SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing
Abstract: Image spatial editing performs geometry-driven transformations, allowing precise control over object layout and camera viewpoints. Current models are insufficient for fine-grained spatial manipulations, motivating a dedicated assessment suite. Our contributions are listed: (i) We introduce SpatialEdit-Bench, a complete benchmark that evaluates spatial editing by jointly measuring perceptual plausibility and geometric fidelity via viewpoint reconstruction and framing analysis. (ii) To address the data bottleneck for scalable training, we construct SpatialEdit-500k, a synthetic dataset generated with a controllable Blender pipeline that renders objects across diverse backgrounds and systematic camera trajectories, providing precise ground-truth transformations for both object- and camera-centric operations. (iii) Building on this data, we develop SpatialEdit-16B, a baseline model for fine-grained spatial editing. Our method achieves competitive performance on general editing while substantially outperforming prior methods on spatial manipulation tasks. All resources will be made public at https://github.com/EasonXiao-888/SpatialEdit.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about “spatial image editing.” Instead of changing what things look like (color, style, texture), spatial editing changes where things are and how the camera looks at them. Think of it like:
- Object edits: moving, resizing, or turning an object inside a photo without messing up the rest of the scene.
- Camera edits: acting like you tilted, panned, or zoomed a real camera when the photo was taken.
The authors noticed that current AI image editors often make pictures that look okay but don’t match the exact movement or angle the user asked for. So they built three things to fix that: a benchmark (tests), a big training dataset, and a strong baseline model.
What questions were they trying to answer?
- Can we test, in a fair and precise way, whether an AI actually followed a spatial instruction like “rotate the camera 90° to the right” or “move the cup into this box”?
- Can we create enough high-quality training data, with exact ground-truth movements and angles, so models learn to do fine-grained spatial edits well?
- Can we build a model that does normal image edits nicely and also handles tricky spatial edits accurately?
How did they do it?
They built three key parts: a benchmark, a dataset, and a model.
1) A new benchmark: SpatialEdit-Bench
A “benchmark” is a set of tests and scoring rules. This one checks whether an edited image is both:
- Plausible to the eye (it looks natural), and
- Geometrically correct (the move/rotation/zoom really matches the instruction).
To score camera edits, they use two ideas:
- Viewpoint Error: imagine reconstructing where the camera was in 3D for the source image, the target, and the AI’s result. Then measure how far off the AI’s camera is from the correct one. This is like checking if you actually turned your head by the requested angle, not just “kinda turned.”
- Framing Error: checks if important objects are where they should be in the picture, pointing from the image center to each object and comparing angles and sizes. This makes sure zoom-ins actually make things bigger, and that objects stay in the right parts of the frame.
For object edits (like move or rotate):
- Moving Score: did the object end up inside the target box, and does it still look like the same object without weird artifacts?
- Rotation Score: did the object get turned to the requested view (like “front-right”) and still look consistent?
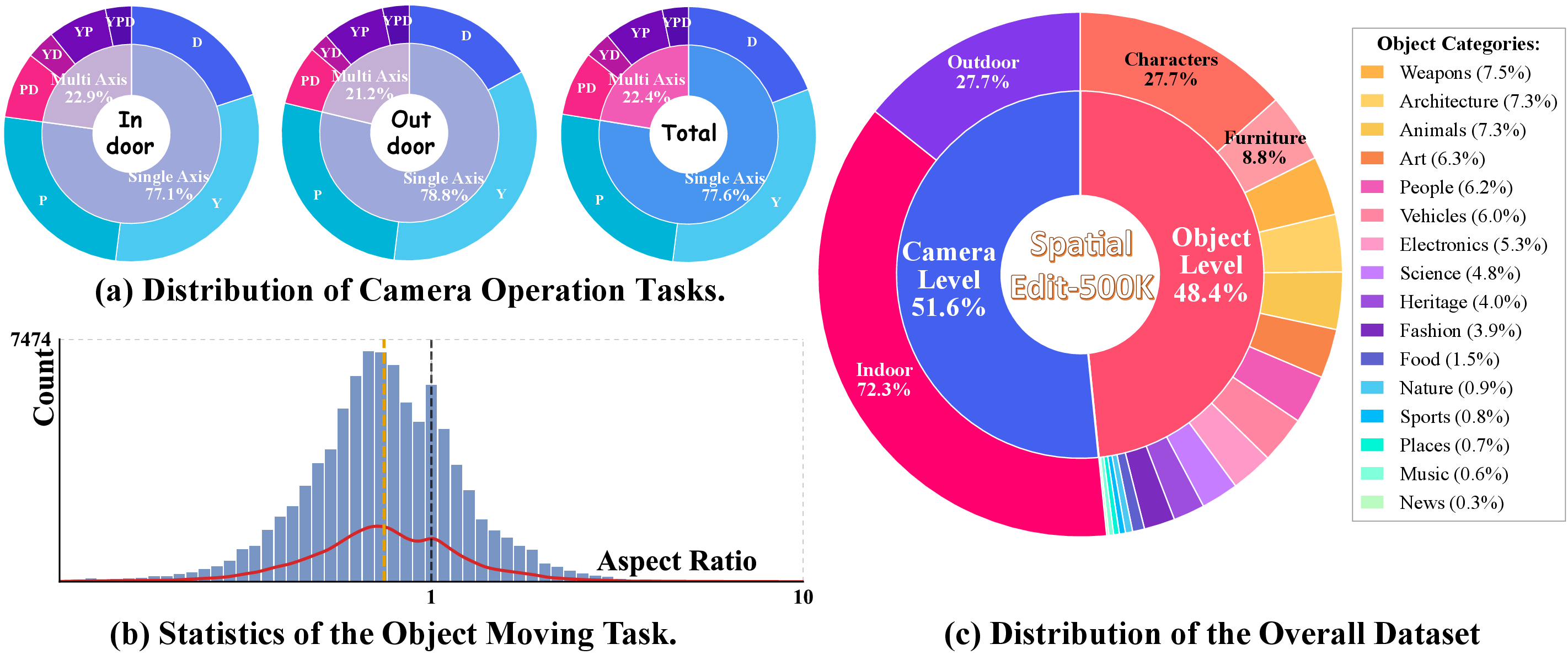
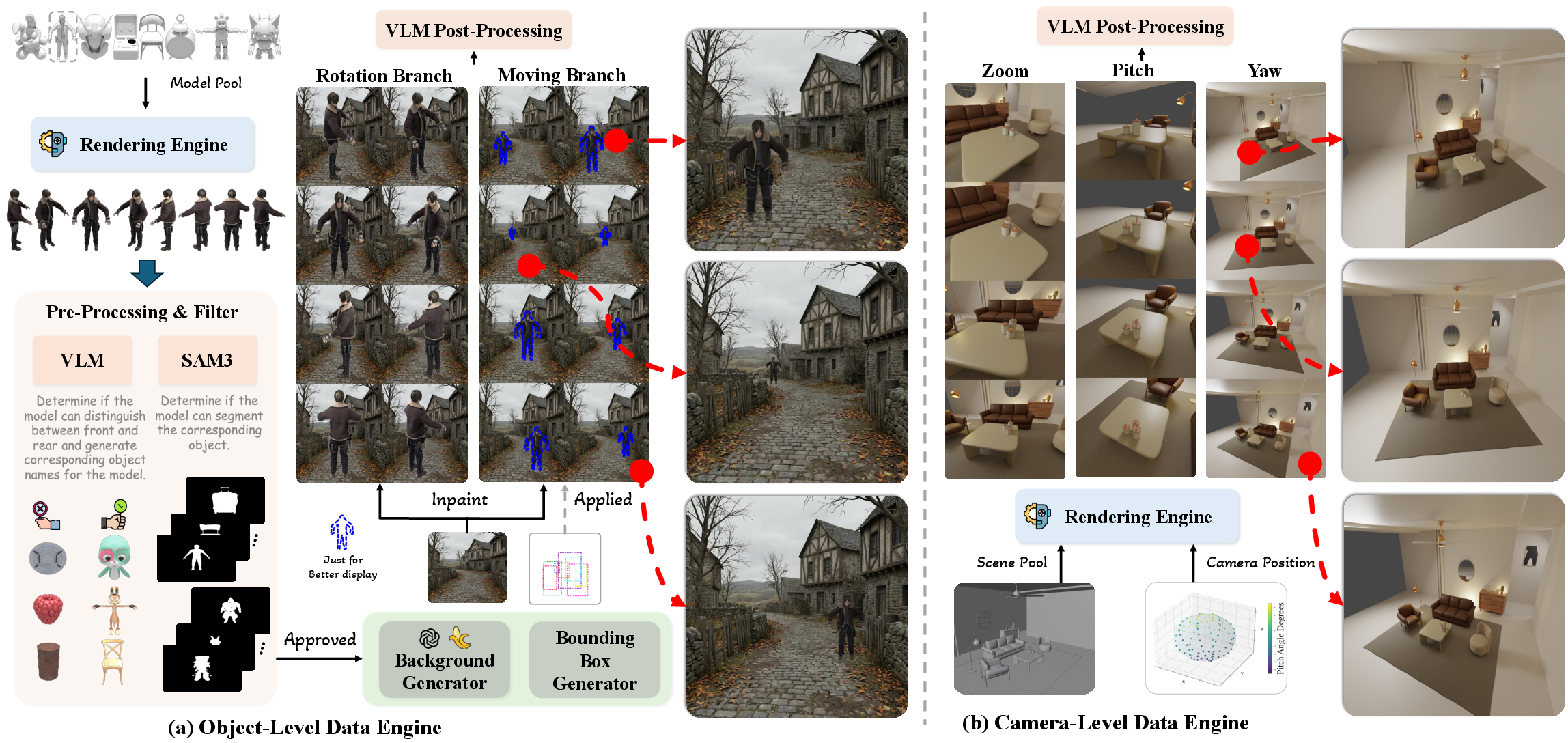
2) A new dataset: SpatialEdit-500k
A “dataset” is a large collection of examples used to train and test AI. Real photos don’t usually come with exact camera angles or object rotations, so the authors made a synthetic dataset using Blender (a 3D program). Think of Blender like a digital movie set where you can place objects, move cameras, and render images while recording the exact moves you made.
They created two branches of data:
- Object-centric: place a 3D object (like a chair) into realistic backgrounds, then generate images where the object is moved, scaled, or rotated to known positions and orientations.
- Camera-centric: build indoor/outdoor scenes, pick a focus object, and systematically change camera yaw (left-right turn), pitch (up-down tilt), and zoom. Because it’s all done in 3D, they know the precise angles and distances for each image pair.
They also used:
- Object detectors and segmenters (AI tools that find and outline objects) to make sure the object is visible and properly cut out.
- Vision-LLMs (AI that understands both pictures and text) to verify that views and instructions match and that images make sense.
This produced about 500,000 high-quality, diverse training examples with exact ground-truth transformations.
3) A new model: SpatialEdit-16B
They built a strong baseline model for spatial editing:
- First, they pretrained it on general image editing so it learns to follow instructions and keep image quality high.
- Then they “post-trained” (fine-tuned) it on their SpatialEdit-500k dataset to teach precise spatial control. They used a technique called LoRA, which is like adding small “adapter” layers to improve a big model without retraining everything from scratch.
In simple terms: they taught the model the basics of good editing, then gave it focused lessons on geometry and spatial accuracy.
What did they find?
- Their benchmark can reliably tell the difference between “looks right” and “is right” for spatial edits. In tests, geometry-aware scores were more trustworthy than just asking a LLM to judge.
- Their dataset helped the model learn accurate, fine-grained moves and camera changes, not just rough guesses.
- Their model, SpatialEdit, stayed competitive on normal editing tasks and was much better at spatial tasks than previous systems. It:
- Moved and rotated objects more accurately, with fewer artifacts.
- Achieved lower camera viewpoint errors and better framing, meaning it actually followed zoom/tilt/pan instructions precisely.
- Video world models (which generate short videos) did worse at precise camera edits when judged frame-by-frame. It’s hard for them to keep exact camera motion and composition consistent.
- As a bonus, their model can help single-view 3D reconstruction: by generating new camera views from one photo, it gives more angles to 3D tools, often resulting in better reconstructions.
Here are the main takeaways summarized in a short list:
- The new tests (SpatialEdit-Bench) measure spatial accuracy, not just visual plausibility.
- The synthetic dataset (SpatialEdit-500k) provides clean, balanced training examples with exact ground-truth moves.
- The model (SpatialEdit-16B) outperforms prior methods on fine spatial edits while keeping general editing quality strong.
Why it matters
Precise spatial editing is important for:
- Content creation: moving items or changing viewpoints exactly, like a director repositioning a camera or a designer arranging a scene.
- AR/VR and simulation: you need accurate viewpoints and object placements to make virtual worlds feel real.
- Robotics and 3D understanding: correct camera and object geometry helps “world models” reason about space.
- Better 3D from 2D: edited alternate views can improve reconstructions when only one real photo exists.
In short, this work pushes image editing from “good-looking guesses” toward “precise, controllable geometry,” making AI edits more predictable and useful. The authors plan to release the benchmark, dataset, and model, which should help others build even better spatially aware image editors.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Real-image generalization: The dataset and benchmark are primarily Blender-synthesized; performance and metric reliability on real photographs (with unconstrained lighting, materials, reflections, motion blur, and complex occlusions) remain unquantified.
- Continuous orientation control: Object rotation is discretized into eight canonical views; the model’s ability to perform continuous, precise object orientation changes (and to match requested angles) is not evaluated.
- Camera roll and full 6-DoF: Camera control excludes roll and varies yaw/pitch in discrete steps with fixed intrinsics; support for full 6-DoF, variable intrinsics/FOV, lens distortions, and rolling shutter is not assessed.
- Ambiguity in “front” definition: The pipeline relies on VLM checks to verify canonical “front” views; how the system handles objects with ambiguous or symmetric fronts, or multiple plausible canonical orientations, is unclear.
- Non-rigid and articulated objects: The dataset appears dominated by rigid assets; manipulation of humans, deformables, thin structures, and articulated categories (pose changes, partial self-occlusion) is not addressed.
- Multi-object interactions: Simultaneous edits of multiple objects, collision avoidance, inter-object occlusions, and maintaining physical plausibility under multi-object transformations are not supported or evaluated.
- Physical realism in compositing: Object-level inpainting into T2I-generated backgrounds lacks explicit shadowing, contact, and lighting consistency; whether this yields physically implausible results (and how it affects training/evaluation) is unexplored.
- Evaluation dependence on closed models: Object rotation scoring and some verification steps use closed-source VLMs; reproducibility, biases, and robustness of these judgment signals are not analyzed or ablated.
- Detector sensitivity in FE: Framing Error depends on YOLO detections and Hungarian matching; sensitivity to detector failures, category taxonomy mismatches, small objects, and crowded scenes is not quantified.
- VGGT reliability on edited images: Viewpoint Error uses VGGT pose estimates on generative edits; the accuracy and failure modes of VGGT on non-photorealistic or geometrically inconsistent outputs (vs. true multi-view ground truth) need validation.
- Zoom magnitude accuracy: FE only checks zoom direction via a binary metric; how accurately the edit matches the requested zoom magnitude (and whether VE translation correlates with commanded Δd) is not reported.
- Metric weighting and calibration: VE and FE are simply averaged; principled weighting, calibration curves, error bars, and confidence intervals for metric reliability across task regimes are missing.
- Open-source evaluation stack: Alternatives to closed-source VLMs (for rotation correctness and consistency) and cross-metric agreement analyses with multiple open detectors/pose estimators are not provided.
- Instruction diversity and ambiguity: Camera/object instructions are templated or VLM-generated; robustness to colloquial, ambiguous, or multi-step natural language instructions from real users is not studied.
- Generalization to unseen categories and scenes: The category distribution and background diversity are shown, but systematic OOD tests (novel categories, extreme clutter, unusual materials, indoor/outdoor domain shifts) are absent.
- Bounding-box interface scope: Object moving/scaling is constrained by user-defined rectangles; support for mask-based targets, free-form trajectories, and spatial constraints (e.g., “place on the table without occluding the lamp”) is not explored.
- Edit composition and sequencing: Performance on composite edits that chain multiple spatial operations (e.g., move, rotate, then zoom) and cumulative error behavior over sequences remain unevaluated.
- Temporal and video consistency: The benchmark targets single images; extending to video-level spatial edits with temporally consistent camera/object manipulation and measuring temporal drift is an open direction.
- Single-view reconstruction claims: The proposed use of generated novel viewpoints to enhance 3D reconstruction lacks quantitative evaluation (e.g., metrics vs. true multi-view baselines, geometric consistency tests).
- Dataset licensing and ethics: The licensing status of GLB assets/backgrounds and ethical implications of synthetic compositing (e.g., realism leading to misinterpretation) are not discussed.
- Reproducibility of training: Pretraining uses proprietary internal data; the exact data mixture, ablations on LoRA rank/alpha, and compute/inference cost profiles (speed, memory) are not documented for full reproducibility.
- Failure case taxonomy: A structured analysis of typical failure modes (e.g., identity drift, background corruption, geometry hallucinations, detector misalignment) with targeted diagnostics is absent.
- Robustness under extreme edits: Performance under large rotations, extreme zooms, near-clipping viewpoints, heavy occlusions, and very small objects is not characterized.
- Human evaluation: No human studies corroborate that metric improvements correspond to perceived spatial correctness or user satisfaction for fine-grained control tasks.
- Cross-benchmark validation: Results are primarily on SpatialEdit-Bench; triangulation with additional public spatial-control benchmarks (even if limited) and real-world test suites is limited.
- Safety and misuse: Potential for deceptive viewpoint edits (e.g., falsifying spatial context) and guidance on safeguards/traceability are not considered.
These gaps point to concrete next steps: expanding real-world evaluation, adding continuous and full 6-DoF controls, designing geometry-grounded rotation metrics, diversifying object/scene types, reducing reliance on closed models, and rigorously validating metric fidelity and edit consistency across composite and temporal tasks.
Practical Applications
Overview
SpatialEdit introduces: (1) SpatialEdit-Bench, a geometry-aware benchmark for evaluating spatial edits using Viewpoint Error (VE) and Framing Error (FE); (2) SpatialEdit-500k, a controllable Blender-based synthetic data engine with ground-truth object/camera transformations and natural-language instructions; (3) SpatialEdit-16B, a fine-grained spatial editing model that excels at camera-centric (yaw/pitch/zoom) and object-centric (translate/scale/rotate) edits while preserving scene/identity.
Below are concrete applications derived from these findings, methods, and innovations.
Immediate Applications
These can be piloted or deployed now with the released benchmark, dataset, code, and model (subject to resource and integration constraints).
- Industry (Media/Advertising/Creative Tools): Geometry-faithful image edits
- Use case: Precise reframing (zoom, pitch, yaw) and object repositioning/rotation in product shots, ads, and catalog images without breaking background coherence.
- Sectors: Software, e-commerce, digital marketing.
- Tools/products/workflows:
- Editing plug-ins (Photoshop/Blender/Figma) exposing “rotate camera 15° right,” “move product into this box,” or “rotate object to front-right” controls.
- Batch APIs for DAM pipelines to generate canonical multi-view product imagery.
- QC gates using VE/FE to accept or reject automated edits.
- Dependencies/assumptions: Accurate object masks or SAM-like segmentation for object edits; identity preservation; domain gap from synthetic training to real photos; compute for inference.
- E-commerce/Retail: Canonical product view generation and templated layouting
- Use case: Uniform front/front-right/left/rear object views and template-conforming placements for storefronts and marketplaces.
- Sectors: Retail, logistics/content ops.
- Tools/products/workflows:
- Microservices that take a product image + instruction + target box to emit consistent hero shots and thumbnails.
- Template-driven batch layouting for leaflets or marketplace slots with FE/VE gating.
- Dependencies/assumptions: Clean product isolation; avoidance of hallucinated geometry when true multi-views are unavailable.
- Real Estate/Architecture: Controlled perspective edits and virtual staging
- Use case: Adjust camera pitch/yaw/zoom to standardize interior shots; move/scale decor while preserving background.
- Sectors: Real estate marketing, AEC visualization.
- Tools/products/workflows: Editors for perspective normalization and furnishing layout with red-box constrained moves.
- Dependencies/assumptions: Generalization from synthetic scenes to interiors; accurate occlusion handling; brand/regulatory policies about scene fidelity.
- Robotics and Vision R&D: Geometry-aware evaluation and training data
- Use case: Benchmark spatial control in multimodal/editing models with VE/FE; generate synthetic pairs for pose-conditioned training; stress-test viewpoint invariance.
- Sectors: Robotics, autonomous systems, academia.
- Tools/products/workflows:
- Automated regression tests for spatial tasks in model CI using SpatialEdit-Bench.
- Synthetic curriculum via SpatialEdit-500k pipeline to train/finetune spatially controllable models.
- Dependencies/assumptions: Domain transfer to robotics imagery; availability of 3D assets; compute for VGGT-based evaluation.
- 3D Reconstruction Enhancement (research/production pipelines)
- Use case: Synthesize auxiliary viewpoints from a single image to reduce depth-scale ambiguity, improving single-view reconstructions (e.g., NeRF/GS bootstraps).
- Sectors: 3D vision, VFX, cultural heritage digitization.
- Tools/products/workflows: Reconstruction pre-processing step that generates a small set of pose-consistent pseudo-views; select views with low VE relative to the source.
- Dependencies/assumptions: Risk of appearance/geometry hallucinations; need for verification and robust pose estimation; better for rigid/structured scenes.
- MLOps/QA for Generative Editing
- Use case: Add VE/FE as quantitative gates in deployment to ensure spatial instruction compliance (e.g., rejecting outputs that fail camera pose targets).
- Sectors: Software, platform engineering.
- Tools/products/workflows: Evaluation harnesses integrated with CI pipelines; dashboards tracking pose errors across releases.
- Dependencies/assumptions: Access to VGGT or equivalent camera estimation; additional compute; sensitivity to scene content.
- Education and Training (Vision/Graphics)
- Use case: Hands-on labs demonstrating camera geometry (yaw/pitch/zoom), object transformations, and evaluation pitfalls (semantic vs geometric correctness).
- Sectors: Higher education, professional training.
- Tools/products/workflows: Jupyter/lab kits built on SpatialEdit-500k, benchmark, and baseline model.
- Dependencies/assumptions: GPU access for inference; content licensing for classroom use.
- Software/Data Tooling: Domain-specific spatial editing datasets
- Use case: Generate custom spatial-editing datasets (e.g., for specific product lines or indoor categories) by reusing the Blender pipeline.
- Sectors: Software, enterprise AI teams.
- Tools/products/workflows: Configurable asset ingesters, background synthesis, instruction templating, automatic mask/quality checks.
- Dependencies/assumptions: Rights to 3D assets; reliance on VLMs/SAM for filtering/annotation; compute for rendering.
- AR/VR Content Creation
- Use case: Quickly storyboard and iterate consistent camera moves or object placements in concept art and scene mockups.
- Sectors: Gaming, XR production.
- Tools/products/workflows: Editor integrations to prototype camera paths (via instruction steps) and validate with FE/VE.
- Dependencies/assumptions: Integration with Unity/Unreal/Kits; consistency across frames if used for pre-visualization.
- Consumer Photo Apps
- Use case: Perspective correction and reframing (“tilt up by 15°,” “zoom to fit subject”), or relocating an object within a target region.
- Sectors: Mobile software, social media tools.
- Tools/products/workflows: On-device or cloud-assisted lightweight variants/distillations of SpatialEdit-16B.
- Dependencies/assumptions: Latency/battery constraints; smaller models or server offload; robust object selection UI.
Long-Term Applications
These require additional research, scaling, domain adaptation, or regulatory maturation.
- Healthcare Imaging: Geometry-faithful view standardization and augmentation
- Use case: Normalize imaging views (e.g., rotate/tilt) or synthesize clinically standardized perspectives for training/education.
- Sectors: Healthcare.
- Tools/products/workflows: Domain-specialized spatial editors trained on medical assets; evaluation with medically validated pose metrics.
- Dependencies/assumptions: Strict domain shift; clinical safety/validation; regulatory approvals; protected data access.
- Autonomous Driving and Digital Twins: Photorealistic, pose-accurate augmentations
- Use case: Generate alternative viewpoints of scenes for training perception; enforce camera trajectories in simulated QA.
- Sectors: Automotive, smart cities, industrial IoT.
- Tools/products/workflows: Embedded VE/FE-like metrics in simulation loops; scene-aware data engines generating paired views with ground-truth transforms.
- Dependencies/assumptions: High-fidelity domain assets; multi-sensor consistency (LiDAR, radar); safety validation.
- Robotics Manipulation and Embodied AI: Language-driven spatial control
- Use case: Teach policies to move/rotate objects to target areas specified in language or bounding boxes (sim2real transfer).
- Sectors: Robotics, logistics, manufacturing.
- Tools/products/workflows: Coupling SpatialEdit-style supervision with physics simulators; structured curricula for manipulation.
- Dependencies/assumptions: Physics-consistent edits (beyond image realism); 3D scene state estimation; real-world generalization.
- Multi-View Consistent Video Generation with Camera Control
- Use case: Extend SpatialEdit’s camera-centric control to videos with smooth, accurate trajectories for cinematography and virtual production.
- Sectors: Media, entertainment, XR.
- Tools/products/workflows: Video diffusion architectures incorporating explicit pose conditioning; VE/FE-inspired temporal metrics.
- Dependencies/assumptions: New datasets with pose-grounded videos; addressing drift and temporal artifacts.
- High-Fidelity 3D Reconstruction from Sparse Views
- Use case: Use pose-consistent synthetic views as priors to bootstrap NeRF/3DGS in extremely sparse capture settings.
- Sectors: Mapping, VFX, cultural heritage, robotics.
- Tools/products/workflows: Joint optimization that downweights hallucinated views; pose-aware confidence scoring; cross-validation with depth.
- Dependencies/assumptions: Stronger guarantees on multi-view consistency; robust outlier detection.
- Standards, Auditing, and Policy for Generative Spatial Edits
- Use case: Capability reporting and procurement standards using geometry-aware metrics; audit trails for camera/object edits.
- Sectors: Policy, compliance, platform governance.
- Tools/products/workflows: VE/FE thresholds in evaluation reports; audit metadata for edit provenance and pose deltas.
- Dependencies/assumptions: Industry consensus; alignment with content authenticity initiatives; potential to standardize disclosures of geometric edits.
- Industrial Inspection and Energy: Consistent viewpoint synthesis for change detection
- Use case: Normalize viewpoints across inspection cycles (e.g., turbines, pipelines) for more reliable comparisons.
- Sectors: Energy, manufacturing, infrastructure.
- Tools/products/workflows: Camera-pose–guided editing to align images before analytics; VE-based verification.
- Dependencies/assumptions: Strict accuracy requirements; tolerance to environmental variability; safety-critical validation.
- Finance/Insurance: Standardized imagery for assessment and fraud analytics
- Use case: Align viewpoints of asset photos (e.g., property, vehicles) to facilitate consistent review and anomaly detection.
- Sectors: Finance, insurance.
- Tools/products/workflows: Pose-normalization services; internal benchmarks to validate spatial editing fidelity.
- Dependencies/assumptions: Legal/ethical constraints; domain adaptation to varied capture conditions.
- New UI Paradigms for Spatial Editing
- Use case: Natural language + bounding-box interfaces to specify “where and how” to edit with explicit geometric intent.
- Sectors: Creative software, HCI.
- Tools/products/workflows: Interactive tools that surface canonical views and target rectangles with real-time feedback on VE/FE proxies.
- Dependencies/assumptions: User studies; human factors research; on-device acceleration.
Cross-Cutting Assumptions and Dependencies
- Domain transfer: SpatialEdit-16B and SpatialEdit-500k are trained largely on synthetic assets and general imagery; specialized domains (medical, autonomy) need fine-tuning and validation.
- Reliance on external components: Data engine uses VLMs (e.g., Gemini/Qwen) and SAM3; evaluation uses VGGT. Availability, licensing, and reproducibility of these components matter.
- Compute and latency: Geometry-aware evaluation (VE/FE) and high-capacity models may require substantial compute; mobile use cases need distillation.
- Data/IP: Rights to 3D assets and backgrounds; compliance with content authenticity policies.
- Safety and ethics: Image edits used in regulated or safety-critical contexts must include safeguards against hallucination and misrepresentation; geometry metrics help, but human oversight may be required.
Glossary
- 6-DoF: Six degrees of freedom describing a camera’s 3D motion (3 rotations + 3 translations). "such as full 6-DoF camera trajectories"
- AdamW: An Adam optimizer variant with decoupled weight decay for better generalization. "During pre-training, we used the AdamW optimizer with parameters and "
- Blender: An open-source 3D creation and rendering suite used to synthesize scenes and objects. "We leverage Blender to synthesize both objects and scenes,"
- bounding box: A rectangular region that specifies an object’s location and extent in an image. "translation and scaling of objects specified via user-defined bounding boxes."
- camera-centric view manipulation: Changing the camera’s viewpoint (e.g., yaw, pitch, zoom) while keeping scene content consistent. "camera-centric view manipulation (e.g., yaw, pitch, and zoom)"
- canonical viewpoints: A fixed, discrete set of standard object orientations for consistent viewpoint specification. "we discretize object orientation into eight canonical viewpoints: right, front-right, front, front-left, left, rear-left, rear, and rear-right."
- compositing: Combining separate visual elements (e.g., foreground objects and backgrounds) into a single image. "inpainting-based synthesis, compositing, and expert-model orchestration"
- DiT: Diffusion Transformer; a transformer-based backbone for diffusion generative models. "with transformer-based backbones such as DiT improving scalability and conditioning flexibility"
- feed-forward transformer: A transformer architecture used in a forward pass to directly infer outputs without iterative optimization. "which is a feed-forward transformer that directly infers key 3D attributes of a scene"
- focal length: A camera intrinsic controlling field of view and magnification, influencing zoom. "where is the image center and is the focal length."
- Framing Error (FE): A detector-based metric to assess spatial layout and zoom-direction consistency of edited images. "We thus introduce an object-centric spatial consistency metric (FE: Framing Error)"
- geodesic distance: The shortest distance on a curved manifold; used to measure rotation differences on SO(3). "and a rotation error based on the geodesic distance on "
- geometric mean: A multiplicative average that balances factors by penalizing imbalance between them. "The geometric mean formulation enforces a multiplicative coupling between spatial accuracy and semantic fidelity"
- Hungarian Matching: An algorithm for optimal assignment used here to match detected objects across images. "via the Hungarian Matching~\cite{hungarian} algorithm"
- inpainting: Filling or synthesizing image regions (often masked) to integrate objects into new backgrounds. "and inpaint the rendered object into these backgrounds"
- Intersection over Union (IoU): A metric measuring overlap between predicted and ground-truth regions (e.g., boxes or masks). "we first employ a detection model to calculate the IoU."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning technique that adds small trainable adapters. "and then specialize using parameter-efficient fine-tuning (LoRA) on SpatialEdit-500k."
- MMDiT: A multimodal Diffusion Transformer denoiser used to edit latent representations. "an MMDiT~\cite{stablediffusion3} denoises it under multimodal guidance"
- novel-view synthesis: Generating images of a scene from new, unseen camera viewpoints. "camera trajectory manipulation and novel-view synthesis using simulated data"
- parameter-efficient fine-tuning: Adapting large models by training a small number of additional parameters (e.g., LoRA). "parameter-efficient fine-tuning (LoRA)"
- pitch: Vertical tilting of the camera around its horizontal axis. "varying yaw, pitch, and zoom."
- point tracks: Tracked feature points across views/frames that provide geometric constraints in 3D. "including camera parameters (intrinsics/extrinsics), depth maps, point maps, and 3D point tracks"
- Segment Anything Model (SAM3): A segmentation model that produces masks from prompts or cues across diverse scenarios. "we apply the Segment Anything Model (SAM3) to obtain object masks"
- single-view reconstruction: Recovering 3D structure from a single image input. "our model can also serve as a practical enhancement tool for single-view reconstruction."
- SO(3): The mathematical group of 3D rotations used to represent and compare orientations. "geodesic distance on "
- Spearman correlation: A nonparametric rank correlation coefficient used to compare ranking consistency. "we then compute Spearman correlation between the predicted and true rankings"
- text-to-image model: A generative model that synthesizes images conditioned on text prompts. "with a high-quality text-to-image model~\cite{nano-banana}"
- VAE: Variational Autoencoder; encodes images into latents and decodes them back to the image space. "The image is encoded into a VAE latent"
- VGGT: Visual Geometry Grounded Transformer for feed-forward estimation of camera parameters and 3D attributes. "we employ VGGT~\cite{wang2025vggt}, which is a feed-forward transformer"
- Viewpoint Error (VE): A geometry-aware metric aggregating rotation and translation errors of predicted camera pose. "We quantify Viewpoint Error (VE) by reconstructing the camera pose in 3D space"
- Vision-LLM (VLM): A model that processes and reasons over both visual and textual inputs. "We further use a VLM to generate paired images with accurate viewpoint changes"
- world model: A generative video/scene model that simulates or predicts visual dynamics of the world. "video-based world models remain significantly inferior to image-based spatial editing models"
- world-to-camera extrinsics: The rotation and translation that map world coordinates into the camera coordinate frame. "returns estimated world-to-camera extrinsics:"
- yaw: Horizontal panning of the camera around the vertical axis. "yaw, pitch, and zoom"
- YOLO: A family of real-time object detectors (“You Only Look Once”). "One branch employs a YOLO-based~\cite{yolov10} detector"
- zoom: Change in apparent scale via focal length or distance adjustments. "varying yaw, pitch, and zoom."
Collections
Sign up for free to add this paper to one or more collections.