- The paper introduces a dual-prediction framework that jointly forecasts future video latents and action sequences to enhance both in-domain and cross-domain robotic manipulation.
- It employs a multimodal diffusion transformer architecture that integrates textual instructions, visual observations, and motor actions into a unified embedding space.
- Experimental results show up to a 15-point improvement on novel object tasks and a 28-point gain in cross-embodiment skill transfer over baseline methods.
Motivation and Conceptual Framework
The paper "VideoVLA: Video Generators Can Be Generalizable Robot Manipulators" (2512.06963) introduces a paradigm shift in robotic manipulation. Instead of leveraging pre-trained vision-language understanding models, as is typical in Vision-Language-Action (VLA) systems, this work harnesses large pre-trained video generation models as the core for generalizable robot control. The central hypothesis is that high-fidelity, physically plausible generative models conditioned on multimodal inputs (observations and instructions) capture the implicit knowledge necessary for cross-domain manipulation—including generalization to novel objects and unseen skills.
VideoVLA is instantiated by converting a large video generation model (CogVideoX-5B) into a unified multimodal diffusion transformer that forecasts both future visual imagination (i.e., video latents) and action sequences. The dual-prediction strategy enables the model to simultaneously anticipate the consequences of actions and the necessary commands to achieve task goals, with a strong empirical correlation between imagination quality and actual execution reliability.
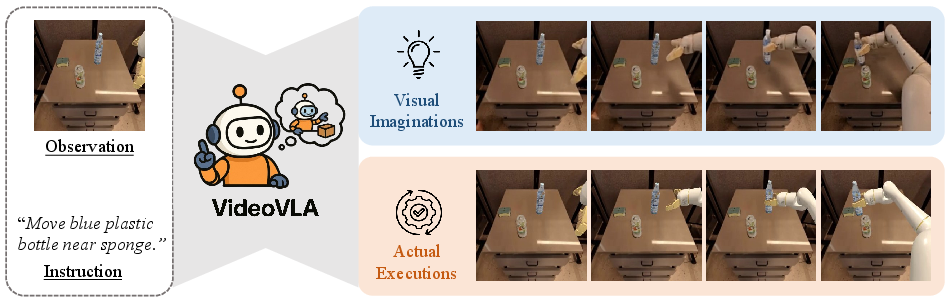
Figure 1: VideoVLA predicts both future actions and corresponding visual outcomes from the current observation and instruction, enabling reasoning about physical interactions and robust generalization.
Model Architecture and Training
VideoVLA adopts a multi-stage processing pipeline. Given a textual instruction and a current visual observation, a T5-based encoder produces language tokens, while the visual input is mapped to a latent representation by a causal VAE encoder from CogVideoX. The first visual latent represents the initial observation, while subsequent latents correspond to imagined future frames. Actions are directly encoded as 7-D vectors (translation, rotation, gripper state). All modalities are projected into a shared embedding space.
Prediction occurs via a DiT (Diffusion Transformer) architecture: conditioned on language tokens and the initial observation latent, VideoVLA jointly denoises the future frame latents and the action sequence targets, using DDPM loss. This concatenation bolsters cross-modal reasoning and aligns predicted actions with generated visual outcomes.
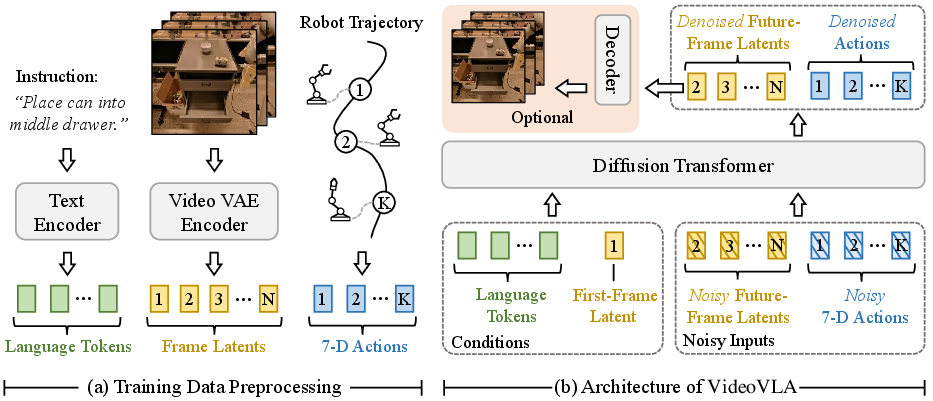
Figure 2: Overview of VideoVLA: a diffusion transformer jointly predicts actions and future visual latents conditioned on the current state and language.
Key empirical design choices highlighted in ablation studies include:
- Using large-scale pre-trained video generators (CogVideoX-5B) dramatically enhances in-domain and generalized task success.
- Increasing the prediction time horizon (number of future frames) directly correlates with better manipulation performance.
- The dual-prediction (video and action) loss is necessary; removing visual loss or predicting actions only collapses generalization and in-domain performance.
Experimental Results
In-Domain Manipulation
Evaluations in the SIMPLER simulation environment (Google/WidowX robots) and with a Realman robot in the real world demonstrate VideoVLA’s superior performance compared to recent VLA baselines (CogACT, π0, OpenVLA, SpatialVLA). Across 12 simulation tasks, VideoVLA attains the highest overall average success rates, outperforming state-of-the-art approaches that rely on understanding models.
Generalization to Novel Objects
VideoVLA achieves the highest average success rates on manipulation of novel objects not seen during training, exceeding previous SOTA by up to 15 percentage points in simulation and by an even larger margin in real-world deployments. Importantly, success rates (e.g., 96% on green cube, 88% on eggplant) reflect robust transfer capabilities from web-scale video knowledge to robotic action.
Embodiment and Skill Transfer
The framework enables cross-embodiment skill transfer: skills learned by one robot (WidowX) but not encountered by another (Google or Realman) can be reliably executed. On a set of eight novel skills for the Google robot, VideoVLA exceeds CogACT by 28 points (average 48.6% vs 20.4%). In real-world cross-embodiment evaluation, VideoVLA reached 58% average success on challenging skills such as "topple", "wipe", and "take out," where competitive baselines perform poorly.
Imagination-Execution Alignment and Analysis
The paper provides quantitative and qualitative analyses of the alignment between imagined futures and physical execution. Visual imagination success is strongly predictive of actual execution reliability, with high robot motion similarity correlating with task success.
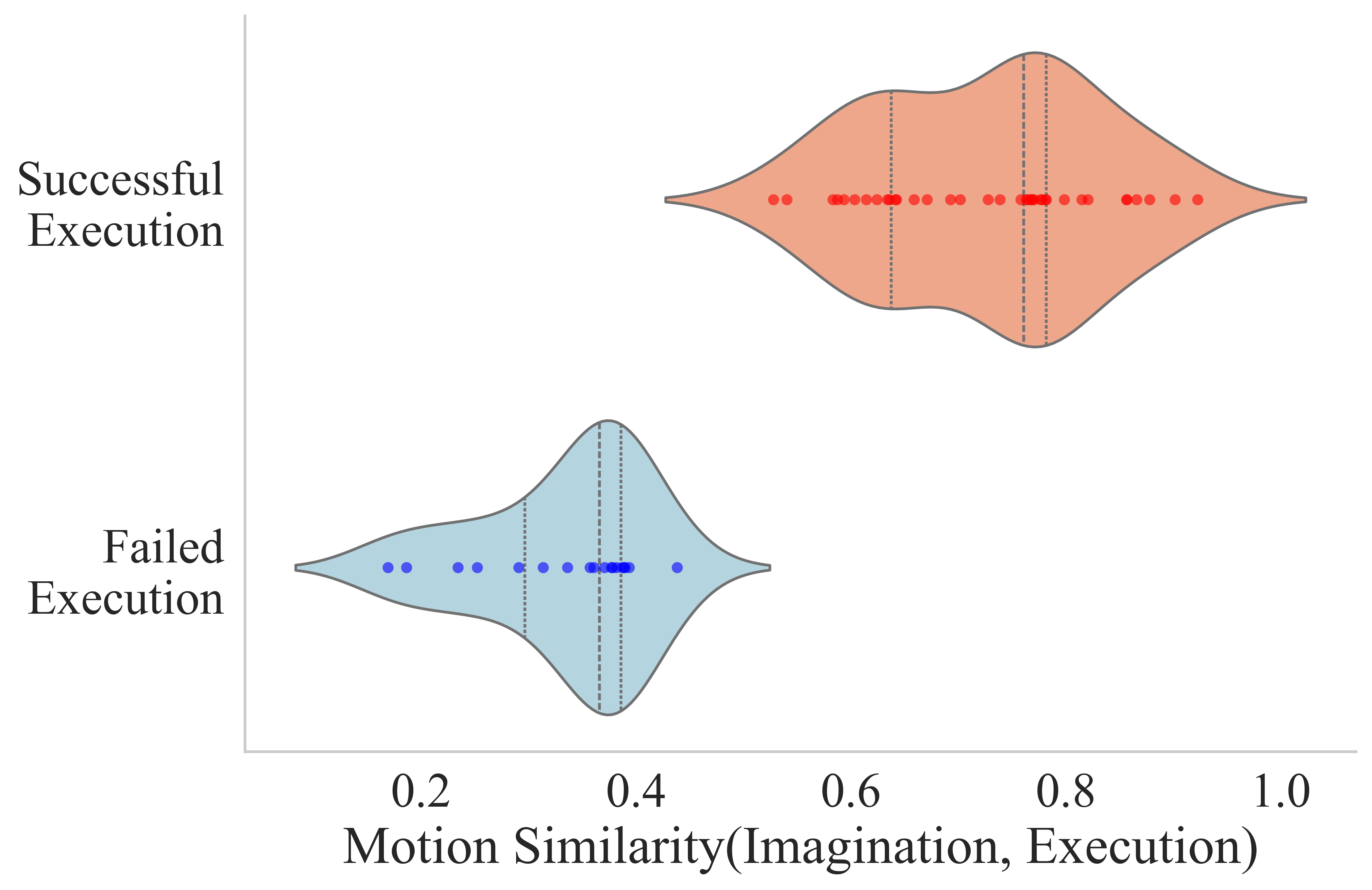
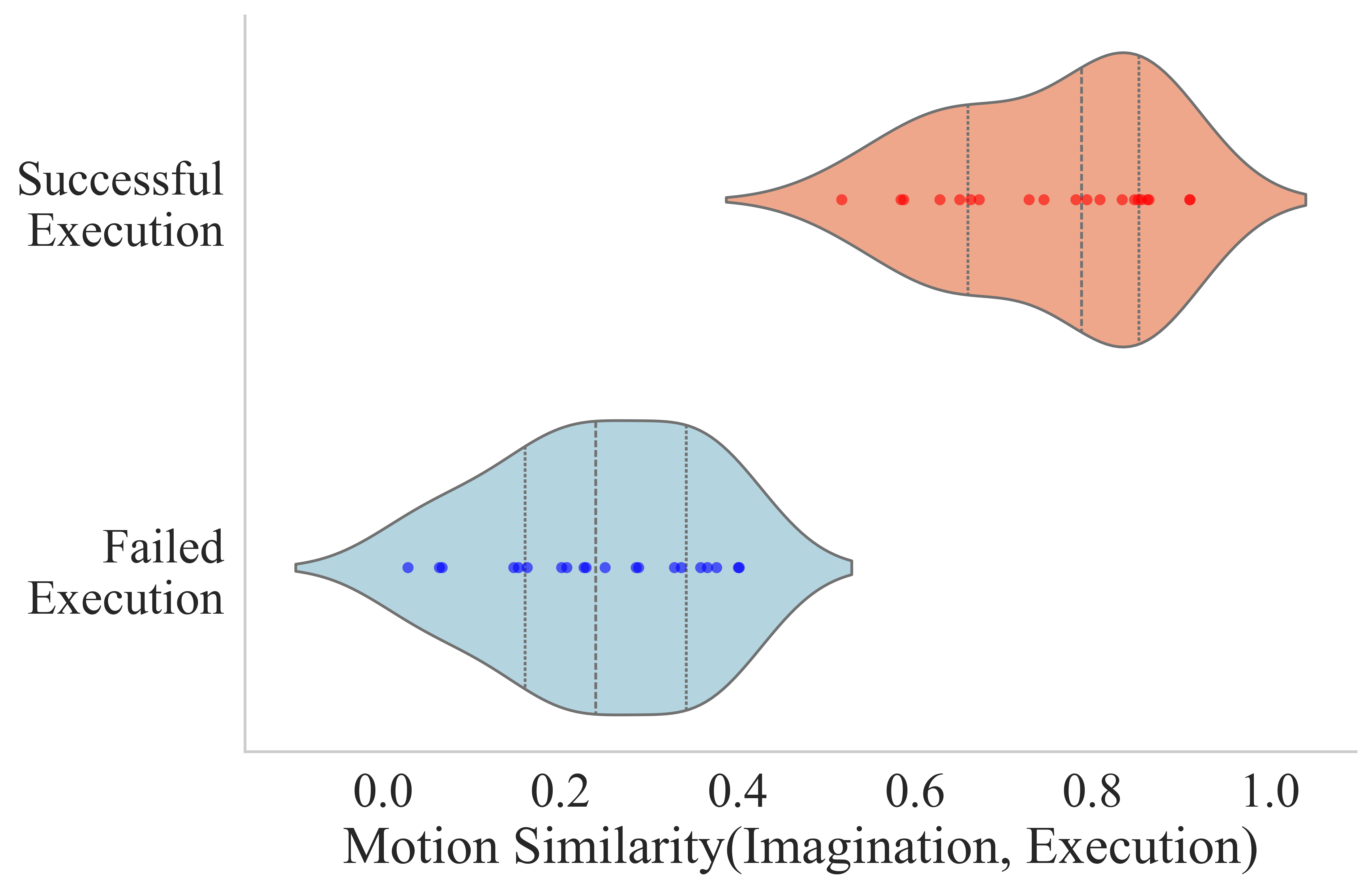
Figure 3: Robot motion similarity between predicted imaginations and actual executions is tightly coupled to task completion rate, as shown for both Google and WidowX robots.

Figure 4: Qualitative alignment between VideoVLA’s imagined visual futures and real-world executions in manipulation tasks.
Further experiments demonstrate that visual imagination is generally more reliable, with success rates (84% for novel objects) exceeding those of physical execution (65%); this gap is attributed to real-world actuation and perception failures.
Comparative and Ablative Insights
The paper exposes the limitations of alternatives:
- Training from scratch or using lower-fidelity generators yields dramatically reduced task performance.
- The dual-prediction approach is necessary—action or video-only modeling collapses both in-domain and generalization capabilities.
- Joint bidirectional attention across modalities (not causal masking) is essential for cross-modal semantic and physical alignment.
- Synchronous diffusion schedules outperform asynchronous variants, reflecting the temporally aligned nature of vision and action modalities.
- Longer time horizon prediction (more future frames) enables better anticipation and planning, with monotonic improvements in performance.
Theoretical and Practical Implications
VideoVLA substantiates the proposition that generative models trained on large-scale video data encode rich knowledge of physical causality, object affordances, and semantic mapping between instructions, perceptions, and actions. By transforming such generators into unified robot policies, the work breaks a bottleneck in generalization, which remains a challenge for understanding-based approaches.
The practical upshot is the feasibility of scalable, broadly capable robot models deployable in open-world environments. The dual-prediction design establishes a mechanism for implicit uncertainty estimation (execution reliability can be inferred from the quality of imagined futures), potentially informing downstream policy selection, multi-agent planning, or self-improvement via simulated imagination.
Persistent limitations relate to inference speed, stemming from large-scale backbone requirements. Suggestions for mitigating these issues include smaller robot-oriented generator pretraining, shortcut/one-step denoising, and model distillation techniques.

Figure 5: VideoVLA predictions and real-world task executions illustrate robust alignment and performance in manipulation tasks with unknown objects.

Figure 6: Visualization of successful imaginations and executions in simulation, highlighting generalization and robustness.
Conclusion
VideoVLA demonstrates that large-scale video generators can be adapted into general-purpose robot manipulators that jointly predict actions and anticipated visual outcomes, enabling robust generalization to novel tasks, objects, and skills in both simulated and real environments. Empirical analyses confirm that the quality of visual imagination is a reliable proxy for action plan reliability, with strong statistical and qualitative links to successful task execution. The approach signals a practical pathway toward scalable, generalist robot control systems grounded in generative modeling rather than perceptual understanding, offering foundational advances for AI-driven manipulation and closing the gap to broader embodied intelligence.

