ActiveVLA: Injecting Active Perception into Vision-Language-Action Models for Precise 3D Robotic Manipulation
Abstract: Recent advances in robot manipulation have leveraged pre-trained vision-LLMs (VLMs) and explored integrating 3D spatial signals into these models for effective action prediction, giving rise to the promising vision-language-action (VLA) paradigm. However, most existing approaches overlook the importance of active perception: they typically rely on static, wrist-mounted cameras that provide an end-effector-centric viewpoint. As a result, these models are unable to adaptively select optimal viewpoints or resolutions during task execution, which significantly limits their performance in long-horizon tasks and fine-grained manipulation scenarios. To address these limitations, we propose ActiveVLA, a novel vision-language-action framework that empowers robots with active perception capabilities for high-precision, fine-grained manipulation. ActiveVLA adopts a coarse-to-fine paradigm, dividing the process into two stages: (1) Critical region localization. ActiveVLA projects 3D inputs onto multi-view 2D projections, identifies critical 3D regions, and supports dynamic spatial awareness. (2) Active perception optimization. Drawing on the localized critical regions, ActiveVLA uses an active view selection strategy to choose optimal viewpoints. These viewpoints aim to maximize amodal relevance and diversity while minimizing occlusions. Additionally, ActiveVLA applies a 3D zoom-in to improve resolution in key areas. Together, these steps enable finer-grained active perception for precise manipulation. Extensive experiments demonstrate that ActiveVLA achieves precise 3D manipulation and outperforms state-of-the-art baselines on three simulation benchmarks. Moreover, ActiveVLA transfers seamlessly to real-world scenarios, enabling robots to learn high-precision tasks in complex environments.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
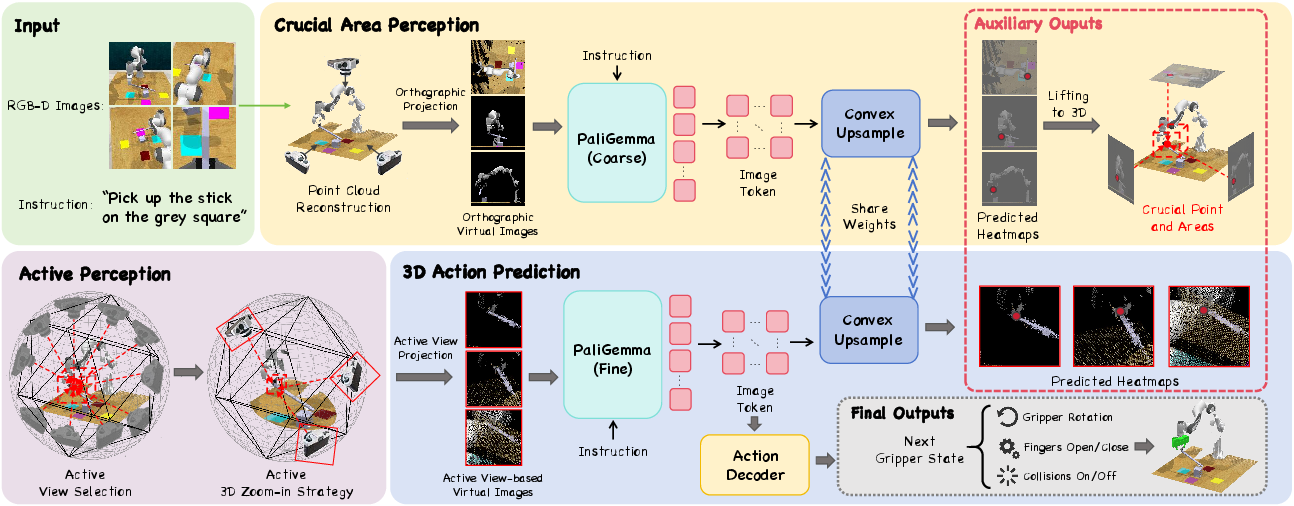
This paper introduces ActiveVLA, a new kind of robot “brain” that can see, understand language, and plan actions in 3D. Its big idea is to make robot perception active instead of passive. Instead of staring from a fixed camera like a security cam, the robot actively chooses better angles and zooms in when needed—just like you move your head or step closer to see small details. This helps the robot do precise tasks, such as inserting a peg into a hole or opening a drawer, even when objects are partly hidden.
What questions did the researchers ask?
The paper focuses on three simple questions:
- How can a robot pick the best camera viewpoints during a task so it can see important things clearly and avoid being blocked?
- How can it zoom in on tiny or detailed areas to work more precisely?
- Will these “active perception” skills actually help the robot perform better on many kinds of tasks, in both simulations and the real world?
How does ActiveVLA work? (Methods in simple terms)
Think of the robot as a careful student doing a tricky craft project. It first scans the scene to find the important area, then moves to get a better look, and finally zooms in to handle the tiny details. ActiveVLA does this with a “coarse-to-fine” plan:
- Step 1: Find the important region (coarse stage)
- The robot builds a 3D picture of the scene (a point cloud—imagine lots of tiny dots forming the shapes of objects).
- It creates three simple “blueprint” views: top, front, and side. These are like flat drawings of the 3D scene.
- Using a big AI that understands images and text (a vision-LLM), it makes heatmaps—maps that glow brightest where important stuff probably is. Picture a weather map where red spots mean “pay attention here.”
- It combines the three heatmaps back into 3D to locate the critical area to focus on.
- Step 2: Actively look better and closer (fine stage)
- Active viewpoint selection: The robot imagines placing a camera at many positions around the important area (like standing around a statue). It chooses views that:
- See the target clearly without being blocked (avoid occlusions),
- Aren’t too close or too far,
- Come from different angles (to reduce blind spots).
- Active 3D zoom-in: From the best view, it “zooms in” by narrowing the camera’s field of view. This is like using a zoom lens so small parts look bigger and sharper, without losing image quality.
- Step 3: Decide the exact action
- Using the refined views, the model produces new heatmaps that mark the best place for the robot’s hand to go.
- It then calculates the 3D position, how to rotate the hand, whether to open/close the gripper, and whether a move might cause a collision.
- It blends “global” information (overall scene) with “local” detail (the zoomed-in area) to make safe and accurate moves.
In short: First find where to look, then look from better spots, then zoom in, then act precisely.
What did they find, and why does it matter?
The researchers tested ActiveVLA on three challenging robot benchmarks and on a real robot:
- RLBench (18 tasks): About 91.8% average success. Some tasks reached 100% success. This shows strong precision in many activities like inserting objects or opening things.
- COLOSSEUM (tests generalization, like changes in color, size, lighting, and camera pose): About 65.9% average success, the best among compared methods. It stayed reliable even when the scene changed.
- GemBench (tests how well skills combine for more complex tasks): Best overall average (51.3%), especially strong on the first three difficulty levels.
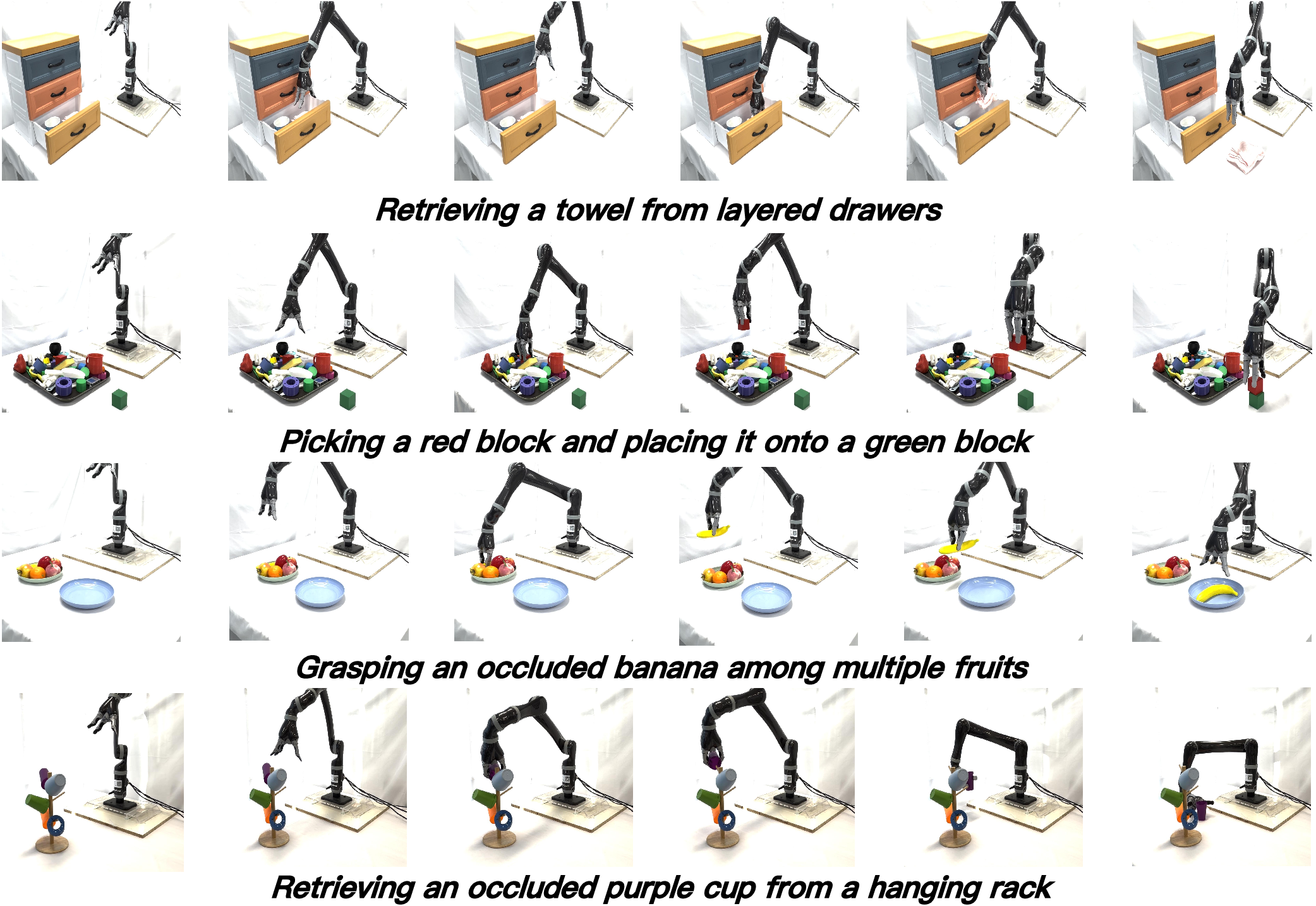
- Real-world experiments: The robot handled cluttered, occluded scenes by choosing better viewpoints and zooming in to see small or hidden details.
Why this matters:
- Active looking and zooming reduce “guessing” and make robots more precise.
- It helps robots deal with occlusions—when important parts are blocked—from different, smarter views.
- It improves performance not just in simulation but also in real, messy environments.
What’s the bigger impact?
ActiveVLA shows that robots shouldn’t just passively watch; they should actively explore—moving their “eyes” and zooming to gather the best information for the job. This could lead to:
- More reliable household robots that can find and grasp objects in clutter,
- Better factory robots for fine assembly tasks,
- Safer robots that avoid collisions by seeing clearly,
- Systems that adapt to new places, new objects, and new lighting without retraining from scratch.
Bottom line: Teaching robots to choose where to look and how closely to look makes them much better at careful, real-world tasks. ActiveVLA is a step toward more capable, adaptable robot assistants.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to be actionable for future research.
- Physical camera actuation and feasibility: The paper does not specify whether Active Viewpoint Selection is realized via physical camera/arm motion or purely virtual rendering; the practical constraints (IK feasibility, collision avoidance, motion planning, travel time, and energy cost) for executing selected viewpoints on real robots remain unaddressed.
- Real-world quantitative evidence: Real-robot results are qualitative only; there is no quantitative comparison to baselines, no statistical success rates, nor ablations of A-VS/A-3Z on hardware, leaving the real-world impact of active perception insufficiently validated.
- Robustness to sensor noise and calibration errors: ActiveVLA assumes accurate RGB-D point clouds and calibrated cameras; the method’s sensitivity to depth noise, missing points, miscalibration, and lens distortions (e.g., with RealSense D455) is not analyzed or mitigated.
- Dynamic scenes and moving objects: All evaluations appear in quasi-static settings; how the active perception pipeline adapts to moving targets, changing occlusions, or human/robot-induced scene dynamics is unexplored.
- Viewpoint feasibility under robot kinematics: The view scoring ignores robot kinematics and workspace constraints; integrating viewpoint selection with IK feasibility, arm-base reachability, and camera mount limitations is an open problem.
- Occlusion modeling limits: The visibility check uses ray sampling on observed point clouds, which can fail under sparsity, noise, transparent/reflective surfaces, or self-occlusions by the robot; more principled or learned occlusion reasoning is needed and untested.
- Learned vs. heuristic view selection: The multi-objective view scoring (visibility, distance, diversity) uses hand-tuned weights; learning task-conditioned, language-conditioned, or uncertainty-aware scoring policies (e.g., via RL or meta-learning) is not explored.
- Scheduling and triggering of active perception: The paper does not define when to re-select views or zoom-in (e.g., confidence thresholds, time budgets, task phases), nor stopping criteria, leaving closed-loop scheduling design open.
- Latency and compute on robot hardware: Inference times are reported on H100 GPUs; end-to-end latency on typical robot PCs (CPU/GPU), including camera motion time and re-rendering, and the impact on control frequency remain unquantified.
- Active 3D zoom-in realism: Virtual zoom-in improves rendered resolution but cannot acquire new sensor detail; the benefit in real sensing (vs. cropping/resampling) under low-resolution and noisy depth is not measured or characterized.
- Orthographic projection assumptions: The pipeline relies on top/front/right orthographic renderings; with limited camera coverage (e.g., single eye-to-hand camera), the completeness and accuracy of these views and their effect on performance are not evaluated.
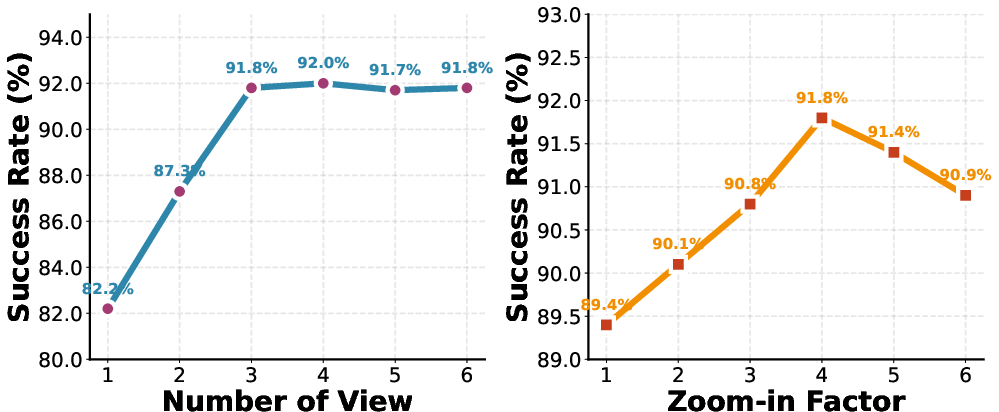
- Candidate viewpoint sampling scale: The icosahedral subdivision level k and the number of candidates are not analyzed for computational scalability, selection quality, or diminishing returns; efficient sampling strategies and pruning remain open.
- Heatmap supervision and uncertainty: The method lacks details on ground-truth heatmap generation and does not model uncertainty; exploring probabilistic heatmaps, confidence calibration, and uncertainty-aware action selection is an open direction.
- Rotation representation limitations: Using discretized Euler angles (72 bins) risks gimbal lock and coarse orientation; the impact on precision and comparisons with continuous quaternion or axis-angle regressors are missing.
- Task-time and efficiency trade-offs: The extra perception steps likely add time; measuring end-to-end task duration, success-time trade-offs, and the net productivity impact vs. fixed-view baselines is not reported.
- Language-conditioned perception: How instructions modulate region localization, viewpoint selection, and zoom-in is under-specified; robustness to ambiguous, noisy, or multi-step language and its influence on active perception is not studied.
- Generalization across embodiments and sensors: Results are limited to Franka Panda and Kinova GEN2 with RealSense; cross-embodiment transfer (mobile bases, bimanual arms), different depth sensors, and multi-camera arrays are not evaluated.
- Failure analysis on long-horizon L4: Performance drops sharply on GemBench L4; detailed failure modes (memory limits, subgoal decomposition, compounding errors) and remedies (hierarchical planning, external memory) are not analyzed.
- Data efficiency: The claim of improved sample efficiency is not substantiated with experiments varying demonstration counts; sensitivity to training data size and quality remains unknown.
- Multi-view fusion weights: It is unclear whether view weights w_v in score volume fusion are fixed or learned; adaptive or confidence-weighted fusion strategies are not investigated.
- Real-world “new views” acquisition mechanism: For the eye-to-hand setup, it is unclear how “new views” are physically obtained (arm motion, camera pan-tilt, base motion), and how this interacts with ongoing manipulation.
- Lighting, motion blur, and challenging materials: Robustness to adverse visual conditions (low light, motion blur) and materials that corrupt depth (transparent, specular, black objects) is untested.
- Integration with manipulation planning: Viewpoint selection is decoupled from the manipulation plan; jointly optimizing perception viewpoints with planned end-effector trajectories to avoid interference and reduce regrasp/repositioning is an open challenge.
Practical Applications
Immediate Applications
Below are applications that can be deployed now, leveraging the paper’s demonstrated real-robot results, existing toolchains (PyTorch3D, ROS, RealSense), and the compatibility of ActiveVLA with current VLM backbones.
- Active pick-and-place in cluttered bins and shelves (Sector: Robotics, Warehouse/Logistics)
- What: Use ActiveVLA’s active viewpoint selection and 3D zoom-in to reduce occlusions and improve grasp success on partially hidden objects.
- Tools/Products/Workflows: ROS-integrated “Active Perception Controller” module that plugs into existing bin-picking pipelines; candidate view proposal + quick re-grasp loop; deployment with eye-to-hand RGB-D (e.g., RealSense D455).
- Assumptions/Dependencies: Calibrated RGB-D sensors and extrinsics; ability to either move the camera (pan-tilt) or reposition the end-effector for alternate views; reliable 3D reconstruction from depth in target lighting; GPU/edge compute sufficient for ~0.5–0.6 s inference; basic safety interlocks.
- Precision insertion and fastening (peg-in-hole, cable routing, screw insertion) on assembly lines (Sector: Manufacturing)
- What: Invoke coarse-to-fine heatmaps and zoom-on-ROI to locate and align small holes/fasteners with high accuracy, reducing cycle failures.
- Tools/Products/Workflows: “Active Alignment” routine integrated with positioners; orthographic projection plus heatmap back-projection to choose end-effector pose; real-time occlusion-aware view switching.
- Assumptions/Dependencies: Stable fixtures; minimal reflective surfaces that degrade depth; pre-trained VLM weights adapted to factory parts; deterministic cycle-time budget; robot controller APIs for dynamic camera/arm reorientation.
- Drawer/cabinet operations and object retrieval from occluded scenes (Sector: Service Robotics, Smart Home)
- What: Robust opening, retrieval, and stacking tasks in cluttered environments using occlusion-aware views and high-resolution local zoom.
- Tools/Products/Workflows: “Home Manipulation Pack” for general-purpose arms (Kinova/Franka) with ActiveVLA; reusable routines for Open Drawer, Stack Cups, Place Items.
- Assumptions/Dependencies: Household lighting and depth fidelity; safe viewpoint motion planning; consumer-grade RGB-D camera calibration; trained task prompts/instructions.
- Teleoperation assistance via “viewpoint suggestions” (Sector: Software, Robotics UI/UX)
- What: Real-time recommendation and automatic positioning of auxiliary cameras (or end-effector-mounted cameras) to reveal occluded regions for human operators.
- Tools/Products/Workflows: UI component that displays top-K active views and a zoomed local ROI; ROS action servers for camera pan-tilt; integration with operator joysticks/controllers.
- Assumptions/Dependencies: Secondary cameras or pan-tilt units; low-latency streaming; operator-in-the-loop safety; good 3D reconstruction under scene textures and materials.
- Active inspection in confined spaces (valves, connectors, small defects) with virtual zoom-enabled close-ups (Sector: Industrial Inspection, Energy Utilities)
- What: Use ActiveVLA to select occlusion-minimizing views and render zoomed-in regions to examine small features for QA checks or maintenance pre-checks.
- Tools/Products/Workflows: “Active QA” plugin for existing inspection robots; ROI heatmaps driving camera reposition; near-field micro-adjustments for higher visual granularity.
- Assumptions/Dependencies: Ability to physically reposition or articulate camera; adequate depth sensing on complex textures; domain-specific prompts fine-tuned on inspection targets.
- Data collection and demonstration generation with active viewpoint planning (Sector: Academia, Tooling)
- What: Reduce dataset size and improve sample efficiency by collecting demonstrations with higher-quality, less-occluded views.
- Tools/Products/Workflows: “Active Dataset Collector” using PyTorch3D render + geodesic viewpoint sampling; alignment with PaliGemma/SigLIP backbones; RLBench/GemBench tasks.
- Assumptions/Dependencies: Calibrated simulation-to-real pipeline; reproducible camera intrinsics/extrinsics; access to GPU compute for multi-view rendering.
- Course and lab integration for active perception in VLA (Sector: Education, Academia)
- What: Teaching labs demonstrating multi-view orthographic projections, heatmap back-projection, and active camera selection on low-cost hardware.
- Tools/Products/Workflows: Lab kits with RealSense + Kinova/Franka; ROS nodes for active view scoring (visibility, distance, diversity); example tasks from RLBench.
- Assumptions/Dependencies: Institutional hardware; stable open-source code; instructor-friendly documentation and prompts.
Long-Term Applications
These require further research, scaling, hardware changes, or regulatory approval. They build on ActiveVLA’s methods to expand capability, generalization, and safety-critical deployment.
- Mobile manipulation with joint planning of base motion, arm, and camera viewpoints (Sector: Robotics, Warehouse/Manufacturing)
- What: Whole-body planners that integrate ActiveVLA’s view selection with base repositioning to optimize occlusion-free observation and fine manipulation in large spaces.
- Tools/Products/Workflows: “Active Perception + Navigation” stack merging SLAM, occlusion-aware view planning, and coarse-to-fine action prediction; multi-camera fusion.
- Assumptions/Dependencies: Reliable localization; multi-sensor calibration; path safety; larger compute budgets; robust on-device inference; more extensive training data across scenes.
- Assistive and healthcare robots for dressing, feeding, and rehabilitation (Sector: Healthcare)
- What: Safe, precise manipulation near humans using active viewpoint strategies to maintain visibility of key anatomy and tools in dynamic, occlusion-heavy contexts.
- Tools/Products/Workflows: “Clinical ActiveVLA” with compliant control, force/tactile feedback, and sterile camera motion planning; integration with hospital information systems and human-in-the-loop supervision.
- Assumptions/Dependencies: Regulatory approvals (FDA/CE), validated safety cases, privacy and data governance for active sensing; domain-specific fine-tuning; robust tactile-vision fusion.
- Surgical assistance and minimally invasive procedures with active camera control (Sector: Healthcare, Medical Robotics)
- What: Intraoperative viewpoint optimization (endoscopes/arthroscopes) to minimize occlusions and improve fine-grained tool placement.
- Tools/Products/Workflows: “Active Endoscope Control” stack integrating 3D zoom-in on tissue ROI; cooperative multi-arm views.
- Assumptions/Dependencies: Specialized sensors (stereo endoscopy), real-time guarantees, strict safety constraints, surgeon oversight, extensive clinical trials.
- Cooperative multi-robot active perception (Sector: Robotics, Energy/Utilities, Construction)
- What: Teams of robots provide complementary viewpoints to each other, sharing ROI heatmaps and active view scores to accomplish complex tasks in occluded/large structures.
- Tools/Products/Workflows: Multi-agent coordination layer; shared 3D scene graph; distributed ActiveVLA inference.
- Assumptions/Dependencies: Low-latency comms; time-synchronized sensors; robust multi-robot localization; conflict-free motion planning; failure-handling protocols.
- Autonomous inspection drones with occlusion-aware viewpoint planning (Sector: Infrastructure, Energy, Transport)
- What: Extend active view selection to aerial robots to inspect bridges, turbines, rails, and pipelines, using 3D recon to propose unoccluded vantage points and zoomed ROI captures.
- Tools/Products/Workflows: “ActiveVLA-Aero” with LiDAR/RGB-D fusion; path planners that trade off proximity, safety, and view diversity.
- Assumptions/Dependencies: Accurate 3D mapping outdoors; GNSS-denied localization solutions; safety regulations for flight; sensor robustness to weather and materials.
- Standardization and policy for active perception safety and privacy (Sector: Policy/Regulation)
- What: Guidelines for camera motion near humans, occlusion-reduction strategies that avoid invasive viewpoints, and data handling for VLM-backed robots.
- Tools/Products/Workflows: Certification protocols for “active observation” behavior; audit trails of viewpoint selections; safe-zone constraints in controller policies.
- Assumptions/Dependencies: Cross-industry consensus; incident reporting frameworks; alignment with privacy laws and workplace safety standards.
- Embedded and energy-efficient ActiveVLA for edge devices (Sector: Hardware/Software)
- What: Model compression and hardware acceleration to achieve sub-100 ms inference for high-throughput manipulation on ARM/Jetson-class platforms.
- Tools/Products/Workflows: Quantization, distillation to compact VLM/VLA backbones; specialized accelerators for token rearrangement and heatmap upsampling; ROS2 real-time nodes.
- Assumptions/Dependencies: Sustained performance under constrained memory/compute; co-design with sensor modules; benchmarking in real-world time budgets.
- Bimanual fine-grained manipulation with tactile and force feedback (Sector: Robotics, Manufacturing/Healthcare)
- What: Integrate ActiveVLA’s view selection with tactile/force cues to handle deformable objects, cable dressing, or delicate human-contact tasks.
- Tools/Products/Workflows: Sensor fusion pipelines; learned policies that weight visual ROI heatmaps with tactile events; multi-end-effector coordination.
- Assumptions/Dependencies: High-fidelity tactile sensors; closed-loop control at high frequency; more complex training regimes; safety verification.
- Digital twin integration for proactive view planning and “what-if” simulations (Sector: Software, Industrial Operations)
- What: Use plant/site digital twins to precompute active viewpoints, occlusion maps, and zoom factors before execution, reducing on-line search.
- Tools/Products/Workflows: “ActiveVLA + Digital Twin” planners; simulation-to-real calibration; automatic generation of task-specific view strategies.
- Assumptions/Dependencies: Up-to-date twins; accurate material and lighting models; alignment with on-site sensor calibration; maintenance workflows.
- General-purpose home robots with robust long-horizon reasoning (Sector: Consumer Robotics)
- What: Household assistants that combine coarse-to-fine perception, occlusion handling, and precision manipulation across varied tasks (tidying, cooking aids, retrieval).
- Tools/Products/Workflows: Task libraries composed from RLBench/GemBench primitives; household-specific active view heuristics; continual learning updates.
- Assumptions/Dependencies: Strong generalization to diverse homes; ergonomic and safe motion; privacy-preserving active sensing; cost-effective hardware.
Notes on cross-cutting assumptions/dependencies:
- Sensing: Reliable RGB-D or multi-view cameras; accurate calibration; depth robustness on shiny/transparent objects is still challenging.
- Compute: Inference times reported (~0.5–0.6 s) may need optimization for strict real-time use; embedded deployment likely requires compression or accelerators.
- Hardware: Physical ability to adjust viewpoints (pan-tilt cameras, mobile bases, or arm-mounted cameras) is central to reaping active perception benefits.
- Data/Models: Access to pre-trained VLM backbones (e.g., PaliGemma/SigLIP) and domain adaptation for target environments; expert demonstrations for tasks; adherence to license terms.
- Safety/Regulation: Motion planning under occlusion with human co-presence; logging and auditability of viewpoint decisions; privacy safeguards for active sensing.
Glossary
- 6-DoF: Six degrees of freedom describing a rigid body pose (three translations and three rotations). "a 6-DoF end-effector pose "
- Active 3D zoom-in: An adaptive virtual rendering technique that narrows the field of view to magnify a local 3D region while preserving pixel resolution. "Active 3D Zoom-in."
- Active perception: A sensing strategy where the agent actively adjusts viewpoints and resolution to gather task-relevant information. "ActiveVLA enables active perception"
- Active viewpoint selection: A method to autonomously choose camera poses that improve visibility, relevance, and diversity while reducing occlusion. "Active Viewpoint Selection."
- Amodal relevance: The degree to which observations pertain to the full object, including parts not currently visible due to occlusion. "maximize amodal relevance"
- Back-projected: Mapped from 2D image space back into 3D coordinates to recover spatial locations. "which are then back-projected to locate the most relevant 3D region."
- Behavior cloning: An imitation learning approach that trains policies via supervised learning on expert demonstrations. "performs 2D behavior cloning"
- Coarse-to-fine: A two-stage approach that first localizes broadly and then progressively refines observations and predictions. "adopts a coarse-to-fine paradigm"
- Collision flag: A binary indicator predicting whether the next action would result in a collision. "a collision flag "
- Cross-entropy loss: A standard classification loss used to train probabilistic predictions such as heatmaps. "The pipeline is trained with cross-entropy loss to predict heatmaps"
- Discretized grid: A finite 3D lattice over the workspace used to accumulate multi-view scores and select target positions. "on a discretized grid "
- Embodied intelligence: Intelligence in agents that perceive and act within physical environments. "a core challenge in embodied intelligence"
- End-effector-centric viewpoint: A camera perspective focused on or mounted near the robot’s gripper, limiting perceptual flexibility. "end-effector-centric viewpoint"
- Euler angles: Three angles (roll, pitch, yaw) used to represent orientation. "represents orientation using Euler angles "
- Eye-to-hand setup: A camera configuration where the camera is external to the robot, viewing the scene rather than being attached to the end-effector. "in an eye-to-hand setup"
- Field of view (FoV): The angular extent captured by a camera, determining spatial coverage. "Let denote the original FoV (in radians)"
- Geodesic sampling: A strategy for near-uniform sampling on a sphere via recursive subdivision of a polyhedron to avoid parameterization bias. "a geodesic sampling strategy"
- Gemma decoder: The language-decoder component from the Gemma model used within the VLM backbone. "Gemma decoder"
- Heatmap: A 2D spatial map highlighting the intensity or likelihood of target regions for attention or prediction. "predict heatmaps to mark critical regions."
- Hierarchical feature fusion: A module that integrates global and local features in stages to predict rotation, gripper state, and collisions. "A hierarchical feature fusion module then integrates global and local context"
- Icosahedron: A 20-faced polyhedron used as the base mesh for uniform spherical sampling via subdivision. "regular icosahedron"
- Isotropic coverage: Uniform sampling or coverage in all directions without directional bias. "To achieve isotropic coverage"
- KDTree: A spatial index for efficient nearest-neighbor queries in point clouds and geometric computations. "Using a KDTree-based nearest-neighbor search"
- Look-at formulation: A camera parameterization defined by eye position, target point, and up vector to orient views. "using the look-at formulation"
- Max-pooling: An aggregation operation that selects the maximum value across features to form global descriptors. "We perform max-pooling over the vision encoder outputs"
- Multi-objective scoring function: A composite metric balancing criteria (e.g., visibility, distance, diversity) to rank candidate views. "a multi-objective scoring function that balances three criteria"
- Multi-view reasoning: Inference that integrates complementary observations from multiple viewpoints to reduce occlusion and ambiguity. "support robust multi-view reasoning"
- Orthographic projection: A parallel projection onto a plane that preserves scale and eliminates perspective distortion. "denotes the orthographic projection."
- PaliGemma: A vision-language backbone architecture combining Pali features with the Gemma decoder. "PaliGemma backbone"
- Perceiver Transformer: A transformer architecture that processes high-dimensional inputs via latent arrays for efficient perception. "Perceiver Transformer policies"
- Point cloud: A set of 3D points representing scene geometry reconstructed from RGB-D inputs. "reconstructs a point cloud of the scene"
- ROI-aware sampler: A sampling mechanism that focuses feature extraction on regions of interest for fine-grained reasoning. "we use an ROI-aware sampler"
- SE(3): The group of 3D rigid-body transformations combining rotations and translations. "SE(3)"
- SigLIP encoder: A vision encoder trained with a sigmoid loss for image-text alignment used in VLM backbones. "SigLIP encoder"
- Spherical surface: The surface of a sphere used for distributing candidate viewpoints uniformly. "on the spherical surface"
- Vision-Language-Action (VLA): Models that map visual observations and language instructions to action outputs for robotic control. "vision-language-action (VLA)"
- Vision-LLMs (VLMs): Models trained jointly on image and text data to enable multimodal understanding. "vision-LLMs (VLMs)"
- Voxel-based: Representing 3D space as volumetric grid cells to enable coarse-to-fine or volumetric processing. "voxel-based coarse-to-fine"
- Z-normalized: Standardized to zero mean and unit variance across candidates or features. "These scores are Z-normalized"
Collections
Sign up for free to add this paper to one or more collections.

