GaussianDream: A Feed-Forward 3D Gaussian World Model for Robotic Manipulation
Abstract: Vision-language-action (VLA) policies have advanced language-conditioned robotic manipulation by transferring semantic priors from pretrained vision-LLMs to action generation. Yet, standard action-imitation training often provides limited explicit supervision for 3D geometry, dense visual structure, and short-horizon environment evolution, which are critical for physically precise manipulation. We introduce \textbf{GaussianDream}, a feed-forward 3D Gaussian world-model plug-in that turns robot trajectories into structured spatial-temporal supervision. The key idea is to couple current Gaussian reconstruction with horizon-conditioned future Gaussian prediction during training, forcing a compact spatio-temporal prefix to be decodable into renderable 3D Gaussian states. This enables dense RGB rendering, depth, and pseudo 3D scene-flow supervision without requiring test-time Gaussian decoding. At inference, GaussianDream discards all auxiliary decoding heads and retains only the learned prefix to condition action generation, avoiding rendering, video rollout, or additional planning during closed-loop control. Experiments on LIBERO, RoboCasa Human-50, and real-robot tasks demonstrate strong and highly competitive performance, achieving \textbf{98.4\%} average success on LIBERO, \textbf{52.6\%} on RoboCasa Human-50, and \textbf{50.0\%} in real-world evaluation.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
GaussianDream: A simple explanation
What is this paper about?
This paper is about teaching robots to use their eyes and words better so they can move things more precisely. The authors build a “world model” called GaussianDream that helps a robot understand the 3D shape of the scene right now and imagine how it will change in the next few moments. This extra understanding makes the robot’s actions more accurate, without slowing it down when it’s actually working.
What questions are the authors trying to answer?
- How can we help robots learn a clear 3D picture of the world, not just flat 2D images?
- How can we use the rich information in videos (colors, depth, and motion) to train better robot skills?
- Can a robot quickly “imagine” the near future (the next few steps) to avoid tiny but important mistakes, like grabbing an object slightly off-center?
- Can we do all of this while keeping the robot fast during real-time control?
How does GaussianDream work?
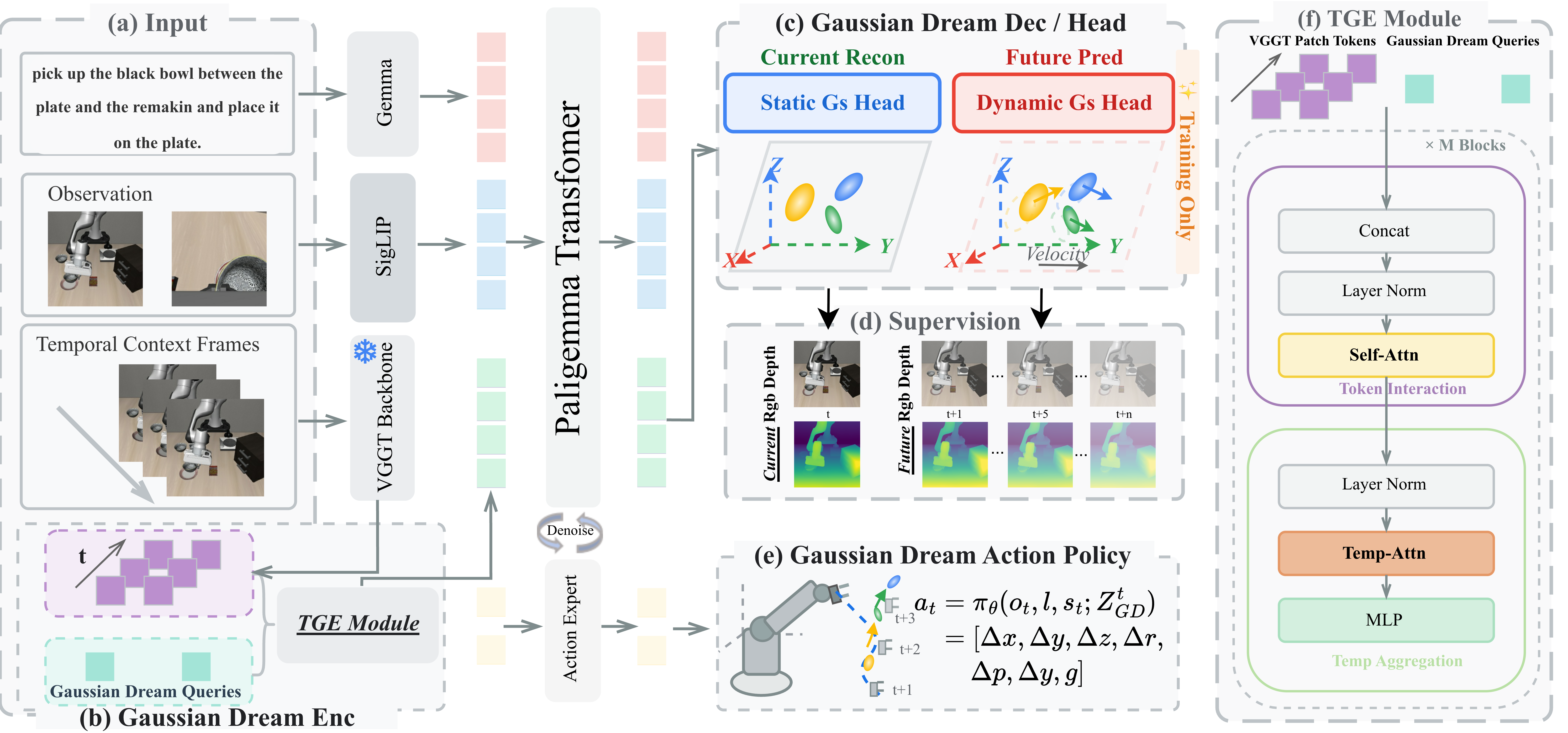
Think of a robot that reads a short instruction (like “put the red block on the blue one”), sees a few recent camera frames, and must decide what to do next. GaussianDream adds a smart “plug-in” that, during training, turns those inputs into a detailed 3D snapshot and a short-range future forecast—then, at test time, keeps only a compact summary so the robot stays fast.
To make this clear, here are the main steps the system uses:
- The robot looks at a few recent frames (for example: 10 steps ago, 5 steps ago, and now), plus the instruction and robot state.
- An encoder mixes this information into a compact summary called a prefix. You can think of the prefix as a short cheat sheet that captures important 3D and motion clues.
- During training only, two extra “heads” use that prefix:
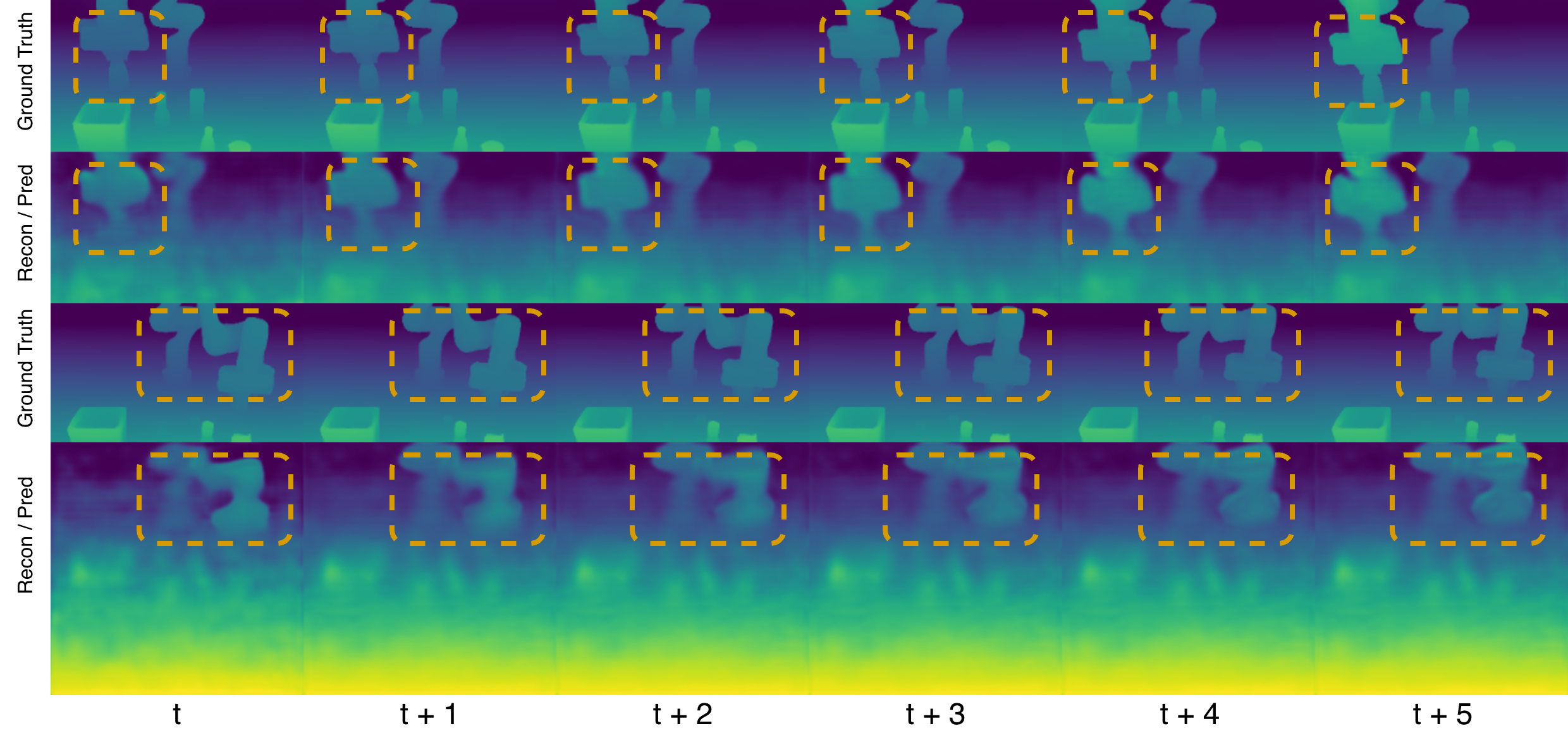
- A current-scene head reconstructs the 3D scene using “3D Gaussians.” Imagine the scene made of many tiny, fuzzy, colored bubbles that together approximate objects. From this, it renders regular images and depth maps and learns to match the real camera view. This gives strong 3D supervision.
- A future-scene head predicts how those bubbles shift over the next 1–5 steps. This is like forecasting short-term motion, known as “scene flow” (how every point in the scene moves). It also learns by comparing predicted images, depth, and motion with what actually happened in the videos.
- Once training is done, the robot throws away the heavy reconstruction and prediction heads. At test time, it only creates the prefix (the cheat sheet) and feeds it into the action policy to decide what to do—no slow rendering, no video rollout, no extra planner. This keeps control fast and simple.
Helpful analogies for the technical ideas:
- 3D Gaussians: a cloud made of tiny, colored soap bubbles that approximates objects in 3D.
- Depth: how far each pixel is from the camera (like a built-in ruler).
- Scene flow: arrows showing where each point in the scene will move next.
- Prefix: a short, information-rich summary the robot uses to act quickly.
What did they find?
The authors tested GaussianDream in simulation and on a real robot:
- LIBERO benchmark: 98.4% average success. It did especially well on spatial and goal-focused tasks (both 99.0%), which demand precise positioning.
- RoboCasa Human-50 (kitchen tasks): 52.6% average success, the best overall in their comparisons. It was notably strong on pick-and-place tasks, where exact placement matters.
- Real robot: improved average success from 34.4% (a strong baseline model) to 50.0%. It helped most in tasks involving spatial relations and longer action sequences.
They also ran ablations (turning pieces on/off) showing:
- Reconstructing the current 3D scene already helps a lot (strong spatial grounding).
- Predicting the near future adds more gains (better short-horizon anticipation).
- Using both rendered images and depth as training signals provides complementary benefits—together they teach the robot cleaner, more accurate 3D understanding.
Why is this important?
Small geometric mistakes (like grabbing a few millimeters off) can cause big failures in real-world robot tasks. By:
- grounding the robot in an explicit 3D scene,
- training it with dense signals from videos (color, depth, motion),
- and teaching it to predict the near future,
GaussianDream helps the robot act more precisely and robustly. Crucially, it keeps inference lightweight: the heavy 3D reconstruction and prediction are only used during training, while actual control just uses the compact prefix. This means better accuracy without slowing down the robot when it’s working.
Bottom line
GaussianDream turns ordinary robot videos into powerful 3D and motion lessons. The robot learns to build a mental 3D model of the scene and to imagine short-term changes—then keeps only a fast, compact summary to guide its actions. The result is more precise, reliable manipulation across simulations and real-world tasks, without adding heavy computation during deployment.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps that remain unresolved and could guide future research:
- Inference efficiency is asserted but not quantified: no end-to-end runtime, control-frequency (Hz), latency jitter, or memory footprint benchmarking versus 2D/3D/VLM world-model baselines on standard robot hardware.
- Reliance on pseudo supervision is under-specified: the procedure, quality, and bias of pseudo depth and pseudo 3D scene flow (constructed from adjacent frames) are not validated against ground-truth sensors; the impact of noisy pseudo targets on policy robustness is unknown.
- Short-horizon future modeling only: prediction horizons are limited to t+1…t+5; scalability to longer horizons, error accumulation, and benefits for long-horizon planning remain untested.
- Limited dynamics expressivity: future prediction updates only Gaussian centers while reusing non-positional attributes (rotation, scale, opacity, SH appearance), which likely hampers modeling of articulation, rigid-body pose changes, deformation, occlusion/disocclusion, and illumination/appearance shifts.
- Articulated-object modeling is implicit: the approach lacks explicit joint/part kinematics; weaker RoboCasa Doors/Drawers results suggest a need for part-aware, articulation-grounded Gaussian dynamics.
- Metric grounding and calibration are not analyzed: the method uses camera intrinsics to unproject depth but does not study extrinsics, scale alignment to robot coordinates, or sensitivity to calibration errors; strategies for self-calibration are absent.
- Multi-view versus monocular benefits are unclear: although “multi-view observations” are mentioned, experiments do not isolate or quantify the advantage of multi-view inputs over single-view setups or varying baselines.
- Robustness to real-world visual challenges is not characterized: no stress tests for lighting variation, motion blur, occlusion, background distractors, domain shift, or adversarial camera poses; the effect of depth noise and compression artifacts is unknown.
- Data and sample efficiency are unreported: how performance scales with fewer demonstrations, reduced prediction horizons, or limited pretraining is not analyzed.
- Architectural sensitivity is unstudied: no ablations on number of GaussianDream tokens, latent grid resolution (32×32→256×256), number of Gaussians (≈65k), TGE depth/heads, or temporal spacing of context frames (e.g., t−10, t−5, t).
- Training cost and scalability are opaque: rendering and supervising tens of thousands of Gaussians across multiple horizons is compute-heavy; wall-clock training time, GPU memory, and dataset size requirements are not reported.
- Real-robot evaluation scale is limited: results on one embodiment and four scenes lack statistical power; cross-robot generalization, broader task suites, and rigorous failure-mode taxonomy are missing.
- Uncertainty is not modeled: the approach provides deterministic prefixes without calibrated uncertainty over predicted geometry/dynamics; how to exploit uncertainty for safer execution or cautious control remains open.
- No analysis of retaining lightweight decoding at inference: potential trade-offs between keeping a minimal renderer for online geometry checks versus pure prefix conditioning are not explored.
- Theoretical information content of the prefix is unquantified: there is no measure of how much 3D/dynamics information is preserved in the prefix after discarding decoding heads (e.g., mutual information or linear/causal probes).
- Contact and force reasoning are absent: learning relies on vision-only cues; integration with tactile/force sensing and its effect on future-state prediction and precise contact behaviors is unexplored.
- Online adaptation is not addressed: whether the prefix can be updated with self-supervised signals during deployment (without decoding heads) to handle drift or domain shift remains open.
- Planning versus feed-forward trade-off is untested: conditions where explicit test-time rollouts or MPC leveraging predicted futures would outperform pure feed-forward action generation are not examined.
- Handling dynamic agents and non-stationary scenes is untested: scenes with moving humans/objects that are not manipulated by the robot are not evaluated; how the model separates exogenous dynamics from robot-induced changes is unknown.
- Failure analysis is shallow: the paper reports aggregate success but lacks error categorization (e.g., perception mislocalization vs. contact failure vs. goal misinterpretation) to guide targeted improvements.
- Transparent/reflective/thin objects and complex geometry are not evaluated: known failure cases for depth/Gaussian reconstructions are absent from the analysis.
- Coordinate-frame handling with moving cameras/mobile manipulators is unspecified: performance with wrist/ego cameras, camera motion, or base mobility and the necessary frame transforms are not studied.
- Use of real depth at training/inference is not compared: whether substituting pseudo depth with sensor depth or adding depth at inference improves performance is unknown.
- Horizon-encoding design choices are unvalidated: the choice of learnable horizon embeddings and temporal scale factors lacks ablations; alternative parameterizations (continuous-time, learned integrators) remain unexplored.
- Generalization breadth is unclear: zero-shot generalization to unseen objects, language instructions, and environments beyond the chosen benchmarks is not systematically characterized.
- Safety constraints and guarantees are not discussed: there is no treatment of collision avoidance, conservative behavior under uncertainty, or recovery strategies during closed-loop control.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that can be implemented now with the paper’s methods and findings, along with sectors, potential tools/workflows, and key assumptions.
- [Industry | Software/Robotics] Bold plug-in upgrade for existing VLA robot policies
- What: Drop-in “GaussianDream prefix” module to augment RT-2/OpenVLA/π-series robots with explicit 3D spatial grounding and short-horizon anticipation while keeping feed-forward, low-latency inference.
- Tools/workflows: ROS2 node exposing gdream_prefix; training script that jointly optimizes action loss with dense RGB/depth/flow supervision heads; simple config to disable decoding heads at inference.
- Assumptions/dependencies: Access to robot videos/demos; camera intrinsics (approximate or calibrated); compute for offline pretraining; compatible VLA backbone and token interface.
- [Manufacturing, Logistics] Precision pick-and-place and placement verification on assembly lines and in fulfillment centers
- What: Improve grasp-point accuracy and place-on-target reliability for short-horizon manipulations (bin picking, kitting, parcel sorting) without adding runtime planners.
- Tools/workflows: “Skill pack” pretraining using in-house demos; production deployment with only the prefix encoder; QA dashboard to monitor reconstruction loss during training.
- Assumptions/dependencies: Multi-view or well-posed single-view cameras; stable lighting; short horizons (1–5 steps) cover the task; safety interlocks remain in place.
- [Retail, Warehousing] Shelf restocking and order consolidation robots with better spatial robustness
- What: Reduce misplacement and collision near shelves through geometry-aware action conditioning learned from dense supervision on store videos.
- Tools/workflows: Store-specific dataset curation pipeline; pseudo-depth/scene-flow generation module; scheduled fine-tuning on new planograms.
- Assumptions/dependencies: Accurate shelf geometry or good camera pose; maintained dataset reflecting new SKUs/packaging.
- [Home/Service Robotics | Daily Life] Household short-horizon tasks (tidying, placing dishes, folding starts/finishes)
- What: Increase reliability of pick/place, opening/closing, and short transfers in cluttered kitchens or living rooms using only the prefix at runtime.
- Tools/workflows: Teleoperation data collection + automatic dense supervision; on-device inference on embedded GPU (no rendering/rollouts).
- Assumptions/dependencies: Camera intrinsics known or estimated; tasks remain within short horizons and moderate contact complexity.
- [Healthcare | Assistive Robotics] Safer assistive manipulation with improved placement accuracy
- What: Precise handover/placement of objects (cups, utensils, medication organizers) for assistive arms; geometry-aware responses to language commands.
- Tools/workflows: Hospital/home environment demos; validation scripts measuring depth/rendering alignment; conservative action limits.
- Assumptions/dependencies: Clinical safety procedures unchanged; limited-contact tasks; regulatory approvals still required for patient-facing use.
- [R&D/Academia] Turn robot videos into dense supervision for geometry and dynamics without new sensors
- What: Reuse existing lab datasets to supervise RGB, depth, and pseudo 3D scene flow for improved sim-to-real and spatial generalization.
- Tools/workflows: gdream_supervise pipeline to generate pseudo depth/flow; ablation-ready training scripts; benchmark harness for LIBERO/RoboCasa reproduction.
- Assumptions/dependencies: Off-the-shelf monocular depth/flow estimators; reasonable scene texture; acceptable pseudo-label noise.
- [Software Tooling | MLOps] Low-latency embedded inference for mobile manipulators
- What: Maintain VLA-level runtime while gaining 3D structure, because all Gaussian decoding heads are dropped at test time.
- Tools/workflows: TensorRT/ONNX export of the prefix encoder + policy; latency profiling; watchdogs for compute budgets.
- Assumptions/dependencies: Sufficient VRAM for the base VLA and prefix encoder; no heavy renderers or planners in the loop.
- [Quality Assurance | Safety] Offline “spatial QA” for policies via reconstruction/prediction diagnostics
- What: Before deployment, verify spatial alignment by checking RGB/depth renderings and predicted short-horizon changes against recorded trials.
- Tools/workflows: QA dashboard reporting per-scene reconstruction/prediction losses and failure cases; regression tests on canonical objects.
- Assumptions/dependencies: Access to evaluation datasets; agreement on acceptance thresholds for pixel/depth metrics.
- [Education | Robotics Curricula] Teaching module on world-model-based manipulation with 3D Gaussians
- What: Course labs where students train the static (reconstruction) and dynamic (future) heads, then evaluate the inference-only prefix policy.
- Tools/workflows: Starter code, small-scale datasets, and ablation scripts; visualizations of depth/rendering to connect theory and practice.
- Assumptions/dependencies: Modest GPUs and short curated sequences suffice for course-scale experiments.
- [Policy/Standards] Immediate procurement/testing guidance emphasizing spatial precision under short horizons
- What: Add acceptance tests for 2–5 step spatial tasks (grasp localization, placement deviation) to vendor evaluations of VLA-controlled arms.
- Tools/workflows: Standardized short-horizon “fixture” tasks with depth-consistency checks; transparent reporting of reconstruction/prediction metrics in lab validation.
- Assumptions/dependencies: Not a regulatory mandate; relies on existing QA infrastructure and camera calibration.
Long-Term Applications
These applications require further research, scaling, or engineering to mature (e.g., more robust depth/flow supervision, longer horizons, contact modeling, or certification).
- [Home Robotics | Daily Life] Generalist household assistant with robust spatial reasoning across homes
- What: Broad skill coverage (tidying, cooking prep, laundry) through continual video-to-Gaussian supervision and cross-device prefix transfer.
- Tools/products: Consumer “GaussianDream-enabled” home robot; lifelong dataset engine turning daily operation logs into dense supervision.
- Assumptions/dependencies: Better handling of long-horizon, contact-rich tasks; privacy-preserving on-device learning; diverse home data.
- [Healthcare] High-precision surgical/clinical manipulation aids
- What: Incorporate explicit 3D Gaussian state anticipation into surgical sub-tasks (tool passing, suture handling) for assistant robots.
- Tools/products: FDA/CE-aligned software lifecycle for Gaussian world-model plug-ins; sim-to-real suites with tactile/force integration.
- Assumptions/dependencies: Regulatory approval; precise calibration; integration with force/vision feedback and fail-safe controls.
- [Logistics/Manufacturing] Digital twins for predictive planning with learned Gaussian world models
- What: Use the trained static/dynamic Gaussian heads (re-enabled offline) to simulate short-horizon outcomes for line balancing and what-if analysis.
- Tools/products: “GaussianTwin” planning add-on; batch evaluators that roll forward predicted Gaussians under candidate action sequences.
- Assumptions/dependencies: Accurate camera/asset models; bridging from short-horizon to task-level planning; interfaces to MES/WMS.
- [Autonomy Stack] Unified mapping and manipulation via 3D Gaussian SLAM + action policies
- What: Fuse SLAM-grade Gaussian maps with the prefix-conditioned controller for mobile manipulation (dock-to-shelf, then precise pick).
- Tools/products: Shared Gaussian memory between navigation and manipulation; map-policy synchronization layer.
- Assumptions/dependencies: Persistent, drift-resilient Gaussians; dynamic-object handling; large-scale memory management.
- [Multi-Robot Systems] Shared GaussianDream prefixes for cooperative manipulation
- What: Robots exchange compact prefixes (rather than raw video) to coordinate tasks (handover, large-object manipulation).
- Tools/products: Prefix communication protocol; edge message broker with QoS; consistency checkers for multi-view fusion.
- Assumptions/dependencies: Time sync; bandwidth and privacy constraints; calibrated multi-robot perception.
- [Human-in-the-Loop | AR/VR] Visual action previews from Gaussian predictions for teleoperation or oversight
- What: Overlay predicted short-horizon geometry changes in AR to approve/adjust actions before execution.
- Tools/products: AR headset app rendering future Gaussian states; acceptance UI linked to the robot controller.
- Assumptions/dependencies: Real-time rendering pipeline of Gaussians; accurate interaction modeling; operator training.
- [Sustainability/Energy] Energy-efficient edge manipulation
- What: Lower compute at inference relative to video-rollout world models enables battery-powered mobile manipulators.
- Tools/products: Power-aware schedulers; hardware co-design (low-power GPUs/NPUs) optimized for prefix-only inference.
- Assumptions/dependencies: Further model distillation/quantization; thermal constraints; robust performance under limited compute.
- [Safety/Certification] World-model-based conformance tests and standards
- What: Define certification procedures that include spatial reconstruction quality, future-prediction fidelity, and failure-bound guarantees.
- Tools/workflows: Standard datasets and metrics for Gaussian rendering/depth/flow; third-party audit scripts.
- Assumptions/dependencies: Community consensus on metrics; interoperability across vendors; alignment with existing safety norms.
- [Cross-Embodiment Transfer] Prefix-level adaptation across grippers/cameras/arms
- What: Leverage the modality-agnostic prefix space to transfer spatial understanding between different robot embodiments with minimal re-collect.
- Tools/workflows: Adapters for camera intrinsics/extrinsics; embodiment-conditioned fine-tuning; prefix distillation.
- Assumptions/dependencies: Generalizable visual backbones; coverage of embodiment variations in training.
- [Advanced Skills] Contact-rich, deformable-object, and fluid manipulation
- What: Extend Gaussian dynamics with contact/force priors and longer horizons to handle cutting, folding, pouring, or cable routing.
- Tools/workflows: Multi-modal supervision (tactile, force-torque); differentiable physics augmenting Gaussian prediction.
- Assumptions/dependencies: High-quality multi-sensor datasets; improved modeling of non-rigid dynamics; safety verification for complex contacts.
Notes on Assumptions and Dependencies Across Applications
- Short-horizon bias: The current method supervises horizons of roughly 1–5 steps; longer or highly branched plans benefit from planners or hierarchical policies.
- Supervision quality: Pseudo depth and scene flow introduce noise; performance improves with multi-view data or better estimators.
- Calibration: Camera intrinsics/extrinsics (or robust self-calibration) are important for metric accuracy.
- Compute split: Training is compute-intensive due to dense supervision; inference is light (prefix-only).
- Safety and compliance: Domain-specific safety (e.g., healthcare, industrial) still requires formal validation and oversight.
- Data governance: Video-derived supervision raises privacy/IP concerns; organizations need policies for storage, use, and sharing.
Glossary
- 3D Gaussian: A 3D scene representation using anisotropic Gaussian primitives to model geometry and appearance. "forcing a compact spatio-temporal prefix to be decodable into renderable 3D Gaussian states."
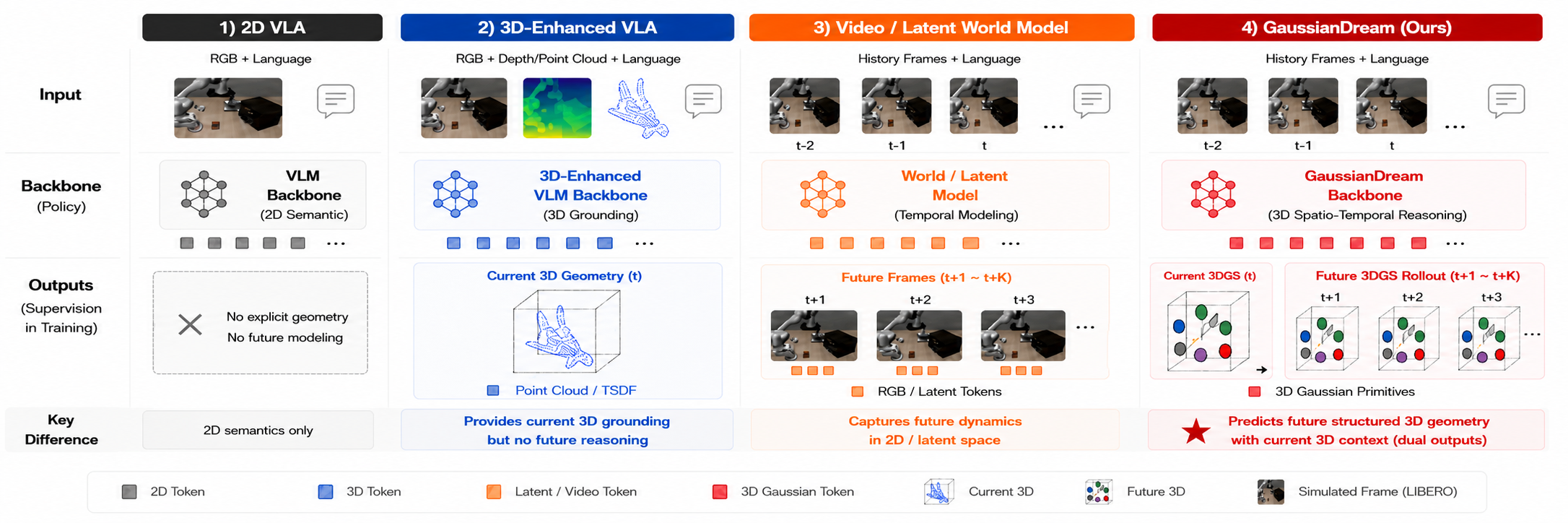
- 3D Gaussian world model: A predictive model that represents and anticipates environment states directly in a 3D Gaussian space. "we present GaussianDream, a unified, feed-forward 3D Gaussian world model framework tailored for language-conditioned robotic manipulation."
- 4D features: Spatio-temporal features that include 3D space plus time to capture motion and structure. "incorporate depth, stereo cues, 4D features, point clouds, or projected 3D representations for spatial grounding."
- autoregressive rollouts: Sequential prediction procedures where future states are generated step-by-step using prior outputs, often increasing inference cost. "their generative predictions typically require iterative voxel optimization or heavy visual autoregressive rollouts"
- back-projecting: The process of mapping pixels and depths from image space back into 3D coordinates. "the depth head predicts a depth map for back-projecting Gaussian centers"
- behavior cloning: Imitation learning that maps observations to expert actions by supervised learning on demonstration data. "their training is largely dominated by behavior cloning"
- camera intrinsics: Parameters defining the camera’s internal geometry (e.g., focal length, principal point) used for projecting between 2D and 3D. "Using camera intrinsics, is unprojected into 3D centers "
- closed-loop control: A control strategy where actions are continuously adjusted based on new observations during execution. "avoiding rendering, video rollout, or additional planning during closed-loop control."
- current Gaussian reconstruction: Reconstructing the present 3D scene as Gaussians from observations to provide explicit spatial grounding. "GaussianDream uses current Gaussian reconstruction and future Gaussian prediction to learn structured 3D supervision from robot videos while retaining efficient prefix-based action generation."
- degree-1 spherical harmonics: A low-order spherical harmonics basis (l=1) used to efficiently model view-dependent appearance. "the appearance head predicts degree-1 spherical harmonics coefficients"
- denoising procedure: The sampling process in diffusion/flow-based policies that iteratively removes noise to produce the final action. "The policy then follows the base denoising procedure to sample the final action chunk."
- feed-forward: A non-iterative inference paradigm where outputs are produced in a single pass without rollouts or optimization loops. "a feed-forward 3D Gaussian world-model plug-in that turns robot trajectories into structured spatial-temporal supervision."
- few-shot setting: An evaluation regime with limited training examples per task. "we use the Human-50 few-shot setting over 24 long-horizon kitchen tasks"
- flow-matching policy: An action model trained via flow matching, a technique aligning data with noise through continuous-time transport. "we enable action learning and condition the base flow-matching policy on the GaussianDream prefix"
- flow-matching time distribution: The distribution over continuous time used when sampling training times for flow matching. "where and is sampled from the flow-matching time distribution."
- future Gaussian prediction: Anticipating short-horizon changes in the 3D Gaussian scene to model how the environment evolves. "GaussianDream uses current Gaussian reconstruction and future Gaussian prediction to learn structured 3D supervision from robot videos"
- horizon embedding: A learned vector that conditions predictions on the desired future time offset. "Here is a learnable horizon embedding"
- horizon-conditioned: Conditioned on a specified number of future steps to predict time-indexed outcomes. "a dynamic, horizon-conditioned Gaussian head for future geometric change prediction."
- learnable queries: Trainable tokens that interact with visual features in attention-based encoders to extract task-relevant information. "a lightweight spatio-temporal reasoning encoder interacts with learnable queries to extract 3D-aware features from temporal observations"
- open-vocabulary instruction following: The ability to understand and act on instructions that include previously unseen words or categories. "further advance open-vocabulary instruction following, continuous action modeling, and generalist policy learning."
- patch tokens: Tokenized representations of image patches used by transformer-like encoders. "The GaussianDream encoder extracts VGGT patch tokens from temporal observations"
- point clouds: Sets of 3D points representing scene geometry, often from depth sensors. "representations like point clouds or depth maps"
- prefix space: A shared embedding space for prefix tokens that condition the policy (across modalities like image and language). "Image, language, and GaussianDream tokens share the 2048-dimensional PaliGemma/Gemma-2B prefix space"
- pseudo 3D scene-flow: Approximate 3D motion vectors between frames used as supervision when true scene flow isn’t available. "This enables dense RGB rendering, depth, and pseudo 3D scene-flow supervision"
- RGB rendering: Synthesizing color images from 3D representations for supervision or evaluation. "This enables dense RGB rendering, depth, and pseudo 3D scene-flow supervision"
- short-horizon: Referring to a small number of future steps relevant for immediate action outcomes. "short-horizon environment evolution"
- Temporal Gaussian Evolution (TGE): The module that fuses temporal features with queries to build the GaussianDream prefix. "This prefix is generated by the temporal 3D-aware encoder ... implemented by the Temporal Gaussian Evolution (TGE) module"
- test-time Gaussian decoding: Decoding/full reconstruction of Gaussians during inference; avoided here for efficiency. "without requiring test-time Gaussian decoding."
- unprojection: The operation of converting depth-aligned image coordinates into 3D positions. "Using camera intrinsics, is unprojected into 3D centers "
- validity mask: A mask indicating which pixels/points have reliable supervision for loss computation. "the flow term matches predicted center displacements to pseudo 3D scene flow under a validity mask."
- VGGT: A backbone for extracting multi-scale, 3D-aware visual features used by the encoder. "we extract multi-scale 3D-aware patch features using VGGT"
- video rollout: Predicting sequences of future frames during inference, typically expensive and avoided here. "bypassing test-time Gaussian decoding, geometric rendering, video rollout, and additional planning."
- Vision-language-action (VLA): Models that integrate visual inputs, language instructions, and action outputs for robotic control. "Vision-language-action (VLA) policies have advanced language-conditioned robotic manipulation by transferring semantic priors from pretrained vision-LLMs to action generation."
- voxel optimization: Iterative fitting of voxel/volume parameters to reconstruct scenes, often computationally heavy. "their generative predictions typically require iterative voxel optimization or heavy visual autoregressive rollouts"
- world models: Predictive models that learn to forecast future environment states to aid control and planning. "emerging robotic world models introduce proactive environment reasoning by forecasting future states in pixel, latent, or action spaces"
Collections
Sign up for free to add this paper to one or more collections.