STARRY: Spatial-Temporal Action-Centric World Modeling for Robotic Manipulation
Abstract: Robotic manipulation critically requires reasoning about future spatial-temporal interactions, yet existing VLA policies and world-model-enhanced policies do not fully model action-relevant spatial-temporal interaction structure. We propose STARRY, a world-model-enhanced action-generation policy that aligns spatial-temporal prediction with action generation. STARRY jointly denoises future spatial-temporal latents and action sequences, and introduces Geometry-Aware Selective Attention Modulation to convert predicted depth and end-effector geometry into token-aligned weights for selective action-attention modulation. On RoboTwin 2.0, STARRY achieves 93.82% / 93.30% average success under Clean and Randomized settings. Real-world experiments further improve average success from 42.5% to 70.8% over $π_{0.5}$, demonstrating the effectiveness of action-centric spatial-temporal world modeling for spatial-temporally demanding robotic action generation.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explain-It-Like-I’m-14: STARRY — Teaching Robots to Think Ahead and Use 3D Geometry
1) What is this paper about?
This paper introduces STARRY, a new way to control robots so they can handle objects better. Instead of just reacting to what the camera sees right now, STARRY tries to “think ahead” by imagining how the scene will change over the next moments and where the robot’s hands should go. It also uses 3D information (like depth and shapes) to focus on the spots that really matter for success, such as handles, openings, and contact points.
2) What questions were the researchers trying to answer?
- Can we make robots better at tricky tasks (like hanging a mug on a hook or handing something to a person) by predicting the near future instead of only reacting to the present?
- Can we guide a robot’s attention to the most important places using 3D geometry, so it avoids clumsy moves and small but costly mistakes?
- If we do both—predict the future and use 3D cues—will robots perform more reliably in both simulations and the real world?
3) How did they do it?
The main idea: a “mental movie” for robots
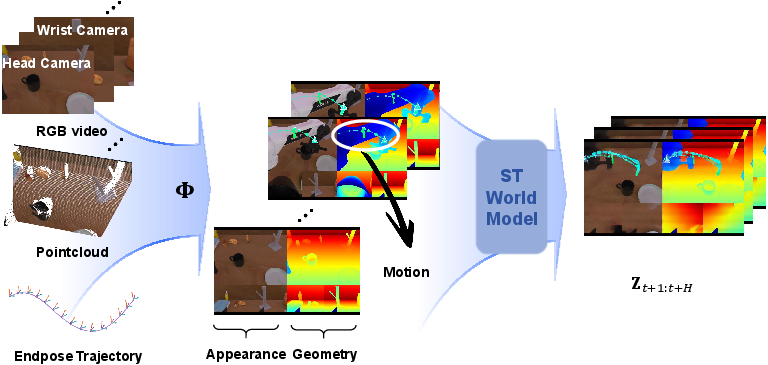
Imagine a robot has a mental movie of what will happen in the next few seconds: how objects will move, where the robot’s hands will be, and what nearby surfaces look like in 3D. STARRY builds this mental movie and then chooses actions that fit that future. Instead of only looking at a single image, it plans with a short “preview” of events.
To create this mental movie and the actions together, STARRY uses a technique called diffusion. You can think of diffusion as starting with a blurry, noisy picture of the future and gradually clearing it up step by step—like un-fogging a window—until both the future scene and the action sequence become clear and consistent with each other.
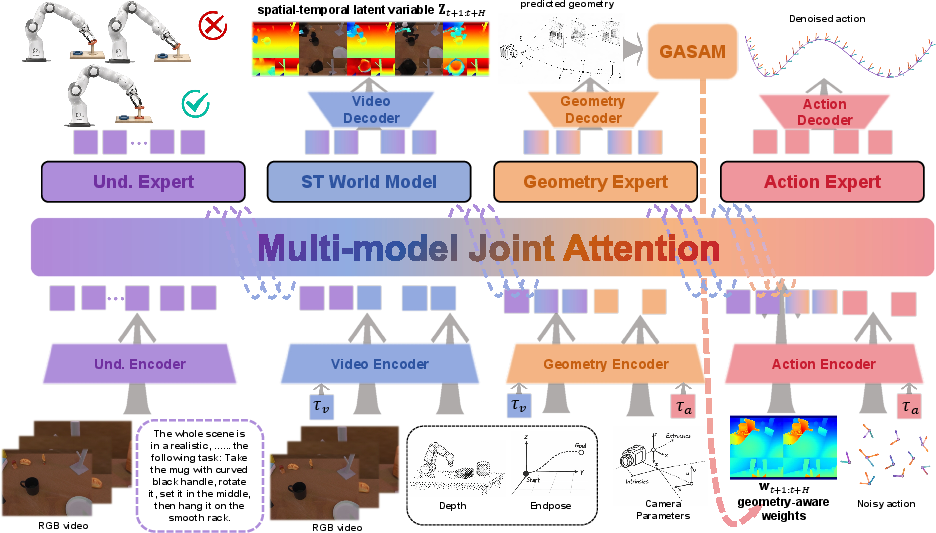
The STARRY “team” inside the robot
STARRY is organized like a team where each member has a job:
- Understanding Expert: Reads the instruction (language) and looks at the scene (images) to understand what the task is about.
- ST (Spatial-Temporal) World Model: Predicts a compact “mental movie” of the future that mixes appearance, motion, and basic 3D cues.
- Geometry Expert: Predicts depth (how far things are) and where the robot’s hand will be in 3D in the near future.
- Action Expert: Uses all of the above to choose the next actions (the robot’s moves).
These parts work together so the predicted future and the chosen actions match each other.
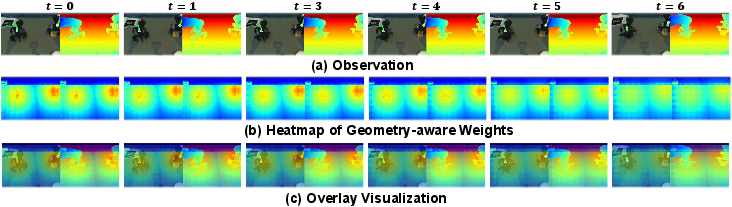
A geometry-aware spotlight (GASAM)
A key invention is GASAM, which acts like a smart spotlight. It uses the predicted 3D depth and the future position of the robot’s hand to highlight the most important areas in the camera view—the parts that are physically close or relevant to where the hand needs to go. This spotlight guides the robot’s attention when deciding actions, helping it focus on handles, openings, edges, and other crucial spots instead of being distracted by background details.
In everyday terms: if the robot is about to grab a mug, GASAM brightens the area around the mug’s handle and dims the rest, making it easier to make the right move.
Training and data (in simple terms)
They trained STARRY in stages, starting with lots of videos (to learn general visual and motion patterns), then adding data with 3D information (depth), and finally using real robot demonstrations. By gradually increasing the realism and detail of the training data, STARRY learns both “what’s happening” and “what to do.”
4) What did they find, and why is it important?
- In a large simulation benchmark (RoboTwin 2.0) with 50 tasks, STARRY achieved about 93.8% success in clean settings and 93.3% with random changes (like different object positions). That’s the best among the compared methods.
- STARRY was especially strong on tasks where small spatial mistakes usually cause failure, such as:
- Hanging a mug on a hook
- Handing over a microphone
- Pressing a stapler
- In real robot tests (not just simulations), STARRY lifted average success from 42.5% (a strong baseline called π0.5) to 70.8%. The improvement was even bigger for longer, multi-step tasks, showing that “thinking ahead” really helps.
Why it matters: Many robot failures happen because of tiny misalignments—being off by a few millimeters can cause a drop, a collision, or a missed placement. STARRY’s focus on 3D geometry and future prediction directly attacks this problem.
5) What’s the bigger impact?
If robots can anticipate what will happen next and pay attention to the right 3D details, they can:
- Work more safely and reliably with people (for example, handing things over without fumbling).
- Handle everyday multi-step tasks at home or in hospitals (like picking up items and placing them precisely).
- Be more robust in messy, changing environments (not just perfect lab setups).
In short, STARRY shows that giving robots both foresight (a short mental movie of the future) and 3D awareness (a geometry-based spotlight) can make them much better at the careful, precise actions real life demands.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research:
- Quantify robustness of GASAM to depth errors, occlusions, specular/transparent surfaces, and camera calibration drift; stress-test by injecting controlled depth and pose noise and report performance degradation.
- Assess sensitivity to sensor configurations: single-view vs multi-view, RGB-only vs RGB-D, varying camera baselines, and changing intrinsics/extrinsics; determine the minimal sensing needed for reliable performance.
- Model and propagate geometric uncertainty: predict depth and end-effector pose with uncertainty estimates and use uncertainty-aware attention modulation (e.g., variance-weighted or risk-sensitive GASAM).
- Clarify and evaluate the action horizon H: how to choose/adapt H per task; study adaptive or variable-horizon denoising and its effect on long-horizon, multi-step manipulation.
- Distinguish open-loop vs closed-loop control: characterize how often actions are replanned, latency per control cycle, and the impact of diffusion steps on responsiveness and stability.
- Report inference-time compute and latency on standard hardware; benchmark throughput vs success rate trade-offs (e.g., 5 vs 10 vs 20 denoising steps), and feasibility on edge/embedded platforms.
- Analyze sample efficiency: quantify success vs number of real-robot demonstrations and synthetic data; compare to baselines under matched data budgets.
- Provide controlled comparisons with baselines under matched pretraining and finetuning data, training steps, and compute to isolate architectural gains from data/compute differences.
- Expand real-world evaluation beyond three bimanual tasks: include single-arm tasks, diverse objects (transparent/reflective/deformable), varied backgrounds, different robots, and unseen environments.
- Study out-of-distribution generalization: novel objects, unseen task compositions, domain shifts (lighting, clutter, camera viewpoints), and human-induced disturbances (moving hands/objects).
- Characterize failure modes systematically (e.g., thin handles, small openings, deformable containment) and quantify how often failures stem from geometry prediction vs action generation vs language grounding.
- Evaluate compositional language generalization: unseen verb–noun pairs, long and ambiguous instructions, multi-instruction sequences; measure instruction sensitivity and failure recovery.
- Integrate force/tactile signals and impedance control for contact-rich tasks; assess whether GASAM can incorporate tactile-derived proximity or contact likelihood maps.
- Extend geometry targets beyond end-effector position to full 6D pose and gripper state; evaluate whether orientation-aware GASAM improves alignment and insertion tasks.
- Explore richer geometry priors in GASAM (surface normals, signed distance fields, affordance maps) and compare fixed vs learned distance-to-weight mappings ρ and the effect of λ (modulation strength).
- Make GASAM robust to erroneous geometry by gating or blending with appearance-only attention; develop confidence-aware modulation that falls back gracefully when geometry is unreliable.
- Investigate modulating other attention paths (e.g., video-to-action, text-to-video) and multi-branch modulation strategies; ablate where modulation helps or hurts.
- Use the world model for explicit planning: compare action generation via joint denoising against MPC/trajectory optimization with rollout in the learned latent space; quantify benefits/drawbacks.
- Provide interpretability of the spatial-temporal latent z: probe disentanglement of motion vs geometry vs appearance; visualize token saliency maps and their correlation with success.
- Evaluate memory and scaling: how do tokens, sequence length, and multi-view inputs affect memory footprint; explore token compression or kernelized attention to scale horizons and views.
- Clarify the role and efficacy of each training stage: isolate contributions of Stage 1/2/3; test curriculum variants and joint vs sequential optimization.
- Detail data composition per hierarchy level (L1–L6): dataset sizes, class/task coverage, camera setups, and mixing ratios; analyze data scaling laws and potential biases/negative transfer.
- Test sim-to-real transfer without target-robot finetuning (zero-shot and few-shot) to quantify domain gap and the utility of geometry-aware modeling for transfer.
- Evaluate multi-robot and cross-embodiment transfer: how well does the learned policy generalize across different kinematics, grippers, and camera rigs.
- Analyze action representation (14-D): specify components (pose, gripper, velocities) and test torque/impedance outputs; study constraints-aware decoding to respect joint limits and avoid collisions.
- Add metrics beyond success rate (e.g., time-to-success, contact stability, path smoothness, peak forces, regrasp counts) to better diagnose spatial-temporal control quality.
- Benchmark robustness under heavy clutter, distractors, and partial observability; test active viewpoint changes and camera failures.
- Examine the effect of number of cameras on performance and cost; determine whether learned single-view monocular depth estimation can replace multi-view depth hardware.
- Provide ablations on number of diffusion steps, noise schedules, and velocity-field vs score/flow objectives for actions; test alternative generative objectives (e.g., conditional flows, energy models).
- Evaluate long-horizon, multi-stage tasks requiring regrasping, tool-use, or complex sequencing; measure error accumulation and drift across subgoals.
- Investigate continual and online adaptation: can the Geometry Expert and GASAM update on-the-fly to new scenes/objects without catastrophic forgetting.
- Assess safety in close human–robot interaction (e.g., handovers): false-positive geometry near human hands, maximum contact forces, and failure recovery strategies.
- Quantify the impact of calibration errors and propose self-calibration or SLAM-based correction integrated into the policy loop.
- Release code, trained models, and standardized RoboTwin 2.0 configs/seeds to improve reproducibility; document exact data usage per level and licensing constraints.
- Compare STARRY against strong world-model baselines in real hardware (e.g., Motus, LingBot-VA) to validate sim gains in practice; analyze where sim-to-real performance diverges.
- Explore hybrid training signals: incorporate analytic geometry constraints (collision, reachability, gripper width) as auxiliary losses or constraints during denoising.
- Study the limits of GASAM under fast dynamics and moving targets; test predictive tracking and time-to-contact weighting rather than static distance weighting.
Practical Applications
Immediate Applications
Below are deployable use cases that leverage STARRY’s joint spatial–temporal action modeling and Geometry-Aware Selective Attention Modulation (GASAM), along with likely tools/workflows and key dependencies.
- Manufacturing and cobot assembly (Robotics, Industrial Automation)
- Use case: Improve success on contact- and alignment-sensitive steps (e.g., switch flipping, stapler press, hanging parts on hooks, precise can/bottle placement), and reliable bimanual coordination for sub-assembly.
- Tools/products/workflows: “STARRY Manipulation Add-on” for common arms (UR/Franka), ROS2 “ST-Diffusion Action Server,” geometry-attention “GASAM Layer” plugin for existing VLA policies, foresight visualizer for line operators.
- Dependencies/assumptions: Calibrated multi-view RGB-D sensing; accurate camera intrinsics/extrinsics; low-level compliant control; GPU for diffusion inference or distilled/lightweight models; on-site task demonstrations or synthetic data with geometry labels.
- Warehouse/retail pick-and-place and containerization (Logistics, Retail Robotics)
- Use case: Robust placement into bins, shelves, baskets; container opening; object reorientation; handling category variation (e.g., diverse bottles, cans).
- Tools/products/workflows: “BinPlace” and “Container-Place” skills built on STARRY; dataset pipeline following the paper’s hierarchical data pyramid (web+egocentric pretraining → geometry-rich sim → target-robot finetuning); QA dashboards comparing predicted futures to outcomes.
- Dependencies/assumptions: Consistent lighting and depth quality; sufficient demonstration coverage of SKU geometries; controlled clutter or domain randomization in training.
- Human–robot handover in controlled environments (Robotics, HRI in Industry)
- Use case: Reliable microphone/tool/sample handover in labs/production lines with predictable poses and constrained zones, leveraging STARRY’s improved bimanual coordination and spatial-temporal foresight.
- Tools/products/workflows: “Handover Orchestrator” (timing and grasp-release sequencing) with foresight-based safety gating.
- Dependencies/assumptions: Human pose/hand detectors; safety-rated stop for proximity; consistent depth sensing; scripted or learned human handover patterns.
- Laboratory automation and small-batch production (Robotics, Biotech/Pharma Labs)
- Use case: Handling diverse containers, caps, boxes; precise placement into trays or holders; transferring items across stations with reduced failures due to misalignment.
- Tools/products/workflows: Skill library for “open/close container,” “place into rack,” “handover to station”; foresight-based failure prediction to trigger re-grasps.
- Dependencies/assumptions: Depth-calibrated cameras around workcells; modest customization per labware geometry; GPU inference budget.
- Field service and facility ops (Robotics, Property Management)
- Use case: Toggle switches, press buttons, open/close standard appliances/doors; place objects into receptacles; tidy-up sequences (as validated by “Tidy Up Room” and “Wash Baby Bottle” tasks).
- Tools/products/workflows: “Control Panel Skill Pack” (button/switch); multi-step task chains using STARRY’s joint denoising for temporal coherence.
- Dependencies/assumptions: Known panel/layout geometry during deployment; multi-view coverage to reduce occlusion; acceptance of partial autonomy with human oversight for edge cases.
- Service robots for structured home tasks (Robotics, Consumer)
- Use case: Dish/bottle washing subtasks, tidying, basket placement, simple handovers in semi-structured settings; higher reliability than reactive VLAs (paper shows ~70.8% vs 42.5%).
- Tools/products/workflows: Consumer-friendly “Foresight Debugger” to visualize predicted futures for setup and troubleshooting; guided demonstration collection in-home.
- Dependencies/assumptions: Adequate RGB-D sensing in home lighting; simpler, constrained household scenarios; controlled initial deployments with monitoring.
- Policy and safety auditing in shared workspaces (Policy, Occupational Safety)
- Use case: Require predictive foresight logs for task executions—record ST future predictions and GASAM attention maps to audit near-miss events, verify compliance with safety margins.
- Tools/products/workflows: “Foresight Inspector” logging module integrated with robot safety PLCs; policy templates for data retention and incident review.
- Dependencies/assumptions: Organizational adoption of foresight-based logging; secure storage of video/geometry data; clear privacy boundaries.
- Academic research and education (Academia, Education)
- Use case: Evaluate and extend action-centric world models; study spatial-temporal foresight vs reactive policies; course labs on geometry-aware attention.
- Tools/products/workflows: Open-sourced ST denoising + GASAM reference; curated “data pyramid” scripts (web/egocentric → geometry-rich sim → real-robot); RoboTwin 2.0 task suites for reproducibility.
- Dependencies/assumptions: Compute (multi-GPU) for training; access to RGB-D cameras or simulators; permissive licenses for pretrained backbones.
- Software integration for VLA stacks (Software, Robotics Middleware)
- Use case: Embed GASAM as a drop-in layer in existing VLA/RT-2/π-series pipelines to bias attention by geometry without changing video modeling; deploy STARRY as a ROS2 action server.
- Tools/products/workflows: “GASAM-for-Transformers” layer; minimal API to feed predicted depth and end-effector pose; model cards clarifying latency/throughput.
- Dependencies/assumptions: Compatible tokenization and attention interfaces; well-calibrated depth streams; budgeting for added compute.
- Process optimization and operations analytics (Operations, Industrial Engineering)
- Use case: Use predicted futures to flag likely failures (misalignment, collisions) before they happen; reduce scrap, rework, and cycle times in delicate tasks.
- Tools/products/workflows: Real-time “failure likelihood” score from ST latents/geometry; A/B testing between reactive vs foresight-enabled runs.
- Dependencies/assumptions: Telemetry plumbing; thresholding calibrated on historical tasks; acceptance of conservative slows/stops when risk spikes.
Long-Term Applications
These opportunities require further research, scaling, or engineering (e.g., broader sensing, stronger generalization, regulatory approval, or on-device efficiency).
- General-purpose home assistants with robust multi-step execution (Robotics, Consumer)
- Potential: End-to-end household routines (laundry sorting, pantry organization, dish cycles) with reliable spatial-temporal coordination and placement across rooms.
- Dependencies/assumptions: Stronger sim-to-real transfer in cluttered, dynamic homes; robust 3D perception under variable lighting; richer long-horizon planning integration; cost-effective RGB-D arrays.
- Assistive healthcare and eldercare robotics (Healthcare, Assistive Tech)
- Potential: Dressing assistance, safe feeding, item delivery and handover near patients or residents, with geometry-aware alignment and temporal coordination.
- Dependencies/assumptions: Regulatory approvals; comprehensive safety cases; tactile/force sensing integration for contact safety; clinician-in-the-loop workflows; datasets covering human-centric interactions.
- Contact-rich industrial tasks (Robotics, Advanced Manufacturing)
- Potential: Screwdriving, cable routing, snap fits, connector insertions—combining ST foresight with tactile feedback to achieve precise, compliant manipulation.
- Dependencies/assumptions: High-frequency force/torque/tactile sensors; extending GASAM to multi-modal cues; high-resolution geometry prediction; specialized training data.
- Multi-robot and human–robot collaborative orchestration (Robotics, HRI)
- Potential: Coordinated bimanual/multi-robot assembly lines, shared payload manipulation, staged handovers with predictive synchronization across agents.
- Dependencies/assumptions: Communication latency bounds; shared world models; cross-embodiment calibration; safety certification for close-proximity collaboration.
- Surgical and interventional robotics support tasks (Healthcare)
- Potential: Setup/teardown, instrument handling/placement, sterile pack organization with precise spatial awareness.
- Dependencies/assumptions: Extremely high reliability and traceability; regulatory certification; domain-specific datasets; sterile and safe hardware design.
- Foundation world models for robotics with geometry grounding (AI Platforms, Robotics)
- Potential: Pretrain large spatial-temporal models on web-scale video + egocentric data, then geometry-augment and fine-tune for manipulation—broad generalist capabilities.
- Dependencies/assumptions: Massive curated data pipelines; scalable training (multi-node clusters); robust geometry supervision at scale (synthetic+real); data governance.
- Edge and embedded deployment of diffusion-based control (Semiconductors, Edge AI)
- Potential: Distilled or compressed STARRY variants running on robot controllers or edge TPUs for low-latency autonomy.
- Dependencies/assumptions: Model distillation/quantization without losing safety-critical foresight; hardware acceleration for attention and diffusion; energy/thermal constraints.
- Standards and certification around predictive control (Policy, Standards Bodies)
- Potential: New safety standards that require predictive spatial-temporal reasoning and geometry-aware attention in shared workspaces; certification tests reflecting contact-sensitive tasks.
- Dependencies/assumptions: Consensus across manufacturers/regulators; reference test suites (e.g., public RoboTwin-like tasks); accepted foresight logging formats.
- Cross-embodiment transfer and low-shot adaptation (Robotics, Software)
- Potential: Train once, adapt quickly across arms/grippers/cameras through modular geometry experts and minimal finetuning on L6 target-robot data.
- Dependencies/assumptions: Robust embodiment-agnostic representations; calibration routines; small, high-quality adaptation datasets.
- Rich multi-modal GASAM (Robotics, Sensing)
- Potential: Extend geometry-aware attention to incorporate tactile, force, audio (e.g., click of snapped fit) for better decision-critical token weighting.
- Dependencies/assumptions: Synchronized multi-modal streams; effective fusion architectures; datasets with aligned multi-modal ground truth.
- Predictive safety monitors and “look-ahead” supervisors (Safety Engineering)
- Potential: Independent supervisory modules that simulate near-future geometry and halt or re-route actions before collisions or unstable placements.
- Dependencies/assumptions: Highly calibrated foresight accuracy; formal verification hooks; integration with robot safety controllers; acceptable false-positive rates.
Notes on Feasibility (Common Assumptions/Dependencies)
- Sensing and calibration: Multi-view RGB-D with accurate intrinsics/extrinsics is central to GASAM and geometry-grounded attention; occlusions and poor depth quality can degrade performance.
- Compute and latency: Diffusion-based joint denoising adds inference cost; practical deployments may need model distillation, batching, or hardware acceleration.
- Data pipeline: The hierarchical data pyramid (web/egocentric → geometry-rich sim → interaction → target-robot) underpins generalization; skipping geometry-rich stages can reduce robustness.
- Control stack: Success depends on stable low-level controllers (impedance/compliance), accurate kinematics, and reliable grasping hardware.
- Safety and governance: Predictive logs may contain sensitive video/geometry; organizations need privacy policies and retention rules; safety certification may require additional validation steps.
Glossary
- Action attention branch: The part of the model’s attention mechanism that processes action queries and attends to visual tokens. "geometry-aware weights are selectively applied only to the action attention branch."
- Action Expert: A module specialized for generating/denoising action sequences in the policy. "The Action Expert follows the same Transformer architecture as the ST World Model but uses action-specific parameters"
- Action-to-video attention: Cross-attention from action queries to video tokens used to condition actions on visual context. "The geometry-modulated action-to-video attention is:"
- Bimanual manipulation: Robotic tasks that require coordinated use of two arms or grippers. "which comprises 50 bimanual manipulation tasks"
- Camera extrinsics: Parameters describing a camera’s pose in the world (rotation and translation). "using camera intrinsics and extrinsics "
- Camera intrinsics: Parameters describing a camera’s internal geometry (e.g., focal length, principal point). "using camera intrinsics and extrinsics "
- Contact-rich: Describing tasks that involve sustained or precise physical contact between robot and objects. "especially in contact-rich or spatially constrained tasks"
- Depth unprojection: Converting depth pixels into 3D points in metric space using camera parameters. "such as depth unprojection or end-effector--scene distance computation."
- Diffusion-aligned Transformer: A Transformer architecture adapted to work with diffusion-model signals and timesteps. "the Geometry Expert is implemented as a diffusion-aligned Transformer"
- Diffusion-based model: A generative model that iteratively denoises samples from noise to data. "Here, $f_{\theta}^{\text{ST}$ is implemented as a diffusion-based model."
- Diffusion timesteps: The discrete noise levels indexing stages of the diffusion denoising process. "diffusion timesteps "
- Egocentric video: First-person viewpoint video, often from wearable or robot-mounted cameras. "Egocentric video"
- Embodied agents: Agents with a physical or simulated body that perceive and act in the world. "general-purpose embodied agents"
- End-effector: The robot’s tool tip (e.g., gripper) that physically interacts with objects. "end-effector trajectories"
- End-effector--scene distance: The 3D metric distance between the robot’s end-effector and points in the scene. "such as depth unprojection or end-effector--scene distance computation."
- Foresight-based action prediction: Generating actions guided by predicted future states rather than only current observations. "foresight-based action prediction (e.g., F1)"
- Generative policy: A policy that produces action sequences via a generative modeling process. "within a unified generative policy"
- Geometry-Aware Selective Attention Modulation (GASAM): A mechanism that uses predicted geometry to bias attention toward action-relevant regions. "we introduce Geometry-Aware Selective Attention Modulation (GASAM)"
- Geometry-aware weights: Attention-biasing weights computed from geometric distances or structure. "The Geometry Expert is supervised on depth, end-effector position, and geometry-aware weights:"
- Geometry Expert: A model component that predicts future depth and end-effector positions for geometric guidance. "we introduce a Geometry Expert."
- Inverse dynamics problem: Inferring the actions that would cause desired transitions between states. "formulates action generation as a prediction-guided inverse dynamics problem"
- Latent predictive learning (JEPA): Learning temporally consistent latent representations for prediction, exemplified by JEPA. "latent predictive learning (e.g., JEPA)"
- Latent video states: Compressed latent representations of future video frames used for prediction and control. "predict future observations or latent video states"
- Monotonically decreasing distance-to-weight mapping: A function that converts larger distances into smaller attention weights. "a monotonically decreasing distance-to-weight mapping"
- Multimodal joint attention: Attention operating across different modalities (e.g., vision, language, action) together. "through multimodal joint attention."
- RGB-D: Combined RGB color images and depth maps used together as input. "multi-view RGB-D observations"
- Spatial-temporal composition function: A function that fuses multi-view appearance, depth, and motion over space and time. "denotes the spatial-temporal composition function"
- Spatial-temporal latent variable: A latent representation capturing predicted future structure across space and time. "a future spatial-temporal latent variable "
- ST World Model: The Spatial-Temporal world model module that predicts future spatial-temporal latents. "The ST World Model predicts future spatial-temporal latent variables"
- Structured domain randomization: Systematically varying environmental factors in simulation to improve robustness. "with structured domain randomization"
- Token-aligned weights: Attention weights aligned to the grid of visual tokens for selective modulation. "token-aligned weights for selective action-attention modulation."
- Understanding Expert: The module that provides semantic grounding from visual-language inputs. "Understanding Expert, ST World Model, Geometry Expert, and Action Expert."
- Velocity fields (in diffusion): Vector fields predicted to parameterize the diffusion denoising process. "via diffusion by predicting velocity fields"
- Video tokens: Tokenized representations of video frames used as inputs to transformers. "We encode into video tokens"
- Video-token grid: The spatial layout of video tokens corresponding to regions in the input frames. "aligned to the video-token grid"
- Vision-Language-Action (VLA) models: Models that jointly handle visual inputs, language, and action outputs for embodied tasks. "Vision-Language-Action (VLA) models have emerged as a prominent paradigm"
- World model: A learned model of environment dynamics used to predict future states or observations. "Recent work incorporates world models into policy learning"
- World-model-enhanced action-generation policy: An action policy augmented with future predictions from a world model. "a world-model-enhanced action-generation policy that aligns spatial-temporal prediction with action generation."
Collections
Sign up for free to add this paper to one or more collections.