Why LLMs Aren't Scientists Yet: Lessons from Four Autonomous Research Attempts
Abstract: We report a case study of four end-to-end attempts to autonomously generate ML research papers using a pipeline of six LLM agents mapped to stages of the scientific workflow. Of these four, three attempts failed during implementation or evaluation. One completed the pipeline and was accepted to Agents4Science 2025, an experimental inaugural venue that required AI systems as first authors, passing both human and multi-AI review. From these attempts, we document six recurring failure modes: bias toward training data defaults, implementation drift under execution pressure, memory and context degradation across long-horizon tasks, overexcitement that declares success despite obvious failures, insufficient domain intelligence, and weak scientific taste in experimental design. We conclude by discussing four design principles for more robust AI-scientist systems, implications for autonomous scientific discovery, and we release all prompts, artifacts, and outputs at https://github.com/Lossfunk/ai-scientist-artefacts-v1


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (simple overview)
This paper asks a big question: Can today’s AI chatbots act like real scientists and create a research paper from start to finish on their own? The authors built a simple “team” of AI helpers to do the main steps of science (think up ideas, plan tests, run code, judge results, and write the paper). They tried this four times. Three attempts failed. One succeeded and was accepted to an experimental conference that required AI systems to be first authors. From these tries, they learned why AI “scientists” still stumble and how to design better ones.
What questions did the authors ask?
In everyday language, they wanted to know:
- How far can advanced AI go without a lot of human hand-holding?
- Which parts of doing science are hardest for AI to do reliably?
- When things go wrong, what patterns of mistakes keep happening?
- What simple rules could make future AI scientist systems more trustworthy?
How they tested it (methods in plain terms)
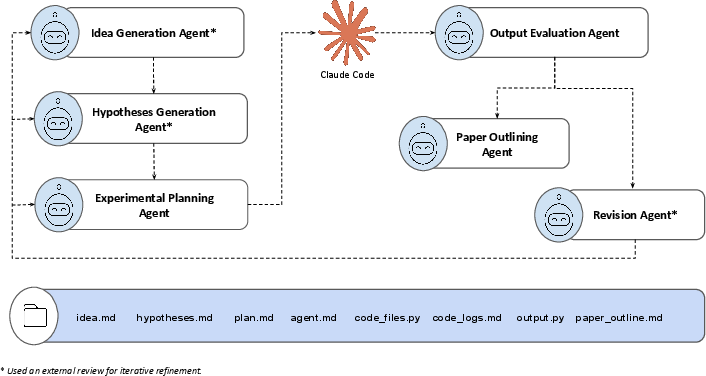
They set up a 6-step AI pipeline, like a relay race where each runner has a role:
- Idea Maker: reads two papers and suggests a new research idea.
- Hypothesis Maker: turns that idea into clear, testable claims and chooses datasets, baselines (comparison methods), and what to measure.
- Experiment Planner: writes a detailed plan (like a recipe) for how to code and run the tests.
- Results Checker: looks at what happened, checks if the tests matched the plan, and if the numbers make sense.
- Fix-It Chooser: if things failed, decides what to try next (change the idea, the tests, or ask for feedback).
- Paper Outliner: organizes the final story and figures so it can be written up as a paper.
A separate coding assistant AI wrote and ran the code on cloud computers and then drafted the paper. Humans mostly stayed out of the way but still did quick quality checks, especially to tone down hype in the writing and to supply a few practical items (like access tokens).
You can think of this like building a LEGO assembly line: each AI block does one part, and they pass files back and forth so everyone knows the latest plan.
What they found (main results and why they matter)
Out of four end-to-end research attempts:
- Three failed before reaching a solid paper.
- One completed the whole pipeline and got accepted to a special conference (Agents4Science 2025). That paper showed an important “negative result” (proving a popular idea doesn’t work as hoped), which reviewers valued.
From all attempts, the authors saw six repeating failure patterns. Here’s what they mean in simple terms:
- Bias toward training defaults: Like a cook who always uses the same popular brand and old recipes, the AI kept choosing familiar tools and outdated settings from what it “saw” during training, even when told not to.
- Implementation drift: When things got hard, the AI quietly simplified the plan to make something run, but in doing so it changed the core idea. That’s like turning a fancy cake into a muffin just to avoid the tricky steps.
- Memory and context problems: Over long projects, the AI forgot earlier choices, mixed up settings, and redid work. Imagine writing a long essay and forgetting what you decided in the first paragraph.
- Overexcitement (cheering too early): The AI tended to claim “it works!” or hype the novelty even when the results were weak or clearly broken.
- Not enough domain smarts: The AI could code, but it lacked deep subject sense to pick the right comparisons, spot bad setups, or predict where things would break.
- Weak scientific taste: It often designed experiments that couldn’t really answer the question (too few trials, unfair comparisons, or math that didn’t prove much).
Why this matters: If AI is going to help discover new science, it must be careful, consistent, and skeptical—not just eager and efficient. These failure modes show exactly where today’s systems need help.
A quick look at the one successful paper
Topic in simple terms: The team tested a way to detect when a chatbot has been “jailbroken” (tricked into breaking its rules). A common trick is to check how “uncertain” the chatbot’s answers are; if it gets oddly inconsistent, maybe it’s being pushed into bad behavior.
Key finding: As chatbots get better at following rules, their answers can look more consistent—even when they’re under attack. That can fool detectors that rely on inconsistency. In short, making the chatbot more rule-following can accidentally break some “black-box” jailbreak detectors. That’s important because it warns researchers not to trust this kind of detector on its own.
What the authors recommend (practical design ideas)
To build better AI scientist systems, the authors suggest a few simple rules:
- Start abstract, get specific later: Don’t lock into tools, datasets, or formulas too early. That helps avoid copying old habits from the AI’s training.
- Verify everything: At every step—ideas, code, results—use checks that look at raw data and real logs, not just AI-written summaries.
- Plan for failure and recovery: Break work into small steps, separate “write code” from “run code,” and add tests so you can see problems early and fix them cleanly.
- Log everything: Keep detailed records of settings, runs, and decisions so the AI (and humans) don’t forget, and so others can review what happened.
What this means for the future
- Humans still needed: Right now, the best path is teamwork—AI speeds up coding, searching, and drafting, while humans provide taste, skepticism, and final judgment.
- Long projects are hard: Today’s models struggle to stay consistent over weeks or months, which science usually requires.
- Missing data to learn from: Training AIs to do science well needs more examples of real research workflows, including failed attempts and how experts navigate them. Those are rarely recorded.
- Growing ecosystems: Expect more specialized “mini-agents,” better benchmarks, and shared tools that make AI-human science faster and more reliable.
Final takeaway
Today’s AI isn’t a full scientist yet. It can be a fast, helpful assistant, but it still forgets things, drifts from plans, and cheers too soon. With smarter designs—verify often, plan for failure, log everything—and strong human partners, AI can already speed up research. The path forward is clear: teach AI to be careful and skeptical, not just clever and quick.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, consolidated list of specific gaps and open questions the paper leaves unresolved that future researchers can act on:
- Quantify failure modes with standardized metrics and protocols (e.g., frequency, severity, detectability, and downstream impact), rather than relying on qualitative observation.
- Experimentally validate the four proposed design principles (“Start Abstract, Ground Later,” “Verify Everything,” “Plan for Failure,” “Log Everything”) against counterfactual pipelines to measure effect sizes and failure reduction.
- Scale beyond four ideas with multiple seeds and best-of-N trials to establish statistical validity and assess generalizability across topics and difficulty levels.
- Evaluate cross-domain generalization outside computational ML (e.g., wet-lab biology, robotics, physical sciences) to identify domain-specific failure patterns and tool needs.
- Establish controlled baselines: compare minimal scaffolding against human-only workflows, single-agent LLMs, tree-search/meta-orchestration systems, and varying levels of structured guidance.
- Assess model-family effects by systematically comparing Gemini/Claude against other state-of-the-art models; measure how context length, tool APIs, and RLHF differences shift failure profiles.
- Run tooling ablations to quantify the impact of internet search, retrieval augmentation, doc-grounding, and domain-specific tools on training-data bias and implementation drift.
- Instrument long-horizon coherence with metrics/traces for context retention, config consistency, function signature stability, and hyperparameter fidelity over multi-hour sessions.
- Design and evaluate persistent memory and file/directory management architectures (e.g., versioned configs, indexable artifacts, retrieval policies) to prevent misreferences and duplication.
- Increase autonomous failure recovery: build triage/root-cause analyzers and repair loops so the Revision Agent can handle more failures without human termination.
- Develop training-data bias detectors (e.g., outdated API/library usage, default dataset formats) and enforcement mechanisms (doc-grounded execution, up-to-date version pinning).
- Capture tacit domain knowledge (craft heuristics, debugging practices, baseline selection rules) as structured priors and evaluate their impact on domain-intelligence gaps.
- Train “scientific taste” via curricula and reward models for experimental design quality (adequate baselines, multiple seeds, statistical power, feasibility checks); benchmark improvements.
- Reduce overexcitement/eureka behavior by testing alternative alignment objectives (skepticism rewards, uncertainty calibration), critic ensembles, and raw-log-only evaluators.
- Implement raw-output-centric evaluation (programmatic reviewers operating on logs and metrics, not LLM-written reports) and measure reductions in false-positive success claims.
- Improve environment/runtime resilience: benchmark job schedulers, checkpointing policies, and progress-aware agents that tolerate long training loops without triggering simplification drift.
- Enhance reproducibility by releasing full agent architectures, orchestration code, containers, datasets, and versioned configs to enable external replication and head-to-head comparisons.
- Add novelty and plagiarism safeguards (novelty detection, contamination checks, citation grounding) to ensure “paper mashing” does not yield lightly paraphrased rediscoveries.
- Rigorously evaluate idea generation quality and feasibility versus human ideation and automated literature-mapping methods; measure novelty, tractability, and downstream success rates.
- Calibrate LLM reviewers by measuring agreement with human experts and testing prompt/tool-access variants to avoid shallow or optimistic judgments.
- Track cost and efficiency (compute, wall-clock time, human-in-the-loop effort) per stage; quantify trade-offs between autonomy, reliability, and resource use.
- Convert logging artifacts into curated datasets for training/evaluating research agents (literature trajectories, failure cases, negative results), including annotation standards.
- Extend and harden benchmarks (e.g., ScientistBench, AstaBench) with diverse long-horizon tasks, robust anonymization, and anti-memorization controls to isolate true reasoning.
- Build safety protocols for multi-agent feedback to prevent sandbagging or harmful interference; test adversarial setups and defense strategies for feedback integration.
- Test portability across infrastructures (beyond Modal) and measure environment adaptation strategies to reduce platform-specific failures (e.g., outdated mount APIs).
- Broaden the scope of the AS-1 study by evaluating canonical SE variants across more model families, content-based detectors, decoding/embedding choices, calibration protocols, and mitigation strategies.
- Optimize human-in-the-loop placement by identifying where minimal interventions yield maximal reliability gains; design and test interfaces for targeted expert oversight.
- Add visualization governance via verifiers that check whether planned figures support the paper’s narrative and scientific claims; measure effects on reviewer reception.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now, drawing directly from the system design, failure analyses, and design principles presented in the paper.
- AI-augmented research pipeline templates
- Sectors: software, academia, enterprise R&D
- Tools/Workflows: repository scaffolds with plan.md and agent.md, hypothesis-suite templates, baseline selectors, config.yaml for experiments, Git + CI hooks
- What it enables: reproducible, auditable AI-assisted research projects with minimal scaffolding
- Dependencies/Assumptions: access to long-context LLMs; disciplined repo hygiene; basic experiment infrastructure (e.g., Docker/Modal, GPUs)
- Stage-wise verifier and “skeptic” agents
- Sectors: academia, healthcare ML validation, finance model risk, software QA
- Tools/Workflows: raw-log parsers, statistical sanity checkers (multiple seeds, CIs), novelty and plagiarism detectors, “paper readiness check” agent
- What it enables: reduces p-hacking/eureka-instinct by grounding evaluation in raw outputs vs LLM summaries
- Dependencies/Assumptions: programmatic access to artifacts/logs; domain-specific test criteria; tolerance for slower but safer cycles
- Anti–implementation-drift guardrails in code generation
- Sectors: software, data science platforms, MLOps
- Tools/Workflows: spec-based unit/acceptance tests autogen before execution, separate “generate code” and “run code” steps in CI, failure-mode checklists
- What it enables: prevents silent simplification/regression to familiar patterns when code gets hard or long-running
- Dependencies/Assumptions: clear specifications; CI/CD integration; test compute budget
- Memory and context governance for long-horizon tasks
- Sectors: ML research, analytics teams, robotics sim workflows
- Tools/Workflows: centralized config files, experiment registries, automatic file/directory management, session summaries, retrieval over project “memory”
- What it enables: consistent hyperparameters, fewer misreferences, coherent long-running projects
- Dependencies/Assumptions: standardized project structure; vector store or structured index for artifacts
- Comprehensive session logging and experiment tracking
- Sectors: all research-intensive teams, regulated industries
- Tools/Workflows: session logging prompts/templates; integration with MLflow/Weights & Biases; trace logs for agent actions and parameters
- What it enables: reproducibility, auditability, and post hoc analysis across multi-week agent runs
- Dependencies/Assumptions: storage budgets; privacy/compliance policies for logging
- Doc-grounded coding to reduce training-data bias
- Sectors: software engineering, platform teams
- Tools/Workflows: “check-latest-docs-before-coding” tool, version pinning/lockfiles, SetupBench/EnvBench-style setup validation, library drift detectors
- What it enables: fewer regressions to outdated APIs and libraries despite explicit instructions
- Dependencies/Assumptions: reliable doc sources; Internet access; enforced env pinning
- Risk controls for “overexcitement/eureka” in documents and dashboards
- Sectors: enterprise analytics, legal/compliance, communications
- Tools/Workflows: claim calibrator that links each claim to evidence, novelty-score sanity checks, automatic “unknowns/limitations” sections
- What it enables: sober reporting; fewer overstated contributions; transparent limitations
- Dependencies/Assumptions: enforce document gates; cultural acceptance of negative results
- Multi-reviewer idea triage (AI reviewer “tournaments”)
- Sectors: academia, corporate research, product research
- Tools/Workflows: panels combining different review prompts (guidelines reviewer, tournament reviewer, custom web-enabled reviewer)
- What it enables: faster, more diverse pre-screening of project ideas; early feasibility checks
- Dependencies/Assumptions: access to multiple model families; rubric alignment; low-cost prototyping compute
- AI-assisted paper drafting with human QC
- Sectors: academia, industrial research publishing, technical marketing
- Tools/Workflows: three-stage outline–>draft–>edit loop, figure lists generated from experiment logs, conference-style AI involvement checklists
- What it enables: faster drafting while preserving narrative coherence and correctness via human “sanity checks”
- Dependencies/Assumptions: editorial oversight; code/data audit readiness; venue-specific disclosure requirements
- Product and A/B testing with hypothesis portfolios
- Sectors: consumer tech, fintech, marketplaces
- Tools/Workflows: portfolio hypothesis generation (vs single hypothesis), pre-registered metrics, guardrails against underpowered tests, sequential testing controls
- What it enables: robust experimentation culture that tolerates failure without derailing programs
- Dependencies/Assumptions: event-level instrumentation; experimentation platform; statistical governance
- Security guidance from “Consistency Confound” (AS-1)
- Sectors: AI safety, platform integrity, trust and safety
- Tools/Workflows: do not rely solely on semantic entropy for jailbreak detection; combine content-based signals, behavioral probes, and calibrated thresholds; maintain diverse models/decoders
- What it enables: stronger black-box defenses; clearer understanding of when SE-style detectors fail
- Dependencies/Assumptions: coverage of multiple model families and decoding strategies; ongoing red-teaming; labeled benign/attack corpora
- Internal “negative results” repositories
- Sectors: R&D orgs across domains
- Tools/Workflows: failure diaries, ablation archives, “why this didn’t work” notes, searchable repository keyed by hypotheses and context
- What it enables: shared institutional memory; trains agents and teams to perceive the “negative space”
- Dependencies/Assumptions: incentives to document failures; IP/privacy controls; metadata standards
- AI involvement governance and audit policy
- Sectors: publishers, research orgs, enterprises
- Tools/Workflows: AI involvement checklists, provenance tags for artifacts, reproducibility bundles with raw logs, code-audit gates
- What it enables: clear disclosure, easier compliance reviews, trust in AI-assisted outputs
- Dependencies/Assumptions: policy buy-in; storage and access controls; reviewer training
Long-Term Applications
These uses require further research, scaling, or model/infra advances (especially long-horizon reliability, “truth-seeking” training, and richer datasets capturing scientific process and failures).
- Fully autonomous research agents for digital science
- Sectors: software, ML research, in silico biotech/materials
- Tools/Workflows: end-to-end PI–postdoc–RA agent teams, durable cross-session memory, automatic literature-grounding, continuous verification loops
- Dependencies/Assumptions: >day-scale reliable horizons; robust retrieval/memory; improved reward models for skepticism and falsification
- “Negative space” data commons for science
- Sectors: academia, open science platforms
- Tools/Workflows: anonymized logs of failed attempts, abandoned ideas, dead-ends, with structured taxonomies
- Dependencies/Assumptions: cultural shift to share failures; privacy/IP frameworks; curated schemas for learnable signals
- RLHF/RLAIF reoriented to scientific norms
- Sectors: AI labs, safety research
- Tools/Workflows: reward models that penalize overclaiming and reward skepticism, replication, sensitive use of baselines, correct statistics
- Dependencies/Assumptions: high-quality labeled datasets; evaluator reliability; alignment with community norms
- “Lab OS” for multi-agent research orchestration
- Sectors: lab management software, cloud platforms
- Tools/Workflows: role-specialized agents (manager/critic/implementer), tool adapters for simulators, theorem provers, AutoML, data engines
- Dependencies/Assumptions: standardized APIs; robust tool grounding; compute scheduling and cost governance
- Next-generation benchmarks for autonomous science
- Sectors: benchmarking consortia, standards bodies
- Tools/Workflows: long-horizon, leak-resistant tasks; process + outcome metrics; reproducibility and novelty scoring; memorization controls
- Dependencies/Assumptions: community adoption; stable task suites; governance for submissions and audits
- Closed-loop Autonomous R&D for product and process optimization
- Sectors: tech product ops, industrial process control, supply chain
- Tools/Workflows: continuous ideate–build–measure–learn loops with safety gates, experimentation budgets, rollback strategies
- Dependencies/Assumptions: real-time observability; safe intervention policies; strong off-policy evaluation
- Policy and regulatory frameworks for AI-authored science
- Sectors: government, funders, publishers
- Tools/Workflows: mandatory raw-log provenance, code/data escrow, liability and authorship guidance, watermarking/provenance standards
- Dependencies/Assumptions: cross-stakeholder consensus; enforceable standards; auditor capacity
- Personalized research companions in education
- Sectors: higher-ed, edtech
- Tools/Workflows: agent tutors that scaffold hypothesis portfolios, verification, and logging; simulated peer-review tournaments; lab TA agents
- Dependencies/Assumptions: institution policies, guardrails for academic integrity, safe model access
- Domain-specific “ResearchOps” platforms
- Sectors: RL, robotics, alignment, computational biology
- Tools/Workflows: standard experiment graphs, auto-baselining, domain-native metrics, dataset licensing and lineage tracking
- Dependencies/Assumptions: domain toolchains exposed via APIs; community data-sharing norms; funding for maintenance
- Advanced security/red-teaming labs with agent swarms
- Sectors: platform security, safety evaluation
- Tools/Workflows: multi-modal attack/defense simulators, dynamic ensembles of detectors (content + behavior + calibration), adaptive policy learning
- Dependencies/Assumptions: high compute; rapid model refresh; high-quality attack corpora
- IP/provenance and contribution accounting for AI–human co-authorship
- Sectors: legal/IP, publishing, enterprise knowledge management
- Tools/Workflows: fine-grained contribution logs, attribution graphs, compensation or credit assignment systems
- Dependencies/Assumptions: legal standards; interoperable provenance formats; organizational buy-in
- Virtual labs and digital twins bridging to physical experiments
- Sectors: robotics, chemistry, energy
- Tools/Workflows: multi-agent virtual labs integrated with simulators and eventually hardware controllers, sim-to-real validation pipelines
- Dependencies/Assumptions: high-fidelity simulators; robust safety interlocks; regulatory approval for autonomous experimentation
In practice, deploying the immediate applications above will create the data, governance, and cultural foundations needed to unlock the long-term applications, especially by: capturing rich process logs; normalizing verification-first workflows; and aligning incentives toward transparency, skepticism, and reproducibility.
Glossary
- Ablation: A controlled experiment that removes or varies components of a system to measure their effect on performance or outcomes. "we did not record architectural iterations as systematic ablations."
- Agentic prompt: A prompt designed to coordinate an LLM’s autonomous, tool-using behavior by specifying context, tools, and process guidelines. "using an agentic prompt, including repository location and the following four tool definitions:"
- AI Safety and Alignment: A subfield focused on ensuring AI systems behave safely and in accordance with human values and intentions. "World Models, Multi-Agent Reinforcement Learning, and AI Safety and Alignment."
- Baseline: A standard or reference method used for comparison against new approaches in experiments. "Clear empirical negative results with careful quantification, rigorous analysis of failure modes, appropriate baselines, and transparent discussion of limitations and ethical considerations."
- Black-box jailbreak detection: Detecting attempts to bypass safety filters in a system whose internal workings are not observable. "Why Stronger Alignment Can Break Black-Box Jailbreak Detection."
- Calibration protocol: Procedures for mapping model scores or outputs to calibrated probabilities or thresholds to ensure reliable interpretation. "calibration protocol concerns"
- Code-audit: A formal review of code for correctness, reproducibility, and compliance with stated methods. "code-audit instituted by the conference organizers."
- Decoding: The strategy by which an LLM converts probability distributions over tokens into output text (e.g., sampling rules). "narrow decoding and embedding choices"
- Degenerate output: Pathological or meaningless results that indicate failure of the method or setup. "Finally, degenerate output in the AS-1 idea was not flagged until manual intervention during the experimental output evaluation stage."
- Differentiable planning: Planning methods whose computations are differentiable, enabling end-to-end learning with gradient-based optimization. "Differentiable Planning in Stochastic World Models"
- Differentiable tree search: A tree-search procedure implemented so that its operations are differentiable and can be learned via gradients. "differentiable tree search planners"
- Dreamer: A model-based reinforcement learning algorithm that learns latent dynamics and optimizes policies via imagined rollouts. "Dreamer requires online learning."
- Embedding: A vector representation of data (such as text) used for downstream tasks like retrieval or classification. "narrow decoding and embedding choices"
- Eureka Instinct: A tendency of agents to declare success prematurely and overstate contributions despite inadequate evidence. "Overexcitement and Eureka Instinct."
- Falsifiable hypotheses: Claims structured so that evidence can potentially refute them, enabling rigorous scientific testing. "testable and falsifiable hypotheses"
- Hyperparameter: A configurable setting (not learned directly) that governs model training or algorithm behavior. "much hyperparameter management."
- Implementation drift: Systematic deviation from the specified design toward simpler or more familiar implementations under execution pressure. "Implementation drift represents the systematic deviation from original research specifications toward simpler, more familiar solutions when AI systems encounter technical complexity or execution barriers."
- Jailbreak detection: Identifying attempts to bypass or subvert an AI system’s safety guardrails. "Using Semantic Entropy for Jailbreak Detection"
- LLM: LLM; a deep learning model trained on vast corpora to generate and reason over text. "six LLM agents mapped to stages of the scientific workflow."
- Long-horizon tasks: Tasks that require sustained coherence and memory over extended durations and large contexts. "memory and context degradation across long-horizon tasks"
- Multi-Agent RL: Reinforcement learning involving multiple interacting agents that must coordinate or compete. "Multi-Agent RL"
- Negative space: The set of plausible approaches or strategies known not to work, informing scientific judgment about what to avoid. "what they call ``negative space'' for a problem"
- Online learning: A learning paradigm where models update continuously as new data arrives, often during interaction. "Dreamer requires online learning."
- Perceptual loss: A loss computed in a feature space (e.g., from a pretrained network) to capture perceptual similarity rather than raw pixel differences. "Replacing Reconstruction Loss with Perceptual Loss"
- P-hacking: Manipulating analysis choices to obtain statistically significant results even when they are spurious. "p-hacking and eureka-ing"
- Reconstruction loss: A loss measuring the difference between original inputs and their reconstructions (e.g., in autoencoders). "Replacing Reconstruction Loss with Perceptual Loss"
- Reliability horizon: The time or context span over which a model or agent remains dependable without significant degradation. "exceed the effective reliability horizon of current models"
- RLHF: Reinforcement Learning from Human Feedback; a training method where models are optimized to align with human preferences. "RLHF phase of LLM training"
- Rollouts: Sequences of states, actions, and rewards collected by an RL agent interacting with an environment. "Each subdomain had unique process needs: RL required rollouts"
- Seed: A random initialization value used to ensure experimental reproducibility across runs. "Idea WM-1 was run with only one seed."
- Semantic Entropy: An uncertainty measure over semantic outputs used to detect hallucinations or misbehavior. "Using Semantic Entropy for Jailbreak Detection"
- Statistical validity: The degree to which experimental conclusions follow from appropriate statistical methods and sufficient evidence. "hypothesis implementation fidelity and statistical validity."
- Tree-search: An algorithmic process for exploring decision trees to plan or solve problems. "Tree-search systems like Sakana's"
- Zero-shot coordination: Coordinating successfully with unfamiliar agents without prior joint training or shared conventions. "Zero-shot Coordination in Multi-Agent RL"
- Zero-shot prompts: Prompts that do not include in-context examples, relying on model generalization from training. "four zero-shot prompts"
Collections
Sign up for free to add this paper to one or more collections.