How LLMs Distort Our Written Language
Abstract: LLMs are used by over a billion people globally, most often to assist with writing. In this work, we demonstrate that LLMs not only alter the voice and tone of human writing, but also consistently alter the intended meaning. First, we conduct a human user study to understand how people actually interact with LLMs when using them for writing. Our findings reveal that extensive LLM use led to a nearly 70% increase in essays that remained neutral in answering the topic question. Significantly more heavy LLM users reported that the writing was less creative and not in their voice. Next, using a dataset of human-written essays that was collected in 2021 before the widespread release of LLMs, we study how asking an LLM to revise the essay based on the human-written feedback in the dataset induces large changes in the resulting content and meaning. We find that even when LLMs are prompted with expert feedback and asked to only make grammar edits, they still change the text in a way that significantly alters its semantic meaning. We then examine LLM-generated text in the wild, specifically focusing on the 21% of AI-generated scientific peer reviews at a recent top AI conference. We find that LLM-generated reviews place significantly less weight on clarity and significance of the research, and assign scores that, on average, are a full point higher.These findings highlight a misalignment between the perceived benefit of AI use and an implicit, consistent effect on the semantics of human writing, motivating future work on how widespread AI writing will affect our cultural and scientific institutions.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “How LLMs Distort Our Written Language”
What is this paper about?
This paper looks at how LLMs—like AI tools that help people write—don’t just change the style or tone of our writing. They can also change what our writing actually means. The authors show that when people rely on LLMs, their opinions can get softened or shifted, their unique “voice” can get lost, and even important systems like scientific peer review can start valuing different things because of AI-written text.
What questions did the researchers ask?
In plain terms, the researchers wanted to know:
- When people use AI to help them write, does it change what they say, not just how they say it?
- If an AI is told to only “fix grammar,” does it still change the message?
- Are AI-written texts in the real world (like scientific reviews) different in what they focus on and how they judge quality?
How did they study it?
The team ran three main investigations:
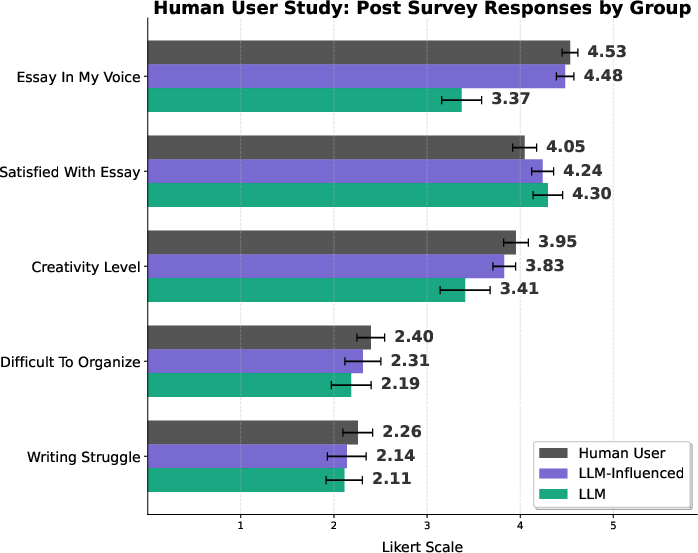
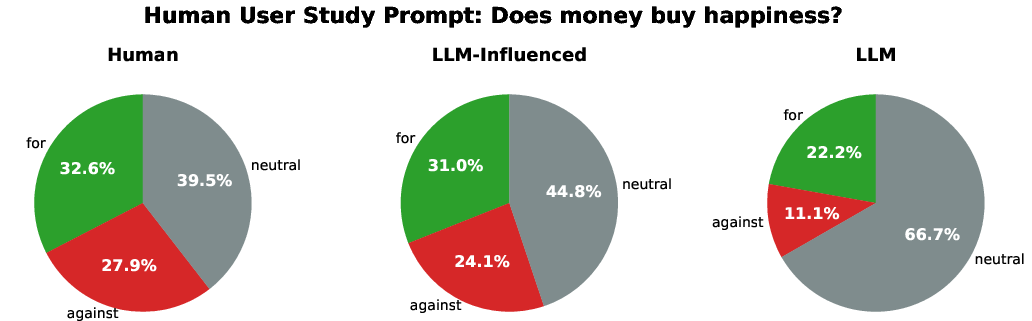
- Human writing study (a small experiment): 100 people wrote an argumentative essay (“Does money lead to happiness?”). Some weren’t allowed to use AI, some used AI a little, and some used it a lot. The team compared the essays and asked people how they felt about their writing.
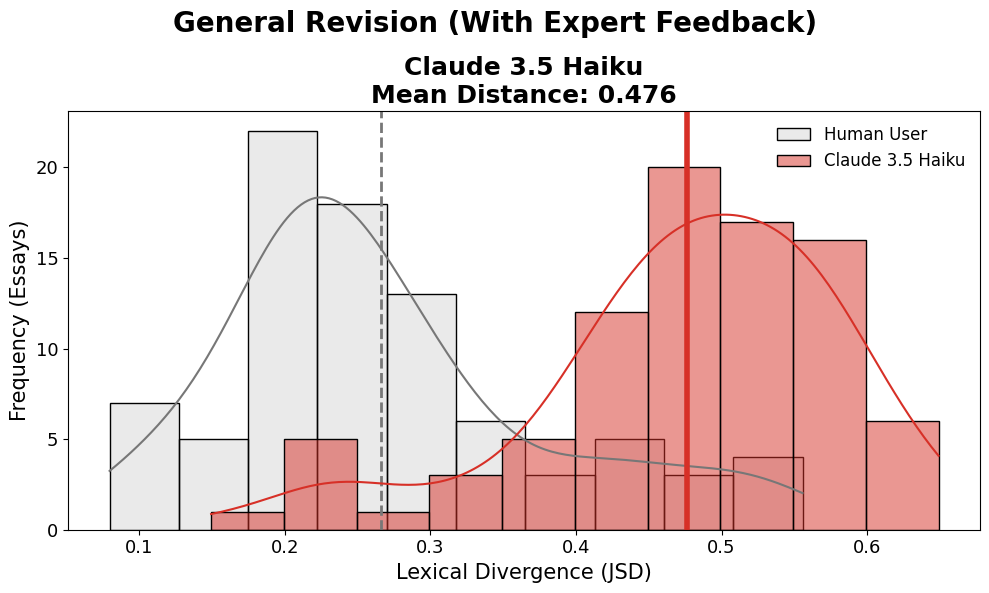
- “Before-and-after” editing study: The researchers used an older set of 86 student essays (from before popular AI tools existed) about self-driving cars. Each essay had teacher-like feedback and a human-edited second draft. The researchers then asked several modern LLMs to edit the original drafts using the same feedback and compared the AI edits to the human edits.
- Real-world peer reviews: They analyzed reviews from a top AI conference where about 21% of reviews were generated by AI. They compared human-written and AI-written reviews from the same papers to see differences in scoring and what the reviews emphasized.
To compare meaning and style, they used a few tools (explained simply):
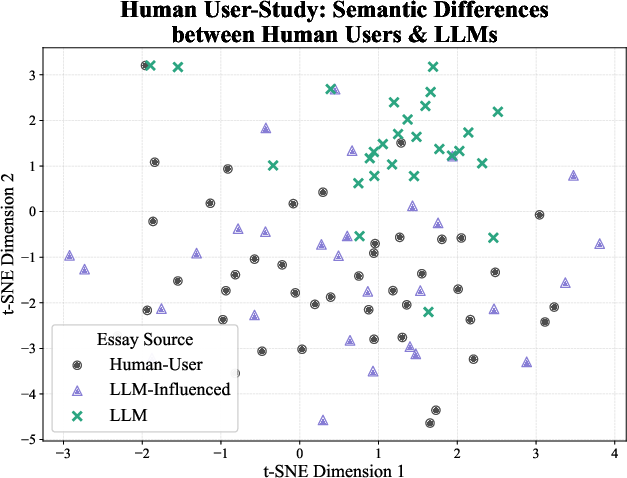
- “Embeddings” and maps: Imagine turning each essay into a dot on a map where nearby dots have similar meanings. If dots move far in the same direction after AI editing, that suggests the meaning is shifting in a consistent way across many essays.
- PCA and t-SNE: Ways to squish big, complicated maps into 2D so we can see patterns (like clusters) more easily.
- JSD (Jensen–Shannon Divergence): A score that measures how different the word choices are before vs. after editing—like comparing two playlists to see how much the song selection changed.
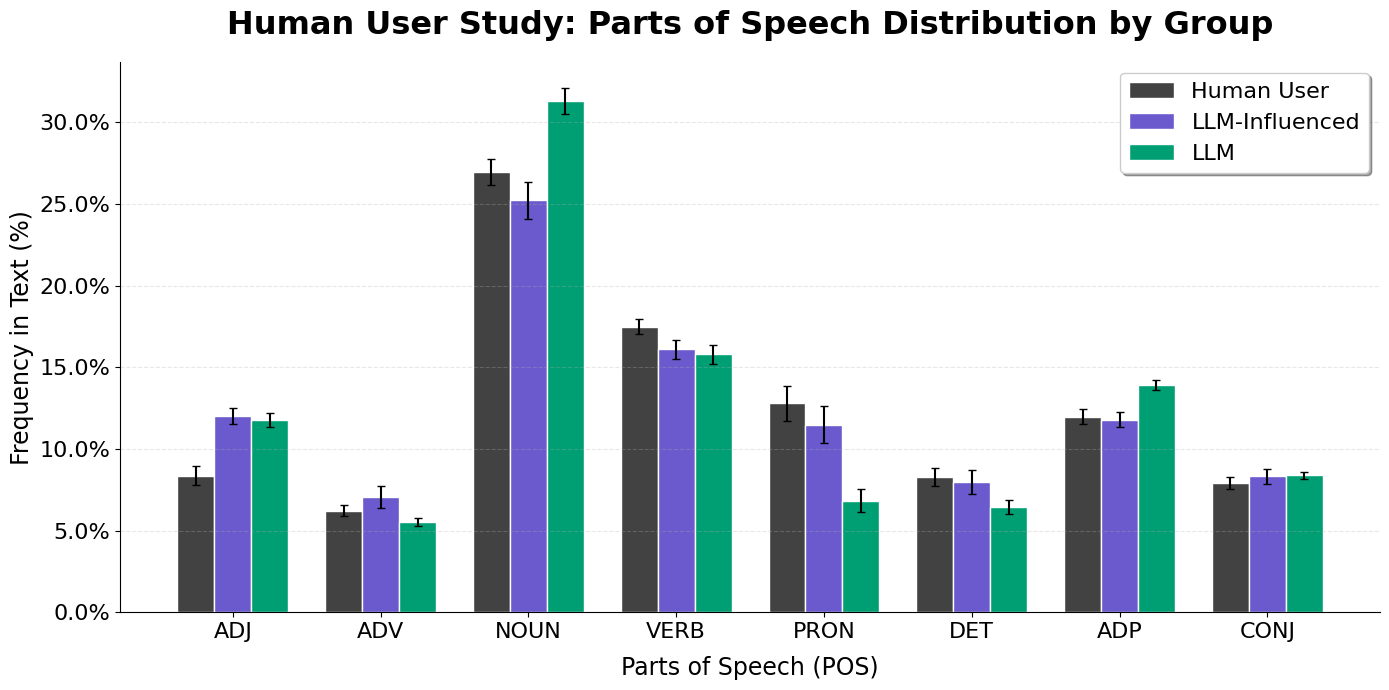
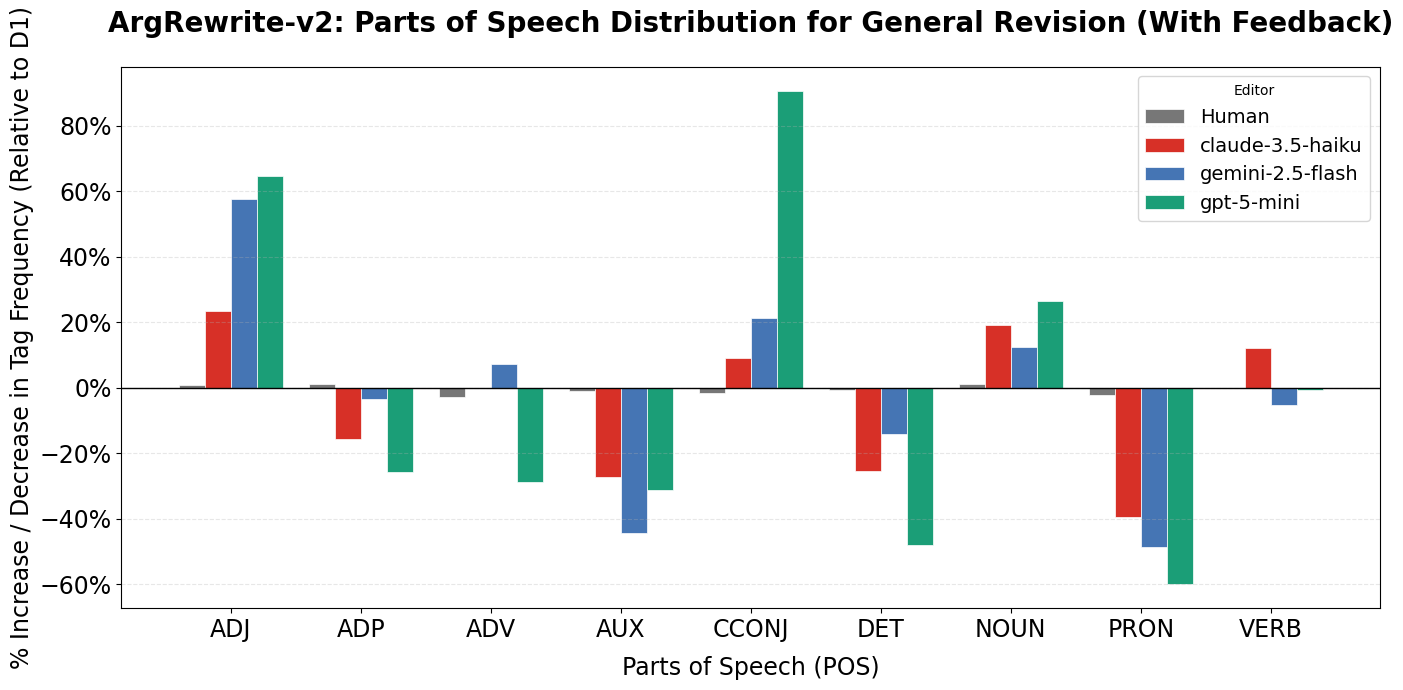
- Parts of speech (POS): Checking if writing uses more pronouns (“I,” “we”), more nouns, more adjectives, etc., to see how the style changes.
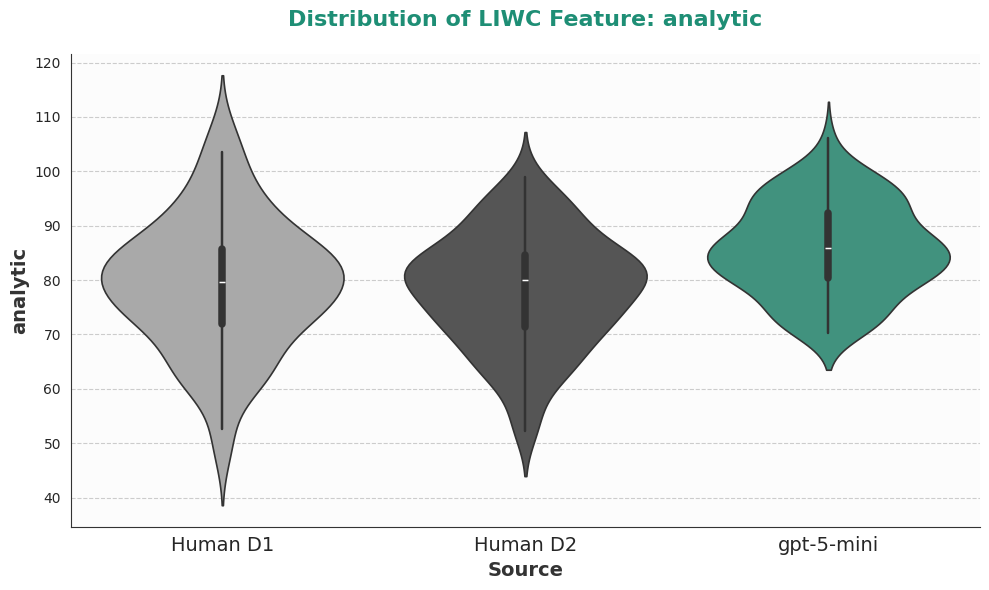
- LIWC and emotion lexicons: Dictionaries that help measure things like how analytical or emotional the language is.
- “LLM-as-a-judge”: Using an AI to label things consistently (for example, deciding if an essay is “for,” “against,” or “neutral” on a topic, or listing the strengths/weaknesses mentioned in a review).
What did they find, and why is it important?
- Heavy AI use made essays more neutral and less personal:
- In the human study, people who leaned heavily on AI were about 70% more likely to end up with neutral essays instead of taking a clear side. They also said their writing felt less creative and less like their own voice—yet they were just as satisfied with the final product.
- This is important because “satisfied but less authentic” suggests people might not notice how their views or style are being shifted.
- Even “just fix the grammar” can change meaning:
- In the editing study, when AI was told to do minimal or grammar-only edits, it still changed the core message. AI revisions moved many essays in the same “direction” on the meaning map, while human edits were smaller and varied based on the writer’s own choices.
- AI edits also replaced more words than humans did (higher JSD scores), pointing to bigger rewrites than people typically make to themselves.
- AI pushes writing toward a formal, less personal style:
- AI-edited texts used fewer pronouns (like “I,” “we”) and more nouns and adjectives, making them sound more formal and less like a person telling their own story or experience.
- This “official-sounding” voice may erase the author’s personality and originality.
- AI increased emotional flavor while sounding analytical:
- AI often added more emotional language (especially positive or “trust” words) even as it used a more formal structure. That can subtly tilt arguments—for example, sounding more upbeat about technology than the original writer intended.
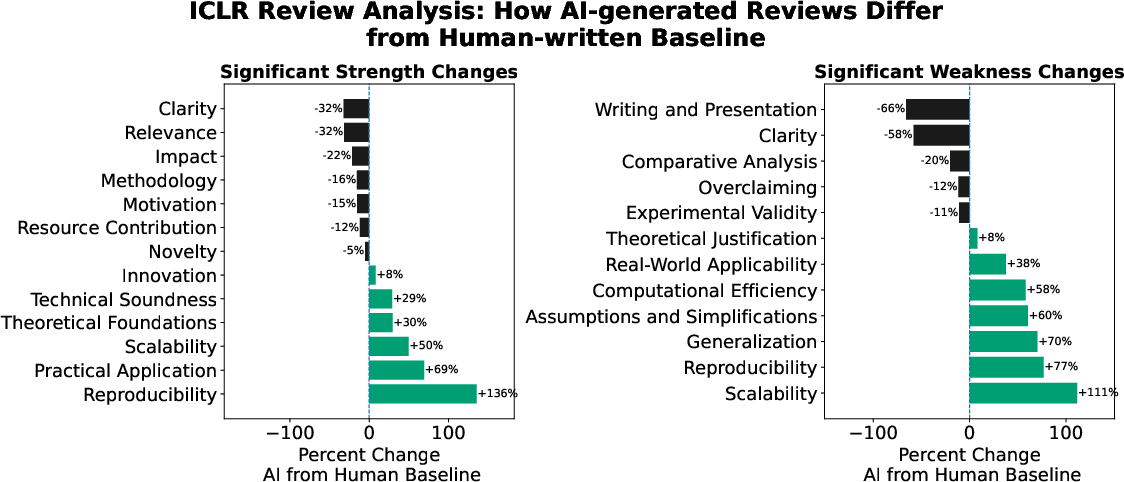
- In scientific peer review, AI changed what reviewers focus on—and boosted scores:
- AI-written reviews gave, on average, scores about one full point higher.
- They focused less on clarity or significance and more on things like reproducibility and practical application.
- This matters because if a lot of reviews are AI-shaped, the entire field might start rewarding different qualities in research, shifting what gets published and studied.
What does this mean for the future?
- For everyday writing: If many people rely on AI to write, we could end up with a lot of texts that sound similar, feel less personal, and take safer, more neutral positions. That could reduce creativity and make public conversations less lively or less honest about real opinions.
- For schools and learning: Students might lose chances to practice their own thinking and voice if they let AI do the heavy lifting. Even asking AI to “just fix grammar” can change what they’re actually saying.
- For science and culture: If AI shapes reviews, articles, and official documents, it may slowly change what society values—what counts as “good” research or writing—without people fully realizing it.
- For AI design: The results suggest today’s LLMs aren’t great at “editing without changing meaning.” Building tools that truly preserve a writer’s intent and voice is an unsolved challenge and an important goal.
In short, the paper warns that AI writing helpers can quietly shift not just how we write, but what we say—and that could reshape education, science, and culture over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up research:
- Limited task/domain scope in the RCT: only one essay prompt (“Does money lead to happiness?”) restricts generalizability to other topics, stakes, and genres (e.g., policy memos, legal briefs, creative writing, emails, technical docs).
- Narrow populations: RCT participants were native English speakers residing in the U.S.; effects across non-native speakers, other countries, multilingual settings, and cross-cultural contexts remain untested.
- Small-scale RCT (N=100): insufficient power to detect nuanced or subgroup effects (e.g., by baseline writing ability, AI familiarity, or demographics); lacks preregistered power analyses.
- Self-selection into “heavy” vs “influenced” LLM usage: categorization is ex post and behaviorally defined, not experimentally manipulated; causal inference about usage intensity is limited.
- Absent ground-truth intentions: the study infers stance shifts via automated judgments but does not elicit authors’ intended stance/meaning pre- and post-interaction to directly quantify “meaning distortion.”
- Heavy reliance on automated evaluators: LLM-as-a-Judge is used to label stance and review criteria; potential circularity and bias are unaddressed by human validation, inter-annotator agreement, or sensitivity analyses across different judges.
- Embedding/PCA/t-SNE dependence: semantic “direction” and clustering conclusions hinge on specific embedding models and dimensionality reductions; robustness to alternative representations, distance metrics, and statistical tests is only partially explored.
- Length confounds: LLM revisions may be longer; lexical divergence (JSD), POS distributions, and emotion densities might reflect length effects; controls for length and matched-sample analyses are not reported.
- Single-topic counterfactual dataset (ArgRewrite-v2 on self-driving cars): meaning-shift findings may be topic-specific; need tests across diverse argumentative topics and expository/creative genres.
- Small counterfactual corpus (86 essays): limits statistical stability and the ability to model heterogeneity (e.g., by initial stance strength, draft quality, or feedback type).
- Prompt and decoding ablations are minimal: no systematic analysis of temperature/top‑p, system prompts, instruction specificity, chain-of-thought usage, or constrained editing modes on meaning preservation.
- Limited model coverage: only three models (gpt-5-mini, gemini-2.5-flash, claude-haiku); unclear whether effects hold for other families, sizes, open-source models, or future versions; no parameter-scaling analysis.
- Incomplete mitigation testing: the paper identifies distortion but does not evaluate interventions (e.g., style-locked editing, constrained grammars, semantic similarity constraints, voice-preservation fine-tuning, editor-in-the-loop workflows).
- No human semantic change ratings: there is no blinded human evaluation to verify that detected “semantic shifts” correspond to perceived meaning changes and not stylistic or embedding artifacts.
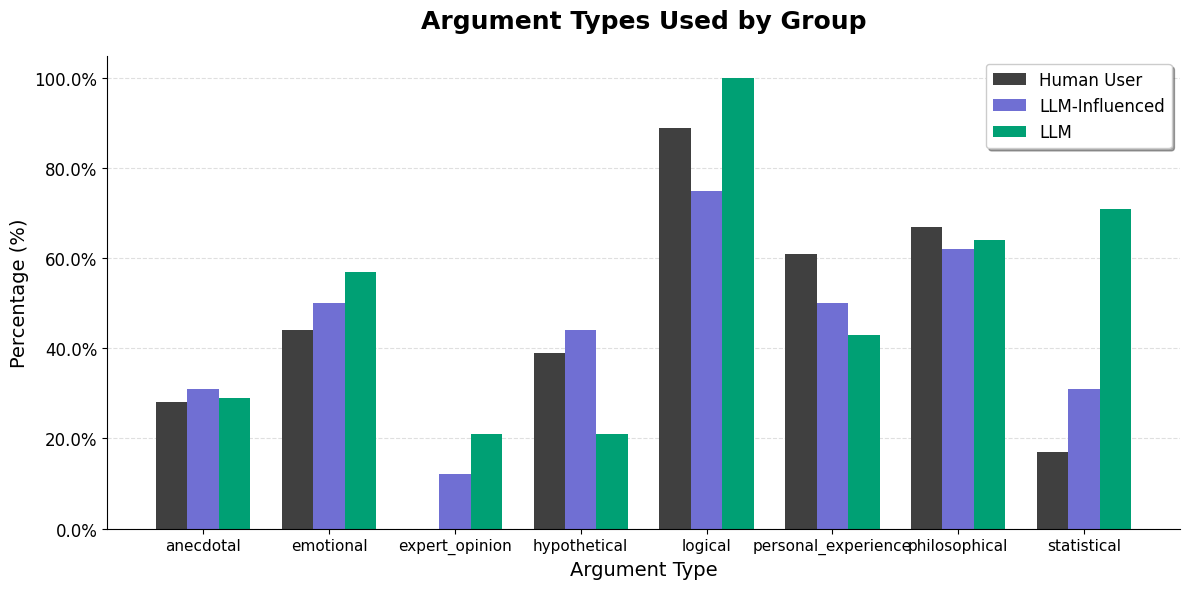
- Argument structure analysis is absent: changes to claims, premises, evidence, and rhetorical structure (argument mining) are not quantified, limiting interpretability of “meaning” alteration.
- Emotion analysis via static lexicons: NRC lexicon may misclassify context-dependent sentiment; contextual sentiment/emotion models and human validation are not employed.
- Style vs content disentanglement: LIWC and POS shifts are shown, but the study lacks causal disentanglement of stylistic normalization vs substantive stance/content changes.
- ICLR “in the wild” analysis lacks causal linkage: differences in criteria emphasis and scoring are reported, but effects on acceptance decisions, area chair deliberations, and downstream scientific outcomes are not established.
- LLM-detection reliability: reliance on Pangram classifications introduces potential mislabeling; the impact of false positives/negatives on findings is not quantified via sensitivity analyses.
- Review quality and expertise confounds: reviewer seniority, time spent, and paper difficulty are not controlled; matched-paper design helps but cannot isolate whether LLM use or reviewer characteristics drive observed differences.
- Temporal dynamics are unstudied: how meaning/style drift evolves with sustained LLM reliance (weeks/months) and whether users “reclaim” voice over time remain unknown.
- Cross-lingual/cross-cultural homogenization: whether the observed semantic convergence follows Western/Anglophone norms and how it manifests in other languages/cultures is not measured.
- Downstream societal impact: the work posits institutional risks but does not quantify real-world consequences (e.g., policy changes, editorial standards, public discourse polarization).
- User intent alignment and satisfaction paradox: users report comparable satisfaction despite voice/creativity loss; mechanisms behind this paradox and long-term satisfaction/agency effects are unexamined.
- Ethical and normative dimensions: when neutrality is beneficial vs harmful is not theorized; criteria for “distortion” vs “improvement” (e.g., clarity, fairness, factuality) are not operationalized.
- Personalization and controllability: to what extent controllable generation, user style profiles, or preference models can preserve meaning while improving form remains unexplored.
- Calibration and guardrails: the paper shows “grammar-only” prompts still change meaning; it does not test guardrailed APIs or constrained editing tools that enforce semantic preservation.
- Replicability and openness: model versions, decoding parameters, and all prompts are not exhaustively documented; reproducibility across API changes and future model updates is uncertain.
Practical Applications
Immediate Applications
The paper’s findings enable several deployable practices and tools that reduce unintended meaning shifts, homogenization, and loss of voice when using LLMs in writing workflows.
- Bold: Semantic-drift alerts in document editors
- Sectors: software, education, journalism, corporate communications, legal/compliance
- What: Integrate “semantic diff” alongside text diff to flag changes in argument stance, conclusions, tone, and lexical fingerprint between drafts (e.g., before/after AI edits).
- Tools/workflows: Plugins for Google Docs/MS Word; embedding-based drift meters; stance classifiers; LIWC/POS panels showing shifts from user baseline.
- Assumptions/dependencies: Reliable sentence embeddings and stance detectors; access to pre- and post-edit text; privacy controls; user acceptance of added friction.
- Bold: “Voice-preserving” edit mode in AI assistants
- Sectors: software (writing tools), marketing, PR, journalism
- What: A constrained editing mode that enforces thresholds on embedding drift, JSD (lexical change), POS profile, and LIWC “Authenticity,” warning or blocking edits that exceed limits.
- Tools/workflows: API parameter “preserve-voice=true”; automatic rollback of edits that change stance or exceed drift budget; per-user voice profiles.
- Assumptions/dependencies: Access to model APIs or on-device models to enforce constraints; calibration per genre; false positive/negative management.
- Bold: AI-edit disclosure and audit trails
- Sectors: academia, government, journalism, legal, finance
- What: Require version histories that log when and how LLMs were used; embed an “AI involvement” section or metadata in submissions and official communications.
- Tools/workflows: Doc management systems that store edit provenance; standardized disclosure templates.
- Assumptions/dependencies: Institutional policy adoption; secure logging; privacy and IP concerns.
- Bold: Peer-review criteria balance checker
- Sectors: academia (conferences/journals)
- What: Automatically assess reviews for coverage of criteria (clarity/significance vs. reproducibility/scalability) and flag “score inflation” and homogenized phrasing typical of LLMs.
- Tools/workflows: OpenReview integration with an LLM-as-a-judge rubric; dashboards for area chairs showing criteria balance and drift from historical norms.
- Assumptions/dependencies: Classifier reliability; community buy-in; risk of over-reliance on automated judgments.
- Bold: Brand-voice drift monitoring
- Sectors: marketing, PR, customer support
- What: Continuously compare team output (emails, blogs, ads) to a brand’s voice baseline (lexicon, POS, LIWC) and alert on homogenization or stance shifts introduced by AI.
- Tools/workflows: CI-like “voice QA” gates in content pipelines; periodic reports on drift and neutrality creep.
- Assumptions/dependencies: A well-defined brand voice baseline; willingness to adjust prompts/workflows.
- Bold: Compliance and commitment-fidelity checks
- Sectors: finance, legal, procurement
- What: Detect AI edits that subtly alter obligations, promises, or risk language in contracts, disclosures, and policies.
- Tools/workflows: Domain-specific rule-checkers plus semantic-drift thresholds; approval gates for AI-assisted redlines.
- Assumptions/dependencies: High-precision domain ontologies; legal review; access to redline history.
- Bold: Education workflows that reduce distortion
- Sectors: education
- What: Enforce “human-first drafting” followed by AI-limited copyediting with a semantic-drift report; grade on argument quality and voice consistency.
- Tools/workflows: LMS integrations that collect first drafts pre-AI; automated stance/semantic diffs for instructors and students.
- Assumptions/dependencies: Student privacy; instructor training; avoiding punitive misuse.
- Bold: Email and client-communication tone guards
- Sectors: enterprise software, sales, support, healthcare admin
- What: Prevent over-emotional or excessively formal language creep from AI suggestions; preserve appropriate first-person voice.
- Tools/workflows: Outlook/Gmail plugins with emotion density meters (NRC) and POS profiles; “reset to original tone” button.
- Assumptions/dependencies: Lightweight, fast on-device or API calls; user trust.
- Bold: Reviewer and author training modules
- Sectors: academia, media, corporate comms
- What: Short modules showing how AI use can neutralize stance, inflate scores, and erode voice; recommended prompting patterns (e.g., use AI for ideas/search more than generation).
- Tools/workflows: Microlearning in IRB, editorial, and HR onboarding; checklists.
- Assumptions/dependencies: Institutional incentives for adoption; updated as models evolve.
- Bold: QA benchmarks for AI writing tools
- Sectors: software (LLM providers, editor vendors)
- What: Use the paper’s code/metrics (embedding drift, JSD, POS/LIWC, stance) as a regression suite to evaluate “meaning-preserving” performance across releases.
- Tools/workflows: Internal CI pipelines to prevent drift regressions; public “meaning-preservation scores.”
- Assumptions/dependencies: Agreement on metrics; dataset licenses; compute budget.
Long-Term Applications
These applications require further research, model development, standard-setting, or scaling to be reliable and broadly adopted.
- Bold: Meaning-preserving editors with formal constraints
- Sectors: software, education, legal, journalism
- What: New models/objectives that enforce semantic invariance (e.g., stance lock, constrained optimization minimizing embedding drift) for true “copyeditor mode.”
- Tools/workflows: Multi-objective RL (voice/stance preservation + fluency); certified semantic-drift bounds.
- Assumptions/dependencies: Robust, task-relevant semantic metrics; datasets with gold “no-meaning-change” edits; compute.
- Bold: Personalized “voice anchors”
- Sectors: all writing-heavy sectors
- What: Train per-user style/voice profiles (lexicon, POS, LIWC, embeddings) to constrain AI edits toward the author’s authentic voice and away from homogenized modes.
- Tools/workflows: On-device fine-tuning or adapters; privacy-preserving federated learning of voice anchors.
- Assumptions/dependencies: Consent and privacy; sufficient user data; preventing reinforcement of harmful biases.
- Bold: Provenance standards and secure edit logs
- Sectors: academia, government, regulated industries
- What: Standards for cryptographically verifiable edit histories indicating human vs. AI contributions and semantic impact per revision.
- Tools/workflows: W3C-like provenance specs; tamper-evident logs; platform-level adoption (Docs/Word/OpenReview).
- Assumptions/dependencies: Interoperability; legal frameworks recognizing provenance; storage/security costs.
- Bold: Regulatory guidance on AI-mediated communications
- Sectors: public sector, finance, healthcare, elections
- What: Policies requiring disclosure, acceptable-use boundaries, and safeguards against meaning distortion in high-stakes communications (e.g., consent forms, financial disclosures).
- Tools/workflows: Compliance audits using semantic-drift toolchains; standardized disclosure language.
- Assumptions/dependencies: Regulatory consensus; measurement validity; enforcement mechanisms.
- Bold: Benchmarks for “homogenization and drift”
- Sectors: AI research, procurement
- What: Public leaderboards that measure stance preservation, semantic drift, lexical diversity, and criteria-balance in reviews for models and tools.
- Tools/workflows: Curated multi-domain datasets (legal, scientific, journalistic); standardized scoring and test harnesses.
- Assumptions/dependencies: Community agreement; dataset governance; sustained maintenance.
- Bold: Peer-review platform redesign for bias resistance
- Sectors: academia
- What: Structured review UIs that require explicit weighting of clarity/significance versus reproducibility/scalability; automated detection of score inflation and mono-voice indicators.
- Tools/workflows: Rubric-enforced forms; cross-review calibration nudges; reviewer feedback loops.
- Assumptions/dependencies: Cultural buy-in; minimizing reviewer burden; platform engineering.
- Bold: Training objectives that penalize homogenization
- Sectors: AI model development
- What: New pretraining and alignment regimes that reduce “mono-voice” effects and maintain diverse styles without altering meaning.
- Tools/workflows: Diversity-promoting losses, counterfactual training with human-edited pairs, adversarial objectives against stance flip.
- Assumptions/dependencies: Data that represent diverse voices; careful balance with safety/alignment goals.
- Bold: Cultural impact monitoring dashboards
- Sectors: policy, media studies, platforms
- What: Ongoing measurement of stylistic and semantic convergence in public discourse (newsrooms, social platforms), tracking neutrality creep or loss of perspective diversity.
- Tools/workflows: Large-scale sampling, embeddings/LIWC/POS analytics, public reports.
- Assumptions/dependencies: Data access and ethics; representativeness; longitudinal funding.
- Bold: Healthcare and patient-communication guardrails
- Sectors: healthcare
- What: AI-assisted messaging that preserves clinician/patient voice and avoids unintended meaning changes in care plans, consent, and instructions.
- Tools/workflows: EHR-integrated semantic-drift checks; certified “low-drift” models for clinical contexts.
- Assumptions/dependencies: Clinical validation; HIPAA-compliant processing; liability considerations.
- Bold: Cross-cultural and multilingual style fairness
- Sectors: global platforms, education, international organizations
- What: Methods to avoid Western-norm convergence by preserving culturally specific styles and rhetorical norms while editing.
- Tools/workflows: Multilingual/cultural style corpora; per-culture voice anchors and constraints.
- Assumptions/dependencies: High-quality, representative datasets; involvement of cultural experts.
- Bold: Legal standards for authorship and accountability
- Sectors: legal, academia, publishing
- What: Define responsibility and authorship when AI edits change meaning; set norms for credit, liability, and correction policies.
- Tools/workflows: Contract clauses; publication ethics standards; dispute-resolution processes.
- Assumptions/dependencies: Jurisdictional harmonization; case law development; community consensus.
Notes on dependencies across applications:
- Metric reliability: Many applications assume that embedding-based semantic drift, stance detection, LIWC/POS shifts, and LLM-as-a-judge labels are sufficiently accurate; continued validation and bias auditing are required.
- Data access and privacy: Voice profiling and provenance logging rely on access to draft histories and personal writing samples; privacy-preserving designs and consent are essential.
- Human factors: Guardrails that add friction may face adoption barriers; UX design and clear benefits are critical.
- Model access: Some controls require low-level API or architectural access to LLMs; vendor cooperation or on-device/open models may be necessary.
Glossary
- Algorithmic mono voice: The tendency of generative models to produce similarly styled text, leading to stylistic convergence across outputs. "this ``algorithmic mono voice'' may be amplified through repeated exposure to model-generated suggestions"
- Analytical Thinking: A LIWC summary dimension indicating formal, structured, and logical writing. "the Analytical Thinking and Authenticity metrics"
- ArgRewrite-v2: A pre-LLM dataset of student argumentative essays with expert feedback and human revisions, used to compare human vs. LLM edits. "ArgRewrite-v2 \citep{chen2022argrewrite} is a dataset of argumentative writing revisions collected from 86 university students."
- Area chair: A senior reviewer in academic conferences who oversees peer reviews and guides decisions. "who act as ``area chairs.''"
- Authenticity: A LIWC summary dimension reflecting personal voice and honesty in writing. "summary variables (e.g., analytical thinking, clout, and authenticity)"
- Clout: A LIWC summary variable approximating social status, confidence, or leadership in text. "summary variables (e.g., analytical thinking, clout, and authenticity)"
- Coordinating conjunctions: A grammatical category (e.g., and, but, or) used to connect clauses of equal rank. "increase in coordinating conjunctions ( increase)"
- Counterfactual analysis: An evaluation method comparing observed outcomes with hypothetical alternatives to infer causal effects. "we perform a counterfactual analysis, comparing human edits to edits produced by three commonly used LLMs."
- Determiners: Grammatical function words (e.g., the, a, this) that introduce nouns and specify reference. "and determiners ( decrease)"
- Embedding space: A high-dimensional vector space where texts are represented so that semantic similarity corresponds to spatial proximity. "a region of embedding space where no previous human-written essay exists."
- International Conference on Learning Representations (ICLR): A leading machine learning conference whose peer reviews are analyzed in the study. "we analyze peer reviews from the International Conference on Learning Representations (ICLR) \citep{iclr2026}."
- Institutional Review Board (IRB): An ethics committee that approves and oversees research involving human participants. "All procedures were approved by our Institutional Review Board (IRB)."
- Jensen-Shannon Divergence (JSD): A symmetric information-theoretic measure of similarity between probability distributions. "quantify lexical shifts using the Jensen-Shannon Divergence (JSD) \citep{Menndez1997THEJD}."
- Likert-scale: A psychometric response scale used to capture attitudes or perceptions along an ordered range. "Likert-scale self-report scores"
- Linguistic homogenization: The reduction of diversity in language use toward a uniform style. "Recent literature highlights a concerning trend toward linguistic homogenization."
- Linguistic Inquiry and Word Count (LIWC): A lexicon-based tool that quantifies psychological, emotional, and cognitive attributes in text. "we also employ the Linguistic Inquiry and Word Count (LIWC) tool"
- LLM-as-a-Judge: Using a LLM to evaluate, classify, or label text as an automated judge. "We use gpt-4o as an LLM-as-a-Judge"
- MiniLM-L6-v2: A compact transformer model used to produce sentence embeddings for semantic analysis. "embedded using MiniLM-L6-v2 \citep{reimers2019sentencebertsentenceembeddingsusing} sentence embeddings"
- NRC Emotion Lexicon: A lexicon mapping words to basic emotions and sentiments for affect analysis. "we utilize the NRC (National Research Council - Canada) Emotion Lexicon \citep{mohammad2013nrc}."
- Pangram AI tool: A classifier used to detect AI-generated text in peer reviews. "Detection was performed using the Pangram AI tool"
- Part-of-speech (POS) distributions: The frequency distribution of grammatical categories (e.g., nouns, verbs) within text. "part-of-speech distributions"
- Principal Component Analysis (PCA): A dimensionality reduction technique to identify major axes of variation in high-dimensional data. "we apply Principal Component Analysis (PCA) to the embedding representation."
- Prolific: An online platform for recruiting research participants for behavioral studies. "Participants were recruited from Prolific."
- Randomized Controlled Trial (RCT): An experimental design where participants are randomly assigned to conditions to infer causal effects. "we first conduct a randomized controlled trial (N=100)"
- Reinforcement Learning from Human Feedback (RLHF): A training paradigm where models are optimized using rewards derived from human preferences. "training with paradigms such as RLHF"
- Semantic shift: A change in the meaning or conceptual content of text, often measured via embeddings. "LLM-generated revisions display a larger and more consistent semantic shift than human-written revisions"
- Sentence embeddings: Dense vector representations of sentences capturing semantic content. "embedded using MiniLM-L6-v2 \citep{reimers2019sentencebertsentenceembeddingsusing} sentence embeddings"
- t-SNE: A non-linear dimensionality reduction method for visualizing high-dimensional data in two or three dimensions. "t-SNE of each essay produced in the RCT embedded using MiniLM-L6-v2 \citep{reimers2019sentencebertsentenceembeddingsusing}."
- t-test: A statistical test used to compare means between groups. "using a t-test."
- Unigram (word count) distributions: Probability distributions over individual word frequencies used for lexical analysis. "the divergence between the unigram (word count) distributions"
Collections
Sign up for free to add this paper to one or more collections.