- The paper introduces a framework that integrates multi-view latent priors using a pre-trained diffusion model to resolve monocular depth ambiguity.
- The paper employs Action Manifold Learning to directly decode actions on a low-dimensional manifold, boosting optimization efficiency and robustness.
- The paper demonstrates improved success rates and spatial consistency across benchmarks, validating its advantages in both simulation and real-world robotic tasks.
Learning Action Manifold with Multi-view Latent Priors for Robotic Manipulation
Introduction
"Learning Action Manifold with Multi-view Latent Priors for Robotic Manipulation" (2605.11832) addresses fundamental challenges in Vision-Language-Action (VLA) models for robotic manipulation, specifically the spatial perception bottleneck due to monocular depth ambiguity and suboptimal action generation rooted in high-dimensional indirect prediction targets (noise/velocity). The proposed framework synergistically integrates multi-view latent priors—synthesized with a pre-trained diffusion model—to augment spatial awareness, and employs Action Manifold Learning (AML) to directly decode actions on a low-dimensional manifold, mitigating the optimization inefficiencies inherent in conventional diffusion/flow-matching paradigms.
Methodology
The core methodological advance is leveraging pre-trained multi-view diffusion models to synthesize latent representations of novel viewpoints, thereby providing complementary geometric context and resolving monocular depth ambiguities without necessitating explicit 3D sensors.
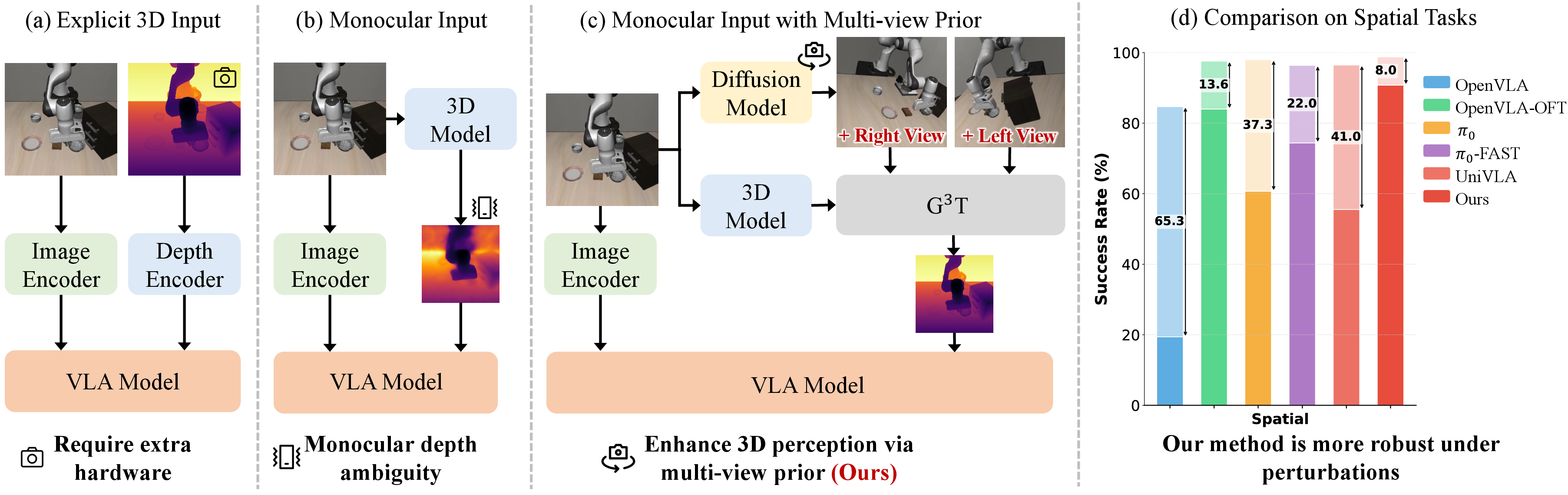
Figure 1: Methodology comparison—existing VLA models rely on explicit 3D sensors or suffer severe monocular depth ambiguity; the proposed method resolves these using multi-view diffusion priors and $\text{G^3\text{T}}$.
Synthesized multi-view latents are integrated via the Geometry-Guided Gated Transformer ($\text{G^3\text{T}}$), which aligns and adaptively gates spatial tokens under monocular and multi-view priors to produce robust spatial embeddings.
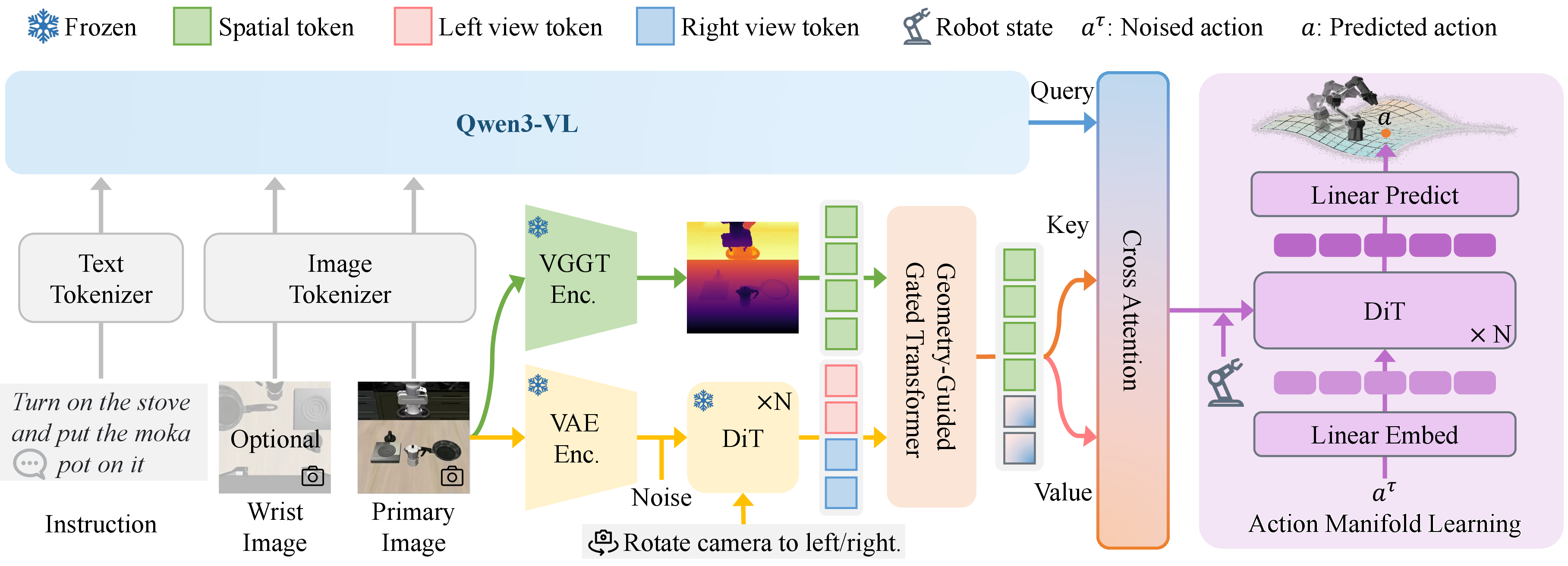
Figure 2: Overview of the method—multi-modal inputs processed for semantic and spatial features, fused via $\text{G^3\text{T}}$, then fed to AML for action decoding.
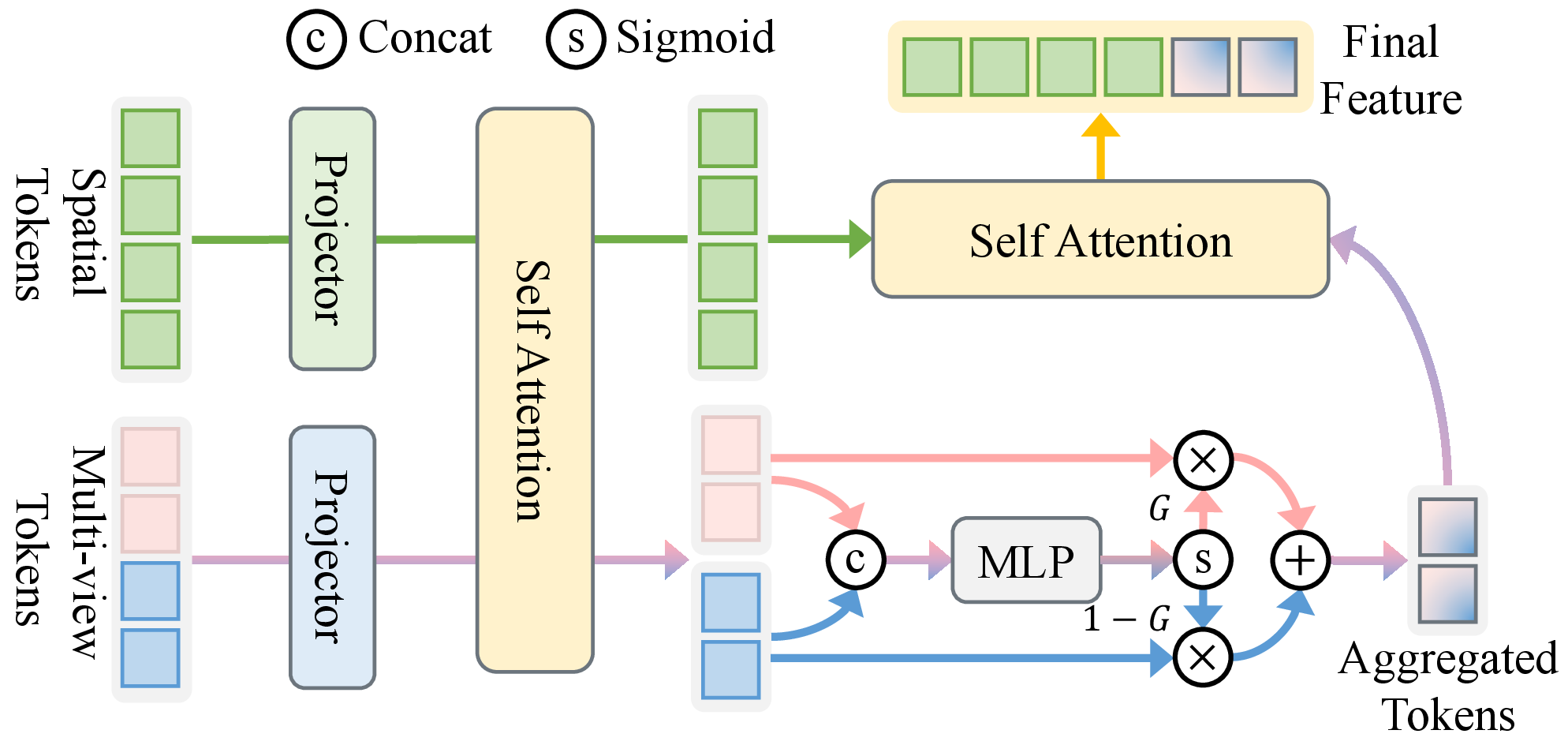
Figure 3: Architecture of $\text{G^3\text{T}}$, detailing fusion of monocular and synthesized spatial tokens.
This mechanism includes an adaptive gating mechanism that dynamically weights synthesized viewpoints according to reliability, suppressing occluded or noisy regions and enhancing geometric consistency.
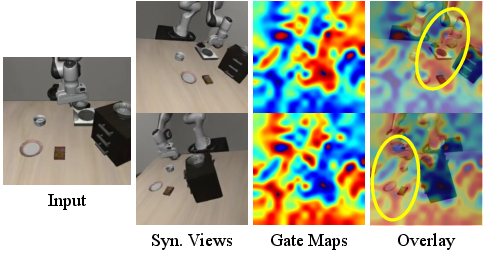
Figure 4: Visualization of $\text{G^3\text{T}}$ gating—reliable geometric structures are highlighted, occluded/unreliable regions suppressed.
Action Manifold Learning Paradigm
The Action Manifold Learning (AML) module eschews indirect prediction targets and directly learns the intrinsic structure of valid action sequences by operating on the action manifold hypothesis: successful actions are highly structured, residing on a low-dimensional manifold shaped by task, physical, and environmental constraints.
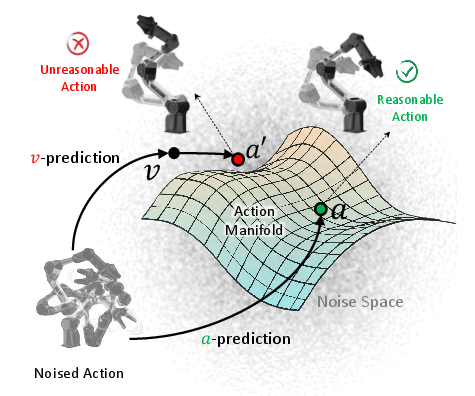
Figure 5: Action manifold hypothesis—valid actions reside on a low-dimensional structured manifold; conventional noise/velocity targets are off-manifold and harder to learn.
Formally, AML decodes action chunks directly via a Diffusion Transformer (DiT), offering superior optimization efficiency, robustness, and scalability vis-à-vis baseline diffusion/flow-matching approaches. The AML loss incorporates a velocity-consistent formulation, dynamically weighting learning signals across noise levels.
Experimental Validation
Benchmark Results
Extensive empirical evaluation across LIBERO, LIBERO-Plus, RoboTwin 2.0, and real-world robotic setups demonstrates consistent superiority in success rate and robustness.
- LIBERO: 98.6% average success rate; highest among all methods.
- LIBERO-Plus (zero-shot robustness): 85.7% success rate and lowest performance degradation (12.9% on average), outperforming OpenVLA-OFT, π0, UniVLA, and other leading VLAs.
- RoboTwin 2.0: >80% success rate in bi-manual manipulation tasks even under severe domain randomization.
- Real-world: Higher success rates in all manipulation tasks compared to representative baselines (OpenVLA-OFT, π0).
Ablation studies confirm the optimality of the proposed fusion and gating strategies, as well as the incremental gains provided by multi-view synthesis, $\text{G^3\text{T}}$, and AML.
Depth Estimation and Spatial Perception
$\text{G^3\text{T}}$-enhanced spatial embeddings yield significant improvements in both absolute depth estimation error and structural coherence, demonstrating sharper boundaries and improved geometric consistency compared to the monocular baseline.

Figure 6: Qualitative visualization—$\text{G^3\text{T}}$ yields robust depth estimation with sharp edges and consistent geometry, outperforming standard monocular approaches.
Action Learning Efficiency
AML exhibits minimal degradation as action chunk size or denoising steps increase, affirming its structured optimization landscape and efficient learning even in high-dimensional temporal action spaces. In contrast, velocity-based baselines suffer severe drops in performance as dimensionality increases.
Real-world Deployment and Generalization
Experimental Setup
A unified model trained on real-world demonstrations executes complex manipulation tasks with high success rates across geometric-constraint and stability-demanding tasks.

Figure 7: Real-world experimental setup using Franka Emika Panda robot.
Qualitative Results & Zero-shot Generalization
Qualitative results demonstrate reliable execution in both clean and cluttered unseen contexts, with robust compositional reasoning and distractor-resistant policy performance.

Figure 8: Qualitative results—execution in trained context.

Figure 9: Zero-shot generalization setup—illustrates unseen task configurations.

Figure 10: Qualitative results in clean and cluttered context—robust to distractors and attribute changes.
Discussion: Implications and Future Directions
Practical Implications
By enabling precise spatial perception and robust action generation solely from monocular RGB inputs, the proposed framework markedly lowers deployment barriers, eliminating the need for expensive explicit 3D sensing hardware and complex multi-view coordination. The AML paradigm further allows for efficient learning and execution over longer horizons and higher-dimensional action spaces, improving reliability in challenging real-world scenarios.
Theoretical Implications
Methodologically, the integration of multi-view generative priors and direct action manifold learning shift the optimization landscape from unstructured, high-dimensional targets to structured, low-dimensional manifolds, aligning with broader geometric-representation trends in embodied AI. The adaptive gating in $\text{G^3\text{T}}$0 substantiates the importance of view selection and occlusion-aware spatial fusion, reinforcing geometric consistency even under severe visual disturbance.
Limitations and Future Work
The main computational limitation stems from the diffusion-based multi-view synthesis overhead, which precludes real-time responsiveness for high-frequency control. Distilling geometric reasoning directly into the VLA backbone, thereby circumventing the need for generative modules at inference, constitutes a promising direction.
Conclusion
The proposed VLA framework, integrating geometry-guided multi-view latent priors with action manifold learning, effectively resolves monocular spatial ambiguity and optimizes action decoding efficiency for robotic manipulation. Empirical results across comprehensive benchmarks and real-world experiments demonstrate best-in-class success rates, robustness, and generalization. The approach advances the state-of-the-art in scalable, geometry-aware embodied AI, with substantial implications for future development of efficient, hardware-agnostic robotic manipulation models.

