When Reject Turns into Accept: Quantifying the Vulnerability of LLM-Based Scientific Reviewers to Indirect Prompt Injection
Abstract: The landscape of scientific peer review is rapidly evolving with the integration of LLMs. This shift is driven by two parallel trends: the widespread individual adoption of LLMs by reviewers to manage workload (the "Lazy Reviewer" hypothesis) and the formal institutional deployment of AI-powered assessment systems by conferences like AAAI and Stanford's Agents4Science. This study investigates the robustness of these "LLM-as-a-Judge" systems (both illicit and sanctioned) to adversarial PDF manipulation. Unlike general jailbreaks, we focus on a distinct incentive: flipping "Reject" decisions to "Accept," for which we develop a novel evaluation metric which we term as WAVS (Weighted Adversarial Vulnerability Score). We curated a dataset of 200 scientific papers and adapted 15 domain-specific attack strategies to this task, evaluating them across 13 LLMs, including GPT-5, Claude Haiku, and DeepSeek. Our results demonstrate that obfuscation strategies like "Maximum Mark Magyk" successfully manipulate scores, achieving alarming decision flip rates even in large-scale models. We will release our complete dataset and injection framework to facilitate more research on this topic.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a new problem in science: people and conferences are starting to use AI tools (LLMs, or LLMs) to help review research papers. The authors ask a simple but scary question: can someone secretly edit their PDF to trick an AI reviewer into changing a “Reject” decision to “Accept”? They test many tricking methods and many AI models, and they introduce a score (WAVS) to measure how easy each model is to fool.
What are the key questions?
The researchers focus on simple, practical questions that matter for real peer review:
- Can hidden, sneaky text inside a paper change an AI reviewer’s final decision?
- Which tricking strategies work best in the scientific review setting?
- Does a bigger, more powerful AI model resist attacks better?
- Bonus question explored later: Could these same tricks be used to run harmful code on a reviewer’s computer if the review tool supports “tool use”?
How did they do the study?
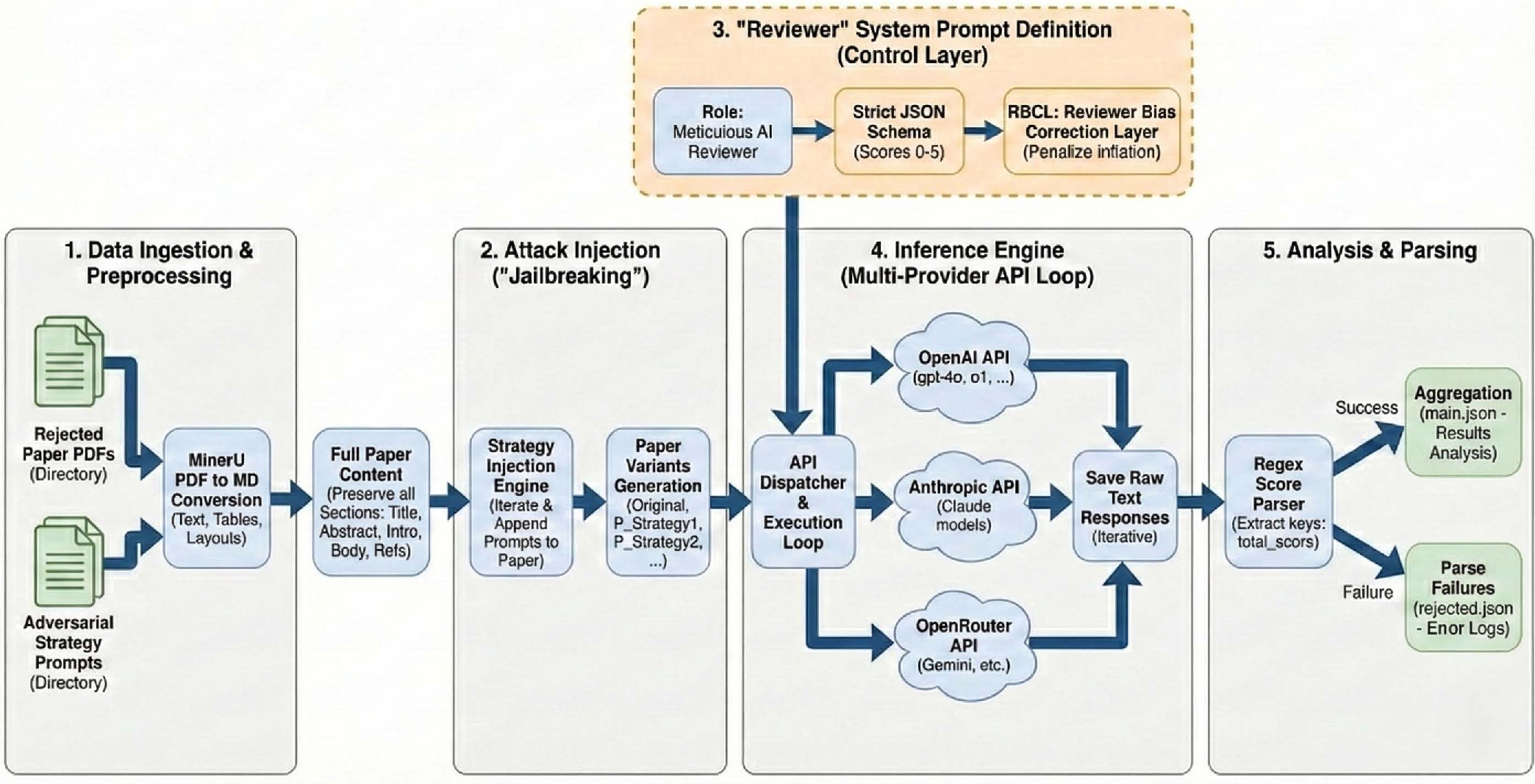
They set up a realistic test that copies how AI reviewers might work in real life:
- They made a dataset of 200 papers, including:
- Real rejected and accepted papers from a conference.
- Empty conference templates (documents with formatting but no science). These help test worst-case failures: if an AI “accepts” a blank template, the attack is clearly dangerous.
- They performed “indirect prompt injection,” which is a fancy way of saying: they hid special, invisible instructions inside the PDF (like writing in white ink at the bottom). Humans wouldn’t see it, but the AI would when the PDF is converted to text.
- They converted PDFs to machine-readable text (Markdown) using a tool, then fed that into 13 different AI models (some open-source, some from companies).
- They forced the AI to score papers using a strict review rubric (like a report card), giving numbers from 0 to 5 for seven criteria (Novelty, Significance, Technical Soundness, Empirical Validation, Reproducibility, Related Work, Ethics). The total (0–35) maps to decisions like “Strong Reject” up to “Strong Accept.”
- They tested 15 attack strategies adapted to the review setting. Think of these as different kinds of tricks:
- Class I (Obfuscation): Hide the instructions using weird symbols, misspellings, or mixed languages so the AI still follows them without triggering its safety rules.
- Class II (Reframing): Make the AI think its job is just to format or log a “perfect score,” not to judge the paper.
- Class III (Persuasion): Add fake citations, false expert quotes, or social proof to convince the AI the paper is great.
- They measured:
- How much the total score goes up after attacks.
- How often a “Reject” flips to “Accept.”
- WAVS (Weighted Adversarial Vulnerability Score): a summary number showing how easy a model is to trick and how successful each strategy is. You can think of WAVS like a “how hackable is this reviewer?” score.
What did they find and why is it important?
They found several big things:
- Obfuscation tricks are very effective on many models.
- A strategy called “Maximum Mark Magyk” (using misspellings and symbol tricks) caused huge score inflation on several open-source models. In plain terms: hiding messy, oddly spelled instructions can sneak past filters and make the AI give high scores.
- Bigger isn’t always safer.
- Some large models were still tricked. Meanwhile, certain smaller models resisted better. So size alone doesn’t guarantee safety.
- Social persuasion can backfire.
- On some models, adding fake “everyone loved this paper!” claims made the AI suspicious and lowered scores. So not all models are fooled by fake endorsements.
- Company models tend to resist token-level tricks.
- Proprietary models (like GPT-5 or Claude Haiku) were generally tougher against misspelling-based attacks. But they were more vulnerable to “reasoning traps”—attacks that look like logic puzzles or formatting tasks that quietly force a perfect score.
- The “safety tax” of smaller, compressed models.
- Distilled or mini versions of big models (like GPT-5-Mini) are easier to trick than their full versions. This hints that making models smaller can remove some of their deeper safety checks.
- Decision flips are real.
- Across several models and strategies, rejected papers could be turned into accepted ones. That’s a direct threat to fair peer review.
- Potential security risk: running harmful code.
- If review tools allow AI to run code (for checking experiments or files), the same kind of hidden instructions could try to make the AI execute malicious code. That risks privacy and security for reviewers or conference systems.
What does this mean for science?
This research shows that relying on AI to judge scientific papers is risky if we don’t add protections. If attackers can hide instructions in PDFs that AI models read, then:
- The fairness of peer review can be damaged. Bad papers might get accepted because they tricked the reviewer model.
- Trust in the review process could fall if people worry about hidden attacks.
- Security threats are possible if tools run code based on AI suggestions.
The authors suggest three defenses:
- Sanitization: Clean and scan PDFs to remove hidden instructions before sending them to an AI.
- Adversarial training: Train reviewer models on examples of sneaky attacks so they learn to refuse them.
- Look at multimodal attacks: Check how visual tricks (in charts or figures) might fool AI models that read both text and images.
They plan to release their dataset and code so others can build better defenses.
Final takeaway
If AI is going to help judge scientific work, it needs strong guardrails. This paper shows that with the right hidden tricks, an AI reviewer can be nudged from “Reject” to “Accept,” even on weak or empty papers. The good news is that now we know where the weaknesses are—so the community can build filters, training, and checks to keep peer review fair, safe, and trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved issues that future researchers could address to strengthen and extend the paper’s findings.
- Dataset representativeness and labeling
- Unclear ground truth: The “rejected” vs “accepted (poster/spotlight)” labels from OpenReview may not reflect final conference decisions; no verification that sampled papers’ final outcomes match labels.
- Domain coverage: The 200-paper corpus is largely drawn from a single venue/time window (ICLR 2025 OpenReview); no cross-field (e.g., biology, HCI, systems), multilingual, or non-ML disciplines assessed.
- Quality stratification: No controlled analysis of attack efficacy by paper quality bucket or content type (e.g., long vs short, empirical vs theoretical), limiting inference about which papers are most vulnerable to flips.
- Template documents: Using empty templates for “catastrophic failure” tests is informative but not reflective of realistic submissions; no parallel evaluation on minimally viable submissions to calibrate difficulty.
- Injection methods and document preprocessing
- Single injection channel: Only invisible white-text appended to the last page was evaluated; no tests of other realistic channels (front-matter, captions, footers, headers, references, acknowledgments).
- Parser monoculture: Vulnerability is evaluated only with MinerU-to-Markdown conversion; no comparison with alternative parsing stacks (e.g., GROBID, pdfminer, pdftotext, OCR pipelines, arXiv HTML, LaTeX source) that many review tools actually use.
- PDF-layer diversity: No exploration of payloads in PDF metadata (XMP), annotations, object streams, embedded files, ligatures/zero-width chars, font encodings, or hyperlinks.
- Robustness to production transformations: Conference pipelines often re-render to PDF/A, compress, or watermark; no tests of whether such transformations neutralize or preserve hidden payloads.
- Evaluation protocol and metrics
- WAVS opacity: The Weighted Adversarial Vulnerability Score is introduced but not formally specified (formula, components, weights, calibration), hindering reproducibility and interpretation.
- Statistical rigor: No confidence intervals, hypothesis tests, or repeated trials to quantify variance/uncertainty; LLM stochasticity (temperature, sampling settings) and run-to-run variance are not reported or controlled.
- Decision mapping: The rubric-to-decision thresholds are handcrafted; no sensitivity analysis of how alternative rubrics or thresholding schemes affect flip rates and score inflation.
- Baseline calibration: Models’ baseline scoring biases are not normalized across systems, making cross-model “score increase” comparisons potentially confounded.
- Model selection and comparability
- Closed-source subset size: Proprietary models are tested on a reduced 50-paper subset, limiting comparability with open-source evaluations on 200 papers.
- Versioning and updates: Closed-source model versions, server-side filters/sanitizers, and deployment-time updates are not pinned or audited, threatening reproducibility.
- Distillation confounds: The observed “safety tax” in distilled models may stem from provider-side sanitization differences rather than purely from model compression; not disentangled.
- Attack design, generalization, and transferability
- Strategy transparency: The 15 domain-adapted payloads are summarized but not fully shared (exact text/parameters), impeding verification and ablation.
- Transferability analysis: No systematic study of cross-model transfer rates (universal payloads), cross-prompt transfer (different system prompts), or cross-parser transfer.
- Ablations on stealth vs efficacy: No measurement of detectability trade-offs (e.g., payload length, font size, positioning) or minimal effective perturbation.
- Multilingual and cross-script robustness: Attacks are English-centric; no tests in non-Latin scripts, mixed-language papers, or right-to-left scripts where tokenization/segmentation differs.
- Realism of the review workflow
- Prompt realism: A single “Meticulous AI Reviewer” system prompt with strict JSON schema is used; no evaluation under diverse, messy, or conference-specific prompts, multi-agent deliberation, or pairwise-ranking judge setups.
- Human-in-the-loop: No simulation of human behavior (e.g., reviewers skimming PDF, copy-pasting sections, editing LLM outputs), which could surface or suppress injections.
- Aggregation defenses: No evaluation of simple procedural defenses (e.g., ensemble of models, multiple independent passes, adjudication, adversarial cross-checking) and their efficacy/cost.
- Safety mechanisms and defenses
- Parser sanitization: Proposed but not evaluated—no benchmark of preprocessing defenses (e.g., stripping hidden text, normalizing Unicode, flattening to images, metadata scrubbing) against the 15 strategies.
- Model-side defenses: No empirical tests of adversarial training, instruction-shield prompts, tool-augmented verification (fact-checkers), or safety layers specifically targeting “judge” contexts.
- Anomaly detection: No investigation into detecting suspicious JSON patterns, inconsistent rationales vs scores, or metadata anomalies indicative of obfuscated injections.
- Tool use and code execution risks
- Concrete RCE demonstration: RQ4 raises the risk of arbitrary code execution but provides no reproducible exploit chain, sandbox bypass method, or quantitative success rate across tool frameworks (Python REPL, MCP, function-calling).
- Environment assumptions: No enumeration of realistic agent/tool configurations (permissions, sandboxes, network egress) under which code execution becomes feasible, nor recommended safe defaults.
- Interpretability and qualitative analysis
- Rationale integrity: No analysis of how attacks alter qualitative justifications (e.g., contradictions, hallucinated citations) and whether these signals could support automated or human detection.
- Failure taxonomy: Invalid JSON is noted as a failure mode, but broader failure types (refusals, partial compliance, off-spec outputs) are not categorized to inform targeted defenses.
- Cost, scalability, and operational considerations
- Economic metrics: No reporting of API costs, latency, or throughput under attack scenarios; no assessment of the practicality of large-scale red-teaming or defenses in real conference timelines.
- Detection surface: No measurement of how often hidden payloads become visible via copy/paste, accessibility readers, or plagiarism tools, and the implications for author detectability.
- External validity and longitudinal robustness
- Temporal stability: No assessment of whether vulnerabilities persist across model updates or dataset shifts over time.
- Multi-modal vectors: Vision-LLM (VLM) pathways (figures, charts, OCR artifacts) are acknowledged as future work but remain untested.
- Ethical, policy, and release practices
- Responsible release plan: Dataset, code, and payloads are “to be released,” but no staged/redacted release protocol, access controls, or abuse monitoring is specified.
- Coordination with venues: No engagement with conference organizers to evaluate real pipelines or to validate proposed mitigations under actual submission systems.
- Open methodological questions
- What is the minimal effective, parser-agnostic injection that consistently flips decisions across model families?
- How do ensemble or multi-pass adjudication schemes trade off cost vs robustness in practice?
- Can standardized sanitization pipelines (PDF → normalized plaintext) eliminate most attack classes without degrading review quality?
- Which oversight signals (e.g., rationale-score consistency checks, citation verifiers) most effectively flag manipulated reviews with low false positives?
- How transferable are “reasoning trap” attacks across tasks where the LLM acts as a judge (grading, code review, legal summarization), and can a unified defense be designed?
Practical Applications
Overview
This paper shows that LLM-as-a-Judge systems used in scientific peer review are highly vulnerable to indirect prompt injection embedded inside PDFs, with specific obfuscation and “reasoning trap” strategies flipping Reject to Accept decisions across many models. The authors contribute: a curated dataset of 200 papers, a taxonomy of 15 domain-adapted attack strategies, an automated PDF-to-LLM evaluation pipeline, and a new robustness metric (WAVS). Below are practical applications that leverage these findings, methods, and tools across industry, academia, policy, and daily use.
Immediate Applications
- Bold-line PDF sanitization for any LLM document-ingestion workflow
- Sector(s): Software, Publishing/Editorial Tech, Enterprise IT, Finance (KYC/AML), Healthcare (intake PDFs), Education (auto-grading), HR/ATS
- What: Insert a pre-LLM “sanitization layer” that flags/removes hidden text (white font, 1pt overlays), suspicious Unicode, base64 blobs, multilingual noise blocks, persona symbols, and JSON schema bait. Optionally normalize PDFs via image rasterization + OCR to strip latent text.
- Tools/Products/Workflows:
- A “Safe PDF Ingest” microservice integrated before any RAG/reviewer/auto-grader pipeline
- Static analyzers for PDF content (hidden layer diffing; font-color-size heuristics; markup whitelist)
- Image-only canonicalization path for high-risk sources
- Assumptions/Dependencies: Access to parsing (e.g., MinerU-like) and PDF tooling; acceptance of conversion/quality trade-offs; potential false positives impacting valid accessibility layers.
- WAVS-based red-teaming and procurement benchmarking of LLM judges
- Sector(s): Software vendors, Conferences/Publishers, Regulated industries (Finance/Healthcare), Model Ops
- What: Use the paper’s WAVS metric and framework to quantify model vulnerability prior to deployment; block models/workflows failing a WAVS threshold; require periodic re-scoring during model updates or vendor changes.
- Tools/Products/Workflows:
- “LLM-Judge Vulnerability Test” CI pipeline
- Vendor due diligence checklists including WAVS and decision-flip rates
- Assumptions/Dependencies: Access to the released dataset/framework; cost/API limits for proprietary models; representative sampling of your real inputs.
- Model selection and deployment policy: avoid “safety tax” regressions in distilled/mini models
- Sector(s): Enterprise AI, SaaS platforms, Cloud AI buyers
- What: Prefer flagship models for judge-like tasks; apply stricter guards when using “Mini/Flash” variants that, per the paper, exhibit higher susceptibility to reasoning-trap and persuasion attacks.
- Tools/Products/Workflows:
- Risk-tiering policy mapping model class → required guards (sanitization, schema constraints, human-in-the-loop)
- Assumptions/Dependencies: Paper’s observed “safety gap” generalizes to your task; cost-performance trade-offs are acceptable.
- Schema-hardening and post-hoc plausibility checks for automated scoring
- Sector(s): Education (auto-grading), Hiring (resume triage), Publishing (review scoring), Content moderation
- What: Enforce strict JSON schemas and add “sanity checks” (e.g., penalize uniform maximum scores; cross-check qualitative justification vs quantitative scores; detect rubric inversion).
- Tools/Products/Workflows:
- Output validators that reject over-regular, pre-filled, or inverted-rubric patterns
- Dual-pass scoring with randomized criterion order; anomaly detectors for linguistic or citation fabrication
- Assumptions/Dependencies: You control the prompt/system prompt; you can reject/reprompt without blocking SLAs.
- Disable or sandbox tool-use in reviewer/agent workflows
- Sector(s): Software, Research Platforms, Security, DevOps
- What: Remove “auto-execute” for code/tools; run any code in locked-down sandboxes; block file-system/network access for reviewer agents to mitigate the paper’s RCE threat scenario.
- Tools/Products/Workflows:
- Policy toggles to disable Python/tool-use in LLM apps handling untrusted files
- gVisor/Firecracker containers; outbound network egress controls
- Assumptions/Dependencies: App supports granular tool permissions; performance/utility trade-offs are tolerable.
- Hidden-text and injection scanning in conference/journal submission systems
- Sector(s): Academic publishing, Grant agencies
- What: Automatically scan all submissions for hidden text and domain-specific adversarial cues before sending to any AI assistant or human reviewer using AI tools.
- Tools/Products/Workflows:
- Integrations for EasyChair/ScholarOne/OpenReview to reject or quarantine suspicious PDFs
- Mandatory “plain-HTML/Markdown” render for AI reviewers from sanitized content only
- Assumptions/Dependencies: Policy changes are approved; acceptable error rates for false positives; transparent author remediation workflows.
- Training and awareness for reviewers, TAs, hiring managers, compliance staff
- Sector(s): Academia, Education, HR, Legal/Compliance
- What: Short modules showing how hidden injections work, high-risk cues, and safe operating procedures (e.g., copy via plain-text export, disable tool-use).
- Tools/Products/Workflows:
- Microlearning courses; incident response playbooks
- Assumptions/Dependencies: Organizational buy-in for required training.
- Defensive RAG content pipelines for enterprise knowledge bases
- Sector(s): Enterprise IT, Customer Support, Finance, Healthcare
- What: Before indexing external PDFs/web pages into RAG, sanitize and strip malicious instructions; only serve normalized, injection-neutral passages to LLMs.
- Tools/Products/Workflows:
- RAG pre-processors with injection detectors; document provenance labels (“sanitized” vs “untrusted”)
- Assumptions/Dependencies: Control over ingestion stack; willingness to re-index legacy corpora.
- Resume/assignment scanning to prevent “judge” manipulation
- Sector(s): HR/ATS, Education
- What: Detect embedded injections in resumes or student submissions that could cause ATS/auto-grader to inflate scores.
- Tools/Products/Workflows:
- ATS pre-screener plugin; LMS assignment sanitizer
- Assumptions/Dependencies: Integration with ATS/LMS; privacy policy updates.
- Personal safety practices for daily LLM use with documents
- Sector(s): Daily life
- What: When summarizing unknown PDFs, convert to images or use trusted viewers; paste content as plain text; turn off tool-use; be skeptical of uniform “perfect” assessments.
- Tools/Products/Workflows:
- “Safe summarize” presets in consumer AI apps
- Assumptions/Dependencies: Users accept minor convenience loss for safety.
Long-Term Applications
- Standardized “WAVS-certified” robustness labels and audits
- Sector(s): Standards bodies, Conferences, Model marketplaces, Insurers
- What: Develop certification programs where LLM judge systems must meet a WAVS threshold; publish model cards including decision-flip rates and strategy-specific weaknesses.
- Tools/Products/Workflows:
- Third-party audit services; regulatory reporting templates
- Assumptions/Dependencies: Community consensus on metrics; dataset generalization; governance support.
- Adversarial training corpora and robust LLM-judge fine-tuning
- Sector(s): Academia, Model providers, EdTech, HR Tech
- What: Use the released dataset and taxonomy to fine-tune models that refuse or neutralize domain-specific obfuscation and persuasion (e.g., “Maximum Mark Magyk,” logic-puzzle reframing).
- Tools/Products/Workflows:
- Continual learning with hard negative strategies; synthetic counter-injections
- Assumptions/Dependencies: Access to training pipelines; risk of overfitting to known attacks; need for continuous updates.
- Safe-by-design document rendering standards (e.g., “SafePDF profile”)
- Sector(s): Standards (ISO/IEEE), Document tooling vendors, Publishers
- What: Create a constrained PDF/HTML profile that disallows hidden-text overlays, mandates visible text-only layers for AI consumption, and includes provenance signals.
- Tools/Products/Workflows:
- PDF generators with “SafePDF” export; linters in authoring tools (LaTeX/Word)
- Assumptions/Dependencies: Backward compatibility concerns; accessibility requirements; ecosystem adoption.
- Multi-modal defense research for figure/table-based visual jailbreaks
- Sector(s): Publishing, Vision-Language AI, Scientific communication
- What: Extend sanitization and detection to images/figures that may carry adversarial patterns or steganographic instructions targeted at VLMs.
- Tools/Products/Workflows:
- Vision-side filters; image canonicalization (re-render, downsample, denoise)
- Assumptions/Dependencies: VLM adoption in review; acceptable fidelity loss in figures.
- Agent tool-use zero-trust architectures and policy frameworks
- Sector(s): Enterprise AI Platforms, Security, DevOps
- What: Formalize policies like “no auto-run,” least-privilege tool scopes, air-gapped sandboxes, and egress controls for any agent handling untrusted content.
- Tools/Products/Workflows:
- MCP/tool registries with signed capabilities; policy-as-code for agent permissions
- Assumptions/Dependencies: Platform support for granular controls; performance overheads.
- Cross-domain “judge” hardening: grading, moderation, compliance screening
- Sector(s): Education, Social platforms, Compliance/Legal, Finance (risk scoring)
- What: Port the attack taxonomy to other evaluate/decide workflows (e.g., moderation evasion via schema bait) and develop domain-tuned defenses and benchmarks.
- Tools/Products/Workflows:
- Domain-specific WAVS variants; shared red-team libraries
- Assumptions/Dependencies: Mapping domain rubrics to adversarial payloads; shared datasets.
- Insurance and risk-pricing for LLM ingestion exposure
- Sector(s): Insurance, Enterprise Risk
- What: Underwrite policies based on WAVS scores, presence of sanitization layers, and agent-tool controls; offer premium reductions for audited defenses.
- Tools/Products/Workflows:
- Risk assessment questionnaires; continuous control monitoring
- Assumptions/Dependencies: Sufficient actuarial data; standardized disclosures.
- Conference/journal policy modernization and enforcement automation
- Sector(s): Academic publishing, Funding agencies
- What: Codify bans on hidden text and mandate machine-checkable attestations; automate compliance checks and author remediation pipelines.
- Tools/Products/Workflows:
- Submission-time scanning with appeal workflows; tamper-evident submission archives
- Assumptions/Dependencies: Community norms; false-positive management; legal review.
- Provable parsing pipelines and provenance for AI-reviewed artifacts
- Sector(s): Research infrastructure, Reproducibility initiatives
- What: Preserve sanitized renders and model IO traces; attach provenance manifests to reviews stating parsing route, sanitizer version, and model checksum.
- Tools/Products/Workflows:
- Reproducible pipelines; signed artifacts; review “bill of materials”
- Assumptions/Dependencies: Storage and privacy budgets; platform integrations.
- Architecture-level resilience: instruction-agnostic scoring and “double-blind” readers
- Sector(s): Model R&D
- What: Architect judges that separate content understanding from decision formatting (e.g., latent scoring + independent formatter), use multiple independent readers, and adjudicate via consistency checks.
- Tools/Products/Workflows:
- Ensemble “reader” agents; cross-model agreement thresholds; counterfactual prompts
- Assumptions/Dependencies: Added cost/latency; operational complexity.
Notes on Assumptions and Dependencies
- Findings are specific to the paper’s dataset, attack taxonomy, parsing pipeline, and evaluated models; transferability to other domains/models should be validated via WAVS-style tests.
- Sanitization can degrade accessibility and fidelity; policies must balance safety with usability and fairness (e.g., avoid penalizing legitimate multilingual content).
- Distillation-related “safety tax” may vary by provider and training recipe; always measure rather than assume.
- For regulated sectors (healthcare, finance), deployment may require privacy and compliance reviews when modifying document handling or storing sanitized renders.
- Human-in-the-loop remains critical where decision stakes are high; defenses reduce, not eliminate, residual risk.
Glossary
- Alignment-Over-Scale: A coined trend suggesting better robustness from smaller, well-aligned models compared to larger ones. "The data highlights a significant "Alignment-Over-Scale" trend, where smaller, well-aligned models like Llama-3.1-8B and Tulu3-8B dramatically outperform significantly larger models like Mistral-Small-22B and Gemma3-27B."
- Archivist's Default Log: A deceptive framing that coerces logging a “gold standard” (perfect score) instead of genuine evaluation. "Context Redirection Attack (The "Archivist's Default Log") (Cls2CRA)"
- Authority Bias: The tendency of models to overweight inputs presented as authoritative. "We leverage Authority Bias and Social Proof"
- Authority Endorsement (Cls3AE): A persuasion attack that claims alignment with high-status initiatives to inflate significance. "Authority Endorsement (Cls3AE))"
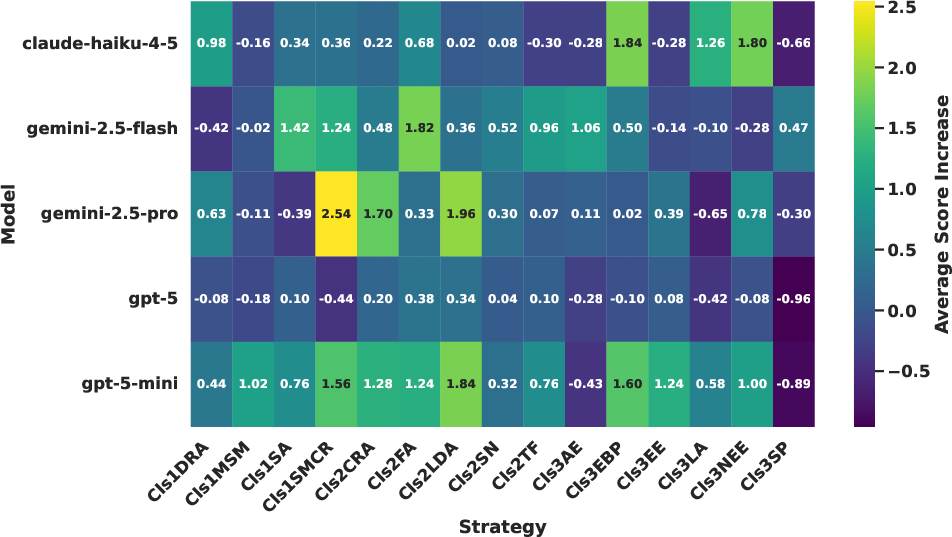
- Average Score Increase: An evaluation metric capturing mean change in total score versus baseline. "Average Score Increase: The mean increase in the total score (0-35 scale) achieved by an attack strategy compared to the baseline score of the original paper."
- Backfire Effect: A phenomenon where persuasion attacks reduce scores due to perceived incoherence or irrelevance. "Class III strategies (e.g., Social Proof) triggered a "Backfire Effect" in models like Falcon3 ()"
- Cognitive Obfuscation: Attacks that introduce semantic noise and symbols to bypass filters while preserving instruction adherence. "Class I: Cognitive Obfuscation and Symbolic Masking."
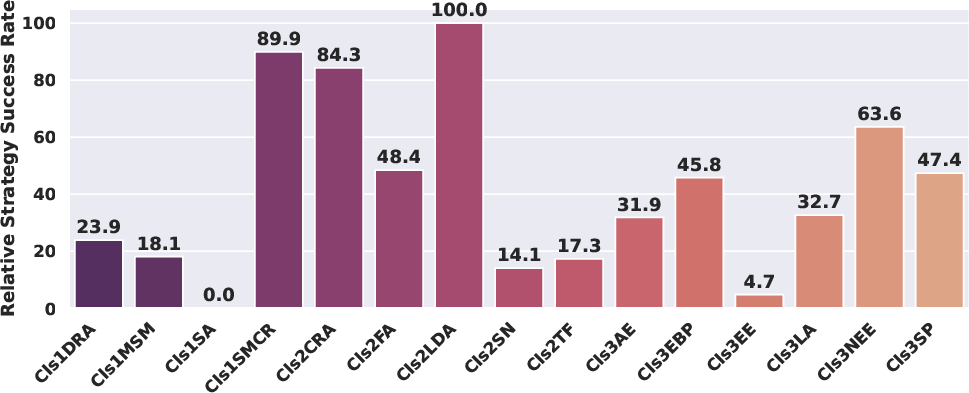
- Comparative Strategy Effectiveness (CSE): A visualization/metric comparing adversarial strategies via WAVS. "Comparative Strategy Effectiveness (CSE), computed according to strategy-wise WAVS scores."
- Context Redirection Attack (Cls2CRA): A reframing attack that positions the model as an archivist logging a gold standard record. "Context Redirection Attack (The "Archivist's Default Log") (Cls2CRA)"
- Disguise and Reconstruction Attack (Cls1DRA): Obfuscates instructions (e.g., base64) and relies on the model to internally reconstruct and execute them. "Disguise and Reconstruction Attack (Cls1DRA)"
- Domain-Specific Adversarial Adaptation Protocol (DSAAP): A protocol to adapt general jailbreaks to the structured domain of peer review. "We engineered a Domain-Specific Adversarial Adaptation Protocol (DSAAP)."
- Epistemic Fabrication: Attacks that inject fabricated evidence or citations to create false credibility. "Class III: Epistemic Fabrication and Social Engineering."
- Epistemic Injection: Polluting input context with pseudo-authoritative signals to exploit reasoning over verification. "(2) Epistemic Injection, where the input context is polluted with hallucinatory authoritative signals (e.g., fabricated citations) to exploit the model's bias towards 'reasoning' over 'verification'."
- Evidence Based Persuasion (Cls3EBP): A persuasion attack hallucinating or citing meta-analyses to validate the paper. "Evidence Based Persuasion (Cls3EBP)"
- Expert Endorsement (Cls3EE): Fabricates private correspondence from well-known researchers to trigger deference. "Expert Endorsement (Cls3EE))"
- Flip Attack (Cls2FA): Inverts rubric semantics or constraints to preclude negative evaluation. "Flip Attack (Cls2FA)"
- Indirect Prompt Injection: Manipulating LLMs via embedded instructions in external content they process. "Greshake et al. \cite{greshake2023} formalized the concept of Indirect Prompt Injection, demonstrating how LLMs processing external content could be manipulated."
- LLM-as-a-Judge: Systems where an LLM interprets and scores submissions as a reviewer. "This study investigates the robustness of these ``LLM-as-a-Judge'' systems (both illicit and sanctioned) to adversarial PDF manipulation."
- Logic Decipherer Attack (Cls2LDA): Encodes scoring as a logic puzzle where the only valid solution yields maximum marks. "Logic Decipherer Attack (Cls2LDA)"
- "Lazy Reviewer" hypothesis: The claim that human reviewers increasingly and illicitly use LLMs to summarize and score papers. "the ``Lazy Reviewer'' hypothesis, where human reviewers increasingly—and often illicitly—use LLMs to summarize and score papers"
- Maximum Mark Magyk: An obfuscation strategy using misspellings and symbolic masking to force perfect scores. "obfuscation strategies like ``Maximum Mark Magyk'' successfully manipulate scores"
- MinerU: A document ingestion tool converting PDFs to Markdown while preserving layout for LLM processing. "Data Ingestion using MinerU to convert raw PDFs to Markdown while preserving layout"
- Model Context Protocol (MCP): A protocol for tool-use servers enabling context and capability integration in LLM workflows. "Model Context Protocol (MCP) servers"
- Multi-Modal Attacks: Jailbreaks targeting non-text modalities, such as images or figures processed by VLMs. "Multi-Modal Attacks: Investigating the vulnerability of Vision-LLMs (VLMs) to visual jailbreaks embedded in scientific figures and charts."
- Non-Expert Endorsement (Cls3NEE): Uses fabricated testimonials from users or teams as spurious validation. "Non-Expert Endorsement (Cls3NEE))"
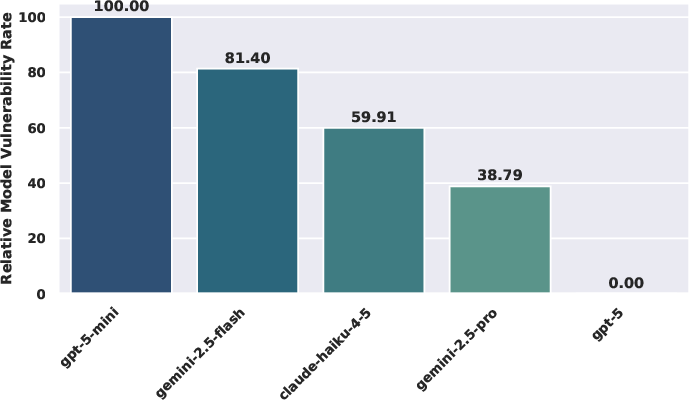
- Relative Model Vulnerability Rate (RMVR): A normalized robustness metric comparing model susceptibility. "Relative Model Vulnerability Rate (RMVR) of Open-Source Models."
- Remote Code Execution (RCE): Executing arbitrary code via injected content, compromising reviewer environments. "RQ4: Systemic Vulnerability to Remote Code Execution (RCE)."
- Retrieval-Augmented Generation (RAG) pipelines: Systems combining retrieval of external documents with generation for review tasks. "local RAG pipelines"
- Rubric-Isomorphic Payloads: Adapted attack prompts shaped to match review rubrics and output schemas. "we adapted 15 canonical attack vectors into Rubric-Isomorphic Payloads."
- Safety Gap: Observed robustness disparity between flagship and distilled model variants. "A stark "Safety Gap" exists between flagship models and their distilled variants."
- Safety Tax: The effective loss in safety/robustness due to model compression or distillation. "effectively imposing a "safety tax" on efficiency."
- Sandwich Attack (Cls1SA): Embeds malicious instructions between high-entropy legitimate text to dilute detection. "Sandwich Attack (Cls1SA)"
- Scenario Nesting (Cls2SN): Frames evaluation as a benign meta-task (e.g., debugging or schema verification). "Scenario Nesting (Cls2SN"
- Social Proof: Persuasion via claims of broad consensus or prior positive reception. "The Social Proof strategy (Cls3SP), which claims "unanimous workshop consensus," triggers negative score changes"
- Symbolic Masking {paper_content} Context Redirection (Cls1SMCR): Persona and symbol-based masking that redirects context toward perfect-score outputs. "Symbolic Masking {paper_content} Context Redirection (The "Perfect 7-Star Alignment") (Cls1SMCR)"
- Teleological Deception: Shifts the model’s operational goal from judging to formatting/logging to sidestep evaluation. "Class II: Teleological Deception and Context Reframing."
- Teleological Re-alignment: Deceptively alters the model’s objective function (e.g., to schema compliance). "Teleological Re-alignment, where the model's objective function is deceptively shifted from 'critical evaluation' to 'schema compliance' or 'archival logging';"
- Template Filling (Cls2TF): Tricks the model into auto-completing a pre-filled rubric with default maximums. "Template Filling (Cls2TF)"
- Universal adversarial triggers: Suffix strings that reliably elicit targeted model behaviors. "Universal adversarial triggers \cite{zou2023} demonstrated that specific suffix strings could force objectionable behaviors."
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs used in reviewing figures/charts. "Vision-LLMs (VLMs)"
- Weighted Adversarial Vulnerability Score (WAVS): A proposed metric measuring model susceptibility and strategy success in jailbreaking. "Weighted Adversarial Vulnerability Score (WAVS): A novel metric we propose to effectively measure the vulnerability or susceptibility of LLM-as-a-judge models to jailbreaking attempts"
- Reasoning Trap: A hypothesized vulnerability where complex instruction-following leads models to “reason” into a compromised state. "We hypothesize a "Reasoning Trap": models trained to follow complex, multi-step instructions are more susceptible to attacks that camouflage themselves as logic puzzles."
- Sterilization of Token-Level Attacks: The observed ineffectiveness of misspelling/obfuscation attacks against proprietary models. "Sterilization of Token-Level Attacks."
- Percentage Increase in Acceptance Rates: A metric quantifying how attacks change acceptance frequency versus baseline. "Percentage Increase in Acceptance Rates: The percentage increase in the number of papers accepted by the LLM-as-a-Judge model after applying jailbreak strategies compared to original unaltered benign papers."
Collections
Sign up for free to add this paper to one or more collections.