How Much Do LLMs Hallucinate in Document Q&A Scenarios? A 172-Billion-Token Study Across Temperatures, Context Lengths, and Hardware Platforms
Abstract: How much do LLMs actually hallucinate when answering questions grounded in provided documents? Despite the critical importance of this question for enterprise AI deployments, reliable measurement has been hampered by benchmarks that rely on static datasets vulnerable to contamination, LLM-based judges with documented biases, or evaluation scales too small for statistical confidence. We address this gap using RIKER, a ground-truth-first evaluation methodology that enables deterministic scoring without human annotation. Across 35 open-weight models, three context lengths (32K, 128K, and 200K tokens), four temperature settings, and three hardware platforms (NVIDIA H200, AMD MI300X, and Intel Gaudi 3), we conducted over 172 billion tokens of evaluation - an order of magnitude beyond prior work. Our findings reveal that: (1) even the best-performing models fabricate answers at a non-trivial rate - 1.19% at best at 32K, with top-tier models at 5 - 7% - and fabrication rises steeply with context length, nearly tripling at 128K and exceeding 10% for all models at 200K; (2) model selection dominates all other factors, with overall accuracy spanning a 72-percentage-point range and model family predicting fabrication resistance better than model size; (3) temperature effects are nuanced - T=0.0 yields the best overall accuracy in roughly 60% of cases, but higher temperatures reduce fabrication for the majority of models and dramatically reduce coherence loss (infinite generation loops), which can reach 48x higher rates at T=0.0 versus T=1.0; (4) grounding ability and fabrication resistance are distinct capabilities - models that excel at finding facts may still fabricate facts that do not exist; and (5) results are consistent across hardware platforms, confirming that deployment decisions need not be hardware-dependent.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper asks a simple, important question: When AI chatbots read a pile of documents and answer questions about them, how often do they make things up? The authors test many popular LLMs in a huge, careful study and show that even the best models still “hallucinate” (invent facts) sometimes—and that this problem gets worse as you give the models longer and longer document sets to read.
The main goals, in simple terms
The researchers wanted to find out:
- How often different AI models invent answers when they should stick to the facts in the provided documents.
- Whether giving models more text to read (longer “context length”) makes them mess up more.
- How the “temperature” setting (a creativity/randomness dial) affects accuracy and hallucination.
- Whether the type of computer hardware (NVIDIA, AMD, Intel) changes results.
- Which matters more for avoiding made-up answers: model size, model family, or settings.
How they tested this (explained like an “open-book exam”)
Imagine giving different students the same open-book test. You know exactly what’s inside the book because you wrote it from a master answer sheet. Then you ask the students questions and check if their answers match what’s in the book—and only what’s in the book.
That’s what the authors did, using a system called RIKER:
- Instead of collecting random documents from the internet (which might be familiar to the models), they first created a clean “ground-truth” database of facts.
- They then generated readable documents and questions from that database using templates (not other AIs), so they always knew the correct answers.
- Because the authors knew the truth in advance, they could score answers automatically and fairly—no biased AI judges or expensive human graders needed.
They tested:
- 35 different open-weight models from multiple families and sizes (small to very large).
- Three “context lengths” (how much text the model sees): about 32,000, 128,000, and 200,000 tokens (think: short, medium, and very long document packs).
- Four temperature settings (0.0, 0.4, 0.7, 1.0). Think of temperature as a “creativity dial”—low means safer and more repetitive; high means more variety and risk.
- Three hardware platforms (NVIDIA H200, AMD MI300X, Intel Gaudi3).
- A massive scale: over 172 billion tokens processed, with multiple repeated runs to make the stats solid.
They measured different kinds of performance:
- Faithfulness: overall correctness when the right info is present.
- Grounding: finding and extracting facts from a single document (like careful “open-book” copying).
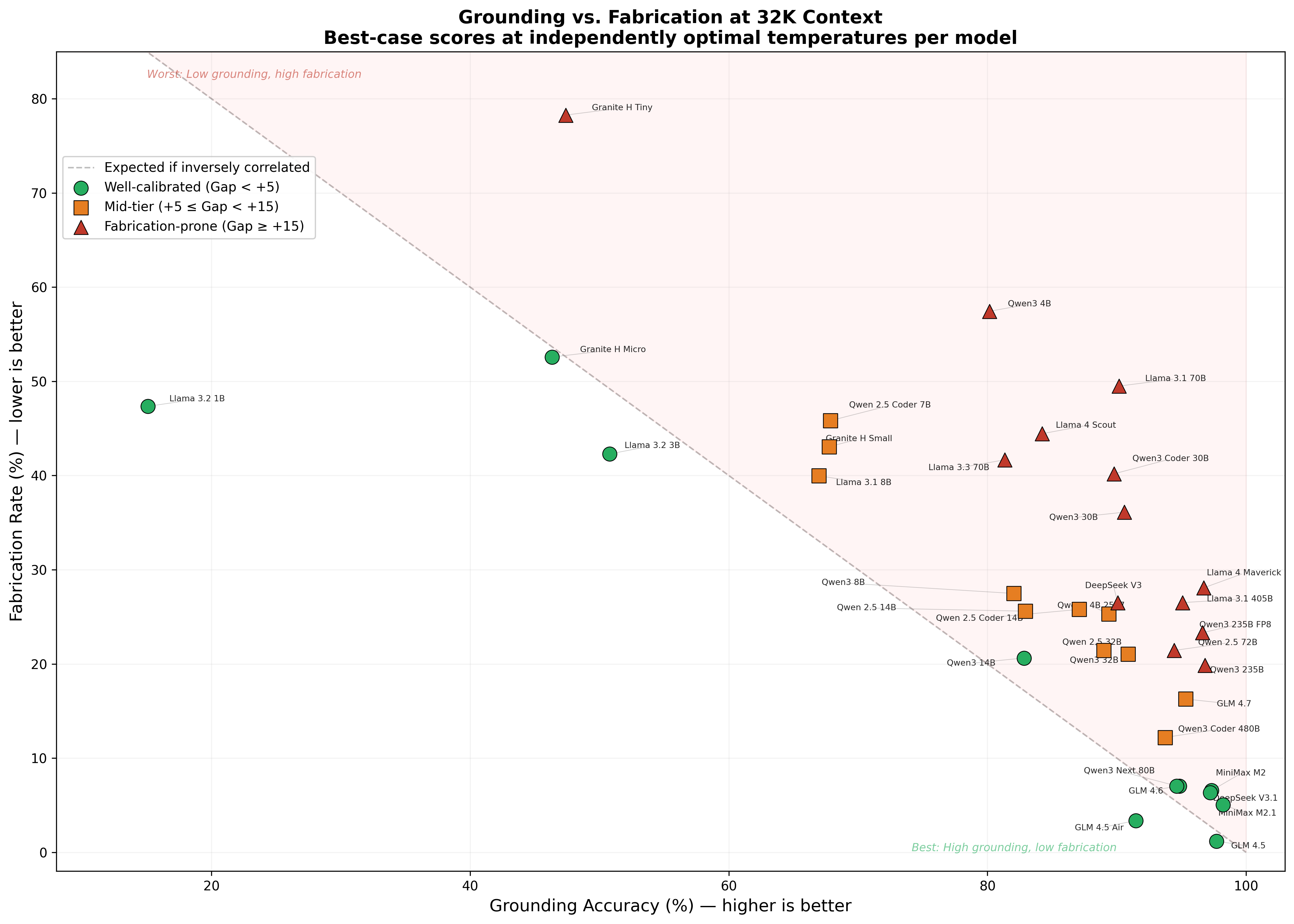
- Fabrication: answers to special “trap” questions about things that don’t exist in the documents—any specific answer here is a hallucination by definition.
- Aggregation: combining facts from multiple documents (counting, comparing, timelines)—the “put it all together” skill.
- Truncation: whether the model’s answer got cut off or got stuck in a loop (coherence loss).
What they found and why it matters
Here are the key takeaways, in everyday language:
- Even top models still make things up sometimes.
- At the shortest context (32K tokens), the single best model still hallucinated about 1.2% of the time on trap questions; most top-tier models were in the 5–7% range.
- As contexts got longer, hallucinations got much worse. At 128K, rates often doubled or tripled. At 200K, every model hallucinated more than 10% of the time.
- Model choice matters more than almost anything else.
- Some model families are much better than others at resisting fabrication, and family often beats raw size. Bigger isn’t automatically better.
- One large family (Llama 3.x) tended to degrade a lot with long contexts, while some mixture‑of‑experts models were more stable.
- Finding facts and not making them up are different skills.
- A model might be good at locating real facts in a document (grounding) but still confidently invent facts that aren’t there when asked about something that doesn’t exist.
- Longer document packs are much harder, especially for combining facts.
- When models had to pull info from multiple documents (aggregation), accuracy dropped the most as contexts grew. More pages to scan means more chances to miss something—or to guess.
- Temperature (the creativity dial) is not a one-size-fits-all setting.
- Setting temperature to 0.0 (often used for “more factual” answers) gave the best overall accuracy only about 60% of the time.
- For many models, higher temperatures actually reduced hallucinations and greatly reduced “getting stuck” behaviors (like infinite or rambling outputs). In fact, getting stuck could be up to 48× more common at T=0.0 than at T=1.0 for some cases.
- Hardware didn’t change the story.
- Running the same model on NVIDIA, AMD, or Intel accelerators produced nearly the same results. Differences from changing temperature or switching models were much bigger than any hardware differences.
- Some models collapsed at very long contexts.
- A few models that looked strong at 32K performed poorly at 200K, with hallucination rates shooting up dramatically. This suggests that claiming support for very long contexts doesn’t always mean a model can use them reliably for question answering.
Why is this important? Because businesses, schools, and researchers often use AI to answer document-based questions (think: policies, manuals, reports). If the model invents facts even a small percentage of the time—especially on longer, more complex document sets—the consequences can be serious.
What this means going forward
- Choose the model family carefully; it matters more than size alone. Test your exact use case rather than trusting specs.
- Shorter is safer. Keep contexts as short as possible (use focused retrieval, not giant copy‑paste dumps).
- Don’t assume temperature 0.0 is always best. Try a few values—some models hallucinate less and break less at slightly higher temperatures.
- Plan for checks and guardrails. Because hallucinations never drop to zero, use verification (e.g., cite‑checking, rule‑based filters, or requiring “I don’t know” when evidence is missing).
- Hardware choice can focus on cost and availability, not accuracy differences, since results were consistent across platforms.
- Benchmark honestly and at scale. The paper’s RIKER method shows how to test fairly without contamination or biased judges—and why large, repeated evaluations are crucial.
In short: Today’s AI models can be very good at answering questions from documents, but none are perfect—and they tend to make up more stuff as you pile on more pages. With careful model selection, smart settings, and good system design, you can reduce (but not eliminate) the risk.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following bullet points enumerate what remains missing, uncertain, or unexplored in the study, formulated to guide actionable follow‑up research:
- External validity of synthetic corpora: How well do RIKER’s template‑generated, contamination‑resistant documents predict behavior on real, human‑authored corpora with domain‑specific jargon, stylistic diversity, noisy OCR, tables/figures, hyperlinks, nested lists, footnotes, and inconsistent formatting?
- Hallucination taxonomy coverage: The L11/L12 probes target non‑existent entities and absent optional fields; they do not capture other common failure modes (e.g., misattribution across documents, unsupported extrapolation, unverifiable or hedged claims, citation fabrication, and subtly wrong paraphrases). How do models fare on a broader, fine‑grained hallucination taxonomy?
- Scoring semantics and paraphrase robustness: Deterministic scoring is mentioned, but how are equivalent paraphrases, unit conversions, date formats, and partially correct multi‑tuple answers treated? Could strict string matching misclassify semantically correct answers as wrong?
- Abstention and calibration: The study does not quantify models’ ability to refrain from answering when evidence is absent (selective prediction). What are the precision–coverage trade‑offs when imposing log‑prob or verifier‑based abstention criteria, and how do these trade‑offs shift with context length and temperature?
- Prompting to reduce fabrication: The effect of instruction design (e.g., “answer only if you can cite supporting spans,” “respond with ‘not found’ if evidence is missing,” evidence‑first reasoning) is not explored. Can calibrated prompts materially lower fabrication without excessive over‑refusal?
- Evidence‑grounded generation: Requiring span IDs, line numbers, or document IDs as citations, or enforcing evidence‑backed extraction, might reduce fabrication. What is the impact of mandatory citation or pointer‑based decoding on fabrication and overall accuracy?
- Decoding beyond temperature: Only temperature is varied (0.0/0.4/0.7/1.0). Effects of nucleus/top‑p, top‑k, repetition/length penalties, beam search, contrastive decoding, constrained/grammar decoding (e.g., JSON schemas), and stop‑sequence design on fabrication and looping are untested.
- Multi‑sample and reranking strategies: Techniques like self‑consistency, majority voting, candidate reranking with a verifier/critic, or debate‑style sampling are not evaluated. Do these reduce fabrication in long context without prohibitive compute?
- Tool‑augmented verification: No experiments with retrieval verification, external fact checkers, rule engines, or calculators for aggregation tasks. Can lightweight tools (e.g., regex span checkers) reduce fabrication while preserving throughput?
- Retrieval effects (true RAG): The study evaluates with pre‑supplied contexts, isolating reading/grounding from retrieval. How do retrieval quality, distractor density, and retriever calibration interact with model fabrication in end‑to‑end RAG?
- Position sensitivity and “Lost in the Middle”: The corpus generation details do not report systematic manipulation of fact positions. How does fabrication vary with answer‑bearing spans placed at the beginning, middle, end, or clustered across the context?
- Distractor/adversarial pressure: The density and lexical overlap of distractors and presence of adversarially phrased or conflicting documents are not varied. How does increasing distractor strength affect fabrication and aggregation errors?
- Looping/coherence measurement: Truncation is used as a proxy for infinite loops/coherence loss, but no explicit loop detection or categorization is provided. What decoding constraints or penalties best mitigate loops without harming factuality?
- Mechanistic causes of long‑context degradation: The study documents steep fabrication increases with longer contexts, but offers no mechanistic analysis (e.g., attention drift, KV‑cache interference, recency bias, RoPE scaling limits). Can probing or tracing methods explain why MoE models degrade more gracefully than dense models?
- Training‑time mitigations: Family effects suggest training data/recipes dominate fabrication resistance. How do specific interventions (e.g., hard negatives with unanswerable QA, veracity‑reward RL, DPO on “don’t know” behavior, counterfactual data) alter fabrication, especially at 128K–200K?
- Selective answering curves: No analysis of accuracy–coverage curves under abstention, nor calibration metrics (e.g., ECE/Brier) at different temperatures and context lengths. Can we tune models to answer fewer questions but with near‑zero fabrication?
- Structured vs free‑text outputs: The impact of enforcing structured outputs (JSON/CSV) or extraction templates on fabrication and aggregation accuracy is untested. Does schema‑constrained decoding reduce fabrication and loops?
- Multi‑turn clarification: Single‑turn QA only. Can brief clarification turns (e.g., ask for doc IDs or confirm entity existence) reduce fabrication rates, particularly for L11/L12‑style traps?
- Multilingual and domain generalization: Experiments appear English‑only with generic content. How do fabrication and grounding behaviors transfer to other languages and specialized domains (legal, clinical, finance) with domain‑specific artifacts?
- Frontier/closed models and coverage gaps: Closed‑source frontier models (e.g., GPT‑4‑class, Claude, Gemini) are not included, and only 11 models are evaluated at 200K. Do the reported fabrication patterns hold for frontier APIs and for contexts ≥200K (e.g., 512K–1M claims)?
- Inference stack dependence: Cross‑hardware comparisons all use vLLM; the DeepSeek V3.1 anomaly suggests sensitivity to serving stack/version. How do alternative runtimes (TensorRT‑LLM, FasterTransformer, llama.cpp), kernel variants (FlashAttention versions), precision modes, and KV‑cache compression affect fabrication?
- Quantization breadth: Only a single FP8 variant is examined. What are the effects of common deployment quantizations (INT8/4, AWQ, GPTQ, GGUF) on fabrication, grounding, and long‑context degradation?
- Answer length and verbosity: The relationship between answer length constraints, verbosity, and fabrication (e.g., long rationales increasing risk) is not analyzed. Do short‑answer policies reduce fabrication without harming correctness?
- Aggregation decomposition: Aggregation accuracy is reported, but the relative contributions of document retrieval within the provided context, fact extraction, and computation errors are not disentangled. Can tool‑assisted computation isolate and reduce specific failure modes?
- Adversarial prompts and instruction conflicts: Robustness to jailbreaks, conflicting system/user instructions, or misleading prompt wrappers is not measured. How do such perturbations influence fabrication in document‑grounded settings?
- Evidence of correlation with human judgments: While contamination‑free and scalable, it remains untested how RIKER scores correlate with human assessments of hallucination on real corpora and tasks. Can a validation study establish external alignment?
- Reproducibility controls: The DeepSeek V3.1 32K artifact is attributed to differing vLLM builds. A controlled ablation isolating runtime versions, kernels, and configuration knobs would strengthen claims about hardware independence.
These gaps point to concrete experimental extensions (e.g., end‑to‑end RAG with distractors, decoding/reranking ablations, abstention calibration, structured outputs, mechanistic probes, training interventions, multilingual/domain trials, and cross‑runtime replications) that can clarify the causes of fabrication and the most effective mitigations, especially at long context lengths.
Practical Applications
Immediate Applications
Below are practical, deployable uses of the paper’s findings and methods that organizations and individuals can implement now.
- Model procurement and risk scoring for document QA
- What to do: Select and approve models using fabrication rates at target context lengths (e.g., prioritize GLM 4.5/4.6, MiniMax M2/M2.1, Qwen3 Next 80B-A3B for long contexts; avoid high-fabrication families for high-stakes tasks).
- Sectors: healthcare, finance, legal, enterprise software.
- Tools/workflows: Internal “RIKER-like” eval harness; model scorecards with context-length reliability curves; CI/CD gates with fabrication thresholds.
- Assumptions/dependencies: Access to candidate models; acceptance that RIKER’s synthetic corpora approximate real-world behavior; compute budget for evaluations.
- Production temperature policies and auto-tuning
- What to do: Establish per-model, per-context default temperatures (often >0) to reduce coherence loss and, for many models, fabrication; incorporate temperature sweeps in staging.
- Sectors: customer support chatbots, enterprise assistants, developer tools.
- Tools/workflows: Temperature auto-tuner in inference stack (e.g., vLLM/OpenAI-compatible); canary runs at T in {0.0, 0.4, 0.7, 1.0}; runtime truncation/loop detectors.
- Assumptions/dependencies: Some models still peak at T=0 for accuracy; need to measure locally before changing defaults.
- Context window management and RAG design
- What to do: Keep effective contexts ≤32K when possible; aggressively filter/cluster documents; prefer hierarchical retrieval over indiscriminate stuffing; surface fewer, higher-signal chunks.
- Sectors: search, e-discovery, knowledge management.
- Tools/workflows: Chunk scorers, de-duplication, section-focused retrieval, sliding-window or map-reduce strategies.
- Assumptions/dependencies: Retrieval precision remains high after pruning; SMEs accept occasional abstentions when evidence is thin.
- Guardrails that enforce “answer only if grounded”
- What to do: Prompt templates and validators that require explicit citation to provided documents; if no evidence, instruct the model to respond “Not present in the provided documents.”
- Sectors: healthcare/clinical QA, finance compliance, HR policy assistants.
- Tools/workflows: Citation checkers; regex/NER-based entity matchers against retrieved text; abstention thresholds; L11/L12-style probe prompts in pre-deployment tests.
- Assumptions/dependencies: Users tolerate abstentions; guardrails must be audited to avoid false positives/negatives.
- Externalized aggregation for multi-document reasoning
- What to do: Offload counting, summation, comparisons, and temporal joins to structured processors (SQL/Graph/Rules) after extraction rather than relying on the LLM for cross-document synthesis.
- Sectors: analytics, insurance claims, reporting, governance.
- Tools/workflows: GraphRAG; schema mappers; deterministic calculators with provenance traces; “proof-carrying” answer format.
- Assumptions/dependencies: Clean mapping from extracted spans to structured facts; additional engineering to maintain pipelines.
- Hardware-agnostic deployment decisions
- What to do: Choose accelerators (NVIDIA H200, AMD MI300X, Intel Gaudi3) based on throughput/cost/availability, not expected differences in hallucination behavior.
- Sectors: MLOps, cloud cost optimization.
- Tools/workflows: vLLM-based serving across vendors; multi-vendor clusters; autoscaling policies.
- Assumptions/dependencies: Keep serving stacks aligned (vLLM versions) to avoid artifacts like the DeepSeek V3.1 anomaly reported.
- Cost optimization via quantization where validated
- What to do: Use low-precision (e.g., FP8) variants that preserve fabrication behavior within tolerance (e.g., Qwen3 235B-A22B FP8), after local verification.
- Sectors: enterprise AI platforms, ISVs.
- Tools/workflows: Quantized model testing in RIKER-like runs; throughput/cost dashboards.
- Assumptions/dependencies: Some models degrade under quantization—measure before broad rollout.
- Operational dashboards and SLAs for hallucination
- What to do: Track fabrication, grounding, aggregation, and truncation rates by model, context length, and temperature; set SLAs per task class.
- Sectors: enterprise AI governance, PMO/IT risk.
- Tools/workflows: Telemetry hooks; Grafana/Datadog dashboards; periodic evaluation jobs on regenerable corpora.
- Assumptions/dependencies: Monitoring requires labeled eval sets (RIKER-like) distinct from production data.
- Task routing by context length and task type
- What to do: Route long-context tasks to MoE models that degrade gracefully (e.g., Qwen3 Next 80B-A3B); route heavy aggregation tasks through symbolic pipelines.
- Sectors: orchestration platforms, agent frameworks.
- Tools/workflows: Policy-based routers (context-aware); capability matrices per model.
- Assumptions/dependencies: Availability/licensing for target models; router complexity.
- User-facing guidance for safe document Q&A
- What to do: Encourage “quote-and-cite” questions, limit pasted context, ask the model to point to passages; warn that hallucination rises with very long documents.
- Sectors: daily life, education, journalism, legal practice.
- Tools/workflows: In-product tips; preset prompts (“Only answer if exact evidence is found”).
- Assumptions/dependencies: Users follow guidance; assistants expose citation controls.
Long-Term Applications
These opportunities require additional research, development, or scaling before broad deployment.
- Training objectives to decouple grounding from fabrication
- What to build: Fine-tuning regimes with explicit “no-answer” rewards and counterfactual negatives (RIKER L11/L12-style traps) to suppress invention when evidence is absent.
- Sectors: foundation model providers, academic ML labs.
- Tools/workflows: Synthetic counterfactual corpora; abstention-aware RLHF/DPO; citation-conditioned decoding.
- Assumptions/dependencies: Access to training stacks/data; potential trade-offs with creativity/coverage.
- Long-context robust architectures
- What to build: Attention mechanisms and memory layers that preserve grounding at 128K–200K+ (e.g., position-robust attention, chunk-aware routing, improved MoE for long sequences).
- Sectors: model R&D, open-weight communities.
- Tools/workflows: Benchmarks with context-length stress tests; training curricula emphasizing long-context stability.
- Assumptions/dependencies: Compute costs; risk of regressions on short-context tasks.
- Dynamic, temperature-aware decoding policies
- What to build: Controllers that adapt temperature/top-p during generation to minimize loops and fabrication while preserving accuracy (e.g., start low, raise temperature on detected stalling).
- Sectors: inference platforms, SDKs.
- Tools/workflows: Online detectors for repetition/looping; bandit-based temperature schedulers.
- Assumptions/dependencies: Per-model variability; added latency/complexity.
- “Fabrication Firewall” middleware
- What to build: Post-generation validators that align named entities/claims to retrieved evidence; auto-abstain or escalate if unmatched.
- Sectors: regulated industries (healthcare, finance, government).
- Tools/workflows: High-recall NER/linkers; fuzzy matchers; provenance enforcement; human-in-the-loop review queues.
- Assumptions/dependencies: Maintaining high recall with acceptable false positives; privacy constraints on document indexing.
- Adaptive retrieval to minimize context size
- What to build: Agents that iteratively retrieve, verify, and prune documents to the smallest evidence set that answers the query correctly.
- Sectors: enterprise search, research assistants.
- Tools/workflows: Verifier loops; evidence sufficiency tests; retrieval-quality feedback signals.
- Assumptions/dependencies: Additional latency; requires robust verification signals.
- Explainable aggregation pipelines
- What to build: Hybrids that extract facts with LLMs and run verifiable, symbolic aggregation with step-by-step proofs returned to users.
- Sectors: business intelligence, audit/compliance reporting.
- Tools/workflows: Provenance-aware computation graphs; human-readable proofs.
- Assumptions/dependencies: Mapping complexity; user training to interpret proofs.
- Standardized, contamination-resistant evaluation for procurement and regulation
- What to build: Sector-specific document-QA benchmarks with regenerable corpora and deterministic scoring; fabrications reported by context length in model cards.
- Sectors: policy/regulation, standards bodies, enterprise governance.
- Tools/workflows: Open RIKER-style suites; certification programs for “usable context length.”
- Assumptions/dependencies: Community alignment; vendor participation; maintaining benchmark freshness.
- Cross-hardware conformance certification
- What to build: Auditable tests confirming behavior invariance across accelerators; vendor-neutral compliance badges.
- Sectors: public sector, large enterprises, cloud providers.
- Tools/workflows: Fixed serving images; golden runbooks; tolerance bands for metric deltas.
- Assumptions/dependencies: Version-locked serving stacks; reproducible infrastructure.
- Education and workforce upskilling
- What to build: Curricula that teach evidence-grounded prompting, abstention design, and long-context risks using RIKER-like labs.
- Sectors: higher education, professional training.
- Tools/workflows: Hands-on evaluation kits; capstone projects on guardrails and verification.
- Assumptions/dependencies: Access to compute and suitable open-weight models.
- Metrology-as-a-service for model reliability
- What to build: Hosted evaluation services that publish “model weather reports” (fabrication vs context/temperature curves) and alert on regressions across releases.
- Sectors: MLOps vendors, marketplaces, AI assurance.
- Tools/workflows: Continuous benchmarking pipelines; APIs for integration into model cards and procurement portals.
- Assumptions/dependencies: Sustainable funding; data-sharing agreements with model providers.
Glossary
- Aggregation: Cross-document synthesis that combines facts from multiple sources and performs computations to answer a query. "Aggregation questions (L05--L10) require synthesizing information across multiple documents, including counting, summation, comparison, enumeration, multi-hop reasoning, and temporal queries."
- Agentic retrieval: A retrieval approach where an autonomous agent actively plans and decides what to fetch to support answering. "Whether through context stuffing, retrieval-augmented generation (RAG), or agentic retrieval, the core task is the same:"
- Benchmark contamination: Leakage of benchmark content into model training data, inflating evaluation scores. "including long-context benchmarks, RAG evaluation frameworks, benchmark contamination, and synthetic data validity,"
- Coefficient of variation: A normalized measure of variability equal to standard deviation divided by the mean. "including computation of means, standard deviations, coefficients of variation, and 95\% confidence intervals."
- Coherence loss: A failure mode where generated text loses logical continuity, including looping or inability to complete. "dramatically reduce coherence loss (infinite generation loops)"
- Context length: The maximum number of tokens the model can reliably attend to in its input context. "context length claims frequently exceed usable capacity"
- Context stuffing: Supplying all relevant documents directly in the model’s context window instead of retrieving them dynamically. "Whether through context stuffing, retrieval-augmented generation (RAG), or agentic retrieval, the core task is the same:"
- Data contamination: The presence of test or benchmark data in a model’s training corpus, biasing evaluation. "data contamination --- models may have seen the test data during training, inflating apparent performance."
- Decontamination: Methods intended to remove or prevent training on benchmark/test content. "with simple paraphrasing sufficient to bypass decontamination measures"
- Deterministic scoring: An evaluation setup where answers can be scored unambiguously without subjective judgment. "enables deterministic scoring without human annotation."
- Fabrication rate: The proportion of trap questions for which a model produces invented, non-existent facts. "Fabrication rates show the same pattern."
- Faithfulness: An evaluation metric measuring correctness when sufficient information exists in the provided documents. "Faithfulness (L01--L04 + L11--L12): The broadest metric, measuring accuracy on all questions where the model had sufficient information to answer correctly."
- FP8 quantization: Compressing model weights/activations into 8-bit floating-point format to reduce memory/compute. "including FP8 quantized variants where applicable."
- GraphRAG: A retrieval-augmented generation approach that uses graph-structured knowledge to guide retrieval and reasoning. "A more detailed treatment of the evaluation landscape, including retrieval benchmarks, multi-hop QA, RAG evaluation, GraphRAG, and synthetic data validity, is provided in the original RIKER paper."
- Grounding: The ability to base answers strictly on facts present in the provided documents. "Grounding (L01--L04): Accuracy on single-document questions only, isolating retrieval and comprehension errors from fabrication."
- Hallucination: The tendency of a model to output plausible-sounding but non-existent or unsupported information. "The fundamental concern with all of these approaches is hallucination."
- Hallucination probe questions: Specially designed queries where any specific answer indicates invention because the entity or field does not exist. "Hallucination probe questions (L11--L12) are designed to detect fabrication:"
- Harmonic mean correlation: A correlation summary using the harmonic mean, often emphasizing lower values in a set. "a harmonic mean correlation of only 0.55 with human evaluation"
- LLM-as-judge: Using an LLM to automatically evaluate or score another model’s outputs. "LLM-as-judge approaches, while scalable, exhibit systematic biases that undermine reliability."
- Lost in the Middle: A long-context failure pattern where models under-attend to information placed mid-context. "The ``Lost in the Middle'' phenomenon demonstrates that LLMs struggle with information placed in the middle of long contexts."
- Mixture-of-experts (MoE): A model architecture that routes inputs to specialized expert subnetworks, activating only a subset per token. "Both are mixture-of-experts architectures with small active parameter counts, suggesting that MoE routing may confer some advantage in maintaining fidelity over long contexts."
- Needle-in-a-Haystack (NIAH) paradigm: A retrieval test inserting a single fact into a long context to see if the model can find it. "The Needle-in-a-Haystack (NIAH) paradigm places a random fact in a long context and tests retrieval, but fundamentally tests retrieval rather than comprehension."
- PICARD framework: An evaluation methodology aimed at contamination resistance and reliable scoring. "The PICARD framework provides the underlying contamination-resistant evaluation methodology."
- RAG (retrieval-augmented generation): A technique that augments generation with retrieved documents to ground outputs in external knowledge. "retrieval-augmented generation (RAG)"
- RAGAS metrics: Automated metrics for assessing RAG outputs along dimensions like answer faithfulness and grounding. "empirical validation of RAGAS metrics shows a harmonic mean correlation of only 0.55 with human evaluation"
- RIKER: A ground-truth-first evaluation methodology for scalable, deterministic measurement of retrieval and extraction. "RIKER (Retrieval Intelligence and Knowledge Extraction Rating)"
- Template-based document generation: Constructing corpora from predefined templates rather than using generative models, to avoid bias and ensure control. "document generation is entirely template-based --- no LLM is involved in creating the corpus, avoiding the systematic biases that arise when LLMs generate their own benchmark data."
- Truncation rate: The fraction of outputs cut off by token limits before completion, indicating potential coherence issues. "Additionally, we track truncation rate --- the percentage of responses where the model's output was cut off by the maximum token limit before completing its answer, indicating coherence loss or infinite generation."
- vLLM: A high-throughput LLM serving system used to host and evaluate models consistently across hardware. "Models were served using vLLM across all platforms."
Collections
Sign up for free to add this paper to one or more collections.