SPATIALGEN: Layout-guided 3D Indoor Scene Generation
Abstract: Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
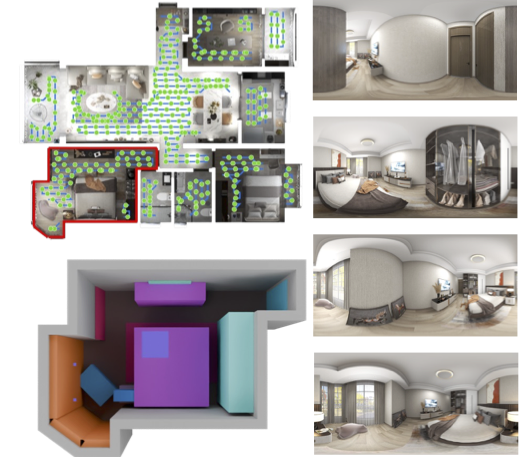
This paper introduces SpatialGen, a new AI system that can create realistic 3D indoor rooms (like bedrooms, kitchens, offices) using a simple 3D “layout” as a guide. Think of the layout like a room blueprint that says where the walls, doors, windows, and furniture should go. SpatialGen can then fill in the details—colors, textures, and shapes—so the room looks real from many different camera angles. It can work from a short text description or a reference photo, and it can even transform a real video of a room into a brand-new styled scene.
To make this possible, the authors also built a huge dataset of indoor scenes to train the model.
What questions does the paper try to answer?
- How can we automatically create realistic 3D rooms that look good from every angle?
- How can we make sure the AI follows a given room layout (so the bed stays where the blueprint says, the window is on the right wall, etc.)?
- How do we keep the scene consistent across different views (so the same couch appears in the same place with the same look when the camera moves)?
- Can we do all this at large scale by training on a big, well-annotated dataset?
How did they do it?
The authors combine two big pieces: a large dataset and a new AI model that uses the layout to guide generation.
1) A massive new dataset
They built a synthetic (computer-generated) dataset of indoor scenes:
- 12,328 full scenes with 57,440 rooms
- 4.7 million panoramic images (360-degree views)
- Precise labels for room structure (like walls, doors, windows) and objects
Why this matters: AI models learn better with lots of high-quality, well-labeled examples. This dataset gives the model many different rooms and camera angles to learn from, which helps it create more realistic and consistent results.
2) The SpatialGen model
Here’s the high-level idea in plain terms:
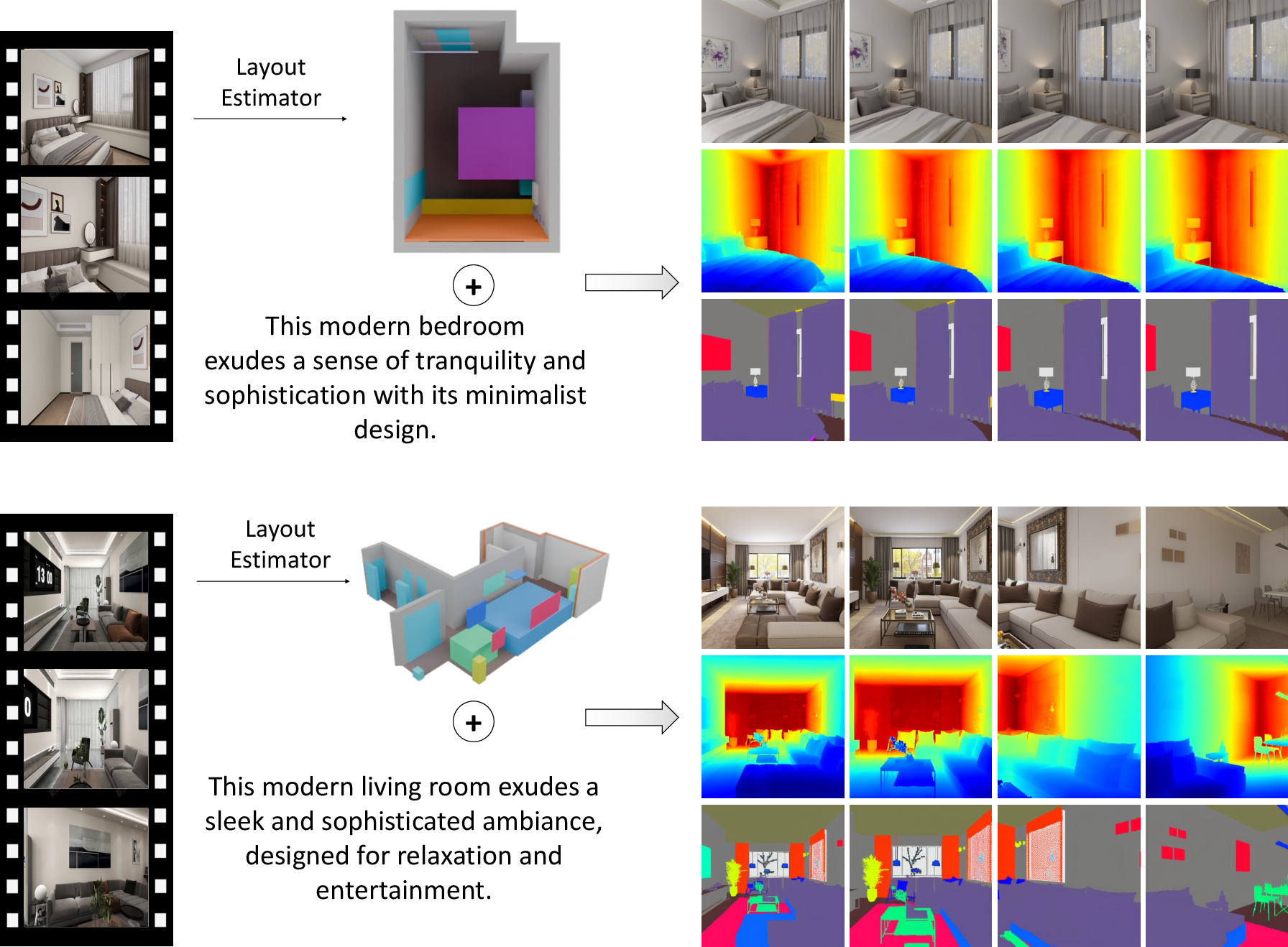
- Input: a 3D layout (like a blueprint with 3D boxes for furniture), plus either a text prompt (“a cozy modern living room”) or a reference image that shows the style.
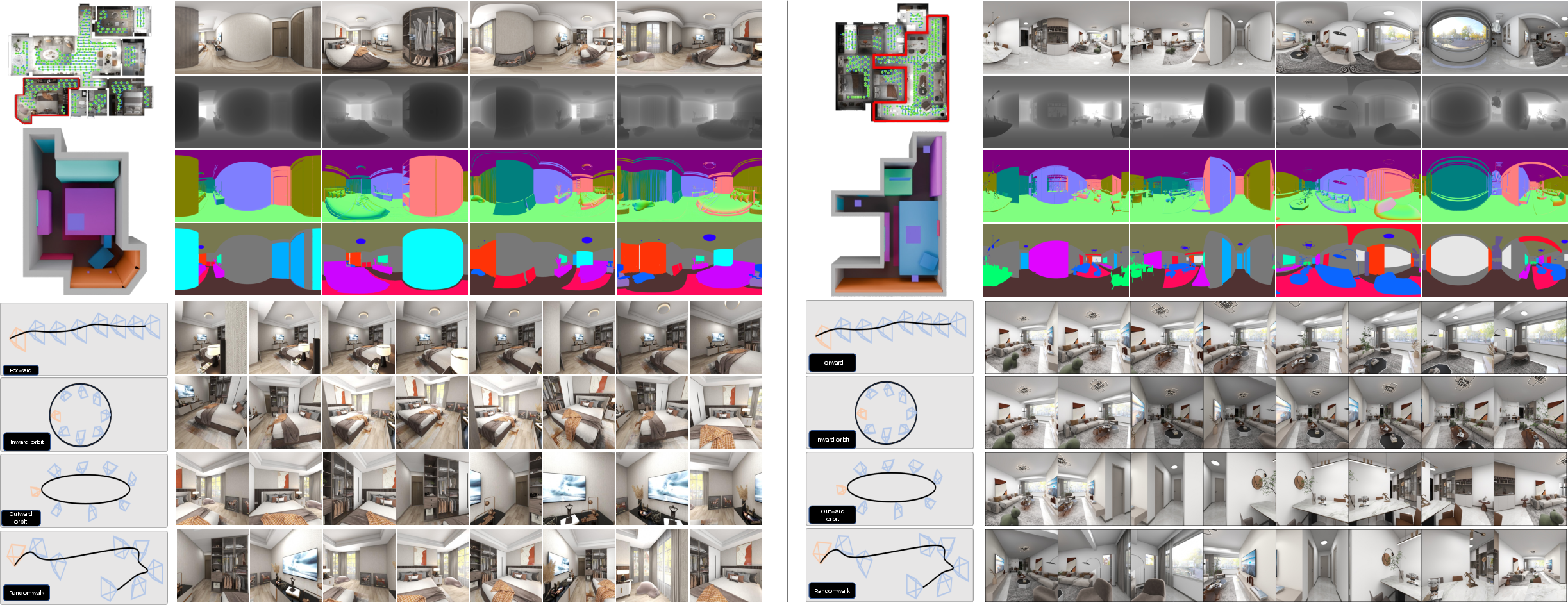
- Output: realistic images of the room from many viewpoints, along with extra “helper” maps that describe the scene’s 3D shape and the meaning of each pixel (what object it belongs to). From these, the system rebuilds the full 3D scene.
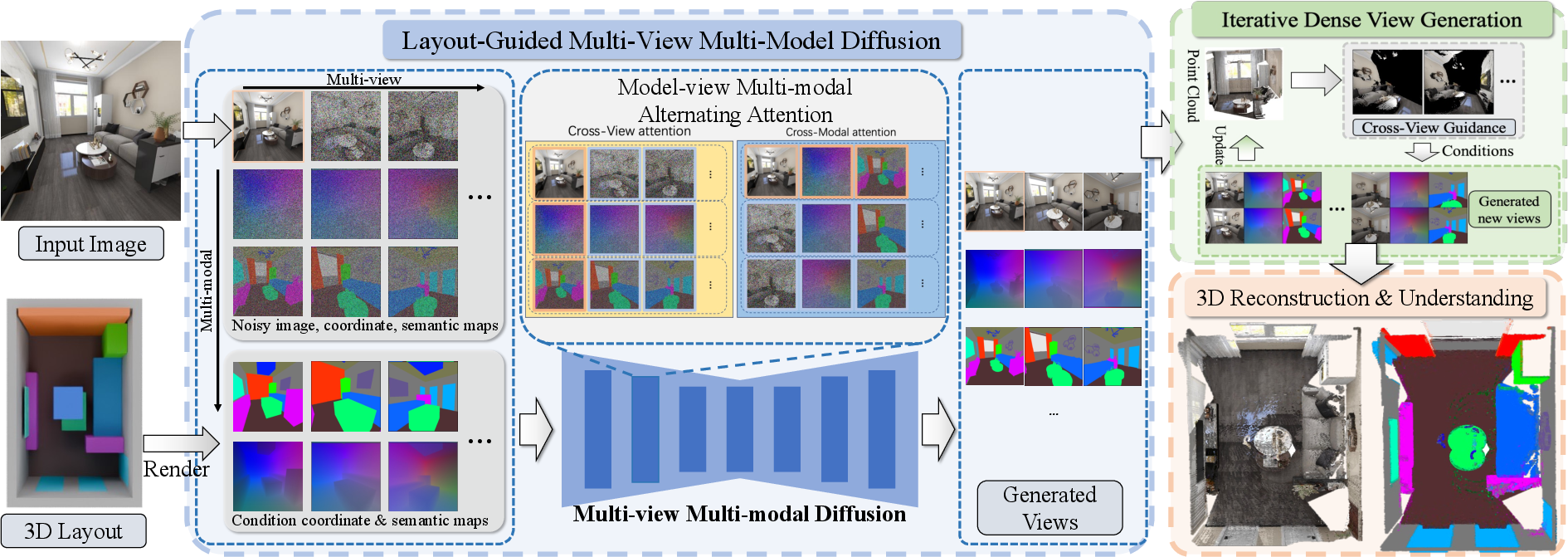
To do that, SpatialGen uses several key ideas:
- Multi-view generation: It creates images from different camera positions, like a movie director moving the camera around the room. This is hard because every view must show the same scene consistently.
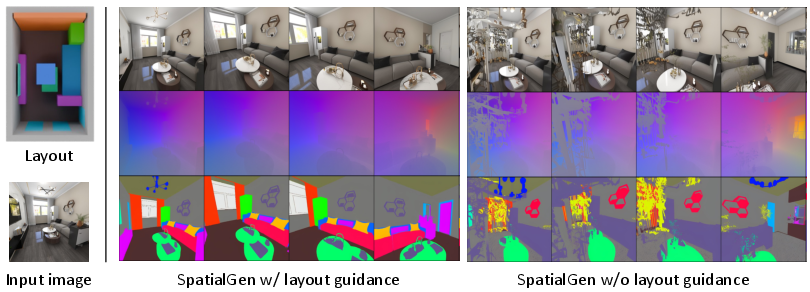
- Layout guidance: The model converts the 3D layout into two simple per-view maps it can understand:
- A semantic map: which pixels belong to which object category (wall, bed, chair…).
- A scene coordinate map: for each pixel, where that point is in 3D space. Think of it like each pixel comes with a tiny label that says “I live at this 3D location.”
- Diffusion model: A type of image generator that starts with noise and gradually “cleans it up” into a detailed image. SpatialGen does this across multiple views at once.
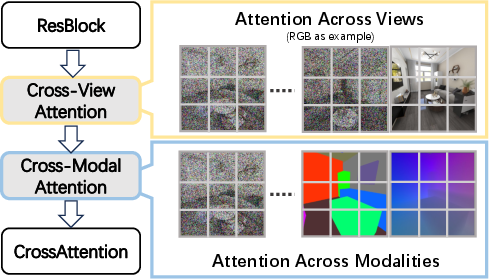
- Alternating attention (how the model “focuses” while generating):
- Cross-view attention: shares information between different camera views so they match.
- Cross-modal attention: aligns appearance (RGB image), meaning (semantic map), and geometry (scene coordinates) within each view so textures, labels, and shapes agree.
- Iterative dense view generation: Instead of generating all views at once (which is heavy on memory), it does it in rounds. It keeps a growing 3D “point cloud” (like colorful 3D confetti) built from earlier views to guide later ones, reducing mistakes.
- Smart geometry compressor (SCM-VAE): A special module that compresses and reconstructs the scene coordinate maps without losing sharp edges or accurate shapes. It also outputs a confidence score, so the system can ignore uncertain points and avoid errors.
- 3D reconstruction with Gaussian splats: After generating many images and maps, the system builds a 3D scene made of tiny, soft blobs (“Gaussians”) that can be rendered from any angle smoothly and fast.
In short, SpatialGen starts from a room layout, produces consistent multi-view images plus 3D info, and reconstructs a detailed 3D scene you can look at from anywhere.
What did they find?
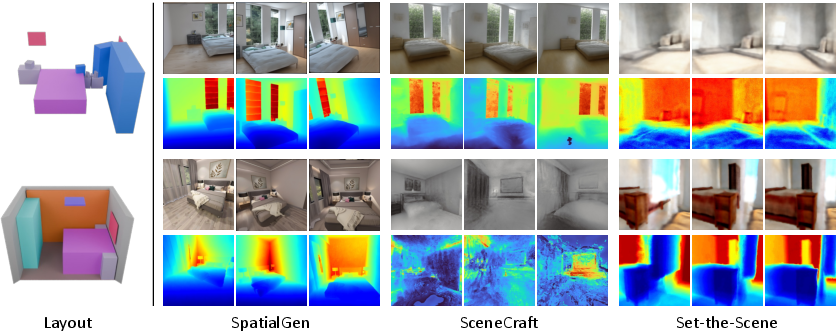
- Better realism and consistency: Compared to previous methods, SpatialGen produces sharper, more realistic rooms that stay consistent as the camera moves.
- Strong layout control: The generated rooms follow the input layout well—furniture appears where it should, and shapes and sizes make sense.
- Works from text or images: You can guide the style using either a text description or a reference photo.
- Beats two common baselines:
- Score distillation methods (which use powerful 2D models in a roundabout way) often produce blurry or oddly colored results. SpatialGen’s results look cleaner and more detailed.
- Panorama-only methods (which make a single 360 image from one spot) struggle when the camera moves. SpatialGen handles new viewpoints much better.
- Layout helps a lot: When they turned off layout guidance, quality dropped—especially for big camera moves. With layout, views stayed more accurate and consistent.
- The big dataset matters: Training on their large dataset clearly improved scene quality and stability compared to training on smaller ones.
Why this is important: Consistency across views is the big challenge in 3D scene generation. If a chair changes color or position when the camera moves, the scene feels fake. SpatialGen significantly reduces these issues.
What does it mean for the future?
- Faster content creation: Interior designers, game developers, and filmmakers could go from a simple room layout to a detailed, realistic 3D scene much more quickly.
- Better VR/AR experiences: Consistent, realistic rooms make virtual environments feel more believable.
- Training robots: Robots need realistic indoor worlds to learn navigation and interaction safely. SpatialGen can generate diverse, high-quality training environments.
- Community boost: The authors are open-sourcing their dataset and models, which will help other researchers build even better systems.
Limitations and next steps:
- It’s computationally heavy, so it can’t generate too many views at once.
- The way you choose camera positions affects quality.
- Future work will aim to make it faster and more flexible.
Overall, SpatialGen combines a strong guiding “blueprint” (the layout), a powerful generation engine (multi-view diffusion with attention), and a massive training set to create realistic, controllable 3D indoor scenes that stay consistent from every angle.
Knowledge Gaps
Below is a single, concrete list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each point is phrased to be actionable for future research.
- Generalization to real-world data: No quantitative evaluation on real-captured datasets (e.g., ScanNet, Matterport3D, ScanNet++) or with layouts estimated from real videos; measure domain gap and develop adaptation strategies.
- Robustness to imperfect inputs: Sensitivity to layout inaccuracies (mislocalized boxes, wrong categories), camera pose noise, and reference-image quality is unquantified; design perturbation studies and robustness training.
- Semantic accuracy metrics: Lack of per-view and 3D semantic evaluation (e.g., mIoU, instance AP, cross-view consistency of labels); establish standardized metrics and benchmarks for semantic maps and 3D semantic features.
- Geometry fidelity metrics: No quantitative assessment of scene-coordinate accuracy (e.g., MAE/RMSE), depth error, Chamfer distance to ground-truth CAD/meshes; add geometry metrics and comparisons to reconstruction baselines.
- Cross-view consistency measurement: The method claims improved multi-view consistency but does not report epipolar residuals, feature reprojection errors, or multi-view semantic consistency scores; define and compute such metrics.
- Ablation of alternating attention: The cross-view/cross-modal alternating attention is introduced without ablations versus simpler/fused attention designs; analyze trade-offs in quality, memory, and speed across variants.
- Scalability and efficiency: Inference-time, memory footprint, and the number of views that can be generated per iteration are not reported; profile the pipeline end-to-end and explore model compression/distillation.
- Camera trajectory sampling: The paper notes camera sampling affects quality but provides no principled view-planning; investigate learned or heuristic trajectory planners that maximize coverage and consistency.
- End-to-end training with reconstruction: Scene synthesis and Gaussian-splatting reconstruction are decoupled; explore joint optimization or differentiable end-to-end training to tighten cross-modal consistency.
- Dataset domain coverage and bias: The synthetic dataset’s style, cultural, and object distribution biases are uncharacterized; audit diversity (materials, clutter, small objects, reflective/transparent surfaces) and quantify coverage gaps.
- Synthetic-to-real transfer: No strategies for bridging photorealistic renders to real sensor artifacts (noise, motion blur, auto-exposure, white balance shifts); develop augmentation and domain adaptation pipelines.
- Reflective/transparent materials: Performance on mirrors, glass, and specular surfaces is not studied; evaluate failure cases and incorporate physics-based cues or reflection-aware modeling.
- Materials and lighting: The model generates RGB, semantics, and scene coordinates, but not PBR materials or lighting parameters; explore multi-modal generation of BRDFs and illumination for physically grounded scenes.
- Dynamics and temporality: Only static scenes are considered; extend to articulated/dynamic objects and temporally coherent scene generation across time.
- Label taxonomy alignment: The dataset’s semantic taxonomy is not reconciled with common standards (e.g., NYU, ScanNet categories); provide mappings and cross-dataset generalization tests.
- Uncertainty calibration: SCM-VAE’s confidence map c is thresholded without calibration analysis (e.g., ECE, NLL); assess calibration quality and its downstream impact on warping and reconstruction.
- Diversity vs control: No quantitative analysis of generative diversity (e.g., intra-prompt diversity, FID/Precision-Recall trade-offs) or fine-grained controllability over object attributes (style, materials); design controllability metrics and tests.
- Text conditioning pathway: Text-to-3D relies on a ControlNet to produce the reference image rather than native text-conditioned multi-view diffusion; evaluate direct text conditioning and object-level text alignment metrics.
- Baselines beyond SDS/panorama: Missing comparisons to modern 3D generative baselines (e.g., ATISS, DiffuScene, GAUDI, Director3D) on layout realism and multi-view synthesis; include strong 3D-based baselines.
- Physical plausibility checks: No evaluation of scene physics (support relations, collisions, clearances, human affordances); incorporate physical plausibility metrics or constraints.
- Multi-room generation: Focus is on single-room layouts, despite the dataset containing multi-room scenes; extend to connected spaces (hallways, apartments) and test cross-room transitions.
- Pose-error sensitivity: Warping depends on accurate camera poses; quantify degradation under pose noise and explore pose-robust conditioning.
- Licensing, privacy, and reproducibility: Dataset release details (licensing, consent, anonymization), annotation quality checks, and exact train/test splits are not fully documented; provide comprehensive datasheets and reproducible protocols.
- Failure modes: No systematic analysis of typical errors (e.g., texture repetition, semantic mislabeling, geometry drift); compile a taxonomy of failures and correlate with scene/layout characteristics.
- Resource accessibility: Training uses 64 RTX 4090 GPUs; explore lighter architectures, efficient attention, or distillation for broader community access.
- Richer layout priors: The method uses object bounding boxes; investigate richer constraints (floor plans, meshes, CAD models, surfaces, affordances) and their impact on controllability and realism.
- Additional modalities: Although dataset includes normals and instance masks, generation targets exclude them; add multi-target outputs (normals, instance maps) and evaluate multi-task benefits.
- SCM-VAE validation: Beyond visuals, provide quantitative comparisons to image VAEs and alternative geometry encoders (e.g., normal-depth joint VAE), sensitivity to gradient-loss weights, and cross-scene generalization.
- Real-time VR performance: 3DGS promises fast rendering, but interactive frame rates and latency for VR/AR are not measured; benchmark real-time performance and optimize the pipeline for interactive use.
Glossary
- 3D Gaussian splatting: A rendering and reconstruction technique that represents scenes with collections of 3D Gaussians to enable efficient view synthesis and optimization. "followed by 3D Gaussian splatting optimization that reconstructs an explicit radiance field to enable free-viewpoint rendering."
- 3D semantic layout prior: A coarse 3D scene description of object boxes (position, size, orientation, category) used to condition and guide generation. "3D semantic layout prior (\cref{fig:teaser}) has been employed in the literature to guide the generation process."
- CLIP similarity: A metric that measures text–image alignment using CLIP embeddings. "CLIP similarity score~\cite{CLIP} to measure text-image alignment"
- ControlNet: An auxiliary conditioning network for diffusion models that injects control signals like layouts to steer generation. "we further train a layout ControlNet~\cite{ControlNet} to generate the reference image for our latent diffusion model."
- cross-modal attention: An attention mechanism that aligns features across different modalities (image, semantics, geometry) within each view. "cross-modal attention for fine-grained feature alignment between appearance, semantic, and geometric representations."
- cross-view attention: An attention mechanism that aggregates information across multiple viewpoints to maintain consistency. "cross-view attention for consistent information propagation across different viewpoints;"
- differentiable rendering: A rendering process whose operations are differentiable, enabling gradient-based optimization of 3D representations. "During differentiable rendering optimization, we employ a depth supervision loss that utilizes the predicted scene coordinate maps, enabling rapid convergence in just 7,000 steps."
- epipolar constraint: A multi-view geometric constraint enforcing correspondences along epipolar lines between camera views. "such as epipolar constraint~\cite{hartley2003multiple}, to capture multi-view features across different source views."
- explicit radiance field: An explicit parameterization of scene radiance used for novel view rendering. "reconstructs an explicit radiance field to enable free-viewpoint rendering."
- FID: Fréchet Inception Distance; a generative quality metric comparing distributions of deep features between generated and real images. "We employ PSNR, SSIM~\cite{SSIM}, LPIPS~\cite{LPIPS}, and FID~\cite{TTUR} to evaluate the quality of image generation."
- Image Reward: A learned aesthetic preference score reflecting human judgments of image quality. "Image Reward~\cite{ImageReward} to assess human aesthetic preference."
- Iterative Dense View Generation: A strategy that synthesizes views incrementally, updating a global representation to ensure full scene coverage and consistency. "via Iterative Dense View Generation (detailed in \cref{sec:iterative_generation})."
- latent diffusion model: A diffusion model that operates in a learned latent space (e.g., from a VAE) for efficient image generation. "A multi-view latent diffusion model takes a single or multiple posed source views as input and generates multiple novel images in some target camera views."
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric that compares images using deep features. "We employ PSNR, SSIM~\cite{SSIM}, LPIPS~\cite{LPIPS}, and FID~\cite{TTUR} to evaluate the quality of image generation."
- multi-view diffusion model: A diffusion framework conditioned on multiple input views and camera poses to synthesize novel views. "We start by providing a brief overview of multi-view diffusion models in \cref{sec:prelimiary}."
- panorama-as-proxy: A strategy that uses panoramic images as proxies when paired multi-view 3D layout data are scarce. "score distillation~\cite{SetTheScene, SceneCraft, Layout2Scene, GALA3D} and panorama-as-proxy~\cite{ControlRoom3D, Ctrl-Room}."
- Plücker coordinate maps: A line-based camera encoding using Plücker coordinates per pixel to represent viewing rays. "Camera poses are encoded by Plucker coordinate maps~\cite{plucker1865xvii, RayDiffusion} and then processed by a Transformer to compute view-conditioned embeddings."
- point cloud: A set of 3D points (optionally with color/semantic attributes) representing scene geometry. "incrementally maintain a colored global point cloud of the scene to enforce appearance consistency between iterations."
- PSNR: Peak Signal-to-Noise Ratio; a distortion-based metric measuring reconstruction fidelity. "We employ PSNR, SSIM~\cite{SSIM}, LPIPS~\cite{LPIPS}, and FID~\cite{TTUR} to evaluate the quality of image generation."
- scene coordinate map: A per-pixel map that encodes the 3D coordinates of the scene point observed at each pixel. "we further predict a pixel-wise semantic map , scene coordinate map for each viewpoint."
- SCM-VAE: Scene Coordinate Map Variational Autoencoder; a VAE specialized for encoding/decoding scene coordinate maps with confidence estimates. "we introduce SCM-VAE, which encodes a scene coordinate map into a latent representation as and reconstructs into a scene coordinate map with an uncertainty map as "
- score distillation: A technique that uses gradients from pretrained 2D diffusion models to supervise 3D content creation without large-scale 3D training data. "score distillation~\cite{SetTheScene, SceneCraft, Layout2Scene, GALA3D}"
- SDS method: Score Distillation Sampling; a specific form of score distillation used to optimize 3D representations via 2D model guidance. "due to the inherent limitation of the SDS method~\cite{DreamFusion}"
- semantic Gaussian Splatting: 3D Gaussian splats augmented with semantic features to enable semantic-aware reconstruction and rendering. "recover those dense views to a unified semantic Gaussian Splatting via an off-the-shelf reconstruction method~\cite{RaDe-GS}."
- semantic segmentation map: A per-pixel map assigning a semantic category to each pixel. "semantic (semantic segmentation map)"
- SSIM: Structural Similarity Index; a perceptual similarity metric comparing luminance, contrast, and structure. "We employ PSNR, SSIM~\cite{SSIM}, LPIPS~\cite{LPIPS}, and FID~\cite{TTUR} to evaluate the quality of image generation."
- uncertainty map: A per-pixel confidence estimate that helps filter unreliable reconstructions or points. "reconstructs into a scene coordinate map with an uncertainty map as "
- v-parametrization: A diffusion training parameterization that predicts v (a velocity-like target) for improved stability and learning. "We use a v-parametrization and a v-prediction loss for the diffusion model~\cite{salimans2022progressive}."
- v-prediction loss: The loss function associated with v-parametrization that trains the model to predict v during diffusion. "We use a v-parametrization and a v-prediction loss for the diffusion model~\cite{salimans2022progressive}."
- warped image: An image obtained by warping source views into a target view using predicted geometry (e.g., scene coordinates). "to obtain the warped image ."
Collections
Sign up for free to add this paper to one or more collections.