- The paper introduces a scalable VLA model that leverages world model-generated data to overcome real-world robot data limitations.
- It integrates RGB-D input and embodied Chain-of-Thought supervision to enhance spatial perception and sequential reasoning for complex tasks.
- The lightweight GigaBrain-0-Small variant demonstrates efficient on-device deployment with significantly reduced computational resources.
GigaBrain-0: A World Model-Powered Vision-Language-Action Model
Introduction
GigaBrain-0 introduces a scalable paradigm for training Vision-Language-Action (VLA) models by leveraging world model-generated data to overcome the limitations of real-world robot data collection. The model is designed to generalize across diverse environments, object appearances, placements, and viewpoints, and is validated on dexterous, long-horizon, and mobile manipulation tasks. Key architectural innovations include RGB-D input modeling for enhanced spatial perception and embodied Chain-of-Thought (CoT) supervision for improved sequential reasoning. The work also presents GigaBrain-0-Small, a lightweight variant optimized for edge deployment.
Model Architecture
GigaBrain-0 employs a mixture-of-transformers architecture, integrating a pretrained Vision-LLM (VLM, PaliGemma2) for multimodal encoding and an action Diffusion Transformer (DiT) with flow matching for continuous action prediction. Knowledge Insulation is used during training to decouple semantic reasoning from action-space learning, preventing optimization interference. The VLM head is augmented with discrete action token prediction to accelerate convergence.
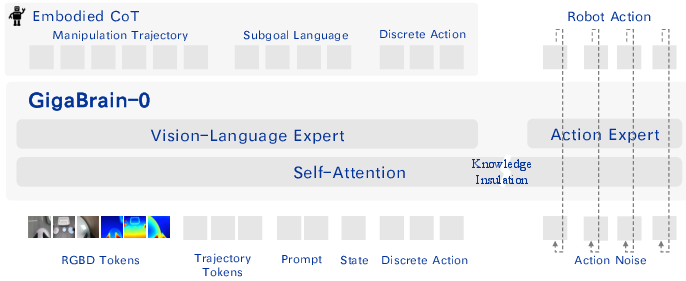
Figure 1: GigaBrain-0 framework: RGB-D input, Embodied CoT output, and Knowledge Insulation for decoupled optimization.
Spatial reasoning is enhanced by adapting SigLIP to RGB-D inputs, extending its first convolutional layer for depth and employing random depth dropout for compatibility with RGB-only inference. Embodied CoT supervision is implemented by generating intermediate reasoning tokens: 2D manipulation trajectories (10 keypoints), subgoal language, and discrete action tokens. Trajectory tokens interact with the visual context via bidirectional attention and are regressed using a GRU decoder. All components are jointly optimized under a unified objective, with Knowledge Insulation obviating manual loss weighting.
Data Generation and Diversity
GigaBrain-0's training corpus integrates public datasets, proprietary real-world robot data, and a broad spectrum of world model-generated data, significantly expanding diversity and reducing reliance on physical collection.

Figure 2: GigaBrain-0's self-collected robot data spans homes, supermarkets, factories, and offices using PiPER arms and AgiBot G1.
World Model-Generated Data
- Real2Real Transfer: Diffusion-based video generation re-renders real trajectories with varied textures, colors, lighting, and materials, multiplying effective data diversity.

Figure 3: Real2Real transfer generates diverse appearance variants from real robot data.
- View Transfer: Depth-based reprojection and inpainting create novel camera perspectives, with robot pose adjusted via IK and rendered for geometric consistency.

Figure 4: View transfer enriches data with varied camera perspectives.
- Sim2Real Transfer: Simulation assets are rendered photorealistically via diffusion models, systematically varying scene parameters to maximize diversity and bridge the sim-to-real gap.

Figure 5: Sim2Real transfer generalizes simulation data for enhanced realism.
- Human Video Transfer: Egocentric human videos are transformed into robot-executable demonstrations by segmenting hands, mapping wrist positions to robot end-effectors, and rendering articulated arms.

Figure 6: Human video transfer maps first-person human actions to robot manipulation.
- Video Generation & Multiview: GigaWorld generates diverse future trajectories and multi-view consistent videos, supporting 3D-aware training and spatial reasoning.

Figure 7: Diverse future trajectories generated from a single initial frame under different prompts.

Figure 8: Multi-view consistent video generation for 3D-aware training.
Quality inspection pipelines filter generated data for geometric, multiview, textual, and physical plausibility, ensuring high-quality synthetic training samples.
Experimental Evaluation
GigaBrain-0 is evaluated on six real-world tasks across two robot platforms (PiPER, AgiBot G1): laundry folding, paper towel preparation, juice preparation, table bussing, boxes moving, and laundry baskets moving.
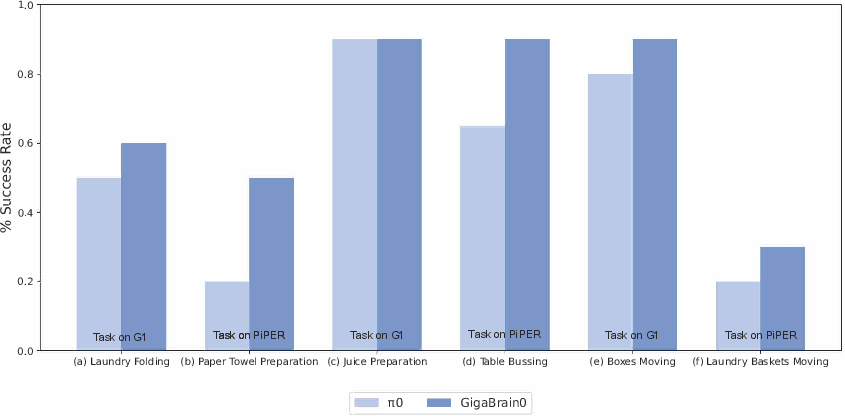
Figure 9: GigaBrain-0 outperforms π0 across dexterous, long-horizon, and mobile manipulation tasks.
- Dexterous Manipulation: GigaBrain-0 achieves 30% and 10% higher success rates than π0 on laundry folding and paper towel preparation, respectively, demonstrating robust dual-gripper coordination and fine manipulation.

Figure 10: GigaBrain-0 deployed for real-world laundry folding.

Figure 11: GigaBrain-0 deployed for paper towel preparation.
- Long-Horizon Tasks: Superior performance in table bussing and juice preparation, enabled by embodied CoT reasoning for multi-step planning.

Figure 12: Table bussing deployment.

Figure 13: Juice preparation deployment.
- Mobile Manipulation: 10% higher success rates in boxes and laundry baskets moving, with seamless navigation-manipulation integration.

Figure 14: Paper towel preparation on G1.

Figure 15: Laundry baskets moving on PiPER.
Generalization Experiments
GigaBrain-0's generalization is validated under appearance, placement, and viewpoint shifts, with the mixing ratio α of world model-generated data as a key variable.
Figure 16: Generalization performance under appearance, placement, and viewpoint shifts as a function of α.
- Appearance: Success rate increases from <30% to >80% as α rises, demonstrating strong generalization to varied garment textures/colors.

Figure 17: Appearance generalization: folding diverse garments.
- Placement: Success rate surpasses 90% with high α, indicating robust adaptation to novel object layouts.

Figure 18: Placement generalization: table bussing with varied object placements.
- Viewpoint: Success rate exceeds 80% with multi-view training, confirming viewpoint-invariant policy learning.

Figure 19: Viewpoint generalization: table bussing from diverse camera angles.
On-Device Deployment
GigaBrain-0-Small, with 12.5% the parameters of π0, achieves comparable success rates on the NVIDIA Jetson AGX Orin, with 5x lower FLOPs, 9x lower VRAM, and 10x lower latency. System-level optimizations include mixed-precision inference, RoPE caching, and static graph compilation.
Implications and Future Directions
GigaBrain-0 demonstrates that world model-generated data can serve as a scalable, effective alternative to traditional robot data collection, enabling robust generalization and efficient training. The embodied CoT framework and RGB-D modeling advance spatial and sequential reasoning in VLA models. The lightweight GigaBrain-0-Small variant makes real-time, on-device deployment feasible.
Future research directions include:
- Integrating world models as interactive policy environments for reinforcement learning, enabling simulated rollouts and reward-driven policy refinement.
- Developing universal representations of physical dynamics and task structure within world models, potentially evolving them into active policy generators.
- Establishing self-improvement cycles where real-world rollouts continuously refine the world model, which in turn generates improved training data, moving toward autonomous lifelong-learning robotic systems.
Conclusion
GigaBrain-0 establishes a new standard for scalable, generalist VLA model training by harnessing world model-generated data. Its architecture and data pipeline yield strong performance and generalization across a spectrum of real-world robotic tasks, with practical deployment on resource-constrained hardware. The approach paves the way for future advances in embodied intelligence, where synthetic data and interactive world models drive continual improvement and autonomy.