- The paper introduces a Vision-Geometry-Action (VGA) model that maps multi-view visual inputs directly to 3D representations for precise robotic manipulation.
- It demonstrates exceptional performance with a 98.1% success rate in simulation and robust zero-shot generalization in real-world tests.
- The study challenges traditional vision-language backbones by emphasizing native 3D spatial reasoning and parameter-efficient fine-tuning via LoRA.
Rethinking Robotic Manipulation: Vision-to-Geometry Mapping via Vision-Geometry Backbones
Problem Statement and Motivation
The paper “Robotic Manipulation is Vision-to-Geometry Mapping (f(v)→G): Vision-Geometry Backbones over Language and Video Models” (2604.12908) scrutinizes the backbone paradigms for robotic policy learning. It asserts that physical robotic manipulation is fundamentally a vision-to-geometry problem, where geometric consistency—rather than semantic or 2D pixel-space correlation—should underpin robotic action generation. This framework is in direct contrast to the prevalent vision-language-action (VLA) and video-predictive model architectures leveraging vision-LLMs (VLMs) or video diffusion transformers, both of which rest on large-scale 2D or spatio-temporal pretraining datasets and are thus prone to overfit 2D priors, failing to capture the essential 3D spatial reasoning required for manipulation tasks.
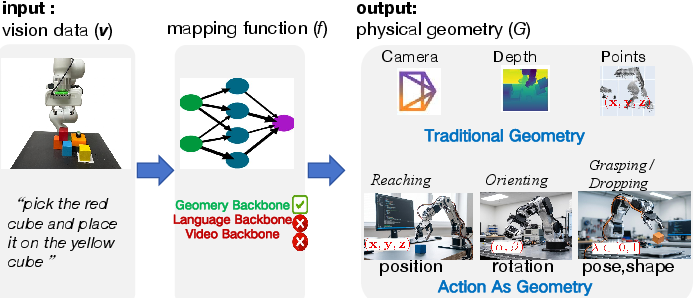
Figure 1: The vision-to-geometry mapping conceptualization, illustrating that geometric entities (positions, orientations, spatial structure) prescribe robot action, motivating a geometry-grounded model foundation.
VGA: A Vision-Geometry-Action Architecture
The heart of the proposed solution is the Vision-Geometry-Action (VGA) model. VGA abandons language and video backbones entirely, instead employing a pretrained 3D world model—specifically, VGGT—to map multi-view visual observations directly into comprehensive, native 3D representations. Action heads condition on these representations, giving rise to a seamless, geometrically grounded policy pipeline.
VGA’s multi-modal input includes multi-view RGB observations, language instructions, and robot proprioception. These signals are tokenized and processed with a transformer backbone that alternates between frame-wise intra-modality and cross-modality attention, constructing a token grid deeply aligned with geometric structure. The VGA decoding stage utilizes a Progressive Volumetric Modulation (PVM) module, optimally fusing these features for action prediction. VGA is optimized with a joint loss on both the physical actions and auxiliary 3D properties (camera parameters, depth maps) to enforce spatial reasoning consistency.
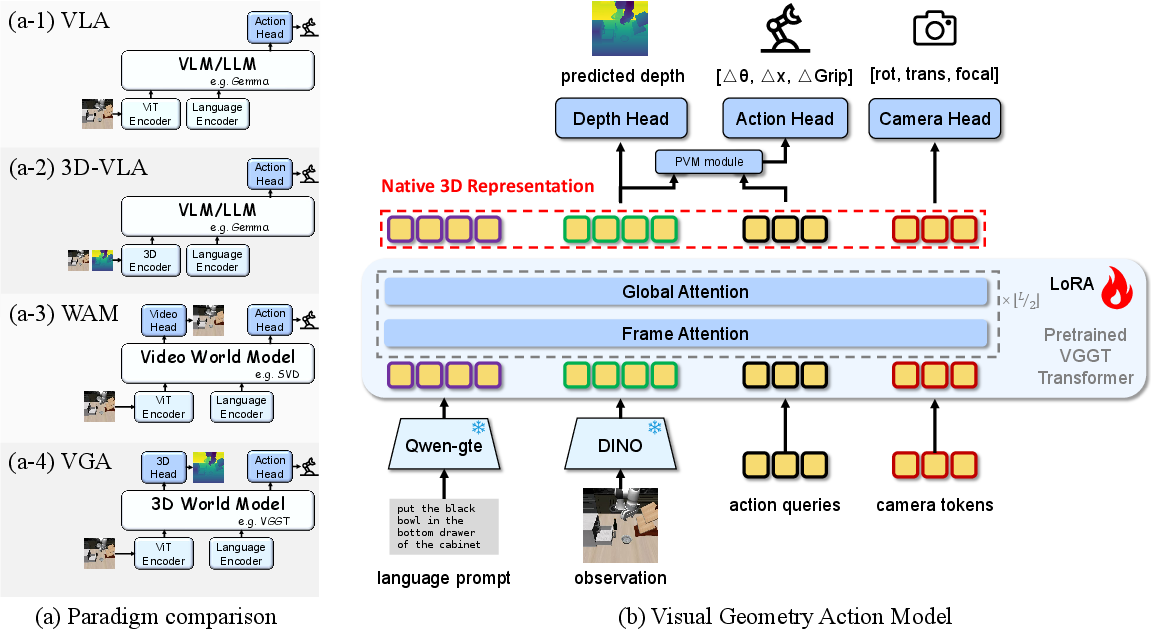
Figure 2: Workflow and structural overview of VGA, illustrating multi-modal tokenization, geometric cross-attention, progressive volumetric modulation, and unified representation for downstream action and 3D attribute prediction.
Key architectural innovations include:
- Native 3D backbone: Direct use of a pretrained geometric transformer (VGGT) for all perception-to-action information flow.
- Progressive Volumetric Modulation (PVM): Layer-wise injection and alignment of geometric priors for action generation.
- Joint training: Simultaneous prediction of 3D geometric attributes and robot actions to maximize cross-modal geometric consistency.
- LoRA parameter-efficient fine-tuning: Selective adaptation preserving backbone priors.
Simulated and Real-World Empirical Evaluation
Simulation Results: LIBERO Benchmark
VGA’s capabilities are analyzed on the LIBERO benchmark, which entails diverse manipulation tasks spanning spatial, object, compositional goal, and long-horizon reasoning. Evaluation focuses on task success rates, geometric prediction quality, and robustness to design ablations.
Numerical results demonstrate that VGA achieves a top-1 average success rate (98.1%) across LIBERO suites, outperforming state-of-the-art VLA models (π0.5, GeoVLA, OpenVLA-OFT) and even the strongest 3D-VLA and World Action Model (WAM) baselines.
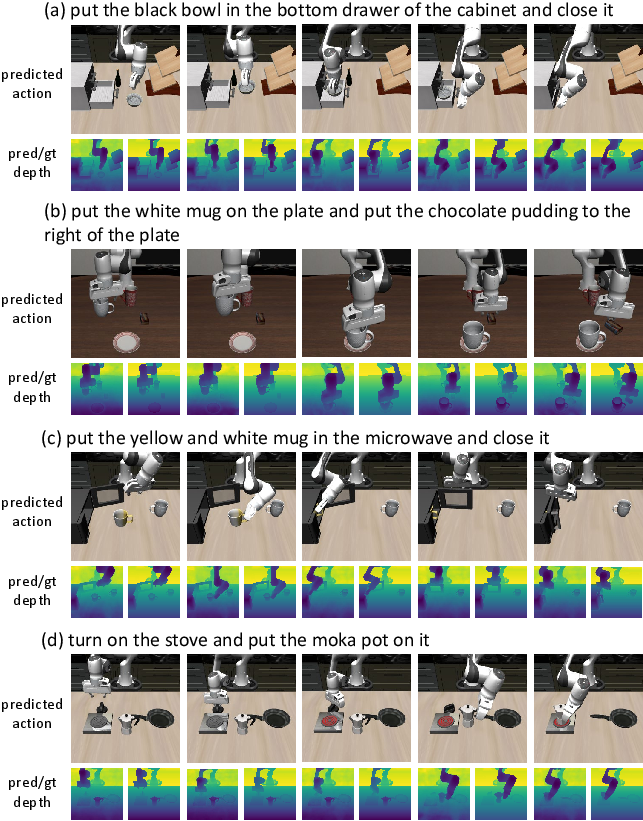
Figure 3: Simulation rollouts with corresponding VGA depth predictions highlight the model’s precise geometric scene understanding and strong manipulation performance.
Ablation studies validate the necessity of each design component: removal of PVM or joint training leads to up to 2.4% and 0.9% performance drops, respectively. The pretrained 3D backbone is essential; random initialization (even with LoRA) leads to catastrophic degradation (down to 6.4% success).
Auxiliary Geometric Prediction
Depth and camera parameter prediction is demonstrably accurate, especially for task-relevant scene regions (robot gripper, target objects), affirming that VGA’s representations retain high-fidelity 3D information critical for real-world transfer.
Real-World Experiments: Zero-Shot Generalization
Physical validation is achieved on a Franka Panda platform with multiple camera configurations. Three tasks (cube pick, button press, stack cube) quantify both in-distribution and extreme out-of-distribution (unseen camera viewpoint) performance.
VGA’s zero-shot generalization is particularly notable: when deployed with camera configurations unseen during training, VGA outperforms all baselines, including π0.5. While ACT and OpenVLA exhibit a rapid collapse in success under OOD conditions (7% and 3% respectively), VGA achieves a 58% average success rate, surpassing π0.5 by 6%. This finding is a strong contradiction of the assumption that generalist VLMs suffice for robust robotic transfer.

Figure 4: Real-world experiment configuration illustrating in-distribution and out-of-distribution camera placements for rigorous spatial generalization tests.

Figure 5: Visualized real-world VGA rollouts, demonstrating geometric robustness under both seen and novel observation configurations.
Language-Grounded Manipulation
VGA robustly grounds semantic language instructions to spatial actions, as evidenced by precise object selection in layouts with visually similar distractors.

Figure 6: Robustness of VGA in grounded grasping tasks across various object layouts, confirming effective visual-language-geometry integration.
Theoretical and Practical Implications
This work substantiates that geometry-grounded architectures fundamentally outperform those that build on semantic or video-centric representations for spatially-sensitive embodied control. Several theoretical implications are clear:
- Elimination of 2D bottleneck: By avoiding representation flattening and reconstructing, VGA maintains metric and volumetric consistency, yielding policies more robust to viewpoint and spatial configuration shifts.
- Separation of perception modalities: Results question the necessity of video or language backbones except when explicit commonsense reasoning is required—geometry alignment takes clear precedence for manipulation.
- Data efficiency and parameter economy: Fine-tuning with LoRA on pretrained geometric representations enables rapid convergence with a fraction of the trainable parameters and strong data efficiency.
On the practical side, these findings support the design of future generalist robots with robust, sensor-invariant manipulation capabilities without reliance on specialized 3D sensors or massive-scale video or language pretraining. A remaining limitation of VGA is its relatively weaker performance on tasks requiring long-horizon memory or high-level semantic reasoning, due to the focus on 3D scene understanding rather than sequence modeling at scale.
Future Directions
Further scaling VGGT-style 3D backbones with more diverse, temporally-extended datasets could close existing gaps on long-horizon tasks. Additionally, modular fusion with VLMs or explicit commonsense/semantic planning layers could re-introduce reasoning capabilities without sacrificing geometric fidelity. The study suggests that for embodied AI, pretraining on synthetic or recorded 3D environments may be a more fruitful path to generalization than mining ever-larger language or action datasets.
Conclusion
The paradigm shift from vision-language or video-centric pretraining to a strictly vision-to-geometry mapping—a native 3D world model backbone—enables unified, robust, and generalizable physical intelligence for robotic manipulators. The empirical, architectural, and theoretical evidence presented establishes geometry-anchored models as the leading backbone choice for embodied manipulation.

