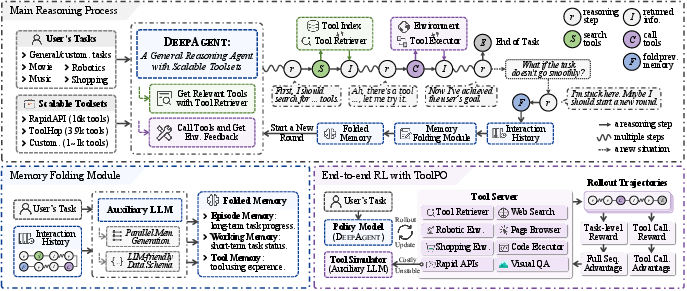
DeepAgent: A General Reasoning Agent with Scalable Toolsets
Abstract: Large reasoning models have demonstrated strong problem-solving abilities, yet real-world tasks often require external tools and long-horizon interactions. Existing agent frameworks typically follow predefined workflows, which limit autonomous and global task completion. In this paper, we introduce DeepAgent, an end-to-end deep reasoning agent that performs autonomous thinking, tool discovery, and action execution within a single, coherent reasoning process. To address the challenges of long-horizon interactions, particularly the context length explosion from multiple tool calls and the accumulation of interaction history, we introduce an autonomous memory folding mechanism that compresses past interactions into structured episodic, working, and tool memories, reducing error accumulation while preserving critical information. To teach general-purpose tool use efficiently and stably, we develop an end-to-end reinforcement learning strategy, namely ToolPO, that leverages LLM-simulated APIs and applies tool-call advantage attribution to assign fine-grained credit to the tool invocation tokens. Extensive experiments on eight benchmarks, including general tool-use tasks (ToolBench, API-Bank, TMDB, Spotify, ToolHop) and downstream applications (ALFWorld, WebShop, GAIA, HLE), demonstrate that DeepAgent consistently outperforms baselines across both labeled-tool and open-set tool retrieval scenarios. This work takes a step toward more general and capable agents for real-world applications. The code and demo are available at https://github.com/RUC-NLPIR/DeepAgent.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeepAgent, a smart computer “agent” that can think through problems, find and use the right tools (like apps or websites), and remember important information while working on long tasks. It aims to handle real-world jobs that need many steps, outside resources, and careful planning—like researching online, shopping on a website, or solving complex puzzles with code.
What questions were they trying to answer?
The researchers wanted to solve a few big challenges:
- How can an AI agent think deeply and plan without being locked into a rigid, pre-made workflow?
- How can it discover and use the right tools at the right time, instead of only using a small set of fixed tools?
- How can it manage long tasks without forgetting important details or getting overwhelmed by too much history?
- How can we train such an agent efficiently and reliably, even when the tools are complicated or expensive to use?
How did they do it? Methods and ideas explained simply
To tackle these challenges, they built DeepAgent with several key parts. Think of DeepAgent like a focused student with a giant toolbox and a smart way of taking notes.
The agent’s unified reasoning process
Most older agents follow a strict loop: “Think → Act → Observe” over and over. DeepAgent is different. It keeps one continuous chain of thought. In that stream, it can:
- Think about the task,
- Search for the tools it needs,
- Call those tools with the right settings,
- Organize its memory,
- And keep going without losing the bigger picture.
This helps it stay flexible and make better decisions overall.
Finding and using tools on demand
Imagine you’re doing homework and need different apps: a calculator, a map, or a music database. DeepAgent can:
- Search for tools by writing a short query (like “find a movie database tool”).
- Retrieve the best tools from a huge library using a “search-by-meaning” system (similar to searching by topic rather than exact words).
- Call a tool by sending structured instructions (like telling the app exactly what to do and with what inputs).
- Summarize long tool outputs with a helper model so the main agent doesn’t get distracted by too much text.
Memory folding: tidying up the agent’s notes
Long tasks create lots of text and history, which can overload the agent. DeepAgent can “fold” its memory—like tidying a messy notebook into neat summaries—whenever it needs a reset. It compresses past interactions into three organized parts:
- Episodic memory: a high-level timeline of important events and decisions.
- Working memory: the current sub-goal, recent obstacles, and next steps.
- Tool memory: which tools were used, how they were used, and whether they worked.
These summaries are stored in a structured format (like clear, labeled checklists) so the agent can easily use them later. This saves space, reduces mistakes, and lets the agent “take a breath” and rethink its strategy.
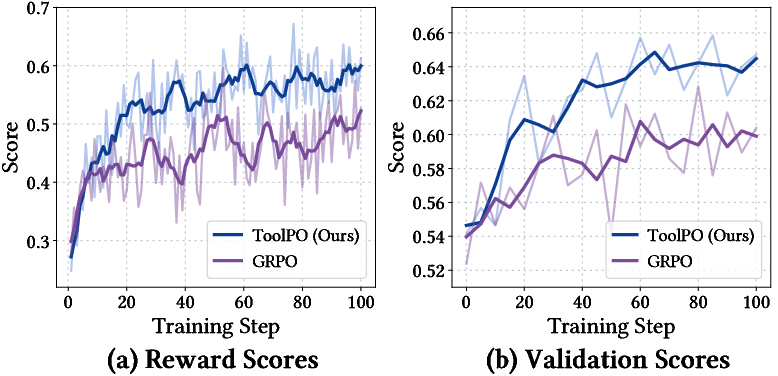
Training with ToolPO (a smart practice routine)
Training AI with real online tools can be slow, costly, and unstable. So the authors created ToolPO, a reinforcement learning (RL) method that uses simulated tools:
- Tool simulator: instead of calling real APIs, the agent practices with a fast and reliable simulator that mimics real responses.
- Two types of rewards:
- Global success: Did the agent finish the task correctly?
- Action-level credit: Did it choose and call the right tools at the right moments?
- Fine-grained credit assignment: The training gives extra “points” specifically to the tokens (tiny pieces of text) where the agent made correct tool calls or folded memory efficiently. This helps it learn the tricky parts precisely.
What did they find?
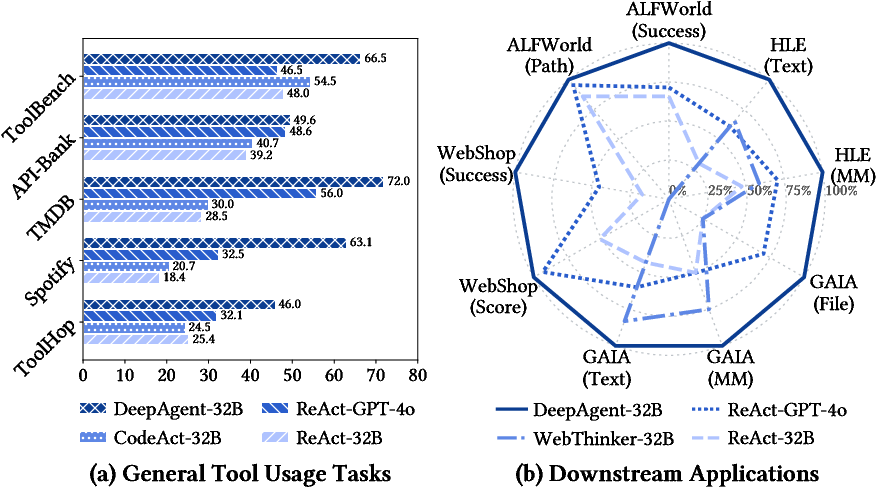
The team tested DeepAgent on many benchmarks, including tool-use tasks and real-world applications:
- Tool-use tasks: ToolBench, API-Bank, TMDB, Spotify, and ToolHop
- Applications: ALFWorld (virtual home tasks), WebShop (online shopping), GAIA (research and reasoning), and HLE (very hard exam-style problems)
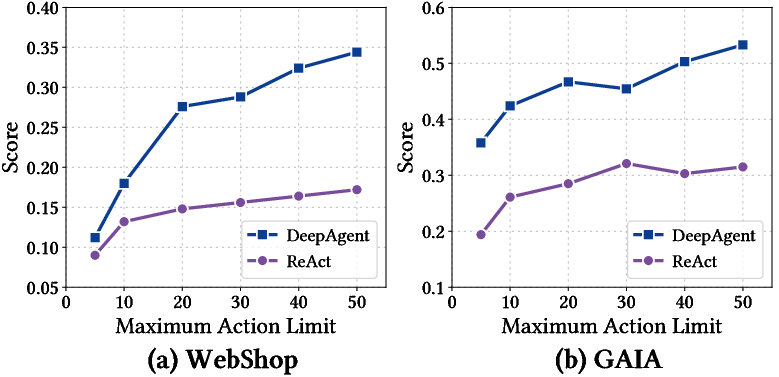
Across these tests, DeepAgent consistently performed better than traditional agents that rely on fixed workflows (like ReAct, Plan-and-Solve, CodeAct, and Reflexion). Two standout results:
- In “open-set” scenarios (where the agent must search for tools from large collections), DeepAgent’s ability to discover tools on demand led to big improvements.
- Using ToolPO training made DeepAgent even stronger, improving both tool-use accuracy and performance on long, complex tasks.
In short, the agent’s unified reasoning, dynamic tool discovery, and memory folding gave it clear advantages.
Why does this matter? Implications and impact
DeepAgent points toward smarter, more independent AI systems that can:
- Handle real-world tasks that need many steps and different tools,
- Keep track of what matters during long interactions without getting lost,
- Learn robustly and affordably using simulated tools,
- And adapt to new toolsets in the wild (like the growing ecosystem of APIs and apps).
This could improve AI assistants for research, shopping, coding, data analysis, and more—especially tasks that require careful planning, reliable memory, and using the right tools at the right time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper; each item is concrete to guide follow-up research:
- Real-world API fidelity: The RL training relies on LLM-simulated APIs, but there is no systematic sim-to-real evaluation with production APIs (e.g., authentication, rate limits, pagination, non-deterministic behavior, schema drift, latency spikes, outages). Quantify performance drop and robustness when swapping the simulator for actual APIs across diverse providers.
- Tool-call correctness definition: “Correct tool invocation” is rewarded, but the paper does not specify how correctness is determined across tasks lacking labeled intermediate calls. Establish formal, task-agnostic criteria (schema validation, argument semantics, side-effect verification) and measure inter-annotator agreement.
- Retrieval scaling beyond 16k tools: Dense retrieval is tested up to ~16k tools; real-world ecosystems can exceed 100k–1M tools. Evaluate retrieval accuracy, latency, memory footprint, and top-k sensitivity at much larger scales, and explore approximate nearest neighbor indices and caching strategies.
- Retriever training and adaptation: The retriever is fixed (bge-large-en) and not trained or adapted end-to-end with the agent. Investigate joint training of the retriever with the reasoning policy, online adaptation to new toolsets, and feedback loops from tool-call outcomes.
- Tool documentation quality and summarization loss: The auxiliary LLM summarizes tool docs and outputs, but the paper does not quantify information loss, hallucination, or misinterpretation introduced by summarization. Conduct controlled studies measuring critical-field omission rates, argument mis-specification, and downstream error propagation.
- Dynamic toolset updates: No mechanism or evaluation for handling tool additions/removals, version changes, or deprecated endpoints during a running session. Design incremental index updates, capability negotiation, and backward-compatibility handling.
- Memory folding policy characterization: While memory folding improves GAIA, the paper does not analyze fold timing, frequency, token savings, and accuracy trade-offs. Provide quantitative analysis of fold-trigger conditions, impact on trajectory length, and fold-related failure modes (e.g., forgetting recent constraints).
- Catastrophic forgetting and memory staleness: The effects of compressing long histories into episodic/working/tool memories on recall of fine-grained details are not measured. Evaluate retention of task-critical facts pre/post-fold, stale-memory detection, and recovery strategies.
- Schema robustness: The JSON memory schema is proposed but not stress-tested for malformed entries, partial writes, or adversarial injection (e.g., prompt poisoning within fields). Add schema validation, type-checking, and sanitization; measure robustness under adversarial inputs.
- Safety and security: The agent can discover and invoke external tools, but the paper does not address permissioning, sandboxing, data exfiltration risks, or potentially harmful actions. Develop a safety layer with allowlists/denylists, least-privilege scopes, and runtime policy checks; evaluate attack scenarios (prompt injection, tool masquerading).
- Latency, throughput, and cost: Inference uses up to 81,920 tokens and 64 H20 GPUs, but there is no analysis of end-to-end latency, throughput, or cost per task. Provide runtime breakdowns (retrieval, reasoning, tool calls, folding), and quantify the efficiency gains from folding under realistic constraints.
- Advantage attribution sensitivity: ToolPO’s advantage attribution relies on λ hyperparameters and masking of action tokens, but sensitivity analyses and theoretical justification are limited. Study convergence properties, variance under different λ values, and alternative credit assignment strategies (e.g., per-argument token weighting, structured action heads).
- Simulator coverage and failure modeling: The tool simulator design, coverage of error modes (timeouts, partial data, 4xx/5xx codes, schema evolution), and calibration to real APIs are not detailed. Build a benchmark of realistic failure distributions and report agent resilience and recovery behaviors.
- Auxiliary LLM dependence: The auxiliary LLM handles summarization, denoising, and compression, but its contribution is not isolated beyond coarse ablation. Quantify its error rates, compare different auxiliary models, and assess how its quality scales with task difficulty.
- Multilingual and cross-lingual generalization: Tasks and tools appear predominantly English. Evaluate tool retrieval and usage with non-English user queries and tool documentation; explore multilingual embeddings and cross-lingual argument generation.
- Coverage of non-text modalities and tools: Beyond VQA, the framework does not explore audio, geospatial, IoT/robotics, or interactive UI tools. Assess generalization to diverse modalities and device APIs, including time-critical control loops.
- MCP interoperability and ecosystem integration: The paper references MCP conceptually but does not implement formal MCP tool discovery/permission flows. Evaluate plug-in lifecycle management, consent workflows, and interoperability across MCP-compliant providers.
- Robustness to noisy/adversarial tool outputs: No experiments assess behavior under misleading or adversarial tool responses (e.g., poisoned search results). Introduce self-verification, cross-tool consistency checks, and rollback/undo mechanisms.
- Argument validation and execution safety: Tool calls are parsed from JSON, but there is no formal schema validation, unit constraints, or exception handling pipeline. Implement typed schemas, contract checks, and safe execution wrappers; report the rate of runtime errors and recovery success.
- Termination criteria and “done” detection: The agent relies on a max step limit, but criteria for detecting completion or futility are not formalized. Develop confidence-based stopping rules and measure trade-offs (precision/recall of completion detection).
- Failure mode analysis: The paper lacks granular error attribution (retrieval miss, argument formatting, tool failure, reasoning flaw) on benchmarks like ToolHop. Instrument trajectories to tag failure causes and prioritize targeted fixes.
- Evaluation breadth: Metrics focus on Pass@1 and path scores; there is no human evaluation of helpfulness, safety, or user satisfaction. Add qualitative assessments, task success under user constraints (budget, time), and compliance/adherence metrics.
- Reproducibility and data availability: Training data sources are listed, but the exact splits, prompts, and simulator configurations are not fully disclosed. Release detailed datasets, simulator scripts, and seeds to enable faithful reproduction.
- Model generality across sizes/backbones: Results center on QwQ-32B; portability to smaller models or different backbones is not studied. Test scaling laws, minimum viable model sizes, and transfer across open/closed-source backbones.
- Measuring “global perspective” claims: The paper asserts a globally coherent reasoning process but does not provide metrics (e.g., plan consistency, re-planning success after fold). Propose and report quantitative measures of global task coherence and long-horizon planning quality.
- Online learning and continual adaptation: The agent does not adapt its policy or memories across tasks or sessions. Explore continual learning, memory reuse, and personalized tool-use profiles with drift detection and mitigation.
- Privacy and compliance: Web and file tools may process sensitive data; no discussion of privacy guarantees or regulatory compliance (GDPR/CCPA). Define data handling policies, logging minimization, and compliance auditing; evaluate privacy-preserving variants.
- Multi-agent coordination: The framework uses a single agent plus auxiliary LLM; potential benefits of specialized sub-agents or negotiators are unexplored. Investigate multi-agent decomposition, communication protocols, and shared memory structures.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging DeepAgent’s unified reasoning, dynamic tool retrieval, and autonomous memory folding, together with the ToolPO training workflow and tool simulation.
- Autonomous web research co-pilot for analysts (industry, academia, media, legal)
- What it does: Plans multi-hop searches, browses pages, extracts and cross-checks facts, runs quick code-based checks, and maintains a structured “research log” via memory folding for long investigations (GAIA-like).
- Tools/workflows: Web search (e.g., Serper), page reading (e.g., Jina Reader), VQA for charts/tables, code execution for light data cleaning/validation, JSON memory for auditability.
- Assumptions/dependencies: High-quality tool documentation; permissioned access to paywalled sources; retrieval quality (embedding model + tool doc quality); human-in-the-loop approval for claims.
- E-commerce shopping assistant (retail/marketplaces)
- What it does: Searches and compares products across stores, summarizes reviews/specs, justifies trade-offs, and prepares carts with vendor-specific APIs (WebShop-style).
- Tools/workflows: Retailer APIs, price/availability APIs, payment initiation with human confirmation, JSON episodic memory to span long user sessions.
- Assumptions/dependencies: API rate limits; identity and payment authorization; fraud/chargeback guardrails; product catalog freshness.
- L1 customer support triage and resolution (software, telecom, fintech, logistics)
- What it does: Retrieves relevant tools on demand (ticketing, KB, account data), reproduces issues via scripted tool calls, and summarizes steps taken using structured tool memory.
- Tools/workflows: Zendesk/Jira/ServiceNow, account lookups, log search, knowledge base, automatic case “memory fold” summaries attached to tickets.
- Assumptions/dependencies: Secure data access; PII/PHI handling and audit; escalation policies; well-instrumented APIs.
- DevOps/SRE co-pilot (software)
- What it does: Investigates service incidents end-to-end by querying CI/CD, APM, logs, and error trackers; runs diagnostic scripts; folds long histories into concise working memory to avoid getting stuck.
- Tools/workflows: GitHub/GitLab, Jenkins, Datadog/New Relic, Splunk/ELK, Sentry; tool memory to track attempted remediations and outcomes.
- Assumptions/dependencies: Safe execution environment and permissioning; runbooks/standard operating procedures; change management with human approval.
- Data engineering and BI assistant (software, analytics)
- What it does: Diagnoses broken pipelines, queries warehouses (Snowflake/BigQuery), inspects lineage and data quality checks, and compiles a structured incident report.
- Tools/workflows: SQL execution, data catalog/lineage APIs, quality monitors; memory folding to keep long triage contexts affordable and coherent.
- Assumptions/dependencies: Stable connectors; cost controls for query execution; role-based access control (RBAC).
- SOC triage co-pilot (security)
- What it does: Correlates SIEM alerts, enriches with threat intel, retrieves EDR/IDS evidence, and drafts response playbooks, storing a detailed, structured episode log for audits.
- Tools/workflows: Splunk/QRadar/Chronicle, EDR (e.g., CrowdStrike), threat intel feeds, case management; tool-call attribution logs for forensics.
- Assumptions/dependencies: Strict access governance; risk thresholds; human gatekeeping on containment/remediation actions.
- Healthcare admin workflow assistant (healthcare)
- What it does: Automates scheduling, eligibility checks, benefit verification, prior authorizations, and billing status checks using dynamic tool retrieval; maintains case histories with memory folds.
- Tools/workflows: FHIR/EHR APIs, payer portals, scheduling/billing APIs; episodic memory as a HIPAA-aligned audit trail.
- Assumptions/dependencies: Regulatory compliance (HIPAA, GDPR); secure handling of PHI; payer/EHR API variability.
- Finance back-office reconciliation and compliance (finance)
- What it does: Matches transactions across ERP/banking APIs, flags anomalies, checks policies/regulatory rules, and produces explainable, structured audit logs from memory.
- Tools/workflows: ERP (e.g., NetSuite, SAP), bank APIs, compliance knowledge bases, file reading and code-based validation for edge cases.
- Assumptions/dependencies: Precise policy rules and test suites; segregation of duties; read/write permissions with approvals.
- Personal travel concierge (consumer)
- What it does: Searches flights/hotels, compares trade-offs, books with multiple providers, handles changes/refunds, and maintains itinerary “working memory” across long interactions.
- Tools/workflows: Aggregators (e.g., Skyscanner), airline/hotel APIs, document/file tools (passport/visa checks), secure vault for credentials.
- Assumptions/dependencies: Human confirmation for payments; vendor-specific quirks; robust error handling for failed bookings.
- Education tutor and lab assistant (education)
- What it does: Solves multi-step problems, fetches references, runs code to verify solutions, explains reasoning, and supports visual Q&A for diagrams; maintains student progress memory.
- Tools/workflows: Web search, code execution, VQA; structured episodic memory for lesson continuity.
- Assumptions/dependencies: Alignment to curricula and academic integrity standards; sandboxed execution; content safety filters.
- Agent development sandbox with tool simulation (software/tooling)
- What it does: Uses LLM-simulated APIs to test agents against large toolsets, enabling low-cost, low-latency RL fine-tuning with tool-call advantage attribution for precise debugging.
- Tools/workflows: ToolPO training pipeline, tool simulators, advantage attribution telemetry dashboards.
- Assumptions/dependencies: Simulator fidelity to production APIs; synthetic-to-real generalization checks; evaluation harnesses.
- Enterprise API catalog and retrieval service (software/platform)
- What it does: Indexes API docs across the enterprise and third parties, supports dense retrieval for agents, and enforces governance/permissions; fits the MCP paradigm.
- Tools/workflows: Embedding index (e.g., bge-large), MCP servers, tool governance UI, ranking/feedback loops.
- Assumptions/dependencies: Up-to-date and standardized API documentation; metadata quality; access control integration.
- Agent memory service for cost and reliability (software/platform)
- What it does: Provides a JSON schema for episodic/working/tool memories and automatic “folding” endpoints to compress long trajectories, lowering token costs and error accumulation.
- Tools/workflows: Memory folding microservice, storage + retrieval of structured memories, observability for fold triggers/outcomes.
- Assumptions/dependencies: Stable schema versioning; privacy retention policies; compatibility across backbone LLMs.
Long-Term Applications
These use cases become feasible as reliability, safety, and ecosystem maturity improve (e.g., standard tool schemas, robust guardrails, stronger verification, and broader MCP adoption).
- Clinical decision support with autonomous tool use (healthcare)
- What it could do: Query guidelines/medical databases, interpret multimodal inputs (labs, images via VQA), simulate treatment options, and explain reasoning with auditable, structured memories.
- Tools/workflows: EHR/FHIR, medical knowledge bases, imaging tools, code for risk calculators.
- Assumptions/dependencies: Regulatory approval; validated clinical performance; strict human oversight and post-hoc verification; liability frameworks.
- Household/industrial robotics orchestration (robotics/manufacturing)
- What it could do: Use dynamic tool discovery as “skill discovery” (e.g., ROS actions, PLC commands), adapt to new devices on demand, and fold memory during long-horizon tasks (assembly/maintenance).
- Tools/workflows: ROS/ROS2, digital twins/simulators, safety interlocks, environment mapping.
- Assumptions/dependencies: Robust perception-actuation; real-time constraints; formal safety guarantees; sim-to-real transfer.
- Fully autonomous procurement and vendor management (enterprise/policy)
- What it could do: Discover suppliers, evaluate bids, negotiate (email/chat), check compliance, generate contracts, and reconcile deliveries and invoices end-to-end with detailed audit traces.
- Tools/workflows: Sourcing platforms, contract management, ERP, supplier risk/intel; structured memory for audits.
- Assumptions/dependencies: Organizational policy encoding; negotiation ethics; human approvals for commitments; robust identity and authority management.
- Automated scientific discovery loops (academia, pharma, materials)
- What it could do: Formulate hypotheses, mine literature, design/run code experiments, control lab equipment or simulators, and iteratively refine approaches with embedded tool memories.
- Tools/workflows: LIMS, lab robots, simulation frameworks, dataset registries; RL with tool simulation before lab runs.
- Assumptions/dependencies: Reliable experiment control; data provenance; reproducibility checks; domain-specific validation pipelines.
- Regulated financial advisors with transactional autonomy (finance)
- What it could do: Monitor markets, query risk/compliance tools, simulate portfolios, execute trades under policy constraints, and produce regulator-grade logs via episodic/tool memory.
- Tools/workflows: Broker/trading APIs, risk engines, KYC/AML checks, supervisory dashboards for approvals.
- Assumptions/dependencies: Licensing and fiduciary requirements; strict guardrails; robust backtesting; incident handling protocols.
- Cross-agency digital service orchestrator (public sector)
- What it could do: Dynamically discover agency services, retrieve personalized records, pre-fill forms, schedule appointments, and track cases across departments with a single agent session.
- Tools/workflows: MCP-based service registry, identity federation, case management; memory folding for multi-month episodes.
- Assumptions/dependencies: Interoperable standards; privacy/security frameworks; equitable access; strong auditability.
- Agent OS / enterprise agent platform
- What it could do: Provide a standardized runtime embedding autonomous tool retrieval, memory folding, ToolPO training, and tool simulators; support multi-tenant governance and observability.
- Tools/workflows: Policy engines, capability-based permissions, tool marketplaces, telemetry and cost controls.
- Assumptions/dependencies: Vendor-neutral standards (e.g., MCP); compatibility with diverse LLM backbones; organizational adoption.
- Standardized tool schemas and compliance/audit pipelines
- What it could do: Establish widely adopted JSON schemas for episodic/working/tool memories and tool invocation logs, enabling cross-vendor audits, reproducibility, and forensics.
- Tools/workflows: Schema registries, conformance validators, signed execution receipts; chain-of-custody for actions.
- Assumptions/dependencies: Industry consortia; regulator engagement; secure logging and attestation.
- Multi-agent ecosystems with shared tool memories (cross-domain)
- What it could do: Specialized agents coordinate via shared episodic/tool memories, hand off subtasks, and negotiate tool ownership and access in dynamic environments.
- Tools/workflows: Orchestration fabric, shared memory stores, role-based tool routing; inter-agent protocols.
- Assumptions/dependencies: Communication safety; conflict resolution; provenance and accountability for collective actions.
- On-device/private agents with local tool discovery (consumer/enterprise)
- What it could do: Run privacy-sensitive workflows locally (e.g., document analysis, offline search), use memory folding to fit small-context models, and selectively escalate to cloud tools.
- Tools/workflows: Local vector stores, sandboxed code tools, private search indices; hybrid execution policies.
- Assumptions/dependencies: Efficient local LRMs; hardware constraints; differential privacy; secure enclave support.
Cross-cutting assumptions and dependencies that affect feasibility
- Tool ecosystem readiness: Availability, stability, and documentation quality of APIs; adoption of Model Context Protocol (MCP) or equivalent.
- Governance and safety: Permissioning, identity, guardrails for high-risk actions; human-in-the-loop checkpoints; content safety and data governance (PII/PHI/financial).
- Reliability and evaluation: Robust retrieval quality, verification/grounding of outputs, test suites and post-hoc validation; simulator-to-reality fidelity for ToolPO-trained behaviors.
- Cost and scalability: Token budgets and latency; memory folding services to control context bloat; observability and cost controls for long-horizon agents.
- Compliance and audit: Use of structured JSON memories for traceability; regulator-grade logging and attestations in sensitive sectors.
- Organizational adoption: Integration with existing stacks (SaaS, data, security), change management, and user training.
Glossary
- ALFWorld: A text-based embodied AI environment used to evaluate agents on household tasks via discrete actions. "downstream applications (ALFWorld, WebShop, GAIA, HLE)"
- API-Bank: A benchmark with human-annotated dialogues and API calls to test planning, retrieval, and calling abilities. "API-Bank~\cite{API-Bank}, which includes 314 human-annotated dialogues with 73 APIs and 753 API calls"
- Autonomous Memory Folding: A mechanism where the agent compresses past interactions into structured memories to manage long-horizon reasoning. "We introduce an Autonomous Memory Folding strategy that allows DeepAgent to consolidate its previous thoughts and interaction history into a structured memory schema"
- Auxiliary LLM: A secondary LLM that supports the main agent by summarizing tool docs/results and compressing histories. "DeepAgent employs an auxiliary LLM to handle complex interactions with large toolsets and manage long histories."
- Brain-inspired memory architecture: A memory design modeled after human cognition, comprising episodic, working, and tool memories. "we introduce a brain-inspired memory architecture comprising episodic memory, working memory, and tool memory"
- Chain-of-Thought (CoT): A prompting/learning approach that elicits step-by-step reasoning in LLMs. "elicit extended Chain-of-Thought (CoT) reasoning"
- Clipped surrogate objective function: A PPO-style training objective that constrains policy updates to stabilize learning. "ToolPO then optimizes the policy using a clipped surrogate objective function:"
- Cosine similarity: A similarity measure between embeddings used for ranking retrieved tools. "by ranking them based on the cosine similarity"
- Dense retrieval: A retrieval method using vector embeddings to find relevant tools/documents. "The system's tool retriever operates via dense retrieval."
- Embedding model: A model that maps text (e.g., tool docs, queries) into vector representations for retrieval. "using an embedding model ."
- End-to-end reinforcement learning (RL): Training that optimizes the entire agent behavior directly through RL signals. "we propose ToolPO, an end-to-end reinforcement learning (RL) training method tailored for general tool use."
- Episodic Memory: A high-level log of key events and decisions to preserve long-term task context. "Episodic Memory (): This component serves as a high-level log of the task"
- GAIA: A complex information-seeking benchmark requiring multi-tool reasoning (e.g., search, browsing, VQA, code). "GAIA, a complex information-seeking benchmark"
- Group Relative Policy Optimization (GRPO): A policy optimization method that uses group-normalized rewards for stability. "compared to the commonly used GRPO."
- Humanity's Last Exam (HLE): A benchmark of extremely challenging reasoning problems for agents. "Humanity's Last Exam (HLE)"
- LLMs: Foundation models trained on vast corpora to perform language tasks and tool-augmented reasoning. "The rapid advancement of LLMs has inspired the development of LLM-powered agents"
- Large Reasoning Models (LRMs): LLMs specialized or trained to perform extended, step-by-step reasoning. "Large Reasoning Models (LRMs) \citep{deepseek-r1,openai2024openaio1card} have demonstrated significant performance improvements"
- Memory Fold: An action where the agent compresses the interaction history into structured memory. "Memory Fold ($a_t^{\text{fold}$)}: A special action to compress the interaction history into a structured memory summary."
- Model Context Protocol (MCP): A paradigm for dynamically accessing diverse, non-preselected tools at inference time. "aligning with the emerging Model Context Protocol (MCP) paradigm."
- Multi-hop reasoning: Solving tasks that require multiple sequential inference steps and tool calls. "a multi-hop reasoning dataset with 3,912 locally executable tools"
- Open-set tool retrieval: Retrieving and using tools from a large, not pre-labeled pool during task execution. "open-set tool retrieval scenarios."
- Parametric knowledge: Information stored in the model’s parameters as opposed to external sources or tools. "models relying solely on parametric knowledge face inherent limitations"
- Pass@1: A metric reporting the success of the top (first) attempt at solving a task. "We report Pass@1 metric for all tasks."
- Policy (in RL): The agent’s action-selection function mapping states/histories to action probabilities. "driven by a policy parameterized by ,"
- Probability ratio: The ratio of new-to-old policy probabilities for a token/action used in PPO-style updates. "is the probability ratio for token ."
- Sequential decision-making process: A formalization where an agent takes a series of actions over time to maximize reward. "We frame the agent's task as a sequential decision-making process."
- Sparse reward: A reward signal that provides feedback only at the end or infrequently, making learning harder. "A sparse reward based solely on the final outcome is often insufficient to guarantee the accuracy of intermediate tool calls."
- Supervised Fine-Tuning (SFT): Training a model on labeled data to improve performance on targeted tasks. "Supervised Fine-Tuning (SFT)"
- Tool Memory: A structured record of which tools were used, how, and with what effectiveness. "Tool Memory (): This consolidates all tool-related interactions"
- Tool Policy Optimization (ToolPO): The proposed RL algorithm that combines global and action-level rewards with advantage attribution. "We train DeepAgent end-to-end with Tool Policy Optimization (ToolPO), an RL approach designed for general tool-using agents."
- Tool retrieval: Selecting relevant tools from a large toolset based on a query or context. "Tool retrieval is performed using bge-large-en-v1.5"
- Tool Simulator: An LLM-based component that mimics real-world APIs to enable stable, low-cost RL training. "we develop an LLM-based Tool Simulator."
- ToolBench: A large-scale tool-use benchmark with over 16k APIs that stress-tests multi-step tool calling. "ToolBench~\cite{ToolLLM}, based on over 16,000 real-world APIs"
- ToolHop: A benchmark requiring sequences of tool calls (3–7 steps) to solve multi-hop tasks. "ToolHop~\cite{ToolHop}, a multi-hop reasoning dataset"
- Trajectory: The sequence of states, actions, and observations generated during an episode. "The sequence of states, actions, and observations forms a trajectory "
- Visual Question Answering (VQA): A task/tool where the agent answers questions about images. "Visual Question Answering (VQA)"
- WebShop: An online shopping environment for evaluating goal-directed browsing and purchasing via tools. "WebShop~\cite{WebShop}, an online shopping environment"
- Working Memory: The short-term memory that maintains the current sub-goals, obstacles, and near-term plans. "Working Memory (): This contains the most recent information"
Collections
Sign up for free to add this paper to one or more collections.

