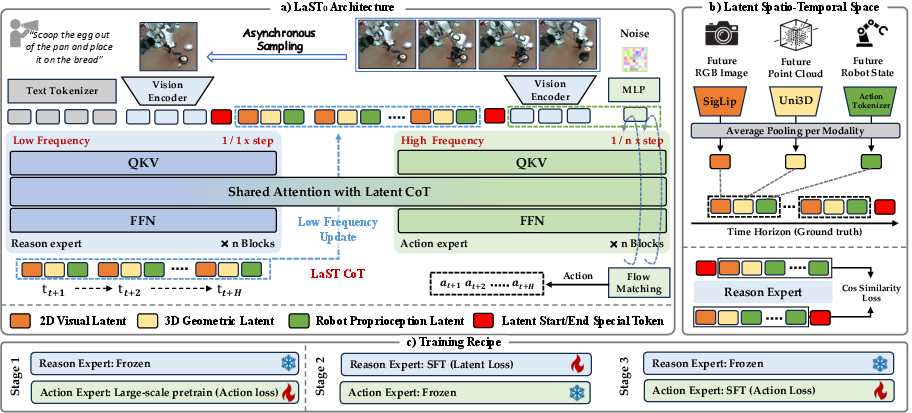
Abstract: Vision-Language-Action (VLA) models have recently demonstrated strong generalization capabilities in robotic manipulation. Some existing VLA approaches attempt to improve action accuracy by explicitly generating linguistic reasoning traces or future visual observations before action execution. However, explicit reasoning typically incurs non-negligible inference latency, which constrains the temporal resolution required for robotic manipulation. Moreover, such reasoning is confined to the linguistic space, imposing a representational bottleneck that struggles to faithfully capture ineffable physical attributes. To mitigate these limitations, we propose LaST$_0$, a framework that enables efficient reasoning before acting through a Latent Spatio-Temporal Chain-of-Thought (CoT), capturing fine-grained physical and robotic dynamics that are often difficult to verbalize. Specifically, we introduce a token-efficient latent CoT space that models future visual dynamics, 3D structural information, and robot proprioceptive states, and further extends these representations across time to enable temporally consistent implicit reasoning trajectories. Furthermore, LaST$_0$ adopts a dual-system architecture implemented via a Mixture-of-Transformers design, where a reasoning expert conducts low-frequency latent inference and an acting expert generates high-frequency actions conditioned on robotics-oriented latent representations. To facilitate coordination, LaST$_0$ is trained with heterogeneous operation frequencies, enabling adaptive switching between reasoning and action inference rates during deployment. Across ten simulated and six real-world manipulation tasks, LaST$_0$ improves mean success rates by 8% and 13% over prior VLA methods, respectively, while achieving substantially faster inference. Project website: https://sites.google.com/view/last0

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “LaST₀: Latent Spatio-Temporal Chain-of-Thought for Robotic Vision–Language–Action Model”
What is this paper about?
This paper is about teaching robots to “think ahead” quickly and quietly before they move, so they can follow instructions and manipulate objects more accurately in the real world. The authors introduce a system called LaST₀ that helps robots plan a few steps into the future inside a compact, hidden “mental space,” then use that plan to act fast and smoothly.
What questions does the paper try to answer?
- How can a robot do some reasoning before acting without slowing down?
- How can a robot plan using details that are hard to express in words (like exact 3D shapes, motion, and its own arm position)?
- Will this new kind of hidden, fast planning actually make robots better and more reliable at real tasks?
How does the method work? (In simple terms)
Think of LaST₀ as a brain with two coordinated experts sharing one memory:
- Slow “Thinker” (Reasoning Expert): Like a coach who occasionally looks ahead and sketches a few future snapshots. These aren’t full pictures or sentences. They’re compact “notes” that capture:
- What the robot’s camera will likely see next (2D visuals),
- The 3D shape and layout of the scene (a “point cloud,” like a dusting of dots forming objects),
- The robot’s own body/arm state (called “proprioception,” like knowing where your hand is without looking).
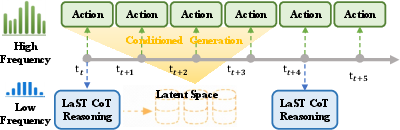
- This “coach” updates only sometimes (e.g., every 4 steps) so it doesn’t slow things down.
- Fast “Doer” (Acting Expert): Like an athlete who moves every step, guided by the coach’s notes. It takes the latest camera view plus the coach’s compact notes and quickly outputs the next action (move here, rotate there, open/close the gripper).
Key ideas made simple:
- Latent Chain-of-Thought (hidden planning): Instead of writing long text plans or drawing full future images (which is slow), the robot creates small, dense codes (latent tokens) that summarize the important future information. Think of them as the robot’s private shorthand.
- Spatio-temporal: “Spatio” = space (what’s where), “temporal” = time (what happens next). The robot’s notes cover both where things are and how they’ll change over the next few moments, like a short comic strip of the future.
- Dual-speed system: The coach (slow) looks ahead occasionally; the athlete (fast) moves every step. This keeps the robot both smart and quick.
- Shared memory and cache: When the coach updates its notes, they’re stored in memory so the athlete can reuse them without asking the coach to repeat, saving time.
- Training in stages: 1) Pretrain on many robot demos to learn general skills. 2) Teach the coach to create high-quality “notes” by copying what strong vision/3D/body encoders produce (only during training). 3) Freeze the coach, then train the athlete to act well using those notes, at different “coach update speeds,” so it stays flexible at test time.
A helpful analogy:
- The “coach” predicts a few steps of the game (future sights, 3D positions, and arm states) using compact sticky notes.
- The “athlete” uses those notes to move smoothly, even if the coach only updates sometimes.
What did they find, and why does it matter?
Main results:
- Better success on tasks:
- In simulation (10 tasks), LaST₀ improved average success by about 8% over leading methods.
- In real-world tests (6 tasks), it improved by about 13% on average.
- Much faster planning than methods that write out full text/image plans:
- About 15.4 actions per second on a single GPU, versus around 1 action per second for explicit “think-out-loud” methods. That’s roughly 14× faster.
- More reliable in long, multi-step tasks:
- On a challenging three-step, real-world task, the final step success was nearly 5× higher than a strong baseline.
Why this matters:
- Robots often fail because they either think too slowly or don’t think far enough ahead. LaST₀ shows you can think ahead in a “silent” way that captures important physics and timing without slowing the robot down. This leads to smoother, steadier actions in the real world.
What could this change in the future?
- Home helpers and factory robots: Faster and steadier handling of tasks like putting items on shelves, opening doors, or scooping food—especially when objects move or the scene changes.
- Safer, more dependable behavior: Planning ahead in a compact form helps keep actions consistent over time, which reduces jerky or confused movements.
- A step toward more general robot intelligence: The idea of a hidden, physically grounded “chain-of-thought” could be combined with other learning methods (like reinforcement learning) and more sensors to handle even more complex, open-world tasks.
- Practical efficiency: Because the robot only uses 3D point clouds to train its inner notes (not at run time), it stays fast at deployment while still benefiting from 3D understanding learned during training.
In short, LaST₀ shows that robots can plan ahead in a small, smart way—without spelling everything out—so they can act faster and more accurately in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Reliance on teacher latents at training time only: The slow expert is supervised using future embeddings from frozen SigLIP and Uni3D encoders (including point clouds unavailable at inference). How robust is LaST₀ to noise, misalignment, occlusions, or calibration errors in these teacher signals, and what happens when the teacher’s inductive biases mismatch the downstream task?
- Lack of analysis of latent prediction fidelity: The paper evaluates task success but does not quantify how accurate the predicted latent CoT is versus ground-truth latents (e.g., error over time, drift, or consistency). How does latent prediction error correlate with action failures?
- Exposure bias in latent autoregression: Latent CoT is trained with teacher forcing on future latents but used autoregressively at test time. Does compounding error degrade long-horizon performance? Would scheduled sampling, self-distillation via rollouts, or consistency regularization reduce this gap?
- Fixed horizon and no termination policy: The latent horizon H is set manually and ablated, but there is no mechanism for adaptive horizon length, early stopping, or re-planning triggers. Can the model learn to dynamically adjust H or terminate latent rollouts based on uncertainty or task progress?
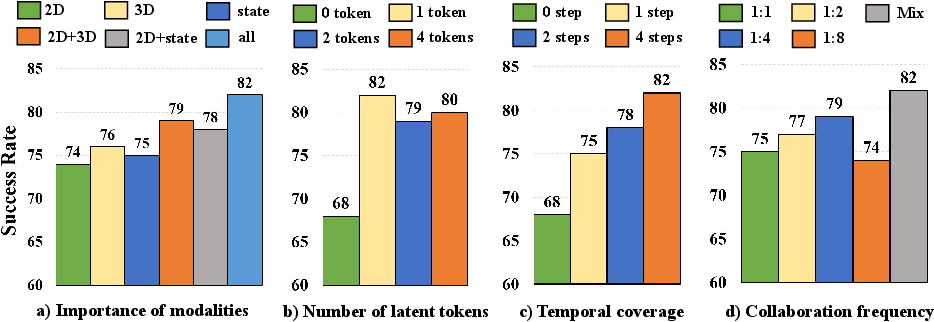
- No uncertainty estimation or update policy: The fast–slow update ratio κ is chosen from a small set and mixed during training, but runtime adaptation is not driven by confidence, novelty, or error signals. How to design uncertainty-aware policies that request new latent reasoning only when needed?
- Compression to one token per modality: Each modality’s future state is average-pooled into a single token. While efficient, this may discard spatially localized details critical for contact-rich or cluttered manipulation. What are the trade-offs of richer latent grids/slots or object-centric tokens, and can adaptive token allocation improve performance without large latency costs?
- Missing tactile/force feedback and actuation nuances: The latent space excludes tactile/force/torque sensing and contact dynamics, and the controller outputs end-effector pose deltas in SE(3). How does LaST₀ handle contact-rich, compliant, or force-regulated tasks, and what changes are needed to support torque control or hybrid position–force control?
- Instruction and language generalization: Tasks mostly use simulator-provided or fixed instructions. How well does LaST₀ generalize to long, compositional, ambiguous, or open-vocabulary instructions, and to multi-step natural-language programs?
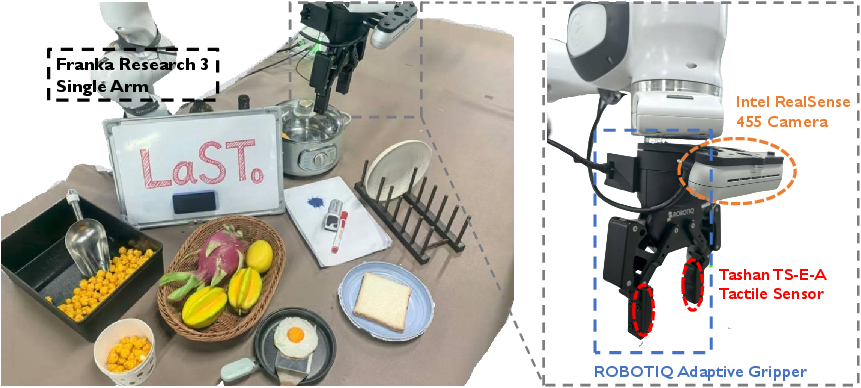
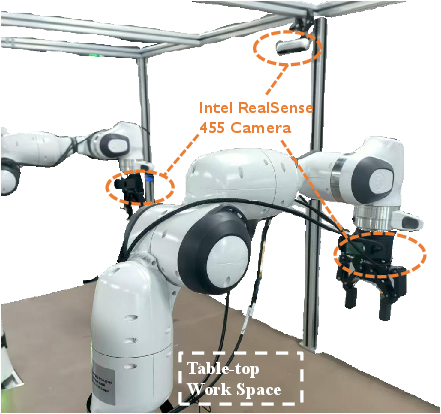
- Cross-embodiment and sensor generalization: Experiments focus on Franka (single/dual-arm). How does the method transfer to different manipulators, grippers, mobile manipulators, and sensor suites (e.g., different cameras, degraded depth, moving cameras)?
- Inference on resource-constrained hardware: The reported 15.4 Hz is on an RTX 4090. What are the latency, memory, and power profiles on embedded compute (e.g., Jetson-class), and how do H, κ, and model size scale under such constraints?
- KV-cache scaling and memory footprint: The approach caches latent CoT K/V states, but memory and attention costs will grow with latent horizon and multi-view inputs. What are the limits of horizon length before cache/memory become a bottleneck, and can retrieval or compression schemes bound these costs?
- Stability and safety under perturbations: There is limited stress testing under severe occlusions, dynamic distractors, adversarial lighting, or large distribution shifts, and no safety guarantees or recovery behaviors. How robust is LaST₀ under such conditions, and can safety constraints or formal verification be incorporated?
- Minimal data requirements and data efficiency: Real-world tasks used ~200 demos per task; simulation used 100. What are learning curves versus demo count, and can augmentation, self-supervision, or preference-based feedback reduce demonstration needs?
- Interpreting and debugging latent CoT: The latent CoT is implicit, improving speed but losing interpretability. Can we develop tools to visualize, probe, and edit latent trajectories, or hybridize with sparse explicit CoT for human-in-the-loop debugging?
- Teacher–student domain gap at deployment: The 3D teacher (Uni3D) supervises geometric latents during training, but inference uses RGB only. How much performance is attributable to this privileged 3D supervision, and can we close the gap with self-supervised 3D priors or multi-view geometry at test time?
- Ablation disentangling MoT vs latent CoT vs flow policy: The paper ablates modalities and horizons but does not isolate the contributions of the MoT dual-expert design and the flow-matching head versus the latent CoT itself. Which component contributes most to gains and in what regimes?
- Long-horizon scalability: Real-world long-horizon evaluation appears limited to one multi-step task. How does performance scale on complex, branching, or partially observable long-horizon tasks requiring memory of many subgoals?
- Action representation choices: Actions use Euler angles (with potential singularities) and simple concatenation for dual-arm. Would quaternions, screw-axis representations, or learned coordination priors for bimanual actions improve stability and coordination?
- End-to-end encoder adaptation: Vision and 3D encoders are frozen teachers and not fine-tuned with the policy. Does joint end-to-end fine-tuning (with appropriate regularization) yield better task-aligned latents without overfitting or catastrophic forgetting?
- Runtime failure handling and replanning: There is no mechanism to detect and recover from failed subgoals or to trigger re-reasoning mid-episode. How can the policy detect dead-ends, reset latent plans, and re-synthesize CoT based on observed deviations?
- Multi-view usage at inference: Real-world experiments use multi-view RGB, but there is no systematic study of view count, placement, or robustness to camera pose drift. What is the sensitivity to multi-view configuration, and can the model self-calibrate or fuse views geometrically?
- Fairness and reproducibility of comparisons: Baselines differ in backbone sizes and pretraining data; reimplementation details vary. Can standardized training budgets, identical backbones, and shared datasets clarify relative contributions?
- Latent supervision objective design: Cosine similarity on continuous embeddings ignores magnitude and can permit scale collapse. Would contrastive, predictive coding, or distribution-matching objectives (e.g., InfoNCE, MSE on normalized latents, or Wasserstein distances) improve alignment?
- Planning vs reactive control boundary: The latent CoT predicts short future windows; there is no integration with explicit task planners or model-based MPC. How can latent CoT be combined with hierarchical planning or learned dynamics models to solve more strategic tasks?
- Safety and ethical deployment: The paper does not discuss safe operation constraints, human–robot interaction, or risk-aware control. How to incorporate safety constraints, human proximity limits, and fail-safes into the latent reasoning and action generation loop?
- Continual and online adaptation: The method is purely offline imitation with fixed experts at deployment. Can online adaptation, preference optimization, or latent-space RL improve robustness over time without destabilizing the acting expert?
- Handling missing or dropped modalities at runtime: There is no study of robustness when a camera fails, frames drop, or latency spikes. Can modality-dropout training or latent imputation maintain performance under partial observation?
- Bimanual coordination and constraints: Dual-arm control is treated as concatenated 14-DoF actions. How to incorporate shared-object constraints, coordinated grasp–manipulate policies, and collision avoidance between arms into the latent CoT and action heads?
Glossary
- Action tokenizer: A component that converts robot state signals into compact embeddings suitable for model input. "proprioceptive latents via an action tokenizer."
- AdamW optimizer: An optimization algorithm that decouples weight decay from gradient updates for better training stability. "using the AdamW optimizer~\cite{loshchilov2017decoupled}"
- Affordance representations: Encodings of actionable properties of objects (e.g., graspable, pushable) used to guide manipulation. "linguistic reasoning traces or affordance representations~\cite{ye2025vla,li2025coa}"
- Asynchronous frequency mechanism: A coordination strategy where different model experts operate at different update rates to balance reasoning and control. "we introduce an asynchronous frequency mechanism between the slow reasoning expert and the fast acting expert."
- Autoregressive generation paradigm: A sequential prediction process where outputs are generated one token or step at a time, conditioning on previous outputs. "The autoregressive generation paradigm introduces inevitable computational overhead"
- Chain-of-Thought (CoT): A reasoning framework that models intermediate steps or plans before producing final outputs. "have been inspired by the Chain-of-Thought (CoT) reasoning paradigm in general VLMs"
- CoppeliaSim: A robot simulation environment used for evaluating manipulation tasks. "conducted in the CoppeliaSim simulation environment."
- DeepSeek-LLM 1B: A 1-billion-parameter LLM backbone used to initialize the system. "DeepSeek-LLM 1B as the backbone."
- Degrees of Freedom (DoF): The number of independent parameters that define the configuration of a robot or mechanism. "7-DoF end-effector pose control mechanism"
- End-effector: The tool or gripper at the end of a robotic arm that interacts with objects. "7-DoF end-effector pose control mechanism"
- Euler angles: A rotation representation using roll, pitch, and yaw angles. "represented as Euler angles [roll, pitch, yaw]"
- Feed-Forward Networks (FFN): Neural network layers that apply non-recurrent transformations to token embeddings in transformers. "Feed-Forward Networks (FFN)"
- Flow Matching: A generative modeling method that learns velocity fields to produce continuous outputs (e.g., actions) efficiently. "adopts a Flow Matching policy~\cite{black2024pi_0}"
- Flow Matching loss: The training objective used to learn the velocity field in flow matching-based policies. "Flow Matching loss $\mathcal{L}_{\text{flow}$"
- Flow velocity field: The learned vector field that guides the generation of continuous actions over time. "transform the predicted flow velocity field"
- Franka Panda: A widely used 7-DoF robotic manipulator for research and benchmarking. "executed using a Franka Panda robotic arm"
- Gello platform: A data collection platform for intuitive, low-cost manipulation demonstrations. "using the Gello platform~\cite{wu2024gellogenerallowcostintuitive}"
- Heterogeneous operation frequencies: Training the system with different update rates for reasoning and action to enable flexible deployment. "trained with heterogeneous operation frequencies"
- Janus-Pro: A multimodal foundation model used to initialize the VLA architecture. "Janus-Pro~\cite{chen2025janus}"
- Keyframe: Selected timesteps at which the slow reasoning expert updates latent plans. "sparse keyframes ()"
- KV cache: The stored key-value attention states used to avoid recomputation during inference. "stored in the KV cache."
- Layer Normalizations: Operations in transformers that stabilize training by normalizing layer inputs. "Layer Normalizations"
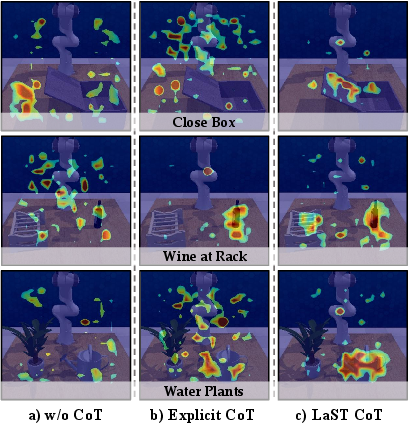
- Latent Chain-of-Thought (CoT): An implicit, continuous reasoning process carried out in a compact embedding space instead of explicit text or images. "Latent Spatio-Temporal Chain-of-Thought (CoT)"
- Mixture-of-Transformers (MoT): An architecture with multiple specialized transformer experts that share attention contexts but have distinct parameters. "Mixture-of-Transformers (MoT)"
- Open Motion Planning Library: A toolkit for generating robot motion plans in simulation or real-world tasks. "Open Motion Planning Library~\cite{sucan2012open}"
- Open-X-Embodiment: A large-scale dataset of robot trajectories used for pretraining. "Open-X-Embodiment~\cite{open_x_embodiment_rt_x_2023}"
- Point cloud: A set of 3D points representing object geometry and spatial structure. "a point cloud uniformly subsampled to 1024 points"
- Proprioceptive: Referring to internal sensing of the robot’s own state (e.g., joint angles, gripper). "robot proprioceptive states"
- RLBench: A benchmark suite of simulated robot manipulation tasks. "on RLBench"
- SE(3): The Special Euclidean group representing 3D rigid body transformations (rotation and translation). "Special Euclidean group "
- SigLIP-Large: A pretrained visual encoder that extracts semantic features from images. "SigLIP-Large"
- Supervised Fine-Tuning (SFT): Training a model on labeled data to adapt it to specific tasks after pretraining. "Supervised Fine-Tuning (SFT)"
- Teacher forcing: A training technique where ground-truth outputs are fed as inputs to guide model learning. "This latent-space teacher forcing establishes a reliable latent scaffold"
- Timestep MLP: An MLP that encodes continuous time coordinates for flow-based action generation. "we use a timestep MLP to encode the continuous time coordinate"
- Uni3D: A scalable 3D foundation model for encoding point cloud features aligned with image/text embeddings. "We adopt Uni3D~\cite{zhou2023uni3dexploringunified3d}"
- Vision-Language-Action (VLA): Models that integrate visual input, natural language, and action outputs for robotic manipulation. "Vision-Language-Action (VLA) models have rapidly advanced"
- Vision-LLMs (VLMs): Models that jointly process visual and textual modalities to enable multimodal understanding. "Vision-LLMs (VLMs)~\cite{alayrac2022flamingo,karamcheti2024prismatic, wang2024qwen2, deng2025emergingpropertiesunifiedmultimodal}"
Practical Applications
Immediate Applications
Below are concrete, near-term uses that can be deployed with current capabilities (as demonstrated in simulation and real-world results) when appropriate hardware, data, and integration are available.
- Cell-level industrial manipulation (manufacturing and logistics)
- Sectors: robotics, manufacturing, logistics
- Use cases: surface wiping/cleaning, pressing buttons/stamps, opening/closing containers or doors, placing items onto racks or fixtures, repeatable tool use (e.g., eraser, spatula) in structured stations.
- Why enabled: Real-time control (≈15 Hz on a single RTX 4090) with temporally consistent latent reasoning improves reliability in closed-loop manipulation; supports single- and dual-arm.
- Tools/products/workflows: ROS2 node for LaST0 with asynchronous slow–fast control; cell integration package that wraps the “slow reasoning KV-cache” for reuse across fast control cycles; calibration toolkit for multi-view cameras; demonstration-to-SFT pipeline.
- Assumptions/dependencies: Structured cell layout; reliable RGB camera placement (multi-view recommended); an x86 workstation with a high-end GPU; several dozen to a few hundred demonstrations per task for SFT; safety cages or certified force limits for human proximity.
- Food service and light assembly tasks
- Sectors: food service, consumer goods, light manufacturing
- Use cases: scooping/pouring granular items (popcorn/grains), opening lids, placing delicate items (e.g., egg on bread), repetitively transferring items between containers.
- Why enabled: Latent spatio-temporal CoT encodes future visual, geometric, and proprioceptive cues, stabilizing contact-rich actions and long-horizon sequences.
- Tools/products/workflows: “Kitchen cell” starter kit with pre-trained latent templates (e.g., lid opening, scooping) and SFT scripts; quality monitoring hooks that watch for horizon failures and trigger retries.
- Assumptions/dependencies: Nonhazardous food handling context; predictable tools and utensils; regular cleaning and calibration of cameras; tactile sensing not required but could further improve robustness.
- Research benchmarking and reproducible VLA workflows
- Sectors: academia, R&D labs, robotics software
- Use cases: studying latent-coT vs. explicit-CoT tradeoffs; long-horizon robustness evaluation; ablations on token budgets, horizons, and slow–fast ratios; dataset creation with latent teacher-forcing.
- Why enabled: Method provides a clear training recipe, modality ablations, and dual-expert MoT implementation with heterogeneous operation frequencies.
- Tools/products/workflows: Open-source training scripts for 3-stage pipeline (pretrain → latent SFT → action SFT); “latent ground-truth builder” that encodes future RGB/point clouds/proprio into compact tokens; attention and KV-cache visualizers.
- Assumptions/dependencies: Access to large, curated manipulation datasets; point clouds required only at training-time; compatible foundation backbones (e.g., Janus-Pro, SigLIP).
- System integrator offerings for brownfield robots
- Sectors: system integration, industrial automation
- Use cases: retrofitting existing 6–7 DoF arms (e.g., Franka, UR) with a LaST0 policy for station-level tasks; dual-arm coordination for transfer operations.
- Why enabled: Policy head uses flow matching without extra action heads; dual-expert MoT is self-contained; can adapt to new stations with task-specific SFT.
- Tools/products/workflows: “Drop-in policy server” exposing gRPC/ROS2 interfaces (act, set_ratio, set_horizon); configuration wizard to pick slow–fast ratios (e.g., 1:4) based on station dynamics.
- Assumptions/dependencies: Stable robot drivers; accurate extrinsic calibration; workstation-grade GPU; operator safety procedures.
- Education and training labs
- Sectors: education, workforce development
- Use cases: courses demonstrating reason-before-act with latent vs. explicit plans; labs on asynchronous inference and KV-cache reuse; project-based learning on multi-view perception.
- Why enabled: Clear separation of slow latent reasoning and fast control enables hands-on demos with measurable speed/accuracy tradeoffs.
- Tools/products/workflows: Curriculum kits (notebooks + ROS demos); tasks such as “open lid,” “place on rack,” and “wipe surface” with analyzable attention maps.
- Assumptions/dependencies: Access to a teaching robot setup (single-arm + two RGB-D cameras) and a desktop GPU.
- Human-in-the-loop teleoperation assist
- Sectors: field service, facilities, operations
- Use cases: operator sets high-level goal; LaST0 handles low-level closed-loop manipulation (e.g., press/turn, open/close, precise placement) with the slow expert updated on keyframes or during pauses.
- Why enabled: KV-cached latent reasoner reduces latency between human cues and robot responses; fast expert maintains smooth control between updates.
- Tools/products/workflows: “Assisted teleop” UI that triggers slow expert updates on operator cue; guardrails that pause fast control on large state deviations.
- Assumptions/dependencies: Reliable comms and perception; safety interlocks; trained operators; GPU at the edge or on-prem.
Long-Term Applications
These opportunities require additional research, scaling, safety validation, or engineering to reach production-level performance and certification.
- General-purpose home assistance and ADL support
- Sectors: consumer robotics, elder care
- Use cases: multi-step chores (kitchen cleanup, loading dish racks, tidying surfaces); repeated long-horizon sequences with dynamic objects.
- Why promising: Long-horizon robustness with latent CoT and asynchronous slow–fast updates; demonstrated repeatability in dynamic scenes.
- Dependencies/assumptions: Robust perception under clutter and occlusion; safe physical interaction in unstructured homes; few-shot/person-specific adaptation; on-device or low-power inference (model compression/distillation).
- Autonomous laboratory assistants
- Sectors: biotech, materials science, R&D automation
- Use cases: opening/closing labware, placing/organizing containers, transferring solids/powders; eventually handling compliant or fragile items.
- Why promising: Multimodal latent reasoning can encode semantics + 3D structure + proprioception for precise, repeatable manipulations.
- Tools/workflows: “Lab protocol executor” integrating LaST0 with LIMS; vision-driven keyframe triggers for slow expert.
- Dependencies/assumptions: High safety requirements; sterility and contamination controls; integration with tactile/force sensing; regulatory validation.
- Multi-robot and multi-arm coordination at scale
- Sectors: manufacturing, intralogistics
- Use cases: coordinated hand-offs, synchronized assembly steps, shared workspaces where latent “team-level” reasoning is updated sparsely and actions run at high frequency across agents.
- Why promising: Dual-expert MoT and KV-cache paradigm extend naturally to shared latent caches and cross-attention among arms/robots.
- Dependencies/assumptions: Low-latency inter-robot comms; time sync; conflict resolution; shared world model updates; safety zoning.
- Long-horizon assembly and tool-use in variable environments
- Sectors: advanced manufacturing, maintenance
- Use cases: sequences combining open/close, fastener manipulation, precise alignments, and tool transitions with environmental changes.
- Why promising: Temporal horizon in latent space can be extended for far-sighted reasoning without decoding text/images.
- Dependencies/assumptions: Expanded training corpora with rich tool-use and contact dynamics; hybrid sensing (vision + force/torque); task monitors and failure recovery.
- Healthcare and clinical support (non-surgical and surgical assistance)
- Sectors: healthcare, medical devices
- Use cases: noninvasive assistive tasks (fetch/organize medical supplies), eventually semi-autonomous surgical assistance.
- Why promising: Latent CoT better captures ineffable physical attributes than textual plans, which is essential for delicate manipulation.
- Dependencies/assumptions: Extensive safety certification, liability frameworks, clinician-in-the-loop oversight, sterilization and reliability standards; regulatory approval.
- Warehouse and retail automation in unstructured settings
- Sectors: retail, e-commerce
- Use cases: shelf restocking, item facing, opening display cases, placement on racks, light depalletizing in semi-structured contexts.
- Why promising: Reason-before-act reduces dithering and improves stability in the face of moving customers or changing layouts.
- Dependencies/assumptions: Strong domain adaptation for new stores and lighting; scalable data pipelines; embedded depth at inference or enhanced 3D perception.
- Policy, safety, and auditing frameworks for latent reasoning in robots
- Sectors: public policy, standards, compliance
- Use cases: certification processes for latent CoT controllers; standardized tests for long-horizon robustness, latency budgets, and failure recovery; audit tools for latent representations and KV-cache usage.
- Why promising: Shift from explicit textual plans to latent reasoning demands new verification methods that are functional rather than purely interpretable.
- Tools/workflows: “Latent CoT auditor” that probes sensitivity to perturbations; benchmarks for slow–fast frequency safety; standardized logging of latent tokens and attention maps.
- Dependencies/assumptions: Industry standards bodies engagement; privacy/governance for datasets used to train latent spaces; incident reporting norms.
- Edge deployment and sustainable compute
- Sectors: embedded systems, energy
- Use cases: deploying LaST0-like policies on Jetson/TPU-class hardware for mobile platforms.
- Why promising: Token-efficient latent CoT and asynchronous reasoning reduce average compute; potential for quantization/distillation.
- Dependencies/assumptions: Model compression without degrading safety; hardware-accelerated attention and flow-matching; thermal/power constraints management.
Cross-cutting assumptions and dependencies
- Hardware and sensing: Real-time performance shown on an RTX 4090; achieving similar responsiveness on edge devices requires model optimization; multi-view RGB recommended; point clouds needed only at training time but can be beneficial at inference in harder scenes.
- Data and training: Quality and diversity of demonstrations strongly impact generalization; latent teacher-forcing relies on accurate future-state encodings; domain shift must be managed (lighting, object variability).
- Safety and reliability: Guardrails for long-horizon failure recovery; physical safety interlocks; human-in-the-loop oversight in early deployments.
- Integration: Precise robot and camera calibration; stable clocking for asynchronous slow–fast cycles; robust ROS2/gRPC middleware.
- IP/licensing: Foundation models (e.g., Janus-Pro, SigLIP, Uni3D) and datasets must be used under compatible licenses; governance for real-world data capture (privacy and consent).
Collections
Sign up for free to add this paper to one or more collections.