AgentEvolver: Towards Efficient Self-Evolving Agent System
Abstract: Autonomous agents powered by LLMs have the potential to significantly enhance human productivity by reasoning, using tools, and executing complex tasks in diverse environments. However, current approaches to developing such agents remain costly and inefficient, as they typically require manually constructed task datasets and reinforcement learning (RL) pipelines with extensive random exploration. These limitations lead to prohibitively high data-construction costs, low exploration efficiency, and poor sample utilization. To address these challenges, we present AgentEvolver, a self-evolving agent system that leverages the semantic understanding and reasoning capabilities of LLMs to drive autonomous agent learning. AgentEvolver introduces three synergistic mechanisms: (i) self-questioning, which enables curiosity-driven task generation in novel environments, reducing dependence on handcrafted datasets; (ii) self-navigating, which improves exploration efficiency through experience reuse and hybrid policy guidance; and (iii) self-attributing, which enhances sample efficiency by assigning differentiated rewards to trajectory states and actions based on their contribution. By integrating these mechanisms into a unified framework, AgentEvolver enables scalable, cost-effective, and continual improvement of agent capabilities. Preliminary experiments indicate that AgentEvolver achieves more efficient exploration, better sample utilization, and faster adaptation compared to traditional RL-based baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces AgentEvolver, a new way to train smart computer “agents” that use LLMs. Think of an agent as a helpful digital assistant that can read, think, use tools (like apps or APIs), and carry out multi-step tasks. The main idea is to let the agent teach itself and get better over time—without needing humans to handcraft lots of training tasks or rely on slow, random trial-and-error.
Key Objectives and Questions
The paper asks: How can we help an LLM-powered agent learn efficiently in new, complex environments when we don’t know the tasks or the scoring rules ahead of time?
To answer that, the authors focus on:
- Making the agent generate its own practice tasks (instead of humans writing them).
- Guiding the agent’s exploration so it doesn’t waste time repeating mistakes.
- Giving the agent better feedback by judging which steps helped and which didn’t.
How They Did It (Methods)
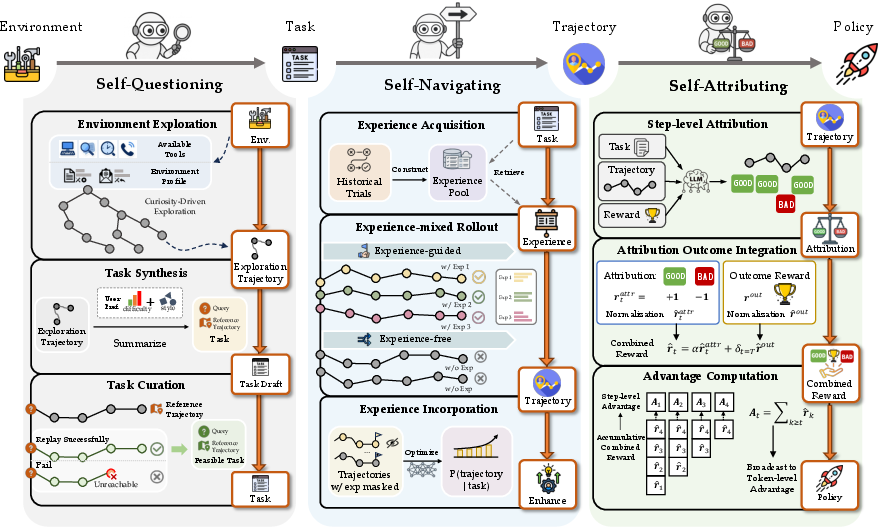
The big idea is to shift from human-built training pipelines to agent-driven self-improvement. Instead of a teacher giving homework and grades, the student (the agent) creates practice questions, studies past attempts, and fairly judges its own work. The framework has three main parts that work together:
Before the three parts, here’s the setup:
- Environment sandbox: Imagine a game world that defines what the agent can see and do, and how the world changes after each action—but it doesn’t tell you what the “right” goal is or give points. The agent must figure out useful goals and how to score itself.
- Proxy tasks and rewards: Since the real tasks and scoring rules are unknown, the agent invents practice tasks and creates its own feedback signals. The hope is that getting better on these smartly chosen practice tasks will also make the agent good at the real tasks later.
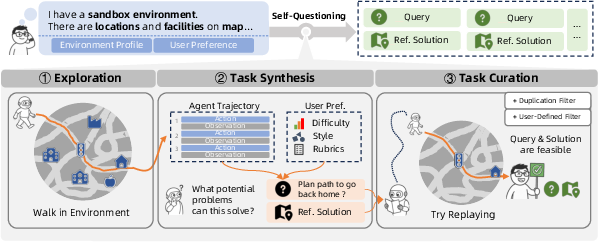
Self-questioning: Curiosity-driven task generation
Analogy: A curious student exploring a new school, noting interesting places, and turning discoveries into practice questions.
What it does:
- The agent explores the environment using “environment profiles”—short, structured descriptions of what exists and what actions are possible (like a map of buildings and roads, and the actions “move,” “enter,” “wait and cross”).
- It uses a “high-temperature” LLM (which makes it try more diverse ideas) to wander broadly, then dig deeper into promising areas. This is like starting wide (breadth-first) and then focusing (depth-first).
- From the explored paths, the agent creates tasks that match user preferences (for example, choosing easy vs. hard tasks or specific styles).
- It extracts trustworthy “reference solutions” from its own earlier successful explorations. These are like answer keys that help check whether future attempts are correct.
- It filters out duplicate, low-quality, or impossible tasks using both quick checks (text overlap) and deeper checks (semantic similarity and actual execution tests).
Why this helps:
- The agent no longer depends on expensive, handcrafted datasets.
- Tasks are diverse, aligned with user needs, and come with reliable solutions for judging success.
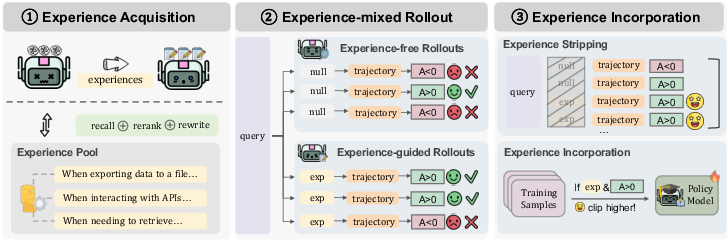
Self-navigating: Experience-guided exploration
Analogy: A student keeps a notebook of helpful tips learned from past success and failure, then uses those tips to plan smarter next steps.
What it does:
- Builds an “experience pool” from previous rollouts (attempts), recording short natural-language lessons like “When you’re not sure if an API exists, check its docs first.”
- Retrieves the most relevant experiences for a new task using embeddings (vector representations) and similarity, then refines them to fit the current context.
- Mixes two kinds of rollouts:
- Vanilla rollouts: Free exploration with no extra hints.
- Experience-guided rollouts: The agent gets a small, retrieved tip to steer its behavior.
- During training, it strips those experience tips out of the input (so the agent doesn’t just memorize the tip text) and adjusts the training math (“selective boosting”) to make sure helpful, experience-guided attempts have a proper impact on learning.
Why this helps:
- The agent learns faster by reusing hard-won knowledge, while still exploring new paths.
- It avoids over-relying on external hints and truly improves its internal decision-making.
Self-attributing: Fine-grained credit assignment
Analogy: A coach doesn’t just say “You won or lost.” They go through each play and note which moves helped, which hurt, and why.
What it does:
- Instead of giving one score for the whole attempt (which treats all steps equally), the agent uses an LLM to judge each step’s contribution:
- Process quality: Did this step move the solution forward or waste time?
- Outcome effectiveness: Did the overall attempt succeed, partly succeed, or fail?
- It standardizes these signals and combines them into per-step feedback, then maps that into a learning signal the agent can use during optimization.
- This creates much richer feedback for long, multi-step tasks.
Why this helps:
- The agent can learn from fewer attempts because it knows exactly which decisions were useful.
- It avoids the common problem where only final success/failure is rewarded, which can hide important lessons.
Practical Infrastructure
To make all this usable:
- Standard interfaces connect to different environments (apps, browsers, APIs).
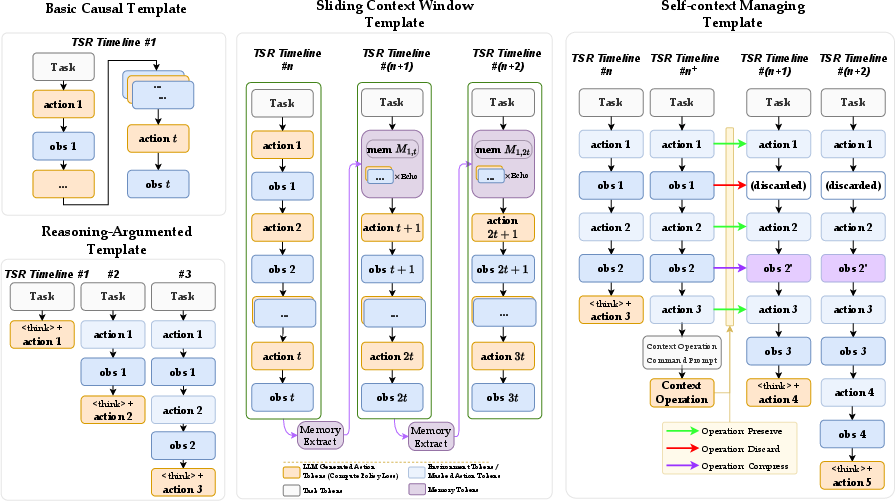
- A Context Manager handles multi-turn interactions consistently.
- It integrates with RL training tools (like veRL), and the architecture is modular, so developers can swap or upgrade parts.
Main Findings and Why They Matter
Early experiments show that AgentEvolver:
- Explores more efficiently (tries smarter, not just more).
- Uses samples better (learns more from each attempt).
- Adapts faster to new environments compared to traditional RL setups that rely on many random rollouts.
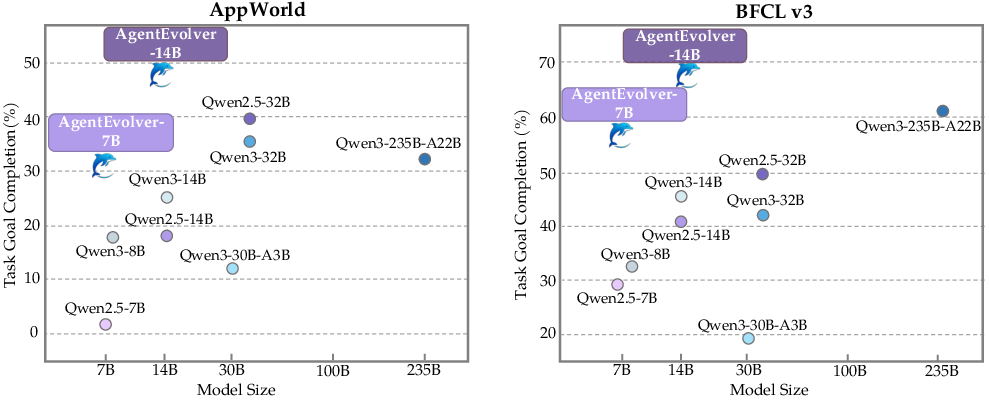
- On benchmarks like AppWorld and BFCL-v3, it reached strong performance while using fewer model parameters than larger baselines.
Why this matters:
- Training LLM agents can be very costly. Lowering the need for massive datasets and random exploration makes development more practical.
- Better per-step feedback leads to more stable, reliable training for complex, tool-using agents.
Implications and Potential Impact
If agents can create their own training tasks, navigate using past lessons, and judge each step fairly, they can:
- Continuously improve with minimal human effort.
- Adapt to new apps, tools, and environments quickly.
- Make smarter use of limited compute and data budgets.
This approach could help build more capable, cost-effective digital assistants for productivity tasks, software operations, research aids, and beyond. In short, AgentEvolver points toward a future where AI agents act more like self-driven learners—curious, reflective, and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up by future researchers.
- Theoretical guarantees: No formal conditions or proofs are provided that optimizing the proxy objective (via and ) improves the true target objective ; derive sufficient conditions (e.g., task distribution divergence bounds, reward calibration guarantees) under which .
- Formalization clarity: Multiple equations (e.g., definitions for , , ) exhibit syntactic issues and incomplete notation; supply precise, verifiable mathematical definitions and assumptions (stochasticity, stationarity, measurability) to avoid ambiguity in implementation and analysis.
- Environment profiles acquisition: How profiles are created (manual vs automated), updated, and validated is unspecified; develop automated profile induction from raw interaction logs, with metrics for coverage, accuracy, granularity, and cost.
- Safety and constraints in exploration: High-temperature LLM-driven exploration may trigger unsafe or irreversible actions (e.g., deletion/modification APIs); design constraint-aware exploration and safety guards (policy shields, sandboxing, reversible operations, constraint programming).
- Cost and compute efficiency: The paper asserts improved efficiency but lacks transparent accounting of compute, API/tool costs, and wall-clock time versus PPO/GRPO; report cost breakdowns, scaling curves, and efficiency metrics (reward per dollar, success per GPU-hour).
- Preference modeling: User preference representation, elicitation, and conflict resolution (difficulty/style constraints) are not defined; study principled preference models, dynamic preference updates, multi-user aggregation, and their effects on task synthesis.
- Task synthesis diversity vs deduplication: The lexical/semantic filtering thresholds and their impact on task diversity, novelty, and difficulty distribution are not evaluated; quantify trade-offs and develop adaptive dedup strategies that preserve diversity.
- Reference solution correctness: Reference solutions extracted via LLM may be incorrect or non-unique; create formal equivalence checking (semantic diff, partial-order plans, program verification) and handle nondeterministic or multi-solution tasks robustly.
- Feasibility checking robustness: The environment-based replay of reference solutions may yield false negatives in partially observable or stochastic environments; add probabilistic feasibility tests, multiple replays, and variance-aware acceptance criteria.
- LLM judge calibration and bias: The judge’s scoring (relevance/repetition checks, continuous scoring) is heuristic; evaluate inter-judge agreement, domain transferability, calibration to human gold standards, and susceptibility to reward hacking.
- Attribution reliability: Step-wise LLM attribution for credit assignment lacks validation; measure attribution accuracy against human annotators, test-time robustness, and impact on downstream policy updates, including error propagation from misattribution.
- Token-level advantage mapping: The paper does not detail how step-level attributions are mapped to token-level advantages; specify algorithms (e.g., per-token credit allocation over actions/tool calls) and evaluate sensitivity.
- Off-policy mismatch in experience stripping: Removing experience tokens during optimization introduces distribution shift; quantify the bias, propose corrective importance sampling or KL-regularization to reduce instability.
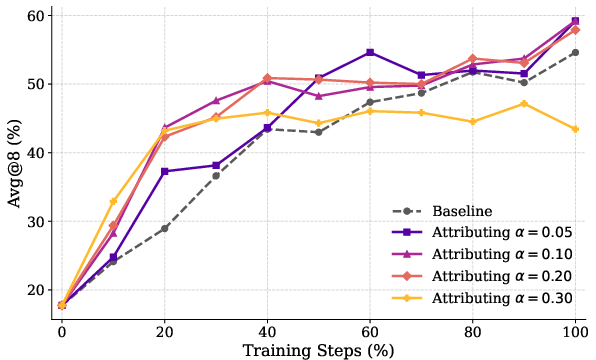
- Selective boosting stability: Raising clipping thresholds for positive-advantage samples may destabilize training; provide convergence analyses, ablations over , and safeguards (adaptive clipping, trust region bounds).
- Experience contamination: The experience pool can accumulate noisy, spurious, or outdated experiences; implement and evaluate experience curation, decay, contradiction resolution, and provenance tracking.
- Retrieval quality: Top-k embedding-based retrieval and rewriting may inject irrelevant guidance; assess retrieval precision/recall, latency, and rewriting fidelity, and compare learned retrievers vs static embeddings.
- Scheduling of experience-mixed rollout: The mixing ratio is fixed; study adaptive schedules (bandit controllers, curriculum learning) that tune by uncertainty, task difficulty, or learning progress.
- Cold-start bias: Experience pool construction with an initial weak policy may encode suboptimal patterns; explore bootstrapping via synthetic optimal traces, expert demonstrations, or model-based planning to mitigate bias.
- Catastrophic forgetting: Continual integration of new tasks/experiences may erode prior capabilities; add retention mechanisms (regularization, rehearsal buffers, modular heads) and evaluate backward transfer.
- Distributional hybrid tuning: The mixing parameter between proxy and target tasks is not analyzed; develop methods to learn online (e.g., via performance signals) and assess sensitivity to distribution shift.
- Robustness to adversarial or spurious tasks: Self-questioning could generate adversarial or unproductive tasks; incorporate anomaly detection, adversarial filters, and metrics that penalize low-learning-value tasks.
- Long-horizon evaluation: The LLM judge and attribution approach may under-evaluate deferred outcomes; add temporal credit tests (delayed rewards, subgoal tracking, hierarchical evaluation) and measure performance on long-horizon tasks explicitly.
- Reward hacking risks: Agents may over-optimize the judge’s heuristics; design anti-gaming strategies (disagreement-based ensembles, randomized audits, programmatic checks) and benchmark robustness.
- Generalization across environments: Claims are based on AppWorld and BFCL-v3; broaden benchmarks (more tool-rich, real-world, partially observable, stochastic) and report cross-domain generalization and failure modes.
- Baseline comparability: “Traditional RL-based baselines” are not defined; include strong recent baselines (model-based agents, planning+tool-use hybrids, retrieval-augmented RL) with matched training budgets and standardized metrics.
- Hyperparameter sensitivity: Key settings (temperature, , , , , clipping thresholds) are not systematically studied; run sensitivity analyses and provide recommended defaults per environment class.
- Scaling laws: The system’s performance scaling with model size, dataset size, and interaction budget is unreported; characterize scaling curves and diminishing returns to guide practical deployments.
- Privacy and compliance: Experience logs and environment interactions may include sensitive data; define anonymization, access controls, and compliance auditing, and assess the impact on retrieval quality.
- Safety alignment of task generation: Self-questioning may produce harmful tasks; add policy-level safety filters, red-teaming evaluations, and safe preference constraints.
- Multi-agent extensions: The framework focuses on a single agent; explore collaborative self-questioning/self-navigating, shared experience pools, and coordination mechanisms.
- Reproducibility: Implementation details (prompts, thresholds, embeddings, infrastructure configs) and code/data availability are not specified; release artifacts and detailed protocols to enable replication.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage AgentEvolver’s mechanisms (self-questioning, self-navigating, self-attributing) and infrastructure to improve efficiency, reduce data-construction costs, and accelerate agent adaptation in digital environments.
- Auto-onboarding LLM agents to new SaaS tools and internal apps (software/IT) — Use self-questioning with environment profiles to discover supported operations, generate tasks and reference solutions, and bootstrap policies without manual datasets; integrate via standardized interfaces and context manager, with veRL-backed optimization. — Potential product/workflow: “AgentEvolver SDK” plus an “Environment Profile Authoring Tool” that ingests app docs/UIs, synthesizes tasks, and runs feasibility checks; deployable as an internal service to rapidly acclimate agents to CRM, ERP, ITSM, or analytics platforms. — Assumptions/dependencies: reliable API/DOM instrumentation; sandboxed environments; an LLM with strong tool-use reasoning; compute for rollouts; guardrails to prevent unsafe actions.
- Continuous end-to-end QA and regression testing for software (software/QA) — Self-questioning generates diverse, preference-controlled tasks; reference-based LLM judge provides automatic scoring; self-attributing yields step-wise credit to pinpoint fragile steps. — Potential product/workflow: CI/CD plugin that autogenerates tests from live UIs/APIs and scores them, surfacing actionable traces for developers. — Assumptions/dependencies: deterministic test environments or robust flakiness handling; accurate reference solution extraction; acceptance criteria alignment.
- Synthetic task/data generation for agent training at reduced cost (software/research) — Replace handcrafted datasets with curiosity-driven exploration and adaptive task synthesis; curate tasks via lexical/semantic dedup and executability checks; optional hybrid data mixing with any target distribution. — Potential tool: “Task Synthesis Service” that outputs high-diversity, difficulty-controlled tasks and proxy rewards for agent finetuning. — Assumptions/dependencies: consistent task curation thresholds; embedding-based semantic similarity quality; coverage balance to avoid overly narrow curricula.
- Experience-reuse to stabilize and accelerate agent learning (software/automation) — Self-navigating builds and retrieves an experience pool (vector store) with “When to use” and “Content”; experience-mixed rollouts balance exploration/exploitation; experience stripping and selective boosting improve policy learning without overfitting. — Potential tool: “Experience Memory Layer” that can be mounted to any agent, with retrieval and rewrite modules (e.g., using ReMe). — Assumptions/dependencies: high-quality experience extraction and validation; effective similarity metrics; prompt templates that preserve relevance while avoiding leakage.
- Autonomous workflow discovery and documentation (enterprise operations) — Agents explore apps to infer latent workflows and produce validated reference solutions and “operational playbooks.” — Potential product/workflow: “Workflow Miner” that outputs step-by-step SOPs, risk flags, and executable recipes for routine processes (e.g., data pulls, report generation). — Assumptions/dependencies: sufficient environment observability; permissions and governance for data access; human review loop for critical workflows.
- Targeted reward shaping for long-horizon tasks (software/RL training) — Self-attributing yields fine-grained, token-mapped advantages to distinguish impactful steps from neutral ones, improving sample efficiency compared to GRPO-style uniform credit. — Potential workflow: RL training pipelines that switch to contribution-based attribution for complex tool-use tasks. — Assumptions/dependencies: robust attribution prompts; reliable separation of process vs outcome signals; careful standardization to prevent reward hacking.
- Internal benchmarking and evaluation harness for LLM agents (academia/industry) — Reference-based LLM judge and curated tasks facilitate reproducible agent evaluation in AppWorld-like environments. — Potential product/workflow: “Agent Evaluation Harness” that standardizes scoring, logs, and experience reuse for research and applied teams. — Assumptions/dependencies: reference coverage of critical steps; calibration of continuous scoring; audit trails.
- Customer support and back-office automation with safer exploration (customer service/finance) — Agents learn tool use (ticketing, billing, reconciliation) in sandboxed replicas using self-questioning and self-navigating before promotion to production workflows. — Potential workflow: “Staging-first Agent Training” that requires successful task completion and quality scores prior to limited-scope deployment. — Assumptions/dependencies: high-fidelity sandboxes; data masking/privacy; tiered access policies; human-in-the-loop sign-offs.
- Personalized productivity assistants that adapt to individual apps (daily life/software) — Agents explore personal calendar/email/notes/spreadsheets to discover user-specific workflows and generate bespoke tasks and reference solutions (e.g., recurring meeting setups, file organization). — Potential product: desktop/mobile “Self-Evolving Personal Agent” with environment profile support for common apps. — Assumptions/dependencies: local sandboxing; explicit user permissions; privacy-preserving logging; controllable exploration limits.
- Education/coding practice environments with auto-generated curricula (education/software) — Difficulty- and style-controlled task synthesis, plus reference-based judging, provide graded exercises for coding, data analysis, or math tool use. — Potential product/workflow: “Adaptive Practice Generator” (IDE plugin or web platform) with step-level feedback via self-attributing. — Assumptions/dependencies: accurate difficulty scaling; domain-aligned rubrics; anti-hallucination curation.
Long-Term Applications
Below are use cases that will benefit from further research, scaling, integration, or regulatory development before broad deployment.
- Cross-app autonomous enterprise process discovery and optimization (enterprise software) — Agents self-evolve across heterogeneous tool chains (CRM, ERP, data warehouses), discover end-to-end workflows, and optimize for cost/time/quality. — Potential product: “Autonomous Ops Orchestrator” that continuously mines processes, updates SOPs, and proposes improvements. — Assumptions/dependencies: standardized environment profiles across vendors; inter-app identity and access management; robust safety and rollback; change-management policies.
- Agent-ready API standards and “environment profile” schemas (software/platforms) — Tool vendors publish AgentEvolver-compatible profiles to make their apps self-explorable and safely operable by agents. — Potential outcome: an “Agent Profile Spec” ecosystem, SDKs for instrumentation, and certification programs. — Assumptions/dependencies: community and vendor adoption; interoperability testing; backward compatibility; security controls.
- Robotics: self-evolving embodied agents in homes and factories (robotics/industrial) — Extend mechanisms to multimodal perception and physical actions, enabling curiosity-driven discovery and step-wise attribution in the real world. — Potential products: “Adaptive Robot Learner” for new tasks/environments, with experience memory and attribution for safe skill acquisition. — Assumptions/dependencies: reliable perception-action loops; safety constraints; simulators/digital twins; human supervision and formal verification.
- Healthcare automation in EHRs and clinical workflows (healthcare/software) — Agents discover and learn tasks in EHR systems (data entry, scheduling, coding), reusing validated experiences; fine-grained attribution improves reliability. — Potential product: “Clinical Workflow Assistant” with staging-to-production promotion and continuous auditing. — Assumptions/dependencies: HIPAA/GDPR compliance; secure sandboxes; bias/safety evaluation; institutional approvals and traceability.
- Scientific automation: self-evolving lab assistants and data pipelines (research/science) — Agents explore analysis tools and lab information systems, generate tasks (e.g., dataset QC, pipeline orchestration), and attribute steps to improve reliability. — Potential product: “LabOps Agent” that maintains reproducible pipelines and generates documented SOPs. — Assumptions/dependencies: domain-specific tool instrumentation; provenance tracking; rigorous validation against ground truth.
- Autonomous curriculum generation and tutoring across subjects (education) — Agents synthesize graded tasks aligned with learner profiles and course outcomes; reference-based judging and step-level feedback improve formative assessment. — Potential product: “Self-Evolving Tutor” that co-creates curriculum with educators. — Assumptions/dependencies: pedagogical oversight; fairness and accessibility; reliable difficulty scaling and evaluation fidelity.
- Red teaming and security testing via curiosity-driven task generation (security/software) — Agents generate adversarial tasks to probe app/security surfaces; experience reuse catalogs attack patterns and mitigations. — Potential product: “Autonomous Red Team Agent” for continuous security assessment. — Assumptions/dependencies: strict containment; comprehensive logging; legal/ethical frameworks; risk scoring calibration.
- Agent training-as-a-service on cloud platforms (cloud/MLops) — Hosted pipelines for self-questioning, self-navigating, and self-attributing with standardized interfaces and vector-store experiences. — Potential product: “AgentEvolver Cloud” offering managed adaptation for enterprise apps. — Assumptions/dependencies: cost-effective compute; multi-tenant privacy; SLA-backed reproducibility; platform governance.
- Energy and industrial control assistants (energy/industry 4.0) — Agents learn SCADA/HMI-like systems in sandboxes, attribute critical decision steps, and propose optimizations under safety constraints. — Potential product: “Industrial Ops Agent” for anomaly handling and procedural support. — Assumptions/dependencies: high-fidelity simulators; strict interlocks; domain-specific validations; regulatory compliance.
- Policy and governance frameworks for self-evolving AI systems (policy/regulation) — Standardize audit trails (experience logs, attribution scores), define safe exploration boundaries, and certify agent readiness for critical domains. — Potential outcome: regulatory guidance for synthetic-data use, attribution-based evaluations, and staged deployment requirements. — Assumptions/dependencies: multi-stakeholder consensus; harmonization across jurisdictions; transparency tooling and reporting standards.
Glossary
- Advantage: A reinforcement learning signal measuring how much a trajectory’s return exceeds a baseline, used to weight policy updates. "we compute the standardized advantage for each trajectory across the entire set:"
- AgentEvolver: The proposed self-evolving agent system that autonomously improves via self-questioning, self-navigating, and self-attributing. "we present AgentEvolver, a self-evolving agent system"
- AppWorld: A benchmark environment used to evaluate agent performance and sample efficiency. "Performance comparison on the AppWorld and BFCL-v3 benchmarks."
- Bandit methods (UCB-based): Algorithms for exploration–exploitation trade-offs using confidence bounds to select actions. "UCB-based bandit methods"
- BFCL-v3: A specific benchmark suite used for evaluating agent capabilities. "Performance comparison on the AppWorld and BFCL-v3 benchmarks."
- Credit assignment: Determining which states or actions in a trajectory contributed to the outcome to guide learning. "fine-grained credit assignment"
- Curiosity-guided exploration: An exploration strategy that drives agents to seek novel or informative states using curiosity signals. "curiosity-guided exploration with environment profiles."
- Discount factor: The parameter in RL (commonly denoted by gamma) that weights future rewards. "discount factor "
- Distributional Hybrid: A mixed training distribution combining target and proxy tasks to stabilize and expand performance. "Distributional Hybrid (Optional)"
- Experience-mixed rollout: A rollout strategy interleaving unguided and experience-guided trajectories to balance exploration and exploitation. "Experience-mixed Rollout"
- Experience stripping: Removing retrieved experience tokens from training samples to prevent overfitting to contextual cues. "experience stripping strategy"
- Goal-conditioned policy: A policy that conditions action selection on a specified goal input. "goal-conditioned policy "
- Goal-conditioned value function: A value function estimating expected return given both state and goal. "the goal-conditioned value function follows the standard formulation"
- GRPO: A policy optimization method (related to PPO) used for trajectory-level optimization in LLM agents. "PPO- or GRPO-style policy optimization"
- Hybrid policy learning: Combining multiple policy guidance sources or strategies to improve exploration efficiency. "Through hybrid policy learning and trajectory guidance"
- Importance ratio: The ratio of new to old policy probabilities used in importance sampling during policy optimization. "leading the importance ratio to grow uncontrollably."
- In-Context Learning (ICL): An LLM capability to adapt behavior from examples provided in the prompt without parameter updates. "through In-Context Learning (ICL)"
- Interaction sandbox: An environment specification with states, actions, and transitions but without predefined rewards. "we define an interaction sandbox"
- Intrinsic rewards: Internal exploration incentives that encourage agents to visit novel or uncertain states. "intrinsic rewards"
- Kullback–Leibler (KL) divergence: A measure of distributional difference used as a regularization term in policy updates. "KL"
- LLM Judge: An LLM-based evaluator that assigns trajectory-level rewards based on correctness and quality. "The LLM Judge is a broadly validated solution for self-evaluation"
- MDP: Markov Decision Process, a formal model of environment dynamics with states, actions, rewards, and discounting. "Unlike a standard MDP environment"
- Myopic decision-making: A decision rule that considers only recent observations to prevent premature convergence. "myopic decision-making rule"
- Off-policy learning: Learning from trajectories generated by a policy different from the one currently being optimized. "causes a typical off-policy learning problem"
- Oracle reward: Ground-truth reward associated with target tasks used for evaluating true performance. "Target Task Space and Oracle Reward"
- PPO: Proximal Policy Optimization, a widely used RL algorithm employing clipped objectives and KL regularization. "PPO- or GRPO-style policy optimization"
- Proxy reward: A synthetic reward designed by the system to guide learning when environment rewards are unavailable. "proxy reward function through self-attributing"
- Proxy task distribution: A distribution over self-generated training tasks intended to emulate the unknown target tasks. "proxy task distribution $p_{\mathrm{train}(g)$"
- Selective boosting: Increasing the clipping threshold for positive-advantage samples to preserve strong optimization signals. "we propose a selective boosting strategy"
- Self-attributing: A mechanism that assigns differentiated rewards to steps in a trajectory based on their contribution. "Self-attributing: enhances sample efficiency by allocating fine-grained rewards"
- Self-navigating: A mechanism that leverages experience reuse and guidance to improve exploration efficiency. "Self-navigating: improves exploration efficiency by reusing and generalizing from past experiences."
- Self-questioning: A mechanism that autonomously generates tasks by probing environments to discover functional boundaries. "Self-questioning: enables curiosity-driven exploration"
- Upper Confidence Bound (UCB): An exploration strategy that selects actions with the highest upper confidence estimate of reward. "UCB-based bandit methods"
- veRL: A reinforcement learning infrastructure integrated for efficient policy optimization and parameter updates. "veRL \citep{sheng2024hybridflow}"
- Vector store: An indexed storage of embeddings enabling similarity-based retrieval of experiences. "vector store updating"
Collections
Sign up for free to add this paper to one or more collections.