- The paper demonstrates that depth map prediction as generative supervision significantly improves spatial reasoning and robotic manipulation.
- The GEM framework uses a hybrid VLM backbone coupled with a diffusion transformer-based depth generator, employing a progressive training pipeline.
- Empirical results show GEM models outperform state-of-the-art benchmarks, with key improvements in spatial grounding and real-world manipulation tasks.
Generative Supervision for Embodied Intelligence: The GEM Framework
Motivation and Conceptual Foundations
The paper "GEM: Generative Supervision Helps Embodied Intelligence" (2605.28548) addresses a central gap in existing Vision-LLMs (VLMs) for embodied intelligence, particularly within Vision-Language-Action (VLA) architectures. Standard VLMs, pre-trained predominantly on text-guided tasks, effectively align visual and linguistic representations at a semantic level. However, such models are limited in their capacity to encode low-level spatial and physical knowledge critical for actionable intelligence in dynamic environments. This semantic-structural disconnect is especially problematic for robotic manipulation, where understanding spatial geometry, object affordances, and physical constraints is indispensable.
The authors propose that generative supervision—specifically, depth map prediction as an auxiliary task during VLM pre-training—can bridge the semantic-physical divide. Unlike prior work where spatial or geometric priors are injected post hoc or treated as isolated modalities, GEM aims to unify structural and semantic feature learning directly in the foundational model.
GEM Architecture and Training Paradigm
GEM introduces a hybrid design: a VLM backbone augmented with a diffusion transformer-based depth generator, forming a generative-supervised model for embodied understanding. Visual tokens from the backbone are projected via a connector into a conditional space for depth synthesis, allowing the model to reconstruct depth maps corresponding to visual observations.
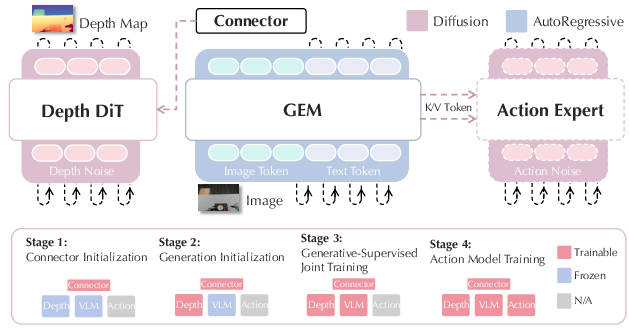
Figure 1: Architecture of GEM, showing the VLM backbone, DiT-based depth generator, connector, progressive training, and VLA action head.
A progressive training pipeline is employed:
- Stage 1: Connector initialization, aligning backbone outputs to the generator's input.
- Stage 2: Depth generator warm-up, adapting generative head to conditioning features.
- Stage 3: End-to-end joint optimization, allowing co-evolution of semantic and structural representations using combined cross-entropy and flow-matching generative losses.
On completion, the learned representations are further extended with a diffusion-based action expert for continuous action prediction, yielding GEM-VLA—a model capable of robust embodied task execution.
GEM-4M Dataset Construction
To support generative supervision and comprehensive embodied reasoning, GEM-4M is curated as a multi-million scale dataset. QA pairs span three core categories:
- Embodied Grounding: Object detection, localization, and affordance annotation from diverse sources, supplemented by automated point and bounding box extraction.
- Physical/Spatial Reasoning: 3D spatial estimation, measurement, and attribute perception using spatially annotated scene datasets augmented with manual curation.
- Spatiotemporal Planning: Sub-task segmentation, trajectory generation, and question-answer pairs designed for action planning and forecasting, utilizing visual traces of manipulated objects.
This dataset is normalized for resolution consistency and covers both open-vocabulary and structure-aware tasks, ensuring that training encompasses both semantic and geometric skill sets.
Empirical Results and Benchmark Evaluation
The GEM and GEM-VLA models are extensively benchmarked across a span of embodied reasoning and manipulation tasks. Highlights include:
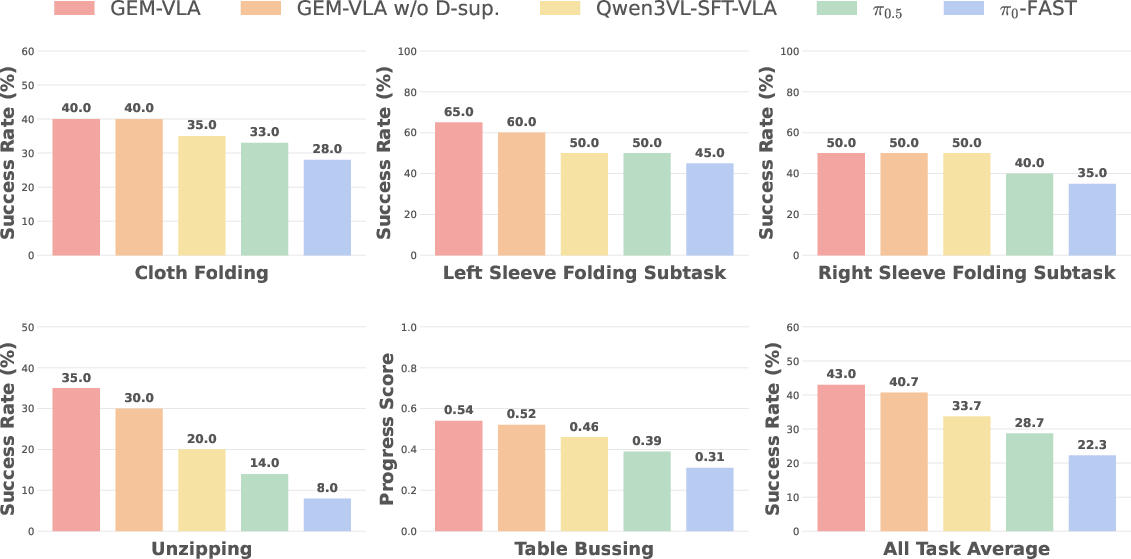
Real-world deployment on a UR5 platform confirms superior long-horizon robustness and deformable object manipulation, with success rates such as 43% on challenging tasks—marking a 14.3% increase over the previous top baseline.

Figure 3: Demonstrations of GEM-VLA completing table bussing, cloth folding, and zipper manipulation tasks on real robots.
Ablation Studies and Structural Priors
Through ablation, the authors validate two bold claims:
- Depth Is a Superior Supervisory Signal: Replacing depth generation with RGB reconstruction sharply reduces performance, especially on distance estimation tasks. Depth encoding is shown to supply explicit spatial cues absent in purely semantic SFT models.
- Progressive Training Is Essential: Direct end-to-end training produces unstable convergence and suboptimal fusion of semantic and structural features; the staged paradigm outperforms alternatives consistently.
Generated depth maps from GEM exhibit high fidelity, capturing nuanced geometric detail missing from standard SFT models.

Figure 4: Depth generation comparison; GEM visual tokens produce structurally rich maps, surpassing SFT-based features.
Qualitative Reasoning and Planning Examples
The model is showcased on multiple embodied AI benchmarks:
- Grounding: Objects mentioned in instructions are located and highlighted, supporting open-vocabulary spatial referencing.

Figure 5: Target objects localized and highlighted based on instructions.
- Spatial Reasoning: QA pairs cover absolute/relative distance, object size, room estimation, and direction understanding.

Figure 6: Spatial reasoning samples illustrating multidimensional geometric queries.
- Planning and Trajectory Prediction: Next-step and initial-step reasoning, task verification, and trajectory generation for complex manipulation.

Figure 7: Planning QA pairs for manipulation tasks.

Figure 8: Predicted multi-point trajectories for object transfer and task completion.
Practical and Theoretical Implications
GEM establishes a compelling case for integrating generative supervision within the pre-training phase of embodied VLMs, unifying semantic and structural learning to yield actionable intelligence. The model's adaptability, data efficiency, and ability to generalize sim-to-real are validated both quantitatively and qualitatively. The demonstrated superiority of depth supervision—over alternatives like RGB reconstruction or late-stage spatial priors—appears to generalize across diverse VLA architectures and manipulation tasks.
Practically, the approach enables fine-grained spatial reasoning and robust manipulation without incurring the cost of expensive 3D inputs or late-stage fusion complexity. Theoretically, the results encourage further investigation into generative objectives as intrinsic targets for multimodal foundation models.
Speculation on Future Directions
Future work is likely to focus on scaling GEM further in terms of model sizes and datasets, incorporating large-scale robot data for pretraining, and expanding the architecture to support additional modalities (e.g., point cloud, tactile inputs). Integration with broader action reasoning and planning benchmarks and deeper exploration of self-supervised generative signals in embodied learning are promising avenues.
Conclusion
GEM offers a rigorous framework for generative-supervised embodied intelligence, directly addressing the limitations of conventional VLMs in spatial and physical grounding. Its progressive training paradigm and depth-driven supervision yield superior performance across both simulation and real-world robot benchmarks, underscoring the value of structural priors for embodied reasoning and manipulation. The practical successes and ablation-backed claims indicate substantial potential for future multimodal model research and embodied AI applications.