LLMs Corrupt Your Documents When You Delegate
Abstract: LLMs are poised to disrupt knowledge work, with the emergence of delegated work as a new interaction paradigm (e.g., vibe coding). Delegation requires trust - the expectation that the LLM will faithfully execute the task without introducing errors into documents. We introduce DELEGATE-52 to study the readiness of AI systems in delegated workflows. DELEGATE-52 simulates long delegated workflows that require in-depth document editing across 52 professional domains, such as coding, crystallography, and music notation. Our large-scale experiment with 19 LLMs reveals that current models degrade documents during delegation: even frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4) corrupt an average of 25% of document content by the end of long workflows, with other models failing more severely. Additional experiments reveal that agentic tool use does not improve performance on DELEGATE-52, and that degradation severity is exacerbated by document size, length of interaction, or presence of distractor files. Our analysis shows that current LLMs are unreliable delegates: they introduce sparse but severe errors that silently corrupt documents, compounding over long interaction.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple, important question: if you let an AI write and edit your work over many steps (like a helpful assistant you “delegate” tasks to), will it keep your documents safe—or quietly mess them up?
The authors build a big test called DELEGATE-52 to check how well today’s most advanced AIs handle long, realistic editing workflows across 52 different types of professional documents (like code, recipes, music notation, spreadsheets, and more). Their main finding: even the strongest models slowly corrupt documents as they edit them over time, and small mistakes add up.
What questions did the researchers ask?
They focused on five easy-to-understand questions:
- Can current AI models be trusted to edit real work documents over many steps without breaking them?
- Does performance get worse the longer the workflow goes?
- Does the type of document matter (code vs. text vs. data tables, etc.)?
- Do extra files in the workspace (distractors) make things worse?
- Do “agent” tools (like reading files, running code, search-and-replace) help models avoid mistakes?
How did they test it?
Think of a shared folder at school or work. It has your main file plus other related files. You tell an AI to make a series of changes across the folder—split a file, reformat it, move parts into separate files, convert units, then later undo those changes—and you expect everything to be put back exactly as it was.
Here’s the core idea, explained with simple analogies:
- Reversible edits (the “do–undo” trick): For each task, there’s a forward instruction and a backward instruction. For example, “split a long ledger into separate files by category” (forward) and “merge them back exactly” (backward). If the AI does both correctly, you end up back at the original. It’s like translating a sentence to French and then translating it back to English—you should get the same meaning if nothing went wrong.
- Long relay of edits: They chain many of these “do–undo” pairs to simulate a long workday—20 interactions in total. If a model is reliable, the original document should remain intact after each full “do–undo” cycle. If it isn’t, errors creep in and build up.
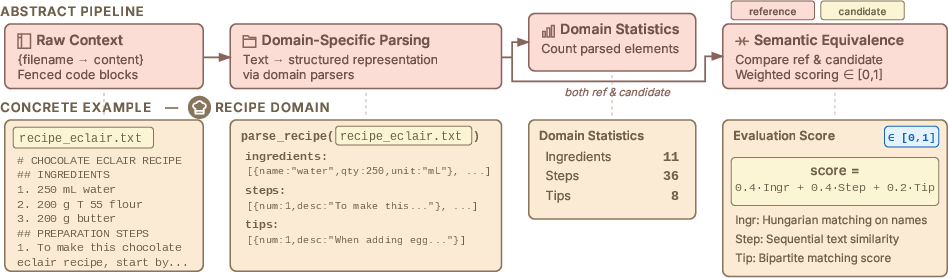
- Smart scoring per domain: Simple text matching (like counting same words) isn’t enough. The team wrote custom checkers for each domain. For example, a recipe is turned into a structured list of ingredients (with amounts), steps, and tips. Then they compare original vs. after to see what truly changed. This catches real errors (like changing “200 g” to “800 g”) while ignoring harmless changes (like reordering lines).
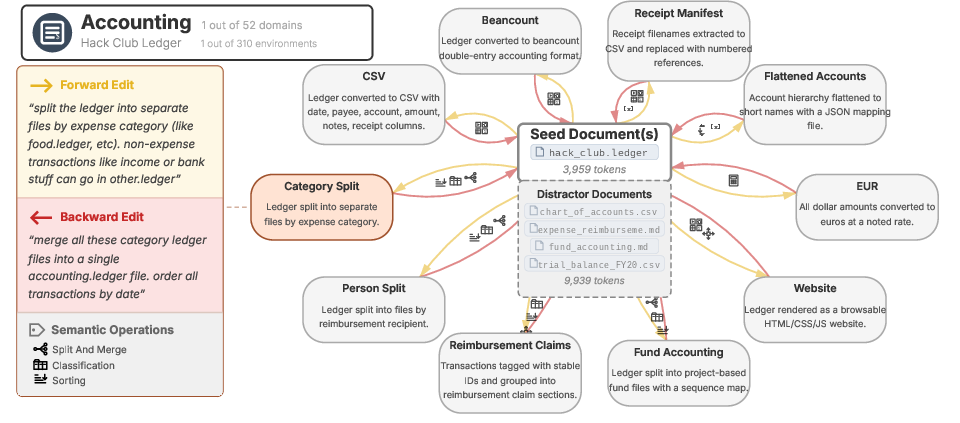
- Realistic work environments: Each test workspace includes:
- A real “seed” document (like an actual accounting ledger or real music sheet),
- 5–10 meaningful edit tasks that require real reasoning (not just reformatting),
- Extra related files that shouldn’t be touched (distractors), to mimic a messy folder.
They ran these tests with 19 major AI models and measured how similar the “restored” document was to the original after 2, 4, … up to 20 interactions.
What did they find?
The key results are clear and important:
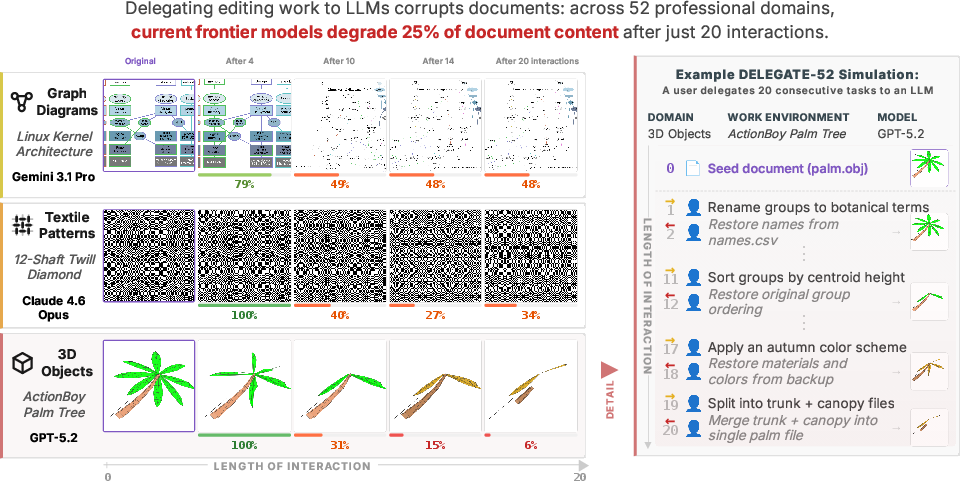
- All models accumulate errors over time. Even the newest, strongest models ended up corrupting around 25% of the document content on average by the end of the long workflow. Many other models did worse, averaging around 50% degradation.
- Mistakes are “sparse but severe.” The models don’t always wreck everything at once. Instead, they make a few silent, high-impact changes (like deleting a section, changing a number, or breaking a file link), and these small breaks compound with each additional edit.
- Domain matters a lot. Models do best in programming-related tasks (especially Python) where structure is strict and easier to verify. They do worse in natural language and niche formats (like earning statements or music notation), where meaning is subtle and structure varies.
- Short tests can be misleading. A model that looks fine after 2 edits can be much worse after 20. In other words, quick demos don’t reveal long-run reliability.
- Tools didn’t help (yet). Giving the models a basic “agent” setup—tools for reading/writing files and running code—did not improve results. In fact, it sometimes made things worse, possibly because using tools created longer, more complex interactions and the tasks require deep understanding, not just simple script fixes.
- Bigger documents, longer workflows, and more distractor files make corruption worse. The harder and messier the environment, the more the errors pile up.
Why this matters: Delegated work depends on trust. If you can’t easily spot errors (or don’t have time to check), corrupted documents can slip into final work—spreadsheets, reports, code, even legal or scientific materials.
Why does this matter and what’s the impact?
- For everyday users and teams: Don’t blindly trust AI to make many edits across complex files without checks. If you delegate, build in safeguards—limit the scope, review diffs, lock critical sections, and verify results regularly rather than at the very end.
- For companies and tool builders: Reliability over long workflows is a major gap. You’ll likely need:
- Better guardrails (e.g., structured editors, schema-aware tools),
- Stronger verification (domain-specific checkers that understand meaning, not just text),
- Smarter agents that minimize unnecessary rewrites and prove that they preserved what matters.
- For researchers: DELEGATE-52 is a public benchmark to measure progress. It shows that:
- Long-horizon evaluation is essential,
- Agent tool use needs to be re-thought for complex text domains,
- Domain-aware scoring beats “generic” similarity or simple LLM judging.
- Big picture: Today’s models are powerful, but as long-term document editors, they’re not yet trustworthy across most professional domains. The path forward is building systems that can edit precisely, prove they didn’t break things, and stay reliable over many steps—not just one or two.
In short: As AI assistants become part of real work, we need to move from “can it do the task once?” to “can it edit safely, repeatedly, and reversibly?” This paper shows we’re not there yet, and provides a way to measure when we are.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper and DELEGATE-52, framed as concrete directions future research could act on:
- External validity beyond reversible edits: Real delegated work often involves non-invertible transformations (summarization, creative expansion, refactoring with information loss). Evaluate models on non-reversible tasks with appropriate success criteria (task completion, constraint satisfaction) rather than round-trip reconstruction.
- Single-turn editing vs. realistic multi-turn supervision: Each edit step is run as an independent, single-turn session. Study multi-turn clarification, persistence of working memory across steps, and whether conversational planning reduces corruption.
- Reliance on curated, unencoded text formats: The benchmark excludes ubiquitous real-world formats (PDF, DOCX/XLSX, PPTX, proprietary CAD, binary spreadsheets). Extend to these via toolchains (e.g., parsers/converters) and measure whether format conversion itself introduces failure modes.
- Lack of multimodal editing: Although some domains render visually (e.g., graphs, 3D), evaluation is text-only. Add multimodal tasks (image/audio/CAD editing with semantic constraints) and multimodal consistency checks.
- Domain-specific similarity metrics’ validity: Similarity functions and weights are hand-designed per domain. Quantify their reliability via human studies (agreement with expert judgments), sensitivity/specificity to targeted perturbations, and cross-domain ablations.
- Threshold for “ready” (RS@20 ≥ 98%) is ad hoc: Conduct sensitivity analyses and domain-specific tolerance studies to calibrate readiness thresholds against real-world quality bars and risk profiles.
- Uncontrolled pretraining contamination: Seed documents are from the web; models may have seen them. Construct contamination-controlled splits (e.g., newly created or private documents) and measure performance deltas to estimate familiarity effects.
- Distractor realism is limited: Distractors are validated to be non-interfering. Introduce conflicting/ambiguous distractors and vary retrieval precision/recall to study robustness to noisy retrieval.
- Task sequencing realism: Round-robin repetition of edits may not reflect real workflows. Generate realistic task graphs with dependencies, evolving requirements, and cross-file couplings; evaluate degradation under such sequences.
- Agentic harness minimalism: Only basic tools (read/write, code execution) were tested. Evaluate advanced mechanisms: structured diff/patch outputs, AST- or schema-level editors, domain validators/linters, transactional edits with rollbacks, pre-commit tests, and schema-constrained or typed edit APIs.
- Version-control integration: Assess whether using VCS (git) with atomic commits, diffs, pre-commit hooks, and enforced review/checks reduces corruption over long horizons.
- Early-warning signals for long-horizon failure: Short-term performance poorly predicts 20-step outcomes. Develop predictors (e.g., entropy/uncertainty, self-consistency, invariant checks, small canary edits) that forecast drift early.
- Corruption taxonomy and root causes: Provide a fine-grained error analysis by domain (deletions vs. substitutions, structure breakage, unit/format errors, cross-file inconsistencies) and map failure modes to mitigation strategies.
- Scaling horizons and contexts: Simulations stop at 20 interactions with ~15–27k tokens of context. Test much longer horizons (50–100+ steps) and much larger contexts (100k–1M tokens), including chunking and memory strategies (buffers, retrieval, episodic memory).
- Minimal-edit constraints and patch formats: Compare full-file rewrites to constrained edits (e.g.,
unified diff, JSON Patch, AST patches) and measure whether constraints reduce silent corruption while preserving task success. - Decoding and prompting effects: Systematically vary decoding parameters (temperature, top-p), system prompts (edit conservatism, change manifests), and reasoning modes (CoT vs. no-CoT, tool-first vs. text-first) to map stability–quality trade-offs.
- Cost/latency and efficiency: Agentic runs consumed 2–5× more tokens. Quantify performance–cost curves, and evaluate compute-aware strategies (program synthesis for deterministic substeps, selective tool invocation, caching).
- Human-in-the-loop oversight: Study lightweight review protocols (spot checks, checklists, change summaries, risk-based sampling) and automated guardrails (parsers, unit tests, invariants) to determine minimal oversight needed to bound corruption.
- Human baselines and trust: Compare LLM delegates to human assistants on the same workflows for corruption rates, detectability, time, and perceived trust; calibrate benchmark difficulty against human performance.
- Interference by conflicting goals across steps: Introduce tasks whose objectives partially conflict (e.g., format vs. content edits) to test whether agents can preserve invariants under competing constraints.
- Memory and retrieval augmentation: Evaluate persistent memory stores and vector retrieval for reusing prior decisions (nomenclature, mappings) across steps; study how memory eviction/refresh affects drift.
- Domain-specialized scaffolding: For each domain, test specialized validators (e.g., schema validators, compilers, renderers, unit tests, checksum-based file partition checks) as part of an agent loop to prevent structural corruption.
- Training for round-trip consistency: Explore using reversible-edit consistency, invariants, or edit minimality as training objectives/regularizers (finetuning or RL) and measure gains on DELEGATE-52.
- Generalization across documents within a domain: Evaluate whether edit strategies learned on one seed document transfer to unseen documents in the same domain with different structure/complexity.
- Robustness to adversarial perturbations: Stress-test with near-miss formats (e.g., subtly invalid syntax, mixed encodings, unit ambiguities) to probe brittleness and evaluate hardening techniques.
- Reproducibility over time: Frontier APIs evolve rapidly. Provide standardized model versioning, seeds, and harness snapshots; study benchmark stability across model updates and the effect of provider-side changes.
- Safety of agentic code execution: Assess sandboxing, resource limits, and side-effect containment in agentic settings; measure how safety constraints interact with edit success and corruption rates.
Practical Applications
Overview
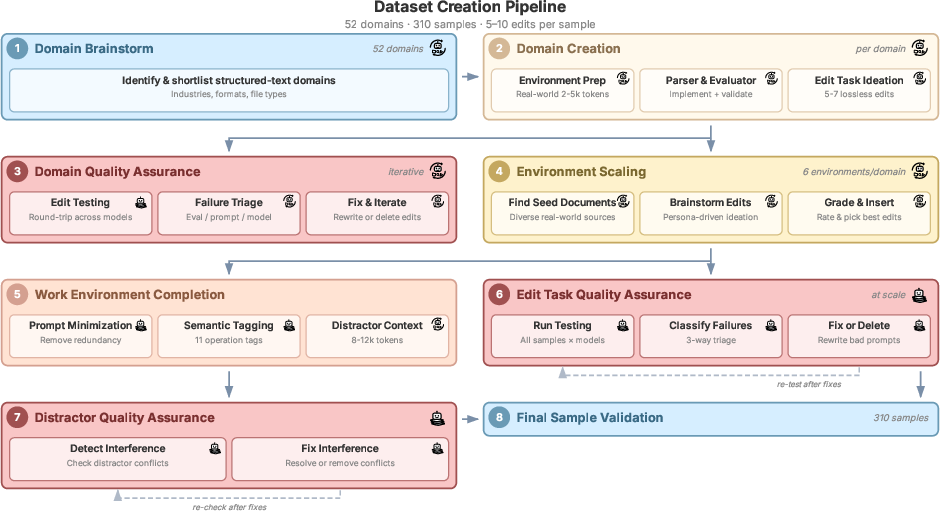
This paper introduces DELEGATE-52, a benchmark and evaluation method for long-horizon delegated workflows where LLMs repeatedly edit real documents across 52 professional domains. Core findings: (1) all tested models accumulate sparse but severe errors, silently corrupting documents over long interactions; even top models lose ~25% of content after 20 interactions, (2) performance varies by domain (Python is comparatively “ready”), (3) basic agentic tool use did not improve outcomes and often worsened them, (4) degradation increases with document size, interaction length, and distractors, and (5) short-term tests are not predictive of long-horizon reliability. The benchmark relies on domain-specific parsers and reversible edits (“round-trip relay”) to measure semantic fidelity without gold references.
Below are practical applications grouped by immediacy, with sector links, candidate tools/workflows, and key dependencies.
Immediate Applications
These can be deployed now with available methods, code, and practices.
- Industry: reliability benchmarking and vendor selection
- Use DELEGATE-52 to benchmark internal/third-party AI assistants for document editing across domains; report RS@k (reconstruction score) at 20+ interactions before launching features.
- Sectors: software, productivity suites, enterprise content management, consulting.
- Tools/workflows: benchmark-as-a-service dashboards; procurement checklists requiring long-horizon scores; model routing by domain readiness.
- Dependencies/assumptions: compute budget; access to benchmark; acceptance that DELEGATE-52 is text-centric.
- Software: CI/CD “round-trip relay tests” for AI editing features
- Gate releases with automated round-trip tests on representative documents; fail builds if long-horizon fidelity drops (regression).
- Sectors: IDEs, content platforms, agent products.
- Tools/workflows: CI plugins that run reversible edits and compute RS@k; nightly regression suites.
- Dependencies: domain parsers for target document types; curated reversible task sets.
- Enterprise/Compliance: document integrity monitors
- Continuously score semantic drift during AI-assisted sessions; trigger alerts when risk thresholds are crossed; enforce transactional commits and rollbacks.
- Sectors: finance (ledgers, statements), healthcare (EHR notes), legal (contracts), logistics (EDIFACT), government records.
- Tools/workflows: “Document Fidelity Monitor” microservice; semantic diff visualizations; auto-rollback checkpoints.
- Dependencies: robust parsers; change management; audit logging.
- Workflow design: reduce compounded risk in delegated editing
- Mitigate identified failure modes by limiting: (a) interaction length (session resets), (b) context size (chunking, high-precision retrieval), (c) distractors (better filtering), and (d) full rewrites (prefer patches).
- Sectors: all knowledge-work contexts.
- Tools/workflows: retrieval precision checks; session “timeouts” after N edits; aggressive context pruning; simple “patch-only” policies.
- Dependencies: retrieval quality; product UX updates.
- Editing strategy: enforce patch/diff-based editing over regeneration
- Require LLMs to output structured minimal diffs (e.g., unified diff, JSON patch, AST edit scripts) and apply them programmatically.
- Sectors: software engineering, config management, data pipelines, localization.
- Tools/workflows: “LLM Patch Guard” libraries; AST-based editors for code/JSON; canonicalization pre/post steps.
- Dependencies: patch application infrastructure; canonical serializers; doc-specific ASTs.
- Human-in-the-loop triggers based on semantic risk
- Define RS-like proxies (or domain parsers + change magnitude) to trigger mandatory review for high-risk edits.
- Sectors: healthcare, finance, legal, HR.
- Tools/workflows: approval gates; risk scoring panels; forced “track changes” + reviewer assignment.
- Dependencies: policy definitions; reviewer capacity.
- Agent platform design: tool budgets and simpler harnesses by default
- Given basic agentic tool use did not help, start with constrained harnesses and explicit caps on tool invocations/context growth; selectively enable code-execution where it clearly reduces rewrites.
- Sectors: agent frameworks, RPA, enterprise AI platforms.
- Tools/workflows: dynamic tool-budgeting; telemetry on tool effectiveness; “use-code-or-write” decision policies.
- Dependencies: instrumentation; cost controls.
- Domain-aware model routing and fallbacks
- Route tasks in “ready” domains (e.g., Python) to general LLMs; in weak domains, prefer specialized tools/rules or require human oversight.
- Sectors: developer tooling, data/analytics, creative tools.
- Tools/workflows: domain readiness matrices; router policies; fallback to validators/compilers/linters.
- Dependencies: up-to-date readiness assessments; integration with domain tools.
- Data/QA: detect corruption in LLM-generated corpora
- Use parsing-based similarity and canonicalization to validate that iterative LLM edits did not corrupt datasets used for training or evaluation.
- Sectors: ML data engineering, content operations, localization.
- Tools/workflows: corpus integrity scans; parse–serialize round-trips; anomaly dashboards.
- Dependencies: parsers; canonical forms.
- Daily life/productivity: safer use patterns for AI edits
- Adopt versioning and frequent checkpoints; ask for “suggested changes” or patches, not full rewrites; verify numerical/structural fields (ingredients, amounts, dates, IDs) after AI edits.
- Sectors: individuals, SMBs, education.
- Tools/workflows: autosave; “review changes” modes; diff viewers; backup/restore.
- Dependencies: basic version control; user training.
- Policy/procurement: require long-horizon reliability disclosures
- Include DELEGATE-52-like tests in RFPs for AI writing/editing tools; mandate reporting by domain and RS@k thresholds.
- Sectors: public sector, regulated industries, large enterprises.
- Tools/workflows: procurement templates; third-party attestations; periodic re-certification.
- Dependencies: benchmarking capacity; governance frameworks.
- Education and research training
- Integrate DELEGATE-52 into coursework and labs to teach limits of delegated AI editing and evaluation methodology.
- Sectors: academia, workforce upskilling.
- Tools/workflows: assignments on long-horizon evaluation; parser-building labs.
- Dependencies: curriculum integration.
Long-Term Applications
These require additional research, scaling, or ecosystem development.
- Model training objectives for edit fidelity
- Incorporate round-trip consistency losses and invariance training so models learn to preserve semantics over reversible transforms and repeated edits.
- Sectors: foundation model R&D, fine-tuning providers.
- Tools/workflows: synthetic invertible transforms at scale; self-consistency training pipelines; fidelity KPIs.
- Dependencies: compute; diverse reversible task libraries.
- Structured editing agents over free-form generation
- Architect agents to operate on ASTs/DOMs/schemas with API-level operations (insert/update/move) rather than regenerating whole documents.
- Sectors: software (IDEs), spreadsheets/BI, CMS, EHRs, ledgers.
- Tools/workflows: domain-specific operation sets; schema-aware planners; verification before commit.
- Dependencies: reliable schemas; operation semantics; system APIs.
- Standards: canonicalization and parse–serialize round-trips
- Develop open standards for canonical JSON/YAML, ledgers (e.g., Beancount), recipes, subtitles, and other text formats to support robust semantic equality checks.
- Sectors: standards bodies, industry consortia.
- Tools/workflows: reference parsers/serializers; conformance test suites.
- Dependencies: community adoption; backward compatibility.
- Regulatory frameworks for AI-assisted document integrity
- Define “Document Integrity under AI Assistance” baselines (e.g., minimum RS@20 by domain) and audit procedures for safety-critical domains.
- Sectors: healthcare, finance, aviation, public records.
- Tools/workflows: certification programs; third-party audit services; continuous compliance monitors.
- Dependencies: stakeholder consensus; enforcement mechanisms.
- Runtime self-checking and self-healing agents
- Embed plan–do–check–act loops with semantic diffing, unit tests for documents, and automatic rollback/repair when integrity drops.
- Sectors: enterprise AI, RPA, content automation.
- Tools/workflows: policy engines; semantic test harnesses; repair libraries.
- Dependencies: test oracles; fast diff/rollback infrastructure.
- Long-context and memory research tailored to editing
- New architectures and retrieval schemes that remain robust under long sessions, large documents, and distractors; memory as deltas/patches instead of regenerated text.
- Sectors: LLM research, platform providers.
- Tools/workflows: hierarchical memory, delta-based editing buffers, distractor-resistant attention.
- Dependencies: model innovations; eval at 20–100+ interactions.
- Multimodal and collaborative benchmark extensions
- Extend DELEGATE-52 to CAD, code+diagram co-editing, musical scores with audio, and real-time multi-agent co-authoring.
- Sectors: engineering, media, education, robotics.
- Tools/workflows: multimodal parsers; cross-modal similarity metrics; collaborative session simulators.
- Dependencies: dataset curation; evaluation standards.
- Transactional editing systems with semantic commit protocols
- OS- or platform-level transactional layers for AI edits: stage → validate (semantic checks) → commit → audit trail, with guaranteed rollback.
- Sectors: operating systems, enterprise platforms, DMS/CMS.
- Tools/workflows: semantic pre-commit hooks; integrity contracts; “two-phase commit” for documents.
- Dependencies: platform integration; performance overhead control.
- Marketplace for domain parsers and integrity scoring
- Ecosystem of high-quality, versioned parsers and similarity functions that vendors can license to assure integrity in specific domains.
- Sectors: developer tooling, compliance, vertical SaaS.
- Tools/workflows: scoring APIs; plug-and-play validators; governance of updates.
- Dependencies: standard interfaces; maintenance/community support.
- User experience patterns for safe delegation at scale
- Mature “review checkpoints,” risk meters, and progressive disclosure into standard UX for AI writing/editing tools.
- Sectors: productivity suites, collaboration software.
- Tools/workflows: interaction patterns/libraries; design guidelines; usability studies.
- Dependencies: product adoption; user education.
Notes on Assumptions and Dependencies
- The benchmark is text-only; extending to binary/multimodal formats needs new parsers and metrics.
- Invertible (round-trip) tasks are a proxy for real workflows; many real edits aren’t strictly reversible, so integrity proxies must be adapted (e.g., canonicalization, invariants, unit tests).
- Domain-specific parsing is central to robust scoring; deploying integrity monitors requires reliable parsers and canonical forms for each target document type.
- Agentic results are based on a basic harness; more advanced tool ecosystems may change outcomes but should still be validated with long-horizon tests.
- Context size, distractor quality, and session length materially affect corruption rates; mitigation depends on retrieval and product UX capabilities.
- Privacy and compliance constraints may limit use of third-party benchmarks on sensitive data; construct internal analogs with the same methodology.
Glossary
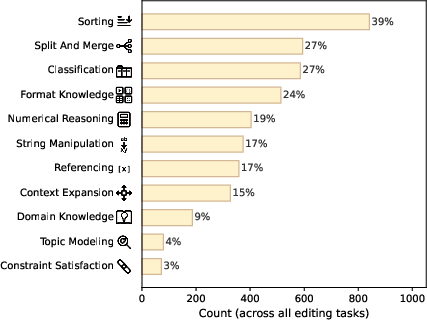
- ablation testing: An experimental method where components or factors are systematically removed to assess their impact on performance. "Per-domain component combination and relative weights are calibrated through ablation testing to ensure proportional sensitivity to content loss or corruption"
- agentic harness: A framework that lets an LLM act as an agent by invoking tools (e.g., read/write files, run code) to complete tasks. "we implemented a basic agentic harness \citep{Yao2022ReActSR} with file reading, writing, and code execution tools"
- agentic tool use: The practice of an LLM using external tools during task execution within an agent framework. "agentic tool use does not improve performance on DELEGATE-52"
- backtranslation: A technique that applies a forward transformation and its inverse to check if the original content is recovered, often used in machine translation. "Backtranslation originated as a data augmentation and evaluation technique in machine translation"
- backtranslation round-trip primitive: A two-step reversible edit (forward and inverse) used to test whether document content is preserved. "The backtranslation round-trip primitive."
- Beancount format: A plaintext accounting format used for double-entry bookkeeping. "formatting the ledger in Beancount format."
- chained reversible transformations: A sequence of reversible operations applied one after another to evaluate consistency or robustness. "evaluate LLM consistency through chained reversible transformations"
- CIF (.cif): Crystallographic Information File; a standard text file format for crystallography data. "e.g., .srt for subtitles, .cif for crystallography"
- context window: The maximum span of text an LLM can attend to in a single interaction. "as text in its context window in a single turn"
- data augmentation: Techniques that expand or transform data (e.g., via backtranslation) to improve or evaluate model performance. "Backtranslation originated as a data augmentation and evaluation technique in machine translation"
- delegated work: An interaction paradigm where users assign tasks to an LLM to execute on their behalf under supervision. "such as delegated work \citep{Shao2025FutureOW, Ulloa2025ProductMP}"
- distractor context: Additional, topically related documents included in the input that are irrelevant to the current task and can cause confusion. "each work environment includes a distractor context"
- distractor files: Irrelevant files present alongside the target documents that can mislead the model during editing. "presence of distractor files."
- domain-specific similarity function: A custom scoring function tailored to a domain to measure how semantically similar two documents are. "we implement a domain-specific similarity function "
- embedding space: A vector space where texts are mapped to numerical representations so that semantic distances can be measured. "semantic distance in a generic embedding space"
- frontier models: The most capable, cutting-edge LLMs available at the time of evaluation. "frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT~5.4)"
- Levenshtein ratio: A normalized measure of similarity between two strings based on edit distance. "Levenshtein ratio \citep{Levenshtein1965BinaryCC}"
- LLM-as-a-judge: Using a LLM to evaluate outputs or compare documents instead of human annotators. "including LLM-as-a-judge with GPT~5.4"
- long-horizon (delegated interaction): Tasks or evaluations that span many steps or interactions, emphasizing sustained performance over time. "simulate long-horizon delegated interaction"
- parsing function: A component that converts raw text into a structured representation for downstream evaluation. "A parsing function converts documents into a structured representation."
- quality assurance: Systematic checks to ensure the validity and reliability of the benchmark and experiments. "we performed quality assurance at each stage of the construction process"
- reconstruction score (RS@): A metric measuring similarity between the original and reconstructed documents after k interactions. "We compute reconstruction scores RS@ after each round-trip"
- reference annotations: Human-provided labels or gold-standard markings used for evaluation. "reducing evaluation to semantic equivalence without reference annotations"
- reference solutions: Canonical, correct outputs used for supervised evaluation. "evaluate LLM performance without requiring annotation or reference solutions"
- retrieval precision: The proportion of retrieved documents that are relevant to the task. "(i.e., retrieval precision is imperfect)"
- round-robin scheduling: A procedure where tasks are cycled through in order, repeating as needed. "We validate the use of round-robin scheduling in Appendix~\ref{app:round_robin}"
- round-trip relay: A sequence of multiple round-trips applied in succession to simulate extended workflows. "A round-trip relay: a sequence of 10 consecutive round-trip tasks, total: 20 interactions."
- seed document: The initial document provided at the start of each workflow that all transformations operate on. "The seed document is the starting point for all simulations."
- semantic equivalence: The property of two documents conveying the same meaning despite surface differences. "Semantic equivalence is measured in two steps"
- tiktoken encoder: A tokenizer used by OpenAI models (e.g., GPT-4) to convert text into tokens. "Based on the GPT~ 4 tiktoken encoder"
- work environment: A domain-specific setup consisting of a seed document, editable tasks, and distractor materials used to simulate realistic workflows. "For each domain, we construct six work environments"
Collections
Sign up for free to add this paper to one or more collections.

