BankerToolBench: Evaluating AI Agents in End-to-End Investment Banking Workflows
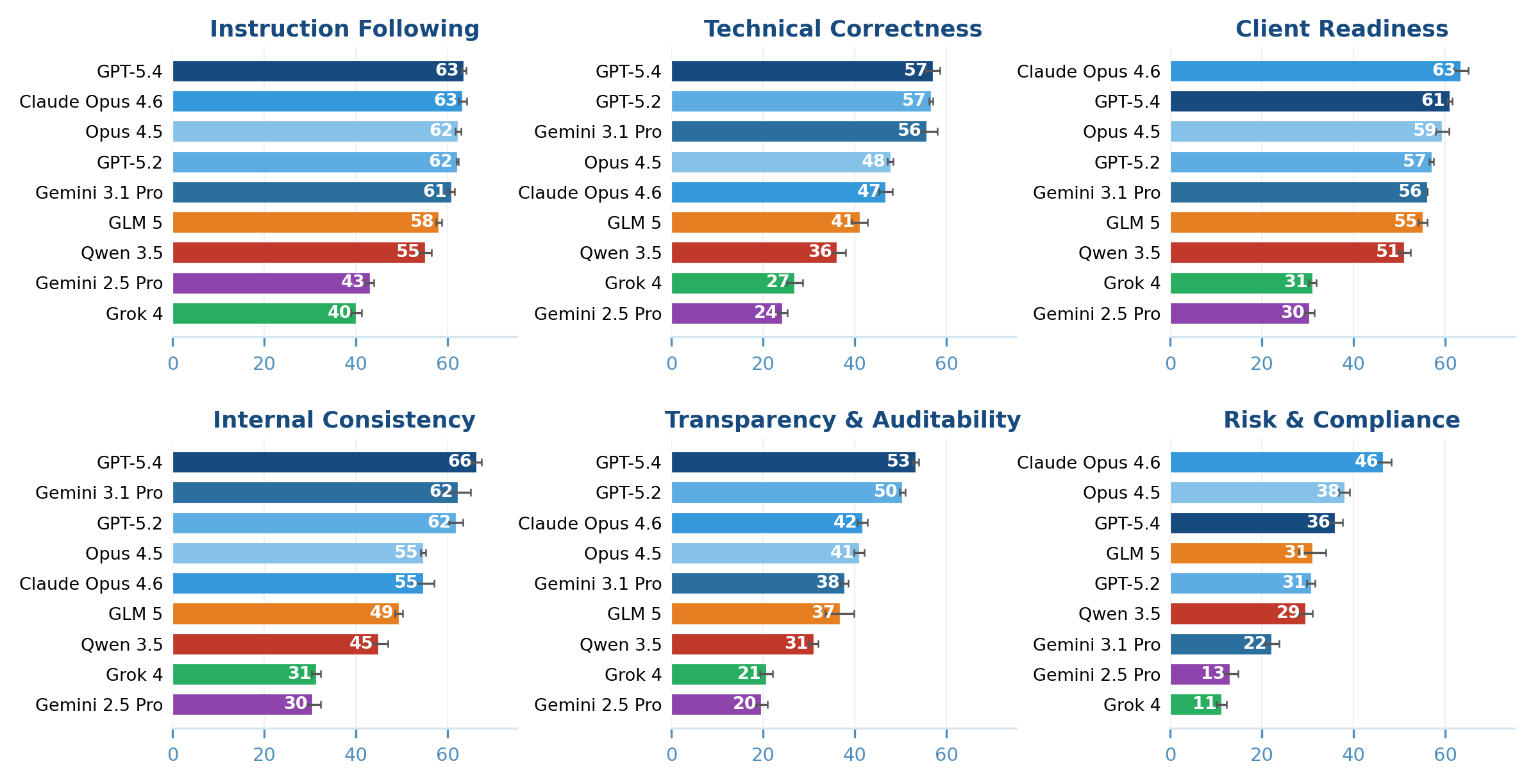
Abstract: Existing AI benchmarks lack the fidelity to assess economically meaningful progress on professional workflows. To evaluate frontier AI agents in a high-value, labor-intensive profession, we introduce BankerToolBench (BTB): an open-source benchmark of end-to-end analytical workflows routinely performed by junior investment bankers. To develop an ecologically valid benchmark grounded in representative work environments, we collaborated with 502 investment bankers from leading firms. BTB requires agents to execute senior banker requests by navigating data rooms, using industry tools (market data platform, SEC filings database), and generating multi-file deliverables--including Excel financial models, PowerPoint pitch decks, and PDF/Word reports. Completing a BTB task takes bankers up to 21 hours, underscoring the economic stakes of successfully delegating this work to AI. BTB enables automated evaluation of any LLM or agent, scoring deliverables against 100+ rubric criteria defined by veteran investment bankers to capture stakeholder utility. Testing 9 frontier models, we find that even the best-performing model (GPT-5.4) fails nearly half of the rubric criteria and bankers rate 0% of its outputs as client-ready. Our failure analysis reveals key obstacles (such as breakdowns in cross-artifact consistency) and improvement directions for agentic AI in high-stakes professional workflows.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “BankerToolBench: Evaluating AI Agents in End‑to‑End Investment Banking Workflows”
What is this paper about?
This paper introduces BankerToolBench (BTB), a big, realistic “test” for AI systems to see if they can do the kinds of tasks junior investment bankers do from start to finish. Instead of just answering questions, AIs have to gather real information, build spreadsheets, make slides, and write reports—just like a person would on the job.
Think of it like a full school project: not just answering a quiz, but researching, doing calculations, making a slideshow, and turning in everything neatly and correctly.
What questions were the researchers trying to answer?
- Can today’s top AIs actually do complex, professional work—not just short answers—on their own?
- If we ask an AI to complete real banking tasks (like building a financial model and a pitch deck), how good are the results?
- Where do AIs mess up most, and how can we improve them?
How did they study it?
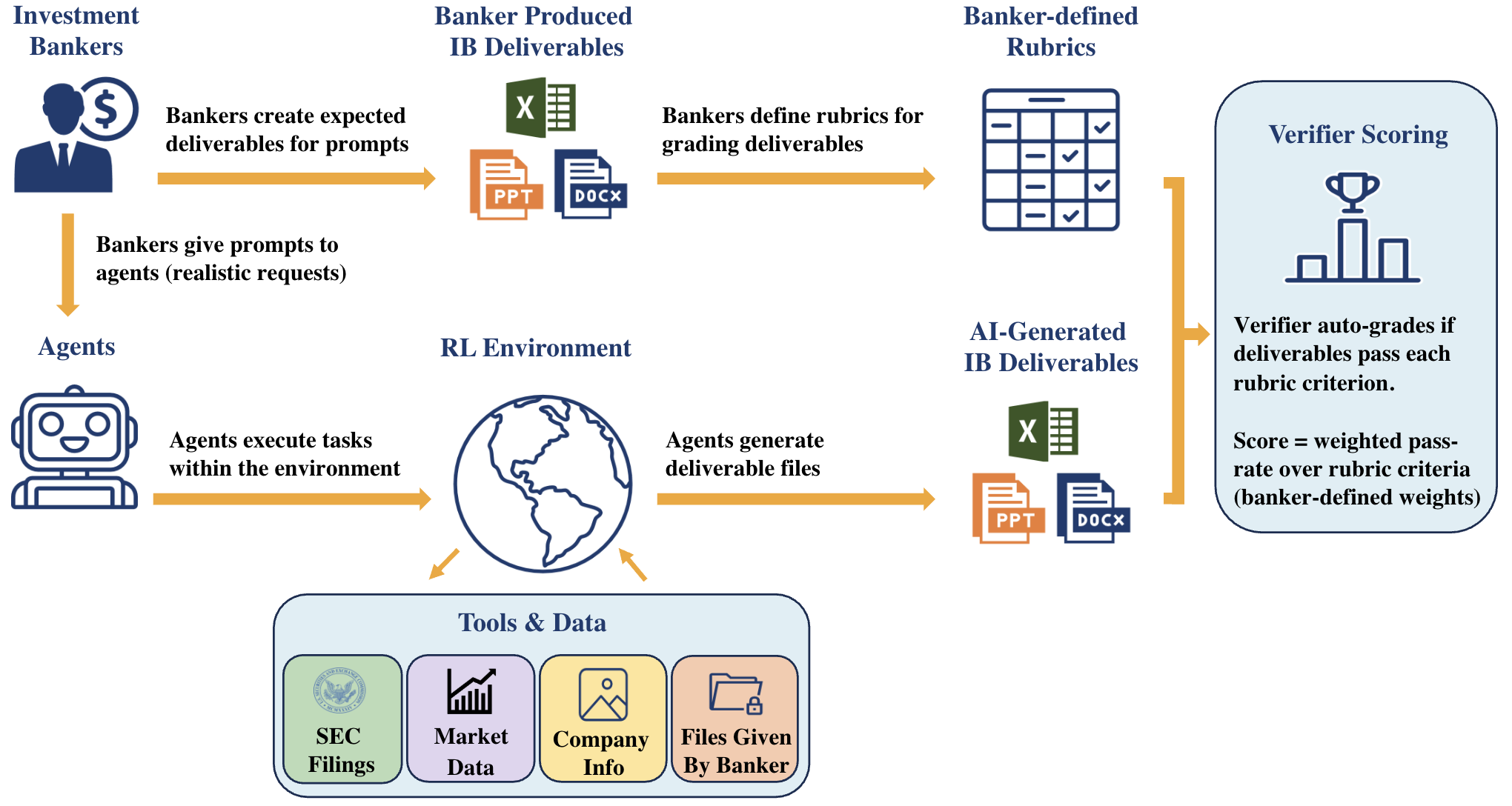
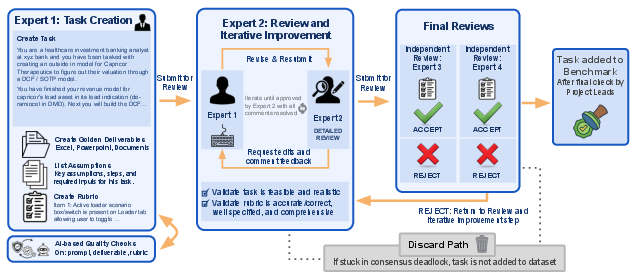
The team built a realistic testing setup with the help of 502 real investment bankers from top firms. They designed 100 end-to-end tasks that junior bankers regularly do.
Here’s how the test works, in everyday terms:
- The AI gets a realistic “boss request” (the prompt), like “build a company valuation and make a client-ready slide deck.”
- The AI works inside a locked-down “sandbox computer” with:
- A “data room” (like a digital folder of real files)
- Tools similar to what bankers use (for example, getting stock prices or reading SEC filings)
- Common software to make Excel spreadsheets, PowerPoint slides, and Word/PDF reports
- The AI must produce real files—often multiple files that must agree with each other.
- The results are graded with detailed checklists (rubrics) written by veteran bankers.
To grade fairly and consistently, they built an automated “referee” agent called Gandalf:
- It opens the files, runs code when needed, checks formulas in Excel, looks for specific numbers, and verifies formatting and consistency across files.
- It uses a pass/fail checklist with weights for importance (e.g., “critical” issues matter most).
- Its grades match human banker judgments closely, so it’s a reliable grader.
The researchers then ran 9 top AI models through the same setup to compare performance.
What did they find?
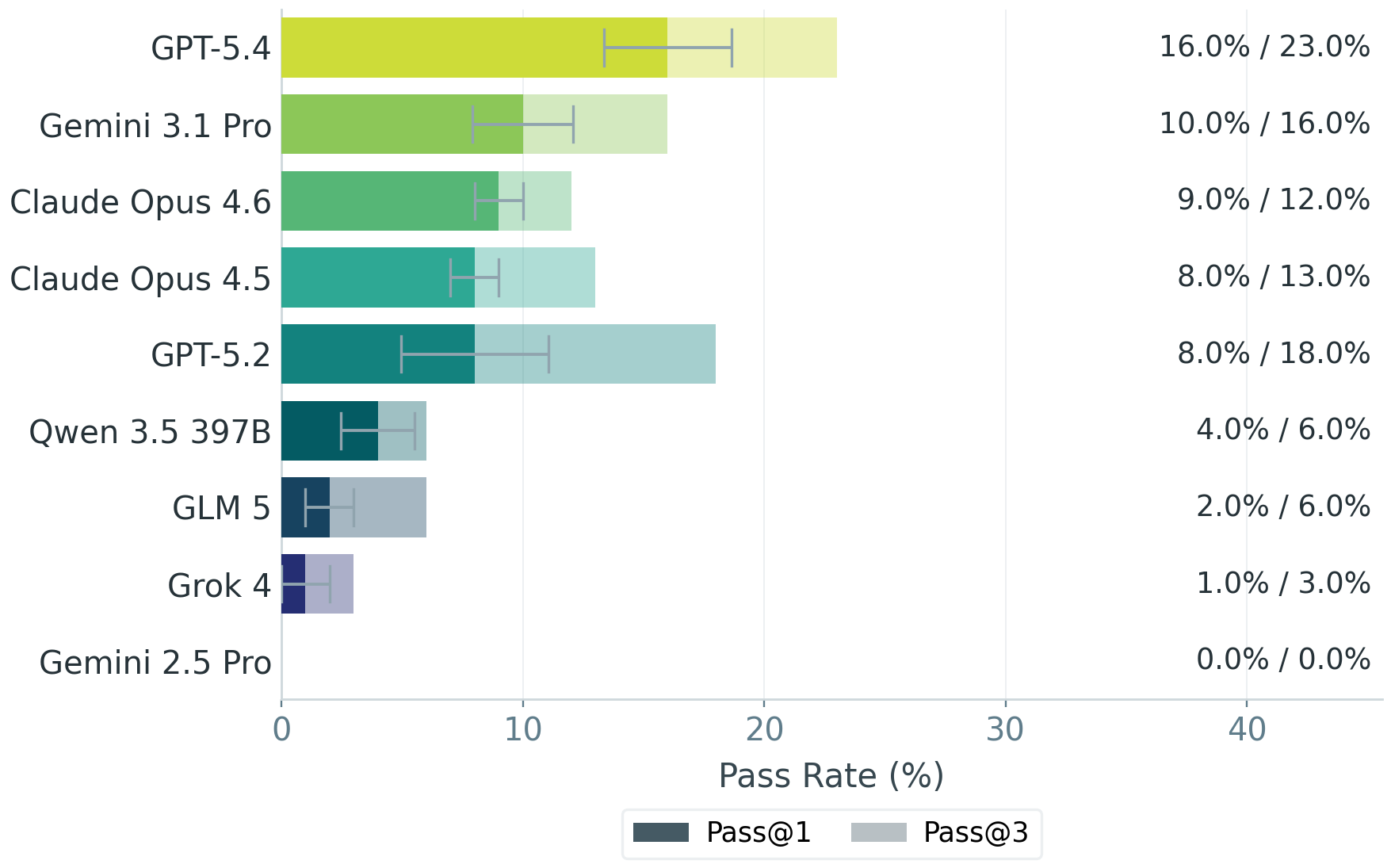
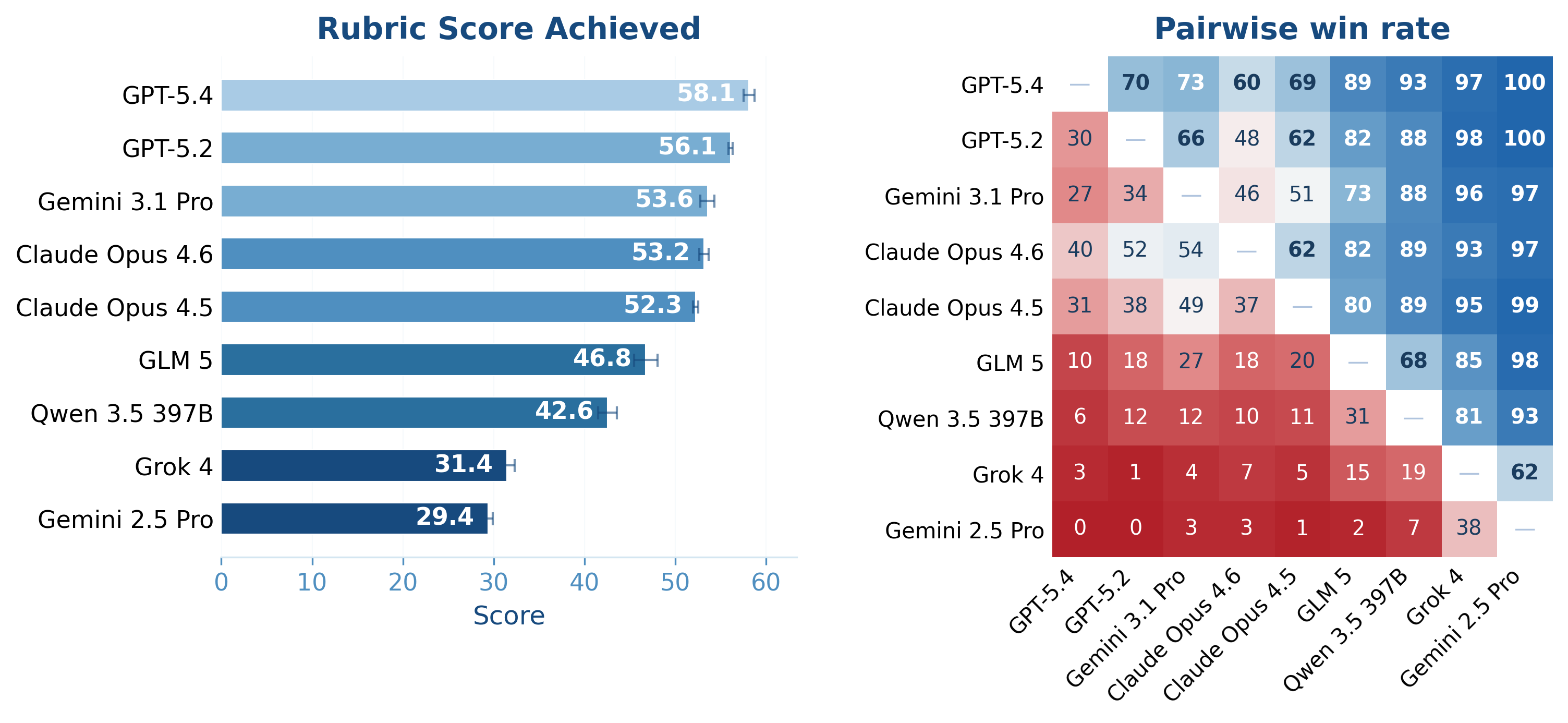
- Even the best AI struggled. The top model (called GPT‑5.4 in the paper) still failed nearly half of the grading criteria on average.
- Bankers rated zero of the AI-produced deliverables as truly client‑ready.
- Only a small fraction of tasks met a reasonable quality bar (the best model passed about 16% of tasks by a more lenient standard).
- AIs often tripped over “human” details that matter in real work:
- Keeping numbers, names, and facts consistent across many files and tabs
- Using correct, auditable formulas (not just typing in numbers)
- Following professional formatting and naming conventions
- Clearly showing where data came from and what assumptions were made
- Including proper disclaimers and risk notes
Why this is important: A single banking task can take a human up to 21 hours. If AI could reliably do this, it would save huge amounts of time and money. But today’s AIs aren’t consistently reliable enough for high‑stakes client work.
Why does this matter, and what’s the impact?
- For businesses: Don’t expect current AIs to replace junior bankers yet. They can help with parts (like drafting or data lookup), but full handoff is risky.
- For AI developers: BTB shows exactly where AIs fail in real workflows—especially cross‑file consistency, correct formulas, auditability, and “client polish.” This gives a clear roadmap for improvements.
- For researchers: BTB is open-source, realistic, and repeatable. It moves beyond toy tests to measure whether an AI can deliver complete, usable work products.
- For the economy: As AIs get better at these complex tasks, the potential productivity gains are large. BTB helps track real progress toward that goal, not just scores on simple benchmarks.
In short: The paper builds a tough, realistic test for AI in investment banking. Today’s AIs can’t consistently meet professional standards for end-to-end tasks, but this benchmark shows where to focus so future AIs can become truly useful for high‑skill jobs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated concretely so future work can address them.
- External validity beyond U.S. public-company contexts is untested:
- Tasks, tools, and rubrics rely on SEC/EDGAR and U.S.-centric conventions. How well does performance transfer to IFRS regimes, non-U.S. regulatory filings (e.g., SEDAR, Companies House), and non-English deliverables?
- Private-company workflows (limited disclosures, sparse data) are minimally represented.
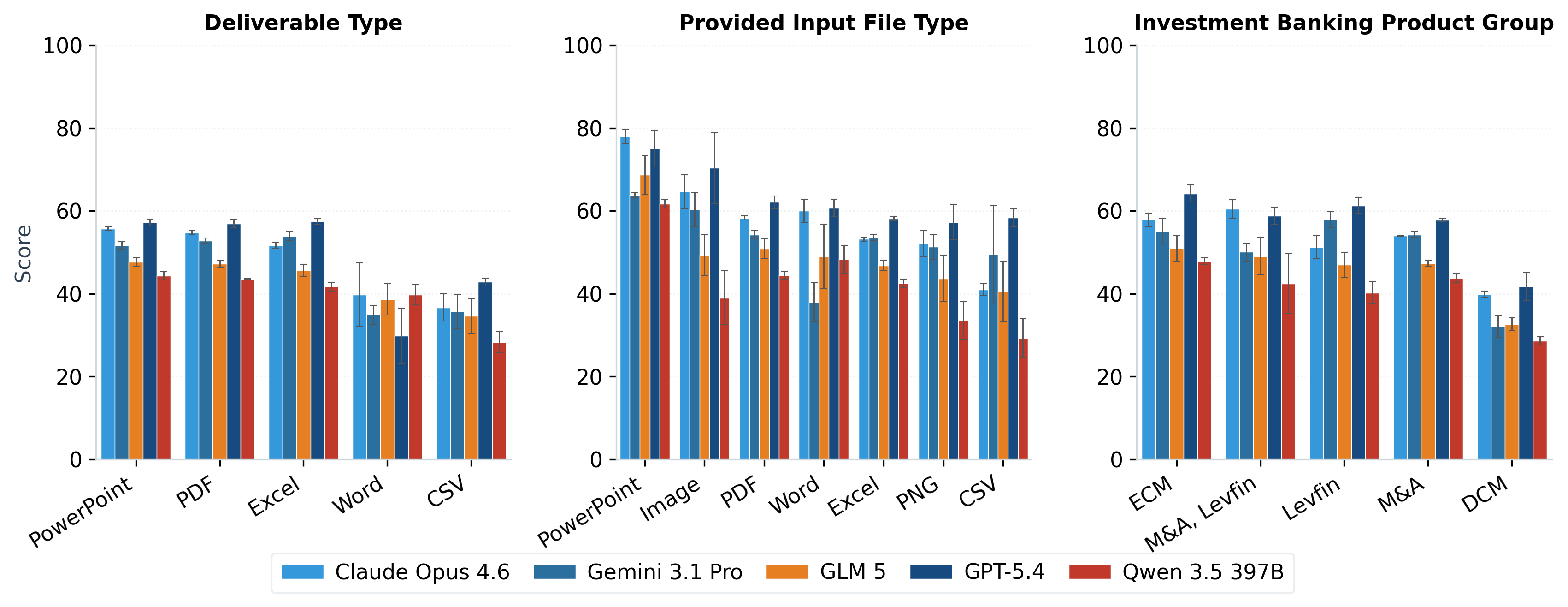
- Task distribution representativeness and coverage:
- Benchmark skews to M&A (62%) with small-n subcategories (1–3% each); statistical reliability for rare subcategories is unclear. How sensitive are model rankings to this mix?
- Many high-value IB tasks (e.g., live deal iteration, diligence coordination, client Q&A prep, negotiation strategy) are not modeled.
- Realism of software/tooling environment:
- Environment uses LibreOffice and Python libraries rather than Microsoft Office; no VBA/macro support, add-ins, or bank-specific templates. How much does this misalign with real banker workflows (e.g., Excel Data Tables, circulars, firm-standard macros)?
- Only three MCP tools are provided (market data, EDGAR, company profile). How would results change with richer ecosystems (e.g., Bloomberg, Capital IQ, PitchBook, SNL, Reorg, Refinitiv), internal knowledge bases, and asset libraries?
- Visual fidelity of PowerPoint outputs (fonts, templates, color palettes, brand lockups) is not fully evaluated under enterprise Office rendering.
- Evaluation and verifier robustness:
- A single agent-as-judge (Gandalf) with one underlying LLM (Gemini 3 Flash Preview) is used. Cross-judge robustness, cross-provider bias, and ensemble-judge agreement are not reported.
- Susceptibility to reward hacking/Goodhart effects is untested: can agents game rubrics (formatting, naming) without improving true client readiness?
- Adversarial inputs and file pathologies (linked workbooks, hidden sheets, external references, protected cells, corrupted files) are not stress-tested.
- No analysis of false positives/negatives by criterion category (e.g., formula integrity vs presentation polish) or failure modes specific to spreadsheets vs slides vs PDFs.
- Rubric design and validity:
- Criterion weights (1/3/5/10) and category allocations are based on expert judgment; no sensitivity analysis shows whether model rankings are stable to different weights.
- Cross-firm convention diversity is not modeled (banks differ on tab naming, color coding, disclaimer standards, KPI definitions). How portable are rubrics across firms and sectors?
- Alternative valid methodologies (e.g., valuation choices, normalizations, treatment of non-GAAP metrics) may be penalized. How tolerant are rubrics to justified deviations?
- Human baselines and ceilings:
- Human-authored “expected deliverables” are not graded to establish human Score distributions. What is the human performance ceiling, interquartile range, and inter-rater spread by task type?
- Time/error trade-offs for humans vs agents and mixed-initiative setups (co-pilot workflows) are not quantified.
- Economic metrics and feasibility:
- Cost/latency/resource usage per task (e.g., 539 LLM calls) is not reported; ROI relative to human hours and compute costs remains unknown.
- Pass/Score thresholds mapping to “client-ready” are derived from an internal study; external validation across banks and MD-level standards is not presented.
- Generalization and transfer:
- Robustness to market regime shifts (e.g., zero-rate era vs tightening cycles), differing sector structures (regulated industries, financials/insurance), and cross-cycle assumptions is not studied.
- OOD resilience to missing, lagged, noisy, or conflicting source data is unmeasured.
- Task process realism:
- Multi-actor workflows (analyst–associate–VP–MD feedback cycles), redlines, comment resolution, and rapid “turns” under time pressure are not simulated.
- Communication artifacts (emails, Slack threads), meeting pre-reads, and verbal ambiguity negotiation are absent.
- Internet and knowledge access:
- Internet is disabled; many real tasks require web research, press releases, primary sources, and vendor portals. How does enabling safe web access change outcomes and failure modes?
- Dataset governance and leakage:
- Open rubrics and sample expected deliverables introduce risks of overfitting/benchmark gaming; no hidden test sets or periodic refresh strategy is described.
- Judge–agent provider coupling is partly mitigated (Gemini as judge), but training-time exposure to rubric patterns is not controlled; contamination risks are not audited.
- Reliability and reproducibility:
- MCP data fidelity and versioning are not documented (e.g., if the API schema or backfilled data change). How reproducible are scores across time and environment versions?
- Library/version sensitivity (pandas/openpyxl/libreoffice) and sandbox determinism are not benchmarked.
- Failure mode taxonomy depth:
- The paper notes cross-artifact consistency breakdowns but does not release a fine-grained, labeled taxonomy of error types or per-category error rates to guide targeted model improvements.
- Agent harness dependence:
- Only a baseline harness is primary; systematic ablations on planning, memory, tool-use strategies, and self-verification loops are not reported. How large is the harness effect relative to the base model?
- Safety and compliance evaluation:
- Although “Risk & Compliance” criteria exist, there is no dedicated evaluation of hallucinated legal claims, inappropriate comparative statements, or misguiding financial advice risks and mitigations.
- Internationalization and accessibility:
- Non-English tasks, region-specific formats (e.g., decimal/thousand separators, date conventions), and localization of disclosures and legal language are not included.
- Benchmark scope and maintenance:
- At 100 tasks, coverage of the long tail of workflows is limited; update cadence, task refresh processes, and sunset policies for stale tasks are unspecified.
- Ethical and workforce impacts:
- The broader implications of automating junior IB workflows, skill erosion, and oversight frameworks are not addressed.
- Practical deployment questions:
- How to integrate agent outputs into bank IT (DLP controls, model risk management, audit trails) is unexamined.
- How well do agents interoperate with proprietary data entitlements and compliance constraints (e.g., restricted lists, MNPI handling)?
- Post-training to the verifier:
- While the verifier is “good enough for RL,” no empirical results show that optimizing to Gandalf improves human-rated client readiness without overfitting to rubric artifacts.
- Multimodal evaluation depth:
- Grading of charts/tables/visuals emphasizes structural checks; calibration to perceived clarity, information density, and executive readability is not validated with blinded human panels.
- Statistical power and reporting:
- Confidence intervals for overall model rankings, per-category scores, and task-subset analyses (e.g., LBO vs DCF) are not reported; small-sample variance for rare subcategories is unclear.
These gaps suggest concrete avenues for future work: add non-U.S./private-company tasks; integrate Microsoft Office and VBA; expand/validate rubrics across firms and jurisdictions; ensemble multiple verifiers and conduct sensitivity analyses; establish hidden test sets; report human baselines, cost/latency; simulate multi-actor workflows and feedback cycles; enable safe web tools; and publish a detailed error taxonomy with per-category metrics.
Practical Applications
Immediate Applications
The following applications can be deployed today using the released benchmark, verifier, and environment. They translate BTB’s tasks, rubrics, and agentic verifier into concrete workflows for industry, academia, policy, and education.
- Benchmark-driven vendor selection and procurement (Finance, Software/AI)
- Use BTB as an internal “fitness test” to compare LLMs/agents for investment banking tasks before purchase or deployment, using pass thresholds and rubric-weighted scores aligned to client-readiness.
- Tools/workflows: Harbor environment for reproducible runs; Gandalf agent-as-a-judge for automated grading; CI dashboards for model score tracking.
- Assumptions/dependencies: Compute/ops capacity to run BTB; adaptation of rubrics to firm conventions; sandboxed environment (no internet) consistent with BTB’s historical data assumption.
- Human-in-the-loop QA gates for client deliverables (Finance)
- Integrate Gandalf to auto-check Excel/PPT/Word artifacts (formulas, cross-file consistency, rubric criteria) prior to sending to VPs/MDs/clients; flag critical failures (e.g., missing disclosures, broken formulas).
- Tools/workflows: Gandalf integrated with document management systems; Office automation via openpyxl/python-pptx; rubric-driven “deliverable linter.”
- Assumptions/dependencies: Legal/compliance approval for automated checks; adaptation to firm formatting/naming standards; accurate rubric mapping to teams’ workflows.
- Analyst onboarding and upskilling with automated feedback (Finance, Education)
- Use BTB tasks and expected deliverable exemplars as training labs; Gandalf provides granular, rubric-aligned feedback on Excel models, pitchbooks, and memos.
- Tools/workflows: Internal training portals with BTB tasks; automated scoring and feedback loops; progress dashboards by rubric category (e.g., Technical Correctness vs. Client Readiness).
- Assumptions/dependencies: Customization to firm-specific conventions; time allocation for training; governance of scored assessments.
- Continuous evaluation/regression testing for internal copilots (Finance, Software/AI)
- Treat BTB as a standardized test suite to catch performance regressions when updating model versions, tools, or prompts for internal AI assistants.
- Tools/workflows: Harbor-based CI pipelines; pass@k thresholds; alerts tied to high-importance rubric criteria (critical/major).
- Assumptions/dependencies: Stable compute budget; version control around prompts/agents; disciplined MLOps.
- Targeted model improvement via BTB-guided post-training (Software/AI, Research)
- Use Gandalf’s pass/fail signals as a reward for RL post-training on investment banking workflows; prioritize failure modes (e.g., cross-artifact consistency) revealed by BTB.
- Tools/workflows: RL pipelines; reward shaping by rubric category; ablations on memory, tool-use reliability, formula generation.
- Assumptions/dependencies: Verifier accuracy ~88% (sufficient but imperfect); guard against reward hacking; compute and data budgets.
- Pre-deployment risk assessment and policy setting (Finance, Policy/Governance)
- Translate BTB score distributions and pass rates into internal risk policies (e.g., “AI outputs must pass all critical criteria and be human-reviewed”); define deployment scope (draft-only vs. client-ready).
- Tools/workflows: Risk dashboards; approval workflows gated by BTB-equivalent checks; exception handling.
- Assumptions/dependencies: Executive buy-in; harmonization with existing model risk management frameworks.
- Failure-mode diagnostics and tool-chain hardening (Finance, Software/AI)
- Use BTB failure analysis to prioritize engineering investments (e.g., spreadsheet formula integrity, cross-file name/number reconciliation, compliance disclaimers).
- Tools/workflows: Consistency checkers for Excel/PPT; structured “artifact graphs” tying values/formulas/labels across files; error surfacing in IDE-like UIs.
- Assumptions/dependencies: Instrumentation to track cross-artifact links; Office suite automation; data provenance capture.
- Academic research platform for agentic AI (Academia/Research)
- Study long-horizon reasoning, tool-use reliability, and multi-artifact generation; compare harnesses (e.g., OpenHands/OpenCode) under controlled, reproducible conditions.
- Tools/workflows: Harbor experiments; open-source Gandalf; rubric taxonomy for research on evaluation validity and psychometrics.
- Assumptions/dependencies: Access to model APIs or open models; compliance with BTB’s historical-date constraint.
- Recruiting and performance assessment (Finance, Education)
- Deploy BTB tasks as standardized, auto-graded exercises for candidate screening or periodic skill checks for analysts/associates.
- Tools/workflows: Proctored sandboxes; Gandalf scoring with category breakdowns; benchmark-based thresholds by role level.
- Assumptions/dependencies: Fairness/legal review; anti-cheating controls; localization to region-specific accounting practices.
- Productization of “grading-as-a-service” for enterprise documents (Software/AI)
- Offer Gandalf-like agent-as-a-judge for non-IB artifacts (e.g., board decks, FP&A models, sales proposals) to ensure structure, formulas, and disclosures meet internal standards.
- Tools/workflows: API for document upload; customizable rubrics; integrations with SharePoint/Box/Drive.
- Assumptions/dependencies: Domain-specific rubrics; verifier accuracy tuning; liability management.
Long-Term Applications
These applications require further model reliability, scaling, or organizational changes. They extend BTB’s methods and signals into broader automation, governance, and cross-industry standards.
- Partial automation of junior banker workflows with human oversight (Finance)
- Agents prepare first-draft LBO/DCFs, trading comps, and pitchbooks that satisfy critical rubric criteria; bankers focus on judgment and storytelling.
- Tools/workflows: Generator+checker (Gandalf) pipelines; structured assumption templates; automated sensitivity tables and data tables.
- Assumptions/dependencies: Significant gains in cross-artifact consistency, formula correctness, and instruction following; robust audit trails.
- Autonomous multi-file deliverable copilot integrated with Office and data rooms (Finance, Software/AI)
- A “deal workspace” that ingests market/SEC data, updates models, refreshes slides, and maintains consistent numbers and labels across artifacts.
- Tools/workflows: Bi-directional connectors to market data/EDGAR; artifact-graph to enforce coherence; versioned update logs.
- Assumptions/dependencies: Model upgrades; strong IT integration; permissions and data governance.
- Standardized regulatory benchmarks for high-stakes AI in finance (Policy/Regulation)
- Regulators adopt BTB-like benchmarks and pass thresholds as preconditions for autonomous AI use in client-facing materials or transaction execution.
- Tools/workflows: Certification workflows; public scorecards; audit packages including rubric coverage and verifier reliability.
- Assumptions/dependencies: Industry consensus; regulator capacity to maintain evolving standards; vendor cooperation.
- Generalized agent-as-a-judge platforms for complex enterprise artifacts (Software/AI, Cross-industry)
- “Gandalf for X” services for legal contracts, clinical documentation, energy project finance models, or safety-critical SOPs.
- Tools/workflows: Domain rubrics co-developed with practitioners; file-type specific instrumentation (e.g., CAD, EHR, BIM).
- Assumptions/dependencies: High-quality, domain-specific rubrics; demonstrable inter-rater agreement vs. experts.
- Cross-artifact consistency engines and integrity checkers (Software/AI)
- Systematically enforce consistency across numbers, formulas, and labels spanning Excel, PPT, and Word, with provenance and dependency tracing.
- Tools/workflows: Artifact graphs; constraint solvers for formula structures; reconciliation reports with suggested fixes.
- Assumptions/dependencies: Standardized file interfaces; agent reasoning about dependencies; enterprise adoption.
- RL ecosystems and curriculum learning for professional workflows (Software/AI, Academia)
- Use BTB tasks and Gandalf rewards to build curriculum schedules (from simpler valuation tasks to full sell-side pitchbooks), advancing agent reliability.
- Tools/workflows: Self-play and iterative improvement; task difficulty scaffolding; reward decomposition by rubric category.
- Assumptions/dependencies: Stable, high-quality reward signals; mitigation for reward hacking; compute.
- Auditability, transparency, and provenance toolchains (Finance, Policy)
- End-to-end capture of assumptions, data sources, and modeling choices with change logs linking cells, slides, and footnotes.
- Tools/workflows: Provenance metadata embedded in files; auto-generated appendix pages; audit reports aligned to risk/compliance rubrics.
- Assumptions/dependencies: Organizational requirements for explainability; standardized metadata schemas.
- Expansion of BTB methodology to adjacent domains (Consulting, Law, Healthcare, Energy)
- Create deep, domain-specific benchmarks and verifiers for client deliverables (e.g., legal closing binders, clinical care plans, project finance models).
- Tools/workflows: Job Task Analysis per domain; practitioner-authored rubrics with 100+ criteria; environment/tooling adapted to domain software.
- Assumptions/dependencies: Expert time investment; data-sharing constraints; validation against practitioner standards.
- Procurement standards and benchmarking consortia (Finance, Policy)
- Banks and vendors align on shared scoring frameworks (rubric coverage, category weighting) to reduce vendor lock-in and improve comparability.
- Tools/workflows: Common evaluation profiles; third-party auditors; shared leaderboards with interpretability (pass@k, critical-failure rates).
- Assumptions/dependencies: Industry collaboration; legal frameworks for score sharing.
- Live-deal assistants and continuous update pipelines (Finance)
- Agents monitor market/filing changes, auto-update models and slides, and surface material changes for banker sign-off.
- Tools/workflows: Event-driven triggers; change highlighting; approval queues and checklists.
- Assumptions/dependencies: Reliable detection of materiality; robust incremental updates without drift.
- Multi-agent “generator–verifier–editor” workflows (Software/AI)
- Coordinated agents produce drafts, verify against rubrics, and propose remediations; escalate unresolved issues to humans.
- Tools/workflows: Orchestration frameworks; error taxonomy routing by rubric category; learning from human edits.
- Assumptions/dependencies: Stable interfaces and memory; clear escalation policies; alignment of incentives.
- Education and credentialing based on deliverable competence (Education, Professional Certification)
- Certifications awarded via standardized, auto-graded tasks that reflect real analyst work quality and client readiness.
- Tools/workflows: Secure task delivery; proctoring; rubric-aligned grading reports and remediations.
- Assumptions/dependencies: Acceptance by employers; robust anti-cheating measures; periodic rubric updates.
These applications leverage BTB’s core innovations—profession-grade tasks, multi-file deliverables, expert-authored rubrics with 100+ criteria, and a file-aware agentic verifier—to enable practical deployment today and chart a path toward reliable automation of high-stakes professional workflows.
Glossary
- Acquisition Matrix: A grid used to evaluate potential acquisitions across defined criteria. "Acquisition Matrix"
- Adjusted EPS: Earnings per share adjusted to exclude non-recurring or non-cash items. "EPS vs.\ Adjusted EPS"
- agent-as-a-judge: An autonomous grading agent that evaluates deliverables against a rubric. "we developed a novel agent-as-a-judge verifier called Gandalf"
- APEX-Agents: A benchmark assessing agentic systems on multi-step professional tasks. "APEX-Agents covers investment banking, corporate law, and management consulting."
- Archipelago: A grading workflow used in APEX-Agents that serializes artifacts before scoring. "serialize-then-grade workflow implemented in Archipelago for APEX-Agents"
- bid-ask spreads: The difference between the best prices to buy and sell, indicative of market liquidity. "tighter bid-ask spreads that improved market liquidity and price discovery"
- Capitalization Table: A table detailing a company’s ownership, securities, and their dilution pre/post-transaction. "Capitalization Table (Pre/Post)"
- client-ready deliverables: Outputs sufficiently accurate and polished to be sent to clients. "client-ready deliverables—including Excel financial models, PowerPoint pitch decks, and PDF/Word reports."
- Confidential Information Memorandum: A detailed marketing document used in private company sales to inform prospective buyers. "Confidential Information Memorandum"
- construct underrepresentation: A psychometric flaw where an assessment fails to capture the full scope of the intended construct. "a form of construct underrepresentation"
- Covenant headroom: The cushion between current performance and debt covenant limits. "Covenant Headroom Prompts"
- data provenance: Documentation of the sources and transformations behind reported figures or conclusions. "data provenance, assumption disclosure"
- data room: A secure repository of deal documents and data for due diligence access. "navigating data rooms"
- Debt Capacity Analysis: An assessment of how much debt a company can sustainably carry. "Debt Capacity Analysis"
- Debt Capital Markets (DCM): The sector focused on raising capital via debt instruments. "Debt Capital Markets (DCM)"
- Discounted Cash Flow (DCF): A valuation method based on discounting projected future cash flows. "Discounted Cash Flow Analysis (DCF)"
- EDGAR: The SEC’s public database for company filings. "an SEC EDGAR API"
- Equity Capital Markets (ECM): The sector focused on raising capital via equity issuance. "Equity Capital Markets (ECM)"
- Excel Data Table: An Excel feature for creating sensitivity tables by varying inputs. "Sensitivity table is properly constructed using Excel Data Table functionality or equivalent formula array"
- Gandalf: The agent-as-a-judge verifier used to grade complex files in BTB. "Gandalf is an agent, built on top of the production-quality OpenHands agent harness"
- GDPVal: A cross-occupation benchmark evaluating agent economic utility. "GDPVal covers 44 occupations"
- Harbor (environment): The framework that packages BTB tasks and sandboxes agent runs. "the \textsf{Harbor} environment for running the benchmark."
- High-frequency trading: Algorithmic trading at very high speeds that exploits small price discrepancies. "A well-known example is high-frequency trading"
- inter-rater agreement: The degree of consistency among different human graders. "human inter-rater agreement = 84.6\%"
- Job Task Analysis (JTA): A structured method to identify and prioritize critical real-world job tasks. "a Job Task Analysis (JTA) survey"
- Leveraged buyout (LBO): An acquisition funded primarily with debt secured by the target’s cash flows. "a leveraged buyout (LBO) task in BTB."
- Leveraged Finance (LevFin): Financing focused on highly leveraged transactions like LBOs. "Leveraged Finance (Levfin)"
- market data platform: An API providing structured financial data (prices, estimates, financials). "a market data platform API"
- market liquidity: The ease with which assets can be traded with minimal price impact. "improved market liquidity"
- MCP tools: Model Context Protocol tools for standardized agent tool-calling. "Agents can call three MCP tools"
- Merger Model: A financial model evaluating the combined performance of two merging firms. "Merger Model"
- Mergers & Acquisitions (M&A): Corporate transactions involving the buying, selling, or combining of companies. "Mergers {paper_content} Acquisitions (M{paper_content}A)"
- model integrity: Correctness and coherence of formulas and logic within a financial model. "Model integrity graded"
- OpenHands agent harness: A production-grade agent framework used to implement Gandalf. "the production-quality OpenHands agent harness"
- Pass@k: The proportion of tasks passed within k sampled attempts. "Pass@1"
- Pitchbook: A client-facing presentation used to pitch ideas or transactions. "a pitchbook PowerPoint presentation (preparing client materials)."
- Precedent transactions: Valuation using multiples from comparable historical deals. "Precedent Transactions"
- price discovery: The market process of determining asset prices from supply and demand. "price discovery"
- Pro forma EPS: Earnings per share adjusted to reflect a proposed transaction’s effects. "Pro forma EPS calculations are correct: Pro Forma NI / Pro Forma Shares"
- psychometric principles: Measurement standards guiding validity and reliability in assessment design. "BTB is grounded in psychometric principles"
- reinforcement learning environment (RLE): An interactive setup where agents take actions and receive feedback. "BTB is designed as a reinforcement learning environment (RLE)"
- SEC filings: Regulatory documents companies submit to the U.S. Securities and Exchange Commission. "retrieve SEC filings"
- sensitivity table: A table showing how outputs change with variation in key inputs. "Sensitivity table is properly constructed using Excel Data Table functionality or equivalent formula array"
- Sources & Uses (S&U): A schedule showing how a transaction is funded and what the funds are used for. "Sources {paper_content} Uses (S{paper_content}U)"
- stratified expert survey: A sampling approach ensuring representation across predefined subgroups. "Stratified expert survey"
- Teaser: A brief, anonymized marketing document sent to gauge buyer interest. "Teaser"
- Trading comparables: Valuation based on trading multiples of peer companies. "Trading Comparables"
- Use of Proceeds Analysis: A breakdown of where raised capital will be allocated. "Use of Proceeds Analysis"
- Valuation ranges: Intervals of estimated company value based on applied methodologies. "Valuation Ranges"
- Verifier: An automated judge that scores deliverables against rubrics. "an LLM-powered agentic verifier"
Collections
Sign up for free to add this paper to one or more collections.

