Towards General Agentic Intelligence via Environment Scaling
Abstract: Advanced agentic intelligence is a prerequisite for deploying LLMs in practical, real-world applications. Diverse real-world APIs demand precise, robust function-calling intelligence, which needs agents to develop these capabilities through interaction in varied environments. The breadth of function-calling competence is closely tied to the diversity of environments in which agents are trained. In this work, we scale up environments as a step towards advancing general agentic intelligence. This gives rise to two central challenges: (i) how to scale environments in a principled manner, and (ii) how to effectively train agentic capabilities from experiences derived through interactions with these environments. To address these, we design a scalable framework that automatically constructs heterogeneous environments that are fully simulated, systematically broadening the space of function-calling scenarios. We further adapt a two-phase agent fine-tuning strategy: first endowing agents with fundamental agentic capabilities, then specializing them for domain-specific contexts. Extensive experiments on agentic benchmarks, tau-bench, tau2-Bench, and ACEBench, demonstrate that our trained model, AgentScaler, significantly enhances the function-calling capability of models.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper is about teaching AI “agents” (smart chatbots) to use tools and apps reliably in the real world. Think of an agent that can check flight times, book a seat, look up your order, or change a calendar—each of those is a tool call. The authors say the best way to make agents good at using many tools is to let them practice in many different, realistic “worlds.” They build a system called AgentScaler that creates lots of these practice worlds and trains agents on them.
The big questions the paper asks
- How can we create many different, high‑quality practice environments where an agent can safely learn to use tools?
- How can we train an agent from those practice experiences so it learns general tool-using skills (and also gets good in special areas like retail or airlines)?
How they did it (methods explained with simple ideas)
Imagine the agent’s world like a video game with a “world state” (what’s true right now). Tools are like apps the agent can use to read or change that world state.
- Read = checking information (like “What’s my next flight?”)
- Write = changing information (like “Book seat 12A”)
To scale up training, the authors do two big things:
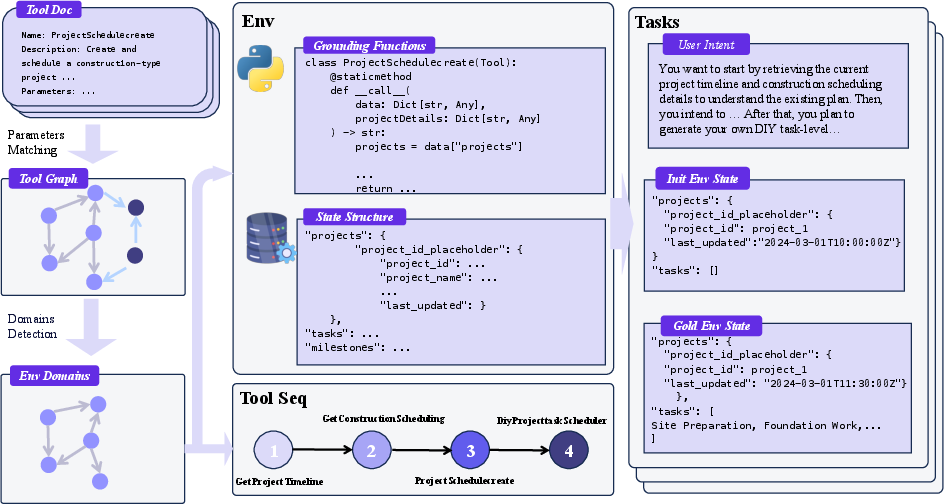
- Build lots of simulated environments automatically
They start with a huge collection of real-world APIs (think: instructions for how to talk to apps). Then they:
- Group similar tools into “domains” (like putting phone apps into folders: travel, shopping, telecom). They use a network method (Louvain community detection) to cluster tools that work well together.
- For each domain, they create a database that represents the world state (like a game save file).
- They turn each tool into runnable code that either reads from or writes to that database. Now tool calls have real, checkable effects.
- They generate practice tasks by sampling sensible sequences of tool uses (like “search flights -> choose flight -> book flight”), filling in arguments (dates, names, seats), and executing them to change the database. Because everything is simulated and grounded in a database, they can verify whether actions were correct.
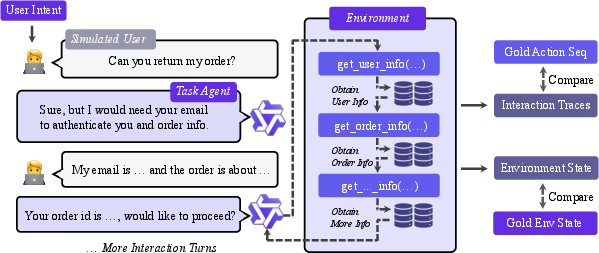
- Collect “agent experience” and train in two stages
They simulate a user with a goal (e.g., “I need to change my flight”), let the agent interact with the tools, and record the whole conversation plus tool calls. Then they filter the data carefully so only good, verifiable examples remain. Finally, they fine-tune the model in two steps:
- Stage 1: General training across many domains (learn the basics of when and how to use tools, and how to talk to users about the results).
- Stage 2: Specialize in a target domain (e.g., retail or airlines) so the agent gets extra good at one area.
A few helpful translations of terms:
- API: a standard way for software to talk to another app (like giving the agent a phone number and script so it can “call” an app).
- Environment/database: the “world” the agent can read and change.
- Tool call/function call: asking an app to do something with specific inputs.
- Verification: checking the database state and tool sequence to be sure the agent really did the right thing.
What they found (results) and why it matters
They trained several AgentScaler models (small to medium size) and tested them on well-known benchmarks that measure tool use:
- tau-bench and tau²-bench (customer-like tasks in retail, airline, telecom)
- ACEBench (broader tool-usage tests, including English and Chinese versions)
Key takeaways:
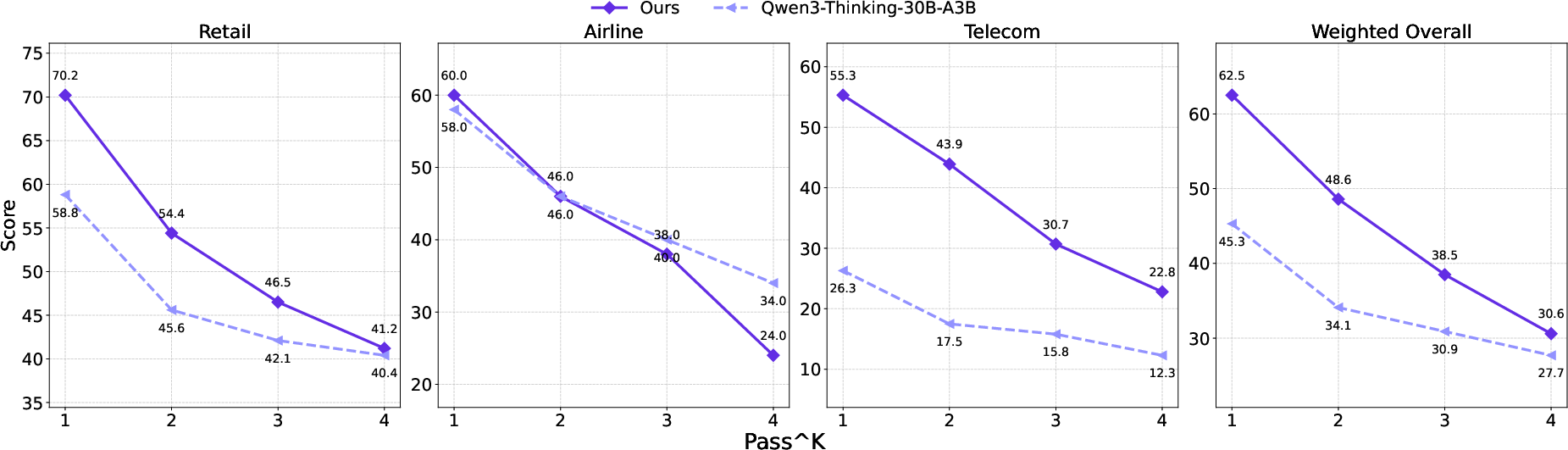
- Their models beat most other open-source models of similar or even much larger size. The 30B AgentScaler often performs close to very large or closed-source systems.
- Even a small 4B model learned strong tool-using skills after this training pipeline, which is impressive for such a compact model.
- The method generalizes well: performance stayed strong on out-of-distribution tests (like the Chinese ACEBench-zh), showing good robustness.
- Stability is better but still a challenge: as you ask the same question multiple times, consistency can drop across all models—so this is an open problem in the field.
- Long tool chains (many steps) are hard for everyone, including AgentScaler. Accuracy goes down as the number of tool calls grows. This highlights a key area to improve.
Why it’s important:
- It shows you don’t need a trillion-parameter model to get great tool-using agents—smart training in rich environments can make smaller models very capable.
- The pipeline is automatic and verifiable, making it practical to scale up training without tons of human labor.
What this could mean in the real world
If AI agents can reliably use tools across many domains, they can:
- Help with customer support (check orders, update accounts, fix issues)
- Plan travel (search flights, book seats, change reservations)
- Manage tasks (calendar updates, reminders, data lookups)
- Work faster and cheaper because smaller models can still perform well
The authors also point to future steps:
- Add reinforcement learning (letting the agent learn by trying actions and getting rewards) on top of these simulated environments.
- Expand to more domains and modalities (e.g., combining text with images or other inputs).
- Tackle long, multi-step tool sequences to make agents handle complex, real-world workflows even better.
In short: AgentScaler shows that building lots of realistic, checkable practice worlds and training in two smart stages can make AI agents much better at using tools—without needing gigantic models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Sim-to-real transfer: How well do skills learned in fully simulated, DB-grounded environments transfer to real APIs that are non-deterministic, rate-limited, versioned, and require authentication, streaming, or asynchronous handling?
- Real API execution: No evaluation with live MCP/OpenAPI endpoints. What is the degradation under real network latency, transient failures, pagination, throttling, and schema drift?
- Distributional shift: The simulator enforces deterministic state transitions; real systems exhibit partial observability, delayed consistency, side effects, and noisy responses. How to model and train for these properties?
- Safety and security: No analysis of prompt injection, tool misuse, data exfiltration, or malicious API responses within the environment. How to harden agents against adversarial tools and untrusted outputs?
- Transactionality and idempotency: The DB abstraction omits transactional semantics (rollback, idempotency keys) common in real APIs. How should agents reason about retries, compensating actions, and exactly-once effects?
- Asynchrony and events: Simulated calls are synchronous; real-world agents must handle callbacks, webhooks, streaming, and long-running jobs. How to extend the environment and training to event-driven workflows?
- Multi-modality: The pipeline focuses on text and DB operations. How to incorporate images, audio, UI actions, and web navigation in the same scalable, verifiable framework?
- Multi-agent coordination: No study of collaboration, delegation, or tool ownership across multiple agents. How to scale environments to multi-agent settings with shared state and role-based access?
- Tool-graph construction fidelity: Dependency edges are initiated by parameter-text cosine similarity and then LLM-audited. What is the precision/recall of edges, and how sensitive is performance to the threshold τ, embedding choice, and auditing quality?
- Cross-domain dependencies: Domains are disjoint communities; many real tasks span multiple domains (e.g., travel+payments+identity). How to represent and train cross-domain compositions and orchestration?
- Tool schema induction: The method for inducing domain DB schemas from tool parameters is under-specified. How to verify correctness, normalization, and minimality of schemas at scale, and how do schema choices affect agent learning?
- Programmatic materialization validity: “High degree of consistency” with τ-bench implementations is claimed via manual inspection; no quantitative code- or behavior-level agreement metrics are reported. How to automate unit/integration testing for generated tool code?
- Argument generation realism: Parameter generation for tool calls lacks explicit validation against real usage distributions and constraints. How to ensure realistic value ranges, entity consistency, and referential integrity?
- Sequence sampling bias: Tool sequences are sampled from the graph via directed walks; it is unclear if the sampling covers long-horizon, branching, and rare compositions. How to actively balance sequence length, difficulty, and coverage?
- Verifiability scope: Environment-level verification checks state equality and exact call sequences; it does not validate semantic equivalence when multiple tool plans are correct. How to design verifiers tolerant to plan diversity while remaining precise?
- Exact-match filtering brittleness: The strict sequence/argument exact-match filter likely discards alternative correct trajectories, biasing data toward canonical plans. Can relaxed or equivalence-class filters preserve diversity without harming supervision quality?
- Error handling and recovery: Although errorful trajectories are kept, there is no targeted training/evaluation of diagnosis, retry, backoff, or fallback strategies. How to measure and improve robust recovery behavior?
- Credit assignment and planning: The approach uses SFT only; no RL for long-horizon planning, tool budgeting, or non-myopic trade-offs. What RL formulations (e.g., environment rewards, curriculum) best improve multi-step tool chains?
- Long-horizon compositionality: The paper shows accuracy declines with more tool calls but proposes no concrete mitigations. Which methods (hierarchical planning, graph-constrained decoding, search, tool-belief states) actually bend this curve?
- Calibration and uncertainty: No evaluation of confidence estimation, abstention, or tool-call calibration. How to train calibrated agents that know when to call tools, when to stop, and when to ask for clarification?
- Memory and state summarization: The framework doesn’t study how memory mechanisms (summaries, scratchpads, slot-filling) help long dialogues with evolving environment state. Which memory strategies provide stable gains?
- Data scaling laws: No analysis of how performance scales with the number of environments, tools, trajectories, or sequence length. What are the data–model–compute scaling relationships specific to agentic tool use?
- Component ablations: Limited ablations on the environment pipeline. What is the marginal contribution of (i) LLM edge refinement, (ii) schema induction, (iii) each filtering stage, and (iv) error-trajectory retention?
- OOD generalization breadth: Evaluation covers τ/τ²/ACE and a single OOD (ACEBench-zh). How does the model perform on other multi-hop tool-use benchmarks (e.g., ToolHop) and entirely new domains/tools unseen in training?
- Fairness of baselines: Inference-time settings (tool budgets, temperatures, system prompts, “thinking” modes) across baselines are not standardized. How sensitive are results to these knobs, and what is a fair comparison protocol?
- Real-world cost and latency: The framework does not measure end-to-end costs (tool calls, tokens) or latency under practical constraints. How to optimize for resource-aware tool policies?
- Continual learning and tool churn: Real APIs change. How can the agent and environment handle tool additions/removals, versioning, and continual fine-tuning without catastrophic forgetting?
- API documentation grounding: Agents are trained on interactions, not on reading API docs at inference time. Would retrieval-augmented API doc grounding improve zero-shot tool adoption?
- Security of execution: Even if “fully simulated,” executing generated code can pose risks. What sandboxing, capability restrictions, and auditing are required for safe large-scale materialization?
- Data leakage risks: The simulator’s schemas and tools may overlap with evaluation designs (e.g., τ-bench) due to “high consistency.” How is leakage prevented, and what strict isolation protocols ensure clean evaluation?
- Reproducibility details: Key hyperparameters (graph thresholds, schema rules), dataset sizes after each filter, and environment-generation code are not fully specified. What exact settings are needed to reproduce results?
- Licensing and release: It’s unclear which APIs, tools, and environments (especially internal repositories) will be released and under what licenses, limiting community validation and extension.
- Multi-lingual and code-switching: Aside from ACEBench-zh, broader multilingual coverage, code-switching, and locale-specific tool behavior (date/time/currency formats) remain unexplored.
- Complex constraints and compliance: No modeling of compliance constraints (PII, KYC/AML, HIPAA/GDPR). How to encode and enforce policy constraints in planning and tool selection?
- Evaluation metrics: Reliance on pass@1/accuracy underplays user-centric metrics (task success under failure modes, satisfaction, safety violations). What richer, reliability-aware metrics should be adopted?
- Orchestration architectures: The work uses monolithic SFT; it does not explore specialized routers, tool planners, or modular controllers. Which architectures best leverage the scaled environments?
Collections
Sign up for free to add this paper to one or more collections.