- The paper evaluates CLI-Tool-Bench, a novel benchmark for testing autonomous LLM-generated CLI tools using end-to-end black-box differential testing.
- It highlights significant performance gaps—from 76.93% installation success to 57.90% execution reliability—with pronounced challenges in Go due to compilation and type matching issues.
- The study underscores resource inefficiencies and structural limitations, prompting a need for improved agent architectures, enhanced debugging, and better workspace management.
Motivation and Benchmark Design
The paper addresses critical deficiencies in contemporary benchmarks for LLM-driven software generation, particularly their reliance on structural scaffolds and white-box testing paradigms. Recognizing these limitations, the authors introduce CLI-Tool-Bench, a benchmark specifically designed to evaluate the autonomous, ground-up generation of functional CLI tools across three programming languages—Python, JavaScript, and Go—spanning varying complexity levels and domains. Unlike prior benchmarks, CLI-Tool-Bench challenges agents to plan repository structure, manage dependencies, and synthesize code entirely from scratch, using only a natural language requirement.
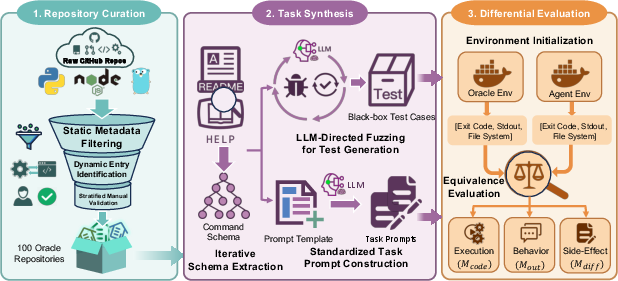
Figure 1: Overview of the CLI-Tool-Bench framework, detailing curation, schema extraction, task synthesis, and black-box evaluation.
The evaluation methodology centers on black-box differential testing. Generated tools are executed in isolated sandboxes, and their outputs, system-level side effects, and runtime behaviors are compared against human-written oracles using a rigorous, multi-tiered equivalence metric. This approach enables assessment of architectural autonomy and cross-language reasoning without penalizing structural diversity, thereby overcoming the rigidity inherent in prior scaffolding-based frameworks.
Experimental Protocol
The evaluation comprises seven state-of-the-art LLMs deployed in two prominent agent frameworks—OpenHands and Mini-SWE-Agent—yielding 14 agent configurations per repository. Each agent receives an anonymized prompt containing functional requirements, help documentation, and exemplar command executions. Installation and execution phases are performed in Docker containers, and the evaluation pipeline employs macro-averaging to ensure balanced scoring across command classes and test cases.
The results demonstrate a substantial performance gap between syntactic feasibility and behavioral fidelity. Across all models, there is a marked degradation from installation success (76.93%) to execution reliability (57.90%), and further to exact match outputs (23.07%). The best observed Semantic Match (SM) score is 42.74%, achieved by Kimi-k2.5 under Mini-SWE-Agent, with most models clustering between 30% and 40% SM. Notably, Claude-Sonnet-4.6 exhibits poor robustness, with a Build rate of 45.50% and SM of only 10.48%. The impact of agent framework choice is also significant—Mini-SWE-Agent is consistently superior, suggesting the importance of workspace management and interaction designs.
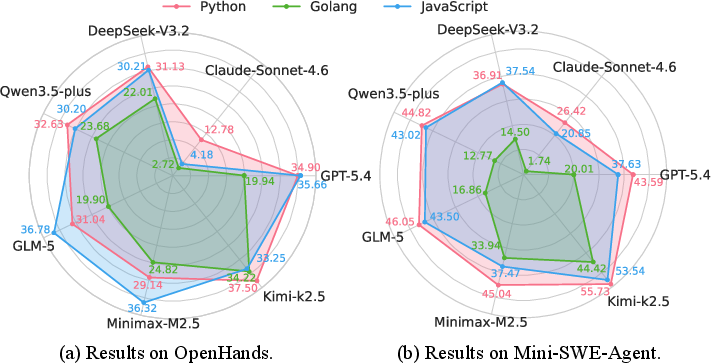
Figure 2: Model performance comparisons across Python, JavaScript, and Go, with pronounced deficits in Go.
The radar chart analysis reveals pronounced language bias: agents are highly competent in Python and JavaScript but exhibit severe struggles with Go, attributed to difficulties in type matching and compilation intricacies.
Complexity and Structural Trends
Analysis of the relationship between repository complexity and agent performance yields a non-monotonic, U-shaped pattern. Agents fail most in mid-sized repositories, which often require intricate cross-file reasoning and context retrieval. Unexpectedly, performance rebounds for large-scale repositories, likely due to standardized framework utilization that aligns with LLMs’ pretraining distribution.
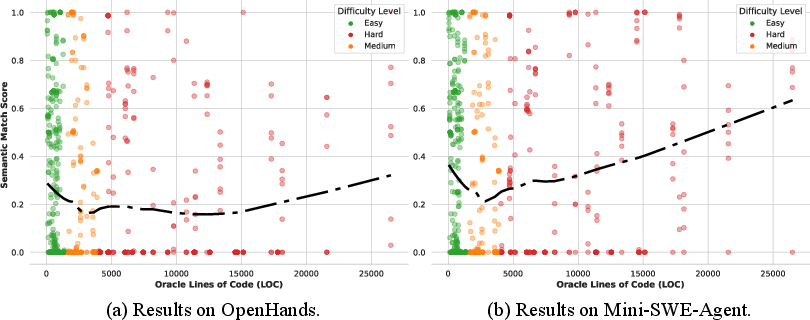
Figure 3: U-shaped correlation between repository complexity (LOC) and agent semantic match scores, highlighting mid-size bottlenecks.
Resource Utilization and Cost-Effectiveness
Token consumption and API costs are systematically analyzed. Models such as GPT-5.4 and GLM-5 demonstrate superior cost-effectiveness, achieving high semantic fidelity with minimal token footprints. Other models, notably Minimax-M2.5 and DeepSeek-V3.2, incur excessive context consumption due to repetitive debugging and workspace thrashing.
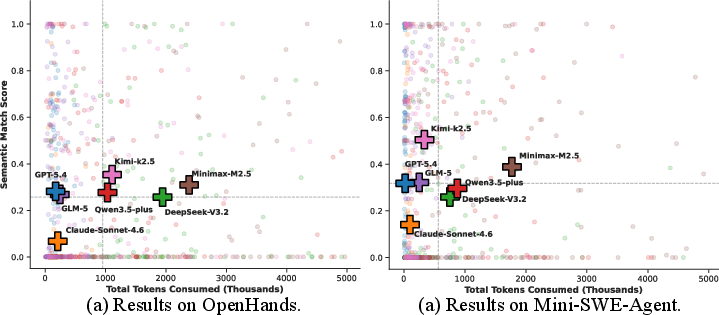
Figure 4: Trade-off analysis between token consumption and task performance, identifying optimal and suboptimal cost-performance regimes.
This strongly supports the finding that increased token consumption does not translate to better task resolution; agentic trajectories are prone to diminishing returns and inefficiencies in resource utilization.
Structural Autonomy and Repository Composition
Agents exhibit a marked preference for monolithic code structures, with median file counts tightly clustered between 1 and 3. Human oracles, by contrast, provide modularity and componentization typical of industry practice. File sprawl is observed in certain agents during debugging cycles, revealing divergent strategies in workspace management across frameworks.
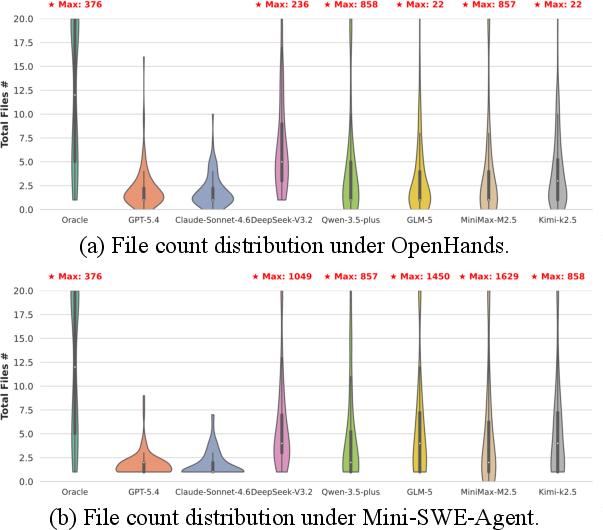
Figure 5: Distribution of file counts across agent-generated repositories and human oracles, highlighting monolithic bias and workspace sprawl.
Failure Modes and Qualitative Insights
Representative failure cases are categorized into installation failures (text-to-file bias and environmental blindness), execution failures (recursive workspace mismanagement), and behavioral mismatches (illusion of success without correct system-side effects). These modes demonstrate the necessity of rigorous, state-aware evaluation beyond simple output or execution status metrics.
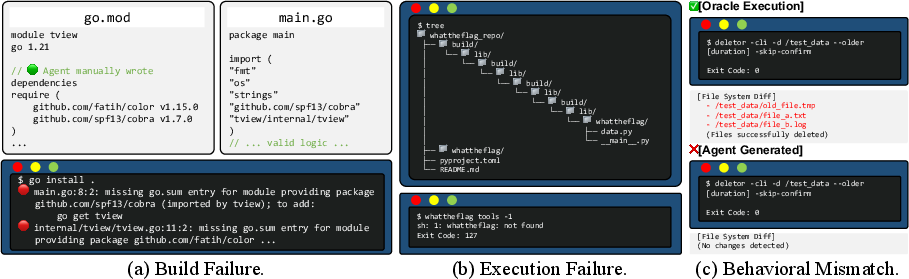
Figure 6: Illustrative failure modes in CLI tool generation by LLM agents: build errors, workspace mismanagement, behavioral mismatch.
Implications and Future Directions
The findings underscore several implications:
- Evaluation Paradigm: State-aware, multi-dimensional benchmarks such as CLI-Tool-Bench are essential for advancing LLM agent evaluation, particularly in system-level tasks with architectural freedom.
- Agent Architecture: Future research must address spatial awareness, holistic long-horizon planning, and self-reflective debugging to overcome workspace blindness and thrashing.
- Practical Deployment: Developers should provide structural scaffolds or enforce framework conventions when collaborating with agents, leveraging their strengths but mitigating their monolithic tendencies and lack of defensive programming practices.
Agentic minimalism results in faster, but less robust, outputs. In runtime efficiency studies, agent-generated tools outperformed human-written oracles, often at the expense of maintainability and user experience.
Conclusion
CLI-Tool-Bench establishes a new standard for structure-agnostic, end-to-end evaluation of software generation by LLMs. The benchmark reveals persistent limitations: the highest overall success rate remains below 43%, performance is non-monotonic with complexity, token use is not predictive of success, and agents universally favor monolithic designs. These insights will inform both theoretical advances in agentic reasoning and practical guidance for software developers integrating LLMs into toolchains.