Nex-N1: Agentic Models Trained via a Unified Ecosystem for Large-Scale Environment Construction
Abstract: The evolution of LLMs from passive responders to autonomous agents necessitates a fundamental shift in learning paradigms -- from static imitation to incentive-driven decision making. However, this transition is significantly impeded by the lack of scalable infrastructure capable of constructing high-quality interaction signals for effective policy learning. To address this, we introduce a comprehensive method designed to systematically scale the diversity and complexity of interactive environments. Our method realizes this scaling by addressing three orthogonal dimensions: (1) Complexity: NexAU, a flexible agent framework that supports building complex agent hierarchies via simple configurations; (2) Diversity: NexA4A automatically generates diverse agent hierarchies from natural language to cover infinite domains; and (3) Fidelity: NexGAP bridges the simulation-reality gap by integrating dynamic real-world environment for grounded trajectories synthesis. We train Nex-N1 upon the diverse and complex interactive environments established by our infrastructure. Empirical results on benchmarks such as SWE-bench and tau2 demonstrate that Nex-N1 consistently outperforms SOTA open-source models and achieves competitive performance against frontier proprietary models on complex agentic tasks. We open-source the Nex ecosystem and model weights to facilitate further research.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Nex-N1: Simple, Clear Summary for Teen Readers
What is this paper about?
This paper is about turning LLMs (AIs that read and write text) into useful “agents” that can plan, use tools, and complete real tasks—not just talk. The authors built a whole system to give these AIs realistic practice worlds, like training grounds, so they can learn how to act step by step, fix mistakes, and get things done. They then trained a model called Nex-N1 with these practice worlds and show it performs very well on tough benchmarks.
What goals or questions does the paper try to answer?
The paper focuses on three big goals:
- How do we help AI learn to act, not just talk? AIs are usually trained to guess the next word. That’s good for conversation, but it’s not enough for solving long, tricky tasks.
- Can we create lots of different, realistic practice environments so AI agents learn to plan, use tools (like APIs), and recover from errors?
- Does training with these environments actually make the AI better at real tasks—like writing code, using tools, browsing the web, and doing research?
How did they do it? The approach in everyday language
The authors built a “training ecosystem” with three main parts. Think of it like building a huge obstacle course for AI agents, where they can learn and improve through experience.
- NexAU (Agent Universe): This is the “game engine” where agents live and work. It lets you design agents easily, connect them to tools, and create teams of sub-agents (like a “boss agent” that delegates tasks to “worker agents”). It uses a think-then-act loop (called ReAct), so the agent looks at the situation, reasons, and then takes an action. It supports:
- Real tools via MCP (a standard way to connect to things like GitHub or databases)
- “Skills” (mini toolkits combining instructions, examples, and scripts)
- Memory and shared storage so agents can keep track of changing states (like files being edited)
- Simple configuration files (YAML), so you can define agents like writing a recipe, without heavy coding
- NexA4A (Agent for Agent): This automatically builds new agents and whole agent teams from plain-language descriptions. If you describe a project, NexA4A can design the workflow, set up roles, pick or create tools, and produce the full configuration. It’s like a factory that generates fresh, diverse agent setups on demand.
- NexGAP (General Agent-data Pipeline): This runs the agents in their environments and records their full “journeys” (called trajectories): the planning, tool calls, results, errors, and fixes. It:
- Uses real MCP tools to make environments feel like the real world (with delays, failures, and messy data)
- Synthesizes many different tasks in a controlled way (varying difficulty, user persona, and problem type)
- Normalizes data into different tool-call formats so it works across many frameworks
- Cleans and filters the data to remove junk like hallucinations, broken traces, or “reward hacking” (fake success)
To help you follow along, here are a few key terms explained in simple words:
- Agent: An AI that can plan and take actions, not just chat.
- Tool/API: A real-world function the agent can call (like searching the web or editing a file).
- MCP: A standard way for AI agents to connect to outside services reliably.
- Trajectory: The detailed record of the agent’s step-by-step thinking and actions during a task.
- ReAct loop: “Think, then act” repeated until the task is done.
- YAML: A simple text format for writing settings, like a recipe for building an agent.
What did they find? The main results and why they matter
The team trained their model, Nex-N1, on many diverse, realistic environments (over 200 agent frameworks, some with up to 34 connected agents, and seven different tool-call formats). Then they tested it on tough benchmarks:
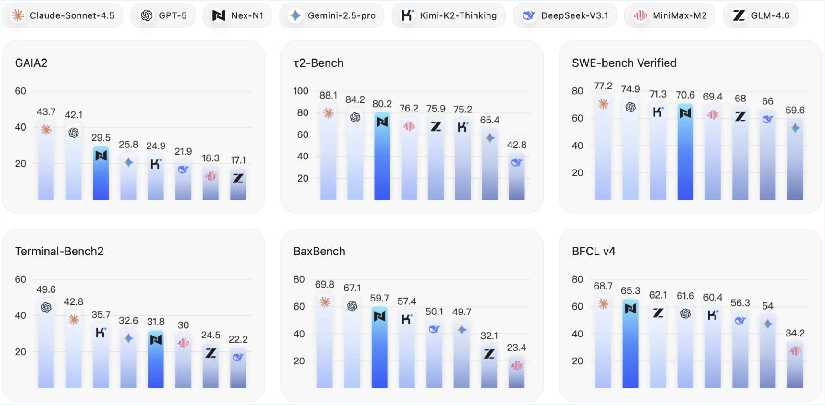
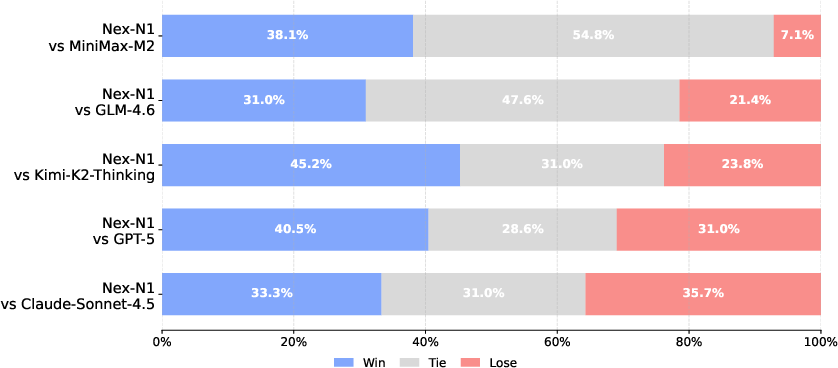
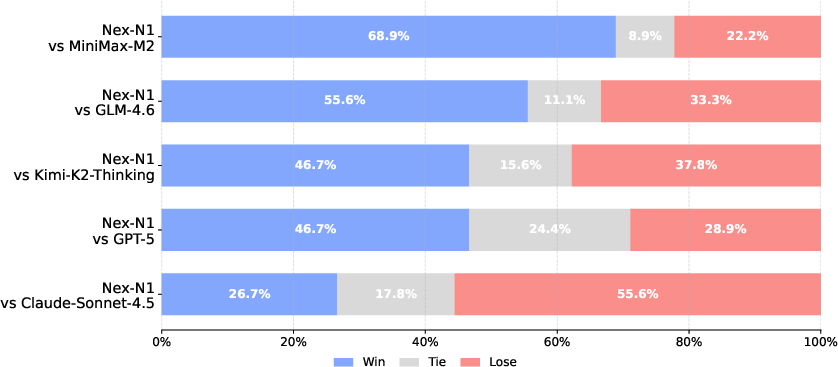
- Agent skills and tool use: On benchmarks like BFCL (function calling) and τ² (complex, dynamic tasks), Nex-N1 often beats strong open-source models and performs close to top proprietary models. In one tool-use test setup, the authors report their largest Nex-N1 variant even surpasses a leading closed model.
- Coding as an agent: On coding challenges like SWE-bench (fixing real GitHub issues) and Terminal Bench (working in a terminal), Nex-N1 shows competitive performance, including good reliability across different agent frameworks (like OpenHands and Claude Code).
- Real-world web and research tasks:
- Webpage creation: Human judges often preferred Nex-N1’s outputs over most baselines in visual quality and completeness.
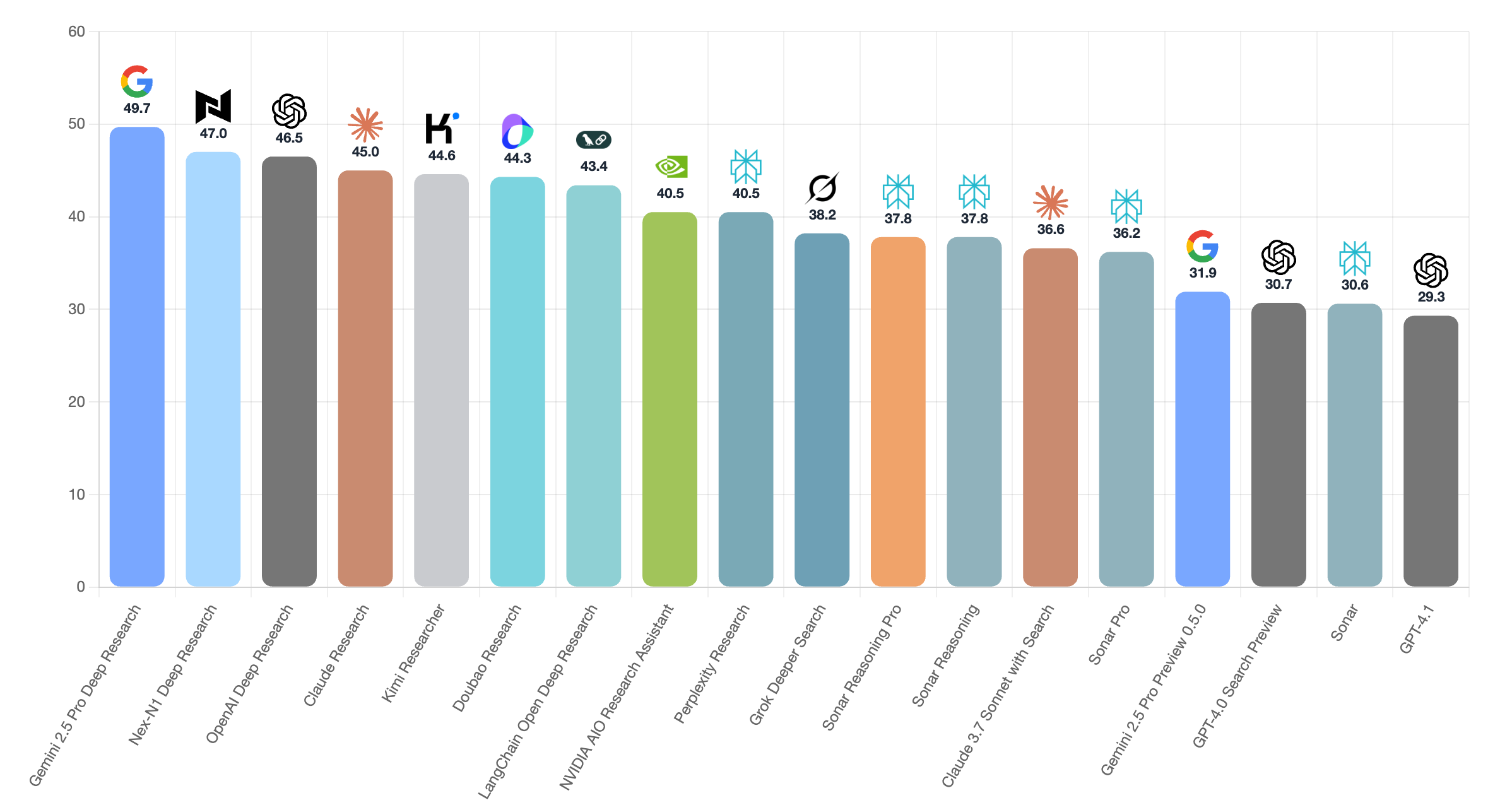
- Deep research: A Nex-N1-based research agent can search the web, extract information, plan multi-step tasks, and produce structured reports—plus create slides and visuals—not just text summaries.
Why this matters: Instead of just chatting, Nex-N1 shows it can operate as a capable agent—use tools, plan multi-step solutions, and handle errors—across many setups. This suggests the training ecosystem actually teaches the model to act in the real world.
Big picture: What’s the impact?
This work points to a practical way to train AI agents that can do real jobs:
- Build lots of varied, realistic practice environments.
- Let the agent interact for long stretches, face errors, and learn from feedback.
- Use standard connectors (MCP) so training matches real-world behavior.
- Automate environment creation so scaling up is affordable.
- Open-source the system so others can build, test, and improve.
The authors plan to evolve this into a large “gym” for reinforcement learning, where agents can keep practicing in harder, verifiable environments. If successful, this could make AI agents more trustworthy and useful for complex tasks like software development, data analysis, research, and interactive web work—moving AI from “what to say” toward “how to act.”
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions identified in the paper that future work could directly act on:
- Training transparency and reproducibility
- Absent details on Nex-N1 training recipe (model sizes per variant, optimizer, learning rate schedule, batch sizes, training tokens, sampling/temperature, context length, curriculum, objective mix SFT/RFT/RL), hindering reproducibility.
- No disclosure of data mixture composition and proportions (agentic trajectories vs. non-agent data; proportion of MCP-grounded vs. synthetic tools), preventing attribution of gains to specific data sources.
- Lack of ablations isolating contributions of NexAU vs. NexA4A vs. NexGAP (e.g., remove/replace one component to quantify its effect).
- No scaling-law analysis linking environment diversity/complexity to performance (e.g., performance vs. number of frameworks, recursion depth, tool formats).
- Data quality, filtering, and leakage controls
- Trajectory Quality Assessment Agent lacks calibration/validation: no agreement analysis against human judgments, precision/recall of error detection, or sensitivity to long-context truncation.
- Reward-hacking behaviors are reported in source data, but the post-training prevalence of such behaviors in Nex-N1 is not quantified or stress-tested.
- No benchmark contamination audit (e.g., SWE-bench, BFCL, GAIA2, τ2) against training corpora; no hash matching, prompt-template checks, or near-duplicate analysis.
- Query synthesis taxonomy coverage is not quantified (e.g., domain coverage heatmaps, long-tail underrepresentation, multilingual balance) and lacks public indices for independent auditing.
- Selection and cleaning criteria for curated MCP tools are not operationalized (e.g., acceptance tests, failure rates, rate-limit handling), limiting reproducibility of “production-ready” claims.
- Only a subset of training data is released; no release of detailed datasheets, sampling seeds, or environment specs to reproduce the training corpus.
- Evaluation methodology and comparability
- Benchmark modifications compromise comparability (e.g., replacing GAIA2 user-agent, switching BFCL web search from DDG to Google) without cross-checks against official harnesses or uncertainty intervals.
- No statistical significance testing or confidence intervals across benchmarks; single-run results without seed sweeps obscure variability.
- Human evaluations (43 coding, 45 web samples) lack rater protocol details (blinding, expertise, inter-rater reliability), adjudication rules, and error bars.
- Robustness across frameworks assessed on a 100-instance SWE-bench subset due to cost; no full-benchmark confirmation or standard-error reporting; several models omitted due to “technical constraints,” reducing comparability.
- Generalization to unseen tool-call protocols and zero-shot schema adaptation not systematically evaluated (e.g., entirely unseen argument schemas, error-code taxonomies, and serialization formats).
- Realism, grounding, and sim-to-real fidelity
- Real-world grounding is claimed via MCP, but no longitudinal evaluation under API drift, latency spikes, quota exhaustion, or schema versioning; no resilience tests to changing external services.
- No evaluation in live end-user workflows with real consequences (e.g., end-to-end CI/CD patches merged, production-grade database updates in a sandbox with audits).
- Lack of explicit error-recovery and self-repair benchmarks (e.g., induced tool faults, partial state corruption, network failures) to test robust reflection and retries.
- Safety, security, and privacy
- No security model for tool execution (sandboxing, permissioning, network/file-system isolation), secret handling (credentials, API keys), or data exfiltration guardrails.
- No red-teaming or safety evaluation on hazardous tool chains (e.g., shell, database, cloud admin APIs), prompt-injection handling, or supply-chain risk from third-party MCP tools.
- No discussion of privacy/TOS compliance for web retrieval and storage, or license provenance of curated tools and synthesized content.
- Agent architecture and reasoning depth
- Hierarchical recursion and state isolation are proposed, but no controlled experiments varying recursion depth, branching factor, or memory usage to quantify long-horizon reasoning limits.
- Memory mechanisms (GlobalStorage) are introduced without evaluations on tasks requiring persistent, cross-session memory or state reconciliation across sub-agents.
- No analysis of the trade-offs and failure modes of treating sub-agents as tools (e.g., error propagation, contract/spec mismatch, context misalignment).
- Generalization, transfer, and OOD robustness
- Limited evidence for cross-framework transfer beyond a few scaffolds; missing systematic tests on entirely novel orchestration paradigms and tool ecosystems.
- No test-time adaptation strategies (e.g., schema induction, tool discovery) or evaluation of meta-learning capabilities for new environments.
- Multilingual capabilities are hinted (bilingual taxonomy, poster generation) but not benchmarked for non-English agentic tasks or multilingual tool ecosystems.
- Multimodal aspects are used in supervision (visual feedback) but not evaluated for Nex-N1’s own multimodal tool use or perception-grounded planning.
- Cost, efficiency, and environmental impact
- Absent measurements of environment construction throughput, trajectory generation cost per task, and training/inference efficiency across frameworks.
- No profiling of context-token budget, message verbosity, and tool-return truncation strategies; unclear how efficiency constraints impact performance at scale.
- No disclosure of compute footprint and energy use; no cost–performance trade-off analysis for practitioners.
- Methodological choices and alternatives
- Despite emphasizing “incentive-driven decision making,” the work does not implement RL or online learning; open question: how to incorporate verifiable, incremental rewards across heterogeneous environments.
- Lack of objective verifiers or programmatic checks for many generated environments; unclear path to automatic ground-truth signals for complex, open-ended tasks.
- Insufficient comparison against alternative environment generators (e.g., program synthesis, simulator-based worlds, self-play curricula) and hybrid pipelines.
- Tooling and schema design
- No formal specification language or type system for tool schemas; absence of static checking and conformance tests to prevent schema drift and runtime failures.
- Error taxonomies and standardized recovery strategies for tool failures are not defined; no shared protocol for retries, backoff, or compensating actions across tools.
- Ethical and societal considerations
- No analysis of potential societal harms (e.g., automated misinformation through research agents, copyright risks in content generation, biased decision support).
- Lack of fairness/bias audits for synthesized queries, agent roles, and personas across demographic dimensions.
- Release artifacts and documentation
- Missing comprehensive documentation and executable recipes to reproduce all evaluations (prompts, seeds, agent graphs, tool lists, parameter settings).
- No public registry/index of the 200+ frameworks with metadata (domains, difficulty, tool dependencies) to enable targeted replication and extension.
These gaps point to actionable next steps: rigorous ablations and leakage audits, standardized benchmark protocols, safety/security hardening, cost and efficiency disclosure, formal tool/schema specifications, RL with verifiable rewards, and broader, statistically grounded evaluations across unseen environments, languages, and modalities.
Practical Applications
Immediate Applications
Below are deployable, concrete use cases that leverage NexAU (runtime), NexA4A (agent/framework synthesis), NexGAP (grounded data/trajectory pipeline), and the Nex-N1 model’s agentic capabilities.
Software/IT and DevOps
- Autonomous bug triage and patching for live repositories
- Workflow: Connect NexAU to GitHub via MCP; use Nex-N1 in OpenHands or Claude Code scaffolds to reproduce issues, generate patches, and validate with unit tests (SWE-bench-style).
- Potential product: RepoFixer (IDE plugin + CI integration).
- Assumptions/Dependencies: Reliable test suites; sandboxed execution; repo access tokens; human-in-the-loop code review; secure secrets management.
- CI/CD troubleshooting and terminal automation
- Workflow: Use Nex-N1 with Terminal Bench harness to diagnose failing pipelines, propose fixes, and execute commands within constrained environments.
- Potential product: Agentic CI Sentry (pipeline assistant).
- Assumptions/Dependencies: Isolated terminal sandboxes; RBAC and audit logs; guardrails to prevent destructive commands.
- Function-calling gateway for enterprise services
- Workflow: Standardize tool/function schemas (BFCL-format) and expose internal APIs via MCP; Nex-N1 orchestrates calls for search, data retrieval, and business processes.
- Potential product: FC Gateway (schema registry + agent router).
- Assumptions/Dependencies: Stable tool schemas; observability; rate limits; deterministic or well-documented error modes.
- Webpage and frontend generation
- Workflow: Agentic HTML/CSS/JS synthesis with visual QA; iterative repair based on binary feedback criteria (page completeness, color richness).
- Potential product: One-Page Builder (SMB website generator).
- Assumptions/Dependencies: Hosting, domain setup, and visual design acceptance; strict UX guardrails; anti-hallucination checks.
Research and Academia
- Deep research assistant producing text and visualized reports
- Workflow: NexDR agent (open-sourced) integrates Google Search, browsing/parsing, multi-step planning, and visual report/slide synthesis via sub-agent tools.
- Potential product: Deep Research Studio (report + presentation pipeline).
- Assumptions/Dependencies: Search API quotas; citation integrity; scraping permissions; trusted summarization with sources.
- Paper-to-poster generation (bilingual)
- Workflow: PDF-to-Markdown (MinerU), institution/conference logo retrieval, QR code generation; iterative layout refinement with feedback.
- Potential product: Paper2Poster (conference-ready posters with EN/ZH switching).
- Assumptions/Dependencies: High-fidelity PDF parsing; visual QA; institutional branding rules; final human review for aesthetics.
Finance and Business Intelligence
- Market intelligence and competitor analysis
- Workflow: Evidence-grounded data collection, clustering, synthesis, and executive brief generation with audit trails.
- Potential product: BI Research Agent (trend tracking + competitor dossiers).
- Assumptions/Dependencies: Licensed data sources; compliance with data usage; bias mitigation; confidence scoring.
- Backtesting and analytics coding assistant
- Workflow: Terminal-oriented code generation and execution for strategy prototyping; reproducibility and artifact logging.
- Potential product: QuantDev Copilot (research sandbox).
- Assumptions/Dependencies: Risk controls; isolation from production trading; reproducible datasets; strict governance.
Healthcare (non-clinical)
- Literature review and guideline synthesis
- Workflow: Search-enhanced synthesis, taxonomy-guided query generation; structured outputs for clinicians or medical ops teams.
- Potential product: MedResearch Assistant (evidence summaries).
- Assumptions/Dependencies: Access to PubMed/paid journals; strict disclaimers; human clinician oversight; no autonomous clinical decisions.
- Operational RPA-style tasks (appointments, reminders, data entry)
- Workflow: MCP integration with scheduling and CRM systems; YAML-defined workflows for repeatable processes.
- Potential product: HealthOps RPA Agent.
- Assumptions/Dependencies: HIPAA/PHI compliance; secure connectors; audit logging; fail-safe escalation.
Public Sector and Policy
- Evidence-based briefings with provenance
- Workflow: Multi-source retrieval; iterative reflection; structured citations; visual summaries for decision-makers.
- Potential product: Policy Brief Agent (transparency-first outputs).
- Assumptions/Dependencies: Public data provenance; FOIA alignment; bias audits; stakeholder review.
Education
- Lesson planning and interactive content generation
- Workflow: Persona- and difficulty-stratified query synthesis; web content generation and lightweight simulations; bilingual outputs.
- Potential product: Classroom Content Designer (teacher co-pilot).
- Assumptions/Dependencies: Curriculum alignment; accessibility standards; LMS integration; age-appropriate filters.
SMBs and Daily Life
- Personal research and planning assistant
- Workflow: Web-grounded information gathering and synthesis for travel, purchasing, and local services.
- Potential product: Daily Research Companion.
- Assumptions/Dependencies: API quotas; local data availability; preference learning; privacy controls.
- Simple business website and brochure creation
- Workflow: Single-page site generation with visual QA; static hosting deployment scripts as Skills.
- Potential product: MicroSite Starter.
- Assumptions/Dependencies: Hosting credentials; asset rights (images/fonts); human aesthetic approval.
Long-Term Applications
Below are applications that need further research, scaling, verification tooling, or regulatory alignment before broad deployment.
Cross-Domain Agent Platforms
- Large-scale reinforcement learning “Agent Gym”
- Concept: Evolve NexAU/NexA4A/NexGAP into a simulation platform with auto-generated, increasingly difficult, objectively verifiable environments for long-horizon decision-making.
- Potential product: Agent Gym (benchmarks + curriculum + verifiers).
- Assumptions/Dependencies: Robust reward design; formal verifiers; safety policies; significant compute and data governance.
- Multi-agent organizational orchestration
- Concept: Hierarchical, role-based “agent companies” coordinating complex projects with sub-agent isolation and memory; autonomous task decomposition, monitoring, and self-repair.
- Potential product: AgentOps Manager (mission control for agent orgs).
- Assumptions/Dependencies: Alignment strategies; escalation/override mechanisms; runaway behavior prevention; organizational ethics.
Robotics and Cyber-Physical Systems
- Real-world robotics control via MCP-like interfaces
- Concept: Bridge simulation–reality gaps and tool-latency modeling; integrate robot APIs for task planning and error recovery.
- Potential product: RoboMCP (hardware connectors + verification harness).
- Assumptions/Dependencies: Certified safety layers; hardware drivers; controlled environments; liability management.
Healthcare (clinical)
- Decision support integrated with EHRs and medical devices
- Concept: Evidence-grounded agents assisting clinicians with triage, guideline adherence, and documentation.
- Potential product: Clinical Copilot (EHR-native, verifiable recommendations).
- Assumptions/Dependencies: Regulatory approval (FDA/CE); rigorous clinical trials; explanation fidelity; clinician-in-the-loop; data privacy.
Energy and Industrial Automation
- Grid and plant operations optimization
- Concept: Agents interacting with SCADA/DCS systems to recommend actions under constraints; anomaly detection with tool-based remediation.
- Potential product: EnergyOps Agent (advice + guardrails).
- Assumptions/Dependencies: Safety-critical verification; secure network segmentation; fail-safe modes; regulatory compliance.
Finance (autonomous execution under governance)
- Compliant, auto-governed trading and risk monitoring
- Concept: Agents performing bounded execution with pre-trade checks and live risk controls; post-trade analytics with provenance.
- Potential product: Risk-Governed Trader (policy engine + agent).
- Assumptions/Dependencies: Regulatory alignment; robust guardrails; stress testing for black-swan events; auditability.
Education (immersive and lab-grade)
- Adaptive tutoring with realistic, verifiable lab environments
- Concept: Dynamic labs and interactive experiments, grounded in physics/chemistry rules with objective verifiers.
- Potential product: LabLearn (science labs as agentic environments).
- Assumptions/Dependencies: Domain verifiers; content safety; school IT support; accessibility considerations.
Governance, Standards, and Ecosystem
- Regulatory sandbox and benchmarking standards for agents
- Concept: Standard MCP tool kits, trace normalization, and auditing protocols; shared “agentability” metrics across sectors.
- Potential product: Agent Sandbox (policy-first testbed).
- Assumptions/Dependencies: Cross-industry standardization; public–private partnerships; transparency requirements.
- Secure MCP tool marketplace and agent QA auditor
- Concept: Curated, security-audited tool ecosystem; automated trajectory quality assessment for hallucinations, reward hacking, and tool misuse.
- Potential product: MCP Store + Agent Auditor (continuous compliance).
- Assumptions/Dependencies: Vendor trust frameworks; vulnerability disclosure processes; formalized quality taxonomy.
Cross-Cutting Assumptions and Dependencies
- Tool fidelity and availability: Many applications rely on high-quality MCP tools with documented latency and error modes; poor tool design reduces reliability.
- Safety and governance: Agent guardrails, RBAC, audit trails, and human-in-the-loop review are critical to prevent unsafe actions and reward hacking.
- Data access and licensing: Legal access to proprietary sources (finance, healthcare, academic publishers) is often required.
- Compute and costs: Large-scale trajectory generation, evaluation, and RL-style training demand substantial compute; budget and energy constraints apply.
- Interoperability: Cross-framework performance depends on consistent tool-call formats, schema registries, and adapters (OpenAI FC, XML variants).
- Privacy and compliance: Sectors such as healthcare and finance require strict adherence to data protection laws (HIPAA, GDPR, SOX), with robust observability and incident response.
Glossary
- AGI (Artificial General Intelligence): A goal of building systems with general, human-like intelligence. "The evolution of LLMs from passive information processors to autonomous Agents represents a fundamental shift in the pursuit of AGI"
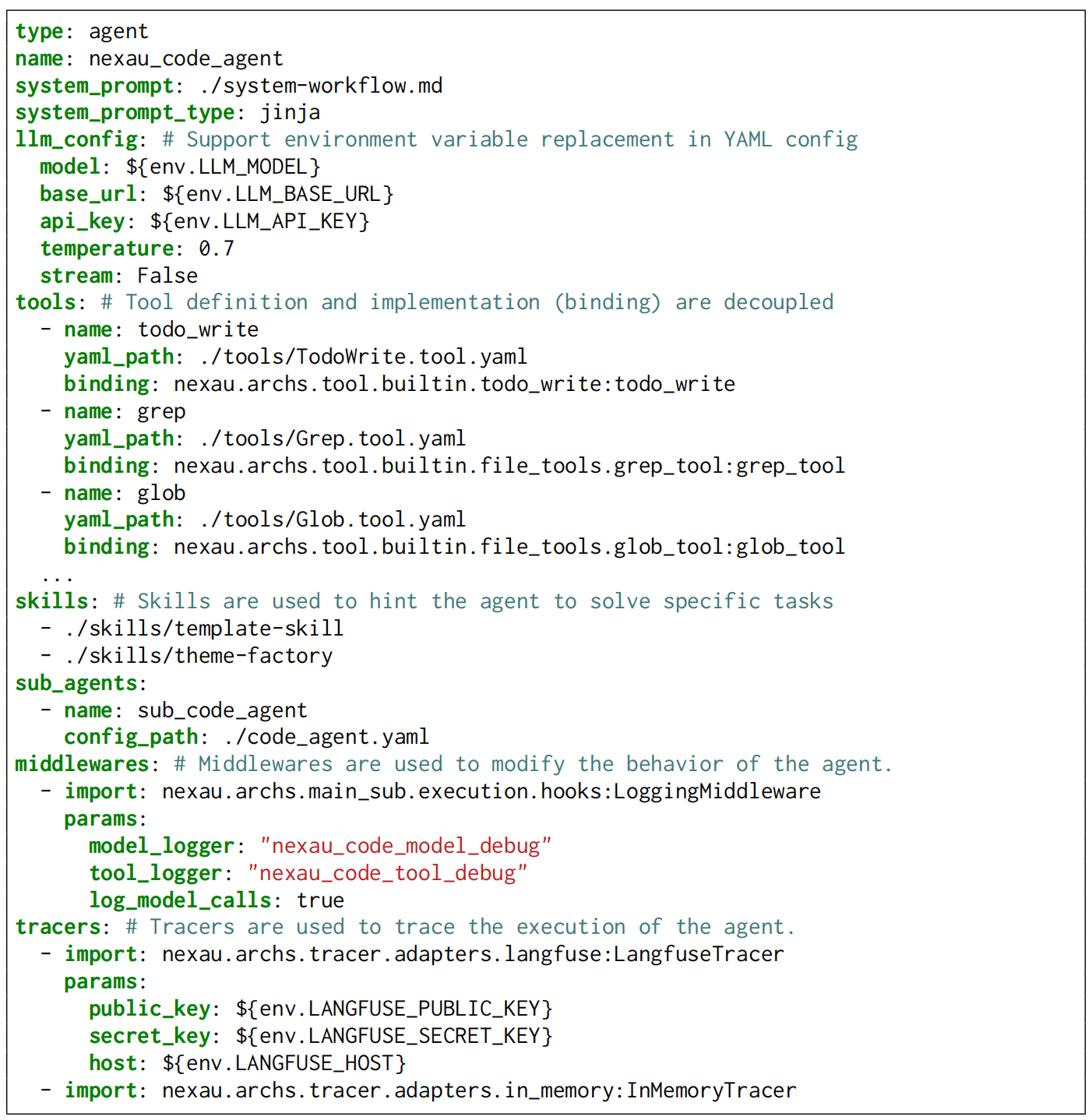
- Agent Universe (NexAU): A universal runtime framework that abstracts agent definition from execution to scale diverse, stable environments. "NexAU (Agent Universe), a universal agent framework that hides complexities of agent features (execution loop, tools, sub-agents, context management etc.) from agent builders."
- AgentBuilder: A component that programmatically assembles complete agent configurations from specifications. "produces a complete agent configuration via the AgentBuilder."
- Agentic coding: End-to-end software development tasks performed by autonomous LLM agents. "We evaluate the agentic coding ability of Nex-N1 on realistic software engineering tasks."
- Agentic execution loop: A standardized cycle where an agent perceives context, reasons, and acts, often in a ReAct-style loop. "At the core of NexAU is the standardized agentic execution loop."
- Agentic scaling: Systematically expanding the diversity, complexity, and realism of environments to improve agent capabilities. "we pursue an approach centered on agentic scaling."
- Agentic trajectories: Long, structured interaction traces generated by agents operating in environments with tools and feedback. "Agentic trajectories are significantly more challenging than standard post-training data due to their length and scenario diversity"
- BaxBench: A benchmark assessing backend application correctness in realistic development settings. "by evaluating its functional correctness on BaxBench~\citep{vero2025baxbench} using its official evaluation settings."
- BFCL V4 (Berkeley Function Calling Leaderboard V4): A benchmark assessing LLM function-calling and tool-use reliability. "We evaluate the LLM's ability to make function calls via the Berkeley Function Calling Leaderboard (BFCL) V4"
- Claude Code: An agent framework/environment for coding tasks used to evaluate agent robustness and performance. "within the Claude Code framework"
- Context window: The portion of conversation/state available to the model for reasoning at any given time. "A sub-agent's "Thought" trace does not pollute the parent's context window"
- Deep research agent: An autonomous system that performs multi-step research workflows including search, parsing, synthesis, and reporting. "Our Deep research agent has been open-sourced at https://github.com/nex-agi/NexDR"
- Declarative YAML configurations: Schema-based agent definitions that separate topology from implementation for automated synthesis. "Agents are defined via declarative YAML configurations"
- Dual-control environments: Interactive settings where agents must coordinate or satisfy constraints under shared or competing control. "collaboration in ``dual-control environments''"
- FrameworkBuilder: A component that constructs multi-agent framework configurations from high-level descriptions. "using a component called FrameworkBuilder."
- Fractal architecture: A recursively composable design where agents, sub-agents, and tools are interchangeable functional units. "adopts a recursive, fractal architecture inspired by the ReAct paradigm"
- Function Call (FC) format: A standardized format for function/tool invocation used in BFCL evaluation. "All evaluations on Nex-N1 follow the BFCL Function Call (FC) format."
- GAIA 2: A benchmark providing broad assessment of end-to-end agent performance. "GAIA 2 provides a broad assessment of end-to-end agent performance."
- GlobalStorage: A thread-safe mechanism to persist and share state across agents and tools during recursive execution. "NexAU provides a thread-safe GlobalStorage mechanism."
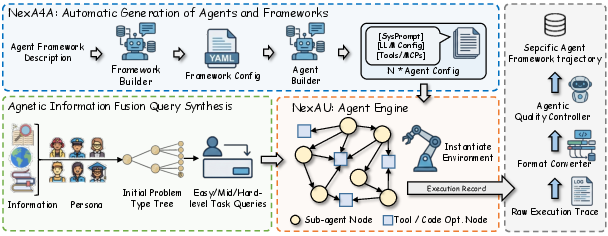
- Grounded trajectories: Interaction traces rooted in real-world execution that capture latency and error dynamics. "NexGAP bridges the simulation–reality gap by integrating dynamic real-world environment for grounded trajectories synthesis."
- Hierarchical decomposition: Breaking complex tasks into sub-tasks across agent layers to enable planning and execution. "expose models to the full range of behaviors needed for complex task solving: hierarchical decomposition, planning, tool-enabled problem solving, and iterative refinement based on environment feedback."
- Information Fusion Query Synthesis: A process that combines capabilities and context to generate diverse, difficulty-stratified tasks. "we apply Information Fusion Query Synthesis to generate tasks of varying difficulty tailored to that framework."
- Interaction topologies: Structured patterns of agent, sub-agent, and tool interactions within an environment. "creating a diverse distribution of "interaction topologies" for the model to learn."
- Inverse-frequency weighted strategy: A sampling method that boosts underrepresented categories to reduce bias. "we adopt an inverse-frequency weighted strategy that increases sampling probabilities for underrepresented categories."
- Long-horizon reasoning: Planning and decision-making over extended sequences of actions and feedback. "master long-horizon reasoning through active exploration and direct environmental feedback."
- MCP (Model Context Protocol): A standardized protocol connecting agents to live external tools and servers. "Model Context Protocol (MCP) tools"
- MetaAgent: A coordinating agent that interprets framework descriptions and assembles multi-agent systems. "A central MetaAgent interprets a high-level description of the target framework"
- Meta-skills: Higher-level capabilities mapped to sets of executable actions via sub-agents, tools, or MCPs. "Each generated agent is defined by a system prompt outlining its role and meta-skills, where each meta-skill corresponds to a set of actions implemented through NexAU components"
- Multi-agent orchestration: A design that coordinates multiple specialized agents for query synthesis and enhancement. "The framework uses a multi-agent orchestration design composed of: (1) a rewriting agent ..."
- Myopic decision-making: Short-sighted action selection that ignores long-term goals or consequences. "models succumb to probability traps and myopic decision-making"
- NexA4A: A generative system that automatically synthesizes agents and frameworks from natural-language specifications. "We introduce NexA4A (Agent for Agent), a system that generates agents as well as the entire agent frameworks from natural-language specifications."
- NexAU: A modular, high-throughput runtime that unifies diverse agent frameworks under a single execution model. "So we introduce NexAU (Nex Agent Universe), a lightweight, high-throughput runtime that decouples agent definition from agent execution."
- NexGAP: An end-to-end pipeline for generating realistic agentic trajectories across heterogeneous formats. "we introduce NexGAP (General Agent-data Pipeline) to generate end-to-end agentic trajectories"
- OpenHands: An open-source agent scaffold/environment used for coding and terminal task evaluations. "an internal implementation based on the OpenHands~\citep{wang2024openhands} scaffold"
- Problem Type Tree: A hierarchical, bilingual taxonomy guiding query generation across structured categories. "The framework uses a Problem Type Tree— a hierarchical, bilingually annotated taxonomy"
- Quality Assessment Agent: An automated judge that identifies issues in long agent trajectories for scalable filtering. "motivating the use of Quality Assessment Agent for scalable assessment."
- ReAct paradigm: A method where agents alternate reasoning and acting steps to solve tasks with tools. "inspired by the ReAct paradigm \cite{yao2023react}"
- Reward hacking: Exploiting loopholes in evaluation or reward signals to appear successful without truly solving tasks. "and widespread reward hacking in coding agents"
- Simulation–reality gap: The discrepancy between synthetic simulations and real-world execution dynamics. "NexGAP bridges the simulation–reality gap"
- Skills (Claude Skills): Self-contained packages with prompts, examples, and scripts injected as procedural knowledge. "NexAU supports Skills—self-contained directories containing specialized prompts, few-shot examples, and executable scripts (similar to Claude Skills~\cite{claude_skills})."
- Stratified queries: Queries organized by difficulty levels to ensure coverage and diversity. "generates stratified queries by difficulty"
- SWE-bench: A benchmark where agents fix real GitHub issues by producing patches verified via unit tests. "The SWE-bench~\citep{jimenez2024swebench} is built from real GitHub issues and their associated pull requests"
- Terminal Bench 2: A benchmark measuring end-to-end terminal task execution by agents. "Terminal Bench 2"
- Terminus-2: An agent framework/environment included in the Terminal Bench Harness for cross-framework evaluation. "including OpenHands~\citep{wang2024openhands}, Claude Code, and Terminus-2~\citep{tbench_2025}"
- Tool-call formats: Standardized schemas for representing tool invocations across different ecosystems. "The resulting trajectories cover seven distinct tool-call formats"
- -bench: A benchmark testing agent constraint satisfaction and collaboration in dual-control settings. "We evaluate the general agentic ability of Nex-N1 on -bench~\citep{barres2025tau2}"
Collections
Sign up for free to add this paper to one or more collections.

