GenEnv: Difficulty-Aligned Co-Evolution Between LLM Agents and Environment Simulators
Abstract: Training capable LLM agents is critically bottlenecked by the high cost and static nature of real-world interaction data. We address this by introducing GenEnv, a framework that establishes a difficulty-aligned co-evolutionary game between an agent and a scalable, generative environment simulator. Unlike traditional methods that evolve models on static datasets, GenEnv instantiates a dataevolving: the simulator acts as a dynamic curriculum policy, continuously generating tasks specifically tailored to the agent's ``zone of proximal development''. This process is guided by a simple but effective $α$-Curriculum Reward, which aligns task difficulty with the agent's current capabilities. We evaluate GenEnv on five benchmarks, including API-Bank, ALFWorld, BFCL, Bamboogle, and TravelPlanner. Across these tasks, GenEnv improves agent performance by up to \textbf{+40.3\%} over 7B baselines and matches or exceeds the average performance of larger models. Compared to Gemini 2.5 Pro-based offline data augmentation, GenEnv achieves better performance while using 3.3$\times$ less data. By shifting from static supervision to adaptive simulation, GenEnv provides a data-efficient pathway for scaling agent capabilities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GenEnv, a new way to train AI “agents” (smart chatbots that can use tools and follow steps) by pairing them with an AI “environment simulator” that creates practice tasks. Instead of learning from a fixed, pre-made dataset, the agent trains on tasks that change and get tailored to its current skill level—like a coach who always gives you challenges that are not too easy and not too hard.
What questions did the researchers ask?
- Can an AI environment that generates tasks on the fly help train agents better and cheaper than collecting lots of real-world data?
- If the environment adjusts task difficulty to match the agent’s “sweet spot” (about a 50% success rate), will the agent learn faster and more reliably?
- Is this approach more data-efficient than simply making a huge static dataset with a very large teacher model?
How did they do it? (The approach, in simple terms)
Think of training as a two-player game:
- Player 1: the Agent (the problem solver).
- Player 2: the Environment Simulator (the problem maker).
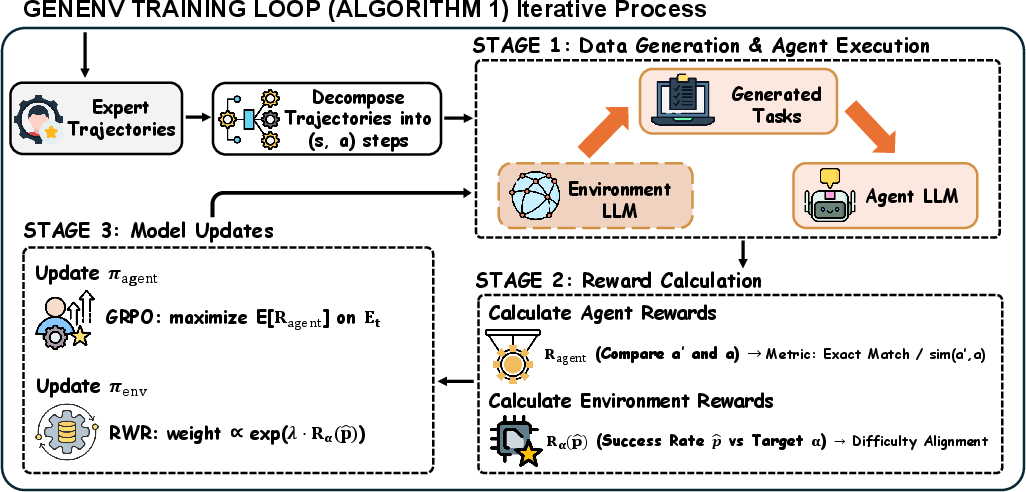
Here’s the loop:
- The environment simulator creates a batch of tasks (like puzzles, tool-use problems, or planning scenarios).
- The agent tries to solve them.
- Both players get feedback and improve:
- The agent is rewarded when it solves tasks correctly.
- The environment is rewarded when it generates tasks that are “just right” for the agent—ideally, the agent succeeds about half the time. That’s the sweet spot where learning is fastest.
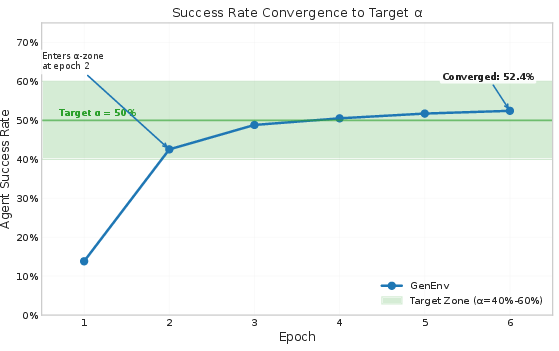
Why aim for about 50% success? Imagine video game levels: if they’re too easy, you don’t learn; if they’re impossible, you give up. The best learning happens when you win sometimes and fail sometimes—right in the middle. The paper calls this the “zone of proximal development,” which just means “the challenge zone where you learn best.”
How does the environment learn what’s “just right”?
- After the agent attempts a batch of tasks, the environment looks at the success rate (say 45% or 60%).
- It gets the highest reward when the success rate is near a target number (they use α = 0.5, or 50%).
- Over time, the environment shifts to generate tasks that keep the agent in that learning sweet spot.
What tasks did they use?
- Tool use and function calling (API-Bank, BFCL)
- Reasoning over information (Bamboogle)
- Acting in a virtual world with step-by-step instructions (ALFWorld)
- Planning realistic trips with tools (TravelPlanner)
How is this different from typical training?
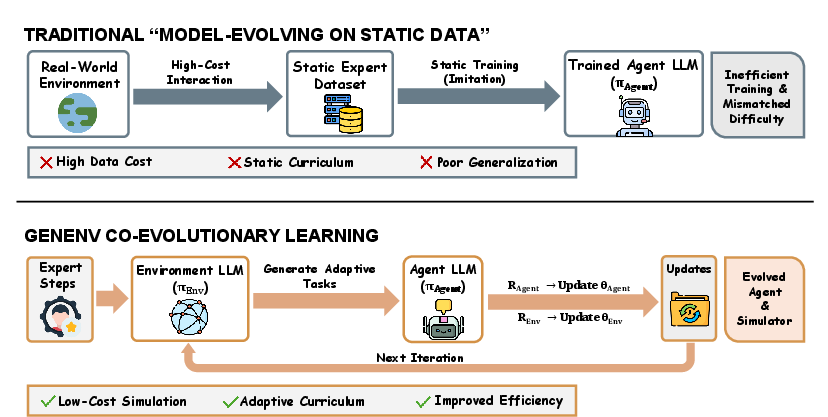
- Usual way: Train on a big, fixed dataset collected beforehand (static and expensive).
- GenEnv way: The training data evolves as the agent learns (like getting new, custom practice problems every day).
Technical note (in everyday words):
- The agent and environment both improve using standard learning updates. You can think of it as “learn from your score and adjust.” No need to dive into complex math to get the idea.
What did they find, and why does it matter?
Main results:
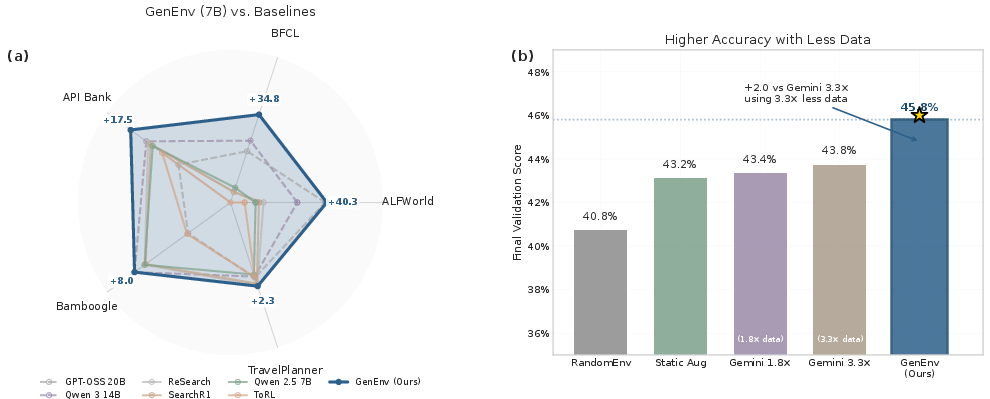
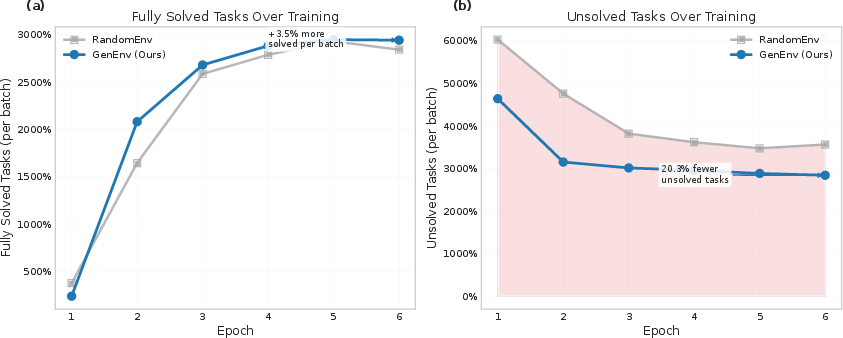
- Big gains with smaller models: A 7B-parameter agent trained with GenEnv beat strong 7B baselines across five benchmarks. On some tasks, performance jumped by over 40 percentage points (e.g., ALFWorld).
- Competes with much larger models: The 7B GenEnv agent matched or exceeded the average performance of many bigger models (14B–72B), showing that smart training can matter as much as model size.
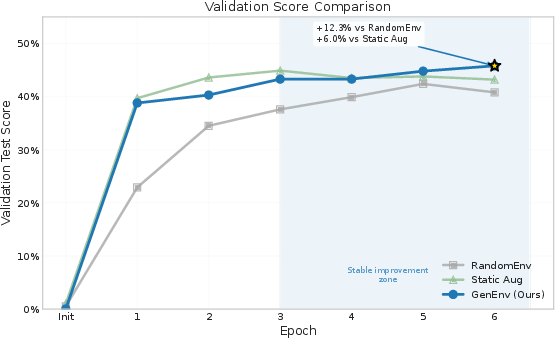
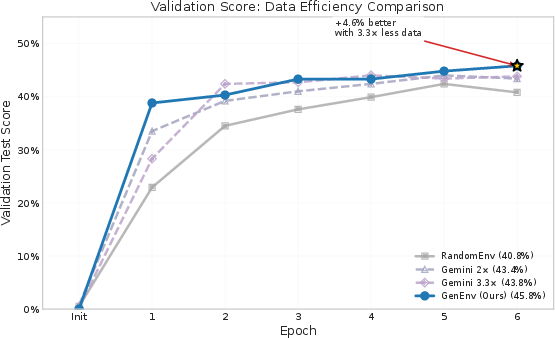
- More learning with less data: Compared to a powerful teacher model (Gemini 2.5 Pro) that generated a large, static dataset, GenEnv did better using about 3.3× less synthetic data. In short: targeted, adaptive practice beats massive but untargeted practice.
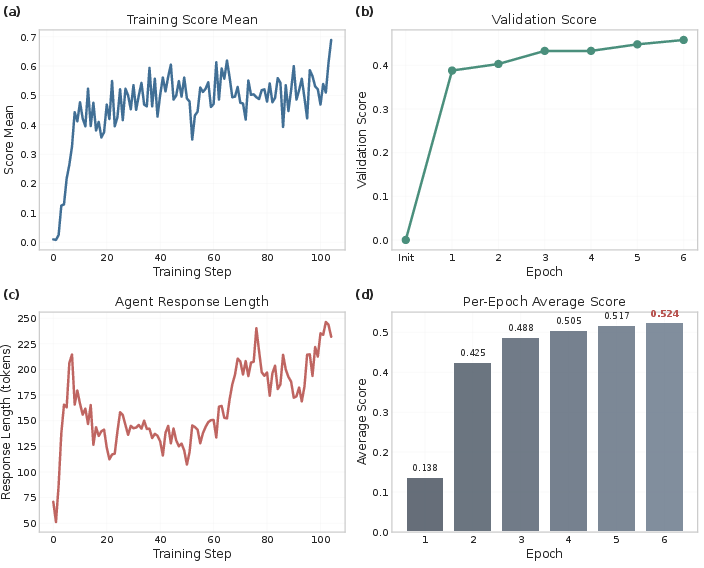
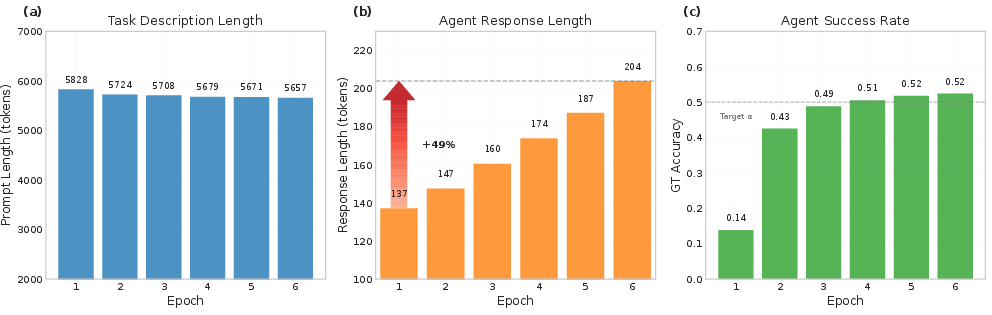
- Stable training and an “emergent curriculum”: As training went on, the environment naturally produced more complex tasks, while keeping difficulty in the “just-right” band. The agent’s success rate on simulated tasks converged around 50%, and its reasoning responses got longer and more sophisticated—signs that it was tackling harder problems effectively.
Why this matters:
- It’s costly and slow to gather real-world interaction data (like clicking around on websites or apps). GenEnv shows that a smart simulator can replace much of that with cheap, adaptive practice—speeding up progress and lowering costs.
- This approach focuses training exactly where the agent is struggling right now, which avoids wasting time on tasks that are too easy or unrelated.
What does this mean for the future?
- Smarter training over bigger datasets: Instead of endlessly collecting more static data or only using bigger models, we can get strong results by generating adaptive, “just-right” training tasks.
- Better, cheaper agent development: For any domain where real interactions are expensive (web agents, tools, robotics-like tasks), an AI environment that co-evolves with the agent can accelerate learning and cut costs.
- General recipe for growth: The idea of co-evolution—agents learning from environments that adapt to them—could become a standard way to train capable AI systems, not just for text tasks but also for multimodal and real-world-like simulations.
In simple terms: GenEnv is like having a personal coach who always gives you the next right challenge. That makes you learn faster, with fewer practice problems, and helps smaller players compete with the giants.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
The following points summarize what remains uncertain or unexplored in the paper and suggest concrete directions for future research.
- Simulator fidelity and sim-to-real transfer: The environment is an LLM-based simulator evaluated on offline benchmarks (e.g., ALFWorld textual tasks, API-Bank), not on live, changing environments (web UIs, real APIs). How well do skills learned via GenEnv transfer to real, noisy, stateful systems with UI drift, latency, and partial observability?
- Correctness of environment-generated evaluation specs: The simulator generates evaluation specifications and, at times, “ground truth.” There is no audit of label quality, error rates, or downstream impact of noisy/incorrect checkers. How can one systematically verify and de-noise environment-generated targets?
- Unstructured reward definition: For non-structured outputs, the similarity function sim(·,·) is unspecified (e.g., token-F1 vs. embeddings), and its thresholds/calibration are not reported. How sensitive are results to the choice and calibration of sim, and what metrics best align with downstream success?
- Hyperparameter sensitivity and ablations: Key knobs (α, β in the environment reward; k_min filter; KL thresholds; rollout batch sizes; sampling temperatures) lack ablations. What robustness ranges and failure regimes exist for these hyperparameters?
- Sample complexity of difficulty estimation: The environment reward relies on empirical success rate p̂ over n task instances. How large must n be for stable ranking and updates in practice, and what is the trade-off between estimation noise and training speed?
- Batch-level reward granularity: R_env is computed per batch, not per instance. The simulator could “game” the band by mixing easy and hard items to average near α, rather than aligning each instance’s difficulty. Does per-instance or per-task-type credit assignment improve alignment?
- Exploration vs. exploitation in the simulator: Reward-weighted regression (RWR) may over-exploit tasks near α and under-explore new task families. What mechanisms (e.g., entropy bonuses, Thompson sampling, UCB) improve discovery of diverse, informative tasks?
- Curriculum narrowness and coverage: Difficulty alignment may over-specialize to the simulator’s distribution. There is no measurement of task diversity, novelty, or coverage over time. How to enforce or track diversity (e.g., via distributional metrics, deduplication, or feature-space coverage)?
- Collusion/Goodhart risks: The environment might embed subtle hints or structure tasks to keep success near α without improving real capabilities (e.g., predictable phrasing). What safeguards (adversarial reviews, red-teaming, leakage detectors) prevent agent–environment collusion and reward gaming?
- Stability of two-player co-evolution at scale: Training stability is shown for 10 epochs and specific settings. How does the dynamics behave over longer horizons, with different optimizers, larger models, or more aggressive updates? What are the failure modes (oscillation, mode collapse) and stabilizers?
- Theoretical assumptions vs. practice: Analysis assumes a bandit REINFORCE setting with bounded score variation; actual training uses GRPO on sequence models with non-stationary co-evolution. Under what conditions do the theoretical guarantees degrade, and can stronger results be proved for sequence-to-sequence settings?
- Generality across model scales and asymmetry: The study centers on 7B agents/simulators. How does GenEnv perform when the agent is much stronger/weaker than the simulator, or with 14B–70B agents? Does benefit persist or diminish with stronger base models?
- Multimodal and UI-grounded extension: Benchmarks are text-centric. Can GenEnv extend to multimodal environments (screens, images, audio) and UI-grounded simulators with consistent DOM/state transitions? What additional representation and evaluation tooling is required?
- Tooling assumptions and evolution: Experiments assume fixed tool specs. Can the simulator introduce new tools or simulate API changes (renamed parameters, altered schemas) and evaluate robustness? How does GenEnv handle tool discovery or deprecation?
- Safety and robustness: The framework does not address harmful/biased task generation, prompt injections in tool calls, or unsafe content in curricula. What safety filters, policies, and adversarial tests are needed for practical deployment?
- Catastrophic forgetting and retention: Although the agent pool accumulates traces, there is no measurement of forgetting or backward transfer as the curriculum shifts. How can one quantify and prevent forgetting across evolving tasks?
- Compute and cost accounting: The claim of data efficiency is not paired with compute/resource reporting (GPU hours, tokens, wall-clock). What is the true cost of training two LLMs online versus static augmentation, and how does it scale?
- Fairness of data-efficiency comparisons: “3.3× less data” lacks normalization by token count, per-sample difficulty, and compute budgets. Can equal-token, equal-step, and equal-compute ablations disentangle data quality from quantity and teacher strength?
- Statistical reliability: Reported results lack variance estimates (multiple seeds, confidence intervals) and significance tests. What is the run-to-run variability of GenEnv and baselines?
- Benchmark protocol deviations: ALFWorld is decomposed into single steps; BFCL long-context is treated turn-wise. How do these choices affect ecological validity, and do GenEnv’s gains hold on full-horizon, end-to-end evaluations?
- OOD generalization: The curriculum adapts to the agent’s current weaknesses, but there is no test on out-of-distribution tasks. Does specialization around α degrade OOD performance, and how to incorporate robustness objectives?
- Conditioning and memory in the simulator: The “summary signals” used to condition the environment (e.g., recent success stats) are not specified. What representations, horizons, and memory mechanisms best capture agent state for curriculum generation?
- Quality control for environment-generated checkers: Executable checkers and targets might be brittle or exploitable. How to design secure, verifiable checkers and detect erroneous or adversarially crafted evaluation logic?
- Difficulty proxies and measurement: Response length is used as a difficulty proxy. Does length correlate with true task complexity? What better metrics (e.g., execution depth, tool-call graph complexity, dependency chains) can quantify difficulty?
- Reward shaping choices for the environment: The bell-shaped reward with β and k_min filtering is presented without ablation. Are other reward shapes (Huber, quantile bands, asymmetric penalties) more effective or stable?
- Data contamination and leakage: Agent and environment are both initialized from the same Qwen2.5-7B-Instruct checkpoint. Is there benchmark contamination or unintended leakage that could inflate scores?
- Robustness to noisy/weak environments: Beyond GenEnv-Random, what happens when the simulator is intentionally noisy or miscalibrated? Can the agent detect and discount low-quality tasks automatically?
- Alternative environment-learning methods: The environment is updated via RWR with KL regularization. How do other approaches (e.g., PPO, DPO, bandit-based selection, rejection sampling) compare in stability, performance, and sample efficiency?
- Real-world anchoring: Mixing in occasional real interactions to anchor the simulator is not explored. Does hybrid training (simulated + sparse real data) improve transfer and mitigate sim2real gaps?
- Reproducibility details: Core implementation specifics—prompts/templates, decoding parameters for generation vs. evaluation, seeds—are not fully specified in the main text. Providing these is necessary for faithful replication and comparison.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging GenEnv’s difficulty-aligned co-evolution between LLM agents and generative environment simulators to improve data efficiency and performance across tool use, planning, and interactive tasks.
- Adaptive synthetic data engine for training tool-use agents (software)
- Use case: Replace static offline augmentation with on-policy, difficulty-aligned synthetic tasks to train function-calling and tool-augmented reasoning agents (e.g., API orchestration, workflow automation).
- Sector linkage: Software engineering, developer tools, enterprise automation.
- Potential tools/products/workflows: “GenEnv Trainer” (SDK integrating GRPO for the agent and RWR for the simulator), evolving training pools, alpha-calibrated curriculum generation for API-Bank/BFCL-like tasks.
- Assumptions/Dependencies: Availability of executable evaluators/checkers for tools/APIs, structured action schemas, sufficient compute for dual policy updates, stable simulator updates (KL regularization).
- Difficulty-calibrated test generation for CI/CD and QA (software/QA)
- Use case: Generate targeted unit/integration tests that concentrate near a target success band (e.g., α≈0.5) to surface near-failure modes and maximize learning signal in regression testing.
- Sector linkage: Platform engineering, QA, DevOps.
- Potential tools/products/workflows: Adaptive test generators that write, execute, and rank test cases with reward-weighted regression; integration with CI pipelines to auto-escalate “breaking point” cases.
- Assumptions/Dependencies: Reliable automatic checkers and structured schemas; sufficient rollouts per task to ensure ranking consistency; guardrails to avoid degenerate or trivial tasks.
- Web automation and RPA agent training via simulators (enterprise software)
- Use case: Train agents to handle dynamic UI changes (e.g., shifting button labels) in low-cost simulated environments before deployment to real sites.
- Sector linkage: RPA, enterprise productivity, customer ops.
- Potential tools/products/workflows: “Adaptive WebSim” for synthetic UI task generation, co-evolution loops to harden agents against UI variability.
- Assumptions/Dependencies: Accurate UI simulators and state transitions; robust mapping from simulated actions to real-world behaviors; policy-compliant usage.
- Travel planning assistants trained in tool-rich simulators (consumer/travel)
- Use case: Improve planning and tool composition (search, booking, routing) using difficulty-aligned simulated scenarios to boost reliability.
- Sector linkage: Travel tech, consumer assistants.
- Potential tools/products/workflows: TravelPlanner-style simulators that compose tools and constraints; alpha-calibrated curricula to reduce failure on complex itineraries.
- Assumptions/Dependencies: Faithful tool specifications and checkers; coverage of real-world variability; evaluation metrics beyond synthetic success (e.g., user satisfaction).
- Rapid improvement on function-calling benchmarks and developer workflows (developer tools)
- Use case: Targeted training to climb leaderboards like BFCL, improving long-context function calling and schema adherence.
- Sector linkage: API platforms, developer experience, SDKs.
- Potential tools/products/workflows: “Function-Calling Coach” with curriculum aligned to schema complexity, argument validation, and error recovery.
- Assumptions/Dependencies: Long-context model capabilities; robust schema validators; token budgets and memory constraints.
- Data-efficient augmentation alternative to teacher distillation (MLOps)
- Use case: Replace expensive static augmentation from larger teacher models (e.g., Gemini 2.5 Pro) with adaptive simulators that achieve comparable or better performance using ≈3.3× less data.
- Sector linkage: MLOps, model training and evaluation.
- Potential tools/products/workflows: On-policy synthetic data pipelines; observability dashboards tracking α-band alignment and success rates.
- Assumptions/Dependencies: Simulator quality must match domain needs; careful monitoring to prevent reward hacking.
- Difficulty-calibrated evaluation and benchmarking service (industry/academia)
- Use case: Offer an evaluation harness that maintains models near α success to reveal blind spots, complementing static benchmarks.
- Sector linkage: Model evaluation, research labs, benchmarking organizations.
- Potential tools/products/workflows: α-band evaluation reports; batch success tracking; reward-weighted task ranking; reproducible co-evolution loops.
- Assumptions/Dependencies: Adequate rollouts for statistical reliability; standardized evaluators per domain.
- Safety and red-teaming via solvable adversarial task generation (security)
- Use case: Generate adversarial but solvable prompts near α to harden agents against realistic, borderline threats (e.g., tool misuse, jailbreaks that exploit agent weaknesses).
- Sector linkage: AI security, trust & safety.
- Potential tools/products/workflows: Difficulty-aligned adversarial task suites; incident analysis with success-band telemetry.
- Assumptions/Dependencies: Strong safety guardrails; policy compliance; careful curation to avoid harmful content.
- Adaptive practice generation for learning (education)
- Use case: Port the α-curriculum concept to edtech—generate exercises calibrated to a learner’s “zone of proximal development.”
- Sector linkage: Edtech, tutoring systems.
- Potential tools/products/workflows: Practice set generators with difficulty filters; student success estimators; curriculum dashboards.
- Assumptions/Dependencies: Accurate per-learner success estimates; mapping between task difficulty and learning outcomes; fairness and accessibility considerations.
- Packaged “Curriculum Simulator SDK” (cross-sector)
- Use case: A developer-facing library implementing GenEnv’s co-evolution loop (GRPO for agents, RWR for simulators), task pools, and reward calibration.
- Sector linkage: Software, research, startups.
- Potential tools/products/workflows: Drop-in SDK, configuration templates, examples for API calling, planning, and QA.
- Assumptions/Dependencies: Licensing and model availability (e.g., Qwen variants); compute resources; integration with existing training stacks.
Long-Term Applications
The following applications require further research, domain-specific simulation fidelity, scaling, or regulatory readiness to realize their full impact.
- Co-evolutionary training for physical robotics and embodied agents (robotics)
- Use case: Combine high-fidelity physics simulators with language-planning agents; keep tasks near α success to maximize learning signal and reduce real-world trial cost.
- Sector linkage: Robotics, manufacturing, logistics.
- Potential tools/products/workflows: “Alpha-Curriculum Robotics Sim,” sim-to-real transfer pipelines, safety validation workflows.
- Assumptions/Dependencies: High-fidelity simulators, sim-to-real generalization, rigorous safety and reliability testing.
- Clinical decision support trained via patient and EHR simulators (healthcare)
- Use case: Train agents with synthetic patient scenarios and tool use (order entry, documentation) while minimizing exposure to PHI.
- Sector linkage: Healthcare IT, clinical AI.
- Potential tools/products/workflows: Clinical simulators with procedural checkers; supervised evaluation protocols; human oversight loops.
- Assumptions/Dependencies: Clinically faithful simulation, regulatory approvals, bias and safety audits, robust error boundaries.
- Enterprise digital twins for AI operations (enterprise/finance/energy)
- Use case: Build environment simulators that mirror workflows, tools, compliance rules, and failure modes to co-evolve operational agents (incident response, reporting, compliance).
- Sector linkage: Operations, compliance, risk management.
- Potential tools/products/workflows: “AgentOps Twin” platforms; continuous co-evolution training with α-calibrated tasks; governance layers.
- Assumptions/Dependencies: Accurate digital twin modeling, secure data access, alignment with organizational policies.
- Regulatory stress-testing and certification for AI agents (policy/governance)
- Use case: Standardize α-calibrated simulators to stress-test agents pre-deployment; quantify misranking risks and task coverage.
- Sector linkage: Public policy, standards bodies, certification labs.
- Potential tools/products/workflows: Certification protocols grounded in α-band success rates; guidelines for rollout budgets and task diversity.
- Assumptions/Dependencies: Broadly representative simulators; consensus standards; legal and ethical frameworks.
- Difficulty-adaptive, self-updating benchmarks and curricula (academia)
- Use case: Community benchmarks that auto-adjust difficulty as models improve, reducing benchmark saturation and spurious progress.
- Sector linkage: AI research, benchmarking consortia.
- Potential tools/products/workflows: Open-source environment policies; weighted SFT datasets; reproducibility and audit tooling.
- Assumptions/Dependencies: Governance and versioning; measures against overfitting to simulators; transparent reporting.
- Multi-agent ecosystems and society-scale simulations (social science/policy)
- Use case: Study emergent behaviors by co-evolving large populations of agents and environments (markets, social networks, institutions).
- Sector linkage: Social science, economics, public policy.
- Potential tools/products/workflows: “Agent Society Sim” platforms with α-calibrated task families; outcome metrics (welfare, stability).
- Assumptions/Dependencies: Ethical review, representativeness of simulations, compute and data governance.
- Sustainable, data-efficient model training (energy/green AI)
- Use case: Reduce energy, storage, and data collection costs by replacing large static corpora with adaptive, on-policy simulation.
- Sector linkage: Sustainability, cloud providers.
- Potential tools/products/workflows: Energy-aware training pipelines; data minimization policies; telemetry on learning signal per sample.
- Assumptions/Dependencies: Broad adoption; standardized measurement; careful accounting of simulator costs.
- Personalized learning platforms with robust student modeling (education)
- Use case: Build accurate models of learner success and align content using α-curriculum to balance challenge and mastery.
- Sector linkage: Edtech, workforce training.
- Potential tools/products/workflows: Learner state estimators; adaptive content generators; outcome tracking and fairness audits.
- Assumptions/Dependencies: Reliable assessment signals; privacy-preserving analytics; long-term efficacy studies.
- Autonomy for complex cloud/software operations (DevOps/Cloud)
- Use case: Co-evolve incident response agents with realistic operation simulators to manage outages, rollbacks, and compliance in α-band training.
- Sector linkage: Cloud operations, SRE.
- Potential tools/products/workflows: Incident simulators; policy-governed action spaces; safety interlocks and human-in-the-loop escalations.
- Assumptions/Dependencies: High-fidelity ops simulators; strong guardrails; organizational change management.
- GenEnv-as-a-Service across sectors (platformization)
- Use case: Hosted platforms providing environment simulators, training loops, evaluation harnesses, and curriculum telemetry for diverse domains.
- Sector linkage: AI platforms, B2B services.
- Potential tools/products/workflows: Multi-tenant simulator hosting; domain-specific evaluators; managed training jobs; governance dashboards.
- Assumptions/Dependencies: Security and IP protections; scalable infrastructure; domain-specific plugin ecosystems.
Glossary
- Agent Policy: The learned decision-making policy of the agent that maps contexts to actions. "We maintain two policies: an Agent Policy $\pi_{\text{agent}$} (the agent) and an Environment Policy $\pi_{\text{env}$} (the environment simulator)."
- α-Curriculum Reward: A difficulty-alignment reward for the environment that peaks when the agent’s success rate matches a target , encouraging tasks in the agent’s learning sweet spot. "This process is guided by a simple but effective -Curriculum Reward, which aligns task difficulty with the agent's current capabilities."
- Adaptive curriculum: A training strategy where task difficulty is adjusted dynamically to match the agent’s evolving capability. "enabling low-cost simulation, an adaptive curriculum, and improved efficiency."
- Bandit setting: A simplified reinforcement-learning setup with single-step decisions used for theoretical analysis of learning signals. "We first consider a stylized bandit setting in which the Agent Policy $\pi_{\text{agent}$ interacts with a single environment-generated task type "
- Bernoulli random variables: Binary-valued random variables (0/1) modeling success/failure outcomes. "which can be bounded using Hoeffding's inequality for Bernoulli random variables."
- Co-evolutionary: Refers to the simultaneous mutual adaptation of the agent and the environment simulator during training. "The GenEnv Co-Evolutionary Loop."
- Concentration inequalities: Probabilistic bounds that control the deviation of empirical estimates from their means. "The argument is based on standard concentration inequalities."
- Data-Evolving Paradigm: A framework where the training data distribution is generated on-the-fly and adapts to the agent’s performance. "GenEnv instantiates a Data-Evolving Paradigm: the simulator acts as a dynamic curriculum policy, continuously generating tasks specifically tailored to the agent's ``zone of proximal development''."
- Embedding similarity: A similarity measure computed over vector representations of text to score unstructured outputs. "e.g., normalized token-F1 or embedding similarity"
- Embodied environments: Simulated physical or interactive environments requiring agents to perform actions grounded in environment states. "ALFWorld~\citep{shridhar2020alfworld} aligns textual instructions with embodied environments;"
- Empirical success rate: The observed fraction of successful attempts in a batch, used to calibrate difficulty. "we compute the empirical success rate:"
- Environment Policy: The generative simulator’s policy that produces tasks with targeted difficulty for the agent. "We maintain two policies: an Agent Policy $\pi_{\text{agent}$} (the agent) and an Environment Policy $\pi_{\text{env}$} (the environment simulator)."
- Exact match: An evaluation criterion requiring the predicted output to match the reference exactly. "evaluation specification (e.g., executable checker / exact-match target / reference answer)"
- Group Relative Policy Optimization (GRPO): A policy-gradient fine-tuning algorithm used to train the agent. "In our experiments, we instantiate this using Group Relative Policy Optimization (GRPO) \citep{shao2024deepseekmath}."
- Hoeffding's inequality: A concentration bound for sums of bounded independent random variables, used to bound mis-ranking probabilities. "which can be bounded using Hoeffding's inequality for Bernoulli random variables."
- KL penalty: A regularization term using Kullback–Leibler divergence to keep updated policies close to the initial policy. "For stability, we regularize updates with a KL penalty to the initial simulator and cap per-step updates by a maximum KL threshold."
- KL threshold: A constraint limiting the maximum allowed KL divergence per update step. "For stability, we regularize updates with a KL penalty to the initial simulator and cap per-step updates by a maximum KL threshold."
- Long-horizon planning: Tasks requiring extended sequences of decisions and reasoning over many steps. "Notably, on ALFWorld, which requires long-horizon planning, GenEnv achieves 54.5\% accuracy"
- Monotone transformation: A function that preserves order; used to shape rewards without changing task rankings. "which is a monotone transformation of "
- Normalized token-F1: A token-level F1 score normalized to [0,1], used to score unstructured answers. "e.g., normalized token-F1 or embedding similarity"
- On-policy: Data generated by and collected from the current policy during training. "newly collected on-policy traces."
- Policy gradients: Gradient-based methods for optimizing stochastic policies to maximize expected reward. "optimized jointly with the agent using standard policy gradients"
- REINFORCE-style estimator: The classic score-function estimator for policy gradient computation. "The Agent Policy is updated with a REINFORCE-style estimator"
- Reward hacking: Exploiting reward signals in ways that increase reward without genuine task solving. "without signs of reward hacking or instability."
- Reward-Weighted Regression (RWR): A method that fine-tunes a generative model using supervised pairs weighted by rewards. "We implement this via Reward-Weighted Regression (RWR):"
- Rollout: Executing a policy to generate an interaction trace or trajectory. "we run independent rollouts"
- Score function: The gradient of the log-probability of actions, used in policy gradient estimators. "squared norm of the score function remains within a trust-region bound."
- SFT (Supervised Fine-Tuning): Fine-tuning a model on labeled input-output pairs. "Environment SFT pool $\mathcal{D_{\text{env}$:} stores environment generations used to train $\pi_{\text{env}$ via RWR."
- Success-rate band: A target interval around a desired success rate (e.g., ) used to align task difficulty. "The core innovation for $\pi_{\text{env}$ is a difficulty-aligned reward that targets a success-rate band around a desired "
- Tool-calling: Invoking external tools or APIs through structured function calls within LLM outputs. "All models---including large models---are evaluated in a unified tool-calling framework."
- Trajectory: A sequence of actions and states (or outputs) produced during an interaction. "Each trace records at minimum: "
- Trust-region policy optimization: Methods that constrain policy updates via KL divergence to ensure stable learning. "as well as in the literature on trust-region policy optimization \citep{schulman2015trust}."
- Zone of proximal development: The difficulty region where tasks are challenging yet solvable, maximizing learning gains. "continuously generating tasks specifically tailored to the agent's ``zone of proximal development''."
Collections
Sign up for free to add this paper to one or more collections.

